はじめに
今更感満載ですが・・・

↑ ↑ ↑ このマリオ君が

↑ ↑ ↑ こうなるように頑張った話!
Gitは以下。環境構築の流れとかも以下を参照。
開発環境
プラットフォームとか
- Hyper-V
- Ubuntu18
- Anaconda
- Python3.8
- Tensorflow2.2.0など、Pythonライブラリ色々
(envs/conda_env.yaml参照)
エミュレータ
- FCEUX 2.2.2
開発環境以外の動作確認済み環境
GPU on WSL2環境
- WSL2
- Ubuntu20
- GPU環境 (cuda toolkit 10.2)
- それより上のレイヤは開発環境と同様
⇒ 学習がCPUよりとても速かった。
あと、WSLなのでHyper-Vより軽量。
ここの詳細はメインとは逸れるので、末尾に記載。
マリオが動くまで
AnacondaとエミュレータであるFCEUX 2.2.2の環境構築は終わっているものとする。(この辺の情報はネットに溢れていた。)
マリオを動かすために、OpenAI Gymというものを使わせて頂いた。
強化学習シミュレーション用のプラットフォームで、色んなコンテンツの強化学習が簡単にシミュレーションできる。
pip install gym
そしてマリオのシミュレーション環境は、神のような以下のライブラリを用いた。
これがなければ、私は何もできなかった。。。
マリオを動かすために自分でやったことと言えば、これをgit cloneして、配置してimportしただけである。
git clone https://github.com/ppaquette/gym-super-mario
cp ./gym-super-mario/ppaquette_gym_super_mario /配置したい/ディレクトリ
import gym
import ppaquette_gym_super_mario
env = gym.make('ppaquette/SuperMarioBros-1-1-Tiles-v0') # ここでマリオの環境・エミュレータが起動
env.reset()
obs, reward, is_finished, info = env.step([0, 0, 0, 1, 0, 1]) # マリオが引数で示唆されたアクションを行う
env.close() # マリオの環境・エミュレータが終了
DQNアルゴリズム
今回マリオをクリアさせるにあたって、DQN(Deep Q Network)という機械学習アルゴリズムを用いた。
機械学習においては色んな所で使われているとても有名なアルゴリズムだ。
以下の記事がめちゃくちゃ分かりやすかった。
まあ正直これを読めばほとんど理解できると思う。
たぶんおそらくたぶん要するに、
- 状態 (今回はマリオのゲーム画面全体)
- 行動 (今回はプレイヤーのボタン操作によるマリオの行動(Bダッシュ!!など))
- 報酬 (今回はマリオが右に進めば+、敵に当たって死ぬと-など)
等々その他諸々、みたいな要素があって、
1回のプレイで得られる報酬を最大にするようなマリオの行動の組み合わせをニューラルネットワークを使って予測できるようにしよう、というもの。
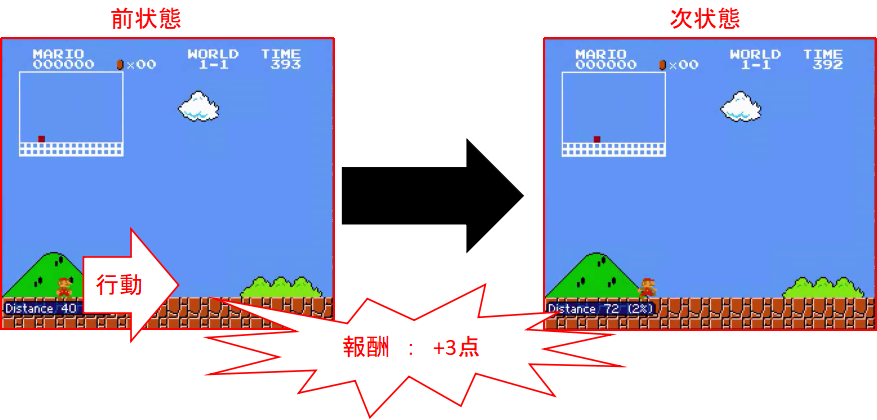
で、今今の行動で得た報酬だけ分かってても、その行動によって入ったルート全体で得られる報酬って分からないよね・・・
っていうので、「今回の報酬」+「その行動により将来期待できそうな報酬のなんやかんや」を含めた行動価値というのを求める必要がある。
(例えばマリオがクリボーに当たる直前、全力Bダッシュをしていればその時の報酬は最大になるが、そのルートは将来クリボーに当たって死ぬルートなので、結果的に全体で得られる報酬は少ない。つまり行動価値は少ない。)
行動価値が最大になる行動をとり続けていれば、報酬も最大になるよね、っていう考え方。だと思う多分。
それでどう学習していくかというと、
今回の行動価値 = 今回得られた報酬 + 割引率 \times max(次状態での各行動により得られる行動価値のリスト)
行動価値 = 前回までの行動価値 + 学習率 × (今回の行動価値 - 前回までの行動価値)
みたいな感じで、よくあるような学習率αによって行動価値を更新していく形になる。
max(次状態での各行動により得られる行動価値のリスト)の部分は、次状態での最も良い行動をしたときの行動価値を表していることになる。
行動価値の計算にこの次状態の最大の行動価値が含まれることにより、再帰的に将来得られる行動価値を知ることができる。
また割引率は0~1で設定し、これを掛けることはつまり「直近の行動であればあるほど、その行動価値は現時点の行動価値に相関している」みたいなことを表している。
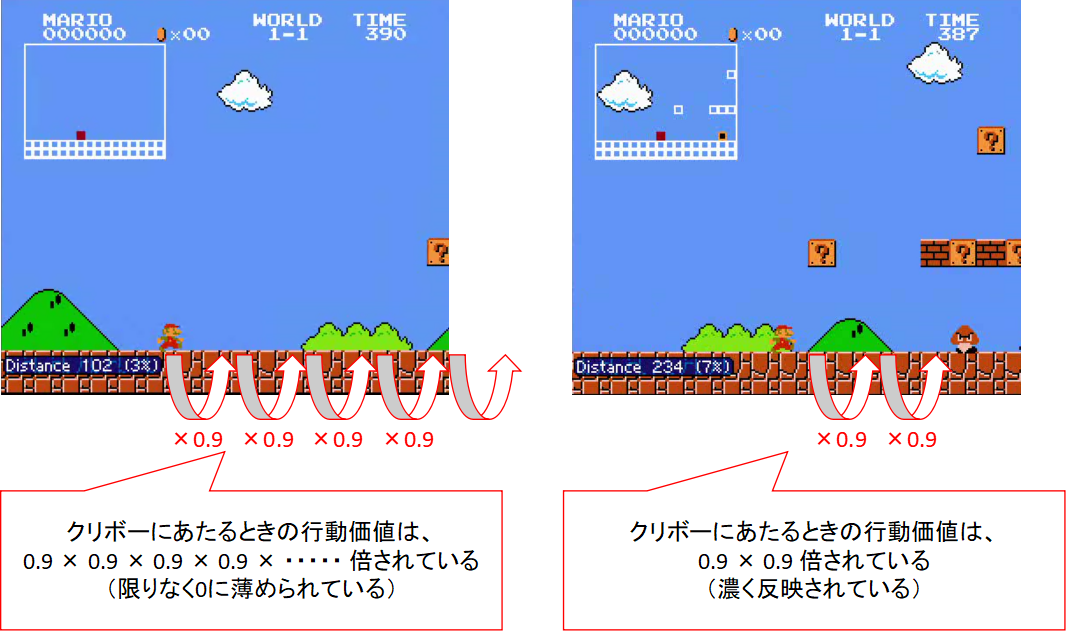
割引率 × 次状態の最大の行動価値の仕組みにより、マリオがクリボーの直前までBダッシュを続け、クリボーの直前になると他の行動に移す、という仕組みが実現できる。
上の式では、「次状態の行動価値」やら、「前回までの行動価値」などが登場するが、一体この「行動価値」はどこにあるのか?
そもそも、この学習をCNNを用いずに行う従来からのやり方を「Q-Learning」という。
Q-tableというテーブルに、「状態」と「行動」を行列にしたすべての行動価値の値が保存されており、そのテーブルの値を参照して学習を進めていくというものである。
状態・行動の数が少ない10×10マスの迷路とかであれば、この方法で良いかもしれないが、スーパーマリオのようにほぼ無限に状態・行動があるコンテンツでは、この方法は不可能である。
そのため行動価値をテーブルで管理するのではなく、ディープラーニングによる学習&推論で行うやり方がDQNである。
今回のような場合は、
- 入力:状態(ゲームの画像)
- 出力:各行動によって得られる行動価値
としたCNN(畳み込みニューラルネットワーク)となる。

ちなみに、DQNの中でも色々な最適化アプローチがあるが、今回は
- ε-グリーディ法
- Fixed Target Q-Network
を採用した。
ぼやき
DQNの前に、GA(遺伝的アルゴリズム)を用いた実装も行った。
GAではマリオが適当な個所で無駄なジャンプをしながらゴールするのに対し、DQNではマリオが必要なときのみジャンプしながらゴールするようになる。
大まかな流れ
if __name__ == '__main__' :
# --- ニューラルネットワークの前回保存済みモデル、または今回保存モデル名を引数で取得する
args = sys.argv
if 2 <= len(args):
filename = args[1]
else:
filename = None
action_list = [
[0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0],
[0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 1, 1],
[0, 1, 0, 0, 1, 0],
[0, 1, 0, 0, 0, 1],
[0, 1, 0, 0, 1, 1],
[0, 0, 0, 1, 1, 0],
[0, 0, 0, 1, 0, 1],
[0, 0, 0, 1, 1, 1],
]
action_map = [
# [i, j] for i in range(len(action_list)) for j in range(len(action_list))
[i] for i in range(len(action_list))
]
network = DqnNetwork(
y_size = len(action_map)
)
if filename != None and os.path.exists("./saved_networks/" + filename):
# --- 前回保存済みモデルを読み込む
network.model = keras.models.load_model("./saved_networks/" + filename, custom_objects={"create_custom_loss": network.create_custom_loss})
print ("Successfully loaded")
else:
# --- 新たにニューラルネットワークを作成する
if filename is None:
filename = 'model'
network.create_network()
print ("Could not find old network weights")
agent = Agent(
mario_course = 'ppaquette/SuperMarioBros-1-1-Tiles-v0', # マリオが学習するコース
loop_count = 30000, # 繰り返すエピソード数
init_randam_num = 1, # ランダムに行動させる初期エピソード数
greedy_rate = 0.002, # greedy率
extreme_greedy_rate = 0.005, # 超greedy率
extreme_greedy_interval = 10000, # 超greedyを行う間隔
extreme_greedy_count = 500, # 超greedyを行うアクション数
discount_rate = 0.9, # 次状態の割引率
frame_per_action = 6, # 同一アクションを繰り返すフレーム数
model_sync_interval = 640, # Target Networkを、Q Networkに同期するアクション間隔
batch_size = 64, # 一度に学習するサイズ
epoch = 10, # 一度の学習のエポック数
filename = filename, # ロード・保存するファイル名
action_list = action_list, # マリオがとりうるアクションをまとめたリスト
action_map = action_map, # 上記アクションリストの組み合わせを定義したリスト
network = network
)
agent.play()
上記がmain処理。
-
action_list(マリオがとりうる行動のリスト)を定義する。
[up, left, down, right, A, B]で定義される、各ボタンに対応した行動を表すリストとなっている。
ボタンが押されているところが「1」、押されていないところが「0」となり、例えばBダッシュなら[0, 0, 0, 1, 0, 1]となる。 -
引数で、モデル名指定があるかどうか判定する。
-
ある場合
保存済みモデルフォルダに指定モデルがあれば、モデルをロードする。 -
ない場合
create_networkに従って、ネットワークを作成する。
-
-
Agentにパラメータを設定し、ゲーム&学習を開始させる。
ちなみに、カスタマイズを想定したパラメータは以下。パラメータ 説明 mario_course プレイしたいコース名を指定。ppaquette/gym-super-marioのライブラリを参照。 loop_count 何エピソード行うか。 init_random_num マリオがとる行動の選択を、行動価値が最大のものではなく、完全にランダムにする最初のエピソード数。 greedy_rate ε-グリーディ法のためのパラメータ。1回の行動の選択において、どれくらいの確率でランダムに行動するかという確率。 extreme_greedy_rate 恒久的なgreedy_rateとは別に、一時的にランダム性を高くしたいときのパラメータ。 extreme_greedy_interval 何アクション間で、extreme_greedy_rateを適用するかのパラメータ。 extreme_greedy_count extreme_greedy_rateが始まったとき、何アクション続けるかのパラメータ。 discount_rate 割引率。 frame_per_action 1回のアクションを何フレーム続けて行うかのパラメータ。ここで指定したフレーム数のまとまりで、状態・報酬などを区別する。 model_sync_interval Fixed Target Q-Networkのためのパラメータ。Target Networkを、Q Networkに同期するアクション間隔。 batch_size 何アクションしたら学習するかを表すパラメータ。 epoch 一回の学習のエポック数。
agent.playの大まかな流れは以下。(長いのでめちゃくち省略している。)
def play(self):
...
# --- マリオスタート、エピソード数繰り返す
for episode in range(self.loop_count):
env = gym.make(self.mario_course)
env.reset()
...
# --- ゲーム終了までアクション、学習を繰り返す
while not is_finished:
...
for index, action in enumerate(action_set):
for i in range(0, self.frame_per_action):
# --- 行動を起こす
obs, reward, is_finished, info = env.step(self.action_list[action])
# --- 報酬を計算する
reward, trunked_info = self.calc_reward(reward, is_finished, info, trunked_info)
total_reward += reward
...
# --- 次状態の行動価値を、ニューラルネットワークから計算する
next_values = main_model.predict(np.reshape(obs, tuple([1]) + resized_screen_size))[0]
next_target_values = target_model.predict(np.reshape(obs, tuple([1]) + resized_screen_size))[0]
...
# --- 次の行動パターンを決める
if random.random() < greedy_rate:
next_action_index = random.randint(0, self.action_list_len-1)
else :
next_action_index = np.argmax(next_values)
# --- 現在の状態の行動価値を計算する
if is_finished:
value = total_reward
else:
value = np.max(next_target_values)
value = total_reward + self.discount_rate * value
...
# --- 学習サイズごとに学習を行う
if loop_i == self.batch_size:
actions = np.reshape(actions, (-1, self.action_list_len))
screens = np.reshape(screens, tuple([-1]) + resized_screen_size)
history = main_model.fit(screens, actions, epochs=self.epoch)
actions, screens = np.empty(0), np.empty(0)
loop_i = 0
...
env.close()
main_model.save('./saved_networks/' + self.filename)
...
「行動を起こす」とコメントで記載されている部分
obs, reward, is_finished, info = env.step(self.action_list[action])
のところで、引数にアクションを渡し、マリオがそのアクションをした結果を取得している。
結果として取得できるものは、以下の情報となっている。
- obs : マリオが行動したことにより得られる状態(変化後の画面)
- reward : マリオのその行動により得られる報酬
- is_finished : ゲームが終わったかどうかの真偽値(マリオが死んだ or ゴールしたら、True)
- info : その他色々な情報
その他の流れは、DQNの説明に対応しており、
- CNNでの次状態の行動価値の推論
- 次の行動の判定
- 現在の行動価値の計算
- 学習
のような流れで処理を行っている。
「やっとのことで」ポイント
実はマリオがなかなかクリアしてくれなくて、最適なパラメータだったり、良い実装を見つけたりするのに時間がめちゃくちゃかかった。
飽きて放置したり急に再熱したりしながら、もがいてもがいて、やっとゴールした感じ。
どういうことに躓いたのかということや、気づきのポイントを備忘録としてまとめていく。
入力画像
env = gym.make("ppaquette/SuperMarioBros-1-1-v0")
ppaquette/gym-super-marioで選べるコースには、「ppaquette/SuperMarioBros-1-1-v0」のようなものと、「ppaquette/SuperMarioBros-1-1-Tiles-v0」のようなものがある。(Tilesが付いていないか、いるかの違い)
1-1がコースを表しているので、ここを1-2とか8-1とかすると任意のコースをプレイできるわけだが、コースの数だけTilesが付いているものと付いていないものがそれぞれある。
obs, reward, is_finished, info = env.step(取りたい行動)
上記を行ったとき、obsにその行動をしたことによる状態(画面全体)が返ってくる。
ここで、Tilesが付いていないものを設定していた場合、obsには私たちが見ているような普通のマリオの画面全体が返ってくる。(256 * 224 * 3の画像データ)
一方、Tilesを付けると、下記のような必要な情報のみに簡略化された「13 * 16 * 1」のサイズの画像データが返ってくる。

最終的に私がゴールできたのは、Tilesがあるバージョンのコースだったが、それに辿り着くまではTilesがあるものは情報不足なのではないか、いやでもTilesがないものは情報過多なのではないか、などという懸念が右往左往しシミュレーションでも行ったり来たりを繰り返していた。
Tilesがない方を使うとすると
- 私の貧弱なPCでは時間がかかりすぎる
- 雲とか木とか(そもそもRGBカラーとか)余計な情報が多すぎる
という結論になり、何かしら加工する必要性があると思い、下記のようなものを組み込んだ。
def image_processor(self, img):
new_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
new_img = cv2.resize(new_img, tuple(list(resized_screen_size)[0:-1]), interpolation=cv2.INTER_LINEAR)
new_img = np.reshape(new_img, resized_screen_size)
return new_img
画像を加工できるようにし、例えばこの中ではグレースケール化&縮小を行っている。
この措置により、学習効率アップにつながり、それまででは最も良いマリオ君が出来上がったが、Tilesがないバージョンでは結局ゴールはできずに終わった。
このサイズの入力に対する最適なハイパラメータが見つかれば、多分クリアできた。
何にせよ元画像においては、マリオをサクサク動かしながら学習したいのであれば、ハイスペックPCでない限り何かしらの加工が必要そうだ。
結果的にはTilesがある方が、サイズが小さく学習効率も良く、クリアできた。
ただ、複雑なコースとかになると難しいかも。画素数も少なすぎるし。
CNN
def create_custom_loss(self, y_true, y_pred):
y_true = tf.where(y_true != np.inf, y_true, y_pred)
return kb.mean((y_pred - y_true) ** 2)
def create_network(self):
initializer = TruncatedNormal(stddev=0.01)
model = Sequential()
model.add(Conv2D(64, kernel_size=(3, 3), strides=1, padding='same', activation='relu', input_shape=resized_screen_size, use_bias=True, kernel_initializer=initializer, bias_initializer=initializer))
model.add(MaxPooling2D(2))
model.add(Flatten())
model.add(Dense(self.y_size, use_bias=True, kernel_initializer=initializer, bias_initializer=initializer))
model.compile(optimizer='adam', loss=self.create_custom_loss, metrics=["accuracy"])
self.model = model
CNNを構成している部分。
「13 * 16 * 1」の入力画像では、このネットワーク構成が最適だった。
畳み込み層 + プーリング層畳 + 全結合層。
すごくシンプルだが、画像サイズが小さいのもあるのか、これで良かった。いやむしろこれしか良くなかった。
最初は何層も重ねたり、隠れ層も増やしたりしてたのだが、一向に成果が出なかった。
そこで、思い切ってシンプル化してみたら良かった。ん~、よく分からない。
であと、最初kernel_sizeを偶数にしていたのと、stridesを2とか3とかで設定していた。
これを改善し、kernel_sizeを奇数に、stridesを1にすると抜群に性能が向上した。
機械学習に精通している人にとっては当たり前?なのか分からないが
- kernel_sizeは奇数が良い(カーネルサイズ領域の「中央」の特徴を活かすため)
- stridesはあまり使わない(オブジェクトが小さい画像では、特徴を取りこぼす可能性があるため)
っぽい。
ちなみにcreate_custom_lossは、今回選択した行動でないもの全て(np.infに設定している)については学習前のものと同じ値を設定することで、今回選択した行動の行動価値のみが更新されていくようにしている。
もっと良いやり方をどこかの記事で見た気がする。
多分、これはあまり良い方法ではない。
ランダム性
init_randam_num = 1, # ランダムに行動させる初期エピソード数
greedy_rate = 0.002, # greedy率
extreme_greedy_rate = 0.005, # 超greedy率
extreme_greedy_interval = 10000, # 超greedyを行う間隔
extreme_greedy_count = 500, # 超greedyを行うアクション数
ランダムに関するパラメータや実装方法についてもあれこれ試行錯誤した。
これらは次の行動の選択を、常に最適な行動価値に基づいて行うのではなく、たまにはランダムで選んでみようというものである。
そうすることにより、局所的な状況に陥らずより良いルートを見つけることが可能になる。
貪欲(greedy)に探索を行うため、greedy法と呼ばれる。
ランダム選択を適用する確率をここで設定しており、色々試した結果、最終的にこれらの値が最適だと落ち着いた。
マリオの自動クリア関連のとある記事では、greedy率が0.05~0.1と高い値を持っていたりとか、高い値から学習が進むごとにだんだん減少していく実装方法とかにしており、最初はそれを参考にしていた。
でそれをもとにシミュレーションしていたところ、しばらくするとマリオが何十回かに一回クリアするようになった。
そこでそのクリアしたモデルを用いて、今度はgreedy率を0に設定して実行してみると、急に最初のクリボーで死ぬようになった。
そのときに気がついた。
皆さんはスーパーマリオの1-1で、Bダッシュしながら適当にそれっぽいところでAを押してたらクリアできていた、なんてことないだろうか?
私は結構あるのだが、それと同じことが起きていると思った。
要するに、例えどんなにパラメータが悪くて、出来が良くないDQNだったとしても、右に行くと高い報酬がもらえるわけだからBダッシュが一番いいよね、っていうぐらいの知能は持てる。
クリボーを飛び越える知能のないBダッシュ大好きマリオ君に、時々ランダムで行動を選択させれば、障害物を上手いこと偶然乗り越え、ゴールしてくれるマリオ君が出来上がるわけだ。
100アクションのうち1回のランダム判定とかになれば、そんな偶然は起こりえないのだろうが、10アクション、20アクションに1回程度のランダム判定であれば、たかが1-1ならクリアできてもおかしくない。
つまり、ランダムでクリアに向かっているのと同等である。
これは私たちが目指しているAIではない。むしろどっちかというとGAに近い。
私たちが目指しているAIは、最終的にはランダム率0のときにクリアし、更に1-1以上に難しいステージに出くわしても、クリアできるマリオだ。
ということで、greedy率は局所的な状態から抜け出すために必要なものだけど、それに頼りすぎると変なことになっちゃうよね、というお話。
最初はこの状況で、「クリアした!」と発狂しそうになったので反省のための備忘録。
続いて、extreme_greedy_rateというものを作っているが、勝手に超greedy法と名付けた。
マリオが障害物にはまって、なかなか飛び越えず時間だけが経過して腹立たしいことがある。
DQNだと、障害物にはまって止まっていると、ゆっくりではあるが「何もしない」という行動の行動価値が減少していくので、いつかは違う行動をしてくれるのだが、それでもなかなか飛び越えないときとかがある。
こういうときは、ランダムな行動に頼って一回飛び越えるルートに入ってみてほしい、と思うときがある。
単純にgreedy_rateを少し上げるのみでいいのでは?となるかもしれないが、greedy_rateを上げるとその分最適な行動を選ぶ回数も少なくなり、コースのほとんどの学習が終わっていたとしてもランダムな行動が邪魔して、コースの途中で変な行動をしてリタイアしてしまうようになる。
そのため、局所的にランダム性を高くしたいと思って作ったのが超greedy法だ。
この局所的な範囲は設定した等間隔でやってくるため、止まっている時間が長い箇所(障害物で引っかかっている箇所)ほど、このextreme_greedy_rateの局所範囲に被りやすく、ランダム性が高くなる。
最高の解決策だ!!
と思って実装してみたが、全然良くなかった。
まあクリアはしたから悪影響でもないんだろうけど、別に全然良くもない。
閃いた!と舞い上がってたのに、萎えてしまったポイント備忘録。
Fixed Target Q-Network
DQNの最適化アプローチの一つである。
DQNの章で記載した式の通り、今回の報酬 + 次状態の最大の行動価値が教師データになるわけだが、これが1回1回の学習で変わってしまっては、値をどこに近づければよいのかわからなくなる。
そこで、
- Target Networkと、Main Networkの2つのネットワークを用意する
- 次状態の行動価値についてはTarget Networkから取得する
- Main Networkを都度学習させていく
- 一定間隔で、Target NetworkをMain Networkと同期させる
というようなアプローチがとられる。
Target Networkは安定させとこう(=教師データを安定させる)ということだ。
これに似たアプローチにDDQN(Double DQN)というものもあり、そっちのほうが使われているかもしれない。
これらが必須だったとは知らず、これを導入してから大幅に良くなった。
マリオがあっち行ったりこっち行ったりするような、迷ってるような行動がなくなった。
def clone_model(self):
config = {
'class_name': self.model.__class__.__name__,
'config': self.model.get_config(),
}
clone = keras.models.model_from_config(config, custom_objects={"create_custom_loss": self.create_custom_loss})
clone.set_weights(self.model.get_weights())
return clone
上記関数は、2つのネットワークを同期させるために、モデルをクローンする関数である。
def play(self):
...
next_values = main_model.predict(np.reshape(obs, tuple([1]) + resized_screen_size))[0]
next_target_values = target_model.predict(np.reshape(obs, tuple([1]) + resized_screen_size))[0]
...
if model_update_i >= self.model_sync_interval:
target_model = self.network.clone_model()
print("model synced.")
model_update_i = 0
...
先ほど述べたことを上記のようにして実現している。
繰り返しになるが、このアプローチは必須だと思っている。
改良版がとても良い!
ちょっと閃いて改良したバージョンがとても良かった。
以下のような感じ。
| 初回ゴールまでの エピソード数 |
安定してゴールするまでの エピソード数 |
|
|---|---|---|
| 改良前 | 1254 | 34000くらい |
| 改良後 | 301 | 2800くらい |
←←←改良前 改良後→→→

ちょっと改良前より無駄なジャンプが増えてそうだけど、あまり動作は変わってないのに、マリオが学習するペースが早くていい感じ。
どう改良したか
結論から言うと、2個のアクションの組み合わせを1まとまりの行動価値として学習した。
なぜかというと、そのほうが人間が本来マリオをプレイするやり方に近いと思ったから。
例えば私たちがマリオをプレイする際、土管をBダッシュ+Aジャンプで超えた後、そのまま同じボタン(Aボタン含む)を押しっぱなしにしてると、マリオはただただ右に走っていく。
Aボタンを押しっぱなしだからといって再びジャンプしようとはしない。
しかし実際私たちは、次のジャンプに備えるため、ジャンプ中かもしくは次の土管の手前ではAボタンのみから指を離す。
そのおかげで次の土管でもスムーズにジャンプすることができる。
しかしこのDQNの場合、マリオは土管を飛び越えた後、次に備えるためにAボタンから指を離すほうがよいと判断できるだろうか?
結局クリアしているので、判断していることになるが、学習に長い時間がかかるような気がしている。
なぜなら、Aボタンを離そうが離さまいが報酬や状態(画面)は全く変わらないからだ。
CNNは時系列データを持たないので、直前の状態や行動がどうだったかなんていうのは全く相関しない。
このためBダッシュ+Aジャンプという全く同一の行動で、さっきのマリオは土管を飛び越え高い報酬を貰ったけど、今回のマリオは(前状態からAが押しっぱなしだったため)土管を飛び越えれず高い報酬を貰えなかったという事象が発生し、行動価値が収束しないケースがある。
そうなると学習に時間がかかってしまうということがありそうだ。
この解決策として、2つの行動を時系列に組み合わせ、それにより得られた報酬の合計で行動価値を求めればよい。
そうすれば、Bダッシュ+Aジャンプで土管を飛び越えた直後にもう一つ土管があるときの最も良い行動の組み合わせは、「①Bダッシュのみ」(ここでAボタン離している)と「②Bダッシュ+Aボタン」の行動の組み合わせだとすぐに分かる。
action_list = [
[0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0],
[0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 1, 1],
[0, 1, 0, 0, 1, 0],
[0, 1, 0, 0, 0, 1],
[0, 1, 0, 0, 1, 1],
[0, 0, 0, 1, 1, 0],
[0, 0, 0, 1, 0, 1],
[0, 0, 0, 1, 1, 1],
]
action_map = [
[i, j] for i in range(len(action_list)) for j in range(len(action_list))
# これが2つの行動の組み合わせ
]
action_set = self.action_map[action_index]
for index, action in enumerate(action_set):
for i in range(0, self.frame_per_action):
# --- 行動を起こす
obs, reward, is_finished, info = env.step(self.action_list[action])
...
上記のように実装できる。
勿論、出力の数がaction_listの長さの二乗になるので、層を増やすなり対策する必要があるかな?と思ったが、意外と大丈夫だった。
この他には、CNN + RNN(Recursive Neural Network)を組み合わせるなどのアプローチもあると思うが、学習が重くなりそうなのでやめといた。
今後試してみたいと思う。
最後に
なんかこういう機械学習って明確な答えがない分、かなり難しい。
まあ多分間違っていることもたくさんあると思うが、クリアしたときはやっぱり感動した。
特に、同じモデルを使って1-2をやってみたところ、3日くらいでクリアするようになってくれていたときは泣きそうになった。(これぞAI感)

他のコースはまだ試してないが、頑張ってチャレンジしてみたい。
皆で競ってみたりとかもしてみたい。
最後までお読み頂き、ありがとうございました。
何か間違い等、発見して頂いた方は、ぜひご指摘のほど、よろしくお願いいたしますm(__)m
蛇足(GPU on WSL2環境について)
下記のページを参考にした。
ソースコード
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from tensorflow.keras.initializers import TruncatedNormal
import tensorflow.keras.backend as kb
import gym
import ppaquette_gym_super_mario
import random
import numpy as np
import os
import cv2
import sys
screen_size = (13, 16, 1)
resized_screen_size = (13, 16, 1)
class Agent:
def __init__(
self,
mario_course = 'ppaquette/SuperMarioBros-1-1-Tiles-v0',
loop_count = 100,
init_randam_num = 10,
greedy_rate = 0.1,
extreme_greedy_rate = 0.1,
extreme_greedy_interval = 1000000,
extreme_greedy_count = 1000,
discount_rate = 0.99,
frame_per_action = 4,
model_sync_interval = 1000,
batch_size = 1,
epoch = 1,
filename = "",
action_list = None,
action_map = None,
network = None,
):
if action_list is None or network is None:
raise Exception('Parameter Error: <action_list> and <model> is required.')
self.mario_course = mario_course # マリオが学習するコース
self.loop_count = loop_count # 繰り返すエピソード数
self.init_randam_num = init_randam_num # ランダムに行動させる初期エピソード数
self.greedy_rate = greedy_rate # greedy率
self.extreme_greedy_rate = extreme_greedy_rate # 超greedy率
self.extreme_greedy_interval = extreme_greedy_interval # 超greedyを行うアクション間隔
self.extreme_greedy_count = extreme_greedy_count # 超greedy探索を行うアクション数
self.discount_rate = discount_rate # 次状態の割引率
self.frame_per_action = frame_per_action # 同一アクションを繰り返すフレーム数
self.model_sync_interval = model_sync_interval # Target Networkを、Q Networkに同期するアクション間隔
self.batch_size = batch_size # 一度に学習するサイズ
self.epoch = epoch # 一度の学習のエポック数
self.filename = filename # ロード・保存するファイル名
self.action_list = action_list # マリオがとりうるアクションをまとめたリスト
self.action_map = action_map if action_map != None else [[i] for i in range(len(action_list))] # 上記アクションリストの組み合わせを定義したリスト
self.network = network
self.action_list_len = len(self.action_map)
# --- 学習しやすいように、入力画像を加工するための関数
def image_processor(self, img):
# new_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# new_img = cv2.resize(new_img, tuple(list(resized_screen_size)[0:-1]), interpolation=cv2.INTER_LINEAR)
# new_img = np.reshape(new_img, resized_screen_size)
# return new_img
return img
# --- 報酬の計算式
def calc_reward(self, reward, is_finished, info, trunked_info):
reward -= 1 # 止まっているだけのときの報酬をマイナスにしたい
if is_finished and info['time'] != 0:
if info['life'] == 0: # マリオが死んだとき
reward -= 100
else: # マリオがクリアしたとき
reward += 300
return reward, trunked_info
def play(self):
main_model = self.network.model
target_model = self.network.clone_model()
extreme_greedy_limit = self.extreme_greedy_interval + self.extreme_greedy_count
loop_i = 1
greedy_i = 1
model_update_i = 1
actions, screens = np.empty(0), np.empty(0)
# --- マリオスタート、エピソード数繰り返す
for episode in range(self.loop_count):
env = gym.make(self.mario_course)
env.reset()
is_finished = False
# --- 1回目の行動をする
obs, reward, is_finished, info = env.step(self.action_list[0])
trunked_info = {'old_distance': info['distance']}
obs = np.reshape(obs, screen_size)
screen = self.image_processor(obs)
action_index = 0
# --- ゲーム終了までアクション、学習を繰り返す
while not is_finished:
# --- 指定したフレームごとに行動を変える
obs_array = np.empty(0)
total_reward = 0
action_set = self.action_map[action_index]
for index, action in enumerate(action_set):
for i in range(0, self.frame_per_action):
# --- 行動を起こす
obs, reward, is_finished, info = env.step(self.action_list[action])
# --- 報酬を計算する
reward, trunked_info = self.calc_reward(reward, is_finished, info, trunked_info)
total_reward += reward
if is_finished:
break
# --- フレーム群の一番最後の観測状態を保存する
if index == len(action_set) -1 or is_finished:
last_obs = np.reshape(obs, screen_size)
last_obs = self.image_processor(last_obs)
if is_finished:
break
obs = last_obs
# --- 次状態の行動価値を、ニューラルネットワークから計算する
next_values = main_model.predict(np.reshape(obs, tuple([1]) + resized_screen_size))[0]
next_target_values = target_model.predict(np.reshape(obs, tuple([1]) + resized_screen_size))[0]
greedy_rate = self.greedy_rate # --- ランダムに行動する確率
if episode < self.init_randam_num:
greedy_rate = 1
elif greedy_i > extreme_greedy_limit:
greedy_i = 0
elif greedy_i > self.extreme_greedy_interval:
greedy_rate = self.extreme_greedy_rate
# --- 次の行動パターンを決める
if random.random() < greedy_rate:
next_action_index = random.randint(0, self.action_list_len-1)
else :
next_action_index = np.argmax(next_values)
# --- 現在の状態の行動価値を計算する
if is_finished:
value = total_reward
else:
value = np.max(next_target_values)
value = total_reward + self.discount_rate * value
# --- 行動(出力)と画面(入力)をリストに保存
action_array = np.full(self.action_list_len, np.inf)
action_array[action_index] = value
actions = np.append(actions, action_array)
screens = np.append(screens, screen)
# --- 学習サイズごとに学習を行う
if loop_i == self.batch_size:
actions = np.reshape(actions, (-1, self.action_list_len))
screens = np.reshape(screens, tuple([-1]) + resized_screen_size)
history = main_model.fit(screens, actions, epochs=self.epoch)
actions, screens = np.empty(0), np.empty(0)
loop_i = 0
if model_update_i >= self.model_sync_interval:
target_model = self.network.clone_model()
print("model synced.")
model_update_i = 0
# --- 現在の状態の保存
old_action_index = action_index
action_index = next_action_index
screen = obs
loop_i += 1
greedy_i += 1
model_update_i += 1
# --- 出力する(ゴールできたときはファイルにも)
if is_finished and info['life'] != 0 and info['time'] != 0:
if not os.path.exists('./goal_logs'):
os.makedirs('goal_logs')
with open(f'./goal_logs/{self.filename}', 'a') as f:
print("episode : " + str(episode), file=f)
print('Episode : ', episode, 'Actions : ', [ self.action_list[i] for i in self.action_map[old_action_index] ], 'Value : ', value, 'Greedy : ', ('{:.3f}'.format(greedy_rate)))
env.close()
main_model.save('./saved_networks/' + self.filename)
actions = np.reshape(actions, (-1, self.action_list_len))
screens = np.reshape(screens, tuple([-1]) + resized_screen_size)
main_model.fit(screens, actions, initial_epoch=0, epochs=self.epoch)
main_model.save('./saved_networks/' + self.filename)
class DqnNetwork:
def __init__(
self,
y_size = 10,
):
self.y_size = y_size
def create_custom_loss(self, y_true, y_pred):
y_true = tf.where(y_true != np.inf, y_true, y_pred)
return kb.mean((y_pred - y_true) ** 2)
def create_network(self):
initializer = TruncatedNormal(stddev=0.01)
model = Sequential()
model.add(Conv2D(64, kernel_size=(3, 3), strides=1, padding='same', activation='relu', input_shape=resized_screen_size, use_bias=True, kernel_initializer=initializer, bias_initializer=initializer))
model.add(MaxPooling2D(2))
model.add(Flatten())
model.add(Dense(self.y_size, use_bias=True, kernel_initializer=initializer, bias_initializer=initializer))
model.compile(optimizer='adam', loss=self.create_custom_loss, metrics=["accuracy"])
self.model = model
def clone_model(self):
config = {
'class_name': self.model.__class__.__name__,
'config': self.model.get_config(),
}
clone = keras.models.model_from_config(config, custom_objects={"create_custom_loss": self.create_custom_loss})
clone.set_weights(self.model.get_weights())
return clone
if __name__ == '__main__' :
# --- ニューラルネットワークの前回保存済みモデル、または今回保存モデル名を引数で取得する
args = sys.argv
if 2 <= len(args):
filename = args[1]
else:
filename = None
action_list = [
[0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0],
[0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 1, 1],
[0, 1, 0, 0, 1, 0],
[0, 1, 0, 0, 0, 1],
[0, 1, 0, 0, 1, 1],
[0, 0, 0, 1, 1, 0],
[0, 0, 0, 1, 0, 1],
[0, 0, 0, 1, 1, 1],
]
action_map = [
# [i, j] for i in range(len(action_list)) for j in range(len(action_list))
[i] for i in range(len(action_list))
]
network = DqnNetwork(
y_size = len(action_map)
)
if filename != None and os.path.exists("./saved_networks/" + filename):
# --- 前回保存済みモデルを読み込む
network.model = keras.models.load_model("./saved_networks/" + filename, custom_objects={"create_custom_loss": network.create_custom_loss})
print ("Successfully loaded")
else:
# --- 新たにニューラルネットワークを作成する
if filename is None:
filename = 'model'
network.create_network()
print ("Could not find old network weights")
agent = Agent(
mario_course = 'ppaquette/SuperMarioBros-1-1-Tiles-v0', # マリオが学習するコース
loop_count = 30000, # 繰り返すエピソード数
init_randam_num = 1, # ランダムに行動させる初期エピソード数
greedy_rate = 0.002, # greedy率
extreme_greedy_rate = 0.005, # 超greedy率
extreme_greedy_interval = 10000, # 超greedyを行う間隔
extreme_greedy_count = 500, # 超greedyを行うアクション数
discount_rate = 0.9, # 次状態の割引率
frame_per_action = 6, # 同一アクションを繰り返すフレーム数
model_sync_interval = 640, # Target Networkを、Q Networkに同期するアクション間隔
batch_size = 64, # 一度に学習するサイズ
epoch = 10, # 一度の学習のエポック数
filename = filename, # ロード・保存するファイル名
action_list = action_list, # マリオがとりうるアクションをまとめたリスト
action_map = action_map, # 上記アクションリストの組み合わせを定義したリスト
network = network
)
agent.play()