Unsupervised Outlier Detection on Databricks | Databricks Blogの翻訳です。
本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Kakapo - PyOD、MLflow、Hyperoptとのインテグレーション
Kakapo(KAH-kə-poh)では、Databricksにおける大規模外れ値検知のための標準APIセットを実装しています。広範な外れ値検知アルゴリズムのPyODライブラリ、モデルのトラッキングとパッケージングのためのMLFlow、広大かつ複雑、不均一な検索空間を探索するためのHyperoptとのインテグレーションを提供します。

本書で示される見解は、著者による個人的なものであり、European Securities and Markets Authority (ESMA)に帰属するものではありません。
異常検知の手法は様々な業界に浸透しています。ユースケースが不正、サービスの劣化、ネットワーク監視などのいずれかであっても、洞察を導き出すために異常検知のツールやテクニックが必要になることでしょう。外れ値の検知は、典型的なデータサイエンスワークフローの重要なフェーズとなります: データがクレンジングされ、あつらえた特徴量で拡張されると、予測モデルは外れ値の存在に関して、最適とは言えない結果を導き出す場合があります。それらの特定が最終ゴールである場合もあります。いずれの場合でも、容易に実装でき、進化する要件に適応できるシンプルでスケーラブルなフレームワークを持つことが求められます。
これらのことを実施するにあたり、この記事で我々はWikipediaの異常検知の定義に従います:"データ分析において、異常検知(外れ値検知や時にはノベルティー検知とも呼ばれます)は通常、データの大部分から大きく逸脱し、通常の挙動に関する適切な定義に準拠しないレアなアイテム、イベント、観測の特定と理解されます。このため、二つの用語は同義語とみなします。"
外れ値検知に取り組む際には、どこからスタートすればいいのでしょうか?どのフレームワークを選択すべきでしょうか?どのような技術を導入すべきでしょうか?ラベルデータがない場合にはどうしたらいいのでしょうか?予測される異常の数がわからない場合にはどうしたらいいのでしょうか?
外れ値検知の技術的側面に加え、堅牢なソリューションを実装し始める際に考慮すべき広範な検討事項があります:
- 将来にわたる継続性とスケーラビリティ、すなわち、単に今日のワークロードに対応するだけでなく、ボリューム/速度/複雑性の増加など要件の変更に応じてスケールするフレームワークを持つにはどうしたらいいか。
- 生産性とコラボレーション、作業やアイデアを容易に共有できるようにすること。
- ガバナンスと監査可能性、メタデータをどのように収集、記録し、堅牢な監査証跡を確実なものとし、最終的には信頼できるデータを生成すること。
この記事では、Databricksで大規模な異常検知を実行するための標準的なAPIセットを提供します。このソリューションは、MLflow(モデルのトラッキングとパッケージング)とHyperopt(モデルとハイパーパラメーターチューニング)とインテグレーションします。数多くの外れ値検知アルゴリズムを提供するPyODライブラリや、容易でスケーラブルなトラッキングと監査可能性のためのMLflowとのインテグレーションを可能とするシンプルなモデルラッパーテンプレートからスタートするステップバイステップのガイドを提供します。ここでのアウトプットは、as-isあるいはさらに強化可能な拡張可能フレームワークを意図しています。このフレームワークの中心には、Kakapoライブラリ、MLflow、Hyperoptが存在しています。
なぜ外れ値が問題になるのか?
上述の異常検知の定義では、統計と洞察は背後にあるデータ以上に優れたものにはならず、"大きく"という用語はケースバイケースで決定され、主観的なものだと考えます。これは、外れ値とは何であるかという厳密な数学的定義がないためです。Chebyshev's inequality、Dixon's Q test、Chauvenet's criterion、Mahalanobis distanceやおそらく他のアプローチは全て、"期待したものと違うというものはどういうことか?"という問いに答えることを狙いとしています。 - "'異なる'(観測結果)というのをどのように特定できるのか?"という問いで補完される期待値の質問と言えます。不均一の定義におけるわずかな違いが、単にコンテキストによってパフォーマンスに大きなインパクトを与えることがあります。
期待値に対する問いは業界によって様々です。規制のある業界では、規制主体の責務は彼ら自身それぞれの業界の監視であるため、最重要かつ中心に据えられています。"規制主体は彼らの責任領域における重要なリスクを特定するために、エビデンスベースのアプローチをとるべきである、..." - UK Regulators' Code。エビデンスベースのアプローチは基本的には、我々のデータを処理する能力と適切に解釈する能力と同等の有効性を持ちます。データポイントの統計的な性質(何が異常で何がそうでないか)はこれらの検討において重要となります。期待値に関する質問の重要性に関する別の例は、European Securities and Markets Authority (ESMA)の非常によく似たミッションステートメントで見つけることができます: "一つのミッション: 投資家の保護と安定かつ秩序のある金融市場を強化すること"。安定し秩序のある市場を適切にモデリングするためには、不安定で混沌とした挙動がどのようなものであるのかを理解する必要があります。ここで、異常検知がデータドリブンの規制活動の達成に向けて多大なる価値を提供するのです。最後に、規制主体によって規定され、監視される同じ規範と標準に準拠することは、規制を受ける側の責務となります。そして、これらの規範に準拠するためには、規制を受ける側は彼らが自分たちのビジネスを提供し、これらの問題をプロアクティブに修正できる方法で、異常や問題の合えるイベントを検知するための同じツールを必要とします。
同じ原則は規制のある業界の外でも適用されます。プライベートやサードセクターでは、期待値に関する問いはこれまで以上に重要なものとなっています - シンプルに他のユースケースにも適用されます。これらのセクターでは、通常のデータの検知によって、望まない顧客の解約や競合への乗り換えを防ぎ、不正検知の自動化の助けとなり、おそらくは予兆メンテナンスの助けにもなることでしょう。秩序のある城田らの逸脱を検知することで、予測されないイベントのエビデンスや到来するイベントの予兆となります。利用可能な全ての性質を考慮することなしに、適切なデータドリブンな意思決定を行うことはできません - そして、異常な状態の観測は、どのような業界でも優れた意思決定のためのパワフルなツールとなります。
ラベルが少ないモデル評価のケース
ケースの大部分でないにしても、多くの場合、ラベル付きの異常データを手に入れることが困難、あるいは、データ資産に対して期待される数の異常のデータを入手することが困難です。労力とコストの両面で、時間を消費し高価となる複雑なタスクです。ラベル付きデータがあったとしても、数多くの他の外れ値が存在し、評価基準をあやふやなものにしてしまいます。さらに、多くの組織では潜在的な異常を含むかもしれない(あるいは実際に含む)数百のデータ資産にラベルづけを行うことは不可能です。
我々は、このことを念頭に置きkakapoライブラリを設計し、コードを変更することなしにフラグのパラメーターを引き渡すことで、教師あり、教師なしのモデルの評価を実行するための全く同じAPIセットを公開しています。ラベル付きのデータがない場合、特徴量とそれらの分布のみに依存する教師なしのメトリックを計算します(このケースでは、N. Goixらの取り組みをベースとしてEM/MVメトリクスを計算しました)。
さらに、この記事でカバーしているKakapoライブラリのインテグレーションを活用することで、様々なハイパーパラメータを用いて数百のモデルをトレーニングするような大規模な取り組みを行うことができ、一つのモデルに依存することなしの同意形成型の異常検知を行う"アンサンブル"モデルを自由に作成できます。
簡素化、標準化、統合は、上述した複雑なシチュエーションからの価値を解放します。この記事を通じて、これらの原則を推進し、異常検知ユースケースにおけるベストプラクティスとクリーンなシステムを推し進めます。
PyDO - 特定のためのツールボックス
"PyODは多変量データにおいて逸脱しているオブジェクトを検知するための、最も包括的でスケーラブルなPythonライブラリです。" - PyOD
PyODから提供される広範なオファリングは、上述の引用に完璧に合致しています。PyODは、従来のモデルやディープモデルを含む異常検知のための40以上の様々なモデルを提供しています。これによって、PyODはベテランから新米に至るすべてのデータサイエンティストのレパートリーにおける重要なツールとなっています。
PyODには、統合APIと様々な選択肢を提供する検知アルゴリズムが含まれています - Isolation Forestのような古典的なものから、ECODのような新規参入のものまで提供しており、1000万以上のダウンロードとなっており、業界における認知や導入の証明となっています。
最後に、おそらくフレームワークの最も魅力的な側面はシンプルさと使いやすさです。異常検知アルゴリズムの実装は数行のコード以上の何物でもありません:
%python
# train an ECOD detector
from pyod.models.ecod import ECOD
clf = ECOD()
clf.fit(X_train)
# get outlier scores
y_train_scores = clf.decision_scores_ # raw outlier scores on the train data
y_test_scores = clf.decision_function(X_test) # predict raw outlier scores on test
なぜシンプルにIsolation Forestを使わないのでしょうか?これらのすべてのメリットは、異常検知の取り組みやシステムデザインにおける統合とシンプルさの協力な候補として、PyODを前に押し出します:
- 現行の異常検知技術の置き換え、拡張を可能にする柔軟性によって、コードベースがより堅牢なものとなります。
- コードベースはよりスリムになり、より宣言的になります。
- MLflowとhyperoptとのインテグレーションによって、提案しているフレームワークでは、以上に対する事前知識がある場合、そのような知識がない場合の両方において異常検知を提供できるようになります。
注意
オフィシャルのPyOD docs pageには様々な情報が提供されており、異常検知に興味を持たれた方はこれらを一読いただくことを強くお勧めします。
MLライフサイクル管理におけるMLflowのベストプラクティス
MLflowは、MLライフサイクルを管理するための最も注目されているオープンソースプラットフォームであり、エクスペリメント、再現可能性、デプロイメント、中央モデルレジストリなどを提供しています。MLflowの主なコンポーネントは以下の通りです:
| MLflow Tracking | MLflow Projects | MLflow Models | MLflow Registry |
|---|---|---|---|
| エクスペリメント - コード、データ、設定と結果の記録とクエリー | 任意のプラットフォームでランを再現するためのフォーマットにデータサイエンスコードをパッケージング | 様々なサービング環境でMLモデルをデプロイ | 中央リポジトリでモデルを格納、注釈、発見、管理 |
Tracking APIによって、ユーザーはたった数行のコードで、簡単かつアクセス可能な方法で機械学習モデルをトレーニングする際に、パラメーター、メトリクス、様々な他のアウトプットを記録できるようになります!
%python
import mlflow
# Log parameters
mlflow.log_param("n_estimators", 100)
mlflow.log_param("max_depth", 5)
# Log evaluation metrics
mlflow.log_metric("f1", f1_score)
mlflow.log_metric("recall", recall_score)
# Log artifacts
mlflow.log_artifact("/dbfs/path/to/confustion_matrix.png")
# Set a single tag
mlflow.set_tag("model", "randomForest")
それぞれのモデルのランを記録した後で、機能が豊富なAPIや直感的なウェブUIを用いて、エクスペリメントを探索し、結果を比較し、他のデータサイエンティストと共有することができます:
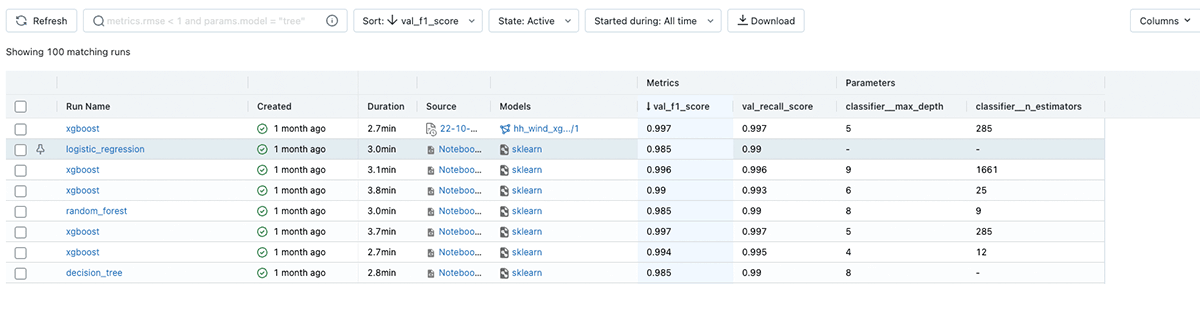
モデル評価と比較のためのMLflow UI
MLflowは、後で容易にデプロイできるように、様々なフォーマット("フレーバー"とも呼ばれます)で機械学習モデルをパッケージングします。MLflowではいくつかの標準的なフレーバーを提供しており、scikit-learn、XGBoostなどのような人気のパッケージを通じて実装された大量のモデルを自動で追跡、記録することができます。
MLflowでは、ネイティブでサポートされていないモデルに対するソリューションも提供しています: python_function (pyfunc)モデルフレーバーは、任意のコードとモデルデータからpyfuncモデルを作成するユーティリティを提供するので、MLflowのベストプラクティスを活用することができます。
この章の残りでは、その他のMLflowエコシステムとの密連携のために、Kakapoパッケージを通じて提供されるpyfuncモデルラッパーとして任意のPyOD外れ値検知モデルをラッピングするアプローチの一つをデモンストレーションします。以下のコードブロックでは、名前の通り動作するPyodWraperというメソッドを参照しています。PyODのベースモデル(コードでは"model space"として参照)を受け取り、最小限のユーザーの介入でMLflowでモデルが記録、追跡されるように、バックエンドでは必要なインテグレーションが実装されています。
%pip install databricks-kakapo
%python
from kakapo import PyodWrapper
from kakapo import get_default_model_space
params = {
"type": "abod"
"n_neighbours": 10
}
model_space = {
"abod": ABOD
}
model = PyodWrapper(**params)
model.set_model_space(model_space)
model.fit(X_train)
y_test_pred = model.predict(None, X_test)
# Get model input and output signatures
model_input_df = X_test
model_output_df = y_test_pred
model_signature = infer_signature(model_input_df, model_output_df)
# log our model to mlflow
mlflow.pyfunc.log_model(
artifact_path="model",
python_model=model,
signature=model_signature
)
上のコードでmodel_spaceは、使用したいPyODアルゴリズムのキーバリューペアのディクショナリーです。Kakapoでは、get_default_model_space() メソッドを通じてアクセスできるデフォルトのモデル空間を提供しています。さらに、デフォルトのモデル空間を補強するために、自由にモデルを追加することができます:
%python
# Default model space available in kakapo
from kakapo import get_default_model_space
from kakapo import enrich_default_model_space
DEFAULT_MODEL_SPACE = get_default_model_space()
print("Default model space: {}".format(DEFAULT_MODEL_SPACE))
"""
model_space = {
"ecod": ECOD,
"abod": ABOD,
"iforest": IForest,
"copod": COPOD,
"inne": INNE
}
"""
# We can also enrich the default model space with other models
# Load new pyod model we want to support
from pyod.models.cof import COF
# Enrich the default model space
model_space = enrich_default_model_space({"cof": COF})
print("Enriched model space: {}".format(model_space))
"""
# Result of print statement shown below:
model_space = {
"ecod": ECOD,
"abod": ABOD,
"iforest": IForest,
"copod": COPOD,
"inne": INNE,
"cof": COF
}
"""
Kakapoのような抽象化を活用することの主なメリットは、汎用性やガバナンスを失うことなしに、外れ値検知のためのモデルのトレーニングに必要なコードのシンプルさです。このパッケージは、MLflowの標準APIに準拠しており、それぞれのサポートされるモデルのユニークさと特化性を抽象化しつつも、相互運用性と可搬性を保証します。エンドユーザーは、複雑、定型文でもあるコードベースの管理ではなく、パラメーターチューニングやパラメーターの解釈にフォーカスできます。
検討している様々な異常検知アルゴリズムのパフォーマンスを評価するために、何かしらのメトリックが必要となります。ラベル付きのデータにアクセスできることもあれば、できないこともあるので、GROUND_TRUTH_OD_EXISTSというフラグを定義しています。Kakapoはその値に応じて挙動を変えます:
- Ground truth labels do exist(正解ラベルが存在する) - roc_auc_scoreが計算され、メインのモデルメトリックとして記録されます。
- Ground truth labels do not exist(正解ラベルが存在しない) - 特徴量とその分布つのみ依存する教師なしのメトリックが計算、記録されます(この記事の例では、N. Goixらの取り組みをベースとしてEM/MVメトリクスを計算しています)。
ラベルなしのデータ資産のサポートを通じて、大規模なデータドメインにおける大きなペインポイントに対応しています。数百のデータセットを含むかもしれないデータドメインで、ラベル付きデータを提供することは困難です。領域全体での外れ値を分析する手段を持つことは、説明されたアプローチの非常に大きなメリットとなっています。
オプティマイザ - Hyperoptによる成功のスケールアウト
パズルの最後のピースは、様々なアルゴリズムと様々なハイパーパラメーターの組み合わせの両方を用いて、数百のモデルの並列トレーニングに対応するために、我々のアプローチをスケールアウトすることです。
Hyperoptは、Pythonにおいて最も高性能なハイパーパラメーター最適化ライブラリとして空れており、データサイエンティストによって広く活用されています。ハイパーパラメータの空間の定義は、数行のコードで済みます。ライブラリのAPIは、この空間におけるモデルのロスを最適化するために活用されることになります。
%python
search_space = {
"criterion": hp.choice("criterion", ["gini", "entropy"]),
"n_estimators": scope.int(hp.quniform("n_estimators", 10, 100, 10)),
"max_depth": scope.int(hp.quniform("max_depth", 2, 8, 1)),
"max_features": hp.choice("max_features", ["sqrt", 10, 15])
}
もう一つのパワフルな機能は、複数のモデルとそれらに対応するハイパーパラメーターを同時にカバーする、ネストされた探索空間を定義できるというものです:
%python
search_space = hp.choice('model_type',
[
{
'type': 'iforest',
'n_estimators': scope.int(hp.quniform('n_estimators_if', 100, 500, 25)),
'max_features': hp.quniform('max_features', 0.5, 1, 0.1)
},
{
'type': 'inne',
'n_estimators': scope.int(hp.quniform('n_estimators_inne', 100, 500, 25)),
'max_samples': hp.quniform('max_samples', 0.1, 1, 0.1)
},
{
'type': 'abod',
'n_neighbors': scope.int(hp.quniform('contamination', 5, 20, 5)),
},
]
)
上の構文を用いることで、ベストなパフォーマンスを示すものを見つけ出す(あるいは、我々のデータに対する多数決スコアリングを行うアンサンブルで組み合わせるための膨大な候補モデルを生成する)ジャーニーに漕ぎ出す際に、数多くの外れ値検知モデルを対応するパラメーターを一緒に連鎖させることができます。
Kakapoのget_default_model_space() と同じように、デフォルトでスタートするためにget_default_search_space() を使うことができます。これも、簡単に組み込みメソッド(nrich_default_search_space())を用いることで補強することができます。
実施すべき残りのことは、並列モデルトレーニングをスタートするために、上のセットアップを用いたHyperoptのfmin関数を実行することだけです。
%python
from kakapo import train_outlier_detection
from kakapo import get_default_model_space
from kakapo import get_default_search_space
# Load default model space
model_space = get_default_model_space()
# Load default hyper param search space
search_space = get_default_search_space()
with mlflow.start_run():
best_params = fmin(
trials=SparkTrials(parallelism=10),
fn = lambda params: train_outlier_detection(params, model_space, X_train, X_test, y_test, GROUND_TRUTH_OD_EXISTS),
space = search_space,
algo = tpe.suggest,
max_evals = 50
)
全てをまとめ上げる
上のトレーニングを完了したら、MLflowのAPIを用いてそれぞれのモデルのランにアクセスすることができます。以下のコードブロックでは、特定のHyperoptランを検索し、それに属するすべてのモデルを取得し、パフォーマンスメトリックでソートしています。そして、ベストなパフォーマンスを示すモデルのユニークなランIDを抽出し、ロードに進むことができます。
%python
metric = "loss"
parentRunId = "<PARENTRUNID>"
# Get all child runs on current experiment
runs = mlflow.search_runs(filter_string=f'tags.mlflow.parentRunId = {parentRunId}', order_by=[f'metrics.{metric} ASC'])
runs = runs.where(runs['status'] == 'FINISHED')
# Get best run id and logged model
best_run_id = runs.loc[0,'run_id']
logged_model = f'runs:/{best_run_id}/model'
以下では、MLflowモデルをロードし、予測結果を生成するための2つのアプローチを確認することができます:
-
Sparkのユーザー定義関数としてモデルをロードし、Sparkデータフレームに対する予測を実行
%python import mlflow from pyspark.sql.functions import struct, col # Load model as a Spark UDF model = mlflow.pyfunc.spark_udf(spark, model_uri=logged_model, result_type='double') # Predict on a Spark DataFrame. df = df.withColumn('predictions', model(struct(*map(col, df.columns)))) -
pyfuncとしてモデルをロードし、Pandasデータフレームに対する予測を実行
%python import mlflow # Load model as a PyFuncModel. loaded_model = mlflow.pyfunc.load_model(logged_model) # Predict on a Pandas DataFrame. import pandas as pd loaded_model.predict(pd.DataFrame(data))
最後に、結果の(SparkかPandas)データフレームを表示し、まさに今生成した異常予測を観察します。
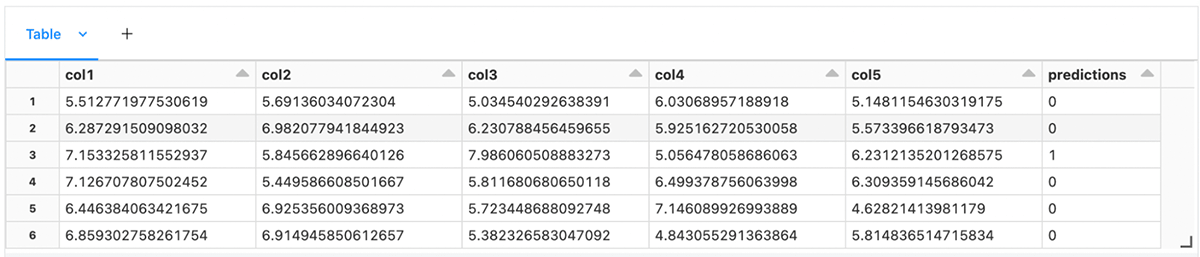
データフレームに対するモデル予測の表示
メトリックに基づいてベストなパフォーマンスのモデルをロードする方法と同じように、連続で多数のモデルをロードし、観測値に対する複数の予測を生成、ここのスコアを集約することができます。これは、異なる強みを持つ複数のモデルを組み合わせ、アンサンブルとして活用する際には、より優れた品質の予測結果を提供する優れた手段となりえます。
この記事を通じて、人気のMLライブラリPyODとMLflowプラットフォームのベストプラクティスとのインテグレーション、Hyperoptが提供するスケーリングのメリットの活用に対する一つのアプローチをカバーしました。教師あり、教師なし両方の異常検知モデリングをサポートするシンプルで拡張可能なフレームワークを提案しました。
このツールボックスは、DatabricksにおけるMLジャーニーのクイックスタートを提供し、個人あるいは企業のベストプラクティスを取り入れ、拡張されることを意図しています。
この記事でカバーされたすべてのコードサンプルは、こちらのノートブックで確認できます。
追伸: パッケージの名前のチョイスを不思議に思っている方向けですが、Kakapoは世界で最も希少な鳥の一種であり、希少かつユニークなイベントを探す際にはこの名前がフィットすると思いました!