はじめに
サーバーレスに触れて数年が立ちました。
そろそろ人にある程度説明ができるレベルの知識と経験が備わったような気もするので、年末なのでまとめてみました。
サーバーレス気になっているけれども、という人に少しでもためになればいいなーと思います。
サーバーレス基礎
皆さん、サーバーレス設計という話を聞いたことはあるでしょうか?
まずサーバーレスについて説明しますが、世の中にはたくさん解説記事があるのでそちらも適宜参照ください。
- サーバーレスでも実際にはサーバーは存在する
- サーバーレスとは開発者がサーバーのことを意識しなくてもよい、ということ
- Function as a serviceに代表されるように、あるプログラムの実行環境を提供するが、プログラムの動作環境は開発者は意識する必要はない、というイメージ
恐らく、AWS Lambdaが一番理解しやすいと思います。
AWS Lambdaではプログラムの実行環境が提供されます。
PythonやNode.jsの環境が提供されるので、プログラムをすぐ実行することができ、実行した時間だけ課金されます。
サーバーレスのメリットは以下かと思います。
- 料金が安くなる
- 使った時間分の課金のため
- 保守のコストが下がる
- 実行環境等のメンテナンスをしなくてもよい
- スケールが簡単
- サービスが疎結合になるため修正の際の影響範囲が限られる
- AWS Lambdaなどは実行する環境がそれぞれ異なる
料金に関しては先に説明した通り、従量課金なので例えばEC2を常時稼働している、よりも断然安くなります。
保守コストに関しても、例えばPythonの実行環境を準備しようと思うと、サーバー準備してPythonインストールして、マイナーバージョンのアップデート対応して、不具合が起きたら対応して、などをしないといけません。
ただ、AWS Lambdaの場合はすべてAWS側がやってくれるので開発者はそのことを一切考え無くてもいいです。
スケールに関しては、例えばEC2の台数を増やす、ということを考える場合、単純に料金が倍になりますし、オートスケールやルーティングなどを考えないといけません。
Lambdaの場合、関数のメモリ数を画面から上げるだけでパフォーマンスを上げることができますし、Lambdaの実行上限に達しそうな場合は、上限緩和申請をすることで上限を増やすことができます。
つまり、LambdaのスケールはEC2に比べると断然楽です。
サービスの疎結合については、Lambdaの場合は処理Aと処理Bが完全に別の環境で実行されます。
なので、たとえ処理Aで無限ループなどで大量のリソースを使ったとしても処理Bに影響しません。
処理Aと処理Bが完全に分離されているので、処理Aのロジックの修正も安心です。
サーバーレス設計具体例
ここで少し疑問に思うかもしれません。
プログラムを実行できる環境を提供されたとして、そんなに有益なのか?、プログラムが一つ動いたところでどうなるのか?、Lambdaでプログラムが動くからと言ってサービスを作ることなんかできるのか?と。
システムを作ろうと思うと必要になるのは、APIサーバー、DBサーバーなどだと思います。
画面から必要な情報をサーバーに問い合わせる、もしくは必要な情報をサーバーに送信する、サーバーはデータをDBに保存、DBから取得する、という構成です。

EC2上にAPIサーバーを構築し、そこにビジネスロジックを実装、RDSに静的なデータを保存する、という構成です。
ほとんどの場合この構成でシステムの作成が可能です。
ただし、ほんとにこの構成が最適解でしょうか?
EC2を利用すると稼働している間ずっと課金されますし、サーバーのメンテナンスは自分でしないといけません。
APIサーバーはほとんどの場合常にAPIが呼ばれていることはないでしょう。
下手をすれば1日の中で朝だけしかAPI呼ばれていない、ということもあるかもしれません。
コスト最適化の観点から考えると、以下が理想だと思うのではないでしょうか。
- API呼ばれた時だけの課金にしたい
- できればEC2の運用は避けたい
この解決策が、サーバーレス設計になります。
以下の構成を見てください。
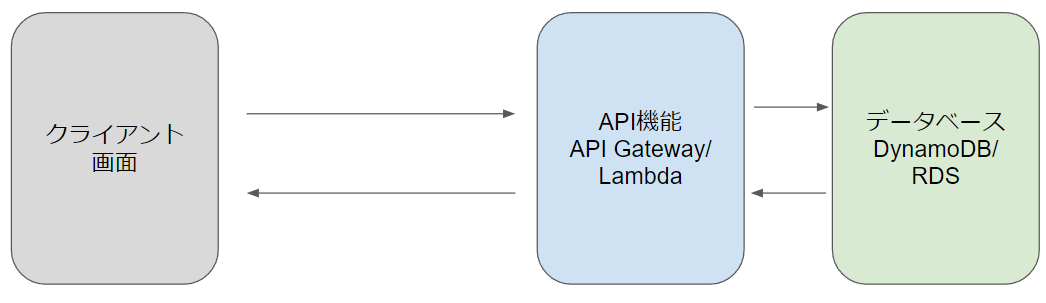
EC2の部分が、API Gateway+Lambdaに置き換わっています。
API GatewayとはAPIサーバーの機能を提供するサービスです。
例えば、REST APIの場合、API呼び出しのエンドポイントや呼び出す際のメソッド(GETやPOSTなど)が決まれば、APIの呼び出しができます。
その部分をAPI Gatewayは担当します。イメージとしてはNode.jsのExpressの部分を丸っと提供しているイメージですね。
次に、Lambda上にビジネスロジックを記載します。
API Gatewayに対してAPI呼び出しがあると、そのパスに紐づくLambdaが実行されます。
このLambdaは様々なサービスと連携することができるので、サーバーレスが成り立っています。
つまり、Lambdaからデータベースへのアクセスができるので、DBからのデータ取得、DBへのデータ書き込みができるのです。
では、API呼び出しの一連の流れの具体例を見てみましょう。
-
https://xxx.yyy/userへGETメソッドでユーザデータの取得をする -
https://xxx.yyy/userへGETにアクセスがあると、API Gatewayは対応するLambda関数を呼び出す - Lambda関数はPythonでビジネスロジックが実装されており、DBから必要なデータを取得し、整形してデータを返す
もちろん、上記はEC2を使っても同じことはできます。
ただし、API Gatewayを使うことでAPI部分のミドルウェアを開発者が管理する必要がありません。
画面から操作するだけでAPIサーバーの部分が自動的に作成され、開発者が意識するのはAPI呼び出し後のLambdaの部分のみです。
API Gatewayの課金も、APIの呼び出し時のみなので、APIが呼ばれなければ料金はかかりません。
Lambdaも従量課金なのでAPIが呼ばれなければ料金はかかりません。
RDSは時間課金ですが、DynamoDBの場合は、オンデマンドキャパシティを使うことで料金を最大限まで低く抑えることが可能です。
補足:マネージドサービス/責任共有モデルについて
AWSには責任共有モデルという考えがあります。
どこまでAWSが担当してどこから開発者が担当するのか、ということです。
例えば、EC2であればネットワークの配線どうするのか、サーバーどこに置くのか、というのはAWSが面倒を見てくれますが、OSのアップデートなどは開発者が面倒を見ないといけません。
マネージドサービスといってもどこまでAWSが面倒を見てくれるのかをしっかりと理解しておかないと足元をすくわれます。
よくAWSではフルマネージドサービスとして紹介されるサービスもあります。
例えば、DynamoDBはフルマネージドなKey-Valueストレージであり、ほぼすべての部分をAWSが面倒を見てくれます。
開発者はサーバーがどこにあるのか、冗長構成どうするのかなどは一切考えなくてもよいです。
できるだけ運用のコストを減らすためには積極的にフルマネージドなサービスを選択するのが良いと思います。
ただし、フルマネージドな場合、開発者ができることが限られるため、その点は注意が必要です。
例えばDynamoDBの場合は、DynamoDBが提供している機能しか使えません。
こういう機能が欲しいなと思っても、その範囲の中でうまく工夫するしかありませんし、提供されていないことはできない可能性もあります。
補足:モノリスとマイクロサービスアーキテクチャ
よくモノリス(モノリシック)、とマイクロサービスアーキテクチャが比較されると思います。
サーバーレス設計はマイクロサービスアーキテクチャの一種と考えています。
なので、そちらについても補足します。
モノリシックなアーキテクチャでは、機能的に区別できるシステムのさまざまな側面(たとえば、データの入力と出力、データの処理、エラーハンドリング、ユーザーインターフェイスなど)が、アーキテクチャとして別々のコンポーネントに分離されているのではなく、すべてが1つに組み合わされたものとなっている(Wikipedia引用)
EC2上でAPIサーバーを構築する場合を考えてみましょう。
- EC2環境構築
- VPC作成
- OSに必要なソフトインストール
- などなど
- APIサーバー構築
- ExpressなどでAPIサーバーの実装
- DB呼び出しなどのビジネスロジック実装
モノリスの場合、それぞれが一つにつながっているので、それぞれがそれぞれで影響します。
例えば、EC2の環境でVPCの設定を触ると、APIサーバーへの接続ができなくなったり、あるビジネスロジックを修正してエラーが起きると、そもそもAPIサーバーの常駐プログラム自体の起動に失敗してすべてのAPIに接続できなくなったり、、、、
では、マイクロサービスアーキテクチャの場合はどうなるのかというと、それぞれの責任範囲が明確に分離されています。
- API部分はAPI Gatewayが担当、かつ、それぞれのリソースは原則独立
- ビジネスロジックはLambdaが担当、かつ、それぞれのLambda関数は独立
例えば、API Gatewayのあるリソースの設定を変更しても、原則他のリソースへは影響しませんし、あるLambda関数のロジックを修正しても、他の関数には影響しません。
システムは人が想像する以上に複雑で難解な存在です。
できる限りシンプルにしないと、ある修正が思わぬところに影響して修正が怖くてできない、ということが起きます。
気軽に修正ができないと、システムはどんどん陳腐化していきます。
システムはできる限り修正しやすい状態にする必要があり、そのためにそれぞれのサービスを疎結合にして影響範囲を限定しよう、という考え方がマイクロサービスアーキテクチャの考え方です(多分)。
サーバーレスの注意点
これまでサーバーレス設計のいい部分にフォーカスしてきましたが、もちろん気を付ける部分もあります。
主に問題になる部分にフォーカスして説明します。
- 速度面
- セッション管理
- 冪等性/トランザクション
- 呼び出し順序
まず、速度面ですが、マイクロサービスの特性上、サービス間の連携部分に時間がかかります。
例えば、API Gateway+Lambdaの場合、API GatewayからLambdaにデータが渡り、Lambdaから再度API Gatewayにデータが渡るので、一定の遅延が発生します。
EC2で構築した場合は、その部分の遅延が発生しません。
また、Lambdaはコールドスタートという別の問題もあり、初回のAPI呼び出しに1秒ほどかかることがあります。
システムとして何を優先するかはそれぞれだと思いますが、サーバーレス設計、マイクロサービスの場合はモノリスと比較すると余計な時間がかかる、ということは意識しておくとよいと思います。
次にセッション管理に関してです。
サーバーレスアーキテクチャの場合は、ステートレスな構成である必要があります。
ステートレスとは前の状態を一切保持しない、保持できないという意味になります。
例えば、EC2の場合はDBから取得したデータをローカルに保存して、適宜参照する、ということができます。
これによりDBへのアクセス負荷を減らすことが可能ですし、DB呼び出しが不要なので速度面でも早くなります。
ただ、Lambdaの場合、API呼び出しごとに環境が異なる、新規作成される可能性があるので、常に必要なデータをDBから取得しなければいけません。
短時間に2回API呼び出しが発生したとしても、前のAPI呼び出しの際のデータは保存できず、前のAPIのデータを取得したい場合は、一度DBにデータを入れて、DB経由でデータ取得しないといけません。
つまり、ローカルにデータを保存する、ということができないため、DBへのアクセスが多くなりがち、ビジネスロジックが複雑になる可能性があります。
次は冪等性/トランザクションについてです。
冪等性とは「ある操作を1回行っても複数回行っても結果が同じである」という考え方です。
例えば、Lambdaの場合、処理が失敗すると同じ処理が複数回実行される可能性があります(今は回避可能かも)。
購入の処理に失敗して同じ商品が複数購入されてしまった、ということが起きると大変ですよね。
つまり、購入の処理が複数回実行されても同じ商品が1回だけ購入される必要があります。
そのためには、冪等性が担保されている必要があるわけです。
処理A(サービスAで実装)→処理B(サービスBで実装)→処理C(サービスCで実装)のような構成の場合、例えば処理Bで失敗した場合は、冪等性を担保するために処理Aの処理を元に戻さないといけません。
そうすることで、再度実行しても同じ結果になるからです。
ただ、ロールバックの処理はそう簡単ではありません。
つまり、マイクロサービスの場合トランザクション処理が苦手ということになります。
ここはトレードオフの関係かと思います。
マイクロサービスにすることでそれぞれの責任範囲が限定されるが、サービスを分けることでトランザクション処理のような一貫性が求められる場合、ロールバックすることが難しい、もしくはロールバックができないというジレンマが発生します。
最後に呼び出し順序についてです。
サーバーレス設計の原則は非同期です。
順序は原則保証されません。
例えば、APIが2回呼ばれた場合、その順序は保証されません。
リクエストAが先に呼ばれて、その後リクエストBが呼ばれたとしても、必ずリクエストAが先に完了するとは限りません。
ただ、呼び出し順序を保証するためのサービスもあるので、それらのサービスをうまく組み合わせることで対応することは可能ですが、原則として非同期でそれぞれが独立して動く、ということは考慮しておく必要があります。
テストコード実装戦略
サーバーレス設計ではビジネスロジックは原則Lambdaに記述します。
また、それぞれの関数が疎結合なのでテストコードは比較的書きやすいです。
ただ、いくつかTIPSがあるので紹介します。
モックについて
Lambdaの中でDBにデータを追加、データの参照をしている場合のテストコードはどうしたらいいでしょうか?
Pythonの場合はmotoというライブラリを利用するのが便利です。
実際のDynamoDBからのデータ取得と同じような感じでデータ取得が可能です。
pytestのパッチ機能と組み合わせると、非常に高品質なテストコードを書くことができます。
テストコードの競合について
例えばDynamoDB LocalのようなDocker環境にAWSのサービスを疑似的に構築するようなサービスをモックとして利用する場合、テストコードの修正が競合する場合があります。
例えば、あるテストコードを修正するとDBの値が変更され、そのDBは別のテストコードでも参照していて、別のテストコードがこける、などです。
テストコードの開発体験が低いと、テストコードの修正が億劫になり、テストコードの品質が落ちます。
個人的なベストプラクティスとしては、上述のmotoを使ってテスト関数ごと(pytestのfixtureの機能を利用)にDBを初期化してテストコードの競合が発生しないようにしています。
これにより、それぞれのテストコードごとに必要なデータをDBに追加する必要がありますが、どのテストでどのデータを使っているのかが分かりやすくなるため、手間をかけてもよい部分だと思っています。
テストコードでDBを共有するとテストコードの量が多くなるにつれて、依存関係が膨れ上がり、テストコードを一つ修正するとあらゆるテストコードを修正しないといけない、ということが起きる可能性があります。
Infrastructure as Code/デプロイ自動化
Infrastructure as Code(IaC)とは、環境をコードで実現する方法です。
例えば、API Gateway+Lambdaを作る場合、画面から作成してもいいのですが、同じ環境をもう一つ作成する場合、作業時間が倍になる、人が作成するとミスが起きるリスクなどがあります。
そこで、コードでサービスを作成するようにすることで、同じ環境を簡単に作成することができます。
IaCのメリットデメリットは以下だと思います。
メリット
- 同じ環境が簡単に複数作成できる
- 誰が実行しても同じ環境ができる
デメリット
- IaCのツールの習得に時間がかかる
- AWSの場合はCDKやTerraformなど
- 画面から操作するのと比較すると時間がかかる
- プロジェクトの作成、コードの実装が含まれるため
Infrastructure as Code(IaC)を導入すべきかどうか
IaCは導入すべきだと思います。
ただし、初回はある程度の投資が必要です。
CDKの習得、ある程度ノウハウがたまるまでは数か月程度かかると思います。
ただし、それだけの時間をかけても、導入する価値はあると思います。
最近の開発では、本番環境と開発環境を用意するのは当たり前になっていると思います。
特に、クラウドの場合は圧倒的に料金が安い、環境の作成や削除が簡単になりました。
できる限り本番と同じ環境でテストするために、本番と同じ構成でもう一つ環境を作ることが多いと思います。
そうなると、手動で作成して開発環境と同じ設定でほんとに本番環境を作ることができると思いますか?一度できたとしても、今後もミスなく設定変更ができるという自信がありますか?
IaCは初期コストは高めですが、必ずメリットの方が上回ると思いますのでぜひ導入を検討ください。
デプロイ自動化
IaCを導入した後の話になりますが、デプロイも自動化すべきです。
AWSの場合、CodePipelineを使うと、プルリクエストのマージ、承認、デプロイまでを自動化できます。
また、デプロイの通知をSlack等へ連携することでデプロイ完了やデプロイの失敗に迅速に気が付くことができます。
開発者は忙しいです。
できるだけ手動の作業は自動化して時間を確保しないと、いつまでたってもその人の作業は減らないし、属人化した状況から抜け出せなくなります。
また、デプロイ時にテストコードの実行を含めるのもよいと思います。
テストコードが失敗したときはデプロイしない、ということができます。
デプロイ自動化も初回のコストはかかりますが、最終的にはメリットが上回ると思いますので、ぜひ導入を検討ください。
ログ戦略
マイクロサービスの場合、ログ戦略がとても重要になってきます。
何か障害が発生したときに、原因はどこにあるのか、ということを迅速に見つけないといけません。
ただし、複数のサービスから構成されているため、ログ戦略を間違えると、ログが無く調査自体がそもそもできない、ということが起きる可能性があります。
ただし、AWSの場合は何でもかんでもログを出力すればよい、という話ではありません。
ログを出力すると当然料金がかかるからです。
つまり、適切なログのみを出力する必要があります。
Lambdaのログ戦略
開発環境と本番環境でログ出力の内容を変えるのはよい選択だと思います。
いわゆるINFOログやDEBUGログなどの使い分けですね。
Lambdaの場合、環境変数にログレベルを設定して、コードでは環境変数を取得して切り替えるのが一番スマートかと思います。
ただ、一番問題なのは何をINFOにして何をDEBUGにするのか、ということかと思います。
ここはビジネスロジックごとに異なるためなかなか難しいのですが、個人的なログ戦略は以下で定義しています。
- INFOログ
- Lambda関数へ渡ってきた値、APIのリクエストボディなど
- IF条件でどのIFに入ったかどうか(ただし、IFすべてではなく重要なものに限定)
- DBのクエリ内容
- WARNINGログ
- 各種バリデーションのログ
- ERRORログ
- トレースバックログ(Pythonの場合はtraceback.format_exc)
API Gateway
APIには詳細メトリクスの記録、ログ記録、X-Rayの有効化の設定があります。
まず、詳細メトリクスの記録はオンにするのがいいと思います。
API Gatewayで例えば400でレスポンスが返る場合、Cloudwatch メトリクスでも400レスポンスが記録されます。
ただし、詳細メトリクスがオフになっていると、どのAPI呼び出しで400エラーが返ったのかまでわかりません。
詳細メトリクスをオンにすることで、どのリソースのどのメソッドが400エラーを変えているのかがわかるので、迅速に調査することができます。
次に、ログ記録についてです。
API Gatewayのログを有効化するとAPI Gatewayへのリクエスト、レスポンスがすべてログに記録されます。
原則すべてログ出力されるので、料金は高くなりがちです。
ただ、もしLambda側でログを一切出力していないと、何か問題が起きた時にログが一切なくて、調査ができない、ということにもなりかねません。
この辺りは料金との兼ね合いですが、運用を見据えるのであれば、API Gatewayのログ記録を有効にすることも検討してもよいと思います。
最後にX-Rayについては後述しますが、有効化しておくとよいと思います。
が、もちろん料金はかかりますので注意して下さい。
モニタリング/運用監視
AWSの各種サービスはメトリクスをCloudWatchに送信しています。
例えば、Lambdaであれば呼び出し回数や失敗の回数などです。
システムを安定して運用するためにはそれぞれのメトリクスを監視する必要がありますが、常に画面に張り付いているわけにもいきません。
いくつかのTIPSを紹介します。
ダッシュボードの作成
運用監視用のダッシュボードを作成するのはよい方法です。
ダッシュボードを見るだけで、必要な情報すべてを見ることができるからです。
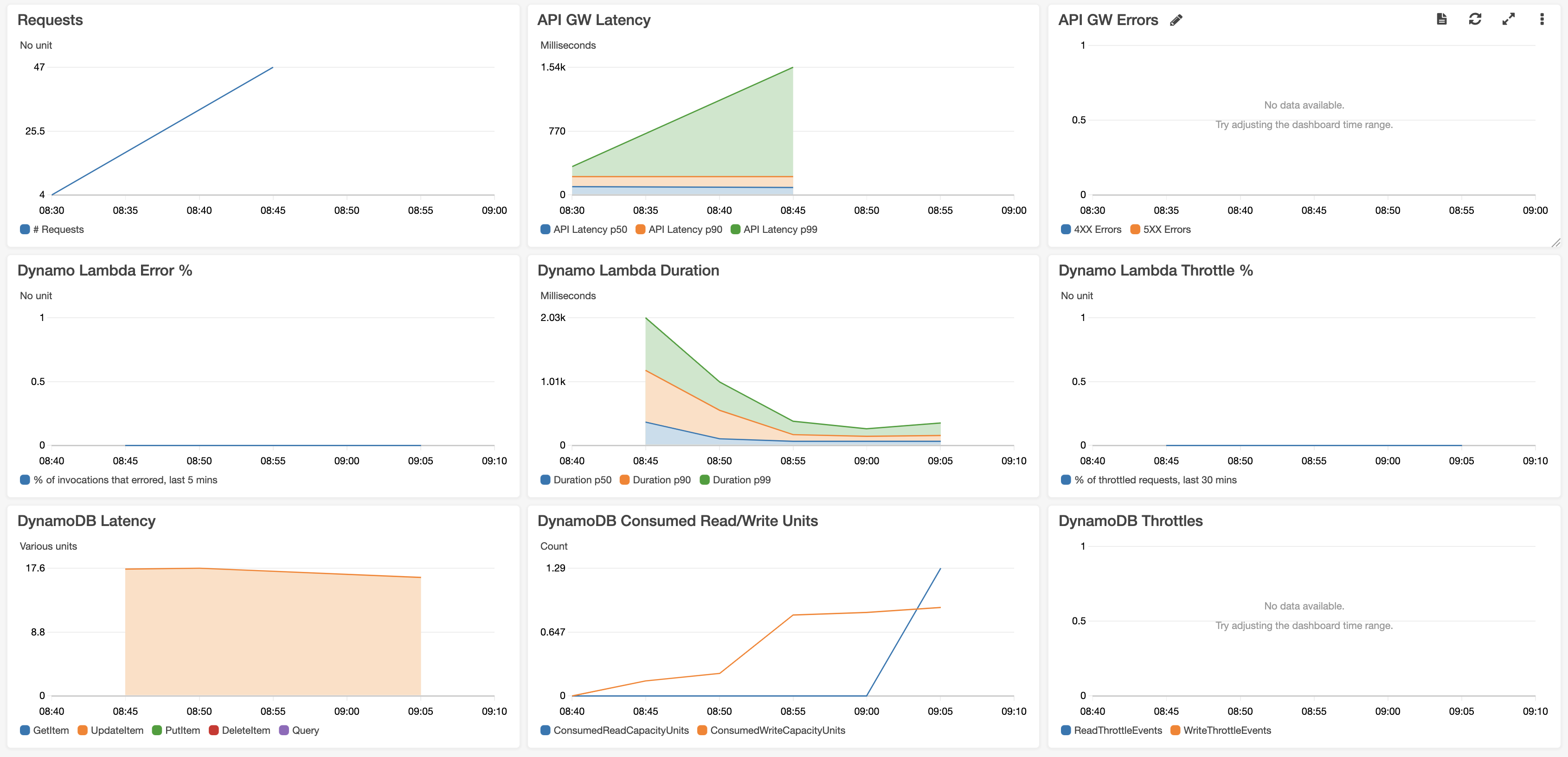
(画像は右記から引用:https://github.com/cdk-patterns/serverless/raw/main/the-cloudwatch-dashboard/img/dashboard.png)
例えば、APIの呼び出し数がどんどん増えている、RDSのパフォーマンスが限界、などに早期に気が付くことができます。
また、Lambdaの実行時間を表示することで、呼び出し時間が長いLambda関数のチューニングの検討もできるかもしれません。
ダッシュボードの作成もIaCすることで、一度ダッシュボードを作ることで、別の環境でもその構成を使いまわることができます。
エラー通知の実装
例えば、APIが500エラーを返したとき、Lambdaの実行が失敗したときはシステム側で何かしらの障害が発生している場合が多いです。
ただし、エラーの際に通知がされないと、システムに不具合が発生していても気が付きません。
利用者からの問い合わせで初めてシステムの不具合に気付く、ということが起きて利用者の満足度が低下する要因になりかねません。
そこで、エラーが起きた時にSlackへ通知する、などを設定しておけばシステム側の障害に迅速に気が付くことができます。
AWSの場合はCloudWatch Alarmを設定することで実現できます。
何を設定するのかは要件次第だと思いますが、以下は必要かなと思っています。
- API Gatewaの500エラー
- Lambdaのエラー
- DBのキャパシティエラー
X-Rayの導入
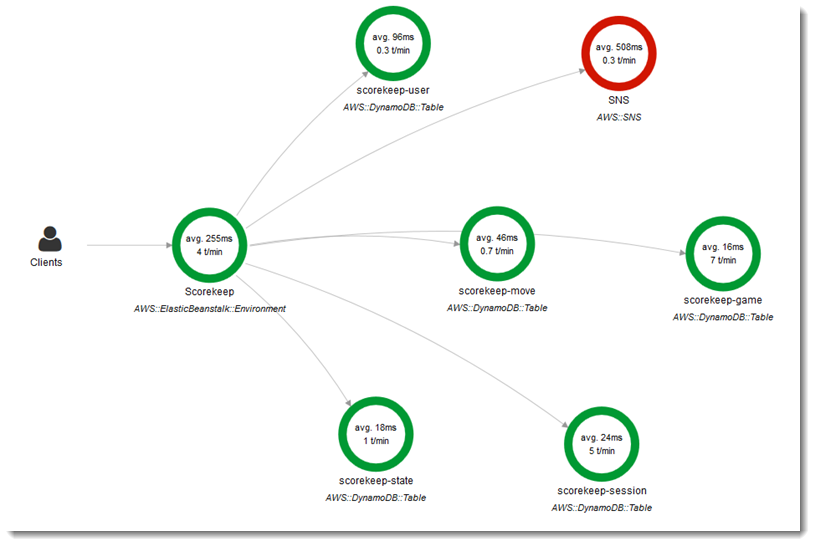
(画像はAWS公式から引用:https://docs.aws.amazon.com/ja_jp/xray/latest/devguide/images/scorekeep-gettingstarted-servicemap-before.png)
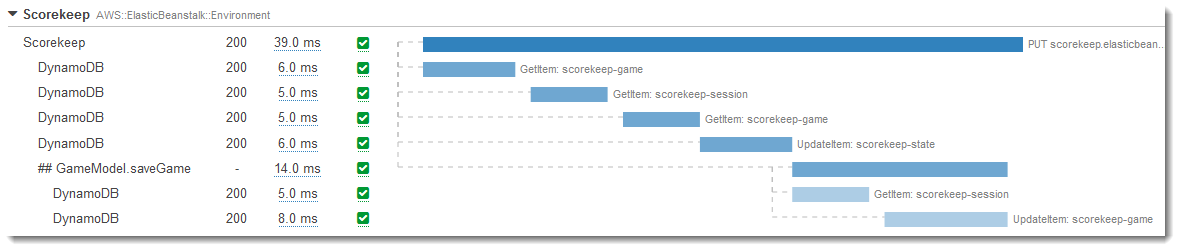
(画像はAWS公式から引用:https://docs.aws.amazon.com/ja_jp/xray/latest/devguide/images/scorekeep-PUTrules-timeline.png)
X-Rayを導入することで上記画像のようにどのようなサービスと連携しているのか、そのサービスの呼び出しにどのくらいの時間がかかっているのかがわかります。
上記画像はElasticBeanstalkの例ですが、Lambdaもほぼ同じような形で表示されます。
これにより、Lambdaが実際にどのサービスと連携しているのか、実際にどのサービスでエラーとなっているのかが可視化されて、調査が容易になります。
なお、LmabdaでX-Rayの連携を有効化する場合、Lambda関数のトレースを有効化する、コードにX-Ray SDKの実装を追加する必要がありますので注意してください。
API Gatewayの場合は、トレースの有効化のチェックをつけるだけで有効化できます。
実際にX-Rayを有効化しておくとどういう場合に使えるのか、を紹介します。
例えば、APIで500エラーが発生した場合にSlackに通知が来たとします。
その通知にはAPI名が記録されていますが、どのメソッドかどうかはわかりません。
そんな時にX-Rayが有効になっていれば、APIの500レスポンスの呼び出し、という条件で検索することができます。
X-Rayが有効化されていない場合は、CloudWatch Logからレスポンス500のログを見つけて、そのAPI呼び出しを見つけて、Lambdaをたどって、という作業が必要になります。
また、最近の機能で追加された「ServiceLens でのトレースビュー」も便利です。
X-Rayの画面での検索と違い、リソース名で絞り込めるのがお気に入りです。
また、各サービスのログが結合されて表示されるのもポイント高いです。
例えば、あるLambda関数が関係するX-Rayのログを検索することもできますし、API Gateway+Lambdaの構成の場合、API GatewayのログとLambdaのログの両方が一画面で見ることができます。
X-Rayを有効にしているのであれば、X-Rayの画面から見るよりもServiceLensで見るほうが良いと思います。
CloudWatcch Log
ログ調査といったらCloudWatch Logからは逃れることはできません。
利用頻度が高いのでできるだけ効率よくログの調査をするのが大切です。
過去のログを検索する場合はCloudWatch Logs Insightsの利用が便利です。
ただし、CloudWatch Logs Insightsはクエリ実行ごとに料金がかかるので注意が必要です。
ポイントはできるだけ期間を絞ってクエリを実行することです。
Like検索(あいまい検索)もできるので、柔軟に検索ができるので便利ですので、料金の部分のみ注意していれば問題ないと思います。
なお、CloudWatch Logs Insightsでの検索を意識してログを出力しておけば、CloudWatch Logs Insightsでログの内容をparseしての絞り込みもできます。
(例えば、ログの出力がJSON形式で、{"userID": "test"}のような形の場合、検索条件でuserID = testのようなイメージでクエリの実行ができる)
ただ、あいまい検索が便利なのでそこまで意識しなくてもいいかもしれません。
最後に
いろいろ書きましたが、サーバーレス構成の場合は運用コストが下がる場合がほとんどです。
ただ、初回の学習コストがかかる、注意点がいろいろある、などの懸念点もあると思います。
何でもかんでもサーバーレスにすればいいというわけでもなく、その時々のベストな選択をしていく際の選択肢の一つとして考えてもらえればと思います。
サーバーレスをうまく取り入れることで、開発者が少しでもハッピーになれればいいなーと思っています。