興味深い記事があったので備忘録の意味も込めて、翻訳しました。
間違いが多々あるかもしれませんが、その点はご容赦を
内容は要約なので、詳しい内容を知りたい方は元記事をご覧下さい。
元記事
コード
Recurrent Neural Networks
Recurrent Neural Networksは何がすごいか?
通常は固定長のベクトルの入力と固定長の出力のベクトルのみだった。
Recurrent Neural Networksはその制限が外れている点が優れている。
下記の例のように
左から(1)〜(5)とすると
(1):Recurrent Neural Networksがないので固定長の入力と出力
(2):連続された出力(画像から文字列出力など)
(3):連続された入力(翻訳:複数の英文入力からフランス語への翻訳など)
(4):連続された入力と出力(ビデオを入力とし、出力がラベル付けされたビデオなど)
(5):同期された連続入力と出力(ビデオを入力として、どのフレームが対応しているかなど)
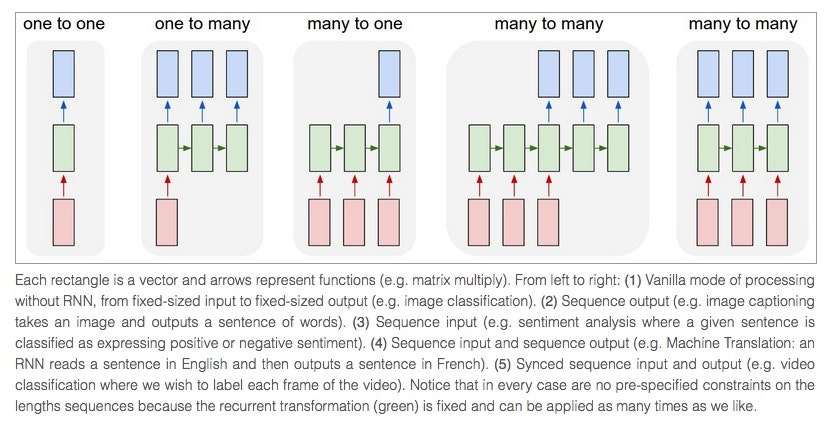
連続操作はすごくパワフルで固定されたネットワークが消える運命にあるくらい。
RNNは入力ベクトル、状態ベクトル、固定関数を用いて新しい状態ベクトルを生成する。
RNNのプラオグラムは理想的なプログラムであることは下記の論文をみれば分る。
http://binds.cs.umass.edu/papers/1995_Siegelmann_Science.pdf
連続的な入力もしくは出力は比較的レアである。しかし、もし固定長の入力と出力しか得られなくてもこのパワフルな手法を使うことは可能である。
下記の論文では具体的な手法を述べている
家の番号を左から右へ読む
画像生成(
Google ではDeep Learningが使える人を募集しているみたいです。

単純なAPIを公開しくれてるみたいです。
入力ベクトル$x$を与えると出力を得られる!!
あなたが入力した値だけでなく、過去に入力した全体の値も考慮された値が得られる
luaという言語で記述されている
著者は初めてみました
rnn = RNN()
y = rnn.step(x) # x is an input vector, y is the RNN's output vector
RNNは毎stepごとに更新されます。
単一の隠れ層で構成されているので、下記でstep関数の中身を変更することも可能です。
class RNN:
# ...
def step(self, x):
# update the hidden state
self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x))
# compute the output vector
y = np.dot(self.W_hy, self.h)
return y
上記の例の場合、
RNNのパラメーターは三つの行列で$W_hh$,$W_xh$,$W_hy$
隠れ状態は$self.h$で0ベクトルで初期化されている。
$np.tanh$関数は非線形で−1から1のレンジで活性化関数として実装されている。
2つの項からなるが一つは過去の入力、一つは現在の入力である。
np.dotは行列計算の関数である。
行列の足し算を計算し、ハイパボリックタンジェント空間に写像している。
$h_{t+1} = tanh(W_{hh}h_t + W_{xh}x_t )$
初期はRNNはランダムな数字で初期化し、損失関数を計測しながら理想的な出力Yを学習し続ける。また連続的な入力の反応を見ながら探索できる。
DeepなRNNを作成したい場合は下記のように行なう。
例として2層のRNNを示す。
y1 = rnn1.step(x)
y = rnn2.step(y1)
最初のRNNで出力された結果を次のRNNに入力する。
もっと良くRNNが働く機能としてLSTM(Long Short Term Memory)がある。
Character-Level Language Models
ここからお持ちかねのCharacter-Level Language Modelの説明である。
大きな文字の固まりを用意し、次の文字の確率分散モデルを過去の連続文字列から取得する。
次に生成される文字列は同時である。
例として”hello”をRNNで学習する場合を考える。
1:"h"を入力として与えた場合:"e"が出力
2:"he"を入力として与えた場合:"l"が出力
3:"hel"を入力として与えた場合:"l"が出力
4:"hell"を入力として与えた場合:"o"が出力
1 of kエンコードにより文字をベクトルで表している
[h e l l o]→[1 1 1 1 1]
[h ]→[1 0 0 0 0]
[ e ]→[0 1 0 0 0]
出力は4次元の出力となる。
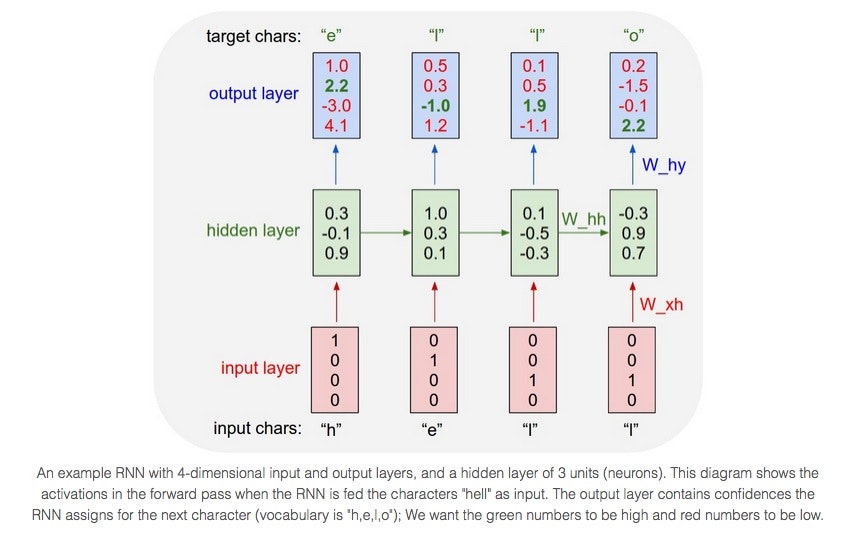
"h"が入力された場合、"h":1.0, "e":2.2, "l":-3.0, "o":4.1
が出力される。
理想は緑が最も高いスコアを出力し、赤が低いスコアを出すことである。
"h"が入力された場合は"e"が出力されて欲しいので緑に塗られている。
一般的なアプローチはクロスエントロピーを損失関数に用いた手法である。
損失は誤差伝搬法とRNNの重みを更新することで次の文字列が入力似たような文字列でも適用できる。
安定的な更新は下記の論文の技術が使用されている。
http://arxiv.org/abs/1502.04390
RNNが力を発揮するのは今回の場合は最初に"l"が出た時は次は"l"を予測して欲しいが2回目の"l"が出現した時は"o"を出力して欲しい場合にリカレントなコネクションを用いれるのでこのような場合でも対応出来る。
今まで記した魅力的なRNNの仕組みを用いて、
Shakespeare
Wikipedia
Algebraic Geometry (Latex)
Linux Source Code
などに元記事ではチャレンジされています。
興味を持った方は是非、下の記事をご参照下さい!!!