はじめに
ICCV 2019のベストペーパーであるSinGANを読んで自分なりにまとめました.
すでに以下の方が解説を書かれており,僕も参考にさせていただいたのですが,自分の言葉でまとめたかったのと,勉強会で発表するために細部までまとめたので公開します.間違い指摘・質問・その他コメント大歓迎です.
論文データ:
Shaham, Tamar Rott, Tali Dekel, and Tomer Michaeli. "SinGAN: Learning a Generative Model from a Single Natural Image." Proceedings of the IEEE International Conference on Computer Vision. 2019.
勉強会で発表したスライドはこちらです.
注意
- 引用元を書いていない画像はすべて論文のものです
- GeneratorをG,DiscriminatorをDと略記しています
Overview
-
1枚の画像中のpatch distributionを学習
- データセット不要!
- 単一のモデルで様々なimage manipulationタスクを実現
- 超解像タスクでSOTA
- Fully ConvolutionalなGeneratorにより入力(出力)画像のサイズやアスペクト比が任意
Method
画像の複雑な統計を様々なスケールでcaptureしたい
- large objectsの並びや形と細かいtextureなど
→ヒエラルキー状のPatch-GANs
粗い画像から段階的に高解像にしながら様々なスケールの特徴をcaptureする
画像全体を記憶しないように,小さいreceptive field(受容野)を設定
CNNにおける受容野はこちらの解説がわかりやすいです.
Receptive field(受容野)とは,ある特徴マップの1画素が集約している前の層の空間の広がりであり,受容野が広いほど認識に有効な大域的なコンテキスト情報を含んでいると言える.
Pipeline
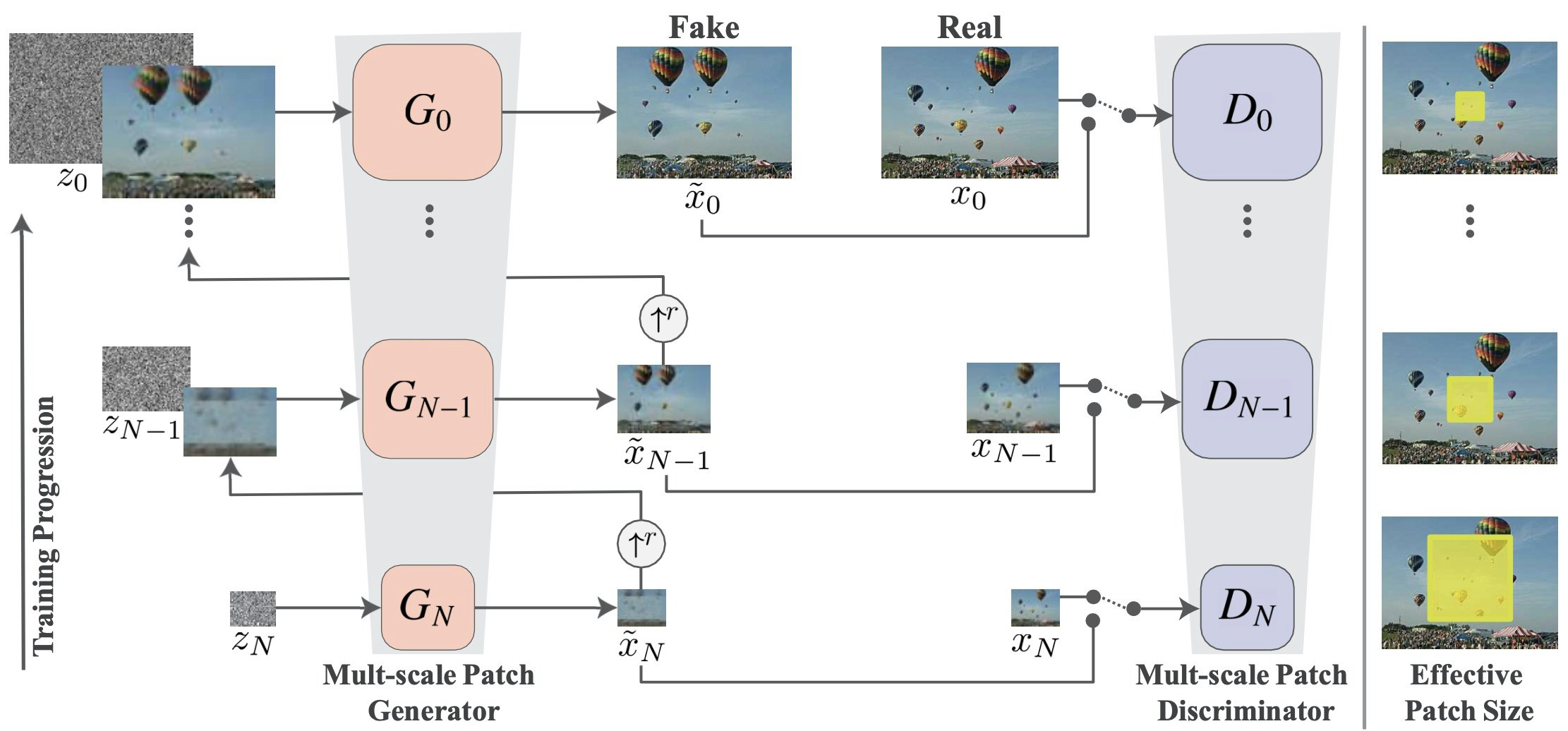
最も粗い$N$番目のscaleでは,$G_N$に低解像度のガウシアンノイズ$z_N$を入力し,同じく低解像度の画像$\tilde x_N$を生成します.それをスケール$r$でupsampleし,同サイズのノイズ$z_{N-1}$を足したものを$G_{N-1}$に入力し,少し解像度の高い画像$\tilde x_{N-1}$を生成します.これを繰り返し,scaleを上げながらノイズによって変化させつつ,realisticに見えるようなdetailも足していきます.
Discriminatorは各scaleにおいて出力が本物か生成されたものかを識別します.
上の画像右端のEffective Patch Sizeは,各scaleでの受容野を黄色い領域で表したものです.黄色い領域が小さくなっていっているように見えますが,実際は後述の通り畳み込み層のkernelサイズが固定で画像の方が大きくなっていくため,相対的に受容野が小さくなっていきます.これにより,粗いscaleで大域情報を,fineなscaleで局所情報をcaptureしていきます.
Generator architecture
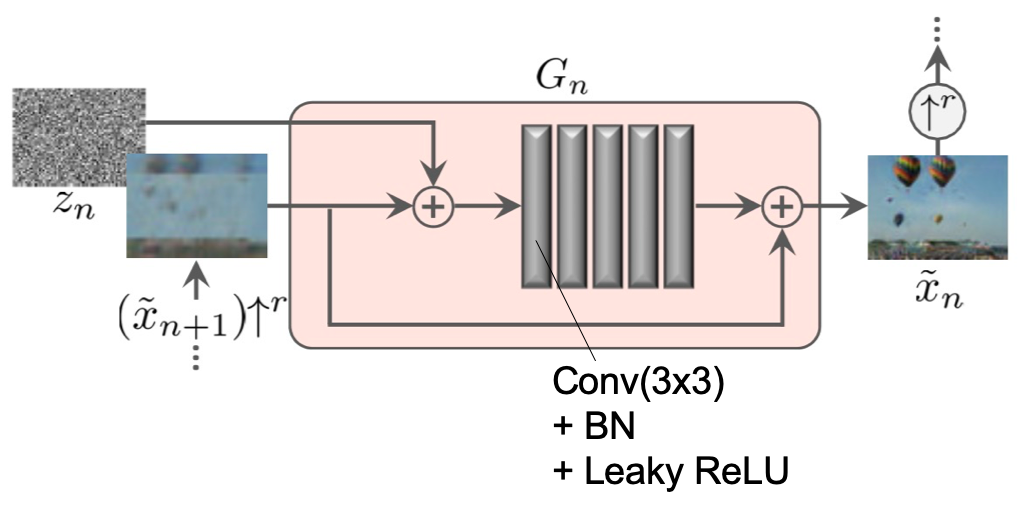
GeneratorはResNetで用いられるようなresidualな構造,つまり入力と出力の差を埋めていくような構造になっています.前のscaleから上がってきた少し粗い画像をupsampleした
$\left(\tilde x_{n+1}\right) \uparrow^{r}$にノイズ$z_n$を足して畳み込んでいき,最終層の出力を$\left(\tilde{x}_{n+1}\right) \uparrow^{r}$に足したものが$G_n$の出力となります.すべてのscaleでこの構造です.
このようなFully ConvolutionalなGeneratorによって任意の画像サイズに対応できます.このFully Convolutionalというのは畳み込み層のみで,全結合やupsampleを用いないということかなと思っていますが合っているでしょうか.
Loss Function
$n$番目のscaleのGとDのLossは,通常のadversarial lossと,CycleGAN等でも使われているreconstruction lossを足したものとしています.$\alpha$でそれらのバランスを調整します.
$$\min {G{n}} \max {D{n}} \mathcal{L}{\mathrm{adv}}\left(G{n}, D_{n}\right)+\alpha \mathcal{L}{\mathrm{rec}}\left(G{n}\right)$$
ここで,$\mathcal L_{rec}$は,$n+1$番目のscaleで生成された粗い画像
$\tilde x_{n+1}^{\mathrm{rec}}$をアップスケールしたものと,ダウンスケールした訓練画像$x_n$とのL2ノルムです.
$$\mathcal{L}{\mathrm{rec}}=\left|G{n}\left(0,\left(\tilde{x}{n+1}^{\mathrm{rec}}\right) \uparrow^{r}\right)-x{n}\right|^{2}$$
ただし,$N$番目の最も粗いscaleでは$G_N$にノイズのみ入力されるため,
$\mathcal L_{\mathrm{rec}}=\left|G_{N}\left(z^{*}\right)-x_{N}\right|^{2}$ となります.
訓練画像のpatch distributionを保持しつつ変化させたいので,この$\mathcal L_{rec}$により画像が変化しすぎるのを防いでいます.
reconstructionした画像にはLossの計算以外にもう一つ役割があります.入力ノイズ$z_n$の標準偏差$\sigma_n$を$\left(\tilde{x}_{n+1}^{\mathrm{rec}}\right) \uparrow^{r}$と$x_n$のRMSEに比例させることで,そのスケールで足すべきdetailの度合いを調整できるらしいです.これはよくわかりませんでした.
WGAN-gpについて
DのLossには,勾配消失を防ぐためにWGAN-gpが使われています.内容については以下の解説を参考にさせていただきました.
Results
Effect of scales at test time
学習済みモデルに画像を入力する際に,どのscaleから始めるかによって生成をコントロールできます.
N番目の最も粗いscaleから始める場合,ノイズのみで画像を入力しないため,$G_{\mathrm N}$は大域的情報が比較的大きく変化した画像を生成します.その先のGは$G_{\mathrm N}$が生成した画像にfine texture等のdetailのみを足していくため,最終的な生成画像も大域情報が変化したままになります.下の画像の1列目を見ると,シマウマの足が多かったり,首元が太くなったりしているのがわかると思います.入力画像がないのでわかりませんが.
次に,$G_{\mathrm N}$を使わずに$G_{\mathrm N-1}$から始める場合,ノイズだけでなく画像も一緒に入力するため,先程のような大域的な変化は起こりにくくなります.画像2列目ではシマウマの体の形自体は変わらず,縞模様だけが変化しています.3列目のN-2から始めた場合は更に細かい模様だけが変化しています.
このように,fineなscaleから始めるほど変化が局所的になっていきます.

Effect of scales during training
ここは理解が曖昧なところなのですが,おそらくどこまで粗いscaleから始めるかということだと思います.Generator内の畳み込み層におけるkernelサイズが固定なので,小さい,つまり粗いscaleになるほど画像サイズに対して受容野が大きくなり,大域的な情報をcaptureできるようになります.
下の画像を見ると,scaleを増やすほど,つまり粗いscaleから始めるほどtextureだけでなくオブジェクトの構造等も再現できるようになるのがわかります.

Quantitative Evaluation
AMT perceptual study
いつか追記します.
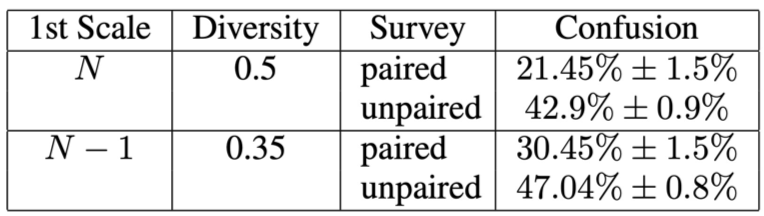
被験者にSinGANで生成した画像を見せて,本物か偽物か答えてもらった結果が以下のとおりです.
new single-image version of the Frechet Inception Distance (SIFID)
いつか追記します.
GANの定量評価でよく用いられるFIDをsingle imageに適用したようです.

perceptual studyの結果と相関があるので,SIFIDは人間の感覚に合っていると述べられています.
Applications
patch distributionを学習するとなぜimage manipulationできるの?と思いましたが,基本的な考え方は以下のとおりです.
SinGANは訓練画像と同じpatch distributionの画像を生成しようとします.つまり,入力画像が訓練画像のpatch distributionに合っていなければ,それを合うように,自然に見えるように変化させていきます.この入力を**injection(注入)**と呼んでいます.
Super-Resolution
入力画像をupsampleし,SinGANの最終scaleに入力することを繰り返します.引き伸ばしてからdetailを足す作業を繰り返すことで超解像を実現しています.超解像は入力画像をなるべく保存したいので,$L_{rec}$の重み$\alpha$を100と(おそらく)大きくしています.

Paint-to-Image
このタスクでは入力画像のエッジ等の低次元情報を保存しなければならないので,$N$番目のノイズのみを入力とするGは使いません.downsampleしたpaint画像を$N-1$や$N-2$番目のGに入力し,段々と細かいtexture等のdetailを足していきます.
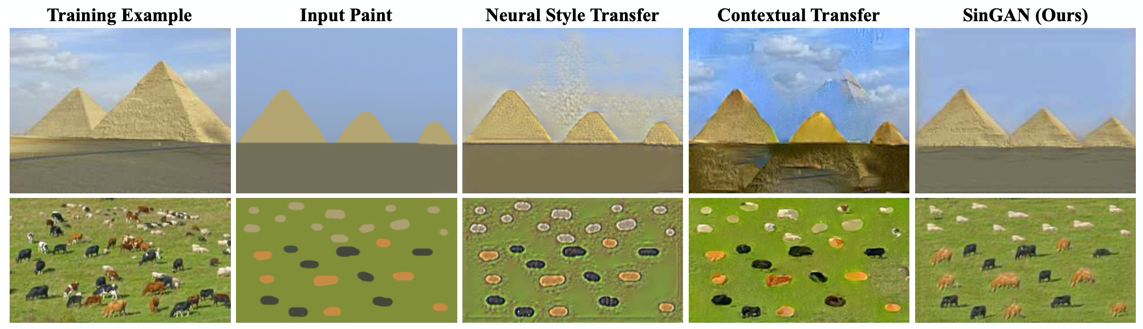
Harmonization
背景のみの画像で学習し,そこにペタっと貼られたオブジェクトのtextureを背景に合うように変化させます.既存の手法に比べてオブジェクトの構造維持と背景との調和のバランスがとれています.

Editing
Harmonizationと同じような感じだと思います.

Single Image Animation
いつか追記します.潜在変数空間をランダムウォークさせているようです.
感想
- Lossは結構単純だった
- 解像度どこまで大きくできる?
- 他にも幅広く応用できそう