はじめに
新人研修でSQLがカリキュラムに組み込まれている場合、ほとんどがSQLの構文のみをスコープとしていて、RDBMSのアーキテクチャまで踏み込むことは少ないと思います。
本記事では、SELECT、INSERT、UPDATE、DELETEしか教わってないけど、現場に配属されてたら「実行計画を取ってゴニョゴニョ」「あ~統計情報が古いから取り直してゴニョゴニョ」みたいな依頼をされた人へ向けて、超簡単に説明します。
※RDBMSの世界は奥が深いのでここでは概要のみに留めます。
RDBMSの基本的なアーキテクチャ
RDBを使った開発では、ほとんどの現場でOracle、SQL Server、MySQL、DB2、PostgreSQLあたりが利用されています。これらのDBのアーキテクチャは、細かな違いこそあれど基本的なところは同じだったりします。
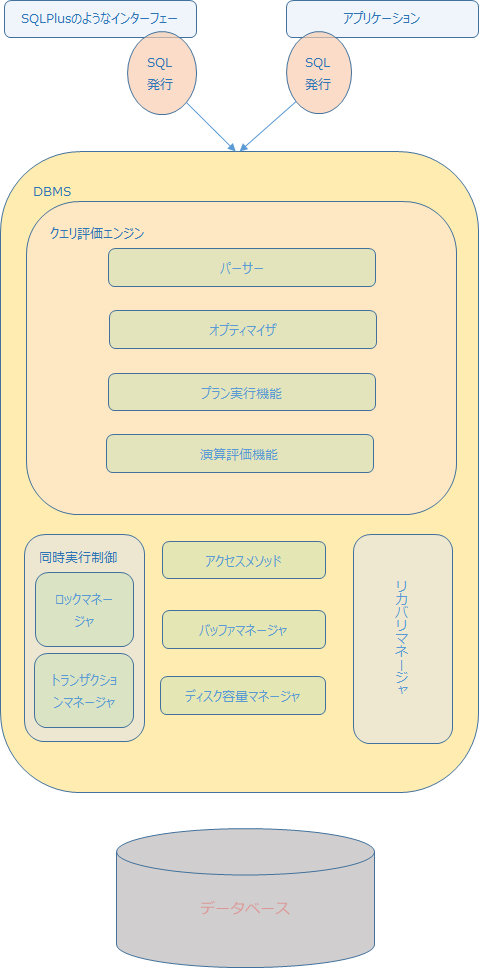
今回は、「実行計画??統計情報??って人へ」ということで、そのあたりに関係のあるクエリ評価エンジンについて軽く触れてみようと思います。
クエリ評価エンジン
まずクエリ評価エンジンとは、実行されたSQL(クエリ)を最初に受け取る機能で、実行されたSQLを解釈してどのような手順で記憶装置のデータ(上記図で言うところのデータベース)にアクセスしにいくかを決定します。
SQLの実行の流れ
SQLの実行の流れは大まかに以下のようになります。
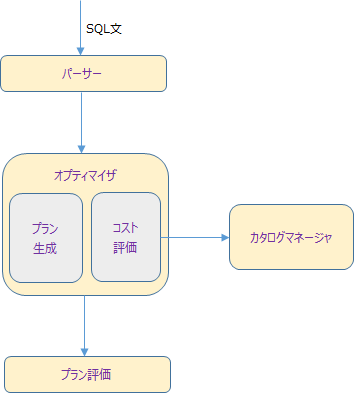
パーサー
実行されたSQLの構文解析(パース)を行い、RDBMSが処理しやすい定型的な形式に変換します。これには以下2つの理由があります。
1. SQL文の整合性チェック
実行されたSQLが常に正しいとは限りません。例えば、SQLを書いた人がカンマを付け忘れていたり、Fromを書き忘れていたり、、、等があったりします。こういったSQLをまずはこの段階で実行エラーとする必要があります。
SELECT
USER_ID
USER_NAME
FROM
USER
SELECT
USER_ID
, USER_NAME
USER
2. 後続処理の効率化
実行されたSQL文を定型的な形式に変換することで、RDBMS内部の後続の処理が効率化されます。
オプティマイザ
無事パーサーを通過したSQL文はオプティマイザに送られます。ここで、最適なデータアクセス方法(実行計画)が決定します。この処理がRDBMSにおけるコアとなる部分です(頭脳なんて表現のされた方をします)。オプティマイザは、複数のアクセス経路、インデックスの有無、データの分散や偏りの度合い、RDBMSの内部パラメータなどの条件を考慮して、コストを評価し選択可能な多くの実行計画を作成します。
実行計画とは
どのようにテーブルに対して検索を行なうかが書かれた、SQLの実行手順書のようなものです。そのため、SQLのパフォーマンスは実行計画によって大きく左右されます。
カタログマネージャ
オプティマイザが実行計画を作成するうえでオプティマイザに重要な情報を提供するのがカタログマネージャです。カタログとはRDBMSの内部情報を集めたテーブル群で、テーブルやインデックスの統計情報が格納されています。そのため、このカタログの情報を単に「統計情報」とも呼びます。
統計情報とは
表やインデックス、使用している領域、データの種類、データの分布等のデータ特性を表す情報のことです。RDBによって若干異なりますが、統計情報には主に以下の情報が含まれます。
- 各テーブルのレコード数
- 各テーブルの列数と列のサイズ
- 列値のカーディナリティ(値の個数)
- 列値のデータ分布(どの値がいくつあるかのヒストグラム)
- 列内のNULLの数
- インデックス情報
実行計画と統計情報の関係
実行計画と統計情報の大まかな関係は以下のようになります。
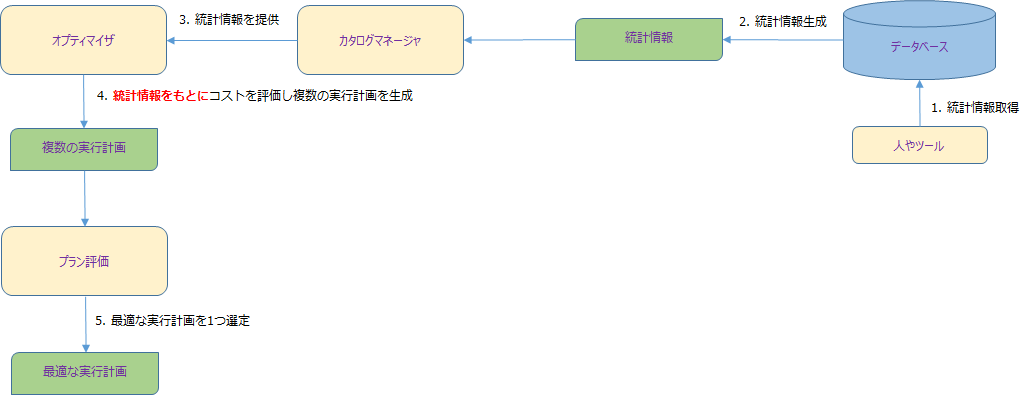
オプティマイザは統計情報をもとに実行計画を作成します。注意したいのは、実際のデータベースの情報をもとに実行計画を作成するのではなく、統計情報をもとに実行計画を作成する、という点です。つまり、テーブルに対してデータの登録・更新・削除が行われたのに、統計情報が最新化されていないと、オプティマイザは古い情報をもとに実行計画を作ろうとします。そのため、ある時点では最適な実行計画が選ばれSQLのパフォーマンスも問題なかったが、データの登録・更新・削除が頻繁に行われるにつれてSQLのパフォーマンスが劣化していく、といったケースがよくあります。これを回避するには、テーブルのデータに大きな更新が入ったら併せて統計情報も最新化する必要があります。
プラン評価
オプティマイザが複数の実行計画を立てたら、それらを受け取って最適な実行計画を選択するのがプラン評価の処理です。
こうして1つの実行計画に絞り込まれたあとに、それをもとにRDBMSはデータアクセスを実行します。