はじめに
RBD高速化のために使用されるINDEXですが、その仕組みについてみなさん語ることができますか?
テーブルの規模や保存されるレコードの特性を考慮した上で適切に設計しないと、貼ったINDEXがなぜか使われず性能改善が難航する...なんてことにもなりかねません。
一般的にRDBで利用されているB-tree INDEXについて、具体的にどのような仕組みで高速化が図られているのか、どのようなテーブル、カラムに対して設定するのが有効なのかまとめました。
B-tree INDEXの仕組み
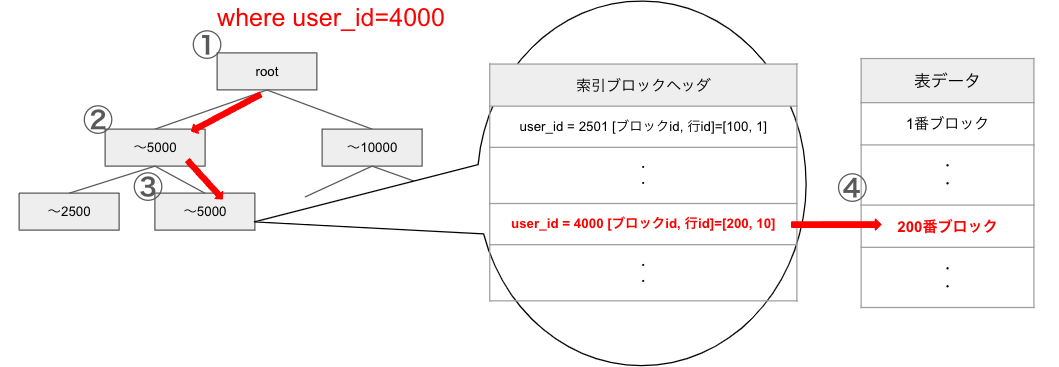
かなり簡略化していますが、BTree INDEXは上記のような構造になっています。
先に索引にアクセスし、必要なブロックだけ取得するため4ブロックのアクセスだけで済みます。
一方でINDEXを使用しない場合、シーケンシャルにブロックにアクセスするため200ブロック読み込む必要があります。
B-treeについてより詳しく学びたい方はこちらを参照ください
インデックスを貼ると更新系の処理が重くなる、という点も広く知られていますが、ここでは詳細な解説を割愛します。興味のある方は、インデックスショットガンで検索いただくと、参考になる素晴らしい記事が多数見つかるはずです。
(以降、INDEXと記載している部分はB-tree INDEXを指しているものとして読み替えてください。)
INDEXのアンチパターン
上述のように探索を高速化してくれるINDEXですが、以下の場合RDBMSはINDEXを使ってくれません。
- 検索結果がテーブル全体のデータに対して一定割合以上占める場合
- カーディナリティの低い列に対する検索
検索結果がテーブル全体のデータに対して一定割合以上占める場合
例えば、総数が1万レコードのテーブルから5000レコード取り出す場合について考えてみます。
- INDEXが使用された場合
- 上述の図において、1行取り出すのであれば「1行4ブロック」でコスト4と考えることができます。5000行取り出すのであれば、「5000行4ブロック」ですのでコストは20000になります
- INDEXを使用しない場合
- テーブルをフルスキャンして、対象のレコード5000行を取り出すので「1OOOO行*1ブロック」でコストは10000になります
少し極端な例でしたが、このようにINDEXを使わない方が早いケースがあるため、RDBMSは以下の条件でINDEXを使用するか否かを判断しています。(具体的な数値についてはRDBMSの種類や設定によって差分があります)
- 検索結果がテーブル全体の約20%以下であるか
- 検索対象にテーブルが数万レコード以上であるか
USE INDEXを指定するなどしてINDEXの使用を強制することもできますが、レコード数を考慮しながら慎重に考える必要がありそうです。
少し余談ですが、RDBMSは統計情報を基にしてSQLの実行計画を立てており、INDEXを使用するか否かもその実行計画ないで判断されるものになります。詳しくは実行計画??統計情報??って人へ に丁寧に書かれていたので参照ください。
カーディナリティの低い列に対する検索
「列に格納されるデータの値にどのくらいの種類があるのか」をカーディナリティと言うらしいです。重複の少ないデータが格納されている場合は、カーディナリティは高くなります。
例えばカーディナリティが低い例として、男女2種類のデータが格納される想定のgender列が挙げられます。
男女の割合が1:1の場合 WHERE gender = 男性で検索するとテーブル全体の50%のレコードが取得されることになります。この場合、検索結果がテーブル全体のデータに対して一定割合以上占めることになり上述の通り、INDEXが使われません。
まとめると、カーディナリティの低い列を基にした検索結果は、検索結果がテーブル全体のデータに対して一定割合以上占めることが多いので、INDEXが使用されないことが多い、と言えることになります。
まとめ
テーブルの特性を考慮しながら適切なINDEXを貼り、性能改善頑張りましょう。