昨年に引き続きDeep Learningやっていき Advent Calendar 2017の25日目の滑り込み記事で,畳み込みニューラルネットワークの歴史および最新の研究動向についてのサーベイです.2017年12月のPRMU研究会にて発表した,畳み込みニューラルネットワークについてのサーベイをベースに追記を行ったものになります.
はじめに
畳み込みニューラルネットワーク (Convolutional Neural Networks; CNN) (以降CNN)は,主に画像認識に利用されるニューラルネットワークの一種である.CNNの原型は,生物の脳の視覚野に関する神経生理学的な知見1を元に考案されたNeocognitron2に見ることができる.Neocognitronは,特徴抽出を行なう単純型細胞に対応する畳み込み層と,位置ずれを許容する働きを持つ複雑型細胞に対応するpooling層とを交互に階層的に配置したニューラルネットワークである.Neocognitronでは自己組織化による学習が行われていたが,その後,LeCunらによりCNNのbackpropagationを用いた学習法が確立され,例えばLeNet3は,文字認識において成功を収めた.
 Neocognitron[^Fukushima_pr82](左)とLeNet[^LeCun_ieee98](右)のアーキテクチャ
Neocognitron[^Fukushima_pr82](左)とLeNet[^LeCun_ieee98](右)のアーキテクチャ
2000年代においては,画像認識分野では,SIFT4等の職人芸的に設計された特徴ベクトルと,SVM等の識別器を組合せた手法が主流となっていた.その時代においてもニューラルネットワークの研究は進められており,ついに2012年の画像認識コンペティションImageNet Large Scale Visual Recognition Competition (ILSVRC) において,AlexNetと呼ばれるCNNを用いた手法が,それまでの画像認識のデファクトスタンダードであったSIFT + Fisher Vector + SVM5というアプローチに大差をつけて優勝し,一躍深層学習が注目されることとなった.
それ以降のILSVRCでは,CNNを用いた手法が主流となり,毎年新たなCNNのモデルが適用され,一貫して認識精度の向上に寄与してきた.そしてILSVRCで優秀な成績を収めたモデルが,画像認識やその他の様々なタスクを解くためのデファクトスタンダードなモデルとして利用されてきた.
CNNは画像認識だけではなく,セグメンテーション6 7 8,物体検出9 10 11,姿勢推定12 13 14など様々なタスクを解くためのベースネットワークとしても広く利用されてきている.また,画像ドメインだけではなく,自然言語処理15 16 17,音響信号処理18 19,ゲームAI20等の分野でも利用されるなど,ニューラルネットワークの中でも重要な位置を占めている.
このような背景のもと,本稿では,AlexNet以降の代表的なCNNのモデルの変遷を振り返るとともに,近年提案されている様々な改良手法についてサーベイを行い,それらを幾つかのアプローチに分類し,解説する.本稿では,CNNのモデルをどのような構造にするかというモデルアーキテクチャに焦点をあてており,個々の構成要素や最適化手法については詳述しない.そのため,より広範な内容については文献21を参照されたい.
結論のようなもの
ResNetが1つの大きなブレークスルーであり,それ以降のモデルはほとんどがResNetの改良と言え,DenseNet以外に独自の全体的なアーキテクチャの成功例はない.Residualモジュールの改良の観点では,ほぼすべての手法が次元削減とsparseな畳み込みを組合せることで,精度とパラメータ数のトレードオフを改善しているアプローチと言える.すなわち,畳み込みのパラメータを削減し,その分深さや幅を大きくすることで精度を向上しているのである.
データおよびモデル内の正則化は,他の手法と組合せられる上に効果が大きく期待できるが,何故改善できているのか不明な点も多く,今後の理論的な説明が期待される.
人間の考案したアーキテクチャを上回る精度を達成するネットワークの自動設計も実現されつつあるが,利用される全体構造や構成要素は引き続き人間が考案したものであり,例えばResNetのショートカットのような構成要素が自動的に発見されるような仕組みはまだ存在しない.
ILSVRCで振り返るCNNの進化
本章では,2012年から2017年までのILSVRCのクラス分類タスク(以降では単にILSVRC)において優秀な成績を収めたモデルを順に振り返り,CNNがどのような進化を辿ってきたかを概観する.下図に2010年から2017年のILSVRCのクラス分類タスクで達成されたtop-5エラー率と,2012年以降のCNNベースのモデルを示す.
 http://image-net.org/challenges/talks_2017/ILSVRC2017_overview.pdf
http://image-net.org/challenges/talks_2017/ILSVRC2017_overview.pdf
AlexNet (2012)
AlexNet22は,2012年のILSVRCにおいて,従来の画像認識のデファクトスタンダードであったSIFT + Fisher Vector + SVM5というアプローチに大差をつけて優勝し,一躍深層学習の有効性を知らしめたモデルである.現在では比較的小規模なモデルということもあり,ベースラインとして利用されることもある.
 文献[^Krizhevsky_nips12]より
文献[^Krizhevsky_nips12]より
上図はAlexNetのアーキテクチャである22.AlexNetは,畳み込み層を5層重ねつつ,pooling層で特徴マップを縮小し,その後,3層の全結合層により最終的な出力を得る.基本的なアーキテクチャの設計思想はNeocognitronやLeNetを踏襲している.学習時には,当時のGPUのメモリ制約から,各層の特徴マップをチャネル方向に分割し,2台のGPUで独立して学習するというアプローチが取られた.幾つかの畳み込み層および全結合層では,より有効な特徴を学習するため,もう1台のGPUが担当しているチャネルも入力として利用している.
CNNの重みはガウス分布に従う乱数により初期化され,モーメンタム付きの確率的勾配降下法 (Stochastic Gradient Descent, SGD) により最適化が行われる.各パラメータはweigtht decay($\ell_2$正則化)により正則化が行われている.ロスが低下しなくなったタイミングで学習率を1/10に減少させることも行われており,上記の最適化の手法は,現在おいてもベストプラクティスとして利用されている.以下では,AlexNetに導入された重要な要素技術について概説する.
ReLU
従来,非線形な活性化関数としては,$f(x) = \mathrm{tanh}(x)$や$f(x) = (1 + e^{-x})^{-1}$が利用されていたが,$f(x) = \max(0, x)$と定義されるRectified Linear Units (ReLU)23 24を利用することで学習を高速化している.これは,深いネットワークで従来の活性化関数を利用した場合に発生する勾配消失問題を解決できるためである.ReLUは,その後改良がなされた活性化関数も提案されている25 26 27が,最新のモデルでも標準的な活性化関数として広く利用されている.
LRN
Local Response Normalization (LRN) は,特徴マップの同一の位置にあり,隣接するチャネルの出力の値から,自身の出力の値を正規化する手法である.空間的に隣接する出力も考慮して正規化を行うLocal Contrast Normalization (LCN)23と比較して,平均値を引く処理を行わず,より適切な正規化が行えるとしている.後述するVGGNetでは効果が認められなかったことや,batch normalization28の登場により,近年のモデルでは利用されなくなっている.
Overlapping Pooling
Pooling層は,$s$ピクセルずつ離れたグリッドにおいて,周辺$z$ピクセルの値をmaxやaverage関数によって集約する処理と一般化することができる.通常,pooling層は$s = z$とされ,集約されるピクセルが複数のグリッドにまたがってoverlapしないことが一般的であった.AlexNetでは,$s = 2$, $z = 3$のmax poolingを利用しており,この場合,集約されるピクセル領域がオーバラップすることになる.このoverlapping poolingにより,過学習を低減し,わずかに最終的な精度が向上すると主張されている.
Dropout
Dropout29は,学習時のネットワークについて,隠れ層のニューロンを一定確率で無効化する手法である.これにより,擬似的に毎回異なるアーキテクチャで学習を行うこととなり,アンサンブル学習と同様の効果をもたらし,より汎化されたモデルを学習することができる.AlexNetでは,最初の2つの全結合層にこのdropoutが導入されている.Dropoutを行わない場合にはかなりの過学習が発生したが,dropoutによりこの過学習を抑えられる一方,収束までのステップ数が約2倍になったと報告されている.
ZFNet (2013)
ZFNet30は,2013年のILSVRCの優勝モデルである.文献30では,CNNがどのように画像を認識しているかを理解し,またどうすればCNNの改良ができるかを検討することを目的とし,CNNの可視化を行っている.その可視化の結果,AlexNetの2つの問題が明らかとなり,これらの問題を解決する改良を行い,高精度化につなげている.
文献30で明らかとなったAlexNetの第1の問題は,最初の畳み込み層のフィルタが,大きなカーネルサイズを利用していることから極端に高周波と低周波の情報を取得するフィルタとなっており,それらの間の周波数成分を取得するフィルタが殆ど無かったという点である.第2の問題は,2層目の特徴マップにおいて,エイリアシングが発生していることである.これは,最初の畳み込み層において,strideに4という大きな値を使っているためである.
これらの問題を解決するため,
- 最初の畳み込み層のフィルタサイズを11から7に縮小する
- strideを4から2に縮小する
という改良を行い,AlexNetを超える認識精度を達成した.最終的なZFNetのアーキテクチャは下記のようなものである30.Layer 2のmax pooling以降の構造はAlexNetと同一である(AlexNetはGPU2台で学習するためにモデルを分割していたが,ZFNetは1GPUで学習している).
 文献[^Zeiler_eccv14]より
文献[^Zeiler_eccv14]より
GoogLeNet (2014)
GoogLeNet31は,2014年のILSVRCの優勝モデルである.このモデルの特徴は,下記で詳述するInceptionモジュールの利用である.
Inceptionモジュール
GoogLeNetの一番の特徴は,複数の畳み込み層やpooling層から構成されるInceptionモジュールと呼ばれる小さなネットワーク (micro networks) を定義し,これを通常の畳み込み層のように重ねていくことで1つの大きなCNNを作り上げている点である.本稿では,このような小さなネットワークをモジュールと呼ぶこととする.この設計は,畳み込み層と多層パーセプトロン(実装上は1×1畳み込み)により構成されるモジュールを初めて利用したNetwork In Network (NIN)32に大きな影響を受けている.

上記にInceptionモジュールの構造を示す.Inceptionモジュールでは,ネットワークを分岐させ,サイズの異なる畳み込みを行った後,それらの出力をつなぎ合わせるという処理を行っている.この目的は,畳み込み層の重みをsparseにし,パラメータ数のトレードオフを改善することである.
そもそも畳み込み層は,sparseかつ共有された重みを持つ全結合層とみなすことができるが,この畳み込み層自体も,入力チャネルとフィルタの重みとしてはdenseな結合をしていると言える.これに対し,Inceptionモジュールは,この入力チャネルとフィルタの重みがsparseになったものとみなすことができる.すなわち,(b)のnaiveなInceptionモジュールは,maxpoolを除けば,本来は重みがsparseな5×5の畳み込み1つで表現することができる.これを明示的にInceptionモジュールを利用することで,遥かに少ないパラメータで同等の表現能力を持つCNNを構築することができる.
このパラメータの削減は下図のように直感的に理解することができる.すなわち,畳み込み層のパラメータ数はbias項を除くと入力チャネル数×出力チャネル数×カーネルサイズ(e.g. 5x5=25)で表現される.通常の畳み込みであれば,左のようにパラメータは全て何かしらの値を持っているためdenseである.一方,Inceptionでは異なるサイズの畳み込みを独立して行っているため,非0のパラメータ数が大きく減ることになる.

また,実際に利用されている(a)のInceptionモジュールでは,各畳み込み層の前に1×1の畳み込み層を挿入し,次元削減を行うことで更にパラメータを削減している.
Global Average Pooling
GoogLeNetではGlobal Average Pooling (GAP)32が導入されている点にも注目したい.従来のモデルは,畳み込み層の後に複数の全結合層を重ねることで,最終的な1000クラス分類の出力を得る構造となっていたが,これらの全結合層はパラメータ数が多く,また過学習を起こすことが課題となっており,dropoutを導入することで過学習を抑える必要があった.
文献32で提案されているGAPは,入力された特徴マップのサイズと同じサイズのaverage poolingを行うpooling層である(すなわち出力は1×1×チャネル数のテンソルとなる).文献32では,CNNの最後の畳み込み層の出力チャネル数を最終的な出力の次元数(クラス数)と同一とし,その後GAP(およびsoftmax)を適用することで,全結合層を利用することなく最終的な出力を得ることを提案している.全結合層を利用しないことで,パラメータ数を大きく削減し,過学習を防ぐことができる.下図にNINでのGAP処理を示す.

GoogLeNetでは,最後の畳み込み層の出力チャネル数をクラス数と同一にすることはせず,GAPの後に全結合層を1層だけ適用し,最終出力を得る構成としている.このGAPの利用は,現在ではクラス分類を行うCNNのベストプラクティスとなっている.
Auxiliary Loss
GoogLeNetの学習では,ネットワークの途中から分岐させたサブネットワークにおいてもクラス分類を行い,auxiliary lossを追加することが行われている.これにより,ネットワークの中間層に直接誤差を伝搬させることで,勾配消失を防ぐとともにネットワークの正則化を実現している.
Inception-vX
文献33では,5×5の畳み込みを3×3の畳み込みを2つ重ねたものに置き換えることで更にInceptionモジュールのパラメータを削減したり,後述するbatch normalization28を導入したりする等の改良が行われたInception-v2,3が提案されている.更に,文献34では,$n$×1や1×$n$の畳み込みを多数導入し,精度と計算量のトレードオフを改善したInception-v4や,後述するResNetの構造を取り入れたInception-ResNetが提案されている.
VGGNet (2014)
VGGNet35は,2014年のILSVRCにおいて,2位の認識精度を達成したモデルである.そのシンプルなモデルアーキテクチャや学習済みモデルが配布されたことから,現在においてもベースラインのモデルとして,またクラス分類以外のタスクのベースネットワークや特徴抽出器としても利用されている.
文献35の主な関心は,CNNの深さがどのように性能に影響するかを明らかにすることである.この目的のために,下記のようなモデルアーキテクチャの設計方針を明確にし,深さのみの影響が検証できるようにしている.
- 3×3(一部1×1)の畳み込みのみを利用する
- 同一出力チャネル数の畳み込み層を幾つか重ねた後にmax poolingにより特徴マップを半分に縮小する
- max poolingの後の畳み込み層の出力チャネル数を2倍に増加させる
この設計方針は,その後のモデルアーキテクチャにおいて広く取り入れられていくこととなる.文献35は,上記の統一的な設計方針の元,ネットワークの深さを増加させていくとコンスタントに精度が改善することを示した.
上記の3×3畳み込み層の利用は,モデルアーキテクチャをシンプルにするだけではなく,より大きなカーネルサイズの畳み込み層を利用する場合と比較して,表現能力とパラメータ数のトレードオフを改善する効果がある.例えば,3×3の畳み込み層を2つ重ねたネットワークは,5×5の畳み込み層と同一のreceptive fieldを持ちつつ,パラメータ数を5×5=25から3×3×2=18に削減できていると言える.ここで,Receptive field(受容野)とは,ある特徴マップの1画素が集約している前の層の空間の広がりであり,受容野が広いほど認識に有効な大域的なコンテキスト情報を含んでいると言える.更に,文献35の主張である深さを増加させることができることから,その後のモデルアーキテクチャでは3×3の畳み込み層が標準的に利用されることとなる.
AlexNetやZFNetで利用されていたLRNは,VGGNetのような深いネットワークではあまり効果がなかったことが確認されており,利用されていない.VGGNetは,従来と比較して深いネットワークであるため学習が難しく,まず浅いネットワークを学習し,その後畳み込み層を追加した深いネットワークを学習するという方針を取っている.一方,その後の検証で,Glorotの初期化36を利用することで,事前学習なしでも深いネットワークの学習が可能であると報告されている.
ResNet (2015)
Residual Networks (ResNet)37は,2015年のILSVRCの優勝モデルである.VGGNetで示されたように,ネットワークを深くすることは表現能力を向上させ,認識精度を改善するが,あまりにも深いネットワークは効率的な学習が困難であった.ResNetは,通常のネットワークのように,何かしらの処理ブロックによる変換$F(x)$を単純に次の層に渡していくのではなく,その処理ブロックへの入力$x$をショートカットし,$H(x) = F(x)+x$を次の層に渡すことが行われる.このショートカットを含めた処理単位をresidualモジュールと呼ぶ.ResNetでは,ショートカットを通して,backpropagation時に勾配が直接下層に伝わっていくことになり,非常に深いネットワークにおいても効率的に学習ができるようになった.
ショートカットを利用するアイディアは,gate関数によって$x$と$F(x)$の重みを適用的に制御するHighway Networks38 39においても利用されているが,非常に深いネットワークにおいて精度を改善するには至っていなかった.
Residualモジュール
下図にresidualモジュールの構造を示す.

(a)はresidualモジュールの抽象的な構造を示し,(b)は実際に使われるresidualモジュールの例を示しており,出力チャネル数が64の3×3の畳み込み層が2つ配置されている.正確には,畳み込み層に加えて,後述するbatch normalizationとReLUが配置されており,文献37のResNetでは下記のような構造のresidualモジュールが利用される.
conv - bn - relu - conv - bn - add - relu
ここでaddは,$F(x)$と$x$の和を示している.このresidualモジュールの構造に関しては複数の改良手法が提案されており,後ほど詳述する.
(c)は,residualモジュールのbottleneckバージョンと呼ばれるものであり,1×1の畳み込みにより,次元削減を行った後に3×3の畳み込みを行い,その後さらに1×1により次元を復元するという形を取ることで,(b)と同等の計算量を保ちながら,より深いモデルを構築することができる.実際に,(b)のresidualモジュールを利用したResNet-34と比較して,同等のパラメータ数を持つ(c)のモジュールを利用したResNet-50は大きく精度が改善していることが報告されている.
Residualモジュールのショートカットとして,基本的にはidentity function $f(x) = x$が利用されるが,入力チャネル数と出力チャネル数が異なる場合には,不足しているチャネルを0で埋めるzero-paddingと,1×1の畳み込みによりチャネル数を調整するprojectionの2パターンのショートカットが選択肢となる.このうち,zero-paddingのアプローチのほうが,パラメータを増加させないことから良いとされるが,実装が容易なprojectionが利用されることも多い.
Batch normalization
深いネットワークでは,ある層のパラメータの更新によって,その次の層への入力の分布がバッチ毎に大きく変化してまう内部共変量シフト (internal covariate shift) が発生し,学習が効率的に進まない問題があった.Batch normalization28は,この内部共変量シフトを正規化し,なるべく各レイヤが独立して学習が行えるようにすることで,学習を安定化・高速化する手法である.ResNetではこのbatch normalizationをresidualモジュールに組み込むことで深いネットワークの効率的な学習を実現しており,ResNet以降のモデルでは,batch normalizationが標準的に用いられるようになった.
ResNetの構造
ResNetは,前述のresidualモジュール複数積み重ねることにより構築される.下図に,例として34層のResNet-34の構造を示す.

まずstrideが (2, 2) の7×7畳み込みを行った後,$s = 2$, $z = 3$のmax poolingを行うことで特徴マップを縮小する.その後は,VGGNetと同様に,同一の出力チャネル数を持つresidualモジュールを複数重ね,その後に特徴マップを半分に縮小しつつ出力チャネル数を2倍にすることを繰り返すことでネットワークが構成される.特徴マップを半分に縮小する処理は,max poolingではなく,各residualモジュールの最初にstrideが (2, 2) の畳み込みを行うことで実現している.またGoogLeNetと同様に全結合層の前はGAPを利用するという方針を取っている.
Heの初期化
VGGNetでは,ランダムに初期化する重みのスケールを適切に設定するGlorotの初期化36を利用することで,深いネットワークでも事前学習なしで学習が可能であると報告されていた.しかしながら,Glorotの初期化で行われるスケーリングは,線形の活性化関数を前提としており,ReLUを活性化関数として利用している場合には適切ではない.これに対し,文献25では,ReLUを活性化関数として利用する場合の適切なスケーリングを理論的に導出しており,ResNetでは,このHeの初期化が用いられる.
ResNetの興味深い性質として,ランダムに1つだけresidualモジュールを削除したとしても,認識精度がほとんど低下しないことが挙げられる40.これは,residualモジュールのショートカットを再帰的に展開していくと,異なる深さのネットワークを統合しているネットワークと同値であることが示されているように,ResNetが暗黙的に複数のネットワークのアンサンブル学習を行っているためと考えられている.
SENet (2017)
Squeeze-and-Excitation Networks (SENet)41は,2017年のILSVRCの優勝モデルであり,特徴マップをチャネル毎に適応的に重み付けするAttentionの機構を導入したネットワークである.このAttentionの機構は,Squeeze-and-Excitation Block (SE Block) によって実現される.下記にSE Blockの構造を示す.

SE Blockは名前の通り,SqueezeステップとExcitationステップの2段階の処理が行われる.Squeezeステップでは,$H$×$W$×$C$の特徴マップに対しGAPが適応され,画像の全体的な特徴が抽出された1×1×$C$のテンソルが出力される.次に,Excitationステップでは,1×1の畳み込みにより,特徴マップのチャネル間の依存関係が抽出される.具体的には,出力チャネル数が$C / r$の1×1の畳み込みが適用され,ReLUを経て,更に出力チャネル数$C$の1×1の畳み込みが適用される.最後にシグモイド関数が適用され,特徴マップのチャネル毎の重みが出力される.このチャネル毎の重みを用いて特徴マップをスケーリングすることで,画像全体のコンテキストに基づいた特徴選択を実現している.
このSE Blockの機構は極めて汎用的で,基本的にはどのようなモデルにも導入することができる.文献41では,ResNetや,後述するResNeXt,Inception-v3,Inception-ResNet-v2といったモデルにSE Blockを導入し,コンスタントに精度改善を実現している.SENetでは,チャネル毎のAttentionを適用しているが,空間・チャネル両方に対してAttentionを適用している手法も存在する42.
ILSVRCにおけるCNNの進化のまとめ
これまで解説した,ILSVRCにおいて特に重要なアーキテクチャおよび技術要素を下記にまとめる.

現在のデファクトスタンダードと言えるResNetで利用されている技術要素について着目してみると,スキップコネクションという最も重要な技術要素こそResNetにて初めて利用されているものの,その他の技術要素はこれまでのCNNの進化の過程で取り入れられてきたものが多く,正にCNNの集大成と言えるアーキテクチャであることが分かる.
最新のCNN改良手法
ILSVRCで優秀な成績を納めた手法以外にも様々なCNNの改良手法が提案されている.本章では,これらの手法を下記のように6種類に分類し,それぞれ解説する.
- Residualモジュールの改良
- 独自モジュールの利用
- 独自マクロアーキテクチャの利用
- 正則化
- 高速化を意識したアーキテクチャ
- アーキテクチャの自動設計
Residualモジュールの改良
ResNetは,residualモジュールを重ねていくだけというシンプルな設計でありながら,高精度な認識を実現できることから,デファクトスタンダードなモデルとなった.これに対し,residualモジュール内の構成要素を最適化することで,性能改善を図る手法が複数提案されている.
初期のResNetの文献37では,下記のようなresidualモジュールの構造が提案されていた.
conv - bn - relu - conv - bn - add - relu
これに対し,文献43では,下記のように,BNおよびReLUを畳み込み層の前に配置することで精度が改善することが示されている.
bn - relu - conv - bn - relu - conv - add
これは,ショートカットの後にReLUによるアクティベーションを行わないことで,勾配がそのまま入力に近い層に伝わっていき,効率的な学習ができるためと考えられる.単純にResNetと参照した場合,こちらの構造を示していることもあるため注意が必要である.明示的に上記の構造のresidualモジュールを利用したResNetであることを示す場合には,pre-activation (pre-act) のResNetと参照されることが多い.
文献44では,pre-actのresidualモジュール内のReLUの数を1つにし,更に最後にBNを加えることが提案されている.
bn - conv - bn - relu - conv - bn - add
Residualモジュール内のReLUの数を1つにすることで精度が改善するということは,文献45でも主張されている.
文献46では,pre-actのresidualモジュールについて,最後の畳み込み層の直前にdropoutを入れることで僅かに精度が向上することが示されている.
bn - relu - conv - bn - relu - dropout - conv - add
上記までの説明では,ResNetのbottleneckバージョンの構造は示していないが,bottleneckバージョンにおいても同様の傾向が確認されている.
WideResNet
文献46では,ResNetに対し,層を深くする代わりに,各residualモジュール内の畳み込みの出力チャネル数を増加させたwideなモデルである,Wide Residual Networks (WideResNet) が提案されている.本論文の主張は,深くthinなモデルよりも,浅くwideなモデルのほうが,最終的な精度および学習速度の点で優れているというものである.例えば,16層のWideResNetが,1000層のResNetと比較して,同等の精度およびパラメータ数で,数倍早く学習できることが示されている.また,WideResNetの中でも比較的深いモデルでは,residualモジュール内の2つのconvolution層の間にdropoutを挿入することで精度が向上することも示されている.
PyramidNet
文献40では,ResNetが複数のネットワークのアンサンブル学習となっており,ランダムにresidualモジュールを削除しても精度がほとんど低下しないことが示されていた.しかしながら,特徴マップのサイズを半分ダウンサンプルするresidualモジュールを削除した場合に限っては,相対的に大きな精度低下が確認されていた.これは,ダウンサンプリングを行うresidualモジュールでは,出力チャネル数を倍増させており,相対的にそのモジュールの重要度が大きくなってしまっているためと考えられる.アンサンブル学習の観点からは,特定のモジュールの重要度が大きくなってしまうことは望ましくなく,これを解決するネットワークとしてPyramidal Residual Networks (PyramidNet) が提案されている44.
PyramidNetでは,ダウンサンプルを行うモジュールのみで出力チャネル数を倍増させるのではなく,全てのresidualモジュールで少しずつ出力チャネル数を増加させる.増加のさせ方として,単調増加させる場合と指数的に増加させる場合を比較し,単調増加させる場合のほうが精度が良いことが示されている.単調増加させる場合,$k$番目のresidualモジュールの出力チャネル数$D_k$は次のように定義される.
D_k = \begin{cases}
16 & \textrm{if} \; k = 1 \\
\lfloor D_{k-1} + \alpha / N \rfloor & \textrm{otherwise}.
\end{cases}
PyramidNetは,bottleneckバージョンのResNetをベースとし,272層という深いネットワークを学習させることで,非常に高精度な認識を実現している.
独自モジュールの利用
ResidualモジュールやInceptionモジュールの成功から,それらに代わる新たなモジュールが多数提案されている.
多くの手法がresidualモジュールをベースとしている.
ResNeXt
ResNeXt47は,ResNet内の処理ブロック$F(x)$において,下式のように入力$x$を多数分岐させ,同一の構造を持つニューラルネットワーク$\mathcal{T}_i (x)$で処理を行った後,それらの和を取るResNeXtモジュールを利用する手法である.
F(x) = \sum_{i = 1}^C \mathcal{T}_i (x).
ここで,分岐数$C$はcardinalityと呼ばれている.このアイディアは,通常のニューラルネットワークの処理$\sum_{i = 1}^D w_i x_i$を,より汎用的な$\mathcal{T}_i (x)$に置き換えたものであることから,Network-in-Neuronと呼ばれる.

上図(a)に,入出力チャネル数が256,$C = 32$とした場合のResNeXtモジュールの構造を示す.ここで$\mathcal{T}_i (x)$は, conv 1x1, 4 - conv 3x3, 4 - conv 1x1, 256 を順に適用する処理として定義されている.(a)の構造は,実は(b)のように書き換えることができる.(b)において2つ目の畳み込みはgrouped convolution(本稿ではgroup化畳み込みと呼ぶ)と呼ばれ,入力特徴マップを$g$分割し,それぞれ独立に畳み込みを行う処理である.
(b)の構造は, conv 1x1 により次元削減を行い, conv 3x3 を行った後, conv 1x1 により次元の復元を行っており,実はbottleneckバージョンのresidualモジュールにおいて,3×3の畳み込みをgroup化畳み込みに変更したものとみなすことができる.Group化畳み込みは,Inceptionモジュールと同様に,チャネル方向の結合が疎なパラメータの少ない畳み込みである.結果的にResNeXtは,ResNetと比較して表現力とパラメータ数のトレードオフが改善され,同等のパラメータ数では精度向上を実現することができている.下記にGroup化畳み込みのパラメータ数の直感的な理解のため,グループ数が2の図を示す.下図の通り,Group化畳み込みは,通常の畳み込みと比較してパラメータ数を1/グループ数にすることができる.

Xception
Xception48は,端的には,通常の畳み込みの代わりに,depthwise separable convolution49(以降separable畳み込み)を用いたResNetである.
Separable畳み込み
通常の畳み込みが,入力特徴マップの空間方向とチャネル方向に対し同時に畳み込みを行うのに対し,separable畳み込みは,空間方向とチャネル方向に独立に畳み込みを行う.これは,畳み込みがこれらの方向にある程度分離することができるという仮説に基づいている.空間方向の畳込みはdepthwise畳み込み,チャネル方向の畳み込みはpointwise畳み込みと呼ばれる.下記に,separable畳み込みの各処理を示す.

Depthwise畳み込みは,特徴マップのチャネル毎にそれぞれ独立して空間方向の畳込みを行う処理である.Pointwise畳み込みは,本稿でも何度も登場した,1×1の畳み込みのことを指す.入力特徴マップのサイズが$H$×$W$×$N$,出力チャネル数が$M$の場合,通常の$K$×$K$畳み込みの計算量は$\mathcal{O} (H W N K^2 M)$となる.他方,depthwise畳み込みの計算量は$\mathcal{O} (H W N K^2)$,pointwise畳み込みの計算量は$\mathcal{O} (H W N M)$となる.すなわち,通常の畳み込みをseparable畳み込み(depthwise畳み込み + pointwise畳み込み)に置き換えることで,計算量が$\mathcal{O} (H W N K^2 M)$から$\mathcal{O} (H W N K^2 + H W N M)$に削減される.比率では,$1/K^2 + 1/M$になっており,通常$M >> K^2$である (e.g. $K=3$, $M=64$) ことから,計算量が$1 / K^2$程度に削減される.
Xceptionモジュール
Xceptionで用いられるモジュールは下記のようなものである.
relu - sep - bn - relu - sep - bn - relu - sep - bn - add
ここで sep はseparable畳み込みを表す.
全体の設計としては,ネットワークの入出力に近い箇所以外は上記のXceptionモジュールを用い,$s = 2$, $z = 3$のmax poolingにより特徴マップを縮小しつつ,そのタイミングでチャネル数を増加させる方針を取っている.
Xceptionは,上記のように通常の畳み込みよりも計算量およびパラメータ数の小さいseparable畳み込みを用いることで,その分モデルの深さや幅を大きくすることができ,結果的にResNetやInception-v3よりも高精度な認識を実現している.
参考のため,下記に通常の畳み込み,depthwise畳み込み,pointwise畳み込みそれぞれのパラメータ数のイメージを示す.

独自マクロアーキテクチャの利用
Residualモジュールの改良や,独自モジュールの利用では,特定のモジュールを順番に積み重ねるというマクロなアーキテクチャは同じであった.一方,そのマクロなアーキテクチャについても独自の提案している文献も存在する.
RoR
Residual Networks of Residual Networks (RoR)50は,複数のresidualモジュール間に更にショートカットを追加することで,ResNetを更に最適化しやすくするモデルである.ショートカットは,階層的に構築することが提案されており,実験的に3階層までのショートカットが効果的であったことが示されている(1階層は通常のResNet).RoRは,ベースネットワークとして,ResNet,pre-actのResNet,WideResNetを比較しており,WideResNetをベースとし,後述するStochastic DepthとRoRを組み合わせた場合に最も良い認識精度が得られている.なお,Stochastic Depthを導入しない場合は逆に精度が低下することが確認されている.
FractalNet
FractalNet51は,下記のように再帰的に定義されるfractalブロックを利用することで,ResNetのようなショートカットを利用することなく深いネットワークを学習することができるモデルである.
\begin{eqnarray*}
f_1 (x) &=& \mathrm{conv}(x), \\
f_{C+1} (x) &=& (f_C \circ f_C)(x) \oplus \mathrm{conv}(x).
\end{eqnarray*}
ここで$\oplus$は複数のパスを統合する処理であり,文献51では,要素ごとの平均値を取るオペレーションとして定義される.上記の処理ブロックを,間に$s = 2$, $z = 2$のmax poolingをはさみながら重ねていくことで,FractalNetが構成される.ブロック数が$B$のFractalNetの層数は$B \cdot 2^{C-1}$となる.FractalNetの学習で特徴的であるのは,出力層まで存在する多数のパスをdropoutのように確率的にdropすることを行う点である.Dropの種類として,localとglobalの2種類のdrop方法を提案している.
- Local: パスを統合する層で入力パスをランダムにdropさせる.但し,最低1つのパスを残す.
- Global: 出力層へ至る同一の列により定義されるパスを1つだけ利用する.
上記のパスをdropする処理により,ネットワークの正則化が行われ,ResNetよりも高精度な認識を実現している.但し,WideResNetやDenseNetに対しては,精度面で劣っている.
DenseNet
Dense Convolutional Network (DenseNet)52は,ネットワークの各レイヤが密に結合している構造を持つことが特徴のモデルで,Denseブロックをtransition layerでつないだアーキテクチャとなっている.
 文献[^Huang_cvpr17]の図を一部利用
文献[^Huang_cvpr17]の図を一部利用
Denseブロック
ResNetでは,$l $番目のresidualモジュールの出力は,内部の処理ブロックの出力$F_l (x_{l - 1})$とショートカット$x_{l - 1}$の和としていた.
x_l = F_l (x_{l - 1}) + x_{l - 1}.
これに対し,DenseNetでは,その内部では,あるレイヤより前のレイヤの出力全てを連結した特徴マップをそのレイヤの入力にする,Denseブロックを利用する.Denseブロック内における$l$番目のレイヤの出力は下式で定義される.
x_l = F_l ([x_0, x_1, \cdots, x_{l - 1}]).
ここで,Denseブロックへの入力のチャネル数を$k_0$,各レイヤの出力$F_l (\cdot)$のチャネル数を$k$とすると,$l$番目のレイヤの入力チャネル数は$k_0 + k (l - 1)$となる.このように,入力チャネル数が$k$ずつ増加するため,$k$はネットワークの成長率パラメータと呼ばれる.なお,各レイヤの処理$F_l$は, bn - relu - conv 3x3 により構成される.下記にレイヤ数が4のDenseブロックの例を示す.
 文献[^Huang_cvpr17]の図を一部利用
文献[^Huang_cvpr17]の図を一部利用
Bottleneckバージョン
DenseNetでは,各レイヤの出力チャネル数$k$は小さい値となっているが,入力チャネル数が非常に大きくなるため,計算量を削減するためにResNetで利用されている入力チャネル数を圧縮するbottleneck構造を利用する.具体的には,各レイヤの処理$F_l$を下記により定義する.
bn - relu - conv 1x1 - bn - relu - conv 3x3
論文中では, conv 1x1 の出力チャネル数は$4 k$と設定されている.
Transitionレイヤ
DenseNetは,上記のDenseブロックを複数積み重ねることで構築され,各Denseブロックはtransitionレイヤにより接続される.Transitionレイヤは, bn - conv 1x1 - avepool 2x2 により構成される.このtransitionレイヤは,通常入力チャネル数と出力チャネル数は同一とされるが,$\theta \in (0, 1]$により定義される圧縮率だけ出力チャネル数を削減することも提案されており,$\theta = 0.5$が用いられる.評価実験では,bottleneckを利用し,かつtransitionレイヤでの圧縮を行い,$k$および層数を大きくしたバージョンが高精度な認識を実現している.
文献53では,DenseNetを複数スケールの特徴マップを持つように拡張し,更にネットワークの途中で結果を出力することで,サンプルの難易度によって処理時間を可変とするMulti-Scale DenseNet (MSDNet) が提案されている.
正則化
DNNにおいては,いかに過学習を回避し,汎化されたモデルを学習するかが重要であり,モデルに対してはdropoutやweight decay等が,学習データおよびテストデータに対しては,ランダムクロッピングや左右反転等のデータ拡張が正則化のために用いられてきた.近年,このような正則化に関してもシンプルでありながら有効な手法が提案されている.
Stochastic Depth
Stochastic Depth54は,ResNetにおいて,訓練時にresidualモジュールをランダムにdropするという機構を持つモデルである.

上記に,Stochastic Depthにおける$l$番目のresidualモジュールの構造を示す.ここで,$b_l$は確率$p_l$で1を,確率$1 - p_l$で0を取るベルヌーイ変数である.$p_l$は,$l$番目のresidualモジュールがdropされずに生き残る確率(生存確率)であり,ネットワークの出力層に近いほど小さな値を取るように設計され,$p_l = 1 - \frac{l}{2L}$と定義される($L$はresidualモジュール数).これにより,訓練時の「期待値で見たときの深さ」が浅くなり,学習に必要な時間が短縮されるとともに,dropoutのような正則化の効果が実現される.なお,テスト時には,それぞれのresidualモジュールについて生存確率の期待値$p_l$を出力にかけることでスケールのキャリブレーションを行う.
Swapout
Swapout55は,ResNetに対してdropoutの拡張を行う正則化手法である.ResNetのresidualモジュールでは,入力を$x$,residualモジュール内での処理の出力を$F(x)$とすると,$H(x) = F(x)+x$を次の層に出力する.これに対し,Swapoutでは,入力のショートカット$x$および$F(x)$に対し,個別にdropoutを適用する.
正確には,$H(x)$が下記のように定義される:
H(x) = \Theta_1 \odot x + \Theta_2 \odot F(x).
ここで,$ \Theta_1$および$\Theta_2$は,各要素が独立に生成されるベルヌーイ変数により構成される,出力テンソルと同サイズのテンソルであり,$\odot$はアダマール積である.文献55では,stochastic depthと同様に,drop率を入力層から出力層まで,0から0.5まで線形に増加させる場合に精度が高くなることが示されている.
推論時は,dropoutと異なり,明示的に各層の出力を期待値によりキャリブレーションできないため,テストデータに対しswapoutを有効にしたまま複数回forwardを行い,それらの平均値を推論結果とする形でないと精度がでないことが特徴である.
Shake-Shake Regularization
Shake-Shake56 57はResNetをベースとし,ネットワークの中間の特徴マップに対するdata augmentationを行うことで,強力な正則化を実現する手法である.

上記に,Shake-Shakeで利用される$l$番目のresidualモジュールの構造を示す.Shake-Shakeでは,residualモジュール内の畳み込みを2つに分岐させ,forward時にはそれらの出力を一様乱数$\alpha_l \in [0, 1]$によって混合することを行う.これにより,画像を対象としたdata augmentationにおいてランダムクロッピングを行うことで,その画像内に含まれている物体の割合が変動してもロバストな認識ができるように学習ができるように,Shake-Shakeでは特徴レベルにおいても各特徴の割合が変動してもロバストな認識ができるようにしていると解釈することができる.
特徴的なのは,backward時には,forward時の乱数$\alpha_l$とは異なる一様乱数$\beta_l \in [0, 1]$を利用する点である.これは,勾配にノイズを加えると精度が向上する[^Neelakantan_iclrw16]ように,forward時とは異なる乱数を利用することで,更に強い正則化の効果をもたらしていると考えられる.推論時には,乱数の期待値である0.5を固定で利用する.
上記の$\alpha_l$と$\beta_l$については,複数のパターンの組み合わせを網羅的に検証した結果,どちらも独立した乱数とする形が良いと結論付けている.また,バッチ単位で上記の乱数を同一のものを利用するか,画像単位で独立に決定するかについても,画像単位で独立に決定するほうが良いと実験的に示されている.このように,forward/backward時の外乱により,強い正則化の効果がもたらされ,非常に高精度な認識を実現している.
Shake-Shakeの学習で特徴的な点として,学習率の減衰をcosine関数で制御し,通常300エポックかけて学習を行うところを,1800エポックかけて学習することが挙げられる.これはShake-Shakeの効果により,擬似的に学習データが非常に大量にあるような状態となっているため,長時間の学習が有効であるためと考えられる.
ShakeDrop
ShakeDrop58は,Stochastic Depthにおいて,層をdropする代わりに,forward/backward時にShake-Shakeのような外乱を加える手法である.

上記にShakeDropで利用される$l$番目のresidualモジュールの構造を示す.ここで,$b_l$は,確率$p_l$で1を,$1 - p_l$で0を取るベルヌーイ変数である.Stochastic Depthと同様に$p_l$はネットワークの出力層に近いほど大きな値を取り,$p_l = 1 - \frac{l}{2L}$と定義される($L$はresidualモジュールの数).
$\alpha_l$と$\beta_l$はShake-Shakeと同様に,forward/backward時に出力をスケーリングする乱数である.
テスト時には,forward時のスケーリング$b_l + (1 - b_l)\alpha_l$の期待値を用いて,出力のキャリブレーションを行う.ShakeDropにおいて,$p_l = 1$(常にdropしない)とすれば通常のresidualモジュールと同一になり,$p_l = 0$(常にdropする)とすれば,Shake-Shakeと同じように全ての入力に対し外乱を加えるreisualモジュールとなる.また,$\alpha_l = 0$と$\beta_l = 0$とすれば,Stochastic Depthと同一のモデルとなる.
$\alpha_l$と$\beta_l$が取りうる範囲は,幾つかの候補から最も精度が良い$\alpha_l \in [-1, 1]$と$\beta_l \in [0, 1]$が採用されている.$\alpha_l$と$\beta_l$をどの単位で変化させるかについて,Shake-Shakeではバッチ単位と画像単位の比較が行われていたが,本論文では更にチャネル単位と画素単位でも比較が行われており,チャネル単位での精度が良いことが示されている.
ShakeDropは,Shake-Shakeと比較して,2つに分岐させていた畳み込みを1つにした構造でも同様の正則化を実現している点で優れている.これにより,パラメータ数を削減できるため,相対的にモデルをより深くすることが可能となり,ベースネットワークとしてPyramidNetを利用し,更に後述するrandom erasingと組み合わせることで,本稿執筆時点(2017年12月)では,CIFAR10/100において最も低いエラー率を達成している.
Cutout / Random Erasing
Cutout59およびRandom Erasing60は,モデルの正則化を目的としたdata augmentationの手法である.同じく正則化を目的としたdropoutは全結合層では効果的である一方,畳み込み層に対しては元々パラメータが少ないため効果が限定的であった.また,CNNの入力である画像が対象の場合,隣接画素に相関があり,ランダムにdropしたとしてもその周りのピクセルで補間できてしまうため,正則化の効果が限定的であった.これに対し,Cutout/Random Erasingでは,入力画像のランダムな領域をマスクしてしまうことで,より強い正則化の効果を実現している.
Cutoutでは,マスクの形よりもサイズが重要であるとの主張から,マスクの形状は単純なサイズ固定の正方形を採用し,そのマスク領域を平均画素に置き換える処理を行っている.
Random Erasingでは,各画像に対しマスクを行うかどうか,マスク領域のサイズ,アスペクト比,場所をランダムに決定し,マスク領域の画素値をピクセルレベルでランダムな値に置き換える処理を行っている.単純な手法ながら,画像分類タスクだけではなく,物体検出や人物照合タスクについても有効性が確認されている.下記に,Random Erasingを行った画像例を示す.

mixup
mixup61は,2つの訓練サンプルのペアを混合して新たな訓練サンプルを作成するdata augmentation手法である.具体的には,データとラベルのペア$(X_1, y_1)$, $(X_2, y_2)$から,下記の式により新たな訓練サンプル$(X, y)$を作成する.
\begin{eqnarray*}
X &=& \lambda X_1 + (1 - \lambda) X_2, \\
y &=& \lambda y_1 + (1 - \lambda) y_2.
\end{eqnarray*}
ここで,ラベル$y_1, y_2$はone-hot表現のベクトルであり,$X_1, X_2$は任意のベクトルやテンソルで表現される学習データである.また,$\lambda \in [0, 1]$は,ベータ分布$Be(\alpha, \alpha)$からのサンプリングにより取得し,$\alpha$はハイパーパラメータである.データ$X_1, X_2$だけではなく,ラベル$y_1, y_2$も混合する点が特徴的であり,画像認識においてもその有効性が主張されている.下記に,CIFAR10データセットに対しmixupを行った画像例を示す.

高速化を意識したアーキテクチャ
組み込みデバイスや,スマートフォン等の,計算資源が潤沢ではない環境においては,高速に動作するモデルが重要となる.そのような高速化を意識したアーキテクチャも提案されている.
SqueezeNet
SqueezeNet62は,1×1畳み込みを活用してパラメータと計算量を削減したfireモジュールを積み重ねることで構築される軽量なモデルである.下記にfireモジュールの構造を示す.

Fireモジュールではまず,residualモジュールのbottleneckバージョンや,Inceptionモジュールのように,squeezeレイヤの1×1畳み込みによって入力特徴マップの次元が削減される.その後,expandレイヤの3×3の畳み込みにより特徴抽出を行いつつ次元の復元を行うが,その一部を1×1の畳み込みに置き換える.これはInceptionモジュールと同様に,明示的にsparseな畳み込みを行うことでパラメータ数を削減する効果がある.文献62では,入力チャネル数とsqueezeレイヤの出力チャネル数$s_{1 \times 1}$の比,およびexpandレイヤの1×1畳み込みの出力チャネル数$e_{1 \times 1}$と3×3畳み込みの出力チャネル数$e_{3 \times 3}$の比を調整することで,精度低下を抑えながらパラメータ数を大幅に削減できることが示されている.
MobileNet
MobileNet63は,Xceptionと同様にseparable畳み込みを多用することにより,計算量を削減した軽量なモデルである.具体的には,下記の処理ブロックを,strideが2の畳み込みにより特徴マップを縮小しつつ,チャネル数を2倍に増加させることを行いながら積み重ねることでモデルが構築される.
dw - bn - relu - pw - bn - relu
ここで dw はdepthwise畳み込み, pwはpointwise畳み込みを表している.Xceptionとの大きな違いは,ResNetのようなショートカットを利用しないことと,depthwise畳み込みとpointwise畳み込みの間にbatch normalizationとReLUを利用している点である.特に後者については,文献48ではbatch normalizationとReLUを利用しないほうが精度が高いことが示されており,全体的なモデルアーキテクチャによって局所的なモジュールの最適な構成が異なることが示唆されている.MobileNetでは,チャネル数を制御するパラメータ$\alpha \in (0, 1]$と,入力画像サイズを制御するパラメータ$\rho \in (0, 1]$を導入し,同一のモデルアーキテクチャで,これらのハイパーパラメータにより精度と処理速度のトレードオフを簡単に調整することができる.
モデルアーキテクチャの自動設計
これまで説明してきたモデルは全て人手によりモデルアーキテクチャのデザインが行われてきた.これに対し,自動的にモデルアーキテクチャを設計する試みも存在する64 65 66 67 68.
例えば,文献64 67では,ネットワークを構成するレイヤのパラメータを出力するRecurrent Neural Networks (RNN) を構築し,このRNNをREINFORCEアルゴリズムで学習させることを提案している.文献67では,このRNNを500 GPUにより学習し,前述のXceptionやSENetといった最新のアーキテクチャに対し,同等の精度をより少ないパラメータで達成している.
注目すべきは,文献64では全体構造や個々の構成要素に対し大きな制約はなかったのに対し,文献67では下記のように全体構造および構成要素を限定している.これは,人間の構築したアーキテクチャに対し効率的に性能で上回るためには,まだ人間のノウハウが必要であることを示唆している.
具体的には,文献67では,ImageNetデータセットに対しては,下記のような全体構造を持つアーキテクチャを設計する.ここで,normal cellはresidualモジュールのような特徴抽出を行うモジュールで,reduction cellはダウンサンプリングおよび特徴抽出を行うモジュールである.
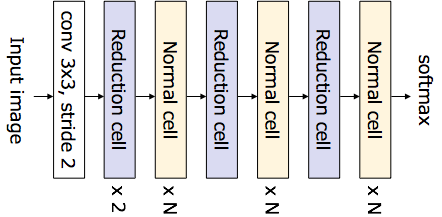
上図から分かる通り,前段でダウンサンプリングを複数回行うことで特徴マップを縮小し,その後特徴抽出を行うモジュールを複数回重ねた後にダウンサンプリングを行うということを更に複数回行う構造になっており,既存のアーキテクチャの設計思想をそのまま具体化しているものと言える.
また,自動設計されるnormal cellおよびreduction cellについても,利用できる構成要素が下記のものに限定されており,conv 3x3 のような一般的な構成要素か,separable畳み込みのようなパラメータ数の少ない構成要素のみを利用することで,探索の効率化を行っていると言える.
- identity
- 1x3 then 3x1 convolution
- 1x7 then 7x1 convolution
- 3x3 dilated convolution
- 3x3 average pooling
- 3x3 max pooling
- 5x5 max pooling
- 7x7 max pooling
- 1x1 convolution
- 3x3 convolution
- 3x3 depthwise-separable conv
- 5x5 depthwise-seperable conv
- 7x7 depthwise-separable conv
下記に,実際に学習によって得られたnormal cellおよびreduction cellの構造を示す.明らかにパラメータ数の少ないseparable畳み込みが優先的に選ばれており,精度とパラメータ数のトレードオフの観点からはseparable畳み込みが優れていることが分かる.一方,separable畳み込みはGPU環境では期待値ほどの処理速度がでないこともあるため,実際の速度も検証してみたい.
 文献[^Zoph_arxiv17]より
文献[^Zoph_arxiv17]より
まとめ
本稿では,ニューラルネットワークの中でも特に発展の著しい畳み込みニューラルネットワーク (CNN) について,画像認識コンペティションILSVRCにて優秀な成績を収めたモデルを概観することで,CNNの変遷を振り返った.また,近年提案されている様々なCNNの改良手法についてサーベイを行い,各手法のアプローチから分類を行い,それぞれ解説を行った.
ResNetが1つの大きなブレークスルーであり,それ以降のモデルはほとんどがResNetの改良と言え,DenseNet以外に独自の全体的なアーキテクチャの成功例はない.Residualモジュールの改良の観点では,ほぼすべての手法が次元削減とsparseな畳み込みを組合せることで,精度とパラメータ数のトレードオフを改善しているアプローチと言える.すなわち,畳み込みのパラメータを削減し,その分深さや幅を大きくすることで精度を向上しているのである.
データおよびモデル内の正則化は,他の手法と組合せられる上に効果が大きく期待できるが,何故改善できているのか不明な点も多く,今後の理論的な説明が期待される.
人間の考案したアーキテクチャを上回る精度を達成するネットワークの自動設計も実現されつつあるが,利用される全体構造や構成要素は引き続き人間が考案したものであり,例えばResNetのショートカットのような構成要素が自動的に発見されるような仕組みはまだ存在しない.
-
D. H. Hubel and T. N. Wiesel. Receptive fields of single neurones in the cat’s striate cortex. The Journal of Physiology, 148(3):574–591, 1959. ↩
-
K. Fukushima and S. Miyake. Neocognitron: A new algorithm for pattern recognition tolerant of deformations and shifts in position. Pattern Recognition, 15(6):455–469, 1982. ↩
-
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998. ↩
-
D. G. Lowe. Distinctive image features from scale-invariant keypoints. IJCV, 60(2):91–110, 2004. ↩
-
J. Sanchez and F. Perronnin. High-dimensional signature compression for large-scale image classification. In Proc. of CVPR, 2011. ↩ ↩2
-
J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In Proc. of CVPR, 2015. ↩
-
L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Semantic image segmentation with deep convolutional nets and fully connected crfs. In Proc. of ICLR, 2015. ↩
-
V. Badrinarayanan, A. Kendall, and R. Cipolla. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. TPAMI, 32(12), 2017. ↩
-
S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proc. of NIPS, 2015. ↩
-
W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg. Ssd: Single shot multibox detector. In Proc. of ECCV, 2016. ↩
-
J. Redmon and A. Farhadi. Yolo9000: Better, faster, stronger. In Proc. of CVPR, 2017. ↩
-
S.-E. Wei, V. Ramakrishna, T. Kanade, and Y. Sheikh. Convolutional pose machines. In Proc. of CVPR, 2016. ↩
-
A. Newell, K. Yang, and J. Deng. Stacked hourglass networks for human pose estimation. In Proc. of ECCV, 2016. ↩
-
Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh. Realtime multiperson 2d pose estimation using part affinity fields. In Proc. of CVPR, 2017. ↩
-
Y. Kim. Convolutional neural networks for sentence classification. In Proc. of EMNLP, 2014. ↩
-
X. Zhang, J. Zhao, and Y. LeCun. Character-level convolutional networks for text classification. In Proc. of NIPS, 2015. ↩
-
M. Auli, D. Grangier, D. Yarats, and Y. N. Dauphin. Convolutional sequence to sequence learning. In Proc. of ICML, 2017. ↩
-
A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu. Wavenet: A generative model for raw audio. arXiv:1609.03499, 2016. ↩
-
A. van den Oord, Y. Li, I. Babuschkin, K. Simonyan, O. Vinyals, K. Kavukcuoglu, , G. van den Driessche, E. Lockhart, L. C. Cobo, F. Stimberg, N. Casagrande, D. Grewe, S. Noury, S. Dieleman, E. Elsen, N. Kalchbrenner, H. Zen, A. Graves, H. King, T. Walters, D. Belov, and D. Hassabis. Parallel wavenet: Fast high-fidelity speech synthesis. https://deepmind.com/documents/131/Distilling_WaveNet.pdf , 2017. ↩
-
D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton, Y. Chen, T. Lillicrap, F. Hui, L. Sifre, G. van den Driessche, T. Graepel, and D. Hassabis. Mastering the game of go without human knowledge. Nature, 550:354–359, 2017. ↩
-
J. Gu, Z. Wang, J. Kuen, L. Ma, A. Shahroudy, B. Shuai, T. Liu, X. Wang, L. Wang, G. Wang, J. Cai, and T. Chen. Recent advances in convolutional neural networks. arXiv:1512.07108v6, 2017. ↩
-
A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Proc. of NIPS, 2012. ↩ ↩2
-
K. Jarrett, K. Kavukcuoglu, M. Ranzato, and Y. LeCun. What is the best multi-stage architecture for object recognition? In Proc. of ICCV, 2009. ↩ ↩2
-
V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In Proc. of ICML, 2010. ↩
-
K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proc. of ICCV, 2015. ↩ ↩2
-
D.-A. Clevert, T. Unterthiner, and S. Hochreiter. Fast and accurate deep network learning by exponential linear units (elus). In Proc. of ICLR, 2016. ↩
-
P. Ramachandran, B. Zoph, and Q. V. Le. Searching for activation functions. arXiv:1710.05941, 2017. ↩
-
S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proc. of ICML, 2015. ↩ ↩2 ↩3
-
N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting. JMLR, 15:1929–1958, 2014. ↩
-
M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional networks. In Proc. of ECCV, 2014. ↩ ↩2 ↩3 ↩4
-
C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In Proc. of CVPR, 2015. ↩
-
M. Lin, Q. Chen, and S. Yan. Network in network. In Proc. of ICLR, 2014. ↩ ↩2 ↩3 ↩4
-
C. Szegedy, V. Vanhoucke, S. Ioffe, and J. Shlens. Rethinking the inception architecture for computer vision. In Proc. of CVPR, 2016. ↩
-
C. Szegedy, S. Ioffe, V. Vanhoucke, and A. A. Alemi. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proc. of AAAI, 2017. ↩
-
K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In Proc. of ICLR, 2015. ↩ ↩2 ↩3 ↩4
-
X. Glorot and Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. In Proc. of AISTATS, 2010. ↩ ↩2
-
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proc. of CVPR, 2016. ↩ ↩2 ↩3
-
R. K. Srivastava, K. Greff, and J. Schmidhuber. Highway networks. In Proc. of ICML Workshop, 2015. ↩
-
R. K. Srivastava, K. Greff, and J. Schmidhuber. Training very deep networks. In Proc. of NIPS, 2015. ↩
-
A. Veit, M. Wilber, and S. Belongie. Residual networks behave like ensembles of relatively shallow networks. In Proc. of NIPS, 2016. ↩ ↩2
-
J. Hu, L. Shen, and G. Sun. Squeeze-and-excitation networks. arXiv:1709.01507, 2017. ↩ ↩2
-
F. Wang, M. Jiang, C. Qian, S. Yang, C. Li, H. Zhang, X. Wang, and X. Tang. Residual attention network for image classification. In Proc. of CVPR, 2017. ↩
-
K. He, X. Zhang, S. Ren, and J. Sun. Identity mappings in deep residual networks. In Proc. of ECCV, 2016. ↩
-
D. Han, J. Kim, and J. Kim. Deep pyramidal residual networks. In Proc. of CVPR, 2017. ↩ ↩2
-
X. Dong, G. Kang, K. Zhan, and Y. Yang. Eraserelu: A simple way to ease the training of deep convolution neural networks. arXiv:1709.07634, 2017. ↩
-
S. Zagoruyko and N. Komodakis. Wide residual networks. In Proc. of BMVC, 2016. ↩ ↩2
-
S. Xie, R. Girshick, P. Dollár, Z. Tu, and K. He. Aggregated residual transformations for deep neural networks. In Proc. of CVPR, 2017. ↩
-
F. Chollet. Xception: Deep learning with depthwise separable convolutions. In Proc. of CVPR, 2017. ↩ ↩2
-
L. Sifre and S. Mallat. Rigid-motion scattering for texture classification. arXiv:1403.1687, 2014. ↩
-
K. Zhang, M. Sun, T. X. Han, X. Yuan, L. Guo, and T. Liu. Residual networks of residual networks: Multilevel residual networks. TCSVT, 2017. ↩
-
G. Larsson, M. Maire, and G. Shakhnarovich. Fractalnet: Ultra-deep neural networks without residuals. In Proc. of ICLR, 2017. ↩ ↩2
-
G. Huang, Z. Liu, K. Q. Weinberger, and L. Maaten. Densely connected convolutional networks. In Proc. of CVPR, 2017. ↩
-
G. Huang, D. Chen, T. Li, F. Wu, L. Maaten, and K. Q. Weinberger. Multi-scale dense networks for resource efficient image classification. arXiv:1703.09844, 2017. ↩
-
G. Huang, Y. Sun, Z. Liu, D. Sedra, and K. Weinberger. Deep networks with stochastic depth. In Proc. of ECCV, 2016. ↩
-
S. Singh, D. Hoiem, and D. Forsyth. Swapout: Learning an ensemble of deep architectures. In Proc. of NIPS, 2016. ↩ ↩2
-
Gastaldi. Shake-shake regularization of 3-branch residual networks. In Proc. of ICLR Workshop, 2017. ↩
-
X. Gastaldi. Shake-shake regularization. arXiv:1705.07485v2, 2017. ↩
-
Anonymous. Shakedrop regularization. ICLR Under Review, 2018. ↩
-
T. DeVries and G. W. Taylor. Improved regularization of convolutional neural networks with cutout. arXiv:1708.04552, 2017. ↩
-
Z. Zhong, L. Zheng, G. Kang, S. Li, and Y. Yang. Random erasing data augmentation. arXiv:1708.04896, 2017. ↩
-
H. Zhang, M. Cisse, Y. N. Dauphin, and D. LopezPaz. mixup: Beyond empirical risk minimization. arXiv:1710.09412, 2017. ↩
-
F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, and K. Keutzer. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and <0.5mb model size. arXiv:1602.07360, 2016. ↩ ↩2
-
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv:1704.04861, 2017. ↩
-
P. Ramachandran, B. Zoph, and Q. V. Le. Searching for activation functions. arXiv:1710.05941, 2017. ↩ ↩2 ↩3
-
H. Liu, K. Simonyan, O. Vinyals, C. Fernando, and K. Kavukcuoglu. Hierarchical representations for efficient architecture search. arXiv:1711.00436, 2017. ↩
-
C. Liu, B. Zoph, J. Shlens, W. Hua, L. Li, L. Fei-Fei, A. Yuille, J. Huang, and K. Murphy. Progressive Neural Architecture Search. arXiv:1712.00559, 2017. ↩
-
B. Zoph and Q. V. Le. Neural architecture search with reinforcement learning. arXiv:1611.01578, 2016. ↩ ↩2 ↩3 ↩4 ↩5
-
E. Real, S. Moore, A. Selle, S. Saxena, Y. Suematsu, J. Tan, Q. Le, and A. Kurakin. Large-Scale Evolution of Image Classifiers. In Proc. of ICLR, 2017. ↩