OutSystemsとElasticsearch
2024/05/02
Data Streamに対応するため内容を改変いたしました
Githubのリポジトリも変更しています
2024/05/21
fingerprintのmethodをSHA512に変更しました。
MURMUR3ではcollisionの可能性があります。
とある案件で、OutSystems(O11)のアプリのログや使用状況をElasticsearchで可視化する、という話があったので、その内容をブログにまとめてみました。
とはいえ、あまり難しいことはなくOutSystemsが用意してくれているLogstashのPipelineをMonitor Probeとあわせて使うだけです。
OutSystemsもLogstashも詳しい方は以下を眺めるだけでできてしまうと思います。
- Logstash Pipeline
https://github.com/OutSystems/outsystems-elastic-integration/tree/main/data_extraction/logstash - Monitor Probe
https://www.outsystems.com/forge/component-overview/4559/monitorprobe-o11
ただこのままでは詰まる部分もあるので、そのあたりを中心に説明します。
今回使用するGithubのリポジトリはこちらです。
https://github.com/legacyworld/outsystems_logstash
環境
- OutSystems
O11が前提です。 - Elasticsearch
Elastic Cloudを使用しています。
使用したバージョンは8.13.2です - Logstash
今回はDockerで動かしています。
Docker version 24.0.5, build ced0996
Docker Compose version v2.20.2
Logstashのバージョンは8.13.2です。
準備
OutSystems
何でも良いのでなにかアプリを作りましょう。
このブログではForgeから取ってきたProductCatalogを利用しています。
Monitor Probe
Forgeから持ってくれば特に問題なく動作するはずです。
https://www.outsystems.com/forge/component-overview/4559/monitorprobe-o11
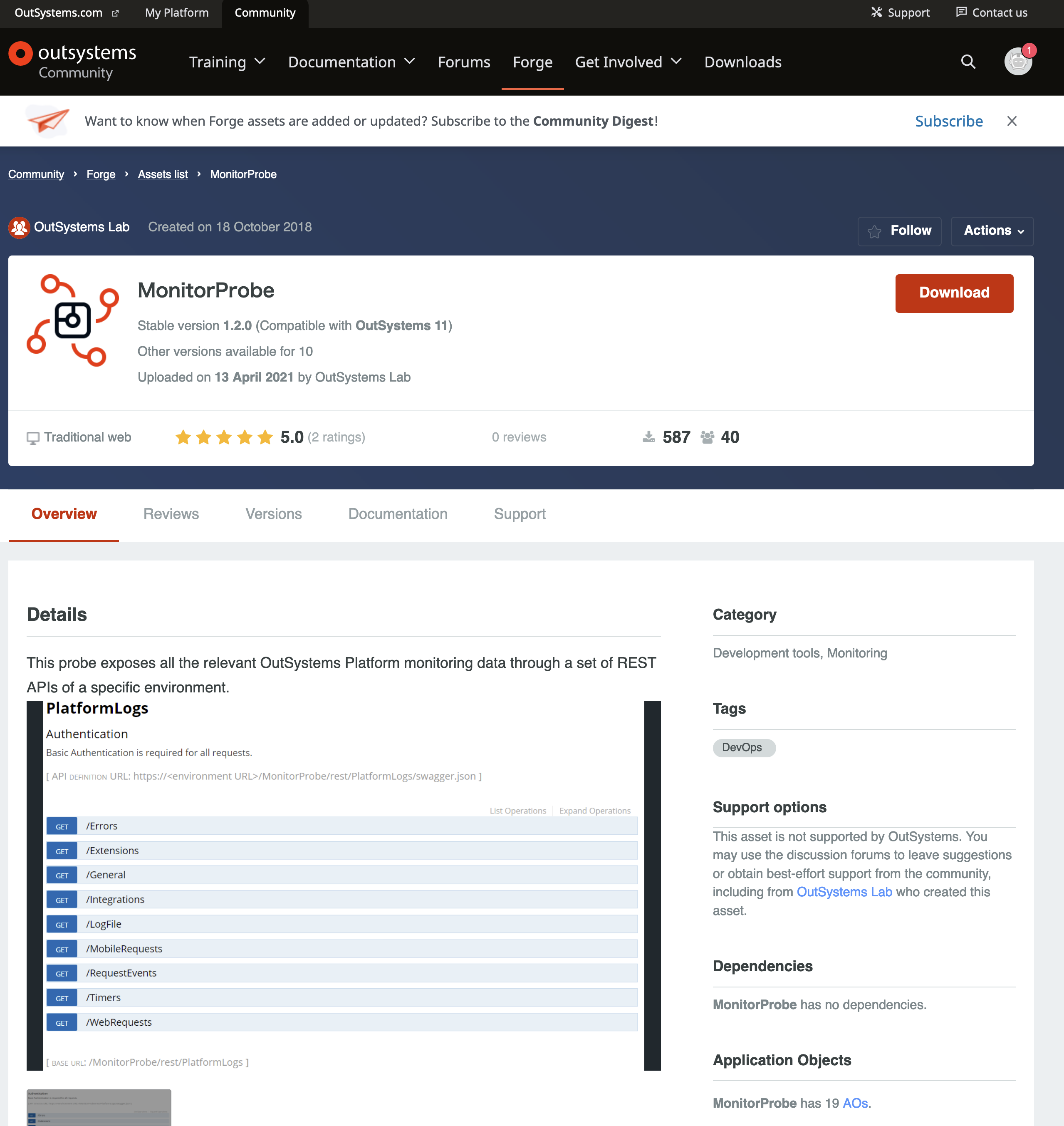
このブログでは面倒なので認証を省いています。認証方法は以下の部分のAuthenticationTypeで変更できます。
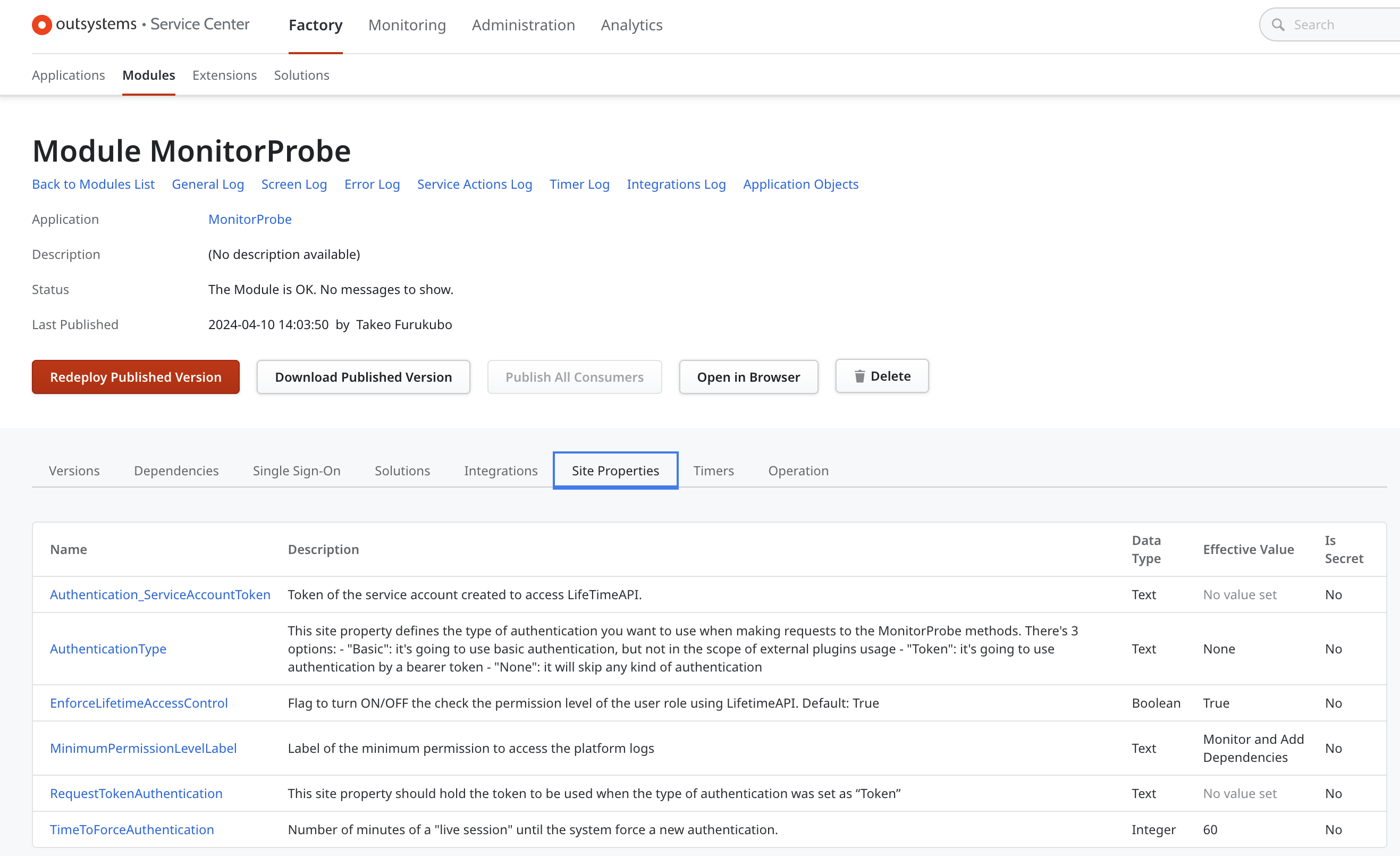
Monitor Probeが動いているかどうか確かめてみます。ブラウザから開くと以下の画面が表示されます。
https://<Personal URL>/MonitorProbe/rest/PlatformLogs/
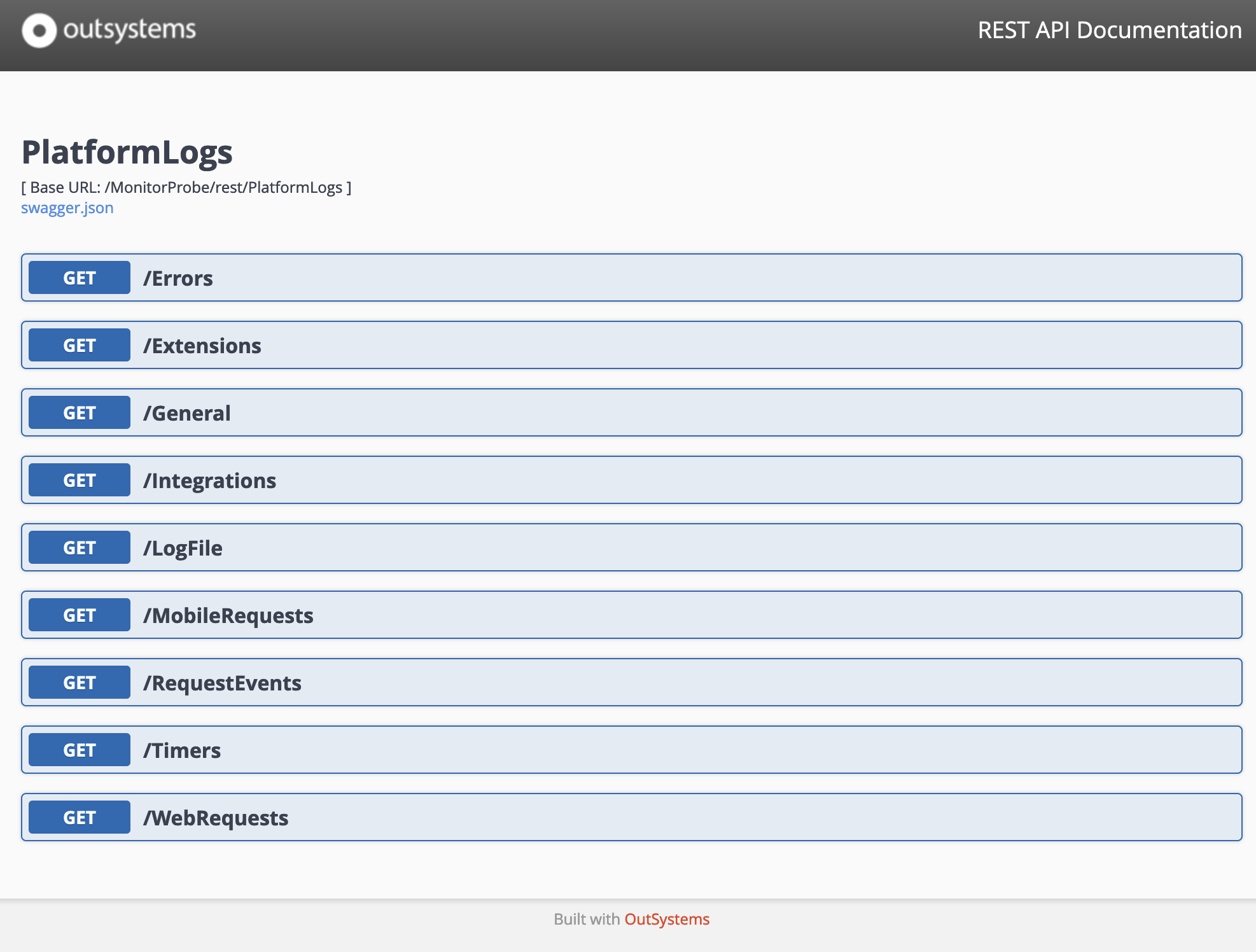
とりあえず過去10分のGeneralのログを表示してみます。
https://<Personal URL>/MonitorProbe/rest/PlatformLogs/General?MinutesBefore=10
問題なければこんな感じで表示されます。
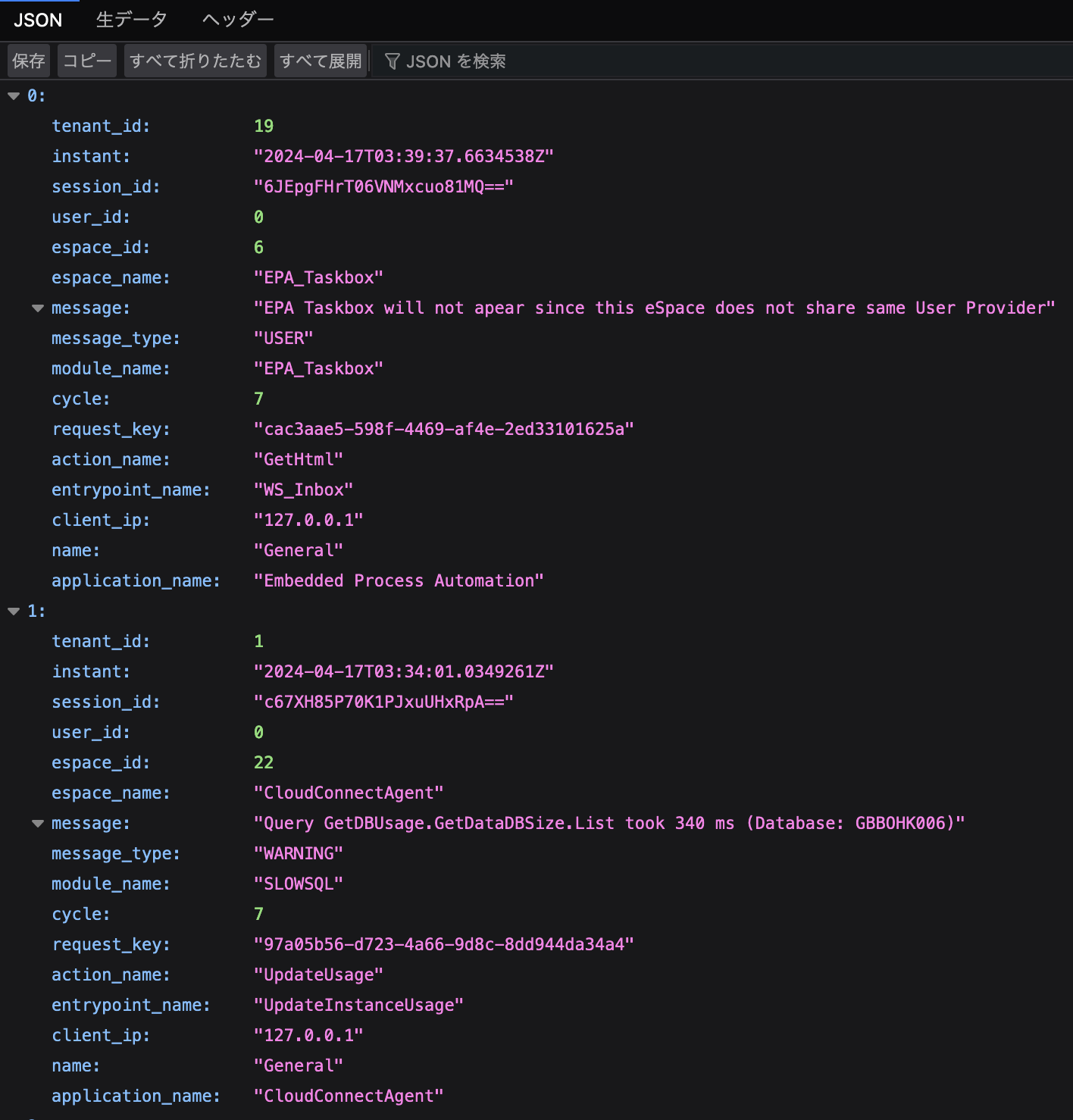
このブログですることはこの表示されているデータをLogstashでElasticsearchに取り込むことです。
Elasticsearch
こちらのブログをベースにElastic Cloudにクラスタを展開します。
https://qiita.com/tomo_s_el/items/3584d0b1fabb0bafa4fa
Logstash
設定
これをクローンします。まだコンテナは立ち上げないでください。
https://github.com/legacyworld/outsystems_logstash
このように展開されます。
outsystems_logstash
├── Dockerfile
├── config
│ ├── logstash.yml
│ └── pipelines.yml
├── docker-compose.yml
├── outsystems.ndjson
└── pipeline
└── outsystems
├── error.conf
├── extension.conf
├── general.conf
├── integration.conf
├── mobile-request.conf
├── patterns
│ └── extra
├── request-event.conf
├── timer.conf
└── web-request.conf
まずoutsystems_envをoutsystems_logstashフォルダの直下に作成します。
MP_BASE_URL="https://<Personal URL>/MonitorProbe/rest/PlatformLogs/"
MP_USER=""
MP_PASSWORD=""
MP_INTERVAL="3"
MP_SCHEDULE="2m"
MP_REQUEST_TIMEOUT="1"
MP_SOCKET_TIMEOUT="60"
LAST_RUN_DIR=""
PATTERNS_DIR="/usr/share/logstash/pipeline/outsystems/patterns"
DATA_CUSTOMER_NAME=""
DATA_LOCATION_NAME=""
DATA_ENVIRONMENT_NAME=""
CLOUD_ID="<Elastic Cloud ID>"
CLOUD_AUTH="<Elastic Cloud Auth>"
変更が必須なのは以下の3つです
-
MP_BASE_URL
My PlatformのYour infrastructure部分をコピーして貼り付けます。

-
CLOUD_ID / CLOUD_AUTH
こちらの記事を参考に確認します。下記の記事ではCLOUD_AUTHはcloud_passとなっています。
https://qiita.com/takeo-furukubo/items/e5d43fa734e4338b895f#%E3%81%9D%E3%82%8C%E3%81%9E%E3%82%8C%E3%81%AE%E7%A2%BA%E8%AA%8D%E6%96%B9%E6%B3%95
実行
docker compose up -dで自動的にビルドしてコンテナを立ち上げます。
docker compose logsで以下のような感じに出てくれば、動いてます。
logstash | "outsystems" => {
logstash | "customer_name" => "",
logstash | "location_name" => "",
logstash | "environment_name" => ""
logstash | },
logstash | "ecs" => {
logstash | "version" => "1.5.0"
logstash | },
logstash | "@timestamp" => 2024-04-18T02:46:02.879527467Z,
logstash | "@version" => "1",
logstash | "log" => {
logstash | "data_source" => "Error"
logstash | }
logstash | }
logstash | {
logstash | "outsystems" => {
logstash | "customer_name" => "",
logstash | "location_name" => "",
logstash | "environment_name" => ""
logstash | },
logstash | "ecs" => {
logstash | "version" => "1.5.0"
logstash | },
logstash | "@timestamp" => 2024-04-18T02:46:03.041240842Z,
logstash | "@version" => "1",
logstash | "log" => {
logstash | "data_source" => "Request Event"
logstash | }
logstash | }
もし
error: open /usr/share/logstash/config/logstash.yml: permission denied
と出てくるようであれば、logstash.ymlのpermissionを変更してから再度実行してみてください。
Kibanaで確認
pipelines/outsystemsフォルダにあるconfファイルを見てみるとわかりますが、ElasticsearchのData Streamという形式を採用しています。これは自動的にインデックス名がローリングして複数インデックスに格納するためです。
ドキュメントはこちらです。
https://www.elastic.co/guide/en/elasticsearch/reference/current/data-streams.html
インデックス名は例えば.ds-logs-os.mon-error-2024.05.02-000001のように.ds-logs-os.mon-error-<日付>-<通し番号>となります。
output {
stdout { codec => "rubydebug"}
elasticsearch {
cloud_id => "${CLOUD_ID}"
cloud_auth => "${CLOUD_AUTH}"
data_stream => "true"
data_stream_type => "logs"
data_stream_dataset => "os.mon"
data_stream_namespace => "error"
}
}
ではこれらのログをKibanaで見られるように設定をしていきます。
Kibana データビュー設定
Management -> Stack Management -> Kibana -> Dataviewをクリックします。
Dataviewはどのインデックスを処理するか、という単位です。
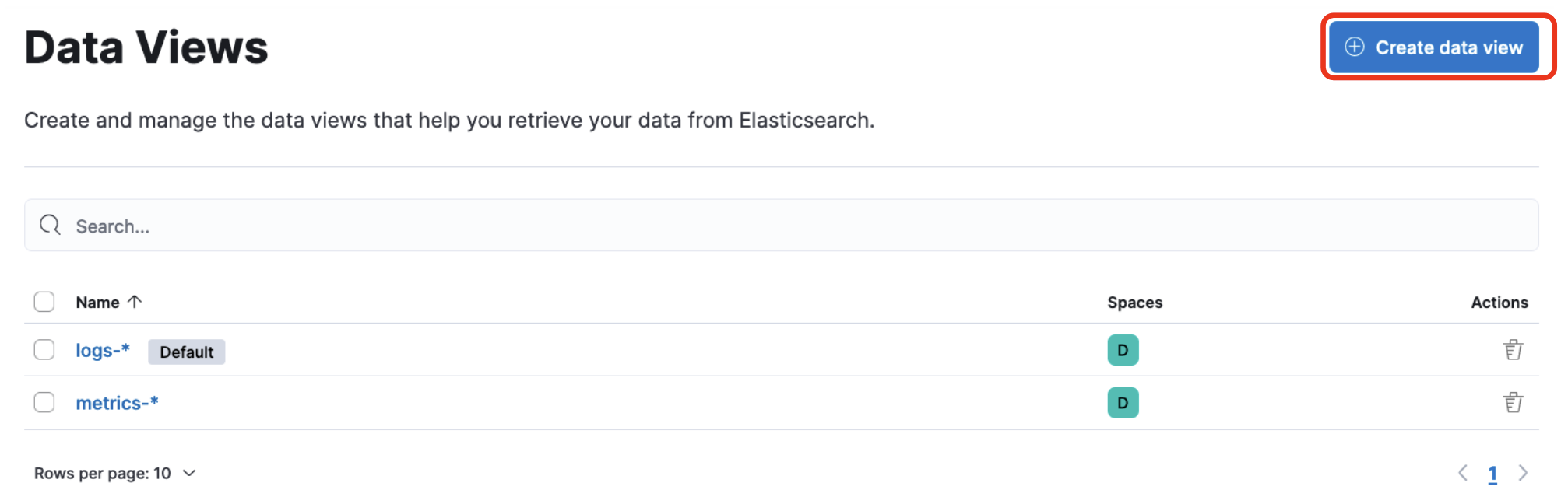
以下のように入力します。
- Name
- outsystems
- ダッシュボードをこのデータビューの名前で設定しているので、この名前を使用してください
- outsystems
- Index pattern
- logs-os.mon-*
- logs-os.monから始まるインデックス全て表示するという設定
- logs-os.mon-*
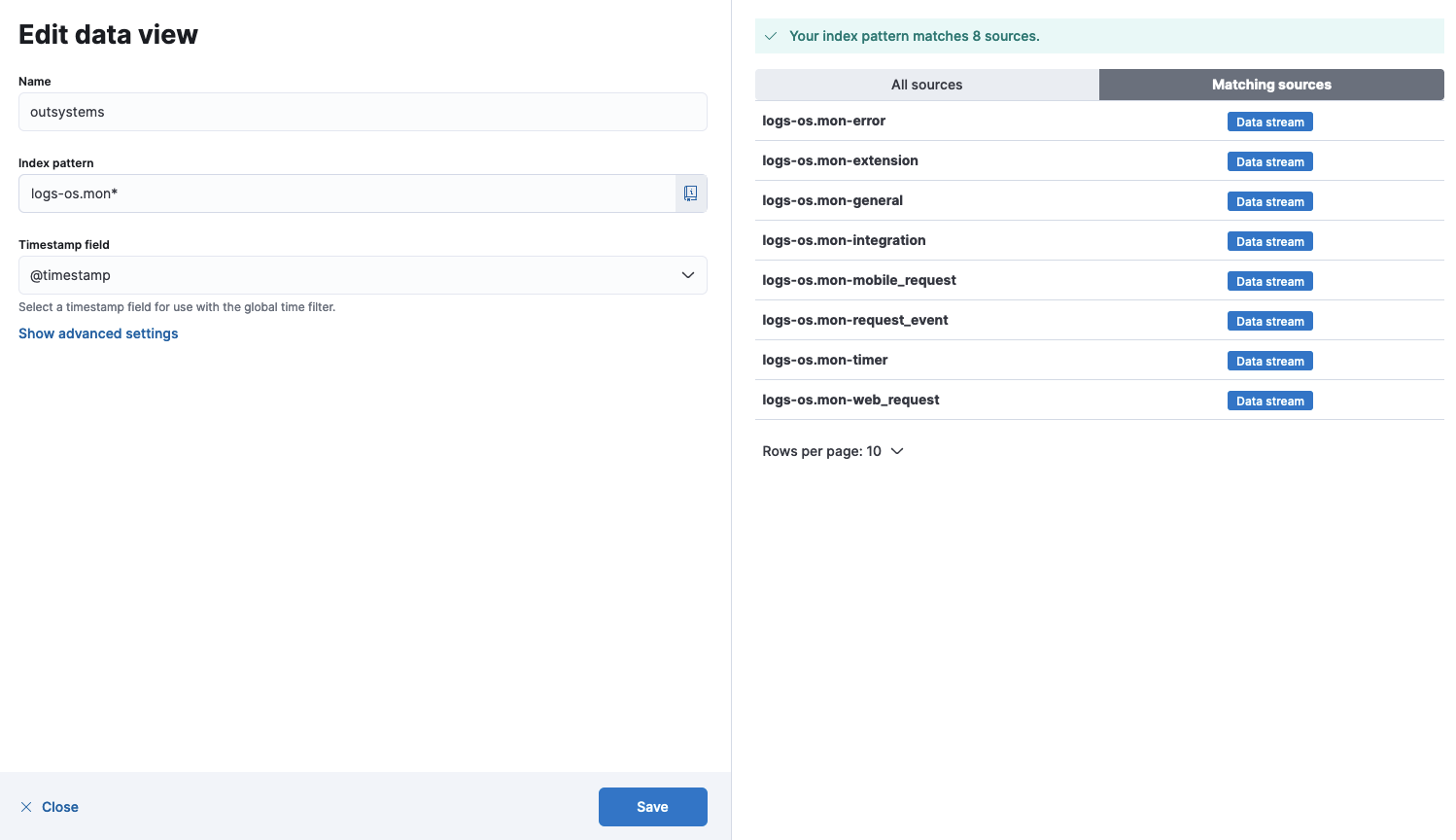
Save data view to Kibanaをクリックして保存します。
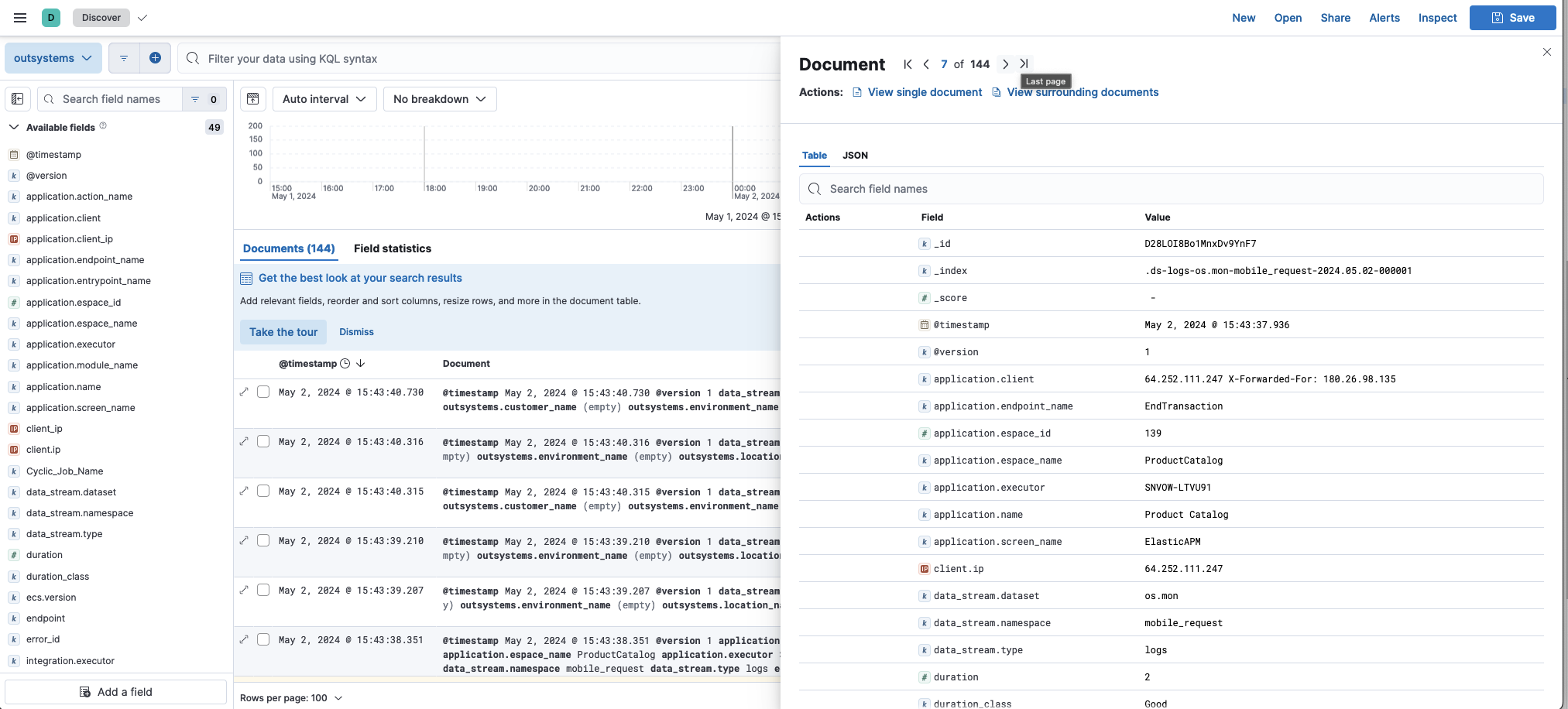
Discoverで確認
Analytics -> Discoverをクリックします。先程作成したDataviewの名前(ここではoutsystems)を選ぶと右側にログが表示されます。
Dashboard
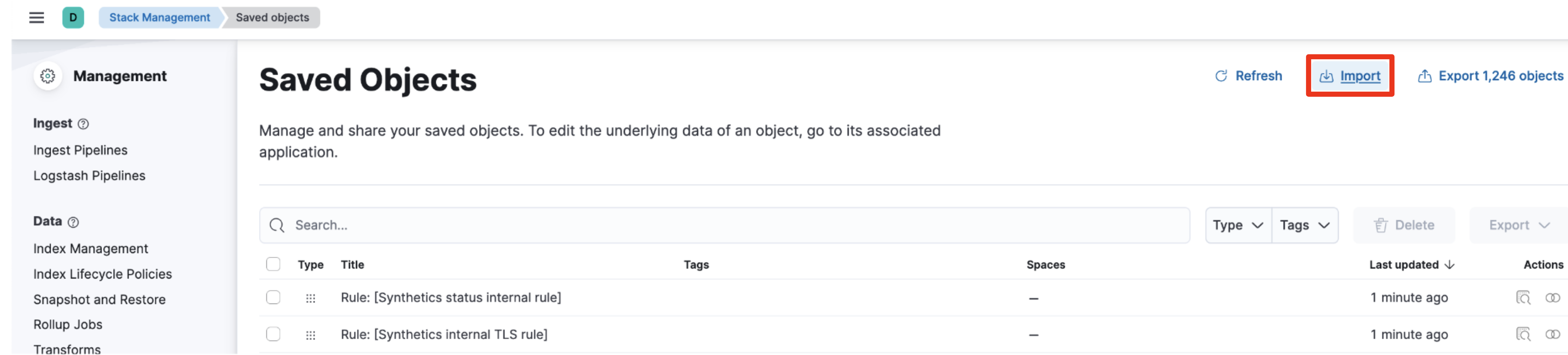
outsystems.ndjsonをアップロードすれば最低限の可視化を行えます。
Stack Management -> Saved Objectsとクリックして、右上のImportをクリック。
Analytics -> Dashboard -> Outsystemsとクリックすれば下記のような可視化が表示されます。
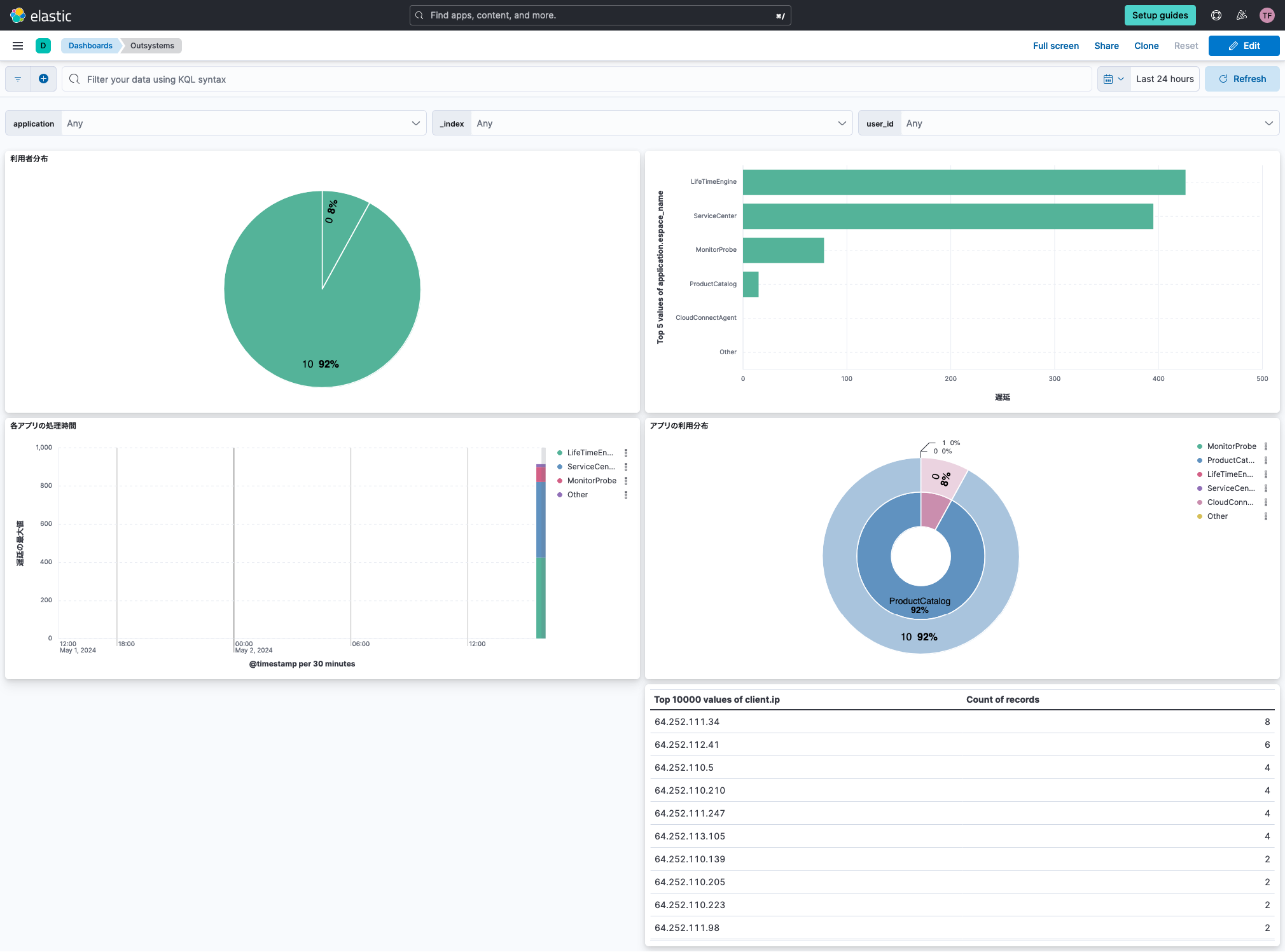
- 左上の円グラフ
ユーザごとのログの数 - 右上の横棒グラフ
アプリごとの最大の遅延(=duration) - 真ん中左の縦棒
時間ごとの最大遅延(=duration)のアプリごとの分布 - 真ん中右の円グラフ
アプリごとのログの数と、各アプリ毎のユーザ分布 - 一番下の表
アクセスしてきているアドレス(=Source)
一番上にはプルダウンでフィルタを掛けられるようになっています。
左から、アプリ名、モジュール名(=index名)、ユーザIDです。
これらを利用することで、誰がどのアプリをどのぐらい使っているのか、どのアプリが遅くなっているのか、などが一目でわかるようになります。
ぜひご活用ください。
設定の解説
ここからは細かい話になります。
Dockerfile
FROM docker.elastic.co/logstash/logstash:8.13.2
USER logstash
RUN /usr/share/logstash/bin/logstash-plugin install logstash-filter-range
CMD ["/usr/share/logstash/bin/logstash"]
特筆すべきことは何もありませんが、filter-rangeがデフォルトでは入っていないのでこれのインストールが必要なことと、DockerHubのオフィシャルイメージではなくElasticのイメージを利用していることぐらいです。
docker-compose
services:
logstash:
build:
context: .
dockerfile: Dockerfile
container_name: logstash
env_file:
- outsystems_env
volumes:
- ./config:/usr/share/logstash/config
- ./pipeline:/usr/share/logstash/pipeline
これも特別なことはしていません。環境変数を設定しているぐらいです。
Logstash Pipeline
Logstashに慣れ親しんでいる方には特段難しいことはないものだと思います。
例としてMobile Requestを見ていきます。
Input
input {
http_poller {
urls => {
mp => {
method => get
url => "${MP_BASE_URL}/MobileRequests?MinutesBefore=${MP_INTERVAL}"
user => "${MP_USER}"
password => "${MP_PASSWORD}"
headers => { Accept => "application/json" }
}
}
request_timeout => "${MP_REQUEST_TIMEOUT}"
socket_timeout => "${MP_SOCKET_TIMEOUT}"
schedule => { every => "${MP_SCHEDULE}" }
metadata_target => "http_poller_metadata"
}
}
Input Filterというのはデータのソースの事です。今回だとOutSystemsのMonitor Probeです。
よくあるのはsyslogだったりFilebeatだったりです。
- http_poller
https://www.elastic.co/guide/en/logstash/current/plugins-inputs-http_poller.html
名前の通りHTTP APIを叩きに行くモジュールです。urlを見るとわかりますが、Monitor Probeのアドレスになています。MinutesBeforeを使っているので指定された直近のデータだけ(MP_INTERVAL)だけ取りに行く設定です。scheduleで取りに行く頻度を決めています。
Filter
Inputで取り込んだものはそのままだと一つのフィールドに入ってしまいます。それを分割してそれぞれフィールドに格納していく部分がFilterの役割です。例えばアプリケーション名などを一つのフィールドとして分離しておくと、後で解析がやりやすくなります。
長いので順に説明していきます。
convert
mutate {
convert => [ "instant", "string" ]
}
mutateはいろんな変換作業を行う部分です。ここでは時間が格納されているinstantをStringで保存しています。
date
date {
match => ["instant", "ISO8601"]
timezone => "Etc/UTC"
}
これは時刻をISO8601フォーマットで解析して取り込む、というものです。
field操作
mutate {
add_field => {
"[ecs][version]" => "1.5.0"
"[outsystems][customer_name]" => "${DATA_CUSTOMER_NAME}"
"[outsystems][location_name]" => "${DATA_LOCATION_NAME}"
"[outsystems][environment_name]" => "${DATA_ENVIRONMENT_NAME}"
"[log][data_source]" => "Mobile Request"
}
remove_field => [ "name", "cycle", "http_poller_metadata" ]
rename => {
"instant" => "[log][instant]"
"id" => "[mobile_request][id]"
"espace_id" => "[application][espace_id]"
"espace_name" => "[application][espace_name]"
"screen" => "[application][screen_name]"
"client_ip" => "[application][client]"
"endpoint" => "[application][endpoint_name]"
"executed_by" => "[application][executor]"
"request_key" => "[request][key]"
"application_name" => "[application][name]"
}
remove_field => ["client_ip"]
}
add_fieldはログにはないデータを追加しています。[ecs][version]はElasticsearchの中ではecs.versionというフィールド名になります。
remove_fieldはそのままでフィールドを削除します。
renameはフィールドの名前だけを変更します。
client_ipをapplication.clientとしているのは、フィールド名にipが入っていると自動的にIPアドレスとして認識されてしまうのですが、ここには64.252.111.34 X-Forwarded-For: 180.26.98.135という形で入っているため、正しくIPアドレスとして処理ができません。
これを処理するために次のGROKフィルタを使用します。
GROK
grok {
match => { "[application][client]" => "%{IP} X-Forwarded-For: %{IP:client.ip}" }
}
ソースのIPを取るために後半部分のIPアドレスをclient.ipとして格納しています。
このclient.ipというのはElasticsearchのログ形式で統一されたフィールド名です。
これをElastic Common Schemaといいます。
https://www.elastic.co/guide/en/ecs/current/ecs-client.html#field-client-ip
range
range {
ranges => [
"duration", 0, 2000, "field:duration_class:Good",
"duration", 2001, 6000, "field:duration_class:Fair",
"duration", 6001,999999999999, "field:duration_class:Bad"
]
}
rangeはデフォルトでは入っていないプラグインなのでDockerfileのRUN /usr/share/logstash/bin/logstash-plugin install logstash-filter-rangeでインストールしています。
durationの値によって、duration_classというフィールドにGood,Fiar,Badと入れていきます。
finterprint
fingerprint {
source => ["[mobile_request][id]"]
target => "[@metadata][fingerprint]"
method => "SHA512"
concatenate_sources => true
}
https://www.elastic.co/guide/en/logstash/current/plugins-filters-fingerprint.html
fingerprintは同じログを重複して書き込まないようにする仕組みです。Elasticsearchは一度書きこんだものは変更できませんので、同じログを複数回書いてしまうと同じ内容が複数検索でヒットしてしまうため、統計データなどでおかしくなってしまうこともあります。
Elasticsearchにはドキュメントごとに一意なIDが振られます。同じIDで書き込みをすれば、ドキュメントのバージョンが増えていって、一番新しいバージョンのデータのみを参照するようになりますので、同じ内容のログは同じIDで書き込めば上記の問題を避けられます。
確実に異なるフィールド(ここではid)からハッシュを作成して、それをIDとすれば重複を避けられるわけです。
これと同じことはIngest Pipelineを使用してElasticsearch側でも行えます。Logstashを複数立てるような場合はElasticsearch側で行う方が良いです。
こちらをご参照ください。
https://www.elastic.co/guide/en/elasticsearch/reference/current/fingerprint-processor.html
output
output {
stdout { codec => "rubydebug"}
elasticsearch {
cloud_id => "${CLOUD_ID}"
cloud_auth => "${CLOUD_AUTH}"
data_stream => "true"
data_stream_type => "logs"
data_stream_dataset => "os.mon"
data_stream_namespace => "mobile_request"
}
}
LogstashからElasticsearchへ送信する部分です。stdout { codec => "rubydebug"}は標準出力へ出すものなので、特に必要はないです。
今回はElastic Cloudを使用しているのでcloud_idとcloud_authで認証を行います。
Data Streamはインデックスの命名規則が決まっています。下記ブログを参考にしてください。
https://www.elastic.co/jp/blog/an-introduction-to-the-elastic-data-stream-naming-scheme
まとめ
OutSystemsのログ保持期間は9週と少し短いため、Elasticsearchに取り込んで可視化を行ってシステム全体をより俯瞰的に見ることができるようになると思います。
作成するシステムによっては監査ログとして長期保管が必要になることもあると思います。その場合はElasticsearchではSearchable Snapshotという機能を用意しています。これは古いログをオブジェクトストレージに保管することでコストを大幅に下げる機能です。
Searchable Snapshotのポイントはオブジェクトストレージから自動的に必要なデータのみ持ってくるということです。1年前の時間帯をKibanaで指定すれば裏で自動的にデータを引っ張ってきますので、非常に使い勝手が良いです。詳細はこちらをご参照ください。
https://qiita.com/nobuhikosekiya/items/dd2ce836b184730f8d70
https://qiita.com/nobuhikosekiya/items/8ab82e70953b6b5d1736
こちらの記事がOutSystemsにて構築したシステムのObservabilityに貢献できれば幸いです。