こんにちは。noteでSREを担当していますfukudaです。
今年、ログ収集の仕組みをDataDogからGrafana Lokiに移行しました。
この記事では、移行の理由、メリットとデメリット、気づきや運用のコツをお話しします。サービスの規模や運用ポリシーによって最適解は異なりますが、少しでも参考になれば幸いです。
お話しする内容を5行でまとめると
- DataDogからGrafana Lokiに移行し、すべてのログを低コストで収集・参照可能に
- Ingress NGINX以外の主要アプリケーションの全ログも検索可能になり、対応が迅速化
- S3を活用した過去のログ参照が容易になり、手動ダウンロードが不要に
- HPAを活用してオートスケールを行うことで、効率的なリソース利用と安定運用を両立
- 長期間のログ検索や集計などに課題もある
前提
まず今回Lokiを導入した弊社の環境を簡単にご紹介します。
- AWSのEKS でKubernetesクラスタを運用
- Karpenter でノードの管理を自動化
- Prometheus でメトリクスを収集
- Amazon Managed Grafana でダッシュボードを構築
課題
まず、Loki導入前に抱えていた課題をお話ししたいと思います。
- コスト面の理由からDataDogに送っていたのはIngressNGINXのログの数%のみで、保存期間も1週間だった
- サービスの規模の拡大に伴いログ量も増加傾向だったため、サンプルレートを段階的に切り下げて対処していた
- 数%のログだと開発者からの要望に応えられないことが多くあった
- 稀にアクセスが特に多かった日は、1日のバジェットを使い果たしてログが全く取得できていない時間が発生した(1日1回バジェットがリセットされるタイミングで復活)
- IngressNGINX以外のログが必要な場合は、S3からダウンロードしてローカル環境で参照するしかなかった
問い合わせが来るたびに「すいません、数%のサンプルなんですよ」とお答えするのはSRE-Tとしてはなんとも歯がゆいものでした。
Lokiを選んだ理由
前職ではElasticsearchを使って全ログを保存していたため、最初はElasticsearchの導入も検討しました。しかし、noteのサービス規模を考えると運用コストが高くなることが懸念されました。そこで、代替案を調査した結果、Grafana Lokiが最適だと判断しました。
Lokiを選んだ理由は以下の通りです
- OSSで自前運用が可能
- helmを使って低工数でEKSクラスタ内に導入が可能
- 柔軟にスケールイン・スケールアウトが可能
- S3をバックエンドストレージとして活用可能
- Grafana上でTempo、Prometheusと統合してメトリクス、ログ、トレースを一元管理できそう
- Elasticsearchよりも運用コストが安そう
- クエリが比較的わかりやすい
- 公式ドキュメントが充実している
実際の設定
helmfileコマンドを使ってhelm chartで導入しています。
実際の定義ファイルは以下の通りです。
helmfile.yamlの記述はこちら。
repositories:
- name: grafana
url: https://grafana.github.io/helm-charts
releases:
- name: loki
namespace: logging
version: 6.18.0
chart: grafana/loki
values:
- values.yaml
values.yamlの設定に際し、以下のようなことを意図しています。
- 今後のログ増加とそれに合わせた柔軟なスケーリングを行うため、分散構成を採用
- ログの保持期間は社内規定に基づいて3年
- かなり古いログを検索することは稀なのでS3のストレージクラスを
INTELLIGENT_TIERINGに指定 - イメージは基本的にpull through cache経由でpull
- ノードはKarpenter管理のNodePoolを指定
- HPAが設定できるものは全て設定
- 参照時に極力S3へのアクセスは発生しないようにするため、memcacheに大きめのEBSボリュームを追加してextstoreとして使用し、メモリから溢れてもディスクに落ちるようにしている(参考)
- ログの欠損検知は導入のスコープからは一旦外したのでcanaryのpushは無効化
実際のファイルは以下のようになっています
(お見せできない情報は端折ったり伏せてあります)
global:
image:
registry: "AWS_ID.dkr.ecr.ap-northeast-1.amazonaws.com/dockerhub"
deploymentMode: Distributed
serviceAccount:
annotations:
"eks.amazonaws.com/role-arn": "ROLE_ARN"
loki:
commonConfig:
replication_factor: 1
storage:
type: 's3'
s3:
region: ap-northeast-1
bucketNames:
chunks: BUCKET_NAME
ruler: BUCKET_NAME
admin: BUCKET_NAME
storage_config:
aws:
bucketnames: BUCKET_NAME
storage_class: INTELLIGENT_TIERING
limits_config:
retention_period: 1095d # 3 years
max_streams_per_user: 10000000
max_global_streams_per_user: 10000000
ingestion_burst_size_mb: 50
ingestion_rate_mb: 100
max_query_length: 7d
max_query_series: 10000
max_entries_limit_per_query: 10000
allow_structured_metadata: true
query_timeout: 900s
otlp_config:
resource_attributes:
attributes_config:
- action: index_label
attributes:
- service.group
schemaConfig:
configs:
- from: "2024-10-01"
store: tsdb
index:
prefix: loki_index_
period: 24h
object_store: s3
schema: v13
gateway:
autoscaling:
enabled: true
minReplicas: 4
maxReplicas: 20
targetCPUUtilizationPercentage: 80
targetMemoryUtilizationPercentage: 80
resources:
limits:
memory: "128Mi"
cpu: "100m"
requests:
memory: "50Mi"
cpu: "50m"
nodeSelector:
karpenter-role: loki
maxUnavailable: 1
nginxConfig:
enableIPv6: false
logFormat: |-
main escape=json
'{'
'"time_local":"$time_local",'
'"remote_addr":"$remote_addr",'
'"remote_user":"$remote_user",'
'"request":"$request",'
'"status":"$status",'
'"body_bytes_sent":"$body_bytes_sent",'
'"http_referer":"$http_referer",'
'"http_user_agent":"$http_user_agent",'
'"request_time":"$request_time",'
'"request_length":"$request_length"'
'}';
lokiCanary:
push: false
resources:
limits:
memory: "100Mi"
cpu: "100m"
requests:
memory: "50Mi"
cpu: "50m"
compactor:
replicas: 1
nodeSelector:
karpenter-role: loki
maxUnavailable: 1
resources:
limits:
memory: "2000Mi"
cpu: "600m"
requests:
memory: "1000Mi"
cpu: "200m"
distributor:
nodeSelector:
karpenter-role: loki
maxUnavailable: 1
autoscaling:
enabled: true
minReplicas: 4
maxReplicas: 40
targetCPUUtilizationPercentage: 80
targetMemoryUtilizationPercentage: 80
resources:
limits:
memory: "300Mi"
cpu: "400m"
requests:
memory: "150Mi"
cpu: "150m"
indexGateway:
replicas: 4
nodeSelector:
karpenter-role: loki
maxUnavailable: 1
resources:
limits:
memory: "2500Mi"
cpu: "2500m"
requests:
memory: "2000Mi"
cpu: "2000m"
ingester:
nodeSelector:
karpenter-role: loki
autoscaling:
enabled: true
minReplicas: 4
maxReplicas: 40
targetCPUUtilizationPercentage: 80
targetMemoryUtilizationPercentage: 80
behavior:
enabled: true
scaleDown:
policies:
- periodSeconds: 300
type: Pods
value: 1
selectPolicy: Max
stabilizationWindowSeconds: 600
scaleUp:
policies:
- periodSeconds: 5
type: Pods
value: 2
selectPolicy: Max
stabilizationWindowSeconds: 60
resources:
limits:
memory: "3000Mi"
cpu: "3000m"
requests:
memory: "2500Mi"
cpu: "2000m"
querier:
nodeSelector:
karpenter-role: loki
maxUnavailable: 1
autoscaling:
enabled: true
minReplicas: 2
maxReplicas: 40
targetCPUUtilizationPercentage: 30
targetMemoryUtilizationPercentage: 30
behavior:
enabled: true
scaleDown:
policies:
- periodSeconds: 300
type: Pods
value: 2
selectPolicy: Max
stabilizationWindowSeconds: 600
scaleUp:
policies:
- periodSeconds: 5
type: Pods
value: 5
selectPolicy: Max
stabilizationWindowSeconds: 60
resources:
limits:
memory: "2000Mi"
cpu: "3000m"
requests:
memory: "1500Mi"
cpu: "2500m"
queryFrontend:
nodeSelector:
karpenter-role: loki
maxUnavailable: 1
autoscaling:
enabled: true
minReplicas: 2
maxReplicas: 10
targetCPUUtilizationPercentage: 80
targetMemoryUtilizationPercentage: 80
resources:
limits:
memory: "1000Mi"
cpu: "300m"
requests:
memory: "500Mi"
cpu: "100m"
queryScheduler:
replicas: 2
nodeSelector:
karpenter-role: loki
resources:
limits:
memory: "300Mi"
cpu: "300m"
requests:
memory: "150Mi"
cpu: "50m"
ruler:
replicas: 1
nodeSelector:
karpenter-role: loki
maxUnavailable: 1
resources:
limits:
memory: "400Mi"
cpu: "200m"
requests:
memory: "200Mi"
cpu: "100m"
chunksCache:
enabled: true
replicas: 3
nodeSelector:
karpenter-role: loki
maxUnavailable: 1
resources:
limits:
memory: "3500Mi"
cpu: "300m"
requests:
memory: "3Gi"
cpu: "100m"
allocatedMemory: 2800
persistence:
enabled: true
storageSize: 1000G
storageClass: gp3
mountPath: /data
resultsCache:
replicas: 2
nodeSelector:
karpenter-role: loki
maxUnavailable: 1
resources:
limits:
memory: "250Mi"
cpu: "200m"
requests:
memory: "128Mi"
cpu: "100m"
memcached:
image:
repository: AWS_ID.dkr.ecr.ap-northeast-1.amazonaws.com/dockerhub/library/memcached
memcachedExporter:
image:
repository: AWS_ID.dkr.ecr.ap-northeast-1.amazonaws.com/dockerhub/prom/memcached-exporter
bloomCompactor:
replicas: 0
bloomGateway:
replicas: 0
## === for SimpleScalable deployment ===
read:
replicas: 0
backend:
replicas: 0
write:
replicas: 0
singleBinary:
replicas: 0
リソース量の調整
分散構成だと難儀するのがリソース割当ての調整です。
まず、分散構成で導入した場合にインストールされるコンポーネントは以下の通りです。
- Deployment
- loki-distributor
- loki-gateway
- loki-querier
- loki-query-frontend
- loki-query-scheduler
- StatefulSet
- loki-chunks-cache
- loki-compactor
- loki-index-gateway
- loki-ingester
- loki-results-cache
- loki-ruler
当然ながら最初はどのコンポーネントが何をしているのか分からないので、まず公式ドキュメントで確認しました。
https://grafana.com/docs/loki/latest/get-started/architecture/#loki-architecture
前提知識としては理解したとしても、実際にどの程度のリソース設定が適切なのかを事前に把握することは難しかったので、徐々に送信するログの量を増やしながら、勘所を掴みつつ何度も調整を繰り返していきました。
この試行錯誤の過程で、下記のような知見を積み重ね、最終的に現在運用している設定が前述のマニフェストの内容になります。
- ログ量が増えた時に連動して増えるのはdistributor
- Gatewayはリクエストを各コンポーネントに振り分けてるだけだから負荷は大したことない
- Grafanaから重いクエリを投げるとquerierがガツンと上がるのでスケールアウトの初速は早めが良い
弊社の環境では一旦この設定で各コンポーネントを稼働させ、負荷に応じてHPAが自動的にスケールイン・アウトをすることで、効率的なリソース利用と安定運用を両立できています。
サービスによって出力されるログの特性が異なりますし、結局のところは徐々にLokiに流す流量を増やしつつ、メトリクスを分析していい塩梅を探っていく形にはなると思いますが、スタート地点での設定として弊社の設定が参考になれば幸いです。
ログの送信方法
次に、構築したLokiに対し、どのようにログを送っているのかをお話しします。
従来はDataDog AgentとFluentbitがDaemonSetとして設定されており、DataDog AgentがIngressNGINXのログのみをDataDogへ送信、Fluentbitが全てのログをS3に送っていました。
FluentbitやFluentdでもLokiにログを送ることは出来ると思いますが、GrafanaLabsが用意しているpromtailがシンプルで良さそうだったので、今回のLoki導入を機にDataDog AgentとFluentbitは廃止し、promtailに一本化しました。
promtailもLokiと同様にhelmfileコマンドを使ってhelm chartで導入しています。
実際の定義ファイルは以下の通りです。
helmfile.yamlはLoki同様にこの記述だけです。
repositories:
- name: grafana
url: https://grafana.github.io/helm-charts
releases:
- name: promtail
namespace: logging
version: 6.16.0
chart: grafana/promtail
values:
- values.yaml
values.yamlの設定に際し、以下のようなことを意図しています。
- イメージはpull through cache経由でpull
- Grafanaから参照する際に、どこから来たのか分からなくなってしまうので、
hostnameというラベルにコンテナ名、aws_regionというラベルにリージョン名をそれぞれ環境変数から付与 - デフォルトで全てのPodのログを送信しますが、ノードのシステムログは送信しないので、明示的にノードの/var/logディレクトリを/var/log/nodeというディレクトリにマウントし、そのディレクトリをscrapeするように
extraScrapeConfigsを追記 - 全てのノードで一気に有効化すると、膨大なログが一気にLokiに送られて、スケールアウトが間に合わず問題が起きる可能性が考えられたので、
nodeAffinityを用いてKarpenterのnodepool単位で制御
実際のファイルは以下のようになっています
(お見せできない情報は端折ったり伏せてあります)
global:
imageRegistry: "AWS_ID.dkr.ecr.ap-northeast-1.amazonaws.com/dockerhub"
resources:
requests:
cpu: 200m
memory: 256Mi
serviceAccount:
annotations:
"eks.amazonaws.com/role-arn": "ROLE_ARN"
extraArgs:
- -client.external-labels=hostname=$(HOSTNAME),aws_region=$(AWS_REGION)
- -config.expand-env=true
config:
logFormat: json
enableTracing: true
clients:
- url: http://loki-gateway/loki/api/v1/push
tenant_id: default
snippets:
extraScrapeConfigs: |
- job_name: kubernetes-nodes
static_configs:
- targets:
- localhost
labels:
job: node
__path__: /var/log/node/*
extraVolumes:
- name: node
hostPath:
path: /var/log
extraVolumeMounts:
- name: node
mountPath: /var/log/node
readOnly: true
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: karpenter.sh/nodepool
operator: In
values:
- api
- batch
Grafanaからの参照
ログを送っただけでは意味がないので、DataDogのGUIと同様に様々な条件でフィルタしながら参照するためのダッシュボードをGrafanaに作成しました。
IngressNGINXのログを参照するためのダッシュボード用に錬成したクエリは以下の通りです。
{
namespace="$namespace",
pod=~"$pod",
service_name="ingress-nginx",
container="controller",
app="ingress-nginx",
component="controller"
}
# ログ全体からの検索(grep)
|~ "(?i)$include"
!~ "(?i)''|$exclude"
# JSON parser
| json
# パースエラーを避けるための前処理
| label_format apptime_in_s=`{{ replace "-" "0" .apptime }}`
# 検索条件での絞り込み
| apptime_in_s >= $min_response_time
| uri!~"$implicitly_exclude_path"
| uri=~".*(?i)${include_path}.*"
| uri!~".*(?i)''|$exclude_path.*"
| ua=~".*(?i)${include_ua}.*"
| ua!~".*(?i)''|$exclude_ua.*"
| method=~"$method"
| domain=~"$domain_name"
| location_path=~"$location"
| status=~"$status_code"
|= ip("$filter_by_ip_addr")
# 既存の項目の値から追加項目を生成
| label_format level=`{{if and (ge .status "200") (lt .status "400") }}info{{else if and (ge .status "400") (lt .status "500") }}warning{{else if (ge .status "500") }}error{{end}}`
| level=~"$log_level"
| label_format forwardedfor_last=`{{ regexReplaceAll ".* ([0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3})$" .forwardedfor "$1" }}`
# 出力フォーマットの定義
| line_format "[{{.status}}]({{printf \"%6s\" .apptime_in_s }}s) {{printf \"%-15s\" .forwardedfor_last}} >{{printf \"%-30s\" .proxy_upstream_name}} {{printf \"%-25s\" .domain}} {{printf \"%-7s\" .method}} {{printf \"%-70s\" .uri}} (UA: \"{{.ua}}\")"
上記の通り、ログ全体から文言をinclude/excludeするフィルタは当然ながら、JSON形式のログをパースした後の各項目ごとにも細かくフィルタをかけれるようにし、各項目に対応する変数をそれぞれ定義して、ダッシュボード上のテキストボックスやプルダウンに紐付け、フィルタ条件として指定できるようにしました。

DataDogほどリッチな見た目ではないのですが、実用上ほぼ問題ないレベルまで作り込めたかなと思っています。
ここで工夫をした点としては、フィルタリングの候補になるプルダウンを用意する際に、Lokiを集計するのではなく、Prometheusのクエリから生成しました。これはLokiの集計は非常に高コストなので、本番のログ量では実用に耐えられないためです。
これに関してはRulerを使ってIngest時にメトリクスを生成してPrometheusに送り、それを参照するのが理想的ではありますが、これは追々取り組みたいと考えています。
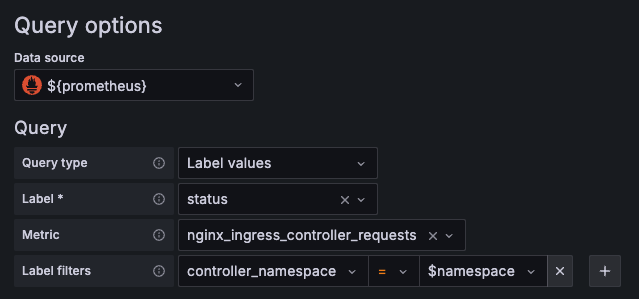
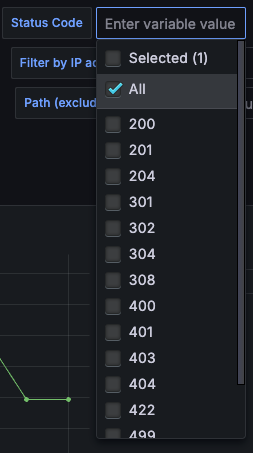
また、Loki Queryには様々な組み込み関数が用意されているので、クエリを作り込む際に活用すると作り込みが楽になると思います。
https://grafana.com/docs/loki/latest/query/template_functions/
その中でも個人的に神機能だなと思うのが、IPアドレスのマッチング関数です。
https://grafana.com/docs/loki/latest/query/ip/
単一IPはもちろんの事、レンジ指定、CIDR指定などなんでも宜しくやってくれて感動レベル。ありがとうGrafanaLabsのみなさん。
成果
ここまでお話ししてきたLoki、Promtail、Grafanaダッシュボードを一通り構築した結果、下記成果を得ることができました。
- DataDogで数%のサンプルレートで取得していた時のコストと比較し、同等以下のコストで全てのIngressNGINXのログを収集可能に
- オリジンをS3に置くことで過去のログも低コストで簡単に参照可能に
- コスト面で許容出来そうだったので、IngressNGINXのログだけでなく、主要アプリケーションの全ログを送るようにし、Grafanaで検索可能に
- SRE-Tに対するログ関係の依頼や相談が大きく減り、問い合わせがきた場合でもGrafana上で必要な検索条件を設定した上で、そのリンクを共有すれば話が早いので、トイル削減につながりました
Loki運用のお悩み
さて、ベタ褒めしてきたLokiですが、運用上のお悩みもまだまだあります。
-
各コンポーネントの設定と調整がなかなか面倒 (特に導入直後)
これは前述の通り、最終的には徐々に送信対象を増やしながらいい塩梅を探るしかありません。 -
長期間のログ検索に時間がかかる
LokiのCLIコマンドで解決しようと取り組んでいます。次項で詳しく説明します。 -
各項目ごとの集計が現実的な処理時間で終わらない
これはパイプラインでメトリクスを生成してPrometheusで収集するようにすればある程度カバーできそうな気はしていますが、まだ着手できていません。 -
ログ量によっては数時間程度しか参照できない
これはLokiではなくAmazon Managed Grafanaの制約でして、AMGはタイムアウトが1分固定なのでログ量によっては数時間程度のタイムレンジしか指定できません。これに関してはAWSのサポートにも問い合わせましたが、「現時点でのAMGにおいては、すべてのクエリに対して60秒のグローバルタイムアウトの設定が存在する」との回答だったので、現状どうにもならないです。
Issueとしては上がっており、弊社としてもサポート経由で改善要望を上げて頂くようお願いしたので、今後の改善に期待です。
(自前でGrafanaを立てる手もなくはないですが、自由度が増す反面、面倒なことも増えるので悩ましいところ)
長期間のログ検索
上記の課題の中で直近で特に要望を頂いていたものの1つが長期間のログ検索です。
例えば、
- 過去1週間の特定User-Agentからのアクセスを全て見たい
- 過去の特定の日付の日の全ログから条件にマッチするものを全て見たい
といった要望が頻度は多くないものの割とあります。
そもそも従来のDataDogではできていなかったことではあるので追加要件ではあるのですが、要望としてある以上、なんとかして解決したいと考えました。
Amazon Managed Grafanaの固定タイムアウト値の問題はそれはそれで問題なのですが、そもそもタイムアウトが無制限だったとしても、大量の対象ログがブラウザに送られてきたところでブラウザがクラッシュするので、ひとまずコマンドベースで集計してS3に保存するスクリプトを作成することにしました。
Lokiにはlogcliというコマンドラインツールが用意されており、これがまた痒いところに手が届く感動レベルの素晴らしい出来です。
https://grafana.com/docs/loki/latest/query/logcli/
これを活用した実行コマンドはこんな感じです。
logcli query \
--timezone=UTC \
--from="$from_date" \
--to="$to_date" \
--addr="http://${loki_fqdn}:${loki_svc_port}" \
--output="${output_format}" \
--parallel-duration="$parallel_duration" \
--parallel-max-workers="$parallel_max_workers" \
--retries=${retries} \
"${query}" \
> "${output_file}"
何が感動レベルかと言いますと、
-
parallel-durationで長期間の指定でもよしなに分割して実行してくれる -
parallel-max-workersでLoki側にかかる負担の調整ができる -
retriesを適度に設定することで、万が一長時間のクエリ実行中にエラーが起きても、分割実行しているリクエストの中でエラーが起きたリクエストだけを再実行してくれる
本当によくできてる。ありがとうGrafanaLabsのみなさん。
このコマンドで出力したファイルを下記コマンドでgzip化してそのままS3にアップロードするようにしました。
# gzip and Upload to S3 bucket
gzip -c $output_file | aws s3 cp - s3://${output_bucket}/$(hostname).gz
ただ、ローカルで長時間実行するのは不便なので、上記コマンドをスクリプトファイルにした上で、EKS上でJobとして実行できるようにして、GitHubActionsからキックできるようにしました。
コンテナでlogcliを実行するための環境は下記のように簡単に用意できますので、Dockerfileにしてコンテナイメージに入れてしまうなり、スクリプトにして実行時に導入するなりで使えるかと思います(Debianベース)
url="https://github.com/grafana/loki/releases/download/v3.3.1/logcli-linux-amd64.zip"
install_dir="/usr/local/bin"
full_path="${install_dir}/logcli"
zip_file="logcli-linux-amd64.zip"
# Install dependencies
apt update
apt-get install -y curl zip awscli
# Install logcli
curl -sSLO "$url"
unzip -d $install_dir $zip_file
mv ${install_dir}/logcli-linux-amd64 $full_path
rm $zip_file
chmod +x $full_path
logcli --version
まとめ
長文お読みいただきありがとうございました。
最後に冒頭でも書いたまとめをもう一度
- DataDogからGrafana Lokiに移行し、すべてのログを低コストで収集・参照可能に
- Ingress NGINX以外の主要アプリケーションの全ログも検索可能になり、対応が迅速化
- S3を活用した過去のログ参照が容易になり、手動ダウンロードが不要に
- HPAを活用して負荷に応じた自動スケールを行うことで、効率的なリソース利用と安定運用を両立
- 長期間のログ検索や集計などに課題もある
まだまだ改善点はあるので、今後も継続的にブラッシュアップしていきたいと思います。