はじめに
最近、プロジェクトで運用回りの設計を行う機会があったので、その際に学習したことをまとめました。AWSのLambdaなどを使っている方でロギングに興味があるけど、まだ良く理解できていないという方のためになれば幸いです。ここではサーバレス環境でのロギングの基本について解説しています。
また、監視に関した記事も投稿していますので、そちらも興味がございましたら一読下さい。
ログ戦略
マイクロサービスの場合、ログ戦略がとても重要になってきます。
マイクロサービスは複数のサービスから構成されているため、ログ戦略を間違えると調査が困難になり得るからです。ただし、AWSの場合は何でもかんでもログを出力するのは間違いです。標準的なログ出力機能を備えているサービスも多いため、重複が多くなりコスト増につながります。つまり、適切なログのみを出力する必要があります。
Lambdaのログ戦略
開発環境と本番環境でログ出力の内容を変えるのはよい選択だと思います。
Lambdaの場合、環境変数にログレベルを設定して、コードでは環境変数を取得して切り替えるのが一番スマートかと思います。ただ、一番問題なのはログレベルでのログの中身の定義ではないでしょうか。
ここはビジネスロジックごとに異なるためなかなか難しいのですが、個人的には以下のような形のログ戦略を採っています。ログ出力時の項目についてはAppendixのログ出力の設計指針を参照ください。
ログレベルの使い分け
| レベル | 内容 |
|---|---|
| ERROR | Slack通知したい情報(対処が必要な事象が起きた) |
| WARNING | Slack通知しないが、残したい情報(対処は不要だけど気にしておきたい) |
| INFO | 開発者がLambdaの処理を追うのに必要な情報(対処する際の参考情報) |
| DEBUG | 開発時にあると嬉しい情報 |
具体例
-
ERROR
- 想定外のデータがあり処理続行できなかった
- DynamoDBからデータ取得しようとしたけど失敗し、処理続行できなかった
- トレースバックログ
- API Request Bodyの値が想定外である
API Gatewayの裏側にいるLambdaの場合は意図的にエラーログを出さないようにする
(クライアント要因のエラーをSlackに通知しても、開発者がやることは無いため)。 -
WARNING
- 必須データが無いけど、デフォルト値を使って処理を続行した
- DynamoDBからデータ取得に失敗したが、リトライ処理では成功した
-
INFO
- Lambdaの入口(event, 環境変数)
- Lambdaの出口(処理の結果)
- Lambda以外に関するアクセスやデータ(DynamoDB・S3・IoTなど)
- Requestの内容
- Responseの内容
-
DEBUG
- 関数の出入り
- 特定変数の内容
ログで記録すべきでない情報
主にセキュリティの観点になるのですが、例えば次のような情報は記録すべきでありません。
あるいはマスク処理を行う必要があります。
- パスワード
- 認証情報
- 個人情報
サーバー負荷を考慮
ログは問題が発生したときの調査や問題の予防などに役立ちますが、一方でサーバーに負荷がかかる行為でもあります。ログを出力することでサーバーにパフォーマンス上の問題が起きたときは、出力の設計指針を見直す必要があり得ます。
API Gatewayのログ戦略
APIには詳細メトリクスの記録、ログ記録、X-Rayの有効化の設定があります。
まず、詳細メトリクスの記録は有効にするのがいいと思います。API Gatewayで例えば400でレスポンスが返る場合、Cloudwatch メトリクスでも400レスポンスが記録されます。ただし、詳細メトリクスがオフになっていると、どのAPI呼び出しで400エラーが返ったのかまで分かりません。詳細メトリクスをオンにすることで、どのリソースのどのメソッドが400エラーを変えているのかがわかるので、迅速に調査することができます。
次に、ログ記録についてです。
API Gatewayのログを有効化するとAPI Gatewayへのリクエスト、レスポンスがすべてログに記録されます。原則すべてログ出力されるので、料金は高くなりがちです。ただ、もしLambda側でログを一切出力していないと、何か問題が起きた時にログが一切なくて、調査ができない、ということにもなりかねません。この辺りは料金との兼ね合いですが、運用を見据えるのであれば、API Gatewayのログ記録を有効にすることも検討してもよいと思います。
最後にX-Rayについては必要に応じて有効化してください。
大規模な分散型アーキテクチャを採用している場合は有効化すると便利ですが、料金もかかるので注意ください。
Appendix
ログの保存先としてのCloudWatch Logs, S3の使い分け
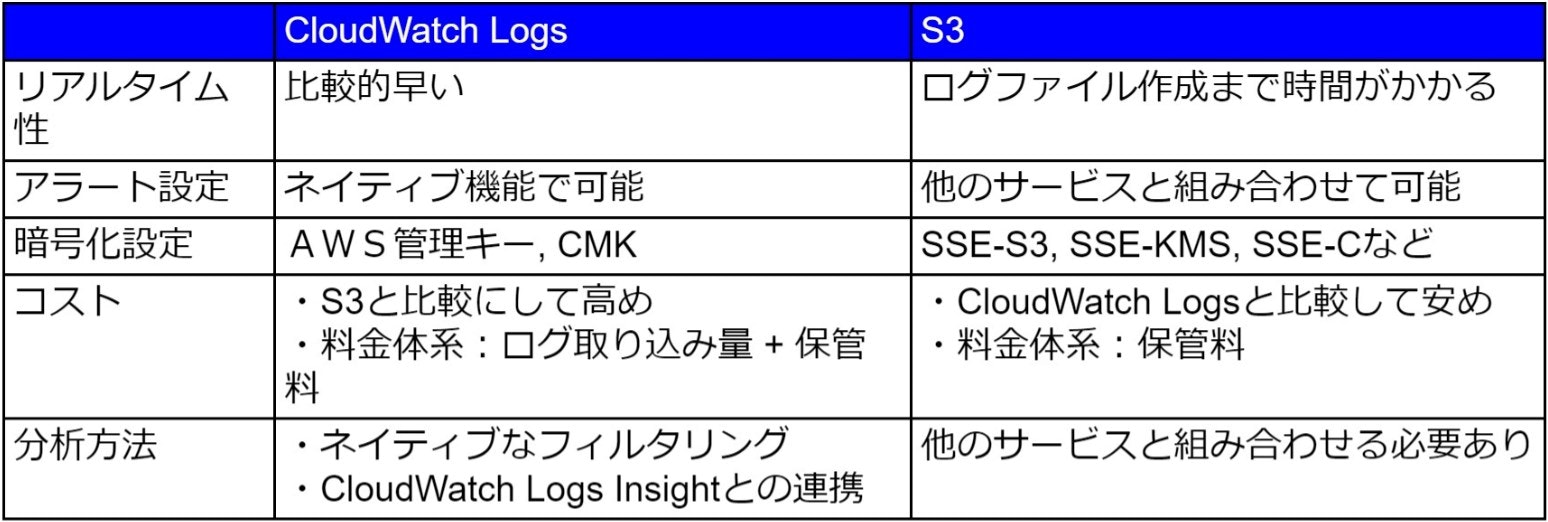
❑ 料金比較(月に100GBのログを1か月保管すると仮定)
- S3: Total 2.5 USD
- データ保管料: 100 GB * 0.025 USD = 2.5 USD - CloudWatch Logs: Total 79.3 USD
- データ取り込み料: 100 GB * 0.76 USD = 76 USD
- データ保管料:100 GB * 0.033 USD = 3.3 USD
ログの保存先としてのCloudWatch Logs, S3の使い分け
- S3: 何かあった時のために保管したい(長期保管用)
- CloudWatch Logs: ログ監視に使用する
CloudWatch Logsの料金
CloudWatch LogsはS3と異なりデータ取り込み料も発生しますので、S3と比較してかなり高めのコストが発生します。
ログ管理で推奨される重点対策
NISTのコンピュータセキュリティログ管理ガイドによれば、以下の項目に関して重点的な施策を実施することが推奨されています。自前ではなくAWSサービスを活用することで、下記の項目に対して実施しなければならないタスクが大幅に軽減できます。
- 組織全体のログ管理に適切な優先順位付けを行う
- ログの記録・監視要件と目標を明確に定める
- ログ管理に関するポリシーおよび手順を確立する
- 首尾一貫した取り組みを確実にする
- ログ管理インフラストラクチャを構築および維持する
- ログファイルの完全性・機密性を保持できるインフラストラクチャを構築する
- 膨大な量のログにも対応できるだけの余裕を持った基盤とする
- ログ管理の各種責任を担うスタッフに対して適切な支援を提供する
- 目標にあったログ管理ツールを用意する
- ログ管理を担当するスタッフに必要なトレーニングを施す
AWSで取得すべきログ
- Must: 取得しなければならないログ
- AWS CloudTrail
- AWS Config
- Should: 利用している場合、取得すべきログ
- VPC Flow Logs
- CloudFront/ELB/S3 Access Log
- API Gateway
- Lambda
- May: 他にも取得方法はあるが、AWSで取得したら便利なログ
- OSログ
- Windowsイベントログ
- /var/log/messages
- ミドルウェアログ
- MySqlのError・監査ログ
- OSログ
ログ出力の設計指針
ログ出力は、5W1Hにもとづいて設計するとよいといわれています。
例えば、次のような項目をログに出力するようにします。
| 項目 | 内容 | 備考 |
|---|---|---|
| 時間 | ログを記録した時間 | 年月日時分秒ミリ秒 |
| ID | イベントのID | 一連のイベントを関連づけるために必要 |
| ログレベル | ログのレベル | INFOやWARNなど |
| ユーザー情報 | リクエストしたユーザーの情報 | ユーザーIDやIPアドレスなど |
| リクエスト対象 | どこにリクエストしたか | URLなど |
| 処理内容 | どんな処理を行なったか | 参照や更新、削除など |
| 処理対象 | なにを処理したか | リソースのIDなど |
| 処理結果 | 処理した結果どうなったか | 成功または失敗、処理件数など |
| メッセージ | その他出力したいこと | - |