はじめに
- データ分析実務において、前処理や集計・可視化後によく行う分析手法をまとめました
- 前処理編とデータ集計・可視化編の続きです
- ここでいう「実務」とは機械学習やソリューション開発ではなく、アドホックなデータ分析や機械学習の適用に向けた検証(いわゆるPoC)を指します
- 領域によっては頻繁に使う手法は異なるかと思うので、自分と近しい領域のデータ分析をしている方の参考になればと思います
今回紹介する分析手法
- パレート分析
- 線形回帰
- 時系列解析(季節成分分解)
- 時系列解析(時系列データの相関)
- ランダムフォレストによる特徴量の重要度
1. パレート分析
- 対象データ:カテゴリカルデータ
- 用途:各カテゴリの全体に対する構成比率
- ケーススタディ:製品カテゴリ別の売上データ(A~H)に対して、各製品カテゴリの売上傾向を把握したい
サンプルデータの生成
A = np.repeat('Cat_A', 15)
B = np.repeat('Cat_B', 5)
C = np.repeat('Cat_C', 135)
D = np.repeat('Cat_D', 23)
E = np.repeat('Cat_E', 86)
F = np.repeat('Cat_F', 44)
G = np.repeat('Cat_G', 13)
H = np.repeat('Cat_H', 3)
I = np.repeat('Cat_I', 3)
J = np.repeat('Cat_J', 2)
K = np.repeat('Cat_K', 2)
data = np.concatenate((A, B, C, D, E, F, G, H, I, J, K))
data = pd.Series(data)
# シンプルに集計し、可視化
plt.figure(figsize=(15, 3))
sns.countplot(data)
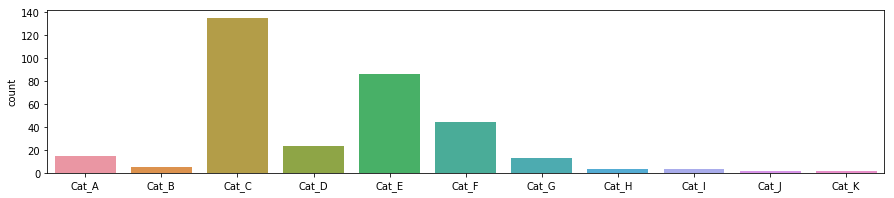
パレート図の作成
t = data.value_counts()# カテゴリ毎の合計
r = t/t.sum()# 割合に変換
r_ = r.cumsum()# 累積割合に変換
# 上記で集計したカテゴリ枚の合計(t)と累積割合(r_)を可視化
# 全体構成80%のボーダーライン
fig, ax1 = plt.subplots()
t.plot.bar(figsize=(15, 3), color='blue', ax=ax1)
ax2 = ax1.twinx()
r_.plot(figsize=(15, 3), color='orange', ax=ax2, marker='o')
plt.hlines(y=0.8, xmin=-1, xmax=len(t), lw=.7, color='indianred', linestyle='--')
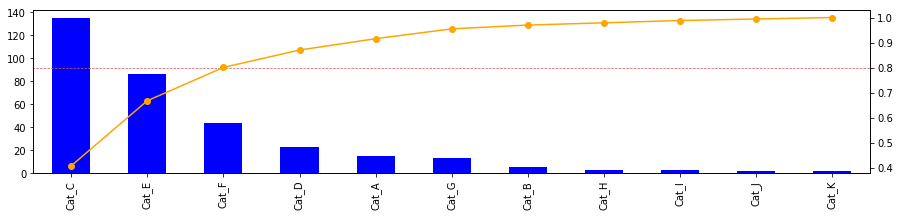
分析結果の解釈
- TOP3カテゴリの製品で全体売上の80%を構成している
2. 線形回帰
- 対象データ:数値データ
- 用途:数値データの関係性の把握や説明変数を基にした応答変数の予測
- ケーススタディ:ボストン住宅価格(skleatnのdataset)を予測する
サンプルデータの生成
# sklearnのボストン住宅価格のデータを利用
from sklearn.datasets import load_boston
boston = load_boston()
data = boston.data
# y(住宅価格)を予測する変数としてRM(部屋数)とDIS(職業訓練施設からの距離)を利用
y = boston.target
x1 = data[:, 5]#RM
x2 = data[:, 7]#DIS
# 各xとyの関係性を可視化
plt.figure(figsize=(10, 5))
plt.subplot(121)
plt.scatter(x1, y, s=4, alpha=.7)
plt.title('x: RM, y: Price')
plt.subplot(122)
plt.scatter(x2, y, s=4, alpha=.7)
plt.title('x: RM, y: Price')
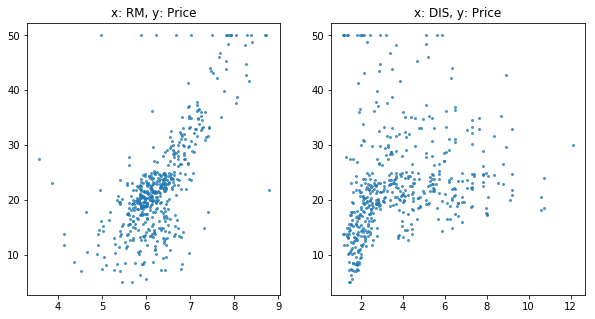
線形回帰
- 方法は色々とあるのですが今回は最も簡単なSeabornを利用
plt.figure(figsize=(10, 5))
plt.subplot(121)
sns.regplot(x=x1, y=y, ci=95, order=1,
line_kws={"linewidth": .7}, scatter_kws={'s': 4}, color='green')
plt.subplot(122)
sns.regplot(x=x2, y=y, ci=95, order=3,
line_kws={"linewidth": .7}, scatter_kws={'s': 4}, color='green')
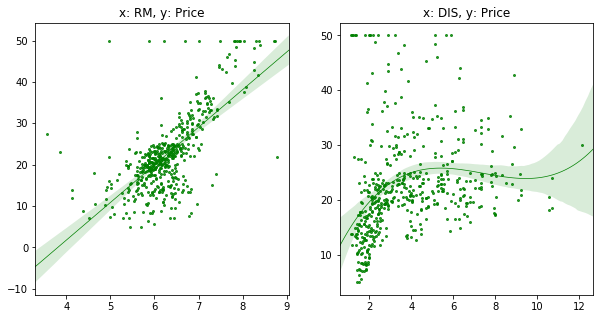
- sns.regplotの主要なオプション
- ci: 回帰の信頼区間(デフォルト95)
- oder: 回帰式の次数
- logistic: Trueにするとロジスティック回帰(デフォルトFalse)
3. 時系列解析(季節成分分解)
- 対象データ:時系列データ
- 用途:時系列データをトレンド・季節性・ノイズに分解
- ケーススタディ:時系列データのトレンドを抽出すうr
サンプルデータの生成
# 適当なノイズを加えた時系列データを作成
x = np.arange(0, 365)
y1 = np.sin(0.1*x)*5
y2 = np.sin(1*x)+5
y3 = np.sin(0.01*x)*10
n = np.random.rand(len(x))*50
y = y1 + y2 + y3+ n
# 時系列データの可視化
plt.figure(figsize=(15, 3))
plt.plot(y)
季節成分分解
- statsmodls.apiのtsa(time series analysis)モジュールを利用
import statsmodels.api as sm
res = sm.tsa.seasonal_decompose(y, freq=90)
# freq(feaquency)はデータ特性から任意に指定
- sm.tsa.seasonal_decomposeに入れると季節成分分解を実施
- res.trend(傾向)、res.seasonal(季節性)、res.resid(残差)にそれぞれの数値が入っている
- 以下で算出結果を可視化してみる(res.plot()でまとめて可視化することも可能)
plt.subplots_adjust(hspace=0.3)
plt.figure(figsize=(15, 9))
plt.subplot(411)
plt.plot(res.observed, lw=.6, c='darkblue')
plt.title('observed')
plt.subplot(412)
plt.plot(res.trend, lw=.6, c='indianred')
plt.title('trend')
plt.subplot(413)
plt.plot(res.seasonal, lw=.6, c='indianred')
plt.title('seasonal')
plt.subplot(414)
plt.plot(res.resid, lw=.6, c='indianred')
plt.title('residual')
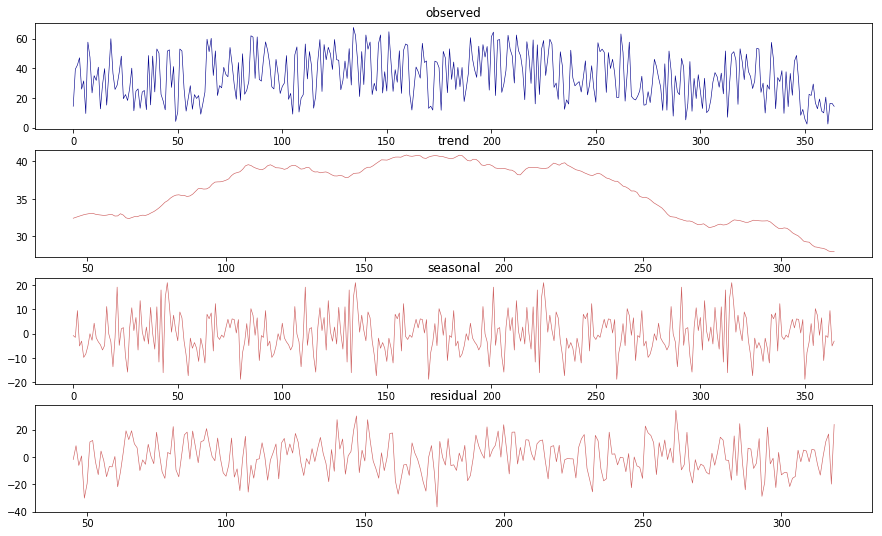
分析結果の考察
- オリジナルデータでは周期性やノイズにより傾向が見出しづらいが、季節成分分解を行うことで、上昇傾向から下降への傾向が見てとれる
4. 時系列解析(時系列データの相関)
- 対象データ:時系列データ
- 用途:時系列データには通常の相関係数が使えない為、残差を利用することで時系列データの相関係数を算出する
- ケーススタディ:複数の時系列があった際、相関のある時系列を発見したい
サンプルデータの生成
ts1 = y# ↑で生成した時系列データの再利用
y1 = np.sin(0.5*x)*5
y2 = np.sin(1.8*x)+5
y3 = np.sin(0.03*x)*10
n = np.random.rand(len(x))*10
ts2 = y1 + y2 + y3+ n
y1 = np.sin(0.4*x)*5
y2 = np.sin(1.3*x)+5
y3 = np.sin(0.013*x)*10
n = np.random.rand(len(x))*30
ts3 = y1 + y2 + y3+ n
y1 = np.sin(0.5*x)*5
y2 = np.sin(1.9*x)+5
y3 = np.sin(0.041*x)*10
n = np.random.rand(len(x))*10
ts4 = y1 + y2 + y3+ n
y1 = np.sin(0.26*x)*5
y2 = np.sin(1.38*x)+5
y3 = np.sin(0.05*x)*10
n = np.random.rand(len(x))*35
ts5 = y1 + y2 + y3+ n
# 5つの時系列データを可視化
plt.figure(figsize=(15, 3))
plt.plot(ts1, label='ts1', lw=.7)
plt.plot(ts2, label='ts2', lw=.7)
plt.plot(ts3, label='ts3', lw=.7)
plt.plot(ts4, label='ts4', lw=.7)
plt.plot(ts5, label='ts5', lw=.7)
plt.legend()
時系列データの相関マトリックスを生成
- 残差はsm.tsa.seasonal_decompositionを利用
- pandas.Dataframeに各残差を入れて、pd.Dataframe.Corr()で相関係数を算出
- seabornのheatmapで可視化
resid_mat = pd.DataFrame()
for ts in[ts1, ts2, ts3, ts4, ts5]:
res = sm.tsa.seasonal_decompose(ts, freq=90)
resid_mat = pd.concat([resid_mat, pd.Series(res.resid)], axis=1)
resid_mat.columns =[['ts1', 'ts2', 'ts3', 'ts4', 'ts5']]
plt.figure(figsize=(15, 5))
sns.heatmap(resid_mat.corr(), annot=True, lw=0.7, cmap='YlGnBu')
plt.title('Time series Correlation matrix')
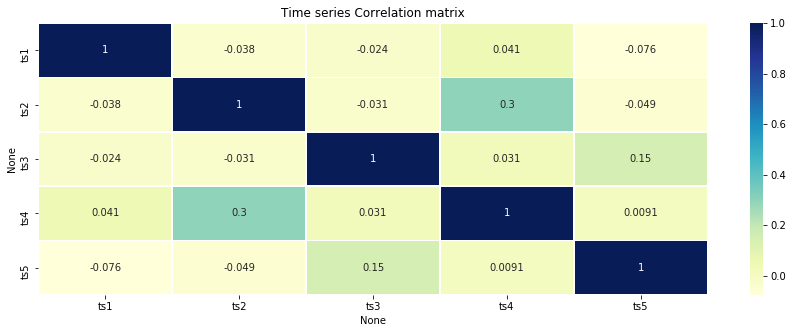
分析結果の考察
- 単純な可視化による目検だと発見しずらい時系列データの関係性を相関係数を算出することで発見することができる
5. ランダムフォレストを活用した特徴量の重要度
- 対象データ:数値orカテゴリカルデータ
- 用途:目的変数に対する各特徴量の重要度を把握したい
- ケーススタディ:irisのデータセットを利用して、目的変数(カテゴリ)の分類に対して、どの特徴量が重要度が高いのか明らかにする
サンプルデータの生成
from sklearn.datasets import load_iris
# Pandas のデータフレームとして表示
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
x = iris.data
y = iris.target
# 単純なirisデータのままだと面白くないので、特徴量にランダムの数値とカテゴリデータを追加
rand_num = np.random.rand(x.shape[0])
rand_num = rand_num.reshape(-1, 1)#axis=1に結合するため、次元を指定
rand_cat = (np.random.rand(x.shape[0])>0.5).astype(str)
rand_cat = pd.get_dummies(rand_cat).values#pd.get_dummiesでダミー変数へ変換し、valuesでnumpy形式へ
# オリジナルirisデータへ追加
x = np.concatenate((x, rand_num, rand_cat), axis=1)
# 特徴量のカテゴリ名を習得
feature_name = iris.feature_names
feature_name.append('rand_num')
feature_name.append( 'rand_cat_False')
feature_name.append( 'rand_cat_True')
ランダムフォレストによる特徴量重量度の算出
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# トレーニングデータをテストデータに分解
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.20)
# 学習
clf = RandomForestClassifier(n_estimators=20, random_state=42)
clf.fit(x_train, y_train)
# 予測データ作成
y_predict = clf.predict(x_train)
# 正解率の算出(今回は予測ではないので重要ではない)
accuracy_score(y_train, y_predict)
# 特徴量重要を抽出
feature_importance = clf.feature_importances_
# pandas.Dataframeへ変換して可視化
feature_importance = pd.Series(feature_importance,index=feature_name)
feature_importance.sort_values().plot(kind='barh', figsize=(10, 4), color='aquamarine')
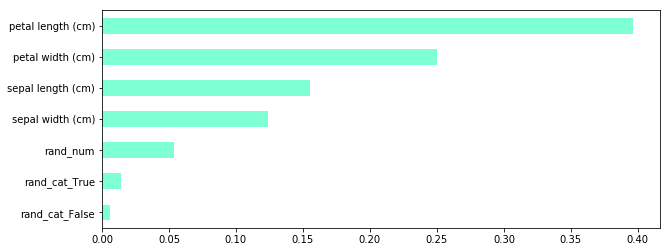
- 補足:pandas.Dataframe.plot(kind='')について
- ''を変更することで色々なグラフを出力できます
- 以下はよく使うグラフ
- 'line': 線グラフ
- 'bar': 棒グラフ
- 'barh': 横棒グラフ
- 'box': 箱ひげ図
- 'hist' : ヒストグラム
- 'kde': カーネル密度推定(KDE plot)
- 'scatter': 散布図
- 'pie': 円グラフ
分析結果の考察
- 分類に対して重要度の大きい特徴量を可視化することができた
- 追加した特徴量(ノイズ)についても特徴がないことが正しく示されている
さいごに
- データ分析をする際によく使う手法をまとめてみました
- 実際のビジネスでは今回のサンプルデータの様に綺麗ではないので、前処理が何より大変(重要)です
- 日々新たな分析手法が登場しているので、実務上で頻出するコードがあれば随時アップデートします