概要
この記事の内容は以下のとおりです。
- KubernetesのコンテナのStateとLast Stateの違い
- Datadogで
kubernetes.containers.state.terminatedを使う際の注意事項 -
kubernetes.containers.last_state.terminatedを用いたOOMKilledの監視方法
やりたいこと
この記事では以下のことを実現します。
- KubernetesのコンテナでOOMKilledが起きたときに、Datadog Monitorでアラートを飛ばしたい
- そのためにOOMKilledだけをメトリクスとして取得したい(他のエラーとは混ぜたくない)
準備: Datadog AgentをKubernetesクラスタに入れる
この章は本題ではなく、公式ドキュメント通りの内容です。適宜読み飛ばしてください。
DatadogでKubernetesのメトリクスを収集するには、Datadog Agentをクラスタに入れます。入れ方は3つあります(Helm, DeamonSet, Operator)
Datadog Agentの仕組みについては、以下の日本語記事をお読みください。この記事はDatadog Cluster Agentの解説ですが、「Datadog Cluster Agentを利用できなかった時代のクラスターの監視」という章でDatadog Agentのアーキテクチャが紹介されており、分かりやすいです。
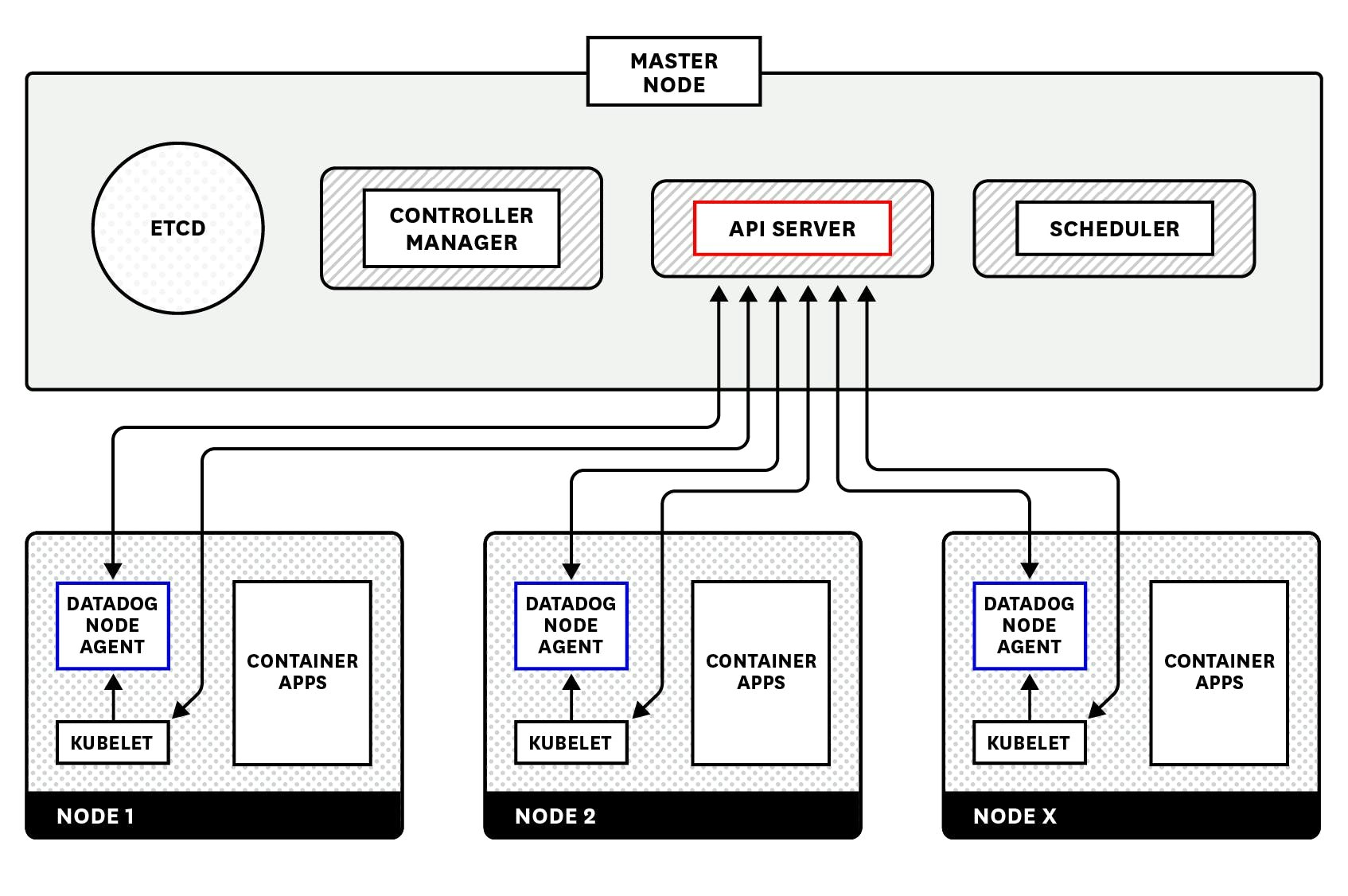
※図は上記記事より引用
また、必須ではありませんが、クラスタにkube-state-metricsを入れておくと、**公式ドキュメント: Kubernetes Data Collected**のKubernetes stateの表にあるメトリクスを使えるようになって便利です。(今回のアラートには不要です)
そもそもKubernetesの監視って何やるの? という方は、以下の記事で全4パートで学べます。オススメです。
OOMKilledの監視に使えそうなメトリクス
本題に入ります。
**公式ドキュメント: Kubernetes Data Collected**には、なんだか使えそうなメトリクスが4つ書かれています。いったんそのまま引用します↓
| メトリクス | 説明 |
|---|---|
| kubernetes.containers.state.terminated | The number of currently terminated containers |
| kubernetes.containers.last_state.terminated | The number of containers that were previously terminated |
| kubernetes_state.container.terminated | Whether the container is currently in terminated state |
| kubernetes_state.container.status_report.count.terminated | Count of the containers currently reporting a in terminated state with the reason as a tag |
説明が少ないですね... 私のような素人には厳しいです。
そこで実際にDatadogのMetrics ExplorerやMonitorをゴチャゴチャしながら、OOMKilledの監視に使えるのはどれかを調べてみました。
表の下の2つ(kubernetes_stateからはじまるメトリクス)は前述の通りkube-state-metricsが必要なので、本記事では上の2つ(kubernetes.containersからはじまるメトリクス)を対象にします。
kubernetes.containers.state.terminated
kubernetes.containers.state.terminatedは「現在進行系でstateがterminatedになっているコンテナの数」です(sumの場合)。runnning→terminatedになった回数ではなく、コンテナの数である点に注意してください。同じコンテナがrunnning→terminatedを繰り返していても、このメトリクスは1のままです。
なお、ここでいうStateとは.status.containerStatuses[].stateのことです。コンテナはWaiting, Running, Terminatedの3つのStateを持ちます(公式ドキュメント)。Waiting, Terminatedの場合はReasonも持ち、以下のような値を取ります(stack overflow)。
- WaitingのReason
- ContainerCreating
- CrashLoopBackOff
- ErrImagePull
- ImagePullBackOff
- CreateContainerConfigError
- InvalidImageName
- CreateContainerError
- TerminatedのReason
- OOMKilled
- Error
- Completed
- ContainerCannotRun
- DeadlineExceeded
なので、Datadogのメトリクスにもkubernetes.containers.state.terminated以外に(略).state.waitingと(略).state.runningがあります。
また、これが最重要なのですが、waitingとterminatedについてはreasonも取得することができます。
例えばMonitorのクエリをsum:kubernetes.containers.state.terminated{reason:oomkilled}とすれば、「現在進行系でstateがterminatedになっていて、かつreasonがOOMKilledであるコンテナの数」という意味になります。
やった! やりたいことにマッチしていますね。さっそくMonitorを作ってみました。
↓
(((( ;゚д゚))) なんかアラートが飛ばないときがある......
そう、なんとうまくいかなかったのです。OOMKilledに限らず、sum:kubernetes.containers.state.terminatedが正しく増えないことがありました(増えることもありました)。なぜでしょうか?
あくまで推測ですが、おそらくDatadog Agentがデータを取得したタイミングでコンテナのstateがterminatedになっていなかったのだと思います。
PodのrestartPolicyをNeverにしていない限り、コンテナが死んだ場合はすぐに再起動されます。そのためstateがterminatedになるのは一瞬です。そのタイミングがDatadog Agentのデータ取得タイミングと被ったらメトリクスに反映され、そうでない場合は反映されないのだと思います(素人の推測です。訂正・補足等お待ちしております)
そのため、このメトリクスはアラートに使いづらいことが分かりました。なのでもう片方を使おうと思います。
kubernetes.containers.last_state.terminated
kubernetes.containers.last_state.terminatedは、「Last Stateがterminatedになっているコンテナの数」です(sumの場合)。
StateとLast Stateは別物です。Stateがterminatedになったコンテナが再起動するとき、Last Stateに終了時刻や理由が入ります。kubectl get podの結果からStateとLast Stateを比較してみましょう。コンテナ「xxx」がOOMKilledがあったコンテナで、コンテナ「yyy」は一度も再起動していないコンテナです↓
※関係のない行は省略しています
"status": {
"containerStatuses": [
{
"containerID": "xxx",
"image": "xxx",
"imageID": "xxx",
"lastState": {
"terminated": {
"containerID": "xxx",
"exitCode": 0,
"finishedAt": "2021-12-02T18:09:45Z",
"reason": "OOMKilled",
"startedAt": "2021-11-29T08:47:55Z"
}
},
"name": "xxx",
"ready": true,
"restartCount": 10,
"started": true,
"state": {
"running": {
"startedAt": "2021-12-02T18:09:48Z"
}
}
},
{
"containerID": "yyy",
"image": "yyy",
"imageID": "yyy",
"lastState": {},
"name": "yyy",
"ready": true,
"restartCount": 0,
"started": true,
"state": {
"running": {
"startedAt": "2021-09-14T05:31:22Z"
}
}
}
]
}
一度も再起動していないコンテナ「yyy」はLast Stateが空です。
よって、例えばMonitorのクエリをsum:kubernetes.containers.last_state.terminated{reason:oomkilled}とすれば、「Last Stateがterminatedになっていて、かつreasonがOOMKilledであるコンテナの数」という意味になり、OOMKilledの発生を検知できます。
ただし、下記の点は注意が必要です。
- **OOMKilledが起きた回数ではない。**同じコンテナがOOMKilledを繰り返していても、この値は1のまま
- 一度1になったら、Podが生まれ変わらない限り0に戻らない。なぜならLast Stateが空に戻ることはないから(※reasonが別の理由になることはあり得る)
- よって、OOMKilledが発生しなくなったタイミングは検知できない。また、同じPodでOOMKilledが再発しても検知できない
つまりなかなか不便です。
弊チームの場合、OOMKilledが発生したら必ず調査・対応をしています。多くのケースではコンテナのメモリのlimitを増やすためにマニフェストを書き換えてkubectl applyします。つまりPodが生まれ変わるので、このとき0に戻ります。なので困ってはいませんが...「運用でカバー」は避けるべきですよね...
まだやっていませんが、Datadog Monitorの機能で色々頑張ることは可能かもしれません。
2つのメトリクスの比較
Dashboardで2つのメトリクスを並べてみましょう。
【上】sum:kubernetes.containers.state.terminated{reason:oomkilled}
【下】sum:kubernetes.containers.last_state.terminated{reason:oomkilled}
※いずれもdefalut_zeroにしています
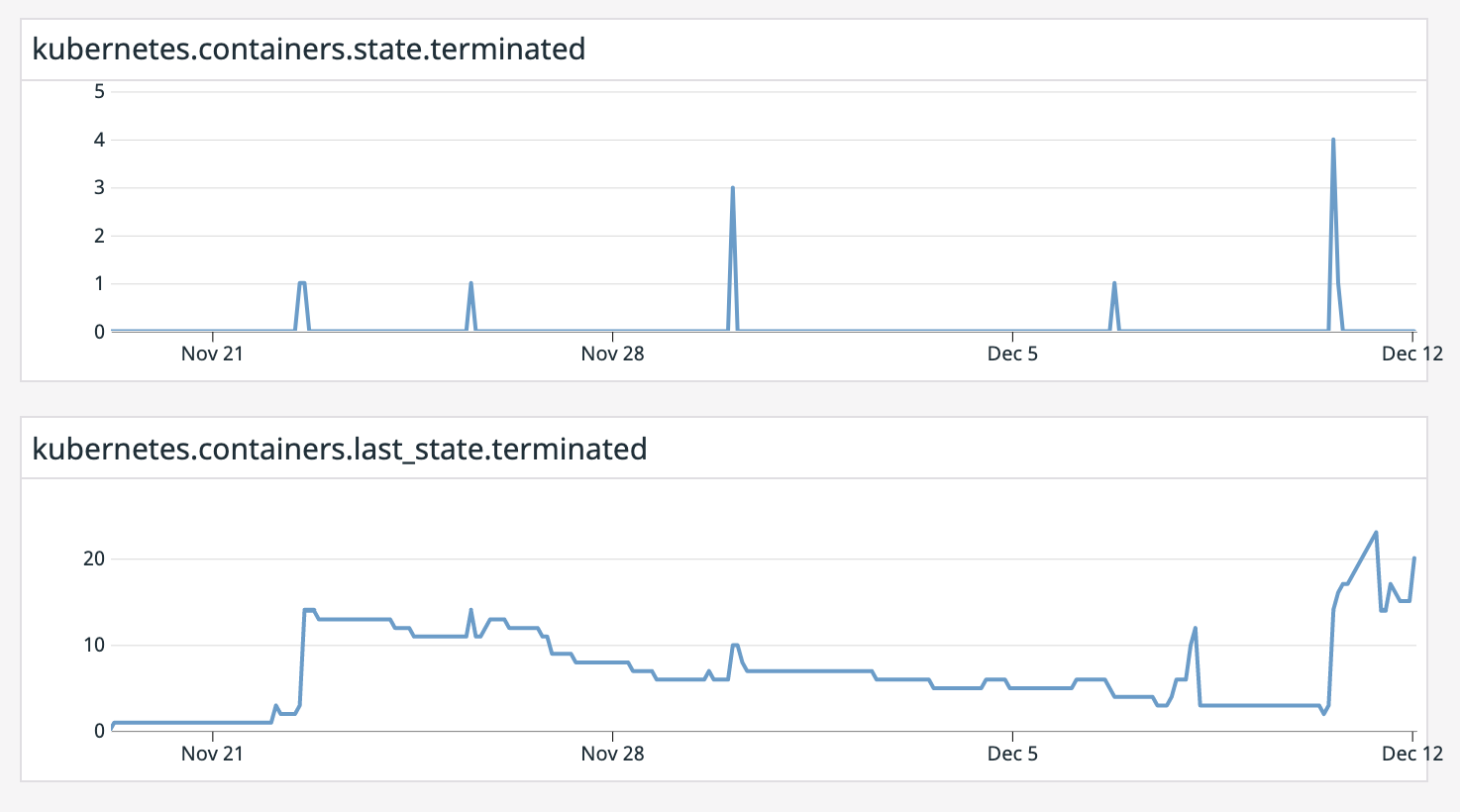
前述した通り、上のkubernetes.containers.state.terminatedはほとんど検知できていません(下のグラフが上がっているのに上のグラフが0のままのタイミングは検知できていません)。
また、下のkubernetes.containers.last_state.terminatedはPodが生まれ変わらない限り値が減らない様子もよく分かりますね。
まとめ
KubernetesのOOMKilledを監視するのに使うDatadogメトリクスはkubernetes.containers.last_state.terminated{reason:oomkilled}が良さそうですが、アラートに使うには不便な点が多いです。