大人気シリーズ(嘘)の2回目
シリーズ目次
- MeCab で形態素解析
- fastText で単語分散表現 ← イマココ
- Shallow Learningで文書分類
スゴいよ単語分散表現
NLP で最も有名なものは、下のような図じゃないだろうか。
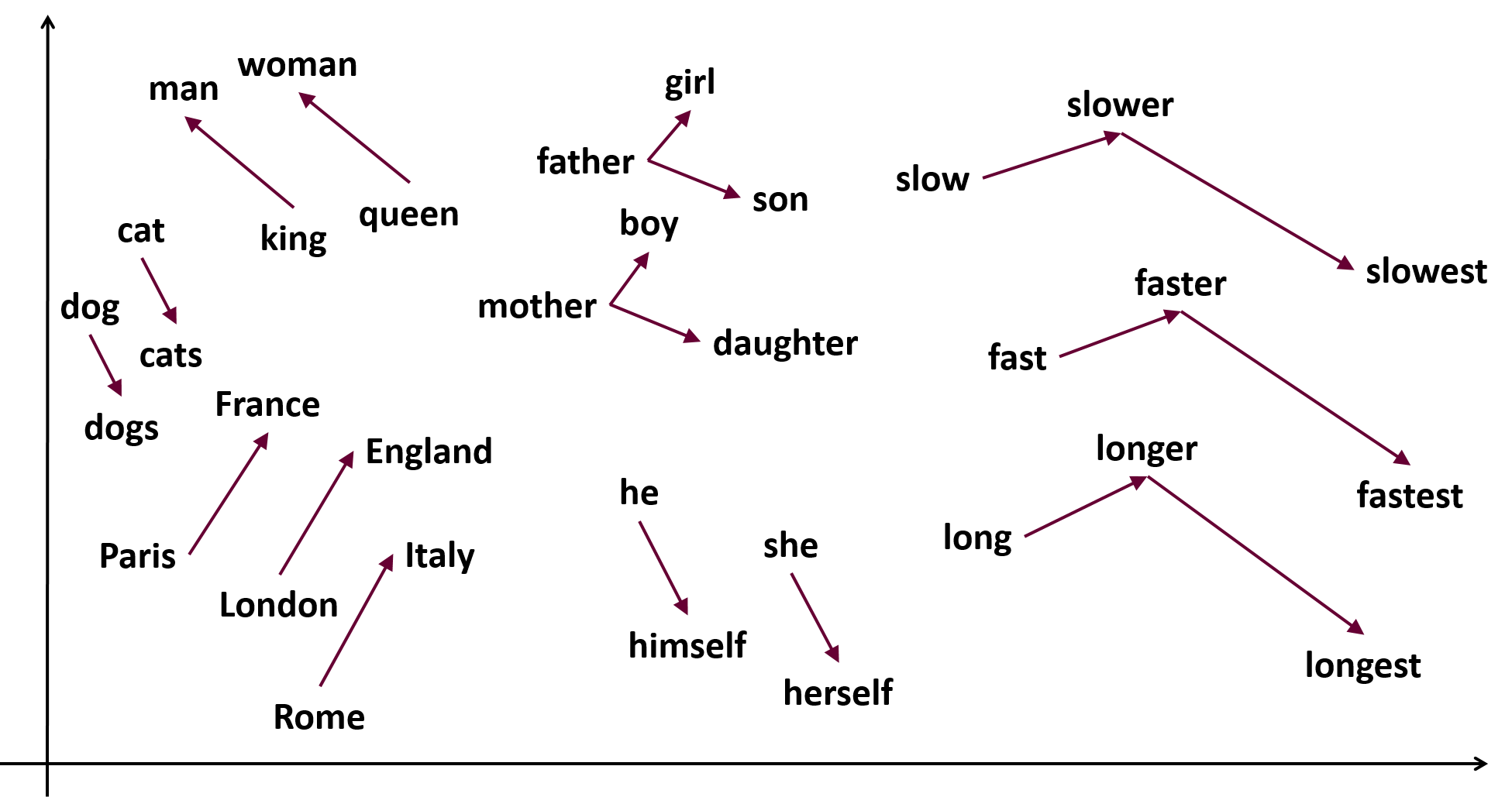
私達が存在するこの空間は3次元だが、100次元や300次元といった高次元空間を考え、各単語をその空間上に「意味が似ているものが『近く』なるように」置く、すなわち単語の意味をベクトル(向きと長さをもつ値)で表すことにする。
すると、ふたつの単語の意味の違いも、ベクトルの引き算をすれば良いので、またベクトルで表すことが出来る。
- "dogs" − "dog" をすると、「複数」という意味を持つベクトルになるはず
- "cats" − "cat" だって、「複数」という意味になるはず
- だから上記2つのベクトル引き算の結果のベクトルは、同じ向き、同じ長さになる
もっと言うと
- "king" − "man" は、"royal" 的な意味になるはず
- "queen" − "woman" だって同じ
- だったら、 "king" − "man" + "woman" = "queen" になる!
という、「単語の意味の計算」が出来てしまう。
これは正直、面白い。そして凄い。
何が凄いのかというと、「言語(単語)を数字(ベクトル)に置き換えてしまった」という点である。言語を数字に置き換えると、普通の機械学習ができる。すなわちコンピューターが言葉を理解できる!(もちろん比喩的な表現だよ!)
単語分散表現とは
この「単語をベクトルに置き換える」やり方を「単語分散表現」というのだが、果たして単語分散表現とは何か、何故重要なのかは Hironsanの記事に書かれているので私が書くことは何も残っていない(笑)
余談だが、Hironsan は私の中で工藤さんと並ぶほどお世話になっており(実際にお会いしたことは無いけど)、「五体投地して感謝を伝えたい人 Top 5」のひとりであるので、こんな文章を読んでないで Hironsan の本を買って読めば良いんじゃないかな、って思う。
なのでここでは用語のまとめをする。
- 単語分散表現(Distributed Representation of Words)
- one-hot 表現だと単語の数の次元数(数十万次元!)が必要なのに対し、各次元を 0/1 の値ではなく実数値で表現することによって高々100次元程度で済ます、要するに各次元の値に意味(の一部)を分散させることによって表現するので、「分散表現」
- 単語埋め込み(Word Embedding)
- 単語を100次元程度の空間に「埋め込む」方法
- 要するに、上記2つは同じ意味(ゆるふわ)
- 私は、日本語だと「単語分散表現」、英語だと "Word Embedding" を使いがち(あるある)
- WORD2VEC
- 単語分散表現と言えば WORD2VEC
- 他にもあるかもしれないけど、あったとしても無視して良いレベル
- 単語分散表現を行う実装の総称でもあるし、実際に word2vec という実装もある
- ここでは、「実装の総称」の場合には WORD2VEC、「word2vecという実装」の場合には word2vec と表すことにする
- 単語分散表現と言えば WORD2VEC
何故に単語分散表現
ここでふたつ疑問が出てくると思う。
- 何で単語分散表現は単語の意味を上手く表現できるのか
- 単語分散表現で果たして言葉の意味を分析することが出来るのか
- 高々100次元程度で大丈夫?言葉ってもっと複雑じゃない?
まずは最初の疑問。似たような意味の単語を近くに置くので「ここらへんの単語は『犬』に近い意味」というのは出来るかもしれないけど、それが何故足し算や引き算をしても人間が思う単語が出てくるのか。
分かってません。
でも、実際に使えるし、良い結果が出てるし、出来れば何でもいいんじゃい!(ゆるふわ)
(もしも最新の研究で何か明らかになっていたら、ごめんなさい!)
そして次の疑問。100次元程度で大丈夫か?そんな装備で(略)
機械学習で最初に学ぶことに「次元の呪い(The curse of dimensionality)」がある。
すべての辺(境界)の長さが1のN次元空間を考える。2次元なら、辺の長さが1の正方形。3次元なら、辺の長さが1の立方体。
そしてその中心から、中心から各辺までの距離(要するに 0.5)でグルっと囲む領域を考える。2次元なら、直径1の円。3次元なら直径1の球。
先程の空間の中に、満遍なく一様に点(データ)があった時に、果たしてどれぐらいが円もしくは球の中に存在するだろうか。
2次元の場合は、全体の面積に対して円以外の面積の割合がそれほど多くないので、ほとんどが円の中に入るだろう。
それに比べて3次元の場合は、全体の体積に対する球の体積の割合は2次元の場合と比べて多くなるので、球以外の所に比較的多くの点が存在することになる。
ではもっともっと次元数が増えた場合はどうなるのか。
2次元の場合、円から見て正方形は、自分の領域ではない、はみ出して尖っている所が4つ。
3次元の場合、球から見て立方体は、自分の領域ではない、はみ出して尖っている所が8こ。
これが8次元になると、尖っている所の数は 2^8 で 256 個になる。
要するに、中心から等距離の領域を、高次元においても無理やり3次元の球で考えると、空間はトゲトゲのウニみたいな形になるってことだ!
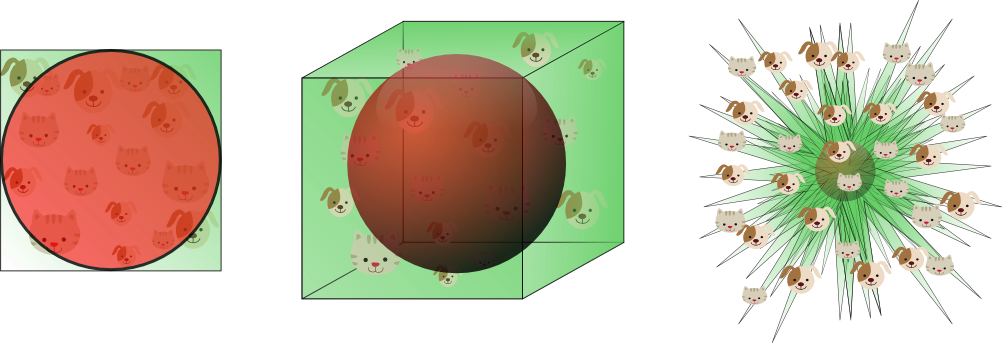
よって、データが高次元になると以下の問題が発生し、これらがいわゆる「次元の呪い」。一般的なデータ分析や機械学習では、これを回避するためにデータの工夫(次元削減や圧縮)をしなければならない。
- いくらデータを揃えても、そのデータはほとんど空間のすみっこに存在し、疎(sparse:スカスカ)な状態になる。これではまともな分析は出来ない
- 空間をスパっと2つに分けることを考えると、ちょっとでも切る位置や角度が違うだけで全然違う結果になってしまう。微妙な誤差が結果に深刻な影響を与えてしまうので、これではまともな分析は出来ない
人間が感覚的に理解できるのは、たかが3次元。宇宙の超ひも理論だって11次元。一般的なデータ分析は多くても数十次元に留めるべき。
ところが WORD2VEC では、これを逆手に取って、100次元程度の空間を利用することで、言語の様々な意味を機械で表現している、ということになる。100次元で十分。
そんな高次元のデータを扱っているので、ちょっとした誤差は気にしないでネ♡
要するに何が言いたいかというと、「WORD2VEC を信じろ!」である。
(これを言いたいがためだけに、長い文章を書いてしまった気がする)
近さと距離
ところで、今まで単語分散表現とは「似た意味の単語を『近くに』置く」と書いてきたが、『近い』とは何だろうか。
よく考えてみると、『近い』とは、距離が定義されて初めて意味がある概念であることが分かる。距離が短い時は『近い』、距離が長い時は『遠い』。
しかし、とあなたは思うだろう。『近い』には「意味が『近い』」という様にも使われると。この場合の『近い』は、まさしく『似ている』という意味である。この意味の『近い』は『類似度』と言うことも出来る。
この「位置的な『近い』」と「意味的な『近い』」は果たして同じなのだろうか。
結局の所、この両者を同じだとしたのが単語分散表現なのである。
位置的な距離とは一般的にはユークリッド距離のことを指す(数学的には L2 ノルムとも言う)。実際に WORD2VEC の各モデルはユークリッド的に学習する。
しかしこの距離をそのまま『類似度』の方に用いると、まずいことがある。
ユークリッド距離は、短い方に有限である。ぴったり一致する時、まったく同じ場所にいる時に、もちろん距離は0である。これ以上短くなることはない。しかし長い方には無限である。無限に離れていれば距離は無限。
しかしこれは『類似度』では都合が悪い。
「意味が同じ」の反対はあくまで「意味が反対」であり、「無限に意味が反対」などということはない。
また、WORD2VEC が通常利用する高次元空間でも都合が悪い。
ユークリッド距離は各次元の位置の違いがそのままダイレクトに距離に影響があるので、高次元空間だと少しの誤差がひどい距離の違いに繋がる。要するに、先程のウニのような形を思い浮かべた時、ちょっとだけ動いただけで、違うトゲの先端に移動してしまうのである。これは厳しい。
なので、WORD2VEC では2つの単語の意味の違いは、ユークリッド距離ではなくコサイン距離で測る。コサイン距離とは、要するに中心から見た2つの点のなす角度の大きさである。
すなわち、WORD2VEC では、中心の近くにある言葉でも、中心から遠くにある言葉でも、その角度が同じであれば同じ意味なのである。
不思議。でもこの不思議なことが出来てしまうのが WORD2VEC。
- 近い意味の単語をユークリッド距離的な意味で近くなるよう学習する
- すると、2点間のコサイン距離がそのふたつの言葉の意味の違いを表す
考えるな!感じろ!(考えて下さい)
蛇足だが、通常『類似度』は『距離』の逆数である。
- 距離が短い(距離の値が小さい)=類似度が高い(類似度の値が大きい)
- 距離が長い(距離の値が大きい)=類似度が低い(類似度の値が小さい)
また上で「ユークリッド距離」「コサイン距離」をロクに説明せずに使ったが、距離は機械学習においてとても重要な概念なので、分からない場合は自分で調べることをお薦めする。
WORD2VEC を使う
御託をたくさん並べてしまったが、そろそろ実際の使い方に入っていこう。
WORD2VECは2層のニューラルネットワーク、すなわち(そんな deep じゃない)deep learning の一種である。でも、deep learning じゃなくてもこれに近い実装をしているものは全部 WORD2VEC と言ってしまっている。
WORD2VEC の実装
有名な WORD2VEC の実装は以下。
-
オリジナルの word2vec
- もはや誰も使ってないと思うけど
-
Gensim の word2vec
- NLP やるなら Gensim
- と、はっきり言ってしまうと色んな所から斧が飛んでくる可能性があるので、こっそりと言ってみる
- この word2vec だって良いものだ
- NLP やるなら Gensim
-
fastText
- facebook 作の WORD2VEC
- 学習が早く性能が良いと専らの評判なので、これを使うことにする
-
SentencePiece
- google 作の WORD2VEC
- 上記の WORD2VEC とは違い、一文字毎に学習することで、内部で形態素解析までやってしまうもの
- なので形態素解析の辞書とかが必要ない
- ただし、日本語だと subword とかの概念が難しく、ちょっと使いづらい(個人的な感想です ← 逃げ)
WORD2VEC のアーキテクチャ
要するに(浅い)deep learning をして単語分散表現を作るのが WORD2VEC なのだが、そのモデルの種類には大きく分けて2種類ある。
- CBOW (Continuous Bag of Words)
- Skip-gram
で、この CBOW と Skip-gram がどういうものかは、実は実装によって違う。
一般的な CBOW と Skip-gram
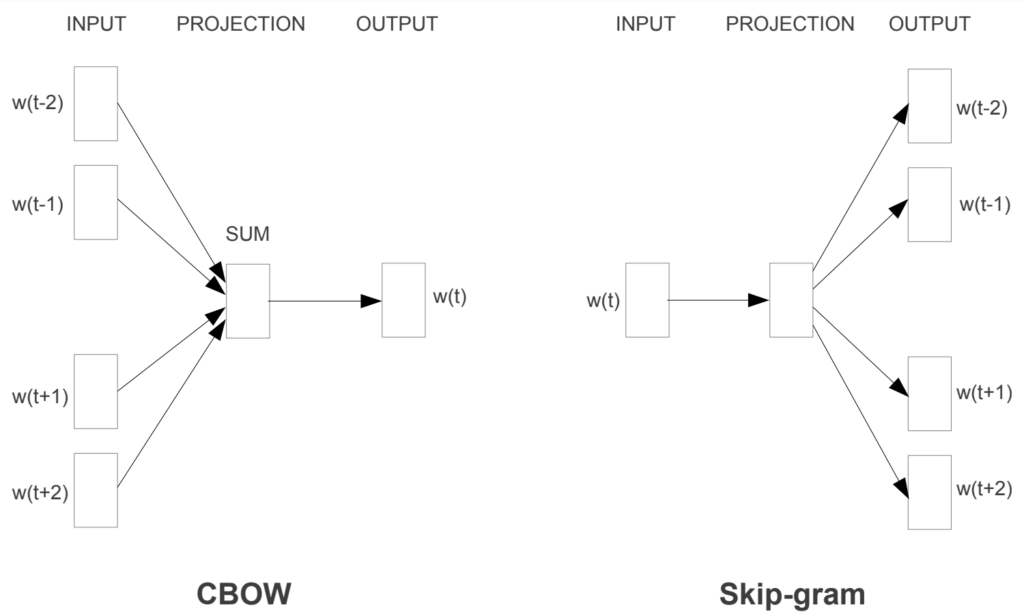
CBOW は、例えば連続する5個の単語の内、真ん中の1個を虫食いにして、周りの4つの単語から真ん中の単語を学習する。
これに対し Skip-gram は、あるひとつの単語から、その周辺に出てくる単語を学習する。
fastText の CBOW と Skip-gram
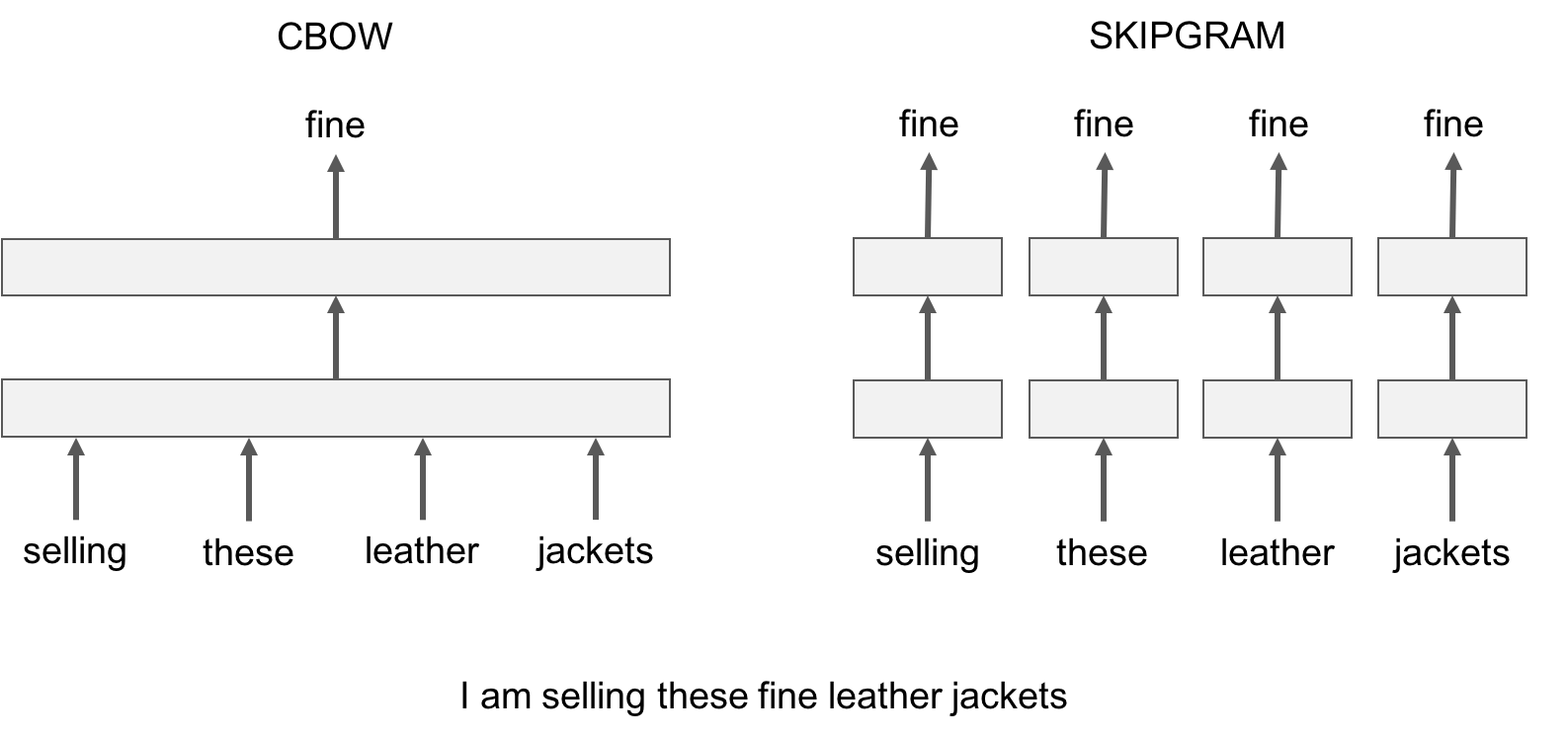
CBOW は、真ん中の単語を虫食いにした周り4つの単語を「ひとまとまり(Bag-of-words)にして、そこから真ん中の単語を学習する(文脈から学習する)。
これに対し Skip-gram は、ひとつひとつの単語を入力として(位置とかあまり気にせずに)虫食いにした単語を学習する(周辺単語の出現頻度から学習する)。
fastText の Skip-gram の利点としては、実際には出現しない単語でわざと学習し(Negative Sampling)、「この単語の時にはこれは出ない」という逆転の学習が出来ることである。
どちらが一概に良いとは言えないが、一般的には、単語数が少なく、単語あたりの出現頻度が多い言語は CBOW、逆に単語数が多く、単語あたりの出現頻度が少ない言語は Skip-gram が良いと言われている。なので、日本語には Skip-gram が向いているだろう。(個人的な感想です)
WORD2VEC のハイパーパラメータ
一般的に機械学習では、学習データをパラメータと呼ぶので、モデル自体のパラメータをハイパーパラメータと呼ぶ。
Gensim word2vec のハイパーパラメータまで解説すると切りが無いので、fastText で、しかも注意したいハイバーパラメータだけを挙げることにする。(全部のハイパーパラメータはここを参照)
-
-dim- 最も重要。単語から変換するベクトルの次元数
- 学習に使う文書の数から決めるのが良いと言われている
- データが少なければ、100。Wikipedia クラスだと 300 ぐらいが良いと言われている
-
-minCount- 学習データの中で、この値未満の数しか出てこない単語は無視するよ、という値
- Wikipedia クラスだったら 20 ぐらいでいいんじゃないかな
- データが少ない場合は減らす
-
-epoch- この回数だけ繰り返して学習するよ、という値
- 少ないと学習しきれないし、多いと時間がかかって仕方がない
- 匙加減ひとつなのだが、Wikipedia クラスだったら 10 ぐらいでいいんじゃないかな
- データが少ない場合は増やす
繰り返しやってみて、良い感じのハイパーパラメータを探すのも、苦労する点のひとつということで。
(一般的な機械学習なら、良いハイパーパラメータの探索方法は色々あるよ!)
WORD2VEC を使う際の注意点
WORD2VEC の学習済みバイナリを作るためには、学習用のデータ(大量のテキストデータ)を読み込んで、1行がひとつの文章であり、形態素毎に半角スペースをディリミタとするテキストファイルを作らなくてはならない。
このWORD2VECの学習に必要な、形態素に分割された膨大な量の文章からなるテキストデータを、コーパスと呼ぶ。
単に「コーパス」と言っても、実は色々な用途のための色々な形のコーパスがあるので、ここでは「WORD2VEC用コーパス」とでも言っておく。
この WORD2VEC用コーパスは、例えば以下のような感じのデータである。
吾輩 は 吾輩は猫である を 読む 猫 で ある 。 名前 は まだ 無い 。
祇園精舎 の 鐘 の 声 。 諸行無常 の 響 あり 。
これを作ったら、後は読み込ませて学習するだけなのだが、これを作る際にも以下の注意点がある。
- MeCab 辞書の問題
- 正規化の問題
- 単語の取捨選択の問題
MeCab 辞書の問題
WORD2VEC用コーパスを作るためには、文章を形態素に分割しなければならないので、当然 MeCab などで形態素解析を行わなければならない。
MeCab は辞書によって分割される形態素が変わってきてしまうので、なるべく同じ辞書を使い続けなければならない。ここは IPA、ここは JUMAN というのはよろしくない。
もちろんお薦めの MeCab 辞書はこれである(笑)
正規化の問題
日本語には「表記の揺れ」という問題がある。
例えば「とりくむ」という言葉には一般的に「取り組む」「取組む」という、いくつかの送り仮名の書き方があり、どれも間違っているとも言えない。(正解はあるのだろうが)
このような送り仮名の表記の揺れは(特に NEologd 辞書では)様々なデータを取り込んで対応している。
その他にも、変な所に空白が入ってしまったとか、全角の数字と半角の数字とか、☆とか♡とか、数え上げればキリが無い。
こういう変な文字や表記が入ってしまった場合にどうするのかが、NLP の前処理のもっとも泥臭く大変な所である。
これを一定のルールで正していくのが「正規化」である。
(一般的な「正規化」は、数値データを平均が0、分散が1になるように変換することである)
NEologd では正規化の方針を定めてくれている。そして、この処理を実装してくれているのが neologdn である。
私の MeCab 辞書は NEologd 辞書を使っているので、正規化として neologdn を一律して使うことにする。
(2023.02.03 追記)上記の辞書はかなり古くなったので削除しました。こっちを使うと良いと思います。こっちの repository についての記事はコチラ。
辞書と同じ様に、一度使ったら、以降は全て同じ正規化処理をすべきである。
単語の取捨選択の問題
例えば文章のテーマを予測して分類する問題(文書分類)に取り組む場合などは、「てにおは」は文章の意味に関係無いので、形態素解析で助詞や助動詞を見つけたら削除する、なんてことをしたりする。
しかし WORD2VEC では、上でも述べたように単語の前後関係を学習するので、逆に単語を削除するという処理をしてはいけない。そのままで使うべきだ。
普通 NLP を始める時は、一番ビジネスへの応用が見込める文書分類から始めたりするので、実は間違えやすい点。
モデルが何をどう学習するということを知らないと、正しい前処理(形態素解析、正規化など)は分からないね、というお話。
fastText で日本語 Wikipedia を学習する
ということで、やってみよう。ここからがやっと本題。
いつものように、もうやってありますよ。
README に書いてある通りにやれば出来るはず。> pip install -r requrements.txt を忘れずに。非力な CPU だとマジで24時間ぐらいかかるし、容量もかなり食う(15GBぐらい)ので、注意。
ソースの解説
折角なんで、ソースの解説をしてみるなり。
あまり凝るつもりもなかったので、ひとつのファイル、ひとつの class (Processor) に押し込んでしまったから、読み辛いと思う。ごめんなさい。
create_fasttext_binary.py の Processor class の関数を呼び出す順に簡単にコメントしていく。
-
_download_wikiextractor()- Wikipedia のダンプは、HTML だったり、本文以外の余計な情報がいっぱいくっついてたりする。それをテンプレートに照らし合わせてパースしなければ本文は抜き出せない
- WikiExtractor は、上記のめんどくさい所をやってくれるありがたいもの。楽できるものはどんどん使っていこうという姿勢
- ただし、本家 WikiExtractor はちっとも動きやがらないので、これの Fork でひとつ前の Version のままでいてくれているこちらを使うことにする
- git clone や pip install する必要はなく、WikiExtractor.py をダウンロードするだけで使えてしまう
-
_load_mecab()- MeCab の Tagger を作るもの
- 私の MeCab 辞書のサンプル実装と同じ
- なので、私の MeCab 辞書をシンポリックリンクなりで使う分には何も考えないで良いし、IPA 辞書や JUMAN 辞書を指定することも出来る
-
_scrape_wikimedia()- Wikimedia の日本語 Wikipedia ダンプのページをスクレイプして、最新のダンプの URL とかを取得する
- 無駄に凝ってしまった
-
_scrape_wikimedia_page()を呼び出す- 上記からリンクされている、各々のダンプのバージョンのページは、ちょうどダンプしている途中だと情報が中途半端だったりする
- なので、情報がちゃんとしているページのみからダウンロードするために、チェックとかをしてたりする
-
download()- 実際に日本語 Wikipedia のダンプをダウンロードする
-
extract()- WikiExtractor を使ってダンプから本文を取り出す
- 下手にまた HTML に変換されても面倒くさいので、簡単に扱える JSON 形式を出力としている
-
wakati()- 上記 JSON から本文を1行1文章、形態素を分割してファイルに書き込む
- 空白をディリミタとして文章を形態素に分割することを「分かち書き」という
- 分かち書きだけで良いので、品詞を取り出す必要もない
- Tagger を呼び出す時に
-O wakatiとすると、Tagger.parse をするだけで分かち書きになる - なので、逆に簡単になる
- Tagger を呼び出す時に
- ファイルがいっぱいあって時間がかかるので、なんとなく multiprocessing を使って処理の並列化をしている
- Python 3.8 以降だと multiprocessing.Process がうまく動かなかったので、バージョンをみて並列化するかしないかと決めている
- なにがいけないのかは明らかで、MeCab.Tagger を安易にスレッドで共有しているのがいけない
- 真面目に実装すれば出来ると思うけど、面倒くさいのでそこまで頑張ってない
- multiprocessing をする関係から、実際にディレクトリ毎に分かち書きする関数を class の外に出している
-
wakati_each_dir()とwakati_eatch_sentence()
-
-
wakati_each_dir()- 改行コード2連続、すなわち1行空いている文のかたまりを「文章」としている
- 何を文章とするかは本当はよく考えなきゃいけない所
-
wakati_each_sentence()- ここで文章の正規化や実際の分かち書きをしている
- WikiExtractor は「リンクを削除する」という設定にしているので、その関係で括弧の中身が消えちゃったりしている
- それを綺麗にする処理もやっている
-
REPLACE_PATTERNSを使っている所 - 本当はこういう泥臭い前処理をもっとちゃんとやらなきゃ駄目
-
- また、あまりに短い文章はサブタイトルだったりするので除外している
- さらに、あまりに長い文章はそもそも fastText で学習できないので、あらかじめ除外している
-
train()- fastText の学習をする
- fastText の学習結果を word2vec 形式のテキストファイルに変換して書き出してもいる
-
convert()- fastText は、実際に遊ぶには使いづらかったりする
- なので、これを Gensim で使えるように、word2vec 形式のバイナリに変換して書き出す
生成物
kv_fasttext_jawiki_YYYYMMDD.bin が目的のバイナリ。
調べると、約40万個の単語が学習されてベクトルに変換できることが分かる。
遊び方
いつものようにサンプル実装もつけています。w2v.py。
上記のバイナリの動かし方は、この実装を参考に。
動かしてみた例を載せる。
「フロンターレ」に近い意味の単語 Top 10
> ./w2v.py フロンターレ --topn 10
【結果】
1. 川崎フロンターレ : 0.801146924495697
2. 大宮アルディージャ : 0.7202813625335693
3. FC東京 : 0.6904745697975159
4. F・マリノス : 0.6865490078926086
5. アルディージャ : 0.6861094832420349
6. 大宮アルディージャユース : 0.6827453970909119
7. 浦和レッズ : 0.6827343702316284
8. ジェフユナイテッド市原・千葉リザーブズ : 0.6774695515632629
9. ヴァンフォーレ甲府 : 0.675808846950531
10. ジュビロ磐田 : 0.6728240251541138
単語をひとつだけ与えると、その単語に似た意味の単語が出てくる。
ここから、フロンターレが J League のチームであることが分かる。
また、川崎と地理的に近いチームが出てきている。
「水泳」+「自転車」+「マラソン」に近い意味の単語 Top 5
> ./w2v.py 水泳 自転車 マラソン
【結果】
1. トライアスロン : 0.7470418810844421
2. 車いすマラソン : 0.7251624464988708
3. 陸上競技 : 0.694725513458252
4. サイクリング : 0.6912835836410522
5. マウンテンバイクレース : 0.6851004362106323
もちろん意味の足し算が出来る。
上手い具合に「トライアスロン」が出てきた!
「王」−「男」+「女」に近い意味の単語 Top 5
> ./w2v.py 王 女 --neg 男
【結果】
1. 王位 : 0.6868267059326172
2. 王妃 : 0.6588720083236694
3. 国王 : 0.6583836674690247
4. 王家 : 0.6464112401008606
5. 先王 : 0.6295769810676575
引き算も出来る。有名な例をやってみた。
1番目には出てこなかったが、2番目に欲しかった「王妃」が出てきた。
「右腕」−「右」+「左」に近い意味の単語 Top 5
> ./w2v.py 右腕 左 --neg 右
【結果】
1. 左腕 : 0.793571412563324
2. 腕 : 0.6797513961791992
3. 片腕 : 0.6668301820755005
4. 左肩 : 0.629976749420166
5. 肩 : 0.6073697805404663
こういう分かりやすいのだったら、きっちり「左腕」が出てくる。
「札幌」−「東京」+「大阪」に近い意味の単語 Top 5
> ./w2v.py 札幌 大阪 --neg 東京
【結果】
1. 函館 : 0.7571847438812256
2. 帯広 : 0.7389914393424988
3. 札幌市 : 0.726713240146637
4. 小樽 : 0.7243739366531372
5. 札幌市内 : 0.712246298789978
「札幌が北海道における東京だとしたら、北海道における大阪はどこ?」という質問を想定した。
まず、地名ばかり出てくるところが、きっちり学習できるなと感じるポイント。
そして、経済活発度とか、地理的な位置関係を考えると、「函館」になるのであろう
その2はこれで終わり
結構うまい結果が出てきたと思う。普通に嬉しい。
次は SVM でも使ってみようか。