背景
- ユーザーから送られてきた大量の位置情報ログをpostgresqlに保存するのがつらくなってきたのでs3に投げて処分するようにしたい。
- けれどもfluentdを入れたaws-ec2をログアグリゲータにしてスケールさせるのは面倒。
- けれども、実証実験や営業資料の作成のニーズが多いためs3に投げたログは引き続きRDBMSのような何かで気軽に検索&集計できるようにしたい。
構成
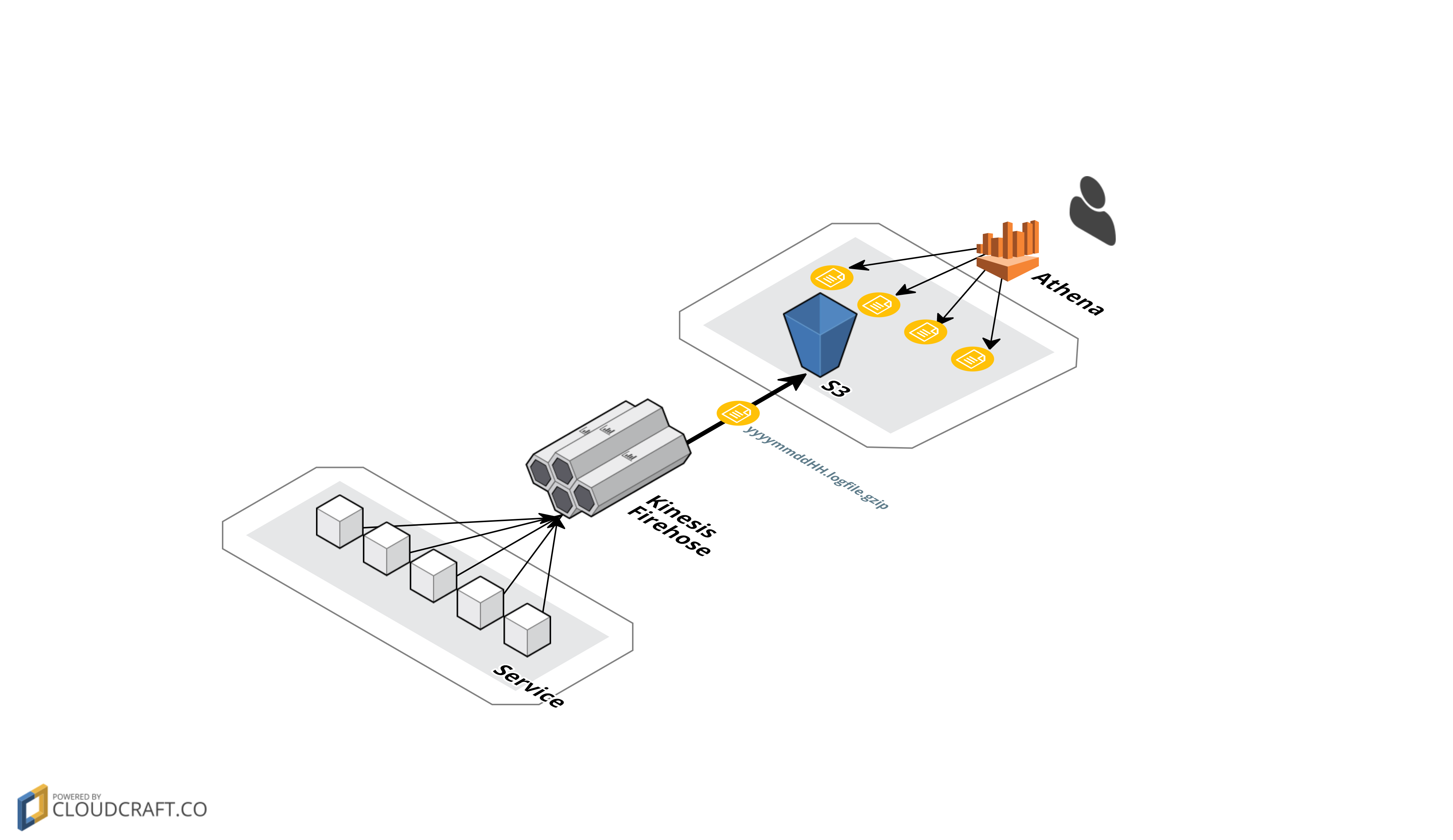
以下のように、サービスから投げたログをKinesisFirehoseが受け取ってs3に保存し、Athenaで検索するようにしました。
実装とハマりどころ
KinesisFirehose
ログ処理に特化したサービスで、流し込んだデータを塊にし圧縮してredshift、s3、elastic searchのいずれかに投げることができる。特徴は負荷に応じた同時実行数やインスタンス数の上限等を調整する必要がなく、使用者がスケーラビリティを気にしなくて良いこと。
現状では日本展開していないので西海岸で日本に近そうなオレゴン(us-west-2)で作る。

まずはバゲット名を指定し、s3にアクセスする用のロールを作る。s3に投げられると
バケット名/2017/07/30/時刻/ログ名
という風にログがモリモリ保存されていくが、s3 buffer sizeは最後のログファイルのサイズの上限で、S3 buffer intervalは1個のログの時間幅の上限。ちなみに時間はUTC。
また、rubyからjson形式で投げる場合は以下のようになるが、
firehose = Aws::Firehose::Client.new(region: 'us-west-2')
firehose.put_record(delivery_stream_name: ENV['KINESIS_DELIVERY_STREAM_NAME'], record: {data: data.to_json + "\n"})
json形式のログをAWS Athenaで解析できるようにする場合は 以下のように1つ1つのobjectが改行されている必要があるため1個のobjectだけを送る場合は末端に改行コードを入れる必要がある。
{"user_id":1111,"coupon_id":2222, "created_at" : "2017-07-06T01:03:36.356Z"}
{"user_id":3333,"coupon_id":4444, "created_at" : "2017-07-06T01:03:37.356Z"}
s3
言わずもがなの何でも置いておける格安ストレージ(1GBあたり2円)
Athena
s3に放り込まれたログをSQLで検索できるシステム。BigQueryと同じクエリがスキャンしたデータ量に応じて課金される料金体系(1TBあたり$5)だが、以下のようにパーティションを作成すると指定されたフォルダ以外のログはスキャンせずパケ死しなくなる。なお、firehoseのYYYY/MM/DD形式のディレクトリにはデフォでパーティションが設定されてはいないので日毎にパーティションを作りたい場合は一日に一度の定期タスクでAthenaのクエリを叩いて作ってやる必要がある(ダルい!)。
ALTER TABLE xxxx_logs.logs add partition (dt='20190630')
LOCATION 's3://xxx-logs/2019/06/30';
SELECT count(id) form logs where dt=20190630
使用するデータベースとテーブル名を設定し、ログが保存されているバゲットのリンク、データの形式、およびカラム(日時はdate型でパースできるよう整形するのが面倒な場合はstring型にした方が良いかも)を入力するとテーブルを作成するcreate文が作られ、成功すれば以後そのバゲットを検索できるようになる。
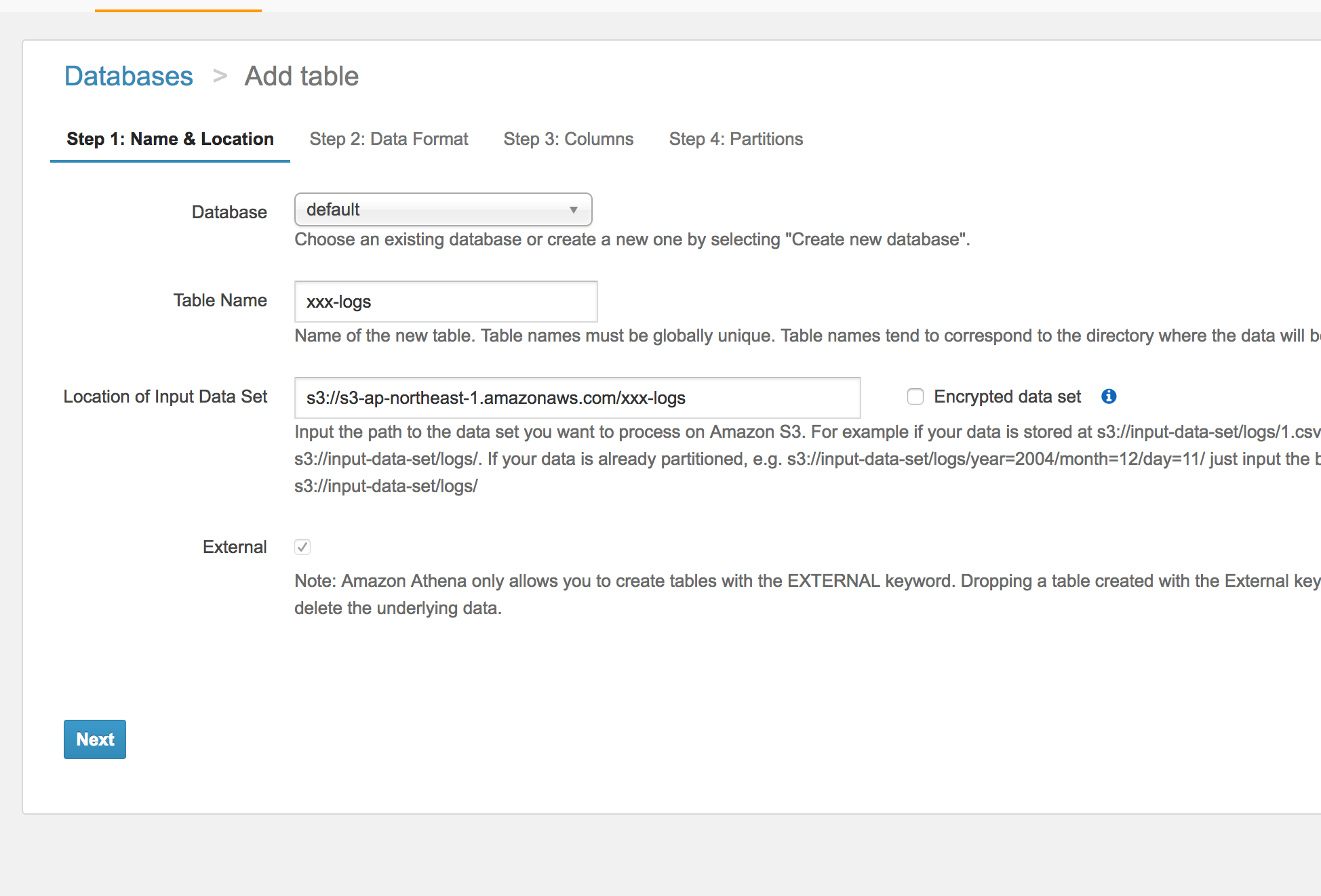
なお、単なるs3ビューワーなので、以下のように新旧の形式が混在したログが入っていても整合性を意識せずに検索できるし、いつでも作り直せる。
{id: 1, latitude: 38.2345, longitude: 121.9876, user_id: 1
{id: 2, latitude: 38.2345, longitude: 121.9876, user_id: 1, app_id: 1}
select count(id) from logs where app_id is null
=> 1
結果
1.DBのコネクション数が劇的に減った♪
2.一日300MBずつ増えていたDBの増加が止まった!
3.Atehnaの検索早い!(100万件のログを2秒で検索可)