環境構築
データを準備
tweet取得
- https://github.com/Tatzyr/alltweets
- 他人のtweetは、3000件まで取れるみたい
- 話題のbecky_bekikoを取得してみる
$ git clone https://github.com/Tatzyr/alltweets.git
$ cd alltweets
$ ./bin/setup
$ ./exe/alltweets becky_bekiko --retweets --json
$ ls alltweets_becky_bekiko.json
alltweets_becky_bekiko.json
データ整形
整形せずにそのまま突っ込みたかったが、geo_pointが配列を受け入れてくれなかった。ドキュメントには"location": [ -71.34, 41.12 ]はOKそうなのだが。
どうせ整形するなら扱いやすいデータ構造にjqコマンドで整形した。
$ cat alltweets_becky_bekiko.json | jq ' .[] |
{
id: .id_str,
created_at: .created_at,
text: .text,
analyze_text: .text,
source: .source,
in_reply: {
status: .in_reply_to_status_id_str,
user_id: .in_reply_to_user_id_str,
screen_name: .in_reply_to_screen_name
},
user: {
id: .user.id_str,
name: .user.name,
screen_name: .user.screen_name,
location: .user.location,
description: .user.description,
url: .user.url,
followers_count: .user.followers_count,
friends_count: .user.friends_count,
listed_count: .user.listed_count,
created_at: .user.created_at,
favourites_count: .user.favourites_count,
statuses_count: .user.statuses_count,
lang: .user.lang,
profile_image_url: .user.profile_image_url_https,
profile_banner_url: .user.profile_banner_url
},
geo: {
lat: (.geo.coordinates[0] // 0),
lon: (.geo.coordinates[1] // 0)
},
place: {
id: .place.id,
url: .place.url,
place_type: .place.place_type,
name: .place.name,
full_name: .place.full_name,
country_code: .place.country_code,
country: .place.country
},
retweet_count: .retweet_count,
favorite_count: .favorite_count,
lang: .lang,
hashtags: .entities.hashtags,
user_mentions: .entities.user_mentions,
media: .entities.media,
retweeted_status: {
created_at: .retweeted_status.created_at,
id: .retweeted_status.id_str,
text: .retweeted_status.text,
source: .retweeted_status.source,
in_reply: {
status: .retweeted_status.in_reply_to_status_id_str,
user_id: .retweeted_status.in_reply_to_user_id_str,
screen_name: .retweeted_status.in_reply_to_screen_name
},
user: {
id: .retweeted_status.user.id_str,
name: .retweeted_status.user.name,
screen_name: .retweeted_status.user.screen_name,
location: .retweeted_status.user.location,
description: .retweeted_status.user.description,
url: .retweeted_status.user.url,
followers_count: .retweeted_status.user.followers_count,
friends_count: .retweeted_status.user.friends_count,
listed_count: .retweeted_status.user.listed_count,
created_at: .retweeted_status.user.created_at,
favourites_count: .retweeted_status.user.favourites_count,
statuses_count: .retweeted_status.user.statuses_count,
lang: .retweeted_status.user.lang,
profile_image_url: .retweeted_status.user.profile_image_url_https,
profile_banner_url: .retweeted_status.user.profile_banner_url
}
}
}
' > becky_bekiko.json
bulkに整形
- bulk用のフォーマットに整形する。
- 雑な整形プログラム
require 'json'
File.open('./becky_bekiko.json', 'w') do |f|
open('./bulk_becky_bekiko.json').each do |line|
json=JSON.load(line)
index = { "index" => { "_index" => "twitter", "_type" => "tweet", "_id" => json["id"]} }
f.puts index.to_json
f.puts line
end
end
$ ruby to_bulk.rb
$ ls bulk_becky_bekiko.json
bulk_becky_bekiko.json
-
stream2esを使えば整形せずにいけるとあったが、_idのmappingsで
"reason": "Failed to parse mapping [tweet]: _id is not configurable"と怒られたのであきらめた。
IndexとMappingの作成
$ curl -XPOST 'http://192.168.33.10:9200/twitter' -d '
{
"settings": {
"analysis": {
"analyzer": {
"ngram_analyzer": {
"type": "custom",
"char_filter": ["html_strip"],
"tokenizer": "ngram_tokenizer",
"filter": ["cjk_width", "lowercase"]
},
"facet_analyzer": {
"type": "custom",
"char_filter": ["html_strip"],
"tokenizer": "keyword",
"filter": ["cjk_width", "lowercase"]
}
},
"tokenizer": {
"ngram_tokenizer": {
"type": "nGram",
"min_gram": 2,
"max_gram": 3,
"token_chars": ["letter", "digit"]
}
}
}
},
"mappings": {
"tweet": {
"properties": {
"created_at": {
"type": "date",
"format" : "EE MMM d HH:mm:ss Z yyyy"
},
"text": {
"type": "string",
"index": "analyzed",
"analyzer": "ngram_analyzer"
},
"analyze_text": {
"type": "string",
"index": "not_analyzed"
},
"source": {
"type": "string",
"index": "analyzed",
"analyzer": "facet_analyzer"
},
"in_reply": {
"type": "object",
"properties": {
"status": {
"type": "long"
},
"user_id": {
"type": "long"
},
"screen_name": {
"type": "string",
"index": "not_analyzed"
}
}
},
"user": {
"type": "object",
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "string",
"index": "not_analyzed"
},
"screen_name": {
"type": "string",
"index": "not_analyzed"
},
"location": {
"type": "string"
},
"description": {
"type": "string",
"index": "analyzed",
"analyzer": "ngram_analyzer"
},
"url": {
"type": "string"
},
"followers_count": {
"type": "long"
},
"friends_count": {
"type": "long"
},
"listed_count": {
"type": "long"
},
"created_at": {
"type": "date",
"format" : "EE MMM d HH:mm:ss Z yyyy"
},
"favourites_count": {
"type": "long"
},
"statuses_count": {
"type": "long"
},
"lang": {
"type": "string"
},
"profile_image_url": {
"type": "string"
},
"profile_banner_url": {
"type": "string"
}
}
},
"geo": {
"type": "geo_point",
"ignore_malformed": true
},
"place": {
"type": "object",
"properties": {
"id": {
"type": "string"
},
"url": {
"type": "string"
},
"place_type": {
"type": "string"
},
"name": {
"type": "string"
},
"full_name": {
"type": "string",
"index": "analyzed",
"analyzer": "ngram_analyzer"
},
"country_code": {
"type": "string"
},
"country": {
"type": "string"
}
}
},
"retweet_count": {
"type": "long"
},
"favorite_count": {
"type": "long"
},
"lang": {
"type": "string"
},
"hashtags": {
"properties": {
"text": {
"type": "string",
"index": "analyzed",
"analyzer": "facet_analyzer"
}
}
},
"user_mentions": {
"properties": {
"screen_name": {
"type": "string",
"index": "not_analyzed"
},
"name": {
"type": "string",
"index": "not_analyzed"
},
"id": {
"type": "long"
}
}
},
"media": {
"properties": {
"id": {
"type": "long"
},
"media_url_https": {
"type": "string"
},
"expanded_url": {
"type": "string"
},
"type": {
"type": "string"
}
}
},
"retweeted_status": {
"type": "object",
"properties": {
"created_at": {
"type": "date",
"format" : "EE MMM d HH:mm:ss Z yyyy"
},
"id": {
"type": "long"
},
"text": {
"type": "string",
"index": "analyzed",
"analyzer": "ngram_analyzer"
},
"source": {
"type": "string",
"index": "analyzed",
"analyzer": "facet_analyzer"
},
"in_reply": {
"type": "object",
"properties": {
"status": {
"type": "long"
},
"user_id": {
"type": "long"
},
"screen_name": {
"type": "string",
"index": "not_analyzed"
}
}
},
"user": {
"type": "object",
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "string",
"index": "not_analyzed"
},
"screen_name": {
"type": "string",
"index": "not_analyzed"
},
"location": {
"type": "string"
},
"description": {
"type": "string",
"index": "analyzed",
"analyzer": "ngram_analyzer"
},
"url": {
"type": "string"
},
"followers_count": {
"type": "long"
},
"friends_count": {
"type": "long"
},
"listed_count": {
"type": "long"
},
"created_at": {
"type": "date",
"format" : "EE MMM d HH:mm:ss Z yyyy"
},
"favourites_count": {
"type": "long"
},
"statuses_count": {
"type": "long"
},
"lang": {
"type": "string"
},
"profile_image_url": {
"type": "string"
},
"profile_banner_url": {
"type": "string"
}
}
}
}
}
}
}
}
}
'
データの登録
$ curl -s -XPOST 192.168.33.10:9200/_bulk --data-binary "@bulk_becky_bekiko.json"; echo
kibana
設定
- 「Index name or patter」に「twitter」
- 「Time-field name」に「created_at」
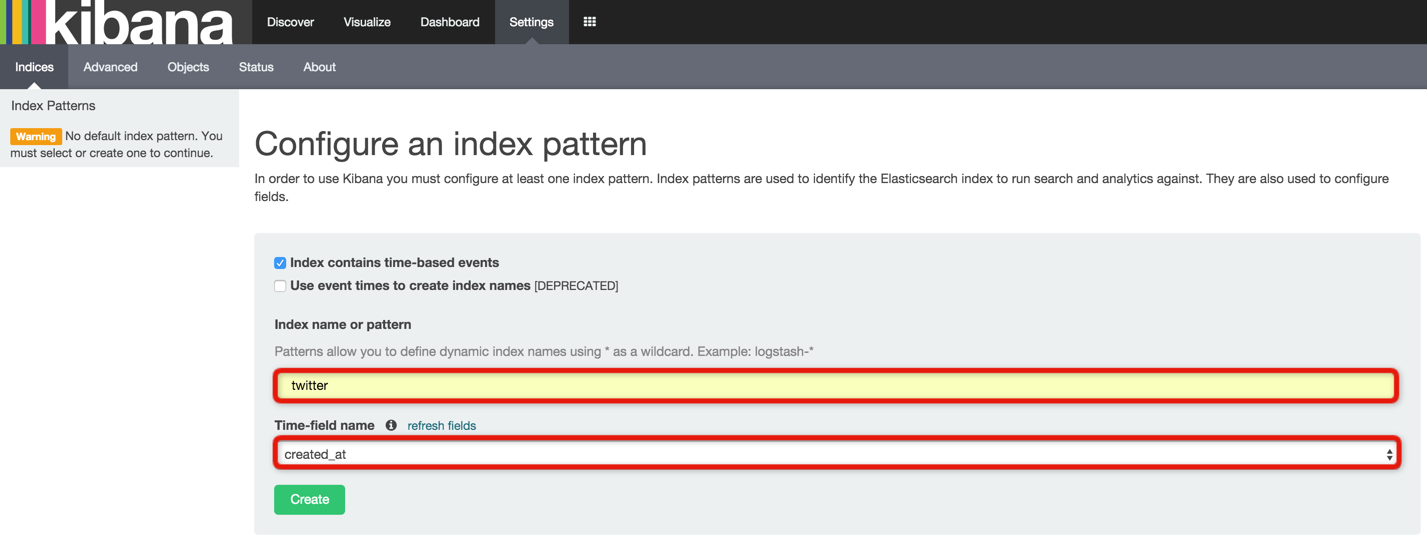
Discoverページ
- 「Discover」を選択
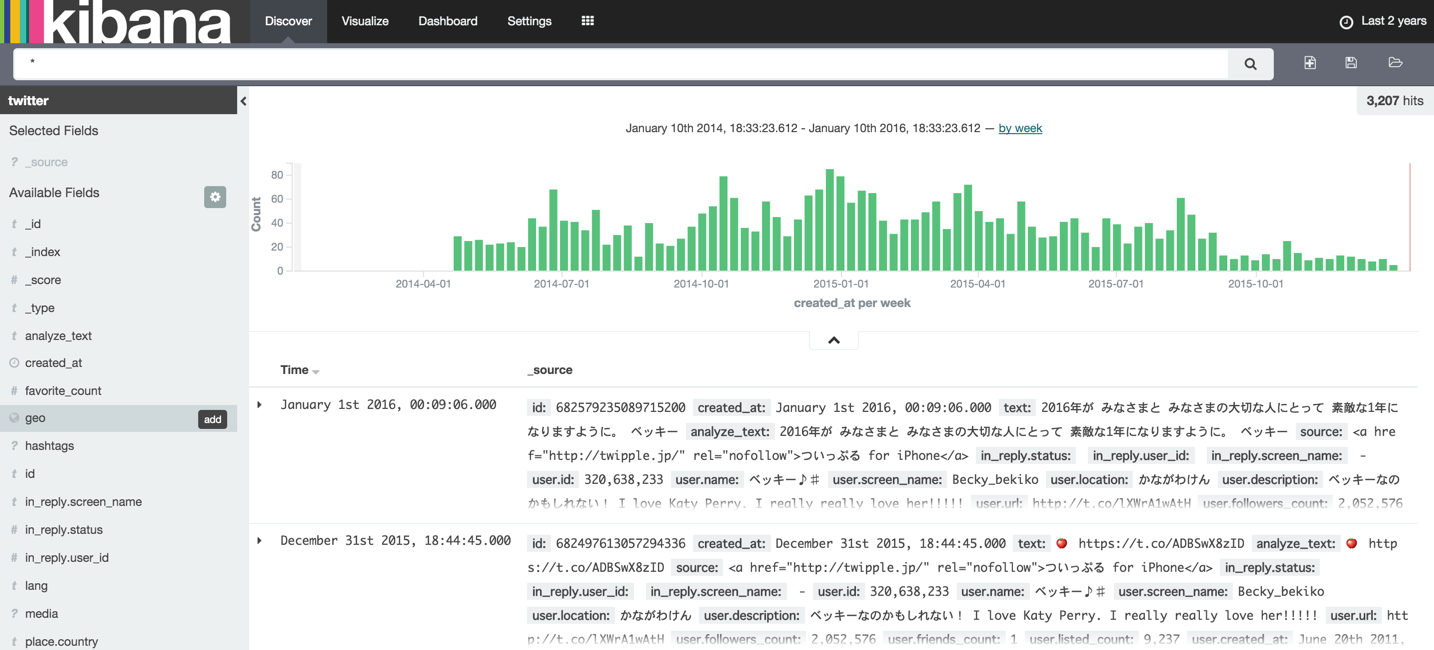
Geo
- 「Visualize」⇒「Tile map」
- geo_pointにnull(
"ignore_malformed": true)は受け入れてもらえなかったので、適当な初期値のgeoです
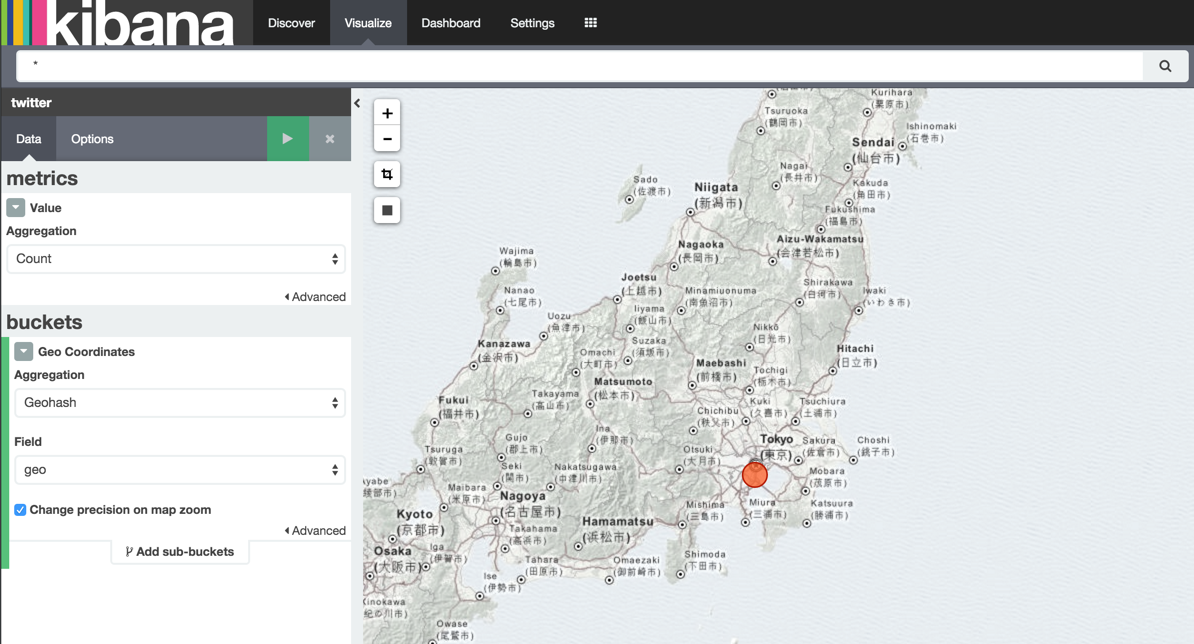
円グラフ
- 「Visualize」⇒「Pie chart」
ハッシュタグ数
- Field「hashtags.text」
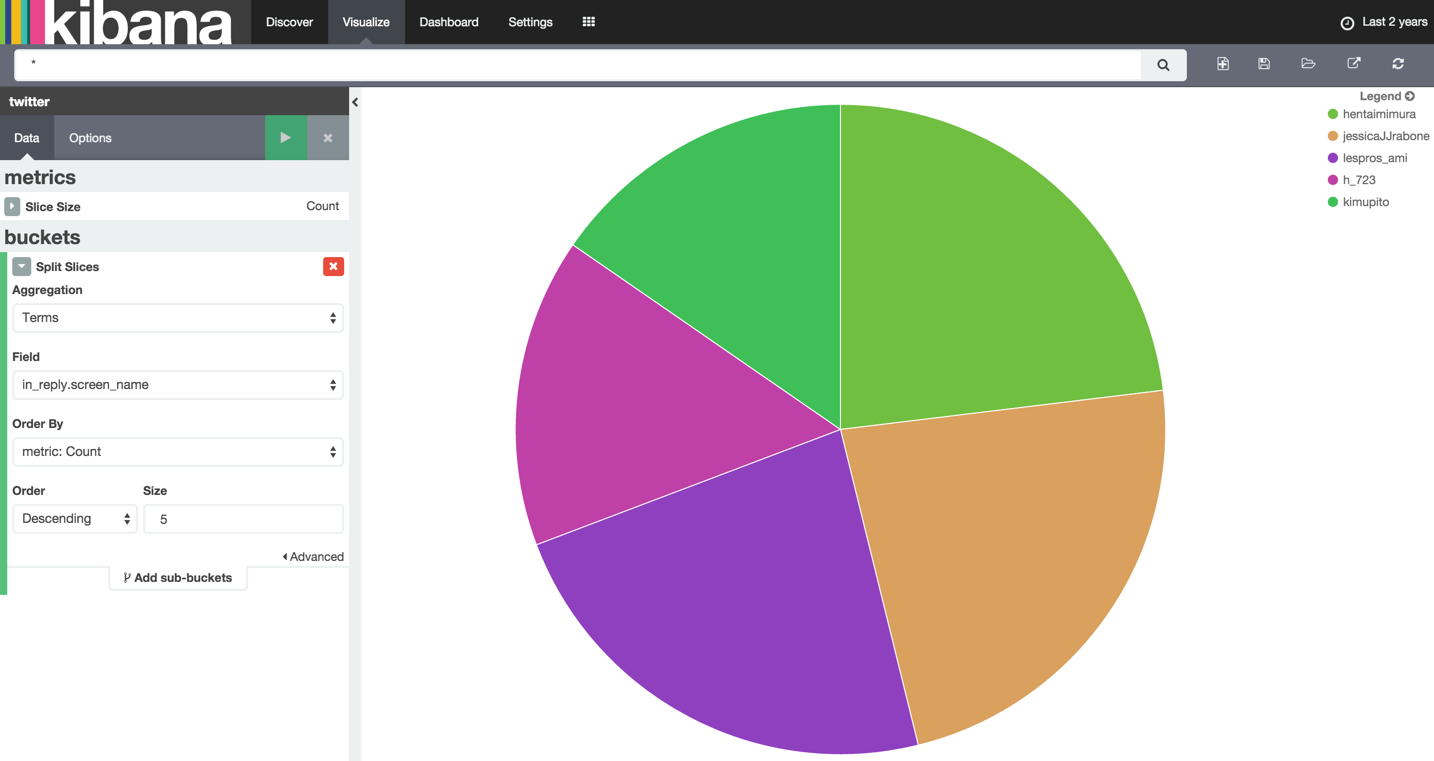
メンションしたユーザの多い数
- Field「in_reply.screen_name」
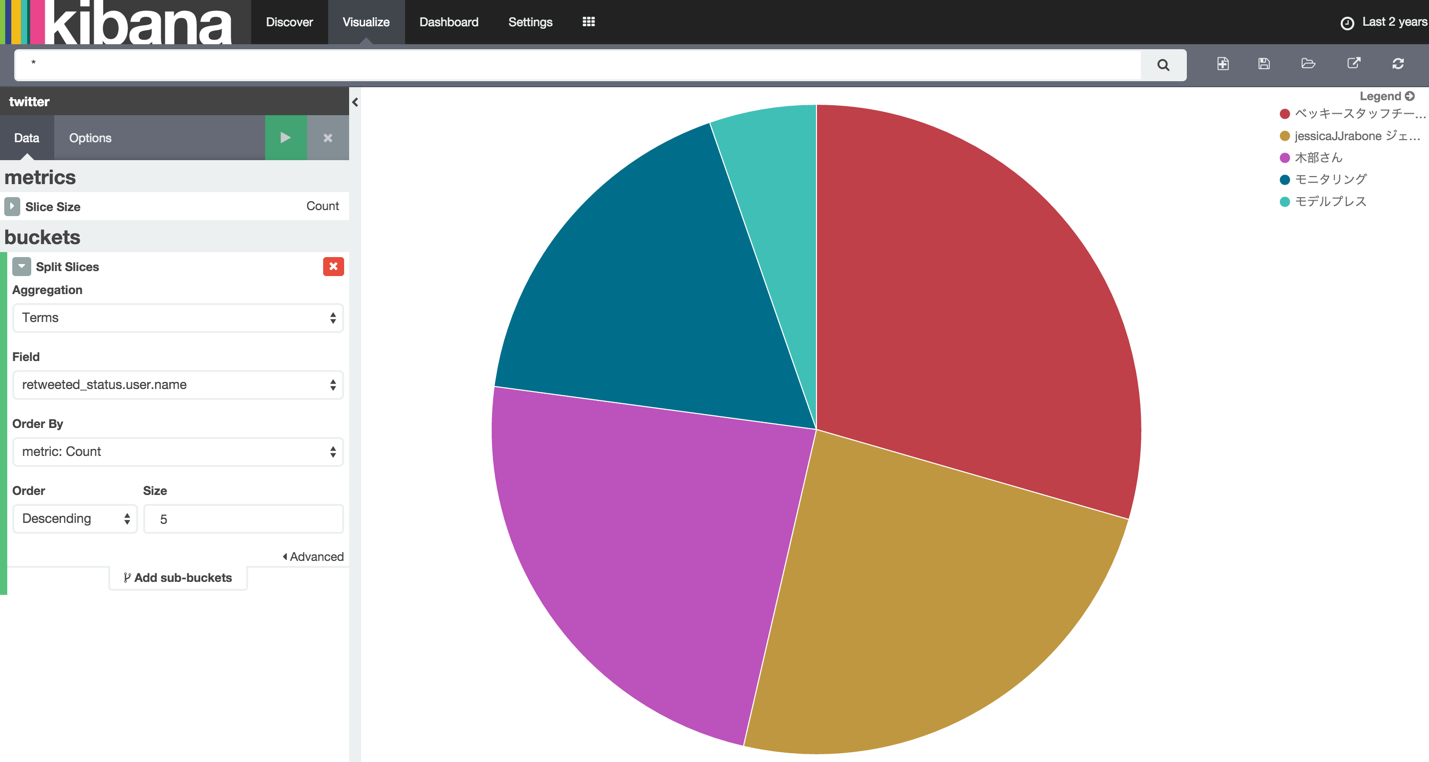
RTしたユーザの多い数
- Field「retweeted_status.user.name」
縦棒グラフ
- 「Visualize」⇒「Vertical bar chart」
Fav数の多いtweet
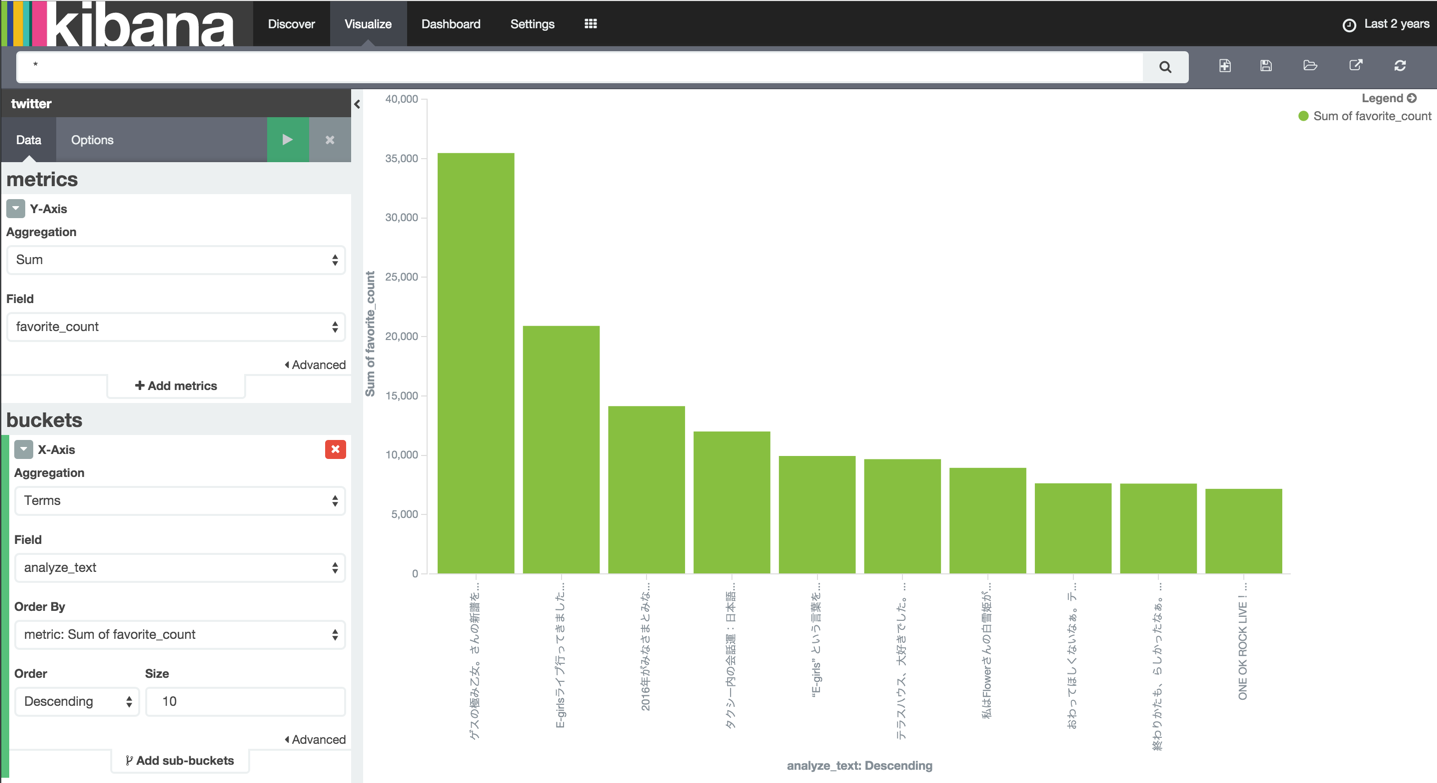
ゲスの極み乙女。さんの新譜を聴く時のあのドキドキ感はなんていうんだろう。 もう、恋のドキドキと同じなんですよね。 胸がきゅーんって。 そのあとに すきすきすきぃー!って。 今年、ライブを拝見するのが目標です。 はぁ。。。幸せなためいき。。。
— ベッキー♪♯ (@Becky_bekiko) June 26, 2015
まとめ
- データ整形とmappingsを整理するのが大変だった
- 日本語検索の精度が適当なので、analysisの理解深めたい