はじめに
- データ分析実務で頻繁に利用するPythonのデータ分析手法まとめです
- 前処理編の続きです
- ここでいう「実務」とは機械学習やソリューション開発ではなく、アドホックなデータ分析や機械学習の適用に向けた検証(いわゆるPoC)を指します
- 領域によっては頻繁に使う手法は異なるかと思うので、自分と近しい領域のデータ分析をしている方の参考になればと思います
- 今回はデータ集計&可視化の際によく使うコードをまとめました
データ集計&可視化
カテゴリデータの集計&可視化:Dataframe.value_counts()&plot.bar() or sns.countplot()
- 2つの方法があります
1. value_countsで集計してから、plot.barで可視化
- value_countsで集計すると件数が多い順にソートされる
data['n_interval'].value_counts().plot.bar(figsize=(15, 3), color='darkblue')
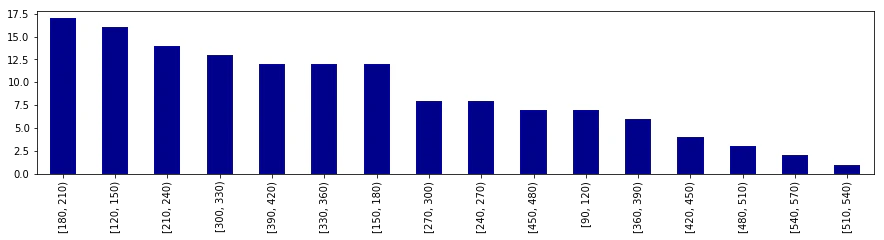
- 集計結果をデータとして保持しているので、関連処理が容易にできる
- よくあるパータンとして、累積構成比率のグラフとセットで見せる
fig, ax1 = plt.subplots()
data['n_interval'].value_counts().plot.bar(figsize=(15, 3), color='darkblue', ax=ax1)
ax2 = ax1.twinx()
ratio = data['n_interval'].value_counts()/ data['n_interval'].value_counts().sum()
ratio.cumsum().plot(figsize=(15, 3), color='lightblue', ax=ax2)

[補足]2軸プロット
- ax1.twinx()を使うことで、2軸プロットが作成できる
- 冒頭でfig, ax1 = plt.subplots()を指定しておくことで、Dataframe.plot()の結果がfig, ax1に格納される
- x軸をシェアしたいので、ax1.twinx()で共有する軸を生成して、ax2に格納する
- 2つ目のDataframe.plot()の軸を明示的にax=ax2とすることで2軸プロットの完成
2. seabornのcountplotで可視化
- seaboarnにはデータフレーム投げるだけで集計&可視化がされる
- 方法1との違いとして、ラベルの順番がカテゴリデータの順番を受け継ぐ
- カテゴリデータでない場合は1と同様に件数が多い順で出力される
plt.figure(figsize=(15, 3))
sns.countplot(data['n_interval'], color='darkblue')

時系列データの集計:pd.resample()
- 時系列データを任意の単位に集計する
- resampleの引数に以下のキーワードを入れると集計単位を指定できる
- resample('kw')以降に集計関数を指定できる(sum, count等)
| Key word | 集計単位 |
|---|---|
| W | Weekly |
| M | Monthly (Month end) |
| MS | Monthly (Month start) |
| A | Annually (Year end) |
| AS | Annually (Year start) |
| H | Hourly |
| S | Secondly |
data = data.set_index('Month')# resampleを使うために、DataframeのIndexにdatetime型のデータをセット
data['n'].resample('M').sum().plot(figsize=(15, 3), lw=.7)

複数のグラフを並べて表示する:plt.subplot()
- 可視化した結果を並べて比較する
- plt.subplot(abc)でグラフの配置を指定する
- a = 行数、b = 列数、c = 配置順番
- for文と組合せることでグラフの自動配置も可
- plt.subplotで可視化するとグラフが重なってしまうときは、plt.subplots_adjustで配置の幅を調整する
- wspaceがグフラ間の横幅を示し、hspaceがグラフ間の縦幅を示す
- デフォルトはwspace=0.2, hspace=0.2
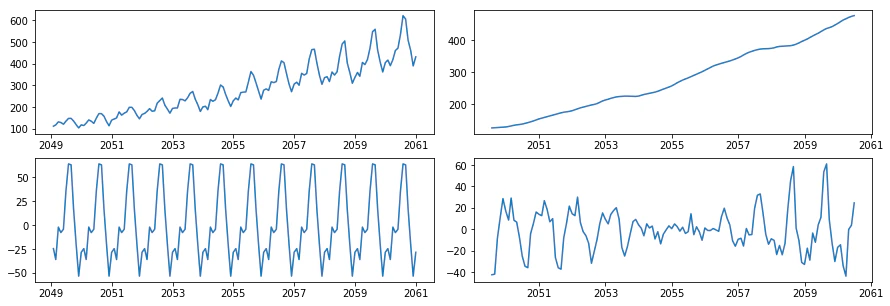
d1 = data['n'].resample('M').sum()
# 適当なデータを生成する
import statsmodels.api as sm
res = sm.tsa.seasonal_decompose(d1)
d2 = res.trend
d3 = res.seasonal
d4 = res.resid
plt.figure(figsize=(15, 5))
plt.subplots_adjust(wspace=0.1, hspace=0.2)
plt.subplot(221)
plt.plot(d1)
plt.subplot(222)
plt.plot(d2)
plt.subplot(223)
plt.plot(d3)
plt.subplot(224)
plt.plot(d4)
グラフの凡例の位置調整:plt.legend(loc, bbox_to_anchor)
- 分析結果を資料にまとめる際、凡例の位置がチャートに重なってしまうことがある
データ分析上はどうでもいいのですが、偉い人達はとても気にします- plt.legendの引数locで場所を指定できる
- "upper left"=左上、"upper right"=左上、"lower left"=左下、"lower right"=左下
- plt.legendの引数bbox_to_anchorを調整することで、凡例をグラフ外に表示することも可能(凡例の数が大きい場合に効果的)
- bbox_to_anchorにタプルでデータを渡す
- 図全体の左下を(0, 0), 右上を(1, 1)として相対値で場所を指定
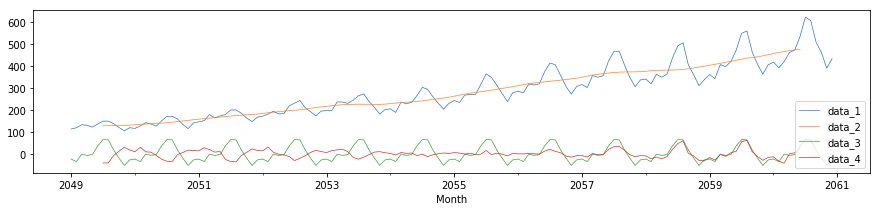
# デフォルト
data.plot(figsize=(15, 3), lw=.7)
# 凡例の場所を指定
data.plot(figsize=(15, 3), lw=.7)
plt.legend(loc="lower right")
# 凡例の場所を指定
data.plot(figsize=(15, 3), lw=.7)
plt.legend(bbox_to_anchor=(1.01,1))


相関マトリックスをヒートマップで表示:Dataframe.corrとsns.heatmap
- 各変数間の関係性を可視化する際に、相関マトリックスを生成して、比較することがよくある
- Dataframe.corr()を利用することで相関係数を算出することができる
- Methodを指定することで相関係数の種類も指定できる
- 'pearson': ピアソンの積率相関係数(デフォルト)
- 'kendall': ケンドールの順位相関係数
- 'spearman': スピアマンの順位相関係数
- Dataframe.corr()をsns.heatmapに渡すことで相関マトリックスがヒートマップで可視化される
- 相関マトリックスをヒートマップで可視化する際によく使うオプションは以下の通り
- annot=True:相関係数を数値として表示する(デフォルトはFalseで非表示)
- lw=0.7:セル間の線幅(追加したが方が見やすい)
- cmap= "Blues":heatmapのカラー指定(個人的に好きなの色は"Blues", "YlGnBu", "Greens")
# 相関マトリックスを計算方法を変えて3つ生成
cor1 = data.corr(method='pearson')
cor2 = data.corr(method='kendall')
cor3 = data.corr(method='spearman')
# ヒートマップで可視化
plt.figure(figsize=(15, 10))
plt.subplots_adjust(wspace=0.1, hspace=0.3)
plt.subplot(311)
sns.heatmap(cor1, annot=True, lw=0.7, cmap='Blues')
plt.title('pearson')
plt.subplot(312)
sns.heatmap(cor2, annot=True, lw=0.7, cmap='YlGnBu')
plt.title('kendall')
plt.subplot(313)
sns.heatmap(cor3, annot=True, lw=0.7, cmap='Greens')
plt.title('spearman')

最後に
- 実際のビジネスでデータ分析をす際によく使う手法をまとめてみました
- 今後、頻出するコードがあれば随時アップデートします
- 次はよく使う分析手法編でもまとめてみようかと思います