せっかく会社の名前を借りたAdvent Calendarの記事なので、会社に絡んだ題材を扱います。
(前置き)転職会議 について
Livesenseでは、転職会議という転職者による企業の評判クチコミを扱ったサイトを運営しており、日々企業についてのクチコミが投稿されている。
これまで転職会議では、クチコミのテキストデータと5段階からなる評点データを別々のデータとして取得していたが、先日のリニューアルで、評点とテキストデータを同時に投稿できるようになり、さらに読みやすいクチコミを提供できるようになった。
| リニューアル以前に投稿されたクチコミ | リニューアル後に投稿されたクチコミ |
|---|---|
 |
 |
ここで感じる課題感
新しく投稿されるクチコミは評点によって読みやすくなったものの、過去に蓄積された大量の投稿には当然5段階の評点データは無いし、そのままでは顔アイコンを出すことは当然出来ない。
しかしこの課題を解決して、過去のクチコミも同じように読みやすくなったらもっと良いサイトになるはず!
という所を解決することは出来ないかやってみることにした。
取っ掛かり探し。手法を調べる
調べてみると、この問題は感情分析(他には評判分析、 Sentiment Analysis または Sentiment Classificationとか)と呼ばれている問題だそう。
さらにその手法は大別するとこんなあたりが確認できた。
- 感情辞書を使った判定手法
- 機械学習を使った手法
手法1: 感情辞書を使った手法
感情辞書を使う手法は、例えば「残業」がネガティブだとして「残業はない」であれば打ち消されてポジティブと判定する、というような単純なロジックだ。
しかし、すぐに困難に当たった。
残業はそんなにありませんでした
例えば上記のような場合、チョチョイと係り受けをするだけでは解決せず、色々なパターンを考えなければならなそうだった。
さらに転職のクチコミという性質のせいか、このような言い回しはよく使われているようだった。。。
という所まで来てこの手法は早々に断念
手法2: 機械学習による手法
機械学習やらディープラーニングやらの未知の領域。
個人的には全く無知だし難易度高そうだなあ、、、と思いつつ、個人的にもそろそろ気になっていたのでこの手法を模索してみることにした。
機械学習による感情分析について調べる
ゆるふわな知識しか無いところから、「Sentiment Analysis」というワードを頼りに更に調査を進めると、だいたい下記のような事が見えてきた。
-
再帰型ニューラルネットワーク(RNN)というのが文章などを扱うにはよさそうらしい。
-
中でもLSTMというのが精度が良くなりやすいとか。
-
The Unreasonable Effectiveness of Recurrent Neural Networks
- 上記の日本語翻訳された記事
-
-
Sentiment Analysisをしているサンプルもそれなりに見つけられた。
-
Tensorflowを使ったサンプル(github)
- 日本語を文字単位に区切って入力としている。
- 良さそうだったが、ちょっと自由に操るのは難しそうだった。
-
Chainerのサンプル(github)
- 英文を係り受け?にしているっぽい。
- 使うには下処理が色々必要そう
- 参考記事
-
Chaninerで文字単位のRNNを行っているサンプル(github)
- これはSentiment Analysisではなく次に来る文章を生成するものっぽい。これも楽しそう
-
- 英文の映画レビューを判定しているっぽい。
- どこで何やっているのかなんとなくわかる。
- データを作れればなんか動かせそう
- 希望が見えてきた。
-
(ここから本題)LSTMで感情分析を行う
今回は Theanoを使ったサンプル を流用して検証を進める事にする。
(利用にあたってコードリーディングした書き置きを別記事にしたので、興味がある方はそちらを参照)
学習データの特徴とか問題設定とか
学習データの特徴
今回学習データにする転職会議のクチコミデータは、1つのクチコミについて下記のような特徴がある。
-
テキストデータ
- 100文字以上
- 1つの企業のついてのレビュー(今回はあんまり関係しない)
- 1つの質問項目についてのレビュー(今回はあんまり関係しない)
-
評点データ
- 会社についての5段階評価
- 1が最も低く、5が最も高い評価
- 星をいくつつけるかで選んでもらうよくあるアレ
問題設定
ここまでの結果を踏まえ、改めて下記のように問題設定をする。
書き込まれたクチコミの文章が、ポジティブであるかネガティブであるかを判定できるモデルを作る
本来であればデータにあわせて5段階評価まで目指したいものの、まあやっぱり難易度が高そうなので、今回は見送り。
あと今回はざっくり感覚に基づいてやってみるので、評点が低く付くような文章が「ネガティブ」、高く付くような文章が「ポジティブ」であるというような前提・仮定をして進める。
データの準備
データの下処理として、だいたいこんな感じで準備を進めていく
- 入力は1文字ずつを辞書の数値化したものを利用
- 例:) いい会社 ->
[1,1,2,3]
- 例:) いい会社 ->
- サンプルに、1300件ずつ、評点が1(ネガティブ)、5(ポジティブ)であるクチコミを準備。
- ネガティブを0、ポジティブを1として再ラベリング
-
データ読み込みのスクリプトを修正して独自のデータが読み込めるように調整
- このスクリプト側で学習データを、訓練用と検証用に分割してくれたりする。
- 学習データと同様に、テストデータも用意。
- 今回のスクリプトでは、テストデータは、学習から完全に独立して、誤差測定にのみ利用される。
とりあえずサンプル的に動かしてみる。
データの準備ができたら動かす。
デフォルトだと結構時間がかかるので、適度に隠れ層の数などを調整するほうが良さそうだった。
簡易スクリプトで試す
しばらく待ってモデルが構築されたら、ひとまず簡易なワードを投げてうまく行ってそうか動かしてみる。
学習スクリプトの400行目あたりのpred_probs()を見ると 「学習済みのモデルで検証したかったらこれ参考にすると良いよ」的な事が書いてあるので、これを参考にちょっとしたスクリプトで検証。
model = numpy.load("lstm_model.npz")
tparams = lstm.init_tparams(model)
(use_noise, x, mask, y, f_pred_prob, f_pred, cost) = lstm.build_model(tparams,
# このへんのoptions投げないとKeyErrorになってしまう。
'encoder': 'lstm',
'dim_proj': 128,
'use_dropout': True,
})
# 最低限に簡略化
def pred_probs(f_pred_prob, sentence):
probs = numpy.zeros((1, 2)).astype(config.floatX)
x, mask, _y = imdb.prepare_data([sentence],
1, # dummy。利用されないので適当に。
maxlen=None)
return f_pred_prob(x, mask)[0]
# それぞれ文字列を数値化した入力
sentences = [
{
"data": [27, 72, 104, 150, 19, 8, 106, 23],
"text": "とても良い会社だ"
},
{
"data": [27, 72, 104, 402, 121, 73, 8, 106, 23],
"text": "とても最悪な会社だ"
}
]
for sentence in sentences:
result = pred_probs(f_pred_prob, sentence["data"])
print "==="
print result
print sentence["text"], ("is positive" if (result[0] < result[1]) else "is negative")
実行
% python sample.py
===
input: とても良い会社だ => [27, 72, 104, 150, 19, 8, 106, 23]
output: [ 0.06803907 0.93196093]
とても良い会社だ is positive
===
input: とても最悪な会社だ => [27, 72, 104, 402, 121, 73, 8, 106, 23]
output: [ 0.73581125 0.26418875]
とても最悪な会社だ is negative
なんかそれっぽく出てきた。すごい。
出力はLSTMを通した結果で、それぞれのクラスである確率が返ってきているらしい。
いけそうな感触が出てきたので、更に検証を進める。
試験結果
色々パラメータをいじりつつ、実行結果を細かく見てみる。
とりあえず今回はそれなりに良さそうな結果になったdim_proj=8(隠れ層)、validFreq=30(検証頻度)の結果。
エラー率の推移
今回実行したスクリプトは、検証用データとテストデータのエラーの遷移を記録している。
だいたいこんな推移らしい。
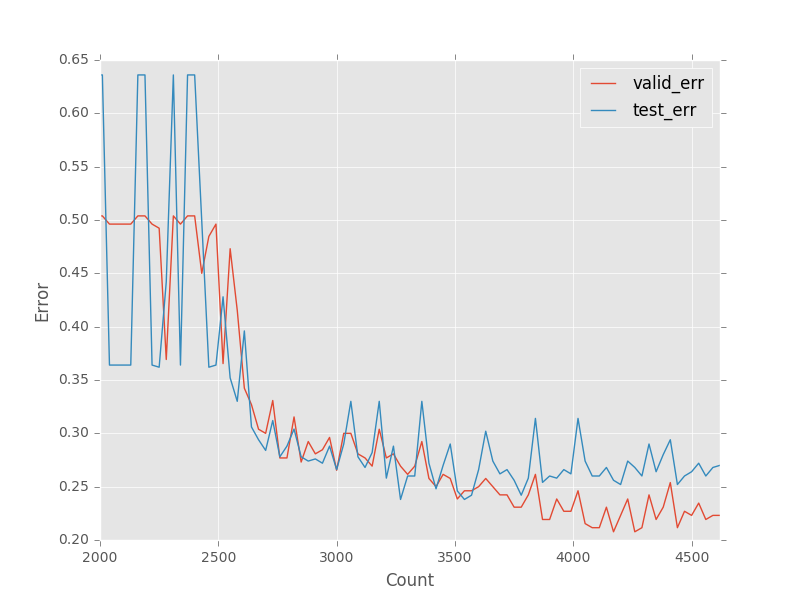
検証データを終える2600 updateを超えたあたりで1エポックを終えるので、その後から誤差が縮んでいる様子が見える。
また、訓練スクリプトの中で、Early stoppingをしてくれているので、過剰適合が起きる前で適度に止まってくれている様子も伺える。
Testデータの結果分析
検証では、最終的にテストデータのエラー率は0.2〜0.3程度ということなので、だいたい正答率7〜8割が期待できる。
本当にそうなっているか、それぞれTestとして利用したデータの中を見てみる。
評点と感情分類の分布を見る
先ほど利用したnegaposi.pyを拡張して、テストサンプルをnegative / positveで分類をし、それぞれの分布を出すとこんな感じ
| 評点 | negative(%) | positive(%) |
|---|---|---|
| ★1つのクチコミ | 84.34 | 15.66 |
| ★2つのクチコミ | 66.53 | 33.47 |
| ★3つのクチコミ | 45.07 | 54.93 |
| ★4つのクチコミ | 25.77 | 74.23 |
| ★5つのクチコミ | 27.59 | 72.41 |
だいたいこんな事が見て取れる
- 所感:割りと良さそう
- ★1、★5でだいたい正答率70%~80%。やはり結果とも大きくは相違無さそう。
- テスト時には除外していた★4、★2もそれなりに妥当な数値になっている。
- ★3が五分五分に近い数値になっているのちょっと興味深い。
- ちょっと中身をじっくり見ると何か気づきがありそう
検証結果を受けて
-
結果:まあ成功ぐらいな感じ
- 大成功!とまではいかないまでも、もうちょっとがんばれば使えるものになりそう。
- 結構実用化も夢ではなさそう
-
さっくりやっただけの割にここまで来れた。LSTMすごい!
- 正直係り受け頑張ってここまで辿りつけたかというとあんまり自信無い
-
精度をもうちょっとあげることを考えたらこのへん出来そう
- 年代や、業界などの情報を絞ったら精度が上がらないか?
- 隠れ層などパラメータをもっと調整?
- データ量がまだ少ない?もう少し待つ?