お詫び(2020年6月9日追記・再修正)
はじめに公開した本記事の内容には、検証時のコードミスによって、間違った情報が含まれておりました。
深くお詫びして、訂正致します。
具体的には、モデル作成と特徴空間へのプロットに使用した画像のサイズが512x512で、GradCamに使用した画像のサイズが500x500でした。(もともとは、どちらも500x500にするつもりでした。)
追加作業の簡素化のために、GradCamに使用する画像のサイズを512x512にしたところ、最初の記事公開時とは、少しだけ傾向が異なる結果となりました。(github上のコードも修正しました。)
また、GradCamの実施のたびに、大きく結果が異なる場合があることが分かりました。
また、GradCamの実施のために、学習済みのモデルのパラメーターを読み込む際に、全結合(metric_fc)のパラメーターを読み込んでいなかったために、GradCamの実施のたびに結果が違うという事態を招いていましたが、その部分も修正しました。(ちなみに、これは私の検証用のコードだけの問題で、github上のコードの修正はありません。)
ちなみに、特徴空間へのプロットの部分については、修正はありません。
はじめに
業務で、画像の異常検知をやる必要が生じたために、下記の素晴らしい記事を参考にして、Metric Learningによる MVTEc AD の画像異常検知と、GradCam による可視化を行いました。
https://qiita.com/shinmura0/items/5c728da8a74208c1308f
https://qiita.com/daisukelab/items/e0ff429bd58b2befbb1b
基本的には、上記の記事と比較して、目新しいことは、ほとんどありません。
強いて言うなら、PyTorch の実装であることぐらいです。。。
※全体のコードはこちらに置いています。(2020年6月9日コードを修正)
(Google colab 上で実行するためのコードを含んでいます。)
https://github.com/nshikimi/MVTecAD/tree/master/Leather
※AdaCosの実装は、下記を参考にしています。(作者様有り難うございます。)
https://github.com/4uiiurz1/pytorch-adacos
※GradCamの実装は、下記を参考にしています。(作者様有り難うございます。)
https://qiita.com/llight/items/d50fe321a3686653aebf
データセット(MVTec AD)について
様々な製品(物体)について、正常な個体の画像と異常な個体の画像が含まれています。
また、異常な個体の画像には、多様な異常の種類が、きちんと分類されて含まれています。
さらに、素晴らしいのは、異常な部分を特定できるようなマスクがはじめから含まれていることです。(これは、本当に有り難いです。)
ただ、実際の現場で、このようなマスクを作るのは極めて手間がかかると思われるので、これに頼ると、その手法が実際の現場で使えない、ということが発生するかも知れません。
製品(物体)の種類は、bottle、cable、capsule、carpet、grid、hazelnut、leather、metal_nut、pill、screw、tile、toothbrush、transistor、wood、zipper の15種類です。
下記にて、入手できます。
https://www.mvtec.com/company/research/datasets/mvtec-ad/
データのサンプル
正常データ
 |
 |
 |
 |
 |
|---|
異常(cut)
 |
 |
 |
 |
 |
|---|
異常(color)
 |
 |
 |
 |
 |
|---|
異常(fold)
 |
 |
 |
 |
 |
|---|
異常(glue)
 |
 |
 |
 |
 |
|---|
異常(poke)
 |
 |
 |
 |
 |
|---|
検証概要
今回の検証の概要は下記の通りです。
- 今回は、MVTecADのなかでも、もっとも簡単なleatherを使用
- leather のみを使い、正常と異常の二値分類問題として実施
- 1000x1000の元画像を、
500x500512x512 に resize して実施 - 学習には、正常だけで構成される train データだけでなく、異常データも使用
(はい、ある意味チートです。すいません。trainデータだけでは、精度が出ませんでした。。。) - NNには、ResNet18を使用
- 学習には、Metric Learning/AdaCos を使用
- Epoch数は300/500/1000
検証結果
モデルの学習と特徴空間へのプロット
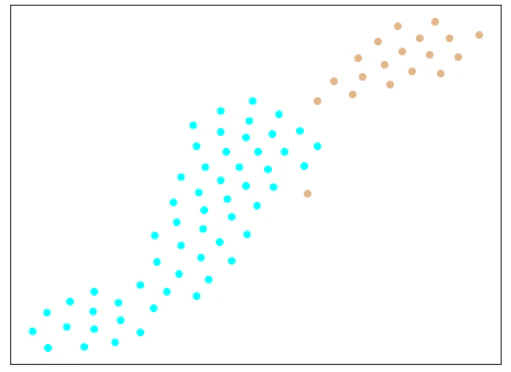
エポック数300/500/1000で学習したモデルから、Metric Learningの特徴(512次元)を抽出し、tSNEで2次元に可視化したものが下記のとおり。
エポック数:300
結果
| 1回目 | 2回目 | |
|---|---|---|
| trainデータ | 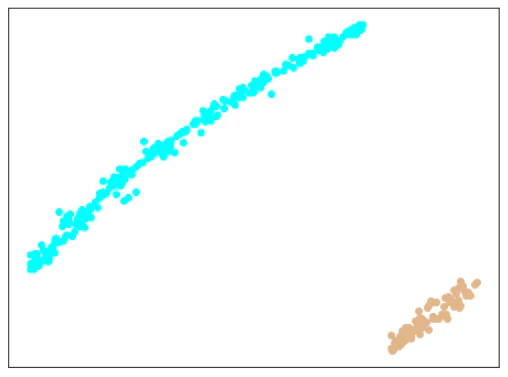 |
 |
| testデータ | 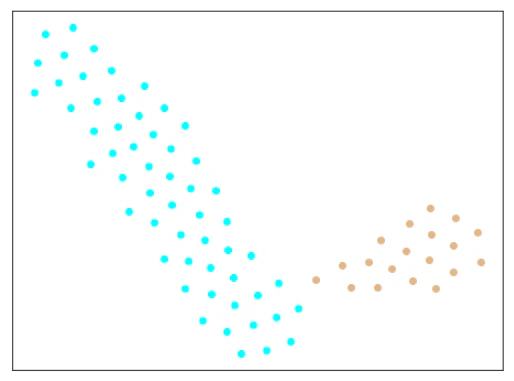 |
 |
| Train+testデータ | 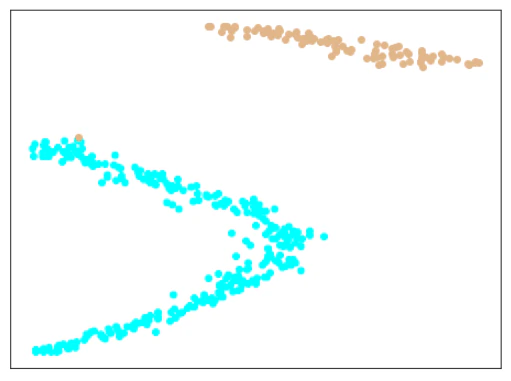 |
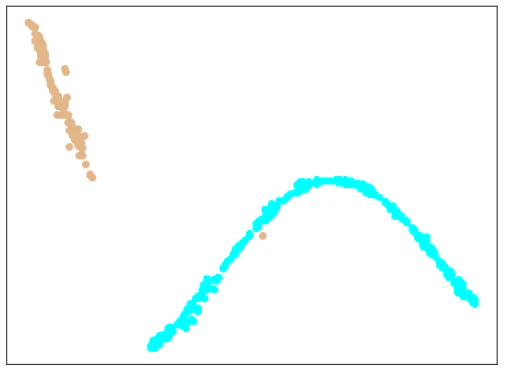 |
考察
ほとんどは、きれいに分離できていますが、Train+testデータで1個だけ、testデータに含まれる異常データが、正常データのエリアにプロットされています。
(何度もやっていると、きれいに分離されることもあります。)
Softmaxの分類問題としての結果も、1点だけ間違っています。
エポック数:500
結果
| 1回目 | 2回目 | |
|---|---|---|
| Trainデータ |  |
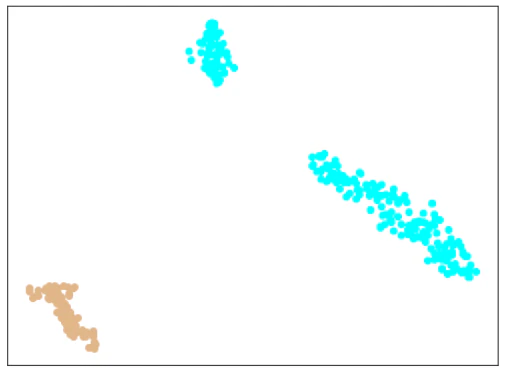 |
| testデータ | 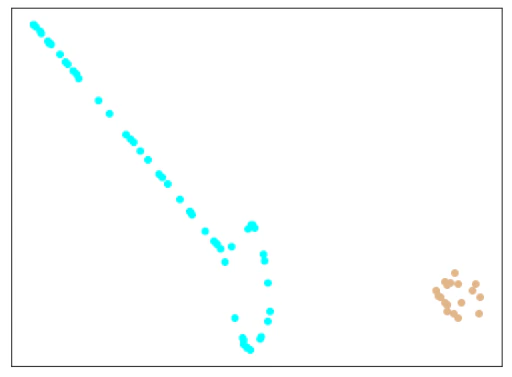 |
 |
| Train+testデータ |  |
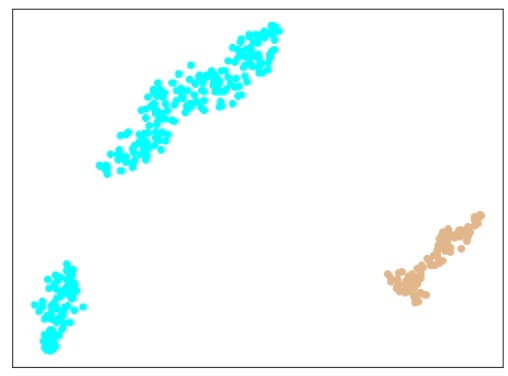 |
考察
きれいに分離できています。
Softmaxの分類問題としての結果も、間違えているものはありませんでした。
エポック数:1000
結果
| 1回目 | |
|---|---|
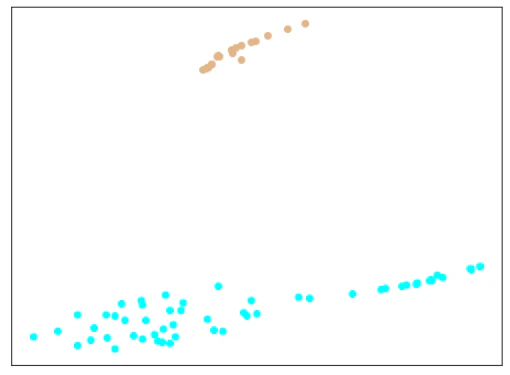
| Trainデータ |  |
| testデータ | 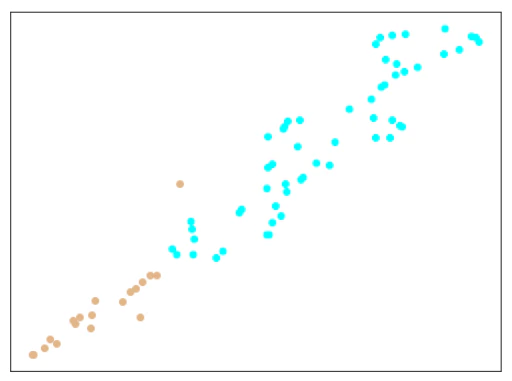 |
| Train+testデータ | 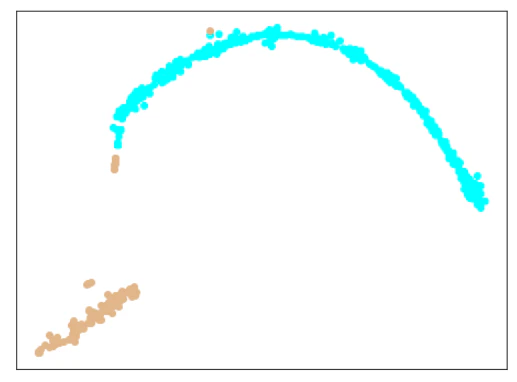 |
考察
やり過ぎてしまったのか、崩れてしまったようです。
Softmaxの分類問題としての結果は、4個のデータで間違っていました。
GradCamによる可視化
結果
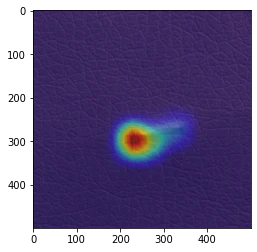
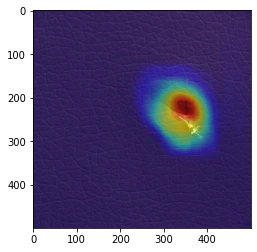
きちんと異常箇所を認識している画像(2020年6月9日修正)
(私の実装している)GradCamは実施するたびに、結果が変わってしまうのですが(なぜなのかが分かっていないので、今後の大きな課題です。)、 きちんと学習できているモデルで、GradCamの可視化がうまくいけばこれになります。
また、全結合層(metric_fc)は、GradCamの結果に大きな影響を及ぼしますが、畳み込み層(model)とは異なるモデルの全結合層(metric_fc)のパラメーターを読み込むことで、GradCamの可視化が非常にうまくいくケースがあることが分かりました。(なぜなのかの理解は、今後の課題です。)
今回の検証では、何らかの方法でGradCamの可視化を調整すれば、エポック数:300、500、1000のほとんどのモデルにおいて、すべての異常データに対するGradCam可視化画像において、このタイプの結果を得ることができました。
| 元の画像 | GradCamで可視化した画像 |
|---|---|
 |
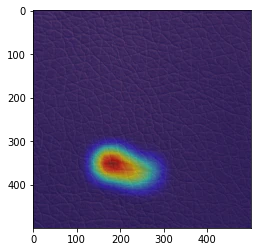 |
 |
 |
 |
 |
 |
 |
 |
 |
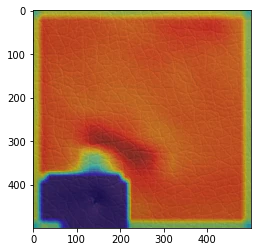
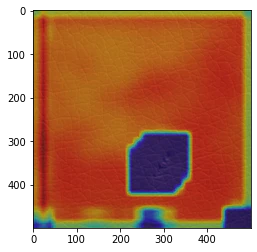
正常箇所と異常箇所の認識が逆転している画像(2020年6月9日修正)
エポック数にかかわらず、それなりの割合でこのパターンが出てきます。
(GradCamを実施するたびに、結果が変わってしまうのですが) 少数の割合でこのタイプが出てくる場合と、ほとんどがこのタイプになる場合と、まったくこのタイプが出てこない場合があります。
着目するべきポイントや正常なものと異なるという認識はできているようですが、なぜなのかが明確に分かりません。。。
| 元の画像 | GradCamで可視化した画像 |
|---|---|
 |
 |
 |
 |
 |
 |
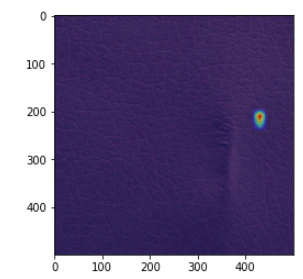
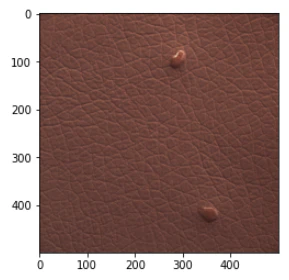
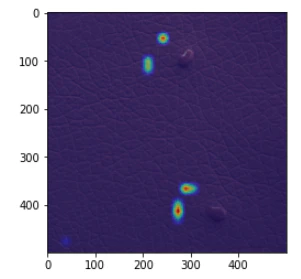
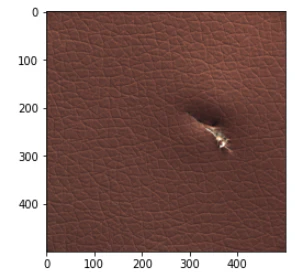
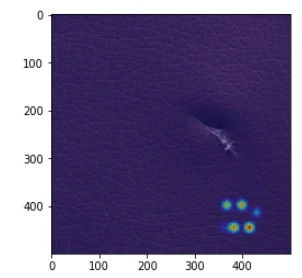
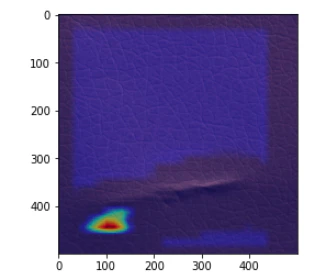
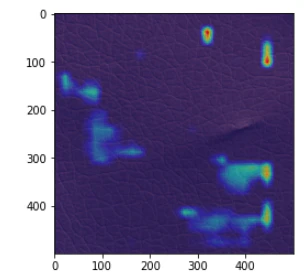
異常箇所の付近で何かを認識しているが、正確ではない画像(2020年6月9日修正)
エポック数:300ではある程度の割合で、エポック数:500と1000ではごく少数の割合でこのタイプの画像が出てきます。
何かに反応はしているし、反応箇所が異常箇所の付近のものもあるので、それらの場合は、それなりの認識はできていると思えますが、位置が正確ではありません。
ただし、最後の画像のように、異常箇所と無関係と思える場所に反応しているものもあり、それらの場合は、ほとんど異常箇所が認識できてないように見えるものもあります。
(2020年6月9日追記)エポック数やモデルの良し悪しというより、GradCamの状態によるように思えます。
| 元の画像 | GradCamで可視化した画像 |
|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
まったく反応していない画像
まったく何にも反応していません。
エポック数:300では少数の程度の割合で、エポック数:500と1000ではごくごくまれにこのタイプの画像が出てきます。
(2020年6月9日追記)エポック数やモデルの良し悪しというより、GradCamの状態によるように思えます。
| 元の画像 | GradCamで可視化した画像 |
|---|---|
 |
 |
 |
 |
 |
 |
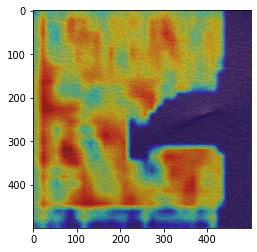
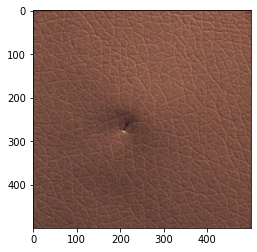
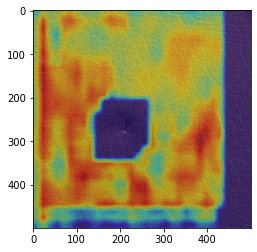
(補足)エポック数:1000の画像
((2020年6月9日追記)全結合(metric_fc)のパラメーター読み込みを追加した後では、全結合(metric_fc)のパラメーターを調整した場合のみに出てくるようになりました。)
異常箇所と反応箇所が逆転していますが、それ以上に正常箇所が(エポック数:300や500のように)均一ではなく、強く反応している場所とそうでない場所があるのが気になります。
過学習して、レザーの細かい模様に反応しているのかも知れません。
ただし、GradCamの実施のたびに結果が変わるので、エポック数:1000でも、正しく異常個所に反応している場合もあります。
| 元の画像 | GradCamで可視化した画像 |
|---|---|
 |
 |
 |
 |
 |
 |
考察
上記画像は、学習データのGradCam可視化ですが、学習に使用していないデータでも、同じような結果が得られました。
ただし、理解できていない大きな問題として、GradCamの実施のたびに結果が変わると言うものがあります。
エポック数:300、500、1000のいずれにおいても、何らかの方法でGradCamの可視化を調整すれば、すべてのGradCam可視化画像で、正確に異常個所を認識している画像を得ることができました。
ただし、特徴空間へのプロットとSoftmaxでの予測も加味すると、すべて期待通りの結果が出たのは、エポック数:500のよくできたモデルだけでした。
GradCam可視化画像で、なぜ、異常個所と反応個所が逆転しているものがあるのか等は、今後の大きな課題となります。
また、GradCam可視化の結果の良し悪しは、モデルの良し悪しとは別の問題のようです。
さいごに
Leatherは、もっとも簡単なデータセットだったので、うまくいきました。
次回は、Capsule編をやります。