昨今の自然言語処理モデルは、どれもTransformerをベースにしていると言っても過言ではない––––。
Transformerが出現するまで
RNN(LSTMやGRUを含む)時代
RNN
再帰型ニューラルネットワーク(Recurrent Neural Network) ニューラルネットワークを拡張して時系列データを扱えるようにしたもの。 ここで言う時系列データとは、ある時間の経過とともに値が変化していくようなデータを指す。LSTM
*Long Short Term Memory* ある程度長い時系列データに対しても学習ができるように考案されたモデル。 RNNとの違いは、「ゲート」と呼ばれる情報の取捨選択機構を持った点。 この忘却ゲートのおかげで、言語モデルの例では、「彼は…」と続く文が終わったときに、主語が彼であるという状態を忘れるといったことができるようになる。GRU
*Gated Recurrent Unit* LSTMをもう少しシンプルにしたモデル。 入力ゲートと忘却ゲートを1つの「更新ゲート」に統合している。RNN時代以前
初期言語モデル(1-gram言語モデルなど)では、限られた単語同士の結びつきを情報として保持するのみ。
→ 文章全体の結びつきを踏まえた処理をしたい!
そこで、文章全体の依存関係情報を保持できる再帰モデルが作られた。
どのように依存関係情報を保持するかと言うと…
入力データを固定長ベクトルに変形する(分散表現化する)際に、それ以前の単語の情報も加味したうえで固定長ベクトルに変形することで、単語の依存関係を反映することができる。
- 同じ関数を再帰的に(何度も)利用して逐次的に出力
- 次の入力に用いられるデータの一部に前の出力を含む
このようにして得られた固定長ベクトルに文脈を加味した形で文章全体の情報が圧縮されている。
<問題点>
- 再帰的に計算するとは逐次計算することを意味し、計算の並列化することができず(GPUなどの特性を生かせない)計算の高速化が難しい
Seq2Seq時代
異なる時系列データを利用するために考案された、RNNをEncoder/Decoderとして二つ利用するSeq2Seqモデル。
<問題点>
- 入力する文章の長さにかかわらず、固定長ベクトルに圧縮していることで必要な情報までが捨象されてしまう
- 単語や文章同士の依存関係を利用することができない
Attention付きSeq2Seq時代
これまではEncoder部分から作られる固定長ベクトルが、最後の部分しか利用されていなかった点に着目し、各単語が入力される際に出力される固定長ベクトルをすべて利用することにした。
これにより、
- 単語の数と同じ数だけの固定長ベクトルを獲得(文章の長さに応じた情報量を獲得)
-
各単語間の依存関係を獲得
することが可能になった。
また、AttentionはSoftmax関数などを用いた確率値(Attentionスコア)を持つ。これらの数値は単語間の関係性を示しているため、どのような単語と紐づいているかを可視化することができる。
Transformer時代
計算の高速化を実現するため、RNNなどを一切利用せずにAttention層だけを構築することで、
- 精度の高い依存関係モデルの構築
- 高速化
を同時に実現した。
Transformer概要
- 2017年中旬、Googleの「Attention Is All You Need」にて発表
- Attentionのみを用いてEncoder-Decoder型のモデルを設計
- BLEUスコア 英仏:41.0, 英独:28.4
BLEUスコア
「プロの翻訳者の訳と近ければ近いほどその機械翻訳の精度は高い」という発想のもと、正解となる翻訳とどれだけ一致できたかによって算出される値(0〜100)<特徴>
-
再帰も畳み込みも一切使わず、Attention層(Self-Attention層&Target-Source‐Attention層)のみで構築
- RNNを併用する場合と比べて、並列計算が可能になり計算が高速化
- CNNを併用する場合と比べて、長文の為の深いモデル構築が不要となった
-
PositionalEncoding層の採用
- RNNなどを利用しないことで失われてしまうはずの文脈情報を、入力する単語データに「文全体における単語の位置情報」を埋め込むことで保持することに成功
-
Attention層におけるQuery-Key-Valueモデルの採用
- 初期のAttentionにおける単純なSource-Target型から改良され、より単語同士の依存関係を正確に反映することができるようになったことで精度が改善
-
翻訳以外の他のタスクにも汎用性が高い
- 長文の文章生成
- 文書要約
- 対話生成
- 画像認識
CNN
畳み込みニューラルネットワーク(Convolutional Neural Network) 文章の依存関係を掴むための逐次的な計算を減らすという目的のもとRNNの代わりに使われた。 並列処理をある程度可能にするものの、文章が長くなるとそれに従って計算量が増えてしまい、より長文の依存関係を掴めないと言う問題が残った。モデル構造
- Encoder-Decoderモデル
- Attention
- Position-wise全結合層
- EmbeddingとSoftmax
- Positional Encoding


Encoder
- Embedding層によって入力文章を512次元のベクトルに圧縮
- Positional Encoding層によって位置情報を付加
- Multi-Head Attention層でSelf-Attentionを計算し、データ内依存関係を付加
- 各種Normalizationを行う
- Position-wise Feed-Forward Networks(PFFN:位置単位順伝播ネットワーク)層で活性化関数を適用
- 各種Normalizationを行う
3〜6を6層繰り返す
Embedding
**埋め込み** 文や単語などで分割した数値型の各トークンを、DeepLearningで扱うためにベクトル化すること。 同じ階層の要素全てが同じ空間内に配置され、常に同じ次元数のベクトルで表現されるため、特徴量として容易に投入可能。Decoder
- Embedding層によって入力文章を512次元のベクトルに圧縮
- Positional Encoding層によって位置情報を付加
- Masked Multi-Head Attention層でSelf-Attentionを計算し、データ内依存関係を付加
- 各種Normalizationを行う
- ここまでの出力をQueryに、Encoderの出力をKeyとValueにしてMulti-Head AttentionでAttentionを計算し、異なる時系列データの依存関係情報を獲得
- 各種Normalizationを行う
- PFFNで変換
- 各種Normalizationを行う
- Linear, Softmax Layerで単語生成
3〜8を6層繰り返す → 9
Positional Encoding層
単語の位置情報を埋め込む層 位置エンコード
Transformerでは単語の位置関係を捉えられる再帰や畳み込みを使っていないため、
"I love cats" と "cats love I"が同じと認識されてしまう。
そこで、単語の分散表現を入力する際に、「n番目」と文中の位置が一意に定まる値を各分散表現に加算する。これによって各要素データを並列処理したとしても、元々入力データが持っていた文章上の前後要素との関係情報を維持できるようになった。
- Attentionによって意味的な繋がりを付与
- Positional Encodingによって文章上の位置的繋がりを付与
<位置情報>
周波数が異なるsin関数・cos関数の値をベクトルに埋め込むことで与える。

単語の位置に一意の値を与えてくれるsin関数とcos関数のパターンもしっかりと学習してくれるため、結果として位置の依存関係を学んでくれている。

↑ Embeddingサイズが4のPositional Encodingの例
<メリット>
- 学習・推論を並列処理することで大幅に高速化
<デメリット>
- メモリを大量消費
Attention層
Attention
文中のある単語の意味を理解する時に、文中の単語のどれに注目すれば良いかを表すスコアのことQuery: $Q$ , Key: $K$ , Value: $V$ の3つのベクトルで計算される。各単語がそれぞれのQueryとKey, Valueのベクトルを持っており、QueryとKeyでAttentionスコアを計算し、そのAttentionスコアを使って**Valueを加重和すると、Attentionを適用した単語の潜在表現**が手に入る。
––––で、$Q, K, V$ って何??
→ 入力単語ベクトルにそれぞれ重みを掛け合わせたもの
Encoderの最初の段であれば、入力単語Embedding $X$ に $W^Q, W^K, W^V$ を掛け合わせたもの(つまり、 $XW^Q, XW^K, XW^V$)。
Encoderの二段目以降であれば、前段の出力にその段特有の別の重み $W^Q, W^K, W^V$ を掛け合わせたもの。
このモデルでは3箇所でAttentionが使用されている。
-
Encoder Self-Attention
-
QueryKeyValue:Encoder内の前層出力
-
-
Decoder Masked Self-Attention
-
QueryKeyValue:Decoder内の前層出力(ただし、対象の単語より右側にAttentionが加わらないようにしている。翻訳タスクにおけるカンニング防止)
-
-
Encoder-Decoder Attention
-
Query:Decoder内前層の出力 -
KeyValue:Encoderの最終出力
-
Scaled Dot-Product Attention
QueryとKeyの内積でそれぞれの単語の類似度(依存関係に反映される)を求める方法。
$Q, K$は次元 $d_k$を持ち、$V$は次元 $d_v$を持つ。Queryと全Keyの内積によりその類似度を計算し、$\sqrt{d_k}$で割った後に、Softmax関数を適用させる。
深さの次元数の平方根$\sqrt{d_k}$でスケーリング(縮小)することで、内積が大きくなり過ぎず上手く逆伝播することができるようになる。
$$\mathrm{Attention}(Q, K, V)=\mathrm{softmax}(\frac{QK^T}{\sqrt{d_k}})V$$
ここで、$K^T$は$K$の転置行列。
Softmax関数
ベクトルを受け取り、同じ次元のベクトルを返す関数の一つ $$\begin{eqnarray} \mathrm{softmax} \left( \begin{array}{c} 0 \\\ 99 \\\ 0 \\\ 100 \\\ 0 \end{array} \right) = \left(\begin{array}{c} 0.00 \\\ 0.27 \\\ 0.00 \\\ 0.73 \\\ 0.00 \end{array} \right) \end{eqnarray}$$ 出力の各成分はすべて0以上1以下の実数で、和は必ず1となるため確率として見なせる。Self-Attention
ある1文の単語たちだけを使って計算された、単語間の関連度スコアのようなもの
それまでは異なる時系列データ間で行われていたことを、同じ入力データ内でも行うことでより適切な単語依存関係を把握することを可能にした。RNNのように逐次的に依存関係を把握せず、個々のデータがデータ全体から並列的に依存関係を参照するため、より広範囲の依存関係も把握することができるようになった。
Self-Attention層はSeq2seqなどで付随される形で利用されていた(異なるデータ間の依存関係を獲得する)Attention層とは異なり、入力データ内の単語同士の依存関係情報(類似度や重要度)を獲得する。
<例>
- 従来のAttention
- I have cats. ⇔ 私は猫を飼っています。
- → 「I」は特に「私」や「飼っています」との依存関係を獲得
- Self-Attention
- I have cats. ⇔ I have cats.
- → 「I」は特に「I」や「have」との依存関係を獲得
<関連度>
| I | have | cats | |
|---|---|---|---|
| I | 0.88 | 0.10 | 0.02 |
| have | 0.08 | 0.80 | 0.12 |
| cats | 0.03 | 0.14 | 0.83 |
| I - have と have - I の関連度は異なる → なぜ? |
| Query | Key | Value | |
|---|---|---|---|
| I | $q_1$ | $k_1$ | $v_1$ |
| have | $q_2$ | $k_2$ | $v_2$ |
| cats | $q_3$ | $k_3$ | $v_3$ |
↑それぞれが持つQuery, Key, Value
|
Self-Attentionは各単語のQueryとKeyの内積にSoftmax関数を適用したもの
| I | have | cats | |
|---|---|---|---|
| I | $q_1 \cdot k_1$ | $q_1 \cdot k_2$ | $q_1 \cdot k_3$ |
| have | $q_2 \cdot k_1$ | $q_2 \cdot k_2$ | $q_2 \cdot k_3$ |
| cats | $q_3 \cdot k_1$ | $q_3 \cdot k_2$ | $q_3 \cdot k_3$ |
| ↑横の行が縦の列の単語に対しての関連度を表している |
I - have と have - Iを見てみると、$q_1 \cdot k_2$と$q_2 \cdot k_1$となっており、それぞれ違う値を使って計算されていることがわかる。よって、関連度の値が異なる。
これによって前後関係が考慮され、それ以上の複雑な係り結びなどの関係も捉えた上での値となっている。
Self-Attentionを行うことで同一文章内の類似度が獲得され、特に多義語や代名詞などが実際は何を指しているのかを正しく理解することができるようになる。
<例>
- The animal didn’t cross the street because it was too tired.
- → この時の「it」は「animal」
- The animal didn’t cross the street because it was too tired.
- → この時の「it」は「street」
<メリット>
- 再帰や畳み込みよりも計算量が小さい
- 並列計算が可能
- 広範囲の依存関係を学習可能
- 高い解釈可能性を有する
Self-Attentionの流れ
![]()
$x_1$に$W^Q$重み行列を乗算すると、その単語に関連付けられたQueryベクトルである$q_1(Q_1)$が生成される。同様に、$k_n$, $v_n$も生成される。
ここで乗算する$W^Q$, $W^K$, $W^V$は、事前学習で学習した値。

※ 「Thinking」に対するSelf-Attention
「Thinking」に対して、入力文の各単語にスコアをつける。
スコアは、Queryベクトルと入力文の各単語のKeyベクトルの内積を取ることによって計算される。
つまり、位置#1の単語のSelf-Attention層の最初のスコアは$q_1$と$k_1$の内積、2番目のスコアは$q_1$と$k_2$の内積となる。
スコア
特定の位置に単語をエンコードする時に、入力文の他の部分にどの程度焦点を当てるか決定する値
次に、$\sqrt{d_k}$でスケーリングする(8で割る)。
その値をSoftmax関数に与えることで、スコアを正規化する。このSoftmaxスコアは、各単語がこの位置でどれだけ表現される可能性があるかを決定する。この位置にある単語が最も高いSoftmaxスコアを持つことは明らかだが、時には関連する別の単語に注目することで良い結果を得ることもある。

各$Value$ ベクトルにSoftmaxスコアを掛け合わせる。これにより、焦点を当てるべき単語の値はそのままに、無関係な単語は(0.001のような小さな数字を乗算することで)注目度を下げることができる。
そして加重ベクトルを合計することで、この位置(最初の単語)でのSelf-Attention層の出力が生成される。
生成されたベクトルは、Feed-Forward層に送られる。
ここで説明したSelf-Attentionの流れは、単語レベルでの計算。実際は、高速な処理を行うため、行列形式で実行される。
Self-Attention行列計算の流れ

まず、Query, Key, Valueの行列値を計算する。
Embedding層で圧縮された入力単語ベクトルに、学習した重み行列($W^Q$, $W^K$, $W^V$)を掛ける。
この時、X行列の全ての行は、入力文の単語に対応する。
埋め込みベクトル(512次元:X)と、$q$, $k$, $v$ベクトル(64次元:$Q$, $K$, $V$)ではサイズが異なることを確認できる。

行列を扱っているため、上記のように一つの式に凝縮してSelf-Attentionの出力を計算することができる。
Multi-Head Attention

**各単語に対して1組のQuery, Key, Valueを持たせるのではなく、比較的小さいQuery, Key, ValueをHeadの数だけつくり、それぞれのHeadで潜在表現を計算する。**最終的にそれらを一つのベクトルに落とすことによって獲得された潜在表現を、その単語の潜在表現とする。
Headが異なれば処理している潜在表現の空間も異なるため、Multi-Headで複数の潜在表現空間を処理してからまとめる方が、単一のHeadで深く潜在表現を処理するよりも、より広範囲に有益な情報を取ってきてくれる。

↑英語とフランス語でトレーニングしていく中で得たHeadごとの依存関係
各Headで異なるAttentionスコアを獲得していることが分かる。
Multi-Head Attentionの流れ
↑$z_1$にはあらゆるエンコーディングが含まれているが、その単語自身に大きな比重がかかっている可能性がある。
“The animal didn’t cross the street because it was too tired”(動物が通りを渡らなかったのは疲れていたからだ)
という文章を翻訳する場合、"it"がどの単語を指しているのかを知ることが重要になる。
↑ "it"に一番Attentionかかってたら翻訳的には意味をなさない

Multi-headを導入することにより、Attention層には複数の「潜在表現空間」が与えられる。
Multi-Head Attentionでは8つのHeadを使用するため、各Encoder/Decoderに対して8つのQuery, Key, Valueベクトルセットが必要になる。これらのセットはそれぞれランダムに初期化される。
事前学習の後、各セットは入力Embedding(または下位のEncoder/Decoderからのベクトル)を異なる潜在表現空間に落とし込むために使用される。

各Headごとにそれぞれの$W^Q$, $W^K$, $W^V$重み行列を維持しそれらをXに乗算することによって、Headごとに異なる$Q$, $K$, $V$行列を生成する。
これを8回繰り返すことで、8つの異なる$Z$行列を獲得する。

Multi-Head Attentionビジュアル化

- 入力文 → Thinking Machines $ ^*$
- 各単語をEmbeddingする → X $ ^*$
- 8つのHeadに分割し、XまたはRに重み行列を掛ける
- $Q$, $K$, $V$の行列を使ってAttentionスコアを計算する
- 得られた$Z$行列を連結し、重み行列$W^O$と乗算することで出力を一つの行列に凝縮する
$ ^*$0番目以外のEncoderでは、Embeddingする必要はない。
自分のいるEncoder直下のEncoder/Decoderで出力されたベクトル(R)を直接使用する。
Masked Multi-Head Attention
訓練時のDecoderでは、全ターゲット単語を同時入力・同時予測することになる。
- Encoder:I have cats
- Decoder:Yo tengo gatos(スペイン語)
例えば、「cats」のスペイン語を予測するときに、Decoderに答えである「gatos」を入力のまま渡してしまうと、Decoderは「gatos」をそのまま出力するカンニングマシンになってしまう。これを防ぐため、Maskingを行うことで、Self-Attention層は対象単語以前の位置にのみAttentionがかけられるようになる。
→ 3番目の単語を予測する際には、最初と2番目の単語のみを使用

Mask
Softmaxへの入力のうち、予測すべき単語より後にある単語に対応する部分を$-\infty$で埋める
Matmul
**Matrix Multiplication(行列積)** $matmul(x, y)$で$x$と$y$の行列関を返す関数Normalization(Multi-Head Attention後)
Multi-Head Attention層の次の層である、Feed-Forward層に期待される入力は、各単語のベクトルにあたる1つの行列。
しかし、Multi-Head Attentionの出力は8つの行列となっているため、Normalization(8つの行列を1つの行列に凝縮)する必要がある。

↑行列を連結後、重み行列$W^O$を乗算し、1つの行列に落とし込む
- 全てのAtteniton-Headを連結する
- 事前学習された重み行列$W^O$を乗算する
- 全てのAttention-Headからの情報を盛り込んだ$Z$行列が生成される
Concat関数 → ベクトルの連結

Position-wise Feed-Forward Networks層
各ブロックのAttention層のあとに入っているPosition-wise 順伝播ネットワーク。
ReLUで活性化する$dff=2048$次元の中間層と$dmodel=512$次元の出力層から成る2層の全結合ニューラルネットワーク。
位置単位で個別に順伝播ネットワークを形成することで、他単語との影響関係を排して位置情報毎に並列に処理することを可能としている。ただし、重みは共有され、全時刻で同じ変換が行われている。

ReLU
**ランプ関数** 入力値が0未満であれば0を、0以上であれば入力値を出力値とする活性化関数。各種Normalization
このモデルには3種類のNormalizationが使用されている。
- Label Smoothing
- Residual Dropout
- Attention Dropout
Label Smoothing
正解ラベルは一意に定まっているため、0(不正解)と1(正解)でのみ判断される。それだと「惜しい」不正解と「的外れな」不正解とが同じように処理されてしまう。これを防ぐために、Label Smoothing処理(正解ラベルに緩みを持たせ、一意に定めないようにする)を行う。モデルは不確かなラベルを学習することになるため、パープレキシティは悪化するものの、精度とBLEUスコアは向上することが知られている。
パープレキシティ
Perplexity:トピックモデルの評価指標Residual Dropout
入力の加算と層正規化 (Add & Norm) 前の各層の出力にドロップアウトを適応している。
EncoderとDecoderのEmbedding層とPositional-Encodingの和にも同様に適応。
実験ではドロップアウト率:Pdrop = 0.1を使用。
Residual
**残差** 実際のデータを用いて推定された回帰式から算出される値と実際のデータとの差 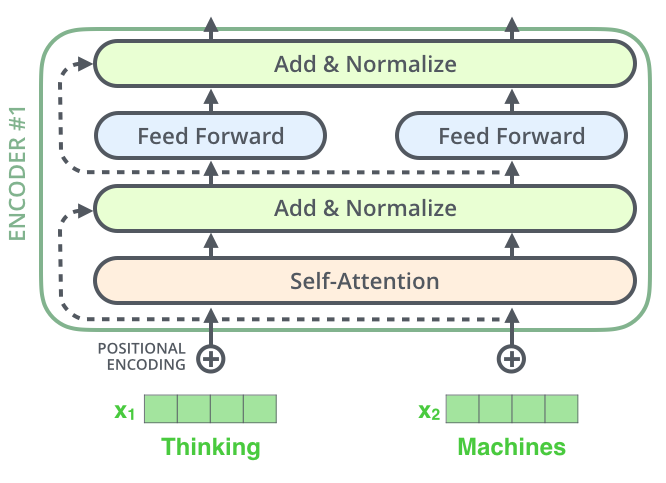 各Encoderの各サブLayer(Self-Attention, PFFN)は、その周りに残差接続を持ち、その後に Layerの正規化(Normalization)が行われる。 残差接続:画像内点線矢印Attention Dropout
Scaled Dot-Product Attention後のsoftmaxによる活性化は、順伝播ネットワークの隠れ層の活性化と同様のものと見做すことができる。そのため、softmaxの出力に対してドロップアウトを適用している。
Linear, Softmax Layer
Decoderが最終的に出力したfloatベクトルを単語に変換する。
Linear層
Decoderによって生成されたベクトルを、ロジットベクトルと呼ばれる遥かに大きなベクトルに落とし込む、シンプルなニューラルネットワーク。
モデルがtrain dataから学習した10,000個の一意な単語(モデルの「出力語彙」)を知っていると仮定したとき、ロジットベクトルの幅は10,000セルとなる。各セルは一意の単語スコアに対応する。
ロジット
**logit** 0から1の値をとるp に対し、 $${\displaystyle \operatorname {logit} (p)=\log \left({\frac {p}{1-p}}\right)=\log(p)-\log(1-p)}$$ で表される値 ロジスティック関数の逆関数Softmax層
Linear層で得たスコアを確率的に変換する。それぞれ確率が最も高いセルが選択され、そのセルに対応した単語が各time-stepの出力として生成される。

参考文献
-
Attention Is All You Need
- 元論文
- 自然言語処理の必須知識 Transformer を徹底解説!
- 深層学習界の大前提Transformerの論文解説!
-
The Illustrated Transformer
- 主に↑3つから引っ張ってきた
- 再帰型ニューラルネットワークの「基礎の基礎」を理解する
- RNN:時系列データを扱うRecurrent Neural Networksとは
- トランスフォーマー時代到来、翻訳技術から汎用言語系AIに
- Embeddingについてまとめた。
-
作って理解するTransformer / Attention
- さらに細かい!組み込みの際に大変お世話になりそう