2024/10/22
Indexの設定に間違いがありました(char_filterがanalyzerに設定されていなかった)
はじめに
ChatGPTで生成AIが一気に注目を浴びて、いろいろ試しに使ってみた方は多いと思います。生成AIの使い方は多岐に渡り、非常に有効なところもあればそうでないところもあります。
例えば、文章の要約、プログラムの作成、翻訳等既に業務で使えるレベルのものも多いです。それに反して、最新の情報やインターネットに出ていない機密情報というのには弱いというところもあります。
ここでは最新情報や機密情報を生成AIで使えるようにするRAG (Retrieval Augmented Generation)をElasticsearchで実現する方法を解説いたします。
こちらの内容は弊社Webinarでも公開しております。
https://www.elastic.co/jp/virtual-events/delivering-generative-ai
RAGやElasticsearchについて既に良くご存じの方は下記のリポジトリを眺めて頂くだけでご理解いただけると思います。
- Elasticsearchの公式リポジトリ
- Elasticsearch社員のリポジトリ
RAGとElasticsearch
RAGの仕組みについては他でも詳細な解説がありますので、ここでは簡単なものにとどめておきます。

ここでESREとあるのは、ElasticのAI関連ツールを纏めたものです。
https://www.elastic.co/guide/en/esre/current/index.html
ベクトル検索、ハイブリッド検索(RRF)、サードパーティモデルの機械学習ノードへのインポート、等の機能を指します。
RAGの流れは大雑把に以下のような感じです。
前提として社内データ(ファイルサーバやクラウドストレージに保管してあるもの)のテキストデータがElasticsearchにインデックスされているものとします。
- 検索文をユーザが入力
- 検索文でElasticsearch内のデータを検索
ここで検索は通常検索(キーワード検索)でもベクトル検索でも、その両方のハイブリッド検索でも良い - Elasticsearchが関連度の高い順に結果を返す
- 上位の結果のいくつかを取り出し、コンテキストとして付加して質問文とともに生成AI(今回はOpenAI)に送信する
- 生成AIがコンテキストと質問文を元に結果を返す
上記の例でいうと、確定拠出年金への加入方法は各社ごとに異なり(証券会社とか開始時期とか)、ユーザの会社の手順はElasticsearchにインデックスされています。そこから証券会社やアカウントの作成方法等を含むドキュメントを抽出して生成AIに要約してもらいます。
まず検索の部分で正しい結果が返っていないと、生成AIからの回答も正しくはなりません。またユーザの権限により出して良い情報とダメな情報があります(経営に関する情報を一般社員が見てはいけない、等)。ここがRAGの難しい部分でも有り、検索の老舗であるElasticsearchの出番でもあります。
構成
概略図
大まかには以下のようになります。

Pythonの部分はFlaskで作ってあります。
1-3のフローと4-6のフローはわかれています。前半は検索で正しく結果を返す部分、後半は生成AIで要約を作成する部分、となります。
今回のサンプルプログラムでは「通常検索」「ベクトル検索」「ハイブリッド検索」「OpenAIによる検索」を個別に比べられるようにしてあります。
動作環境
Dockerが動けば特に環境は問いません。
OS: Linux (ubuntu 20.04)
VM: Azure Standard DS1 v2
Docker: 24.0.5
Docker Compose: v2.20.2
Elasticsearch (Elastic Cloud): 8.10.3
ドキュメント
NewsAPIの記事をインデックスしています。
https://newsapi.org/
クエリ文などもこの構成に合わせてあります。
手順
https://github.com/legacyworld/esre/blob/main/README.md
READMEにざっくりと書いてあります。
Elastic Cloudにクラスタ作成
こちらのブログをベースにElastic Cloudにクラスタを展開します。
https://qiita.com/tomo_s_el/items/3584d0b1fabb0bafa4fa
構成変更
(注)キャプチャ画面は2023年10月時点のものです。
Extension追加
日本語処理のExtension(Kuromoji / ICU)を追加します。
クラウドコンソール画面(ログイン後に最初に表示されるクラスタの管理画面)から作成したクラスタのManageをクリックします

次に左側からEditを選びます。
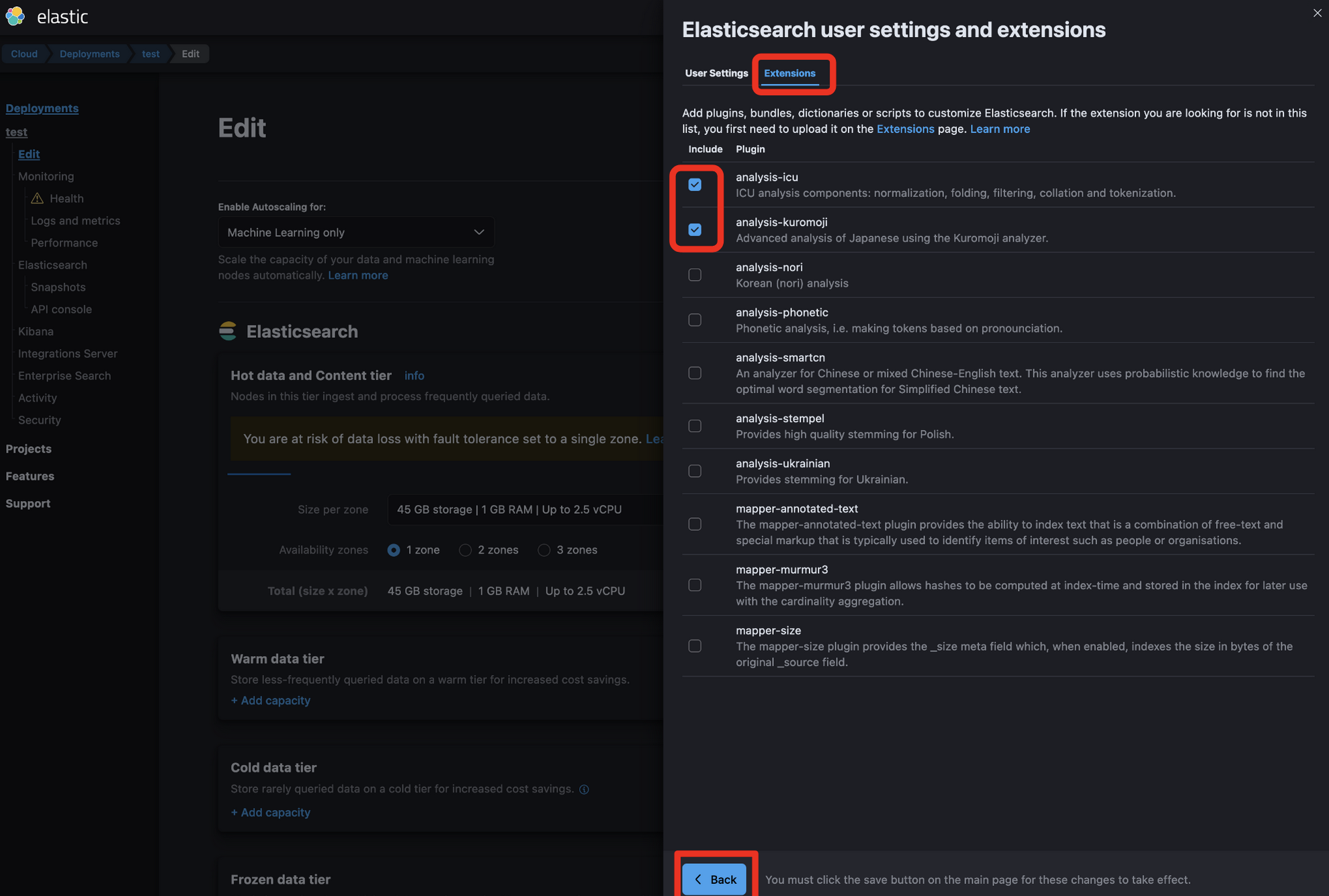
一番上のElasticsearchの横にあるManage user settings and extensions (0)をクリックします

- 右上のExtensionsをクリック
- analysis-icuとanalysis-kuromojiにチェックを付ける
- 左下のBackをクリック
機械学習ノードの追加
上記ブログでは触れていない機械学習ノードを追加します。RAMは4GB以上必要です(モデルの展開に必要です)
Extensionsの追加に続いてEdit画面で設定を続けます。もしEdit画面を間違って抜けてしまっている場合、先程のExtensionsの設定が消えていますので、再度行ってください。
下にスクロールしていくとMachine Learning Instancesがあります。
機械学習ノードは初期設定を変更していなければAutoscaleが有効になっています。

RAMを4GB以上にします。

一番下までスクロールしてSaveをクリックして、ポップアップしたダイアログのConfirmをクリックします。(これをしないと設定変更が行われません)


しばらく時間がかかります。自動的にActivityのページに移動します。完了まで待ちましょう。

設定
Elastic Cloudの準備が完了したらモデルのアップロード、Mappingの設定、ドキュメントの投入などを行います。
RAGを動かす環境で作業します。
Git clone
git clone https://github.com/legacyworld/esre/
.envファイル
esreフォルダに移動して、以下の内容で.envファイルを作成します。newsapi_keyはオプションです。
openai_api_key=<openapi key>
openai_api_type=azure
openai_api_base=<openapi base url>
openai_api_version=<openapi version>
openai_api_engine=<openapi engine>
cloud_id=<cloud id of Elasticsearch Cluster>
cloud_pass=<Cloud pass of Elasticsearch Cluster>
cloud_user=<Cloud User. Normally it is elastic>
search_index=<your index name>
newsapi_key=<newsapi key>
それぞれの確認方法
- cloud_id

- cloud_pass
https://qiita.com/tomo_s_el/items/3584d0b1fabb0bafa4fa#%E4%BD%9C%E6%88%90%E4%B8%AD
ここで表示されたものです。
ダウンロードしていなかった場合はSecurity => Reset Passwordすれば再発行できます。 - openai_api_*
- Azure OpenAI Servicesで確認します
-
openai_api_engineはAzure AI StudioのDeployment名です
Docker Image Build & 起動
docker compose up -d
立ち上がったかどうかdocker compose ps、docker compose logsで確かめましょう。
$ docker compose ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
esre_flask esre-esre_flask "python3 -u app.py" esre_flask 4 hours ago Up 3 hours 0.0.0.0:4000->4000/tcp
docker compose logsで以下のようなものが表示されていれば無事Elastic Cloudに接続されています。
{'name': 'instance-0000000000', 'cluster_name': 'e48072429f3d44beb9286fecc64f4529', 'cluster_uuid': 'u0PuN1DCSN-yVJZhowZ_mw', 'version': {'number': '8.10.3', 'build_flavor': 'default', 'build_type': 'docker', 'build_hash': 'c63272efed16b5a1c25f3ce500715b7fddf9a9fb', 'build_date': '2023-10-05T10:15:55.152563867Z', 'build_snapshot': False, 'lucene_version': '9.7.0', 'minimum_wire_compatibility_version': '7.17.0', 'minimum_index_compatibility_version': '7.0.0'}, 'tagline': 'You Know, for Search'}
モデルアップロード&インデックス初期化
initialize.shを実行すれば全て自動で行われます。但し、実行環境は立ち上げたDockerコンテナに構築してありますので、コンテナに入ってから実行します。
DockerfileのWORKDIRをみればわかりますが、/srcに最初はいます。
docker exec -it esre_flask /bin/bash
./initialize.sh
行っているのは下記のことです。
機械学習モデルのインポート
Hugging Faceにある東北大学のモデルをダウンロードしてきて、機械学習ノードにアップロードします。
こちらのモデルを使っています。
https://huggingface.co/cl-tohoku/bert-base-japanese-char-v2
initialize.shの以下の部分でアップロードまで行っています。
この部分は数分かかります。お茶でも飲んでお待ち下さい。
eland_import_hub_model \
--cloud-id $cloud_id \
-u $cloud_user \
-p $cloud_pass \
--hub-model-id cl-tohoku/bert-base-japanese-v2 \
--task-type text_embedding \
--start
elandはElasticsearchで機械学習のモデルを利用するためのツールです。公式ドキュメントはこちらです。
https://www.elastic.co/guide/en/elasticsearch/client/eland/current/index.html
elandで機械学習モデルをアップロードする方法はこちらに記載があります。
https://www.elastic.co/guide/en/machine-learning/current/ml-nlp-import-model.html
Ingest Pipelineの作成
Ingest PipelineというのはElasticsearchにドキュメントを投入する際に行う前処理を定義する部分です。
公式ドキュメントはこちらです。
https://www.elastic.co/guide/en/elasticsearch/reference/current/ingest.html
Dense Vectorを外で作る必要がなくドキュメント投入と同時にEmbeddingが行われることもElasticsearchの一つの利点です(これがESREの一部です)
今回設定するのは東北大学のモデルを使ってDense Vector Embeddingを行います。このモデルでは与えられた文章を768次元のベクトルにしてインデックスに書き込みます。
initialize.shからcreate_index.pyが呼ばれていますが、その中で下記の部分がpipeline作成です。
pipeline_id = "japanese-text-embeddings"
body = {
"description": "Text embedding pipeline",
"processors": [
{
"inference": {
"model_id": "cl-tohoku__bert-base-japanese-v2",
"target_field": "text_embedding",
"field_map": {
"title": "text_field"
}
}
}
]
}
print(es.ingest.put_pipeline(id=pipeline_id,body=body))
target_field,field_mapは固定値です。
Mappingの作成
日本語の形態素解析を行うkuromojiの設定とベクトル検索をするためのDense Vector Fieldの設定を行います。
形態素解析
日本語全文検索は形態素解析という特殊な処理が必要です。詳細はこちらに記載があります。
https://www.elastic.co/jp/blog/how-to-implement-japanese-full-text-search-in-elasticsearch
kuromojiではなくsudachiと言った別の形態素解析を使用することもあります。
Analyzer / Tokenizer設定
create_index.pyの下記の部分が形態素解析のAnalyzer/Tokenizerの設定です。本番運用となるとN-Gramのフィールドを加えたり、同義語辞書を作成したりします。
'settings': {
'index': {
'analysis': {
'char_filter': {
'normalize': {
'type': 'icu_normalizer',
'name': 'nfkc',
'mode': 'compose'
}
},
'tokenizer': {
'ja_kuromoji_tokenizer': {
'mode': 'search',
'type': 'kuromoji_tokenizer'
}
},
'analyzer': {
'kuromoji_analyzer': {
'tokenizer': 'ja_kuromoji_tokenizer',
'char_filter': ['normalize'],
'filter': [
'kuromoji_baseform',
'kuromoji_part_of_speech',
'cjk_width',
'ja_stop',
'kuromoji_stemmer',
'lowercase'
]
}
}
}
}
},
各フィールドでの設定(Mapping)
create_index.pyの下記の部分がMapping設定です。
'mappings': {
'properties': {
'author': {
'type': 'text',
'analyzer': 'kuromoji_analyzer'
},
...
'text_embedding': {
'properties': {
'model_id': {
'type': 'text',
'fields': {
'keyword': {
'type': 'keyword',
'ignore_above': 256
}
}
},
'predicted_value': {
'type': 'dense_vector',
'dims': 768,
'index': True,
'similarity': 'cosine'
}
}
},
...
ドキュメント投入
esre/data配下にNewsAPIから取得したJSONファイルをいくつか置いてあります。とりあえずこのままインデックスします。
docker exec -it esre_flask /bin/bash
cd data
./load_all.sh
データの確認
投入されたデータをKibanaから確認してみましょう。
Cloudにログインして最初に表示されるページから、作成したクラスタをクリックするとKibanaの画面が開きます。
Dataviewの作成
左上の3本線->Stack Management->Data Viewと開いて、右上のCreate Data Viewをクリック
.envのsearch_indexで設定したインデックス名がマッチするように、Index Patternに入力します。
例えばtest_appというインデックス名にしたのであれば、test_appと入力します。ワイルドカードで複数インデックスを纏めてみることも出来ます。
下記の場合だとtest*というパターンにしているので3つのインデックスがマッチしています。

左上の3本線->Analytics->Discoverをクリックすると生データを見ることが出来ます。

左上に赤で囲っている部分で先程作成したData Viewを選択すると、インデックスしたデータが表示されます。300件余りのデータが表示されるはず。
赤で囲った矢印部分をクリックすると詳細パネルが開き、Dense Vectorが付加されていることがわかります。
RAGをやってみよう
さて、これで準備は整いました。
http://localhost:4000を開きます。

検索ボックスに直接入力してもいいですが、まずは「現在のガソリン価格は?」をクリックしてみてください。

左から順番に「通常検索(キーワード検索)」、「ベクトル検索」、「ハイブリッド検索(通常検索とベクトル検索の結果のハイブリッド)」のTop3が表示されています。
キーワード検索とベクトル検索で少し違うのが見て取れると思います。
一番端のOpenAIで検索をクリックしてみましょう。「現在のガソリン価格は?」という質問をそのままOpenAIに投げます。
「私はリアルタイム情報を提供することができませんが、ガソリン価格は地域や国によって異なります。最新のガソリン価格を調べるには、地元のガソリンスタンドやインターネット上のガソリン価格比較サイトを利用してください。」という結果が返ってきますね。まぁ当然です。
ここでポイントは3つ
- 最初の3つの検索は非常に早い
- OpenAI検索は時間がかかる
- 最新情報はわからない
検索自体はやはり通常検索やベクトル検索は非常に速いです(それらのハイブリッドも速い)
この部分をきちんと設計することがRAGでは非常に重要になります。
では次に、「ハイブリッド検索」にあるOpenAIで要約をクリックしてみましょう。
「現在のレギュラーガソリンの小売価格は、1リットルあたり186.5円です 。」
と表示されます。
欲しい情報が得られているのがわかります。
今回の例では通常検索が有利でしたが、ベクトル検索が良い結果を出す場合もあります。
お互いに補完し合う使い方が現状では良い結果が得られるのではないかと思います。
コード解説
app.pyがほぼ全てです。一部Flask(と一緒に入ってくるjinja2)のRendering機能を使用しているので、index.htmlに多少の描画部分が入っていますが、本質の部分では有りません。
ポイントのみかいつまんで説明します。
ここからの解説はWeb FramewworkであるFlaskについては知識がある前提で書いています(というかその部分の説明はありません)
Elastic Cloud接続
cloud_id = os.environ['cloud_id']
cloud_pass = os.environ['cloud_pass']
cloud_user = os.environ['cloud_user']
es = Elasticsearch(cloud_id=cloud_id, basic_auth=(cloud_user, cloud_pass),request_timeout=10)
print(es.info())
まずは.envからElastic Cloudに接続するのに必要な情報を読み込みます。print文で出力されるものがdockerのlogに出ていれば接続完了です。
検索準備
search_index = os.environ['search_index']
bm25_search_fields = ["title", "description"]
bm25_result_fields = ["description", "url", "category", "title"]
search_fieldは検索の際にどのフィールドを検索するか、です。ここはNewsAPIの構成に合わせてあります。
result_fieldで指定したフィールドの値が返ってきます。通常はこれを使ってFacetを作ったりします。
通常の社内文書検索とかだとurlに文書へのリンクが入っていたりすると思います。
def get_rrf_search_request_body(query, search_fields, result_fields, size=10):
return {
'_source': False,
'fields': result_fields,
'size': size,
"query": {
"multi_match": {
"query": query,
"fields": search_fields
}
},
"knn": {
"field": "text_embedding.predicted_value",
"k": 10,
"num_candidates": 100,
"query_vector_builder": {
"text_embedding": {
"model_id": "cl-tohoku__bert-base-japanese-v2",
"model_text": query
}
}
},
"rank": {
"rrf": {
"window_size": 50,
"rank_constant": 20
}
}
}
この関数はハイブリッド検索を行うためのJSONを作成しています。
queryの部分が通常検索、knnがベクトル検索、rrfでランキング作成
通常検索、ベクトル検索用のJSONもget_text_search_request_body、get_vector_search_request_bodyで作成しています。
size=10と設定しているので、結果を10個までにしています。
検索実行
def get_es_result():
query = request.args['var1']
bm25_body = get_text_search_request_body(query,bm25_search_fields,bm25_result_fields)
bm25_result = es.search(index=search_index, query=bm25_body["query"], fields=bm25_body["fields"], size=bm25_body["size"], source=bm25_body["_source"])
bm25_documents = bm25_result['hits']['hits'][:10]
query文はbase.html、index.htmlのこの部分から来てます。JQueryを使った古いやり方です。
Elasticsearch-labsの方にはReactを使ったイケてる実装があります。
<script>
$(function () {
$('#btn').click(function () {
console.log($('#text').val());
let url = "/api/search_results?var1=" + $('#text').val()
console.log(url)
window.location.href = url;
})
});
</script>
query文を受け取ったらes.searchで検索をかけて、JSONで結果を受け取ります。
結果は10個返ってくるのでそれをbm25_documentsに格納しています。
bm25_all = []
for hit in bm25_documents[:3]:
temp_contents = {'url': hit['fields']['url'][0],'title': hit['fields']['title'][0],'description': hit['fields']['description'][0]}
bm25_all.append(temp_contents)
返ってきた結果のうちTop3を取り出しています。
一つの結果を辞書形式で格納して、それをArrayに3つ格納しています。
同じことをベクトル検索、ハイブリッド検索にも行い、すべての検索結果のTop3の内容が揃います。
最後に
return {'bm25': bm25_all,'vector': vector_all,'rrf': rrf_all,'openai_answer': ""}
でそれぞれの内容を辞書形式にして格納します。ここではまだOpenAIには質問を投げていないのでopenai_answerには何も入っていません。
検索結果表示
index.htmlの下記の部分で表示しています。
<div class="col text-center" style="border:solid 2px">
<p class="text-center">通常検索</p>
<button type="button" class="btn btn-primary" id="bm25" style="margin: 5px;">OpenAIで要約</button>
{% for item in all.bm25: %}
<div style="border:solid 1px; margin: 10px">
<p>{{ item.title }}</p>
<p>{{ item.description }}</p>
<a href="{{ item.url }}">View Documents</a>
</div>
{% endfor %}
</div>
jinja2のTemplateに沿った基本的なやり方です。これでそれぞれTop3が表示されます。
OpenAIにクエリを投げる
RAGではなく、純粋に質問文をOpenAIに投げる部分です。
def get_all_results():
query = request.args['var1']
response = get_es_result()
openai_answer = ""
if request.args['var2'] == "openai":
prompt = query
messages = {"message": [{"role": "system", "content": prompt}]}
completion = completion_with_backoff(engine=engine,temperature=0.2,messages=messages["message"])
openai_answer = completion["choices"][0]["message"]["content"]
prompt = queryとなっているのがわかると思います。
ここを起動するのはUIではOpenAIで検索というボタンで、index.htmlの以下の部分に当たります。
(console文は抜いてあります)
相変わらずJQueryで無理やりやってます。
$('#openai').click(function () {
let url = "/api/all_results?var1=" + $('#text').val() + "&var2=openai"
window.location.href = url;
});
以前の結果を保持しとくとかも面倒なので、ここではもう一回Elasticsearchに対する検索をしています(クエリ文が変わらなければ特に結果は変わらない)
RAG
さて、ここからが本番です。Top3の内容(descriptionのみ)をコンテキストに入れてOpenAIに投げます。
def route_api_stream():
all = get_es_result()
all['openai_answer'] = request.args['var3']
query = request.args['var1']
...
documents = all[request.args['var2']]
for item in documents:
prompt += f"Description: {item['description']}"
prompt += f"\nQuestion: {query}"
truncated_prompt = truncate_text(prompt, max_context_tokens - max_tokens - safety_margin)
messages = {"message": [{"role": "system", "content": "Given the following extracted parts of a long document and a question, create a final answer. If you don't know the answer, just say '検索対象からは回答となる情報が見つかりませんでした'. Don't try to make up an answer."},{"role": "system", "content": truncated_prompt}]}
completion = completion_with_backoff(engine=engine,temperature=0.2,messages=messages["message"],stream=True)
ページ遷移毎に毎回検索結果を取ってきています(保持するのが面倒)
通常検索、ベクトル検索、ハイブリッド検索、どの結果を要約させるのかはrequest.args['var2']で決めています。
最初のforループでTop3のdescriptionをpromptに入れて、最後にクエリ分を追加します。
truncated_promptはdescriptionが長すぎる場合にmax_context_token以下になるようにしています。(このソースコードでは4000)
後はmessagesを組み立ててcompletion_with_backoffを呼ぶだけです。
temperatureとか決め打ちになってますので、適宜変更してください。
streamとかごちゃごちゃしている部分は、OpenAIからの回答を随時表示するための仕掛けです。
ChatGPTで徐々に表示されているのを皆さん見ていると思いますが、それです(間にjinja2が入っていてあそこまでなめらかでは有りませんが)
ここを起動する部分はOpenAIで要約というボタンです。
OpenAIに普通に聞いた部分はもう一度聞きに行くと時間がかかるので、下記のようにhtmlから直接取ってきています。
$('#bm25').click(function () {
let url = "/api/completions?var1=" + $('#text').val() + "&var2=bm25&var3=" + $('#openai_answer').text()
window.location.href = url;
});
簡単ですね。
UI無しにして通常検索だけにすれば、数十行で書けてしまう内容です。
まとめ
ソースコードを見てもらえばわかるように、コンテキストに入れるためのコンテンツ(=検索結果)を用意する部分と、実際にOpenAIに投げる部分は完全に分離されています。
RAGを試す場合は両方を考える必要があります。まずお手軽に試してみたいという場合は、用意が簡単な通常検索のみで始めてみて以下のようにステップアップしてみてはいかがでしょうか?
- 通常検索だけでとりあえずTopNの結果でRAGを行う
- 検索結果のチューニングをしてより正確な結果が得られるようにする
- 形態素解析を工夫したり、同義語辞書を作ったり、文章は短いけど重要なフィールドであるタイトルだけ重みを増やす、などいろいろあります
- ベクトル検索で通常検索では拾いきれない部分を補完する
- ベクトル検索のチューニングもしてみる
- モデルを変えてみたり、ファインチューニングしたり
- Prompt Engineering頑張る
- コンテキストに良い内容が入れられるようになれば、より良い回答を生成AIから引き出す工夫をする
こちらの記事が楽しく生成AIを利用できる手助けになれば幸いです。