こんにちは。「Rookと仲間たち、クラウドネイティブなストレージの Advent Calendar 2020」6日目は、タイトルの通り、ストレージ初心者だった筆者がCephのベンチマークを計測した際に学んだストレージシステムの性能指標とCephに代表されるような分散ストレージを計測する上での特徴や注意点について簡単にまとめます。
Rookではなくてもクラウドネイティブなストレージに関する投稿であればヨシという参加条件でしたので、Rookでもよく利用されているCephをこよなく愛する筆者としては、のりと勢いだけで応募しました。ろくに熟考もせず記載しているため間違いがあれば優しくご指摘ください!
はじめに
さて、本記事は上記の通り、ストレージ素人だった筆者がCephのベンチマーク等を担当したときに、事前にこんな知識を知っておきたかったと感じた事柄について、記載したいと考えております。
また断りが無い場合を除き基本的には、ブロックストレージである、RBDをベンチマークすることに関して記載しています。
目次
書き始めたら盛りだくさんになってしまったので複数回に分割・・・。
こちらの目次にそって紹介していきます。
第一回は、知識ベースの話を記載します。
第二回以降では実際に動かし、ベンチマークする上でのテクニックに関して記載します。
-
第一回(6日目)
- ディスクIOの仕組みについてある程度理解する
- 性能指標について理解する
- Rook/Cephのアーキテクチャについて留意しておく
- キャッシュの存在を理解しておく
- プレースメントグループによる分散読み書き
- ディスクIOの仕組みについてある程度理解する
-
第二回(13日目予定・・・はたしてほんとに書ききれるのか!?)
- なにを測定したいのかを明確にすること
- アプリケーションから使用する場合の性能が知りたいのか?
- ストレージシステム全体のボトルネック・性能限界を知りたいのか?
- ワーストケースが知りたいのか?平均値が知りたいのか?
- 測定したいことに合わせた試験環境を準備する
- 測定ツールのパラメータをある程度理解する
- 簡単な試験ならDDコマンドでも十分
- FIOというツールにはさらいいろんなパラメータを用いることが可能
- 最後に実際のCephの測定をしてみる
- アプリケーションを疑似した計測例
- Cephシステム全体に負荷をかける
- なにを測定したいのかを明確にすること
ディスクIOの仕組みについてある程度理解する
ストレージの性能指標
一口に性能指標といってもストレージを評価する尺度はいろいろあります。
たとえば、もっとも一般的な指標はストレージ容量でしょう。まず必要な容量をまかなえることがストレージの第一の条件となるでしょう。
次によく評価される指標となるのが、今回紹介する単位時間当たりにどれだけのデータを転送速度できるのかを示す、「帯域」や「スループット」と表されるデータ転送速度の指標です。
ストレージシステムを選定するということは、可用性や運用性に関する性能や機能、読み書きの速度、容量、コスト、これらをどうバランスを取るか、ということだと言えるかと思います。
スループット、IOPS、レイテンシ、ブロックサイズ
まず前提として離散的なコンピュータの世界では、ある程度のタイミングにおいて、ある程度の塊で、ストレージデバイスへの読み込み書き込みが実行されます。
その上でストレージの速度を計測するうえでは4つのファクターがよく登場します。
| 単語 | 意味 | よく使用される単位 |
|---|---|---|
| スループット | 単位時間あたりのデータ(読み込み・書き込み)量 | B/s (Bytes Per Second・MB/sが多い) |
| IOPS1 | 単位時間あたりのデータ読み込みまたは書き込み回数 Input/output Operation Per Second |
IOPS (M IOPS/K IOPS等で表現されることもある) |
| レイテンシ | 1回の読み込みまたは書き込み操作にかかる時間 | msec(ミリ秒) |
| ブロックサイズ | 1回の読み込みまたは書き込み操作を行うデータ量 | B(Byte/キロバイト、メガバイト単位が多い) |

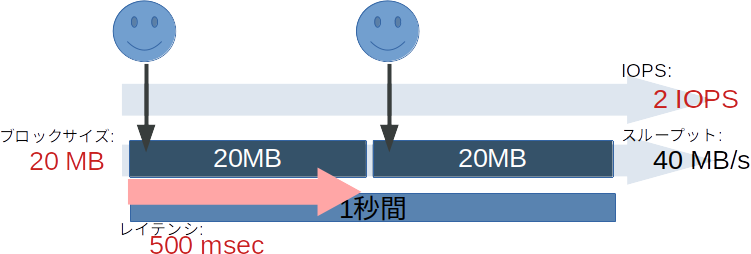
すでにお気づきだと思われますが、同じストレージシステム内においおてこれらの間にはある程度の相関があり、ある単位時間の平均値を見たときに、大雑把に見て次のような関係にあります。
平均スループット = 平均IOPS \times 平均ブロックサイズ
平均レイテンシ = \frac{単位時間}{平均IOPS}
また、これは直感的にも解ると思いますが、平均ブロックサイズが大きくなると転送するデータ量が増えるためレイテンシは長くなり、IOPSも必然的に低下します。逆に平均ブロックサイズが小さい場合、転送するデータ量は減るため、レイテンシは小さくなり、IOPSは増加します。
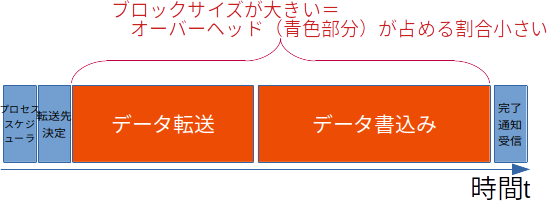
上記の図では10MBの転送に250msかかり、20MBの転送にはは単純に2倍の500msかかるという例をでした。このようにデータ量とレイテンシが比例する場合はスループットに変化はありません。しかしながら一般的に、このレイテンシにはデータ読み書きにかかる純粋な時間だけではなく、OSにプロセスをスケジュールされるまでの実行待ち時間や、データの格納先を決定する処理といった、データ量によって変化しない時間と、データをデバイスまで転送したり、実際にハードウェアに記録、読出す時間など、データ量によって変化する時間の2つがあります。前者のデータ量によって変化しない時間はいわゆるオーバーヘッドと捉えることができます。
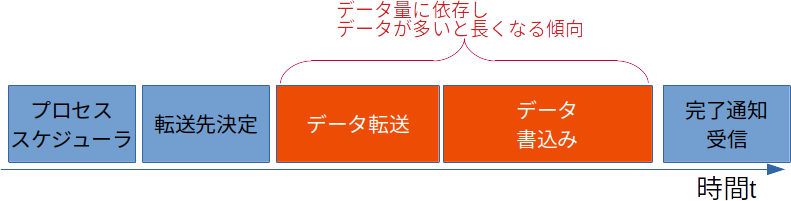
ブロックサイズと「ストレージシステム」の効率と「データ転送」の効率
上記のレイテンシの関係から、ストレージのベンチマーク結果はブロックサイズを変化させ、ブロックサイズごとに IOPS やスループットを評価されるケースが多く見受けられます。
IOPS
ブロックサイズを小さくすることにより、レイテンシの中でストレージシステム全体でのオーバーヘッドが占める割合が増加するため、「ストレージシステム」としての効率・性能の限界を現すようになります。そのため、「ストレージシステム」の効率を表す単位としてはIOPSが用いられることが多くなります。
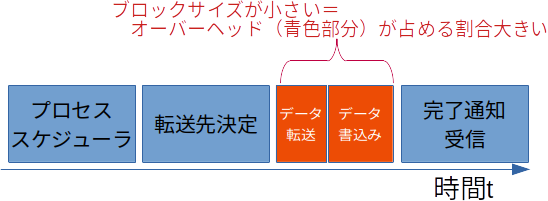
スループット
対してブロックサイズを大きくした場合はストレージハードウェアによるの「データ転送」の効率・性能の限界値に近づきます。そのためブロックサイズを大きくした場合にはスループット(MB/s)が評価に用いられます。
IOPSとスループットの関係まとめ
以上から一般的にはブロックサイズとIOPS,スループットの関係を図示すると以下のようなグラフを描きます。
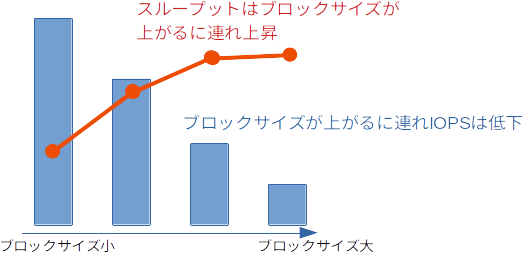
この点は今後Cephの性能を語る上でも重要となります。
Rook/Cephのアーキテクチャについて留意しておく
キャッシュの存在
Rook/Cephを利用する上では複数のキャッシュ層にぶち当たります。
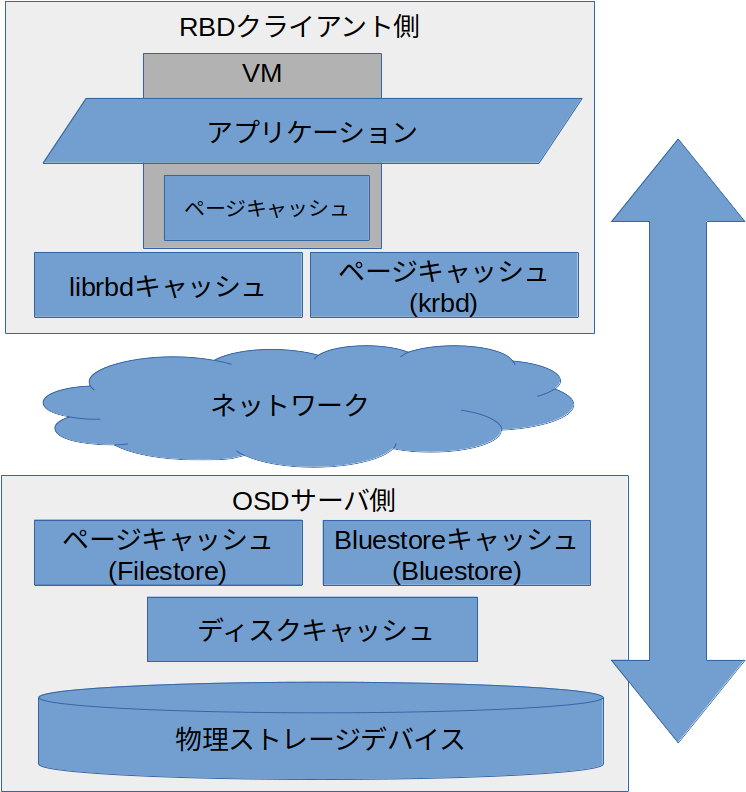
- (VMを用いる場合)Guest OSのページキャッシュ
-
librbdのキャッシュやホストOSのページキャッシュ - OSDサーバ上のキャッシュ
- (もしあれば)ストレージディスクのハードウェアキャッシュ
これらのキャッシュが存在することを理解しておくことが、パフォーマンスを計り、さらにチューニングする上でも重要となります。
そもそもなぜキャッシュするのか、についてはLinux OS上のページキャッシュの働きや、動きについては5日目をご担当されており、Rookメンテナでもある@satoru_takeuchiさんが書かれている本が初心者にもわかりやすく詳しいです。わたしもこちらの本で勉強させてもらいましたので軽く紹介させていただきます。
[試して理解]Linuxのしくみ~実験と図解で学ぶOSとハードウェアの基礎知識
プレースメントグループによる分散読み書き
Cephの細かなアーキテクチャには触れませんが、Cephがたくさんある、OSDの中からどのようにストレージを選択し、読み出したり書き込んだりするのかを理解しておくことは今後紹介するCephの性能特性を理解を助けます。
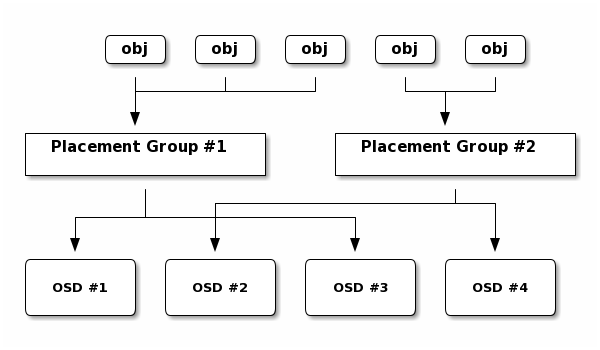
引用元:Ceph Documentation » Architecture
Cephが分散ストレージとして優れているのは、集権的なコントローラを持たないことと聞いたことがある人も多いと思います。
- Cephではデータをデフォルト4MB2のオブジェクトとして扱います
- 事前にOSDの組み合わせであるプレースメントグループを定義しておきます(自動で計算されます)
- データ(オブジェクト)を読み書きする際にはクライアントでオブジェクトのプレースメントグループを計算の上プレースメントグループの所属するOSDに対してオブジェクト単位で読み書きを行います。
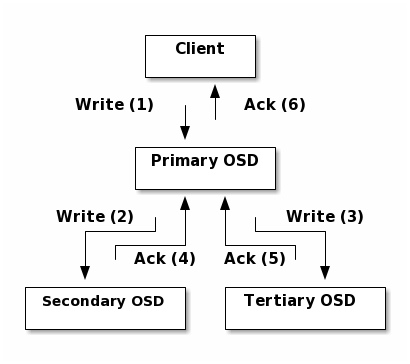
引用元:Ceph Documentation » Architecture
さらに、書き込みの際にはプレースメントグループで選ばれたプライマリのOSDに書き込みを実施し、決められたレプリカ数(3つか、2つが一般的)になるようにのコピーが行われて初めてACKが返されます(上記図では3つのレプリカを作るためにプライマリOSDで2つコピーを生成)。読み込みの際はわざわざレプリカを参照する必要がないためプライマリのOSDから直接読み込みます。
このCephのアーキテクチャを理解することは上記に書いたとおり、Cephのパフォーマンスを理解する上では大きく役立ちます。
第一回(アドベントカレンダー6日目)まとめ
さて、意外と書き出すと説明しておく必要がありそうな事が多岐にわたるな。。。というのが書き始めての印象でした。
「Cephは遅い」ということを聞いたことがある人もいるかもしれませんが、私見にはなりますが、これはYesでもあり、Noでもあります。
次回は今回記述した前提条件をもとに、どういった点でCephが遅いのか、どういった点でCephは速いのかを測定ツールの結果を見て紹介したいと思います。
また、Rookのアドベントカレンダーに興味のある皆さんには知ってるよ、という内容となったかもしれません。その点はご容赦いただければと思います。
ネットワーク屋さんな私からすれば中々ストレージは複雑で難しい(技術の奥行きが大変深い!)と感じてまして、同じような初学者の方の参考になればと思い記載させていただきました。