こちらでADLSのデータにアクセスする方法を説明しましたが、非推奨の方法を説明してしまっていたので、改めて方法を整理します。
詳細はこちらの記事をベースにしています。
Azure Databricksからストレージにアクセスする方法はいくつかありますが、現在はAzure Blob File System(ABFS)ドライバーを用いる方法が推奨となっています。
| アクセス方法 | 説明 |
|---|---|
| Azure Blob File System(ABFS)ドライバーを用いて接続 | 推奨 ABFS に関する Azure のドキュメント |
| Windows Azure Storage(WASB)ドライバーを用いて接続 | 非推奨 WASB で Azure Blob Storage に接続する (レガシ) |
| 外部データの場所をDatabricksファイルシステムにマウント |
非推奨 Unity Catalogのカタログではマウントされたデータは機能しません。 Azure Databricks でのクラウド オブジェクト ストレージのマウント |
| Azure Active Directoryの資格情報パススルーを使ってAzure Data Lake Storageにアクセス | 非推奨 Azure Active Directory の資格情報パススルーを使って Azure Data Lake Storage にアクセスする |
WASBドライバーとABFSドライバー
Azure Data Lake Storage Gen2 用の Azure BLOB ファイルシステム ドライバー | Microsoft Docsで説明されているように、これまではWindows Azure Storage Blob(WASB)ドライバーが使用されていましたが、コードメンテナンスの困難さやパフォーマンスの課題から新たにAzure File System(ABFS)ドライバーが設計されています。
ABFSドライバーを用いてストレージにアクセスするには、以下のURIスキーマを使用します。
abfs[s]://file_system@account_name.dfs.core.windows.net/<path>/<path>/<file_name>
ABFSのURIを用いてADLS Gen2にアクセスする
以下ではマウントポイントを作成せず、ABFS URIを用いて直接ADLS Gen2にアクセスします。アクセスする際には適切に認証情報を設定する必要があります。認証情報を設定する方法には以下のものがあります。
- Azureサービスプリンシパル
- SASトークン
- アカウントキー
Azureサービスプリンシパルを用いて認証情報を設定する
資格情報の格納にはAzure Databricksシークレットを用いることをお勧めします。
サービスプリンシパルの作成
-
Azure PortalからAzure Active Directoryに移動します。
-
エンタープライズアプリケーション > 新しいアプリケーションを選択します。
-
アプリケーションの名前を指定します。リダイレクトURIは後で設定します。
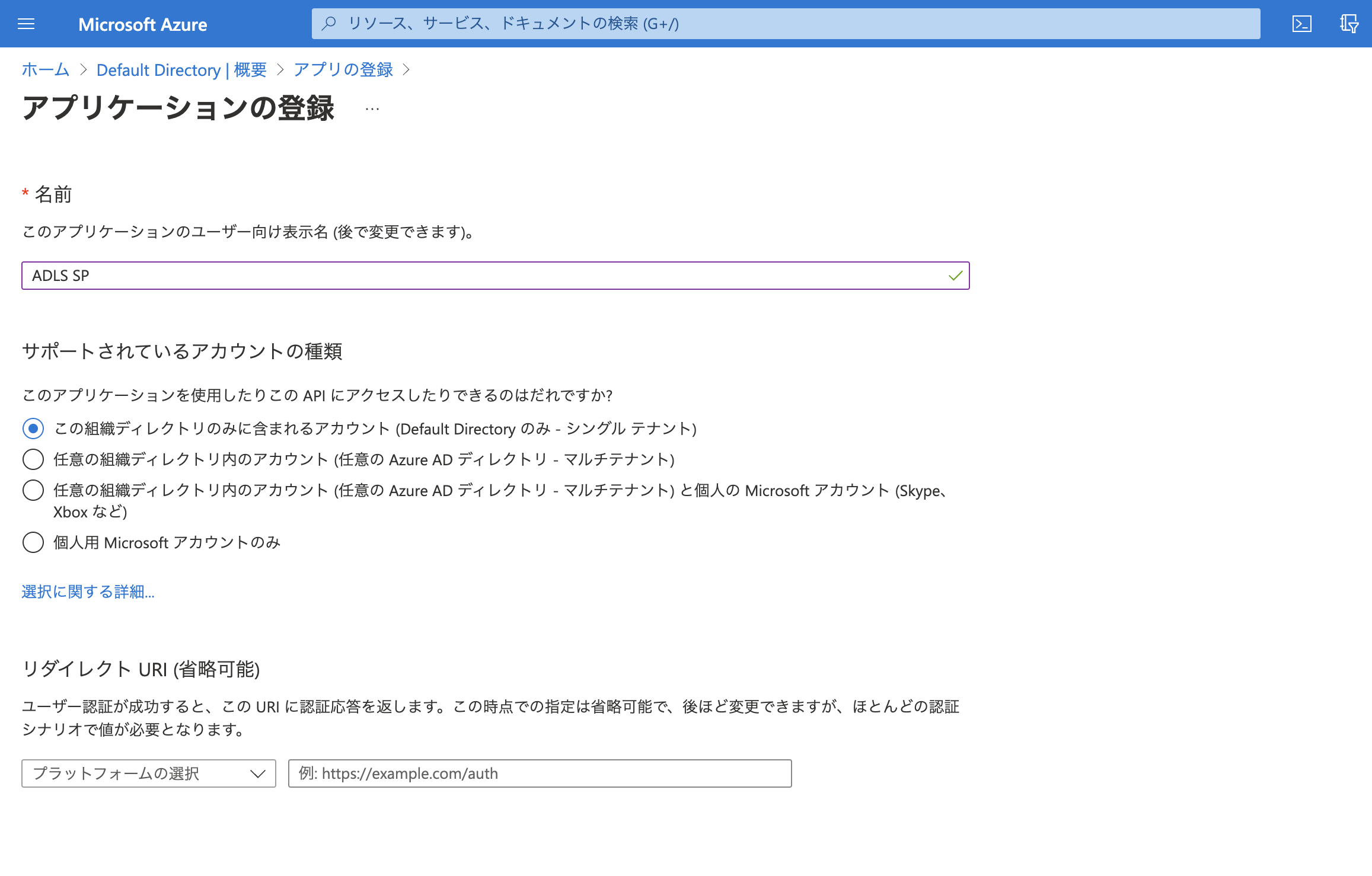
-
アプリケーション (クライアント) IDとディレクトリ (テナント) IDをコピーしておきます。
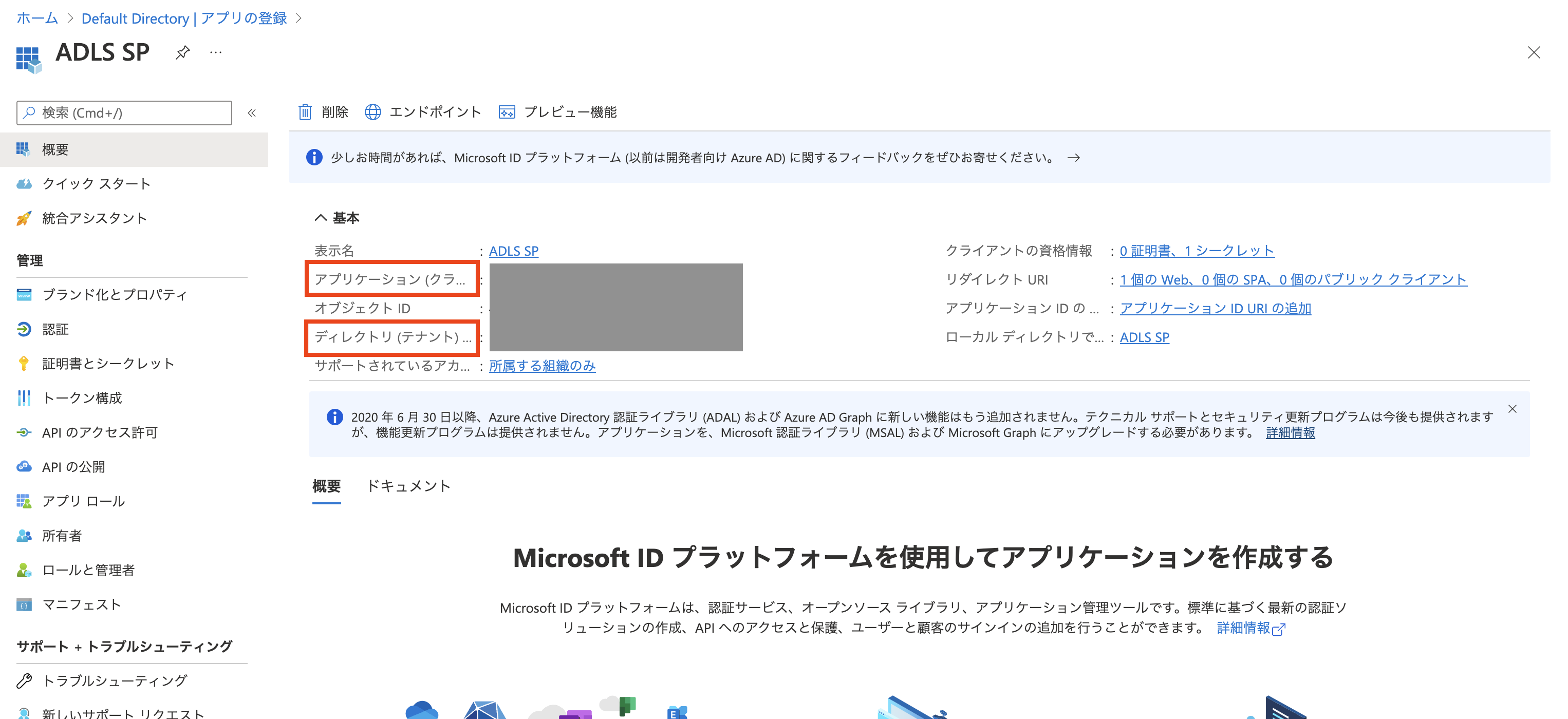
-
クライアントの資格情報をクリックします。新しいクライアントシークレットをクリックしてシークレットを作成します。シークレットの値をコピーしておきます。
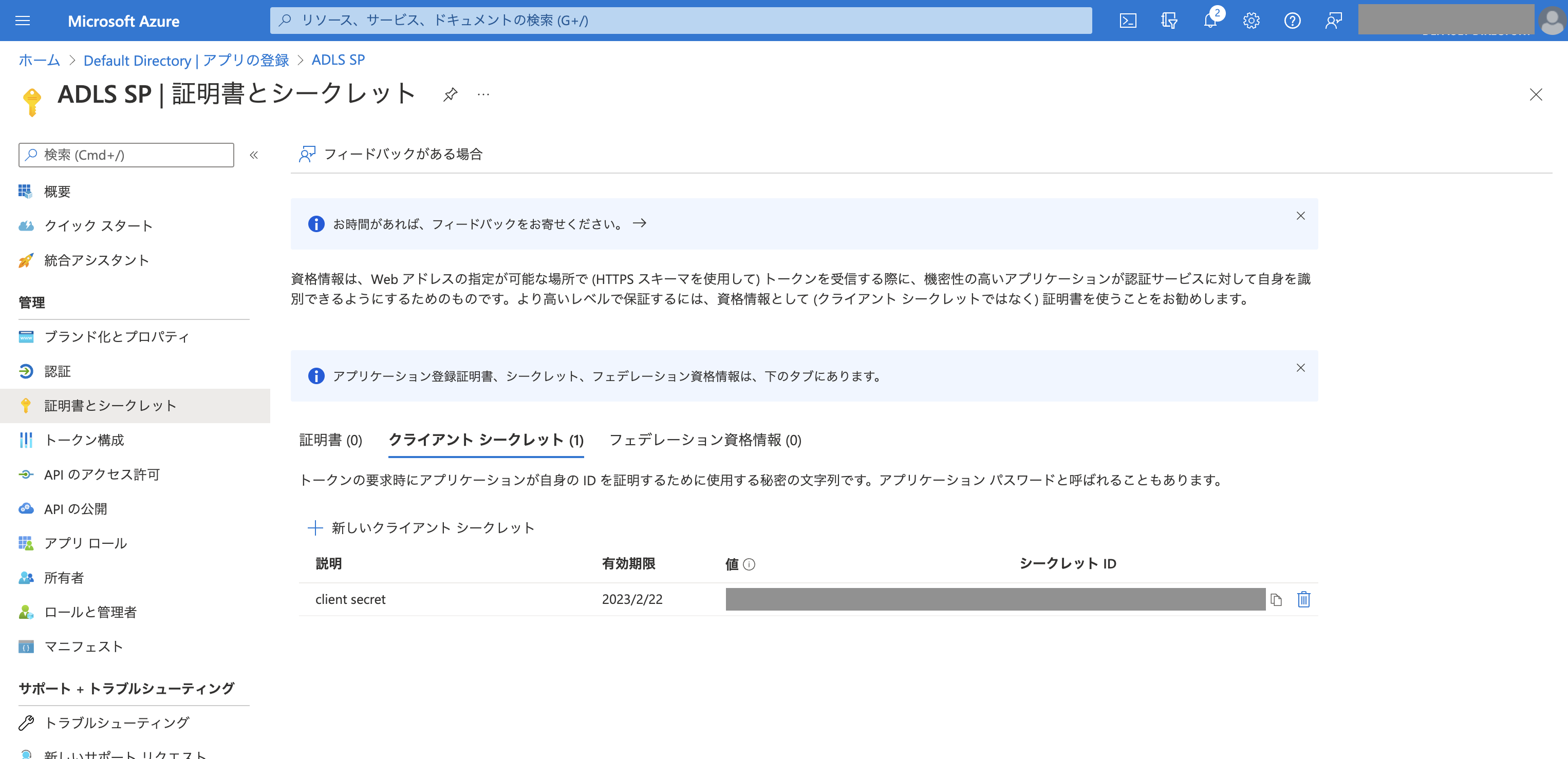
-
リダイレクトURIを設定します。リダイレクトURIをクリックします。
以下の形式でURIを指定します。上で取得したディレクトリ (テナント) IDを埋め込みます。
https://login.microsoftonline.com/<ディレクトリ (テナント) ID>/oauth2/token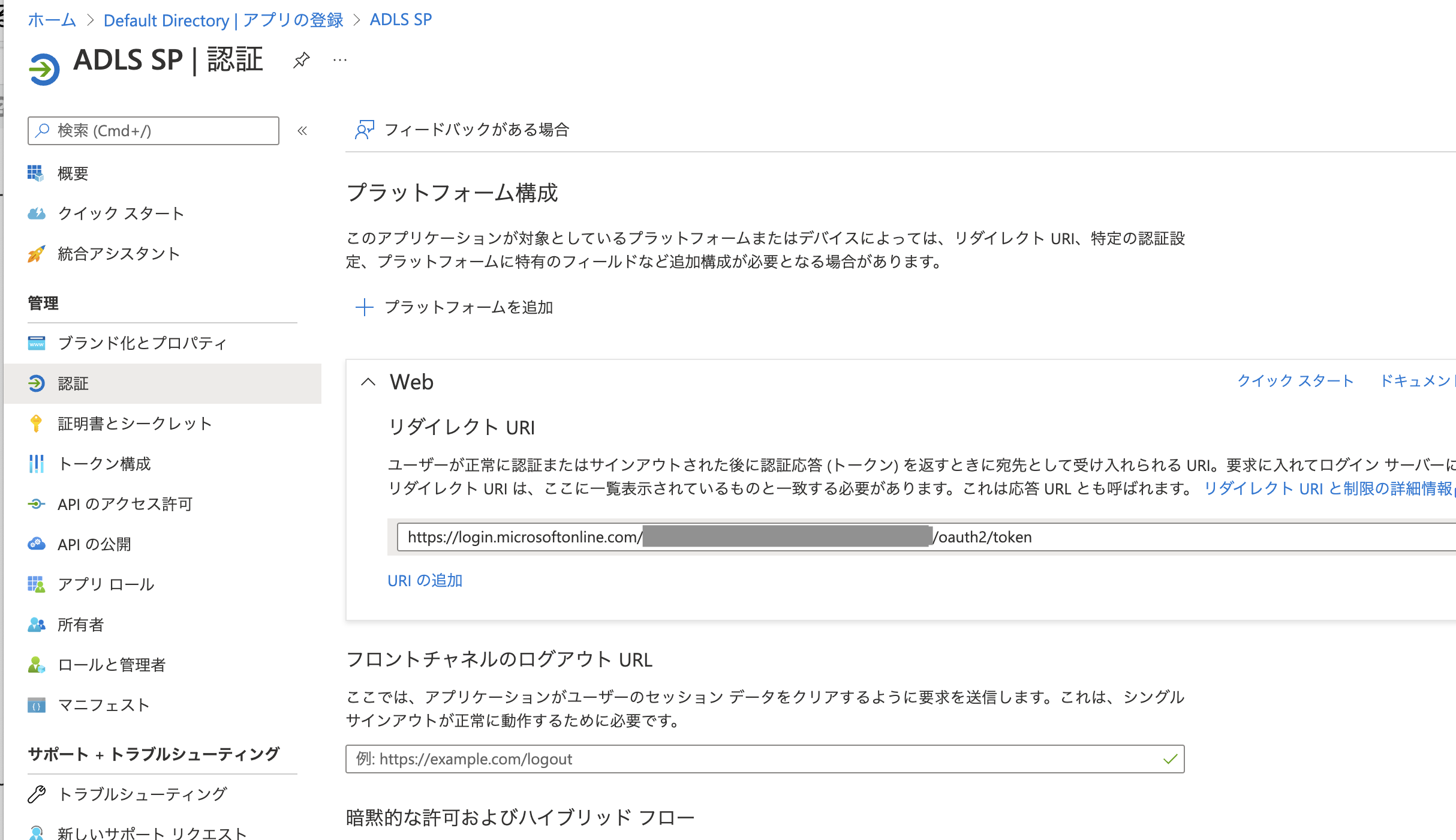
-
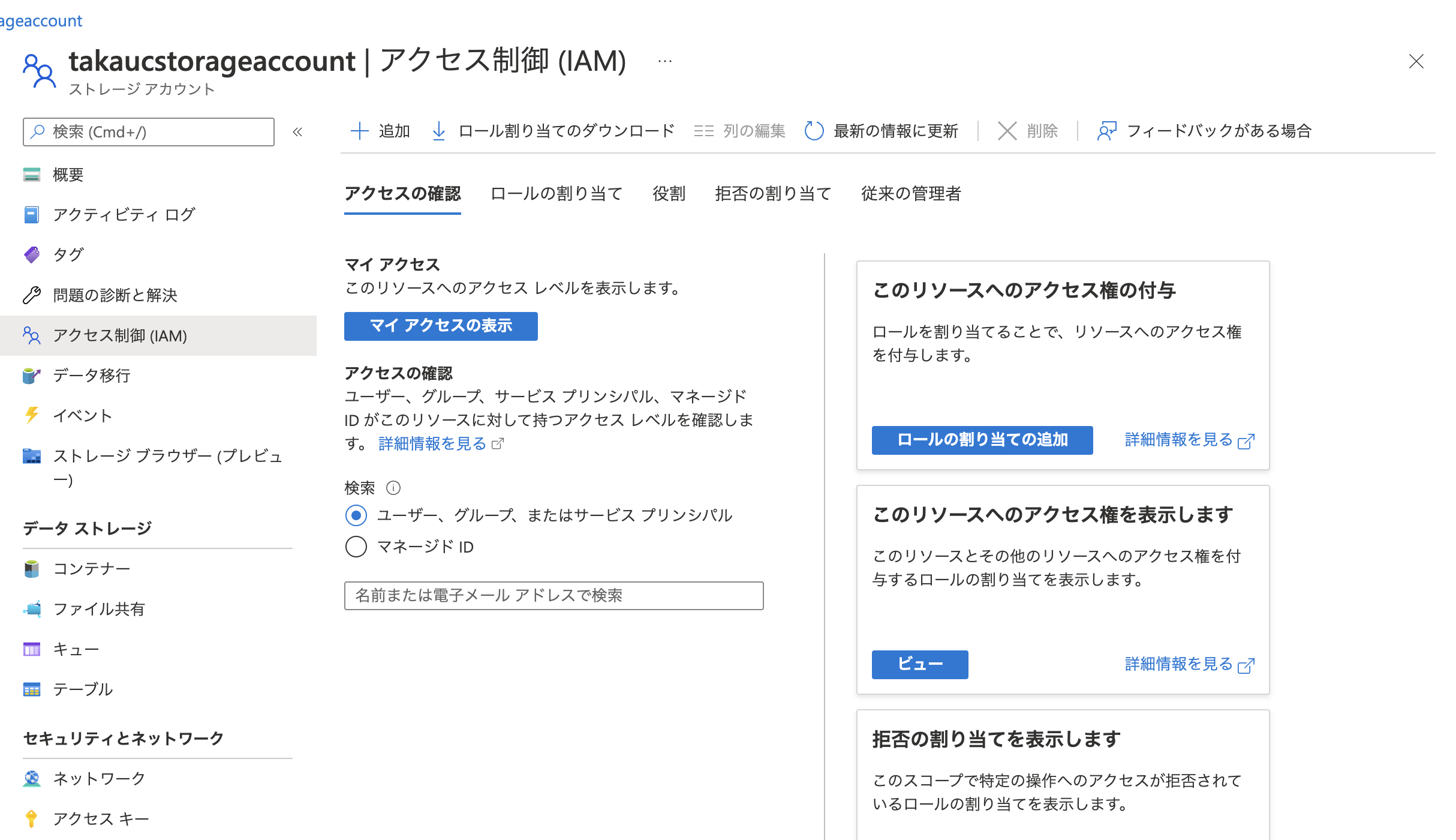
サービスプリンシパルをストレージアカウントに割り当てます。ストレージアカウントに移動しロールの割り当ての追加をクリックします。
-
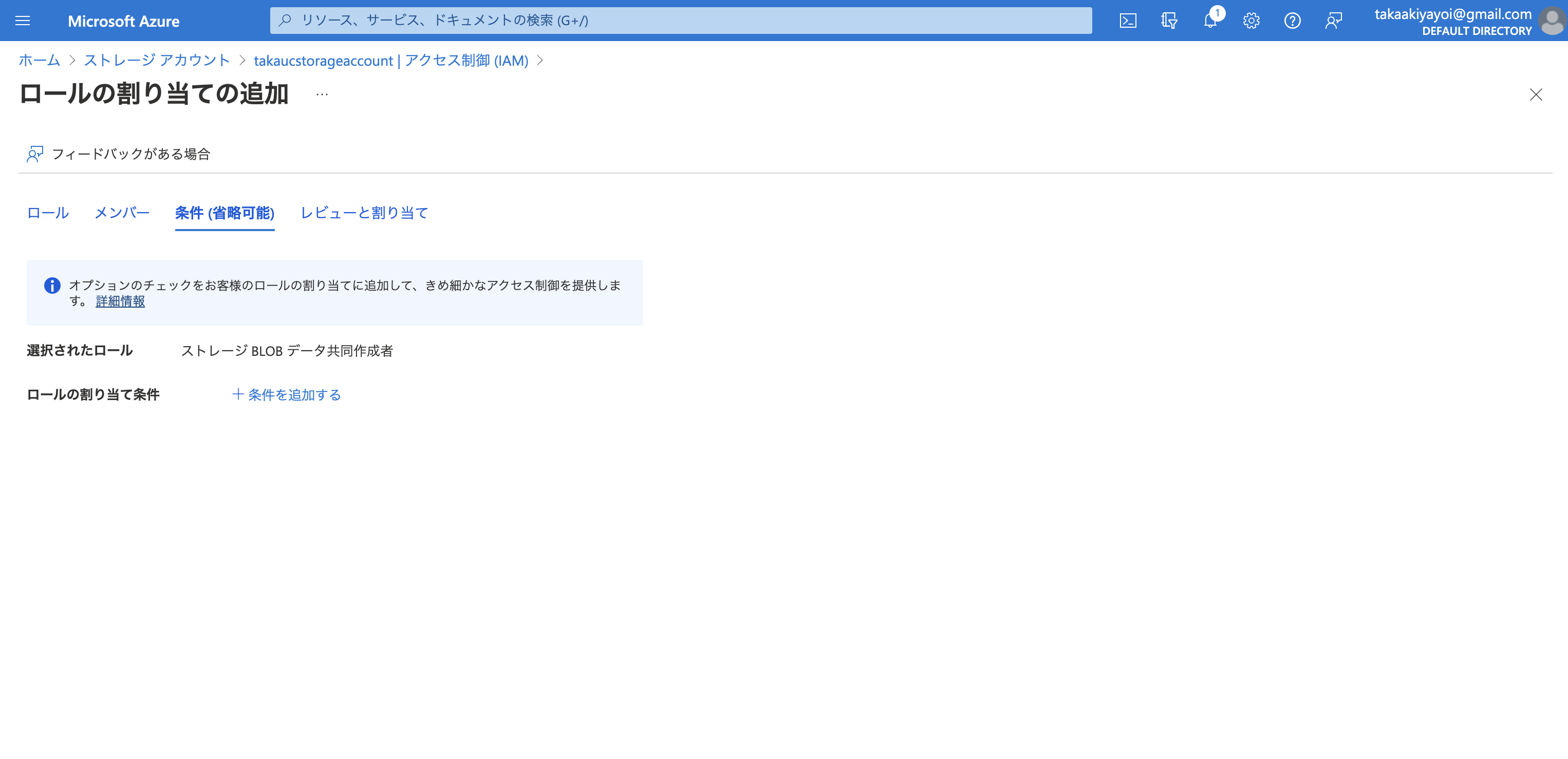
上で作成したサービスプリンシパルをストレージBLOBデータ共同作成者として割り当てます。
認証情報の設定
service_credential = dbutils.secrets.get(scope="<scope>",key="<service-credential-key>")
spark.conf.set("fs.azure.account.auth.type.<storage-account>.dfs.core.windows.net", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type.<storage-account>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id.<storage-account>.dfs.core.windows.net", "<application-id>")
spark.conf.set("fs.azure.account.oauth2.client.secret.<storage-account>.dfs.core.windows.net", service_credential)
spark.conf.set("fs.azure.account.oauth2.client.endpoint.<storage-account>.dfs.core.windows.net", "https://login.microsoftonline.com/<directory-id>/oauth2/token")
-
<scope>をDatabricksシークレット スコープ名に置き換えます。 -
<service-credential-key>をクライアントシークレットを含むキーの名前に置き換えます。 -
<storage-account>はAzureストレージアカウントの名前に置き換えます。 -
<application-id>をAzure Active Directoryアプリケーションのアプリケーション (クライアント) ID に置き換えます。 -
<directory-id>をAzure Active Directoryアプリケーションのディレクトリ (テナント) ID に置き換えます。
SASトークンを用いて認証情報を設定する
Shared Access Signatures (SAS) でデータの制限付きアクセスを付与する - Azure Storage | Microsoft Docsをご覧ください。
アカウントキーを用いて認証情報を設定する
一番お手軽な方法ですが、アカウントキーの取り扱いには注意してください。Azure Databricksシークレットを用いることをお勧めします。
spark.conf.set("fs.azure.account.key.<ストレージアカウント名>.dfs.core.windows.net",
dbutils.secrets.get(scope="<シークレットのスコープ名>", key="<アカウントキーが含まれるシークレットのキー>"))
ファイル一覧を取得する
display(dbutils.fs.ls("abfss://<コンテナー名>@<ストレージアカウント名>.dfs.core.windows.net/adls_data"))

テーブルを作成する
CREATE TABLE default.covid_cases(
Prefecture STRING,
Cases INT,
date_parsed TIMESTAMP
) USING CSV LOCATION "abfss://<コンテナー名>@<ストレージアカウント名>.dfs.core.windows.net/adls_data/japan_cases_20220818.csv" OPTIONS("header" = "True");
このようにABFSドライバーを使うことで、Azure DatabricksからADLS上のデータにアクセスすることができます。