CloudWatch log で運用費用が超過していませんか。
最近 AWS を利用していると必ず聞こえてくる監査ログの取り扱い。
気にせず運用していると毎月チャリンチャリンと費用が発生するため
performance insight とかaudit logとか無料の範囲で出力をして
気が付けばログがなくて涙が出たりはしていませんか。
RDSは標準で監査ログを保存しようとすると全部 CloudWatch Log 行き。
それって。やけに高いと噂ですよね。
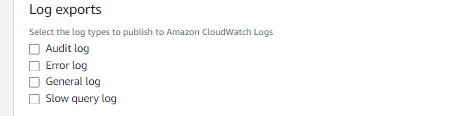
ここにチェックをいれると全部お金の亡者行きです。
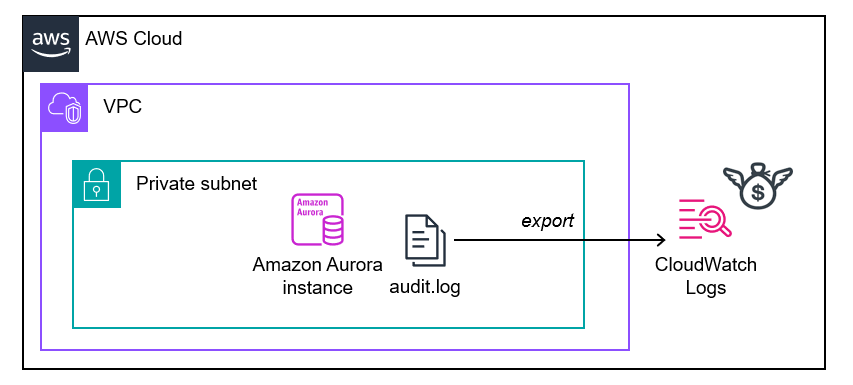
気持ち。正義超人のペンタゴンみたい(違う
もはや S3に直接アップロードするしかない
何が高いのか。気になったらAWSで料金をぐぐる(表現
CloudWatch Log 運用で発生する費用は収集がすごい高い。
| 課金対象 | 金額(東京リージョン) |
|---|---|
| 収集 (データインジェスト) | 0.76USD/GB |
| 保存 (アーカイブ) | 0.033USD/GB |
| 分析 (Logs Insights のクエリ) | スキャンしたデータ 1 GB あたり 0.0076USD |
そうなのです。流行りものの収集癖は高くつくということ。
CloudWatch Log 便利だけど要注意。
それに引き換え S3に保存する費用ってば。もうお買い得感しかない。
30倍です。なにこれ状態。
| 課金対象 | 金額(東京リージョン) |
|---|---|
| 最初の 50 TB/月 | 0.025USD/GB |
| 次の 450 TB/月 | 0.024USD/GB |
とはいえS3だからって保存し続けたら高くなっちゃうので
ライフサイクルの設定したり
S3向けのゲートウェイエンドポイント作成したりして
できるだけ無駄な支出を回避してくださいね
とはいえどんな実装が必要なのかしら。
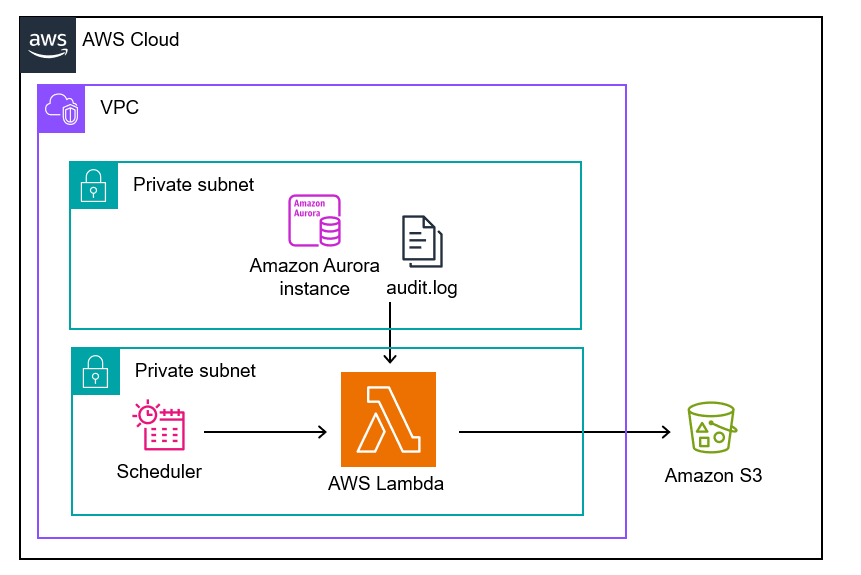
こんな感じ。お金ホイホイの CloudWatch Log は経由しないで
Lambda バッチから audit.log を取得して直接 s3にアップロードです。
ソースコードの中に秘匿情報を書かないように基本環境変数に設定
不要な情報もありそうなので S3バケットに転送するかをファイル単位で設定
| 設定項目 | 設定内容 | サンプル |
|---|---|---|
| RDS_PREFIX | RDSの名前(前方一致) | prd_yamadb |
| S3_BUCKET | S3バケット名 | yamada3 |
| TRANSFER_AUDIT_LOGS | 監査ログを転送するか | true |
| TRANSFER_ERROR_LOGS | エラーログを転送するか | false |
| TRANSFER_SLOW_QUERY_LOGS | スロークエリログを転送するか | true |
S3バケット内には以下の感じで保存されます
バケットの中身
yamada3 バケットの名前(山田さん
┗━ rds/
┣━ prd_yamadb-r/ 対象DB名(前方一致で抽出
┗━ prd_yamadb-w/ 対象DB名
┣━ audit/ 監査ログが出力される(audit.log)
┣━ slowquery/ slowquery が出力される
┗━ error/ error.log 名前で察する何か(略
実際のファイル名は以下の感じ。
Athena から直接クロールできる gzip形式です
audit/audit.log.3.2024-02-12-02-30.0.gz
slowquery/mysql-slowquery.log.2024-02-11.06.gz
error/mysql-error-running.log.2024-02-11.05.gz
なんかいい感じ。
pythonによる実装はこんな感じ
import boto3
import gzip
import os
from io import BytesIO
from datetime import datetime, timedelta
from datetime import datetime, timedelta
def lambda_handler(event, context):
rds_client = boto3.client('rds')
s3_client = boto3.client('s3')
rds_prefix = os.environ['RDS_PREFIX']
s3_bucket = os.environ['S3_BUCKET']
transfer_audit_logs = os.getenv('TRANSFER_AUDIT_LOGS', 'false').lower() == 'true'
transfer_error_logs = os.getenv('TRANSFER_ERROR_LOGS', 'false').lower() == 'true'
transfer_slow_query_logs = os.getenv('TRANSFER_SLOW_QUERY_LOGS', 'false').lower() == 'true'
# 現在の実行時刻
now = datetime.now()
# 2時間と10前のUNIXタイムスタンプを計算
two_hours_ago = int((now - timedelta(hours=2, minutes=10)).timestamp() * 1000) # millisecondsに変換
# 1時間前のUNIXタイムスタンプを計算
one_hour_ago = int((now - timedelta(hours=1)).timestamp() * 1000) # millisecondsに変換
instances = rds_client.describe_db_instances()
for instance in instances['DBInstances']:
if instance['DBInstanceIdentifier'].startswith(rds_prefix):
instance_name = instance['DBInstanceIdentifier']
logs = rds_client.describe_db_log_files(
DBInstanceIdentifier=instance_name,
FileLastWritten=two_hours_ago,
MaxRecords=256)
for log in logs['DescribeDBLogFiles']:
log_file_name = log['LogFileName']
# ファイルが最後に書き込まれた時刻が2時間前から1時間前の範囲にあれば処理対象
if two_hours_ago <= log['LastWritten'] < one_hour_ago:
# S3にアップロードするオブジェクトキーを構築
object_key = f"rds/{instance_name}/{log_file_name}.gz"
if ("audit" in log_file_name and transfer_audit_logs) or \
("error" in log_file_name and transfer_error_logs) or \
("slowquery" in log_file_name and transfer_slow_query_logs):
# S3で同一のファイル名が存在するか確認
try:
s3_client.head_object(Bucket=s3_bucket, Key=object_key)
print(f"File already exists in S3: {object_key}. Skipped.")
continue # ファイルが存在する場合は、次のログファイルの処理に移る
except s3_client.exceptions.ClientError as e:
# ファイルが存在しない場合は処理を続行
# print(f"File upload to S3: {object_key}.")
pass
log_data = rds_client.download_db_log_file_portion(
DBInstanceIdentifier=instance_name,
LogFileName=log_file_name,
Marker='0'
)
compressed_data = BytesIO()
with gzip.GzipFile(fileobj=compressed_data, mode='wb') as f:
f.write(log_data['LogFileData'].encode('utf-8'))
compressed_data.seek(0)
# S3にアップロード
s3_client.upload_fileobj(
Fileobj=compressed_data,
Bucket=s3_bucket,
Key=object_key
)
return {
'statusCode': 200,
'body': 'Log file processing completed.'
}
クリックすると広がるので注意(恥ずかしいw
※
下記のdescribe_db_log_files はパラメタを指定しないと
対象ログファイルが多すぎると取りこぼれが発生いたします。ご注意ください
logs = rds_client.describe_db_log_files(
DBInstanceIdentifier=instance_name,
FileLastWritten=two_hours_ago,
MaxRecords=256)
Lambda関数にはバージョン付与とエイリアスを。
先日 Lambda関数にバージョンを付与せず Node.jsの更新をしたら
冷や汗てんこ盛りだったのを踏まえてエイリアスを付与してみました
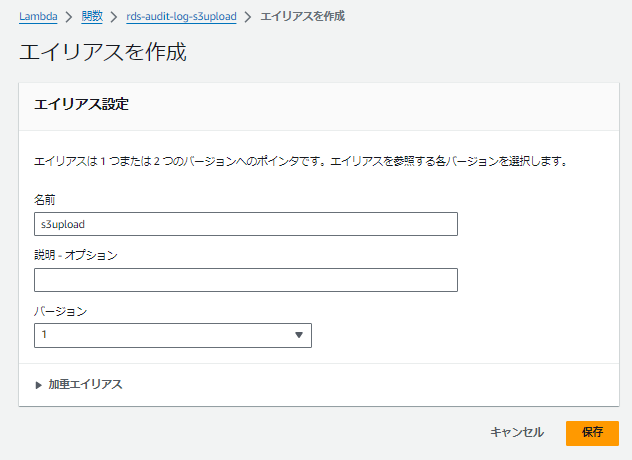
名前が監査ログに特化している気がするけど汎用なので。
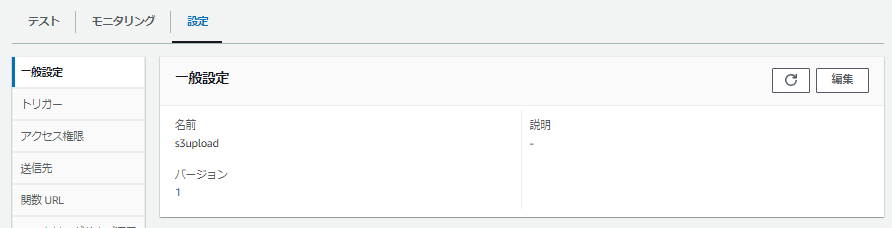
これで外側からLambda関数を実行するときにはs3uploadという別名で
なんか名前のセンスがないけどバージョンは意識しなくてもOK。
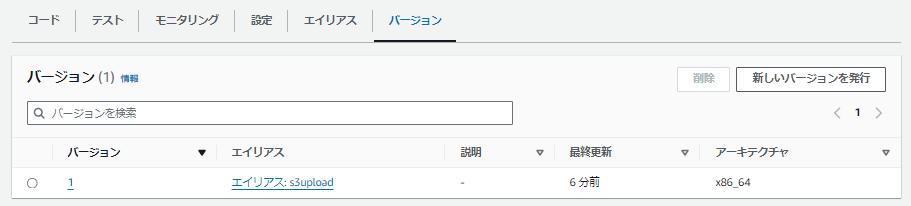
地道にバージョンをあげてもエイリアスを変更しない限り
業務影響を与えずにLambda関数の更新ができるのは安心ですよ、奥さん。
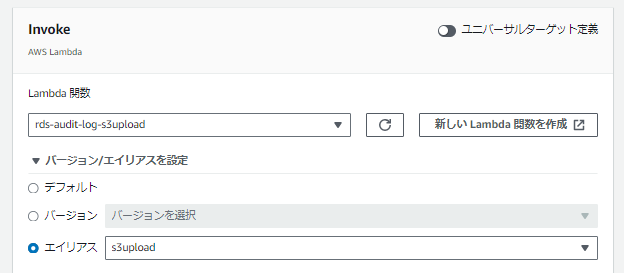
EventBridgeでは上記のような感じでエイリアスが指定可能です。
そうすると呼び出し元を全部更新しなくてもOK牧場。
忘れる前にメモを追記
EventBridge 経由で 1時間に 1回ほどの間隔で実行すれば
気が付けば知らないうちにがっぽがっぽと儲かります(嘘
監査ログに出力したい情報は parameter group で
server_audit_events に設定すれば大丈夫。

ただ DML だけ出力したいわっていう希望があっても
QUERY_DML_NO_SELECT
という設定ができるのは 5.7.34以降です。
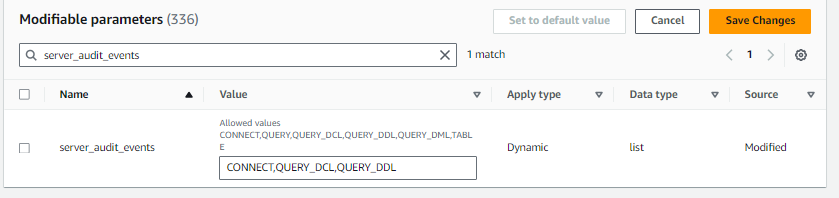
利用可能な値に書いてない、涙
バージョン古いと QUERY_DML しか指定できません。
名前に反する SELECT も大量に出力される鬼監査が開始されますので注意。
※何故 DML なのに SELECT が出るのかと唖然すること間違いなし
※早くバージョンアップしましょう。
このまま運用したい場合には Lambda関数に RDSの読み取り系のポリシーと
S3バケットにアップロードとかとか必要な権限の付与をすればOKです
とにかく動かすために暫定で RdsFullAccess とか付与しないこと
あなたも AWS ベストプラクティスにしたがう「最小権限の法則で」で。
※すでに「で」が過剰
こんなポリシーを Lambda に適用すれば動いたのでたぶん大丈夫。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AuditFileToS3",
"Effect": "Allow",
"Action": [
"s3:ListTagsForResource",
"s3:PutObject",
"rds:ListTagsForResource",
"rds:DownloadDBLogFilePortion",
"rds:DescribeDBInstances",
"rds:DescribeDBLogFiles",
"s3:ListBucket"
],
"Resource": [
"arn:aws:rds:対象のRDS",
"arn:aws:s3:対象のS3"
]
}
]
}
いつも心に太陽を。また来週。マルハラで完了。