はじめに
自分自身よく利用することがあるoptunaですが、内部でなにが起きているのか実際に自分でコードを書いて理解してみたのでそれをまとめようと思います。
特に今回は、全体図を掴むことを目的としているので、optuna自体のコードまでは触れられていません。次回に持ち越したいと思います。
そのまま動かすことができるコードもあります。それも触ってみてください。optunaとの比較もでき、完全に一致していることが確認できると思います。
なおバージョンはv2.9.1を参考にしています。
optunaとは
Preferred Networks社が提供しているハイパーパラメータ最適化ライブラリでTPEというアルゴリズムを採用したものです。
TPEの上位概念はベイズ最適化で、同じような概念ではGP-EIがあります。TPEもGP-EIもベイズ最適化の一種となります。
A hyperparameter optimization framework
参考
ハイパーパラメーター最適化フレームワークOptunaの実装解説
Optuna(TPE)のアルゴリズム理解
機械学習におけるハイパーパラメータ最適化の理論と実践
最適化の概要
optunaがTPEという仕組みでハイパーパラメータを最適化していることはわかったと思うのですが、実際にそれがどのような機構なのか説明しようと思います。
まず、全体図から確認していきます。これはハイパーパラメータの最適化全般に言えることだと思います。(手書きですみません)
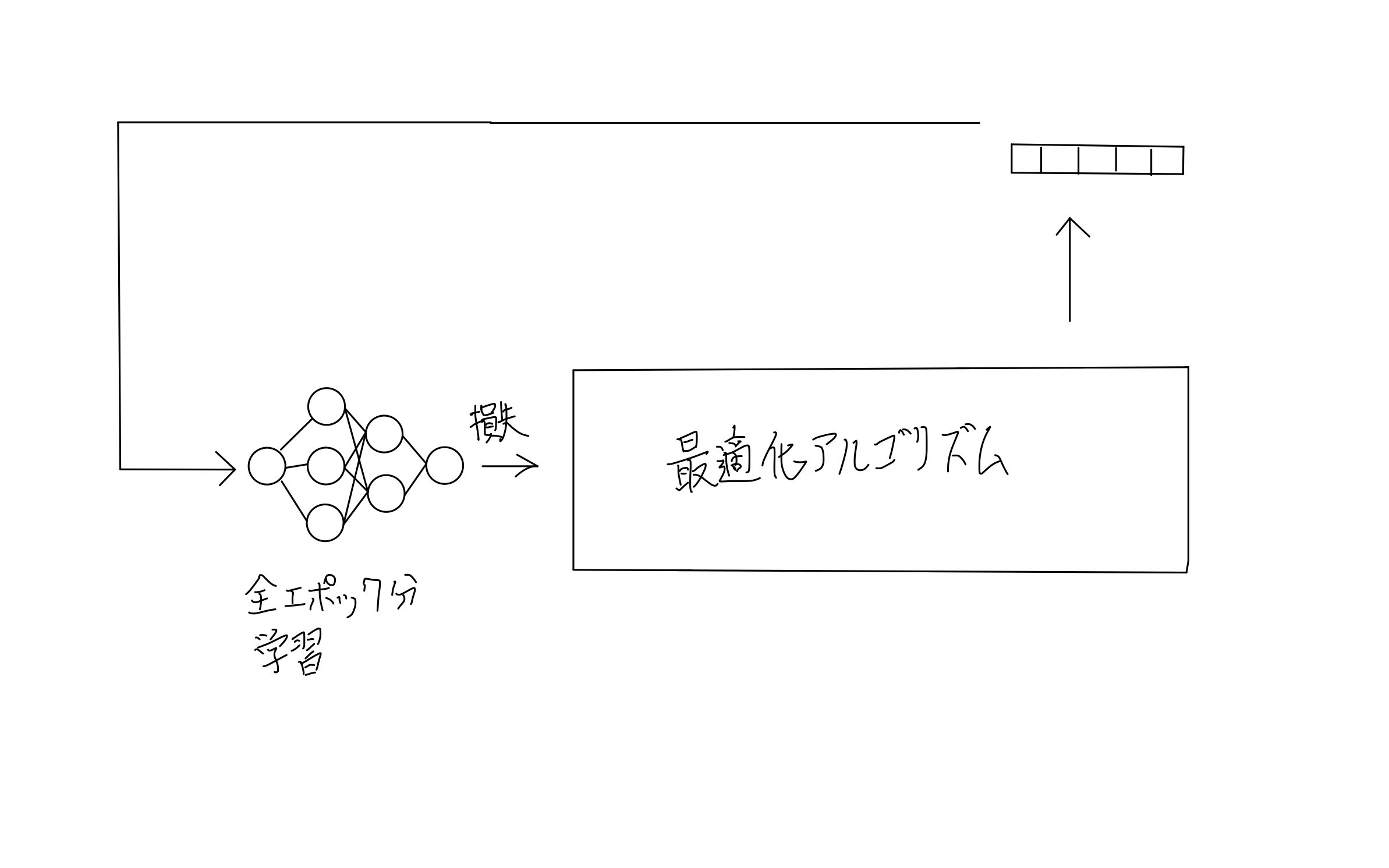
まず、図の左下にあるように通常通りモデルを学習し切ります(全エポック分)。すると、損失(Loss)が出力できると思います。
その後、なにかしらの最適化アルゴリズムを介して、次に学習するときはどんなハイパーパラメータにすれば良いか出力します。その値を再びモデルの学習に利用し、また損失が出力されます。この循環を繰り返していきます。
ベイズ最適化の概要
ハイパーパラメータの最適化の全体像がわかったところで、今度はTPEやGP-EIが属するベイズ最適化の枠組みについて考えてみます。
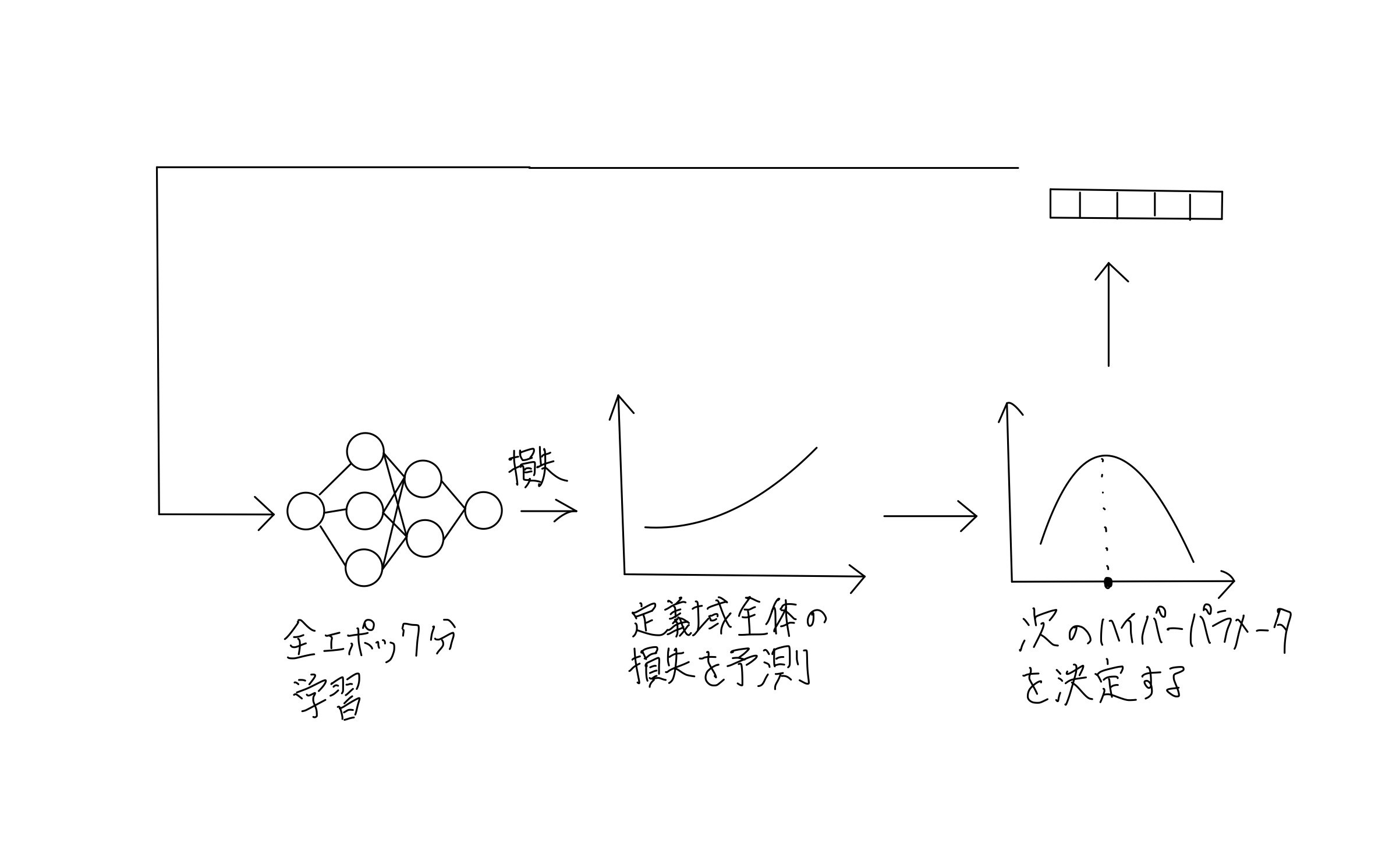
まず、与えられた数個の損失からハイパーパラメータの定義域全体にわたる損失を予測します。これは実際の損失を表す関数を代理するようなもので、代理関数と呼ばれます。
その関数を使って、今度は次のハイパーパラメータをどこにするか決定できる関数を作成します。これは獲得関数と呼ばれます。
この代理関数と獲得関数の作り方の違いによってGP-EIとTPE(optuna)は大別できると思います。
ベイズ最適化の概要(補足)
これは補足なので読み飛ばしても大丈夫です。
そもそもなぜハイパーパラメータの最適化が難しいのかというと、ほとんどの場合、図の左下のモデルの学習に多大な時間がかかってしまうからです。
もし時間がかからない場合は、細かな粒度のグリッドサーチやランダムサーチで全通りに近い回数を試して最適なものを選択すれば良いことになります。
時間が無限であればこのようなアルゴリズムは必要ないですが、限られた時間で、限られた個数の損失しか得られない状況で最善を尽くすためになんとかしようとしているところが僕は面白いと思いました。
最後に
またこの続きを書いていこうと思います。