0. 概要
今回はBigQueryでアソシエーション分析をやってみたいと思います。
1. アソシエーション分析とは
2. 重要な3つの指標について
3. データ紹介
4. 実践
5. まとめ
※BigQueryのSQL言語設定は、標準です。
1. アソシエーション分析とは
「ある消費者がAという商品を買うと、65%の確率で、別のBという商品を買う可能性がある。」
このような傾向を掴むことは、効果的なレコメンデーションを実現するうえで重要です。例えば、あるECサイトの購買ログデータがあったとしましょう。ユーザーIDや、セッションID,、購入商品(…etc)が大量に記録されたデータの中から、上記のような有用な情報を取得するにはどうすればよいのでしょうか。目視で確認するには骨が折れる作業ですし、因果関係がありそう/なさそうの判断をするには、なんらかの指標が必要です。このような時に便利なのが、アソシエーション分析です。アソシエーション分析とは支持度(Support)、確信度(Confidence)、**リフト(Lift)**という3つの指標で相関ルール(アソシエーション・ルール)の抽出を行う代表的な手法で、冒頭のような1対1の関係だけでなく、複数対複数といった関係性も発見できる汎用的なアルゴリズムです。
ただし、冒頭のようなアソシエーション・ルールを見つけたと言って、「ある消費者が"B"という商品を買うと、65%の確率で、"A"という商品を買う可能性がある」とは言えないことに注意が必要です。つまり、A⇒Bという方向性があるということです。
2. 重要な3つの指標について
ある店で、たった一人の消費者が、商品Aと一緒に商品Bを買ったとしてみましょう。
この時、商品間に何らかのアソシエーション・ルールがあるといって良いのでしょうか?直観的には、偶然の事で、あまり関係性が無いように思えます。では、二人の消費者の場合はどうでしょう?さらに三人なら?
このように、商品間に因果関係を見つけるためには、なんらかの指標が必要です。支持度(Support)、確信度(Confidence)、リフト値(Lift)はアソシエーション・ルールにおける重要な指標です。これらについて以下に説明をしていきたいと思います。
支持度(Support)
支持度とは、商品A(以下A)と商品B(以下B)を一緒に購入しているデータ数が、全データ(以下Z)数に対して占める割合です。支持度が大きいほど、AとBの関係性は全体に対して影響力があるということです。逆に、支持度が小さいものはそれほど影響がないということです。数式で表すと以下のようになります。
支持度=
\frac{|A\cap B|}{|Z|}
確信度(Confidence)
確信度とは、AとBを一緒に購入しているデータ数が、Aを購入しているデータ数に対して占める割合です。簡単にいうと、Aを買った消費者が、Bを買う確率ということです。数式で表すと以下のようになります。
確信度=
\frac{|A\cap B|}{|A|}
「Aを買った消費者が、Bを買う確率が分かるのか!この指標さえあれば、他の指標はいらないのでは?」という疑問が浮かぶかもしれませんが、これは間違いです。例えば、確信度だけで、Aを購入した消費者がBを購入すると結論付けたとします。その一方で、背景には次の2パターンの実情があったとします。
パターン1:AとBを購入している消費者が、全体の1%であった。
パターン2:Bを購入している人は、全体の90%であった。
どうでしょう、捉え方が大きく変わったのではないでしょうか。前者のパターンは、すなわち支持度が1%ということです。つまり、販促に力を入れたところで、全体に対して1%しか影響しないのでビジネス的に旨みがないわけです。後者のパターンは、全体の90%がBを購入しているわけですから、A⇒Bを結論付けることはできないでしょう。これは、次に紹介するリフトに関係した考えです。
リフト値(Lift)
リフト値とは、確信度を、全体に対するBの購入割合で割った値です。わかりにくいので数式をみてみましょう。
リフト値=
\frac{\frac{|A\cap B|}{|A|}}{\frac{|B|}{|Z|}}
確信度の説明時にでてきた、パターン2を思い出してください。リフト値の分母は全体に対するBの購入割合ですから、分子が変わらない場合、Bの購入割合が多ければ多いほど、リフト値は小さくなります。その一方で、Bの購入割合が少なくなればなるほど、リフト値は大きくなります。リフト値が小さい場合、A⇒Bを結論付けられないということは、前述の通りです。リフト値が大きくなる場合は、この逆の考えになるわけです。
以上でみてきたように、これら3つの指標のどれか一つだけをみて、結論を出すことはできません。3つの指標に対して、総合的な判断をする必要があります。なお、一般のレコメンドエンジンでは上記の3つの指標に対して、推奨値は以下の値となっているようです。以降の実践では、この推奨値を使ってみようと思います。
| 指標 | 推奨値 |
|---|---|
| 支持度(Support) | 0.5以上 |
| 確信度 (Confidence) | 0.7以上 |
| リフト値 (Lift) | 1.0以上 |
3. データ紹介
今回実践で使用するテーブルは以下の通りとなります。stampは取引が行われた時間、sessionは取引をした人、purchase_idはsession毎に付与されるid、product_idが商品番号を表しています。
テーブル:qiita.purchase_log
| stamp | session | purchase_id | product_id |
|---|---|---|---|
| 2099-06-03 18:10 | user_1 | 1 | A001 |
| 2099-06-03 18:10 | user_1 | 1 | A002 |
| 2099-06-03 20:00 | user_2 | 2 | A001 |
| 2099-06-12 13:00 | user_3 | 3 | A002 |
| 2099-06-12 15:00 | user_4 | 4 | A001 |
| 2099-06-12 15:00 | user_4 | 4 | A003 |
| 2099-06-12 16:00 | user_5 | 5 | B001 |
| 2099-06-12 16:00 | user_5 | 5 | A001 |
| 2099-06-12 17:00 | user_6 | 6 | A001 |
| 2099-06-12 17:00 | user_6 | 6 | A002 |
| 2099-06-12 17:00 | user_6 | 6 | A003 |
| 2099-06-12 18:00 | user_7 | 7 | A001 |
| 2099-06-12 18:00 | user_7 | 7 | A003 |
| 2099-06-12 19:00 | user_8 | 8 | A001 |
| 2099-06-12 19:00 | user_8 | 8 | A003 |
| 2099-06-12 19:00 | user_9 | 9 | A001 |
| 2099-06-12 19:00 | user_9 | 9 | A003 |
| 2099-06-12 20:00 | user_10 | 10 | A001 |
| 2099-06-12 20:00 | user_10 | 10 | A003 |
| 2099-06-12 20:00 | user_10 | 10 | B002 |
| 2099-06-12 21:00 | user_11 | 11 | B001 |
| 2099-06-12 22:00 | user_11 | 11 | A001 |
| 2099-06-12 22:00 | user_11 | 11 | A002 |
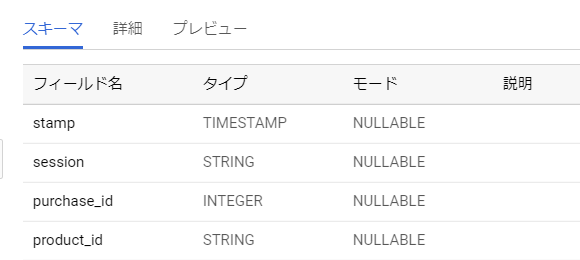
スキーマ詳細は以下の通りです。
4. 実践
それでは、実践に入っていきます。流れとしては、、
- 購入ログ数と購入商品数を算出
- 同じpurchase_id内で複数の商品を購入しているものについて、その組み合わせの総数を算出
- 前述の計算方法に従って、各指標値を算出し、結果から、推奨値以上のものを抽出
という流れになります。
1. 購入ログ数と購入商品数を算出
with_1内で購入ログ数を集計しています。with_2内では、Window関数を利用して、商品毎の個数をカウントしています。そして、with_1で集計したログ数を、log_cntとしてクロスジョインしています。
WITH with_1 AS (
SELECT
COUNT(DISTINCT purchase_id) AS Z_count
FROM
qiita.purchase_log
)
, with_2 AS (
SELECT
a.purchase_id
, a.product_id
, COUNT(*) OVER (PARTITION BY a.product_id) AS product_cnt
, b.Z_count
FROM
qiita.purchase_log AS a
CROSS JOIN(SELECT Z_count FROM with_1) AS b
)
SELECT
*
FROM
with_2
ORDER BY
purchase_id
, product_id;
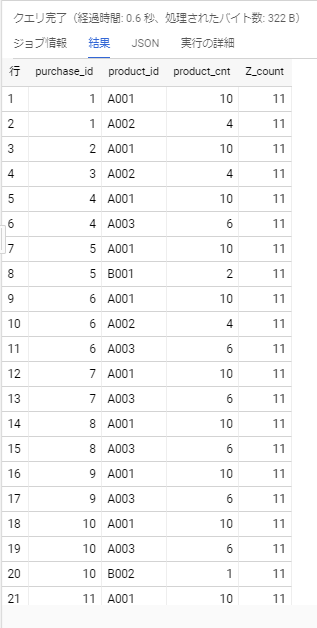
実行結果は以下の通りです。一番右にあるZ_countが、支持度の計算で必要な$|Z|$の値となります。その左隣のproduct_cntが$|A|$や$|B|$の値となります。
2. 同じpurchase_id内で複数の商品を購入しているものについて、その組み合わせの総数を算出
with_1とwith_2の内容については、前述の通りです。with_3内では、JOIN句で自己結合を行っています。結合条件は、「purchase_idが同じもの」という条件にしています。更に、WHERE句で「商品名が異なるもの」という指定をすることで、一つの取引内で購入されている複数商品の因果関係を洗い出すことができます。最後に、GROUP BY句とCOUNT関数を利用して、因果関係の個数を集計しています。
WITH with_1 AS (
SELECT
COUNT(DISTINCT purchase_id) AS Z_count
FROM
qiita.purchase_log
)
, with_2 AS (
SELECT
a.purchase_id
, a.product_id
, COUNT(*) OVER (PARTITION BY a.product_id) AS product_cnt
, b.Z_count
FROM
qiita.purchase_log AS a
CROSS JOIN(SELECT Z_count FROM with_1) AS b
)
, with_3 AS (
SELECT
a.product_id AS A
, b.product_id AS B
, a.product_cnt AS A_count
, b.product_cnt AS B_count
, COUNT(*) AS A_B_count
, a.Z_count
FROM
with_2 AS a
INNER JOIN with_2 AS b
ON a.purchase_id = b.purchase_id
WHERE
A <> B
GROUP BY
A
, B
, A_count
, B_count
, Z_count
)
SELECT
*
FROM
with_3
ORDER BY
A
, B;
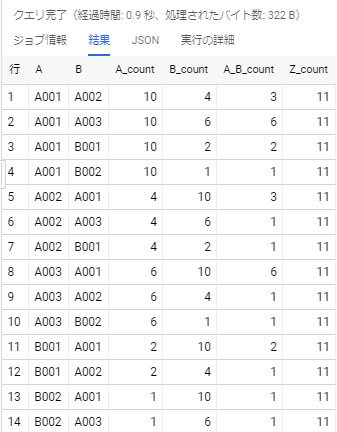
実行結果は以下の通りです。A_count、B_countの値が、数式上の$|A|$、$|B|$です。
そして、A_B_countの値が、数式上のの$|A\cap B|$にあたります。
3. 前述の計算方法に従って、各指標値を算出し、結果から、推奨値以上のものを抽出
ここまでで、計算に必要な値の集計には成功しました。最後に各指標値を求めていきます。一番下のSELECT文で、前述の指標の計算を行っています。
WITH with_1 AS (
SELECT
COUNT(DISTINCT purchase_id) AS Z_count
FROM
qiita.purchase_log
)
, with_2 AS (
SELECT
a.purchase_id
, a.product_id
, COUNT(*) OVER(PARTITION BY a.product_id) AS product_cnt
, b.Z_count
FROM
qiita.purchase_log AS a
CROSS JOIN (SELECT Z_count FROM with_1) AS b
)
, with_3 AS (
SELECT
a.product_id AS A
, b.product_id AS B
, a.product_cnt AS A_count
, b.product_cnt AS B_count
, COUNT(*) AS A_B_count
, a.Z_count
FROM
with_2 AS a
INNER JOIN with_2 AS b
ON a.purchase_id = b.purchase_id
WHERE
a <> b
GROUP BY
A
, B
, A_count
, B_count
, Z_count
)
SELECT
A
, B
, ROUND(100.0 * A_B_count / Z_count, 2) AS support
, ROUND(100.0 * A_B_count / A_count, 2) AS confidence
, ROUND((A_B_count / A_count) / (B_count / Z_count), 2) AS lift
FROM
with_3
ORDER BY
A
, B;
実行結果は以下の通りです。
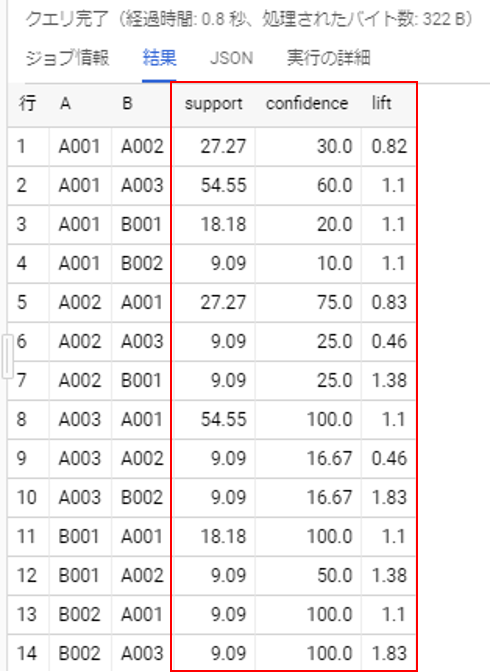
クエリは割愛しますが、推奨値を使って条件検索すると、、
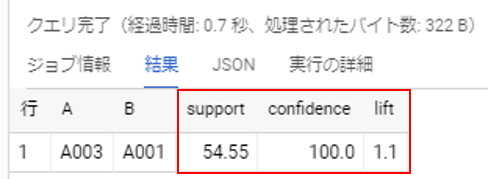
上記の通り、A003を購入した消費者が、A001を購入する可能性が高いという結果を導きだすことができました。
5. まとめ
アソシエーション分析で扱う指標は、どれも簡単な数式で求めることができます。しかし、今回のように1対1の関係に絞った分析ではなく、複数対複数の関係を探っていく場合、パターン数が膨大となり、SQLで実現するのは大変そうだなあと思いました。RやPythonなどのプログラミングを利用する方がいいでしょう。また、今回の実践では、purchase_idで「一つの取引」を定義しましたが、実用上は分析対象の性質に応じて、工夫をしていく必要がありそうですね。
参考サイト/書籍
[ビッグデータ分析・活用のためのSQLレシピ]
(https://www.amazon.co.jp/%E3%83%93%E3%83%83%E3%82%B0%E3%83%87%E3%83%BC%E3%82%BF%E5%88%86%E6%9E%90%E3%83%BB%E6%B4%BB%E7%94%A8%E3%81%AE%E3%81%9F%E3%82%81%E3%81%AESQL%E3%83%AC%E3%82%B7%E3%83%94-%E5%8A%A0%E5%B5%9C-%E9%95%B7%E9%96%80/dp/4839961263)
http://bdm.change-jp.com/?p=1341
https://www.albert2005.co.jp/knowledge/marketing/customer_product_analysis/abc_association