1. はじめに
いくらセキュリティー的に問題がないと言われていても、ブラックボックスになっているSaaSを使うのはやはり怖い、などの理由で自分だけのAIをローカルで動かしたいという要件はあるものです。
今回は、Open AIから最近リリースされたgpt-ossの20bモデルと120bモデルをIBM Cloud上のVSIで試したいと思います。
今回は、GUIを試してみたかったので、Windows Server 2022上で、LM Studioというツールを試し、GPUありとなしでどれぐらい性能差が出るのかを確認してみます。なお、gpt-oss-120bでは80GB以上のVRAMを持つGPUが推奨されるので、比較的安価なA100(80GB VRAM)を東京リージョンで試してみたいと思います。
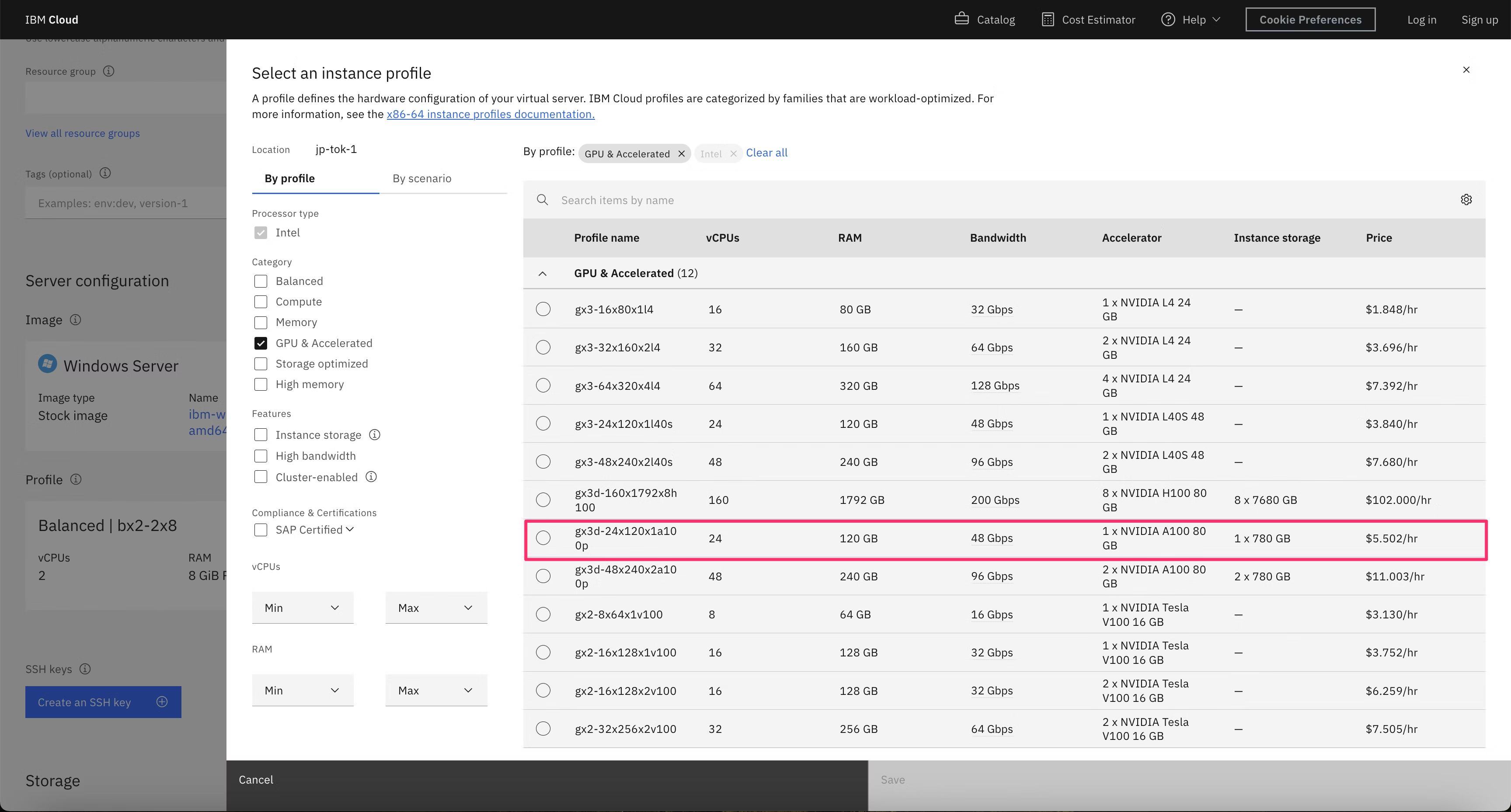
A100(80GB VRAM) x 1を選択できるプロファイルはgx3d-24x120x1a100pです。
2025年8月23日現在、Windowsでgx3系のプロファイルを選択してプロビジョニングすると、Running状態にはなりますが、うまくbootされません。つまり、pingもRDPもVNC接続もできません。
回避策として、bx2-2x8でまず一旦プロビジョニングしてから、プロファイルをresizeしてgx3d-24x120x1a100pを選択すれば上手く行きます。
2. 環境の確認とDriverのインストール
2-1. プロビジョニング直後の状況
- プロファイル情報:
gx3d-24x120x1a100pがプロビジョニングされ、24vCPU/120GB RAM/A100(80GB)x 1が割り当てられている。

- デバイスドライバーがインストールされていないため、OSから正しく認識されていない。

よって、デバイスドライバーのインストールを以下で行う。
2-1. Driverのダウンロード
-
https://www.nvidia.com/en-us/drivers/から、適切なドライバーを選択。今回は以下のようにして検索。

- 以下が検索にヒットする。
Viewを押下。
-
Downloadを押下。
2-2. Driverのインストール
2-3. Driverインストール後の確認
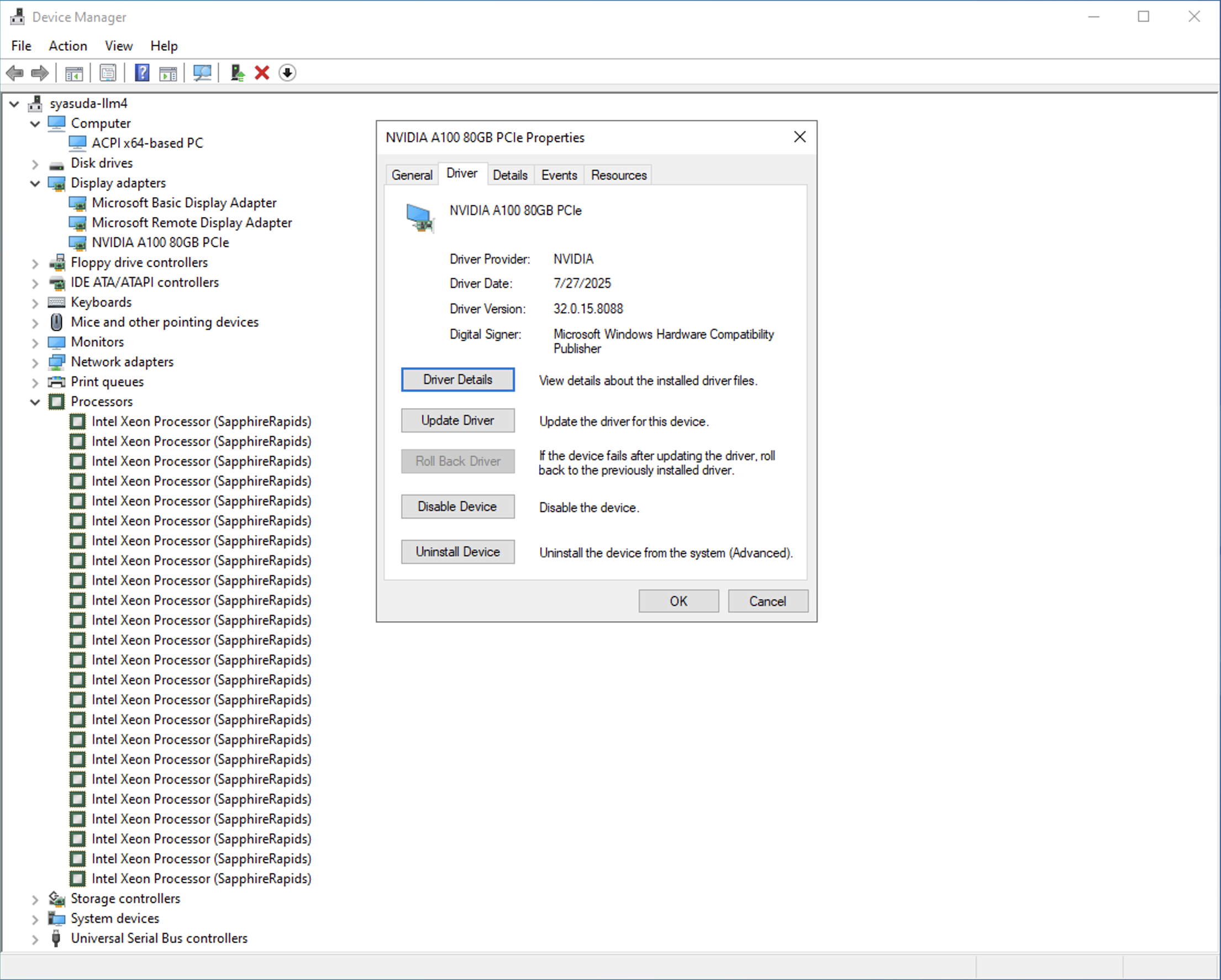
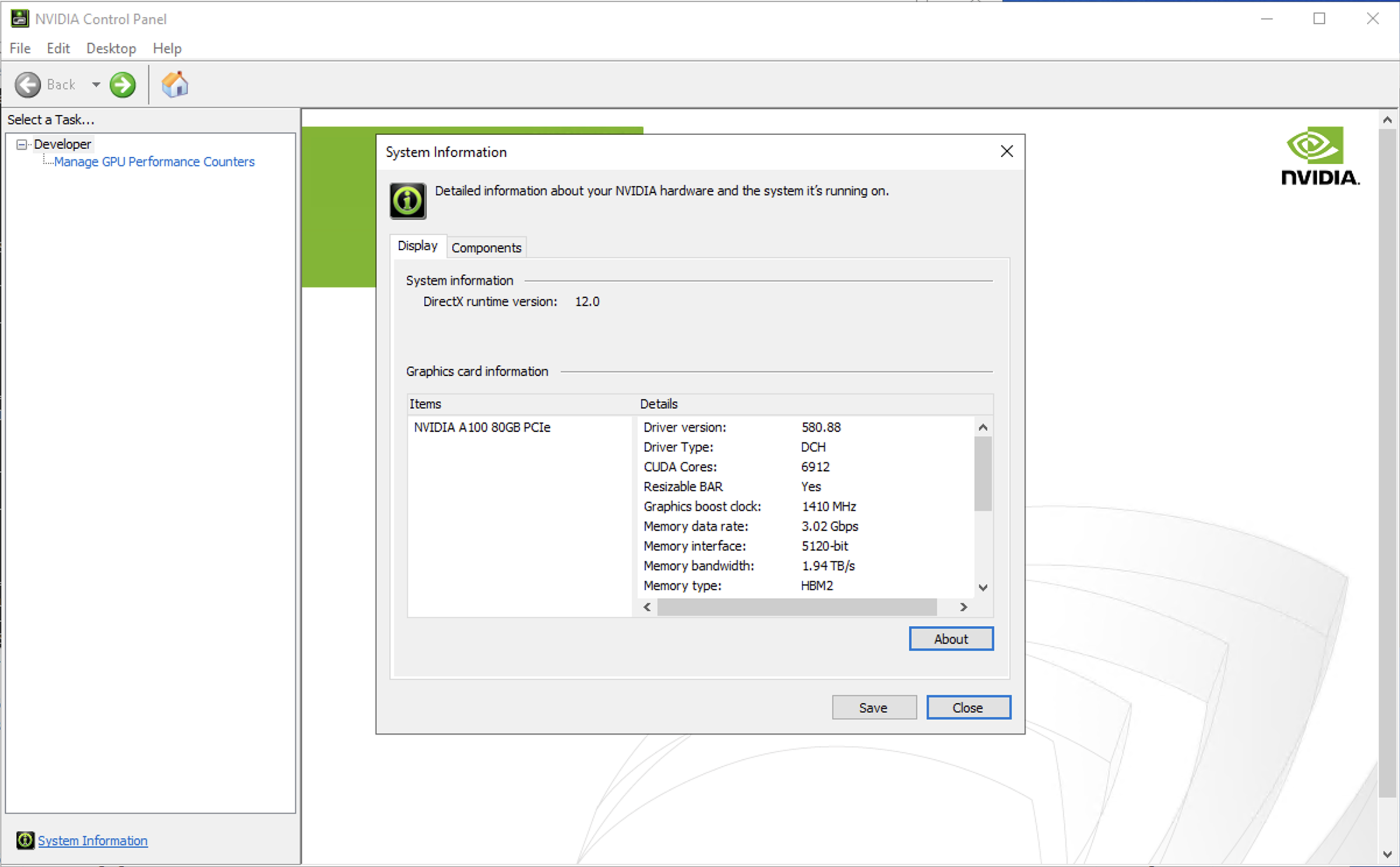
- Display Adaptersの1つとして認識されるようになった。
- Nvidia Control Panelがインストールされた。
PS C:\Users\Administrator.SYASUDA-LLM4> nvidia-smi
Sat Aug 23 22:56:50 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.88 Driver Version: 580.88 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A100 80GB PCIe TCC | 00000000:08:01.0 Off | 0 |
| N/A 36C P0 43W / 300W | 9MiB / 81920MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
3. ディスクの設定
モデルのインストールにはそれなりの容量が必要となります。例えば、gpt-oss-20bだと12.1GB, gpt-oss-120bだと63.4GBほど必要です。当然、VSIのCドライブに配置するには大きすぎる容量なので、別のドライブに配置した方が良いでしょう。今回は、別途500GBのデータ用途のブロックストレージを注文しVSIに割り当てて利用します。
- ディスクの追加購入と割り当て
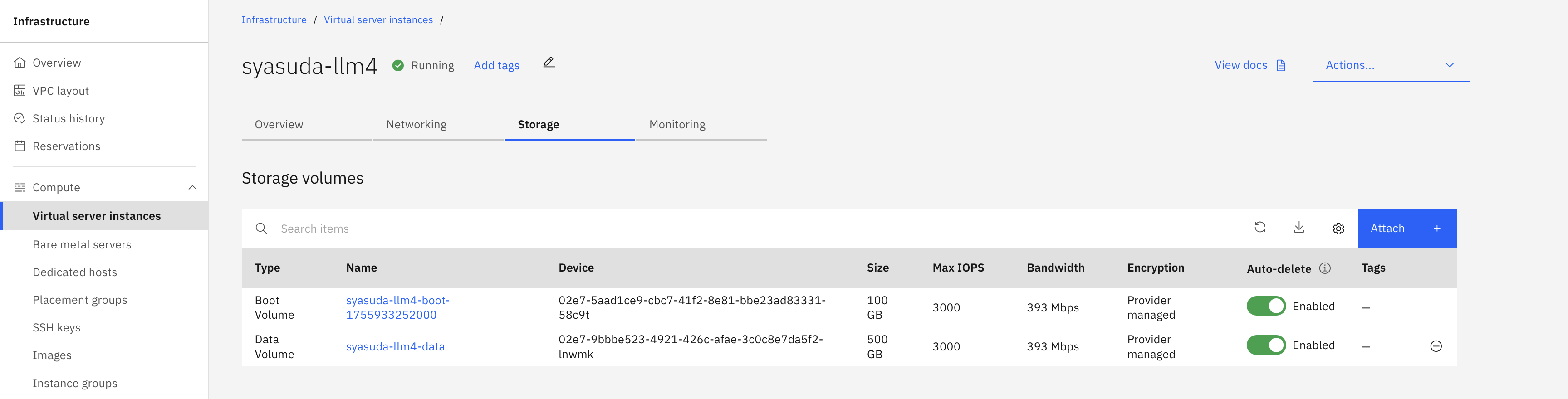
- ディスクの初期化とフォーマット後の状況
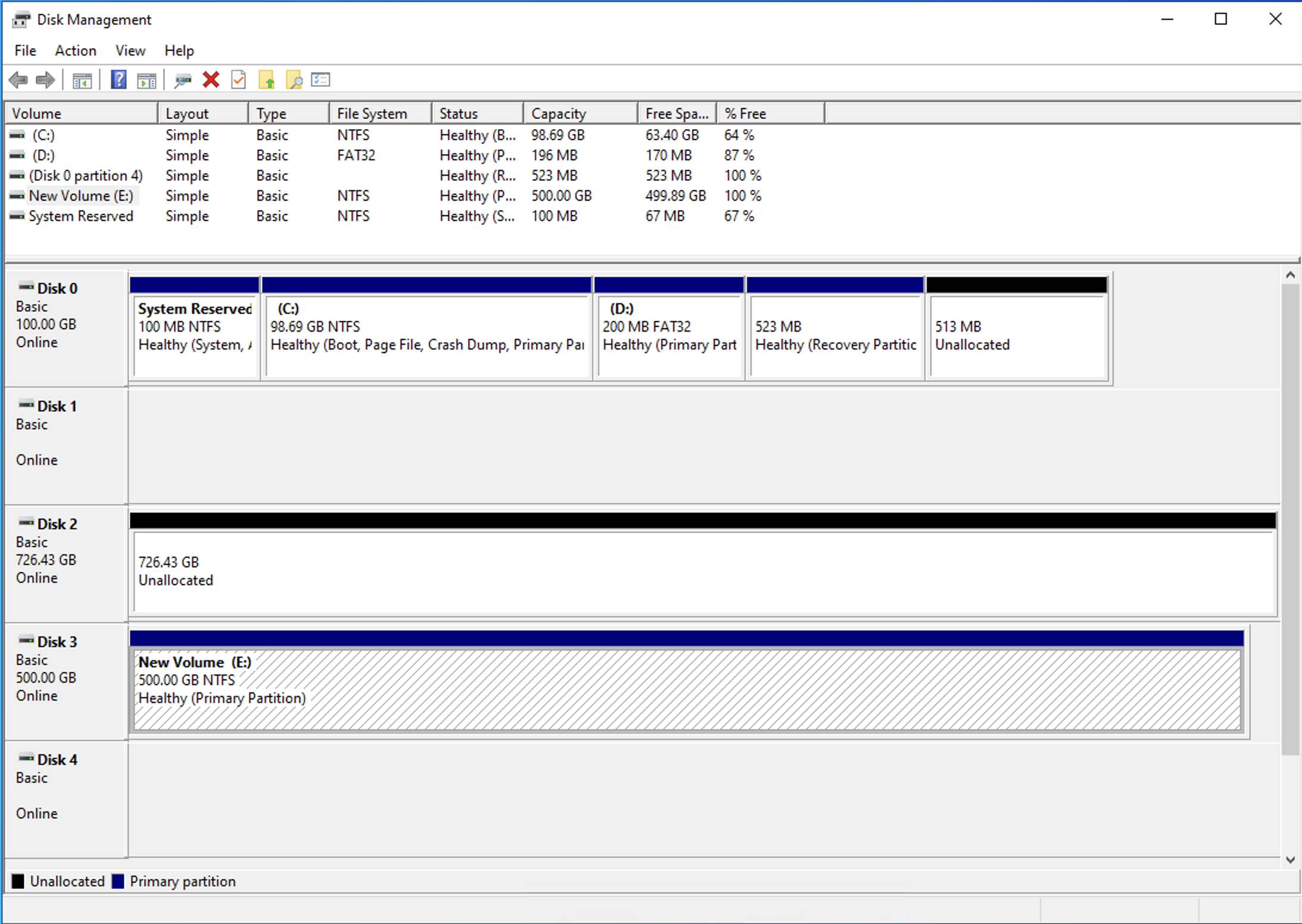
-
E:¥modelsフォルダーを作成(ここにモデルをダウンロードして配置する予定)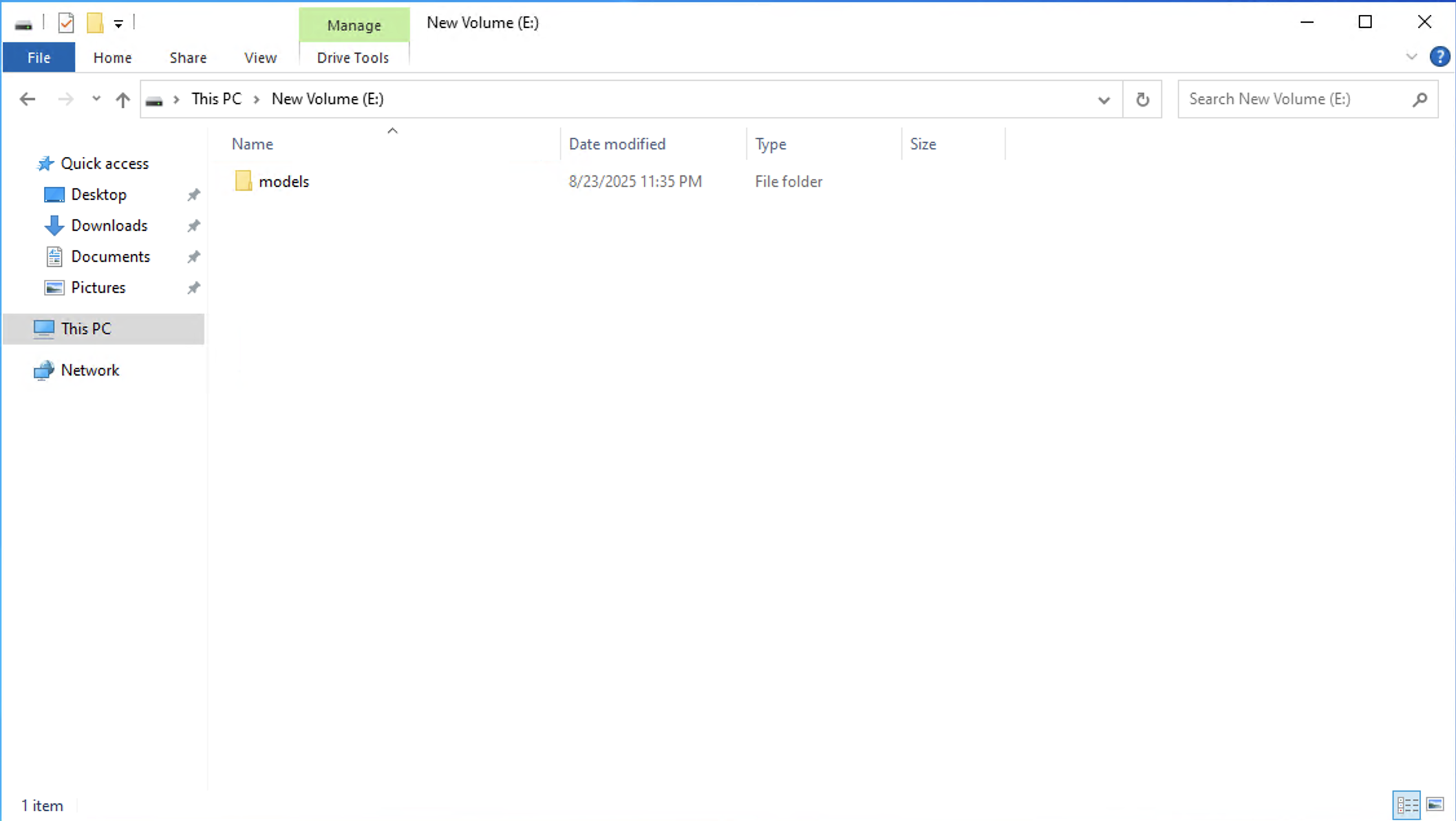
このプロファイルにデフォルトで用意されている700G近い未使用のローカルディスク(Disk2)は、Instance storageと呼ばれるものです。ホストの再起動でデータが失われることはありませんが、ホストの停止やシャットダウンやホスト障害によってデータは失われます。例えば、課金を止めるためにVSIをシャットダウンしたらデータは消えてしまうことに注意してください。
https://cloud.ibm.com/docs/vpc?topic=vpc-instance-storage
4. LM Studioのインストール
-
https://lmstudio.ai/にアクセス。 - ダウンロードしたイメージを起動

- LM Studioを起動。

- 後で容易に切り替えられるが、今回は
Power Userを選択。

- モデルの容量は大きいため、LM StudioをインストールしたCドライブにダウンロードしない。そのため、ここではダウンロードせず右上のSkipを選択する。

- しつこくgpt-oss-20bのダウンロードを促されるため、
Do not show this againを選択してDismissを選択する。

5. 言語設定の変更
せっかくなので、表示言語を日本語に変更しておきます。
- 右下の設定変更ボタンを選択。
- 言語設定で日本語を選択
- 日本語になった
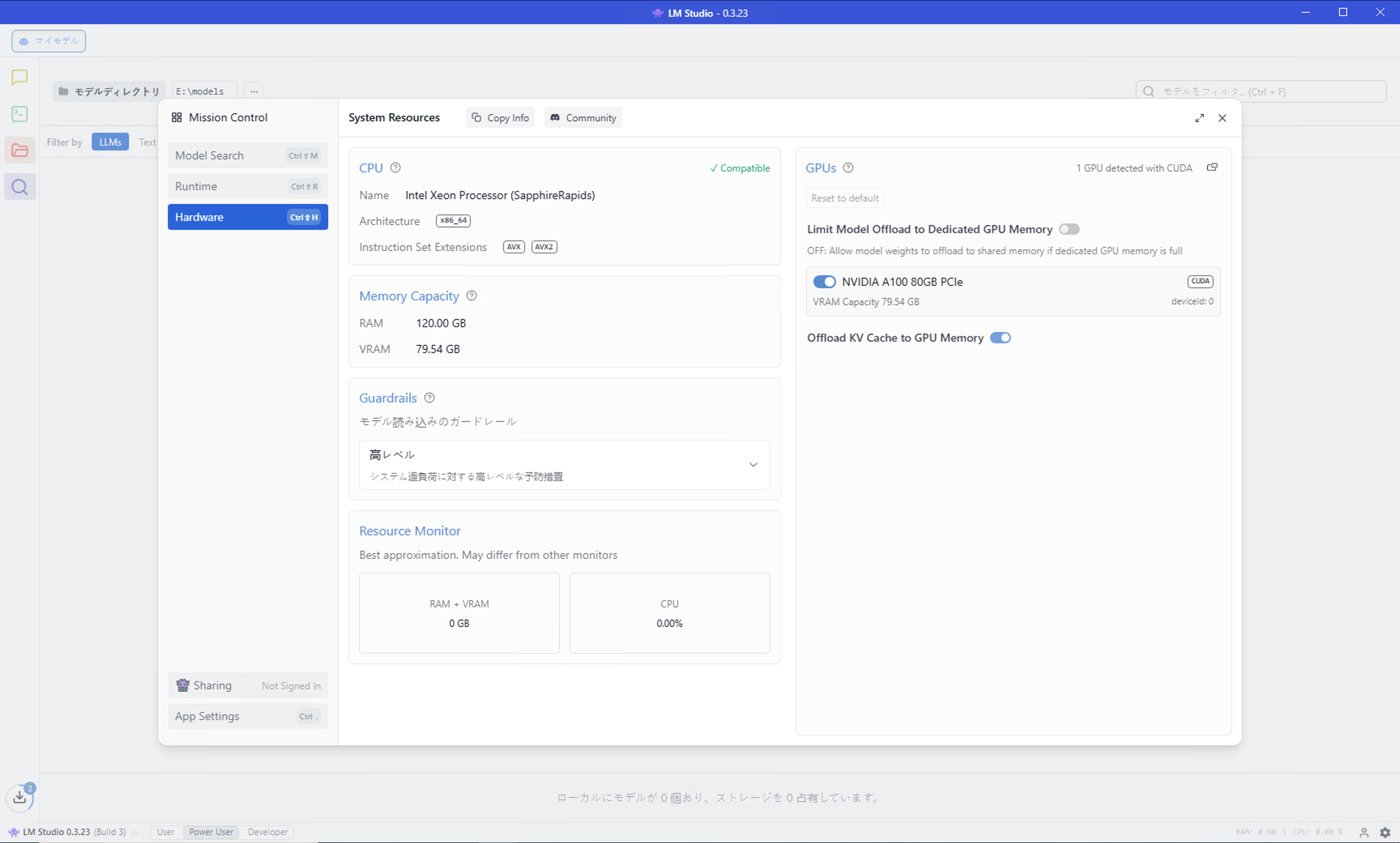
6. Hardware設定の確認
今回は特に設定を変更しませんが、A100が認識されていることがわかります。
7. モデルのダウンロードディレクトリを変更
先ほど作成したディレクトリをモデルのダウンロード先へと変更します。
-
マイモデルを選択。
- モデルディレクトリを
変更
- 先ほど作成したフォルダを選択
- 無事変更が完了。
8. モデルのダウンロード
- 探索(Search)に移動。

- gpt-oss-120bをダウンロード。

- gpt-oss-20bをダウンロード(他のモデルをダウンロードしている間でも、並行してダウンロード可能)

- ダウンロードが完了すると、
マイモデルに一覧で表示される。
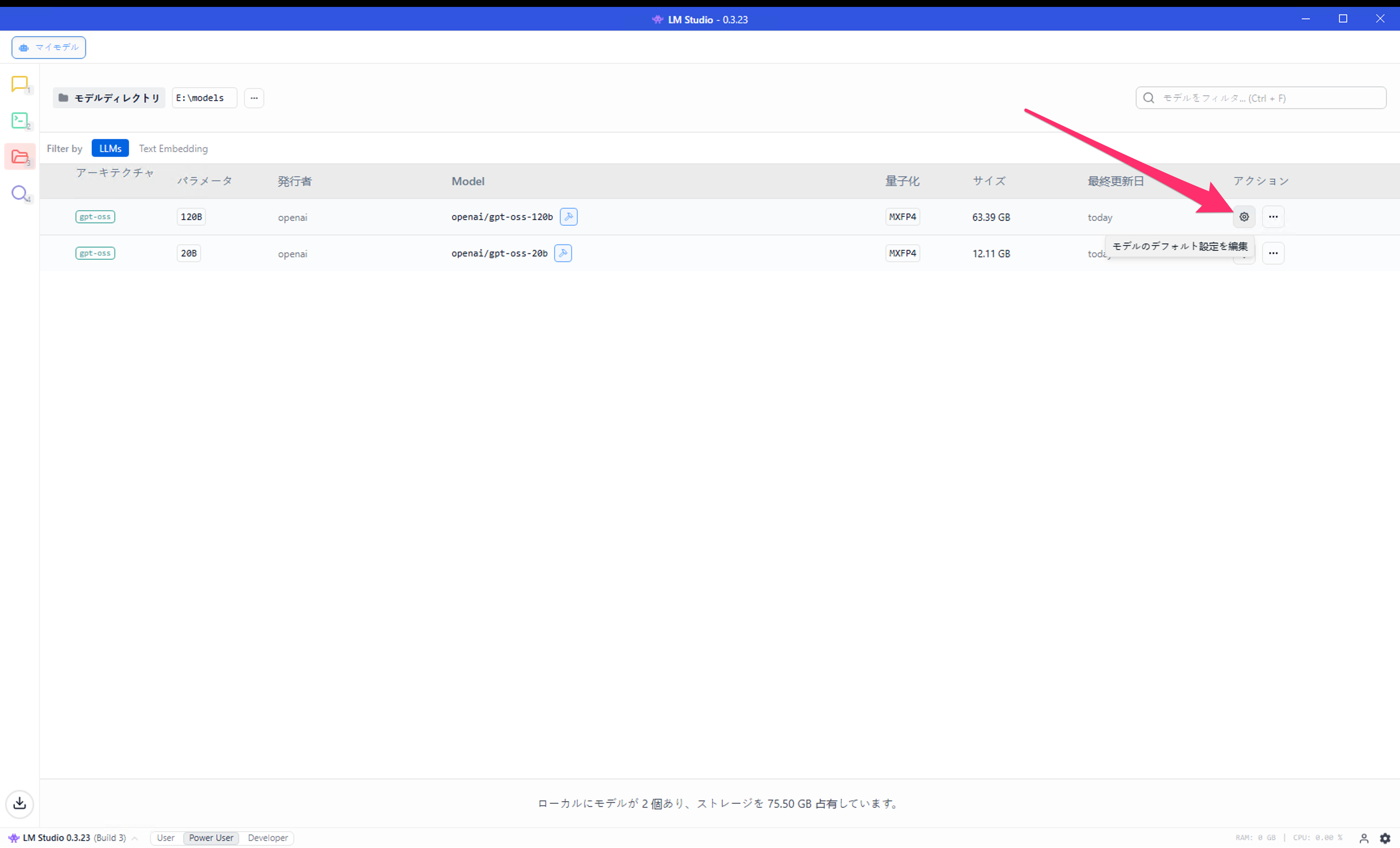
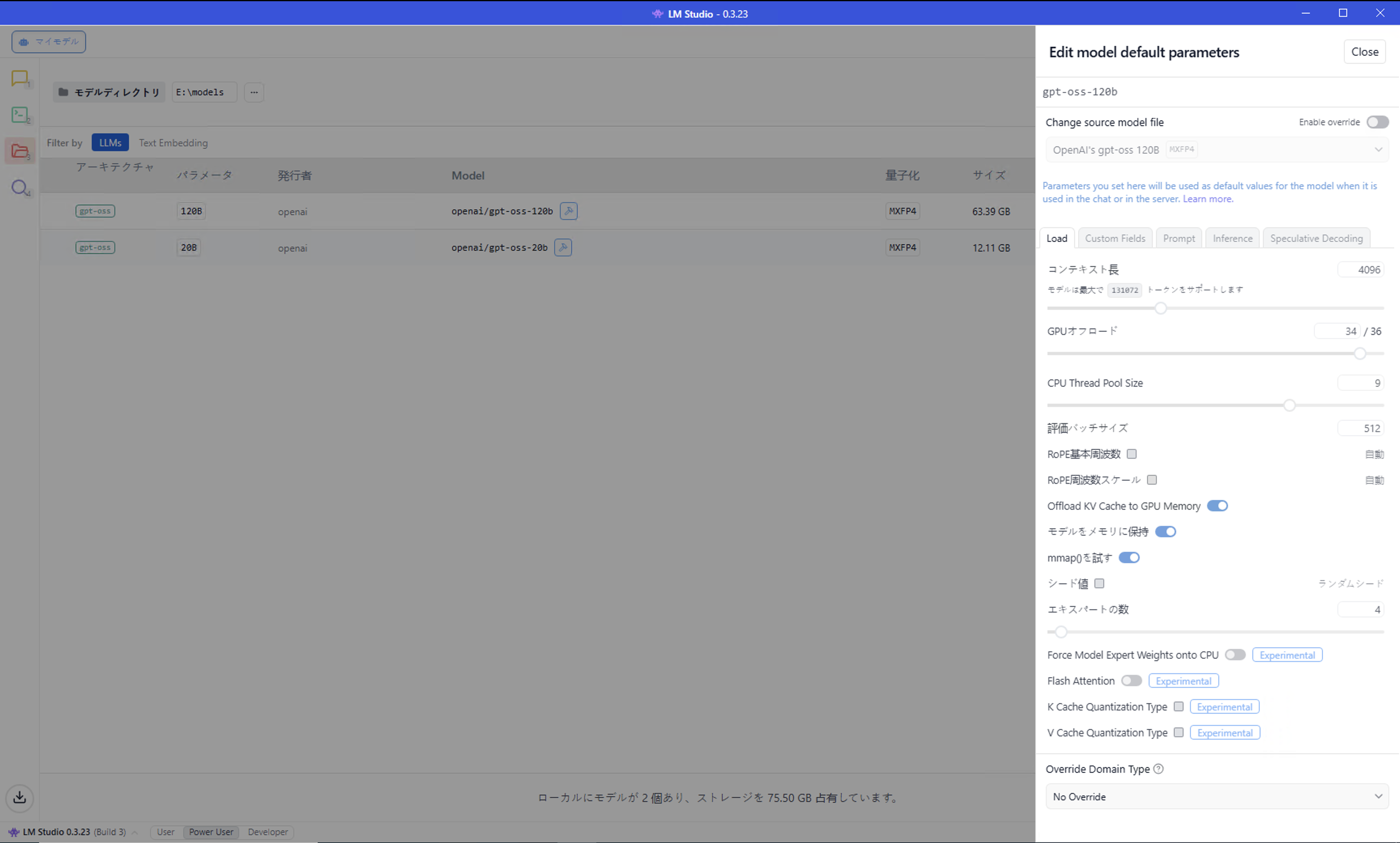
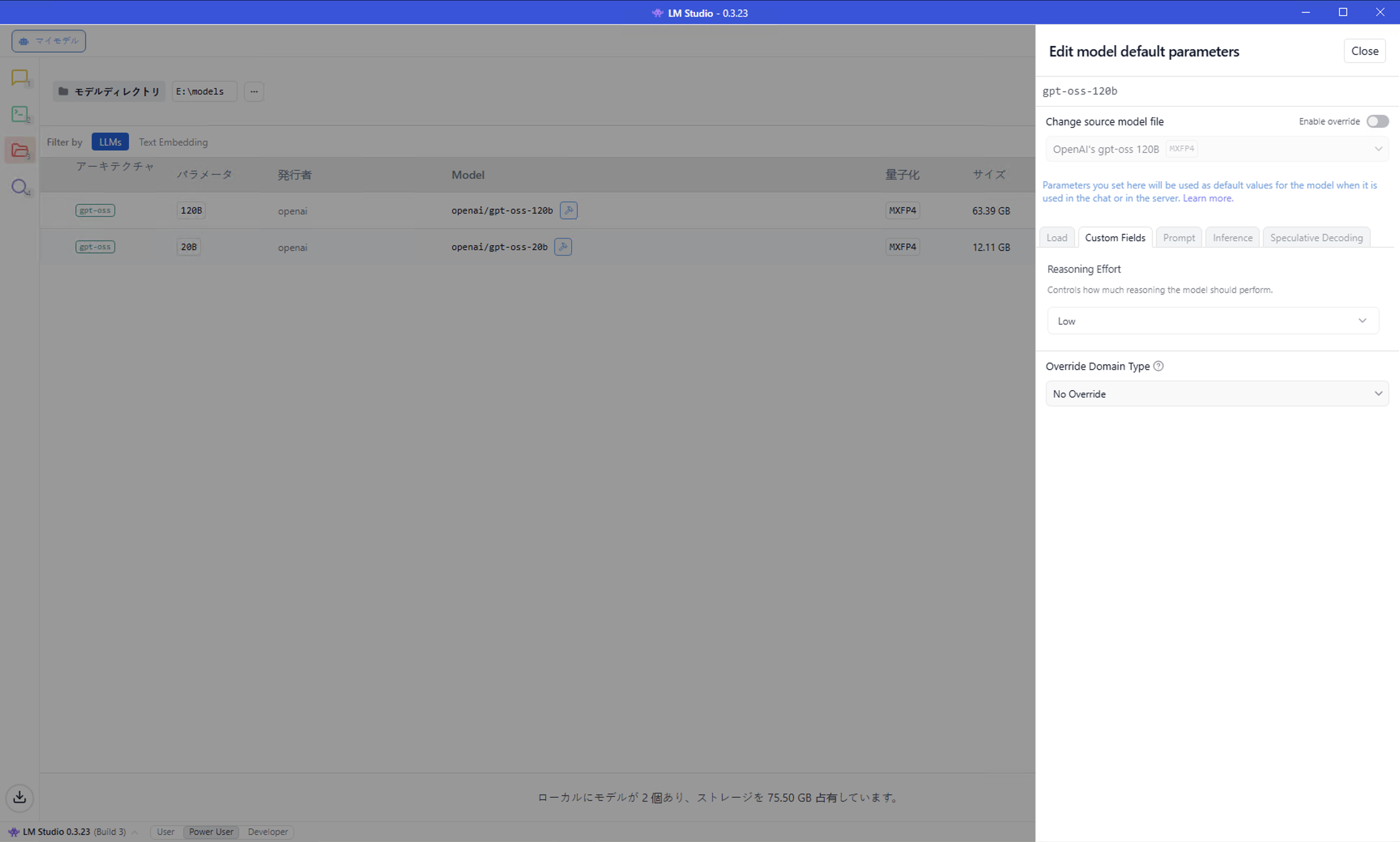
9. モデルのデフォルト設定の確認
モデル実行時には様々なパラメーターを指定可能であり、そのデフォルト設定を変更することができます。ここでは、gpt-oss-120bモデルのデフォルト値を確認するだけに留めます。
- 「モデルのデフォルト設定を編集」を押下
10. 動作確認
今回は、gpt-oss-120bを試してみます。
- モデルのロード前
PS C:\Users\Administrator.SYASUDA-LLM4> nvidia-smi
Tue Aug 26 15:46:29 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.88 Driver Version: 580.88 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A100 80GB PCIe TCC | 00000000:08:01.0 Off | 0 |
| N/A 42C P0 66W / 300W | 426MiB / 81920MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 5868 C ...grams\LM Studio\LM Studio.exe 416MiB |
+-----------------------------------------------------------------------------------------+
-
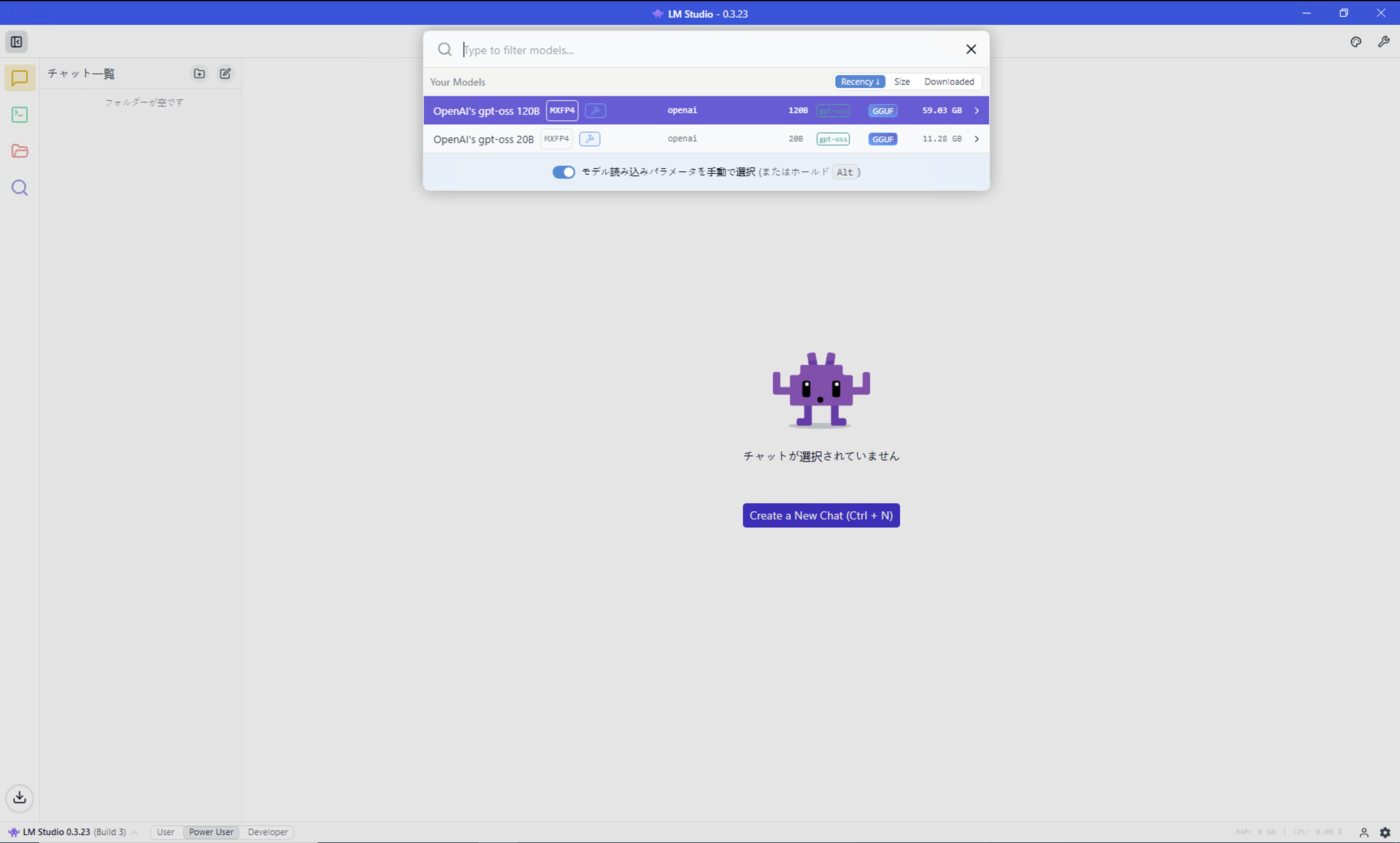
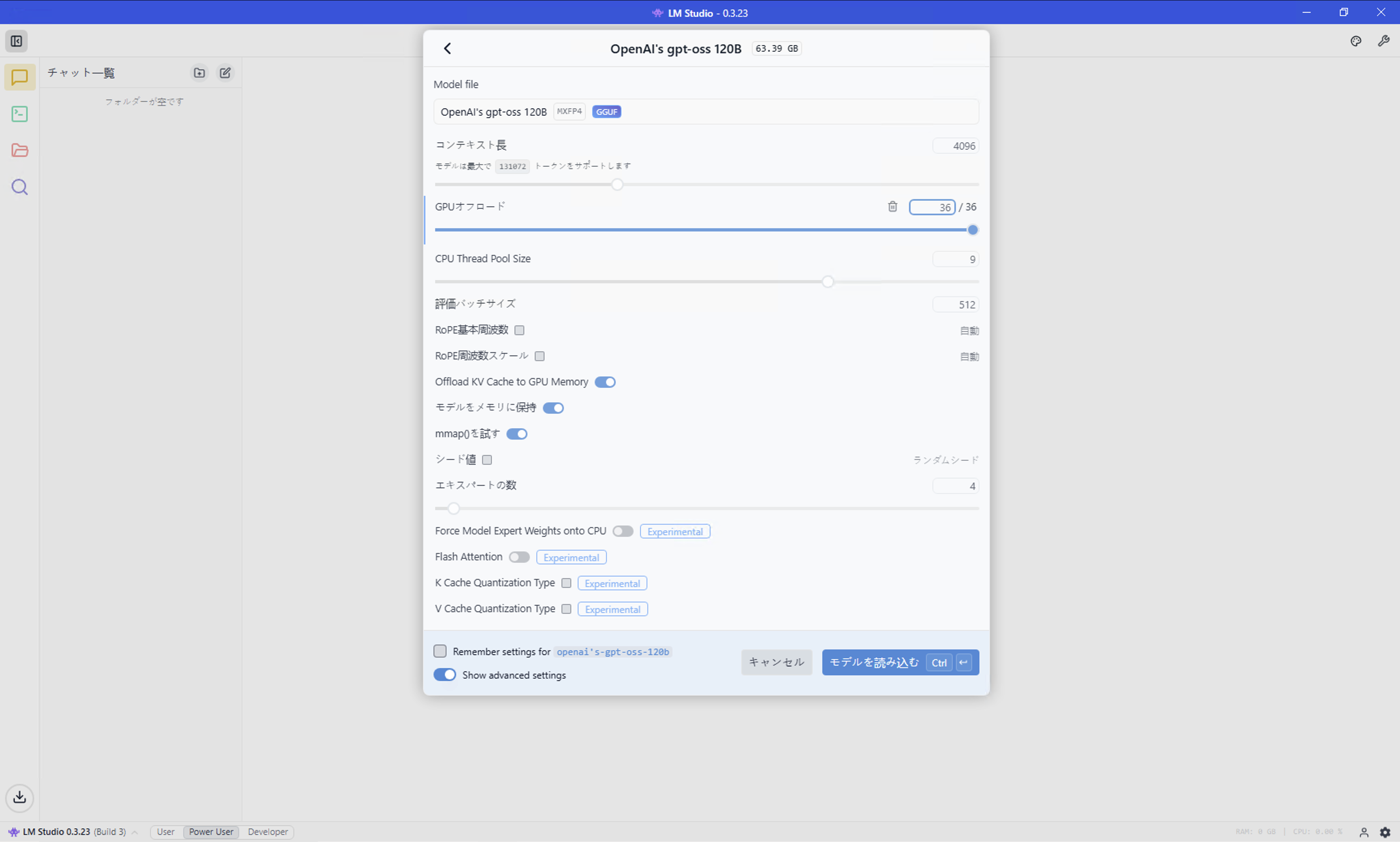
モデルのロード。ここでは、オプションを明示的に確認するため、
モデル読み込みパラメーターを手動で選択にチェックを入れて該当のモデルを選択する。
-
GPUオフロードを最大(ここでは36)にしてモデルを読み込む。
-
モデルロード後の状態
PS C:\Users\Administrator.SYASUDA-LLM4> nvidia-smi
Tue Aug 26 15:48:00 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.88 Driver Version: 580.88 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A100 80GB PCIe TCC | 00000000:08:01.0 Off | 0 |
| N/A 42C P0 66W / 300W | 61731MiB / 81920MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 5868 C ...grams\LM Studio\LM Studio.exe 416MiB |
| 0 N/A N/A 7948 C ...grams\LM Studio\LM Studio.exe 61188MiB |
+-----------------------------------------------------------------------------------------+
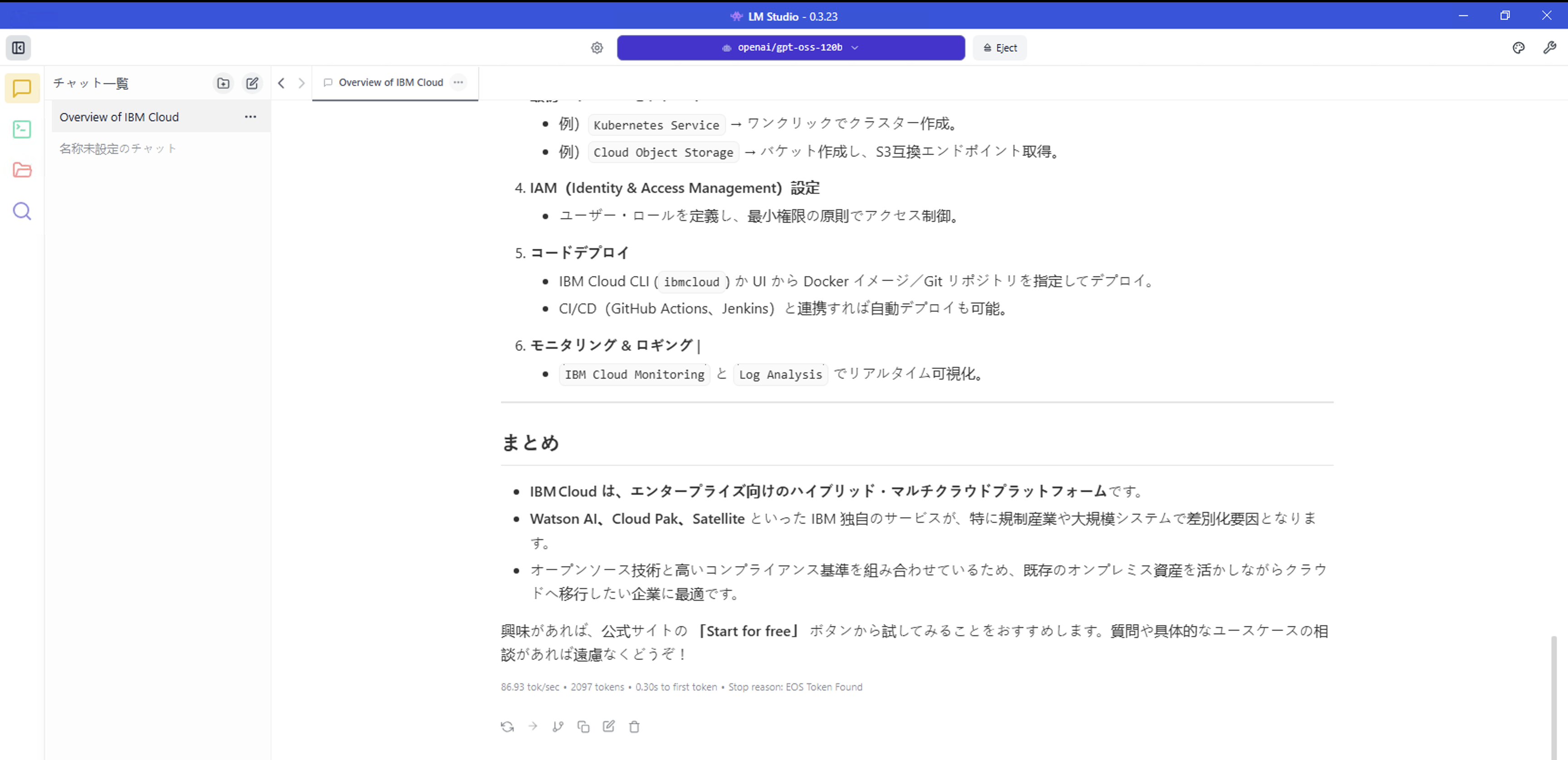
11. 性能まとめ
いくつかのパターンで性能を測ってみた結果が以下になります。
GPU Offloadありの場合は、CPU使用率も最大で11%程度でありRAM消費量も大したことはありませんでした。しかし、GPU Offloadなしの場合は、モデルをRAM上に載せるためにまず最初にRAMを大量に消費します。また、24vCPUモデルにも関わらずCPU使用率も40%程度と大きなものになりました。
token/secの観点において、性能としてはGPU Offloadあり・なしで10倍差の性能がありますが、これはあくまでRAMに十分余裕がありSapphire Rapidsという高性能プロセッサーを利用しているから10倍差で済んだといえます。一般的な廉価なPCなどで実施した場合はもっとこの性能差は顕著になるのでしょう。
| モデル | GPU Offloadあり | GPU offloadなし |
|---|---|---|
| gpt-oss-20b | GPU Offload(24/24) 123.53 tok/sec 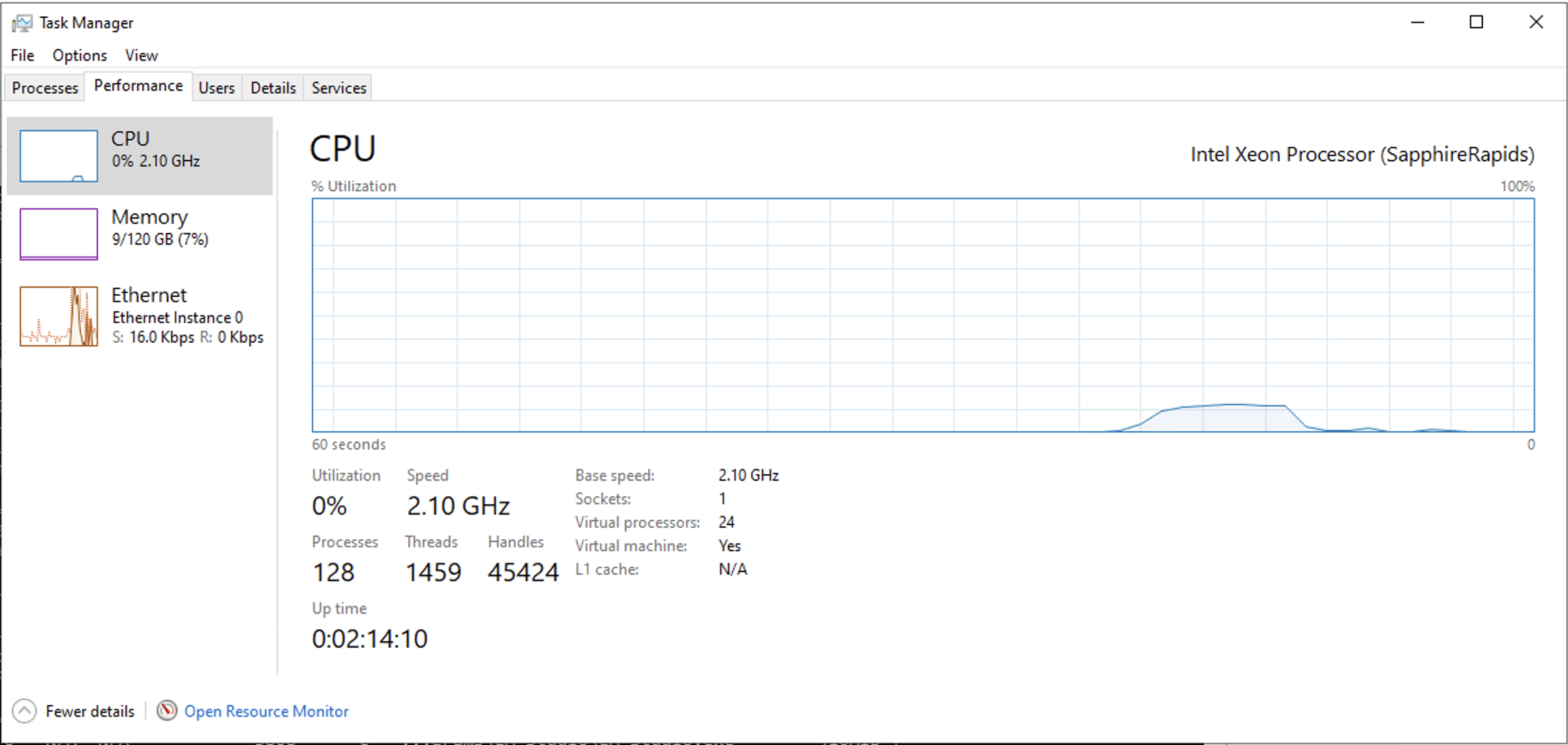
|
GPU Offload(0/24) 12.60 tok/sec 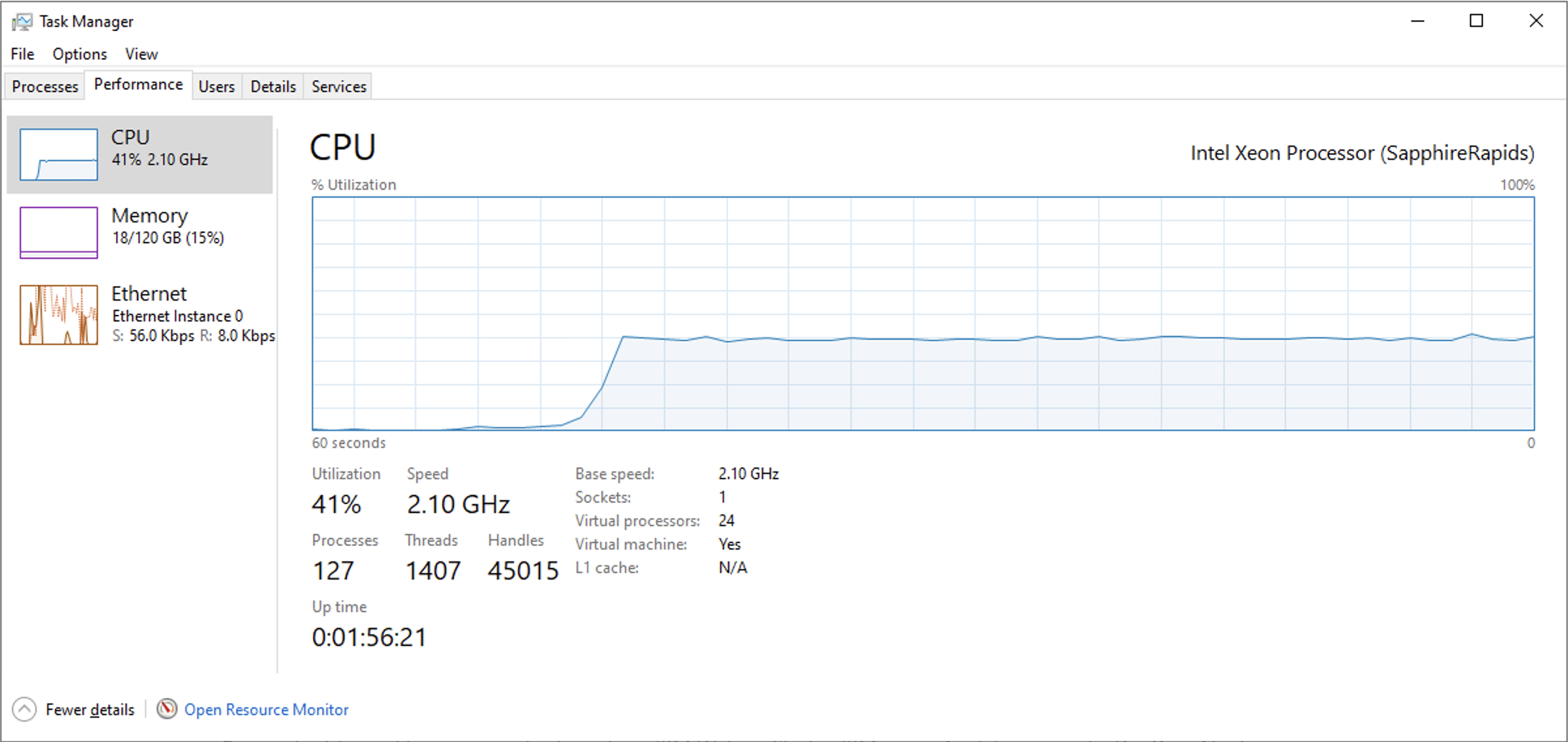
|
| gpt-oss-120b | GPU Offload(36/36) 86.93 tok/sec 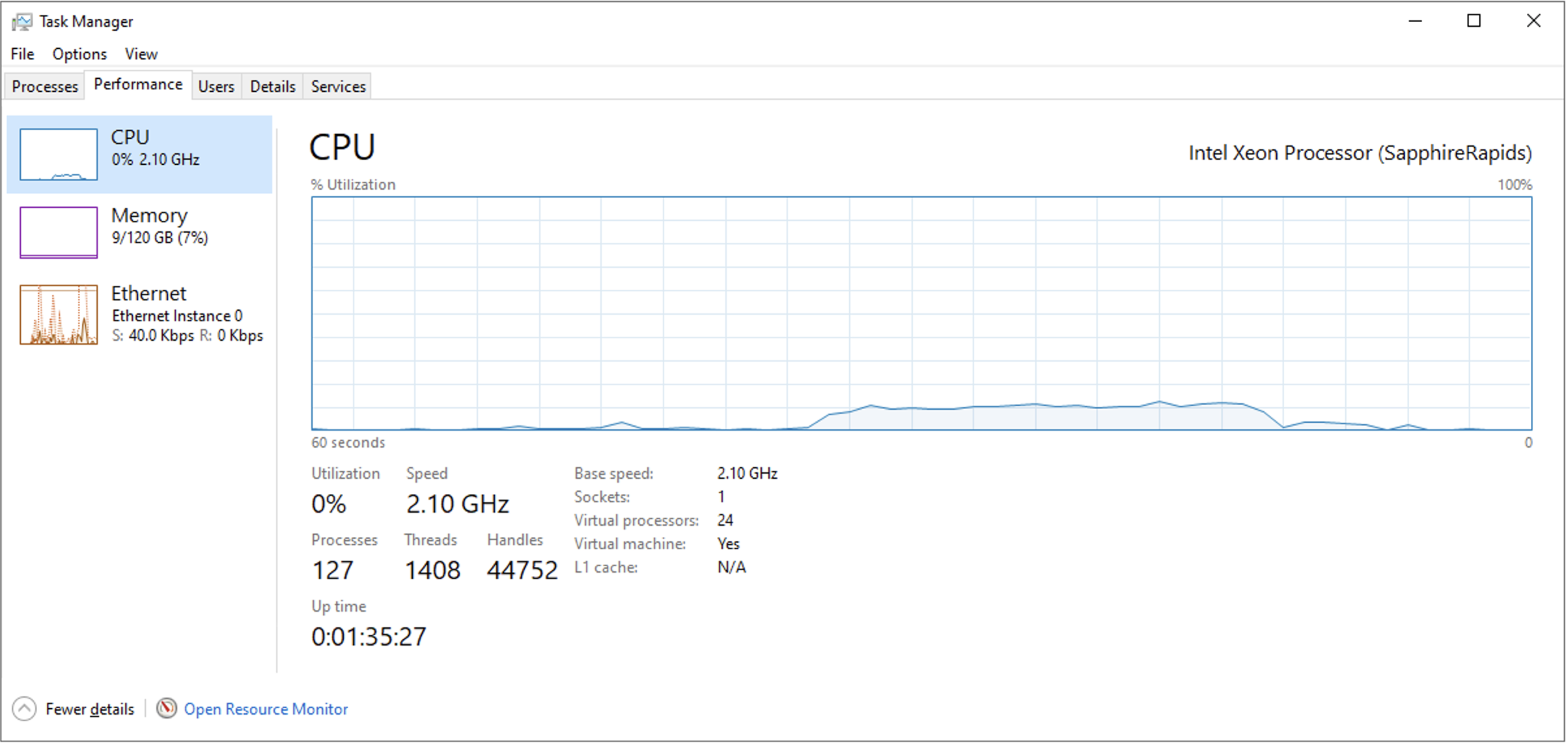
|
GPU Offload(0/36) 8.48 tok/sec 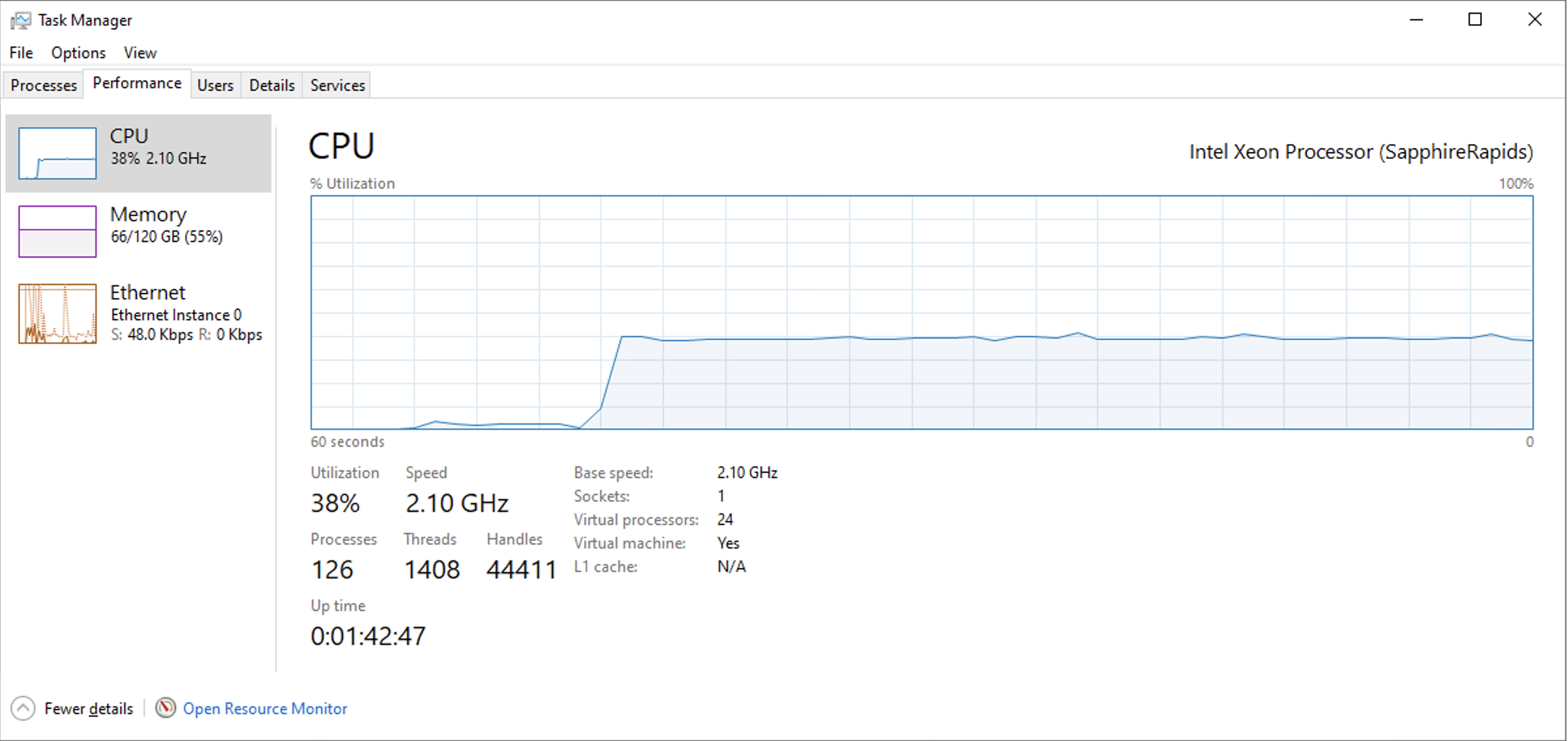
|
おわりに
「毎回WindowsにRDPでログインして使うのは、やっぱり面倒だなぁ。Webサーバー経由で利用できる方が、みんなで環境を共有できて楽だなぁ」と思って、いろいろ調べていたら、LM StudioでもOpen WebUIと連携できるようです。確かに、LM StudioにはServerとして動かしてAPI接続できる仕組みがありました!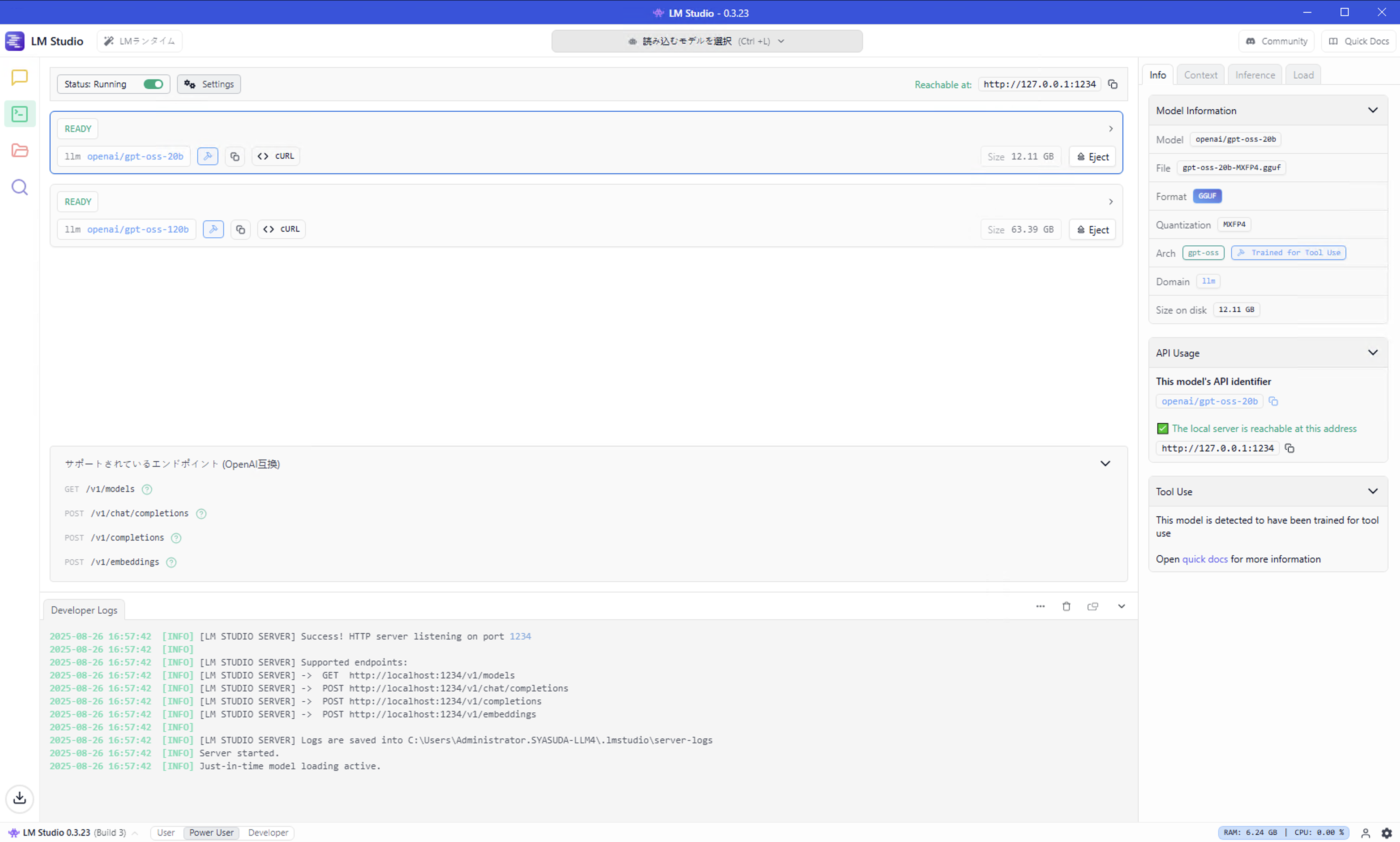
とはいえ、LM Studioの良さは初心者にとっても分かりやすいUIそのものにもある気がしますので、このUIを利用しないのであればその魅力は半減する気もします。Open WebUIと連携するなら、最初からOllamaを使えばよかったのかもしれません。
ということで、機会があれば今度はOllamaをLinux環境に入れてOpen WebUIと連携する構成を試してみたいと思います。