Getting started with NLP using Hugging Face transformers pipelines - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
自然言語処理における進歩は、テキストデータから価値を取り出すというこれまでにないビジネス機会を解放しました。自然言語処理は、テキスト要約、固有表現抽出(人物や場所など)、感情分類、テキスト分類、翻訳、質問回答を含む様々なアプリケーションで活用することができます。多くの場合において、大規模なテキストデータセットを対象に事前にトレーニングされた機械学習モデルから高品質な結果を得ることができます。これらの事前学習済みモデルの多くは、オープンソースとして利用でき、活用は無料です。Hugging Faceはこれらのモデルの一つの偉大な起源となっており、これらのTransformersライブラリは、モデルを適用するための使いやすいツールであり、それらをご自身のデータに適合させることもできます。また、ご自身のデータに対するファインチューニングを用いてこれらのモデルを調整することが可能です。
例えば、サポートチームを持つ企業においては、従業員がサポートケースのキーとなる問題をクイックに評価できるように、人間が読むことができるテキストの要約を提供するために、事前学習済みを活用することができます。また、この企業では自分たちのサポートデータを内部的なタクソノミーに自動的にカテゴリー分けするために、すぐに利用できる基本モデルに基づいて、世界クラスの分類アルゴリズムを容易にトレーニングすることができます。
DatabricksはHugging Faceトランスフォーマーを実行するための優れたプラットフォームです。以前のDatabricksの記事では、事前学習済みモデルの推論とファインチューニングのためのトランスフォーマーの活用を議論しましたが、本書ではレイクハウスでトランスフォーマーを操作する際のパフォーマンスと使いやすさを最適化するために、これらのベストプラクティスを統合します。本書には、これらのベストプラクティスの説明とともにインラインのコードサンプルを含めており、事前学習済みモデルの推論とファインチューニングの完全なサンプルノートブックも提供しています。
事前学習済みモデルの活用
感情分析やテキスト要約のような多くのアプリケーションにおいて、事前学習済みモデルは追加のモデルトレーニングなしにうまく動作します。Hugging Faceトランスフォーマーのパイプラインは、テキストの推論に必要な様々なコンポーネントをシンプルなインタフェースにラッピングします。多くのNLPタスクにおいて、これらのコンポーネントはトークナイザーやモデルから構成されます。パイプラインは、ベストプラクティスをエンコードすることで簡単にスタートできるようにします。例えば、パイプラインは、可能である場合にはGPUの活用を簡単にし、スループット改善のためにGPUに送信されるアイテムのバッチ化を可能とします。
from transformers import pipeline
import torch
# use the GPU if available
device = 0 if torch.cuda.is_available() else -1
summarizer = pipeline("summarization", device=device)
Sparkに推論処理を分散するために、Databrikcsではパイプラインをpandas UDFの中にカプセル化することを推奨しています。Sparkでは、pandas UDFに必要となるすべてのオブジェクトを効果的にワーカーノードに送信するために、ブロードキャストを活用します。また、Sparkは自動でGPUをワーカーに再割り当てするので、シームレスにマルチGPU、マルチマシンを活用することができます。
import pandas as pd
from pyspark.sql.functions import pandas_udf
@pandas_udf('string')
def summarize_batch_udf(texts: pd.Series) -> pd.Series:
pipe = summarizer(texts.to_list(), truncation=True, batch_size=1)
summaries = [summary['summary_text'] for summary in pipe]
return pd.Series(summaries)
summaries = df.select(df.text, summarize_batch_udf(df.text).alias("summary"))
こちらに、バンドEnergy Orchardに関するWikipedia記事のスナップショットに対する要約のサンプルを示します。サマライザーに入力する前にWikipediaのマークアップをクリーンアップしていないことに注意してください。

Energy Orchardに関する生のWikipediaテキスト

サマリーの出力
このセクションでは、Databricksで大規模テキストを処理するために、Hugging Faceトランスフォーマーを使い始めるのがどれだけ簡単なのかをデモンストレーションしました。次のセクションでは、これらのモデルのパフォーマンスをどのようにさらにチューニングできるのかを説明します。
パフォーマンスチューニング
UDFのパフォーマンスチューニングに関しては、2つの鍵となる観点があります。1つ目は、あなたがGPUを効果的に活用したいであろうということであり、これはトランスフォーマーのパイプラインによって、GPUに送信されるアイテムのバッチサイズを変更することで調整が可能です。2つ目はクラスター全体を活用するようにデータフレームを適切にパーティショニングするということです、
あなたのUDFは、batch_sizeを1に設定することですぐに動作するはずです。しかし、これではワーカーで利用できるリソースを効率的に活用していない場合があります。パフォーマンスを改善するために、使用しているモデルやハードウェアに合わせてバッチサイズをチューニングすることができます。ベストなパフォーマンスを見つけ出すために、クラスター上のパイプラインに対して様々なバッチサイズを試すことをお勧めします。詳細は、Hugging Faceドキュメントのパイプラインバッチングとその他のパフォーマンスオプションをご覧ください。クラスターのライブのgangliaメトリクスを参照することで、GPUプロセッサの使用率の「gpu0-util」やGPUメモリー使用率の「gpu0_mem_util」のようなGPUのパフォーマンスを監視することができます。
GPUプロセッサーの使用率

GPUメモリーの使用率
バッチサイズをチューニングするゴールは、GPUの使用率を最大化しつつもCUDA out of memoryエラーに陥らないことにすることです。
お使いのクラスターにおけるハードウェアの使用率を高めるために、Sparkデータフレームの再パーティショニングが必要になるかもしれません。一般的に、(GPUクラスターにおいては)お使いのクラスターにおけるワーカーのGPUの数の倍数あるいは、(GPUクラスターにおいては)ワーカーのコアの数を指定すると実際にはうまく動作します。UDFの活用は、Sparkにおける他のUDFの活用と同じものです。例えば、モデル推論の結果を用いてカラムを作成する際のselect文で使用することができます。
sample = sample.repartition(32)
summaries = sample.select(sample.text, summarize_batch_udf(sample.text).alias("summary"))
MLflowモデルとして事前構築済みモデルをラッピング
MLflowモデルとして事前学習済みモデルを格納することで、バッチ推論やリアルタイム推論のためのモデルのデプロイが非常に容易になります。また、これによってモデルレジストリを通じたモデルのバージョン管理を可能にし、皆様の推論ワークロードのためのモデルロードのコードをシンプルにします。
最初のステップは、パイプラインのために、モデルのロード、GPU利用の初期回、推論関数をカプセル化するカスタムモデルを作成することです。
import mlflow
class SummarizationPipelineModel(mlflow.pyfunc.PythonModel):
def load_context(self, context):
device = 0 if torch.cuda.is_available() else -1
self.pipeline = pipeline("summarization", context.artifacts["pipeline"], device=device)
def predict(self, context, model_input):
texts = model_input.iloc[:,0].to_list() # get the first column
pipe = self.pipeline(texts, truncation=True, batch_size=8)
summaries = [summary['summary_text'] for summary in pipe]
return pd.Series(summaries)
このコードは、上で説明したpandas_udfを作成し、活用することでコードをほぼ並列で実行します。違いの一つは、MLlfowモデルのコンテキストで利用できるファイルからパイプラインがロードされるということです。これは、モデルを記録するさいにMLflowに提供されます。Hugging Faceトランスフォーマーのパイプラインは、ドライバーのローカルファイルにモデルを容易に保存できるようにし、MLflowのpyfuncインタフェースのためにlog_model関数に引き渡されます。
summarizer.save_pretrained("./pipeline")
with mlflow.start_run() as run:
mlflow.pyfunc.log_model(artifacts={'pipeline': "./pipeline"}, artifact_path="summarization_model", python_model=SummarizationPipelineModel())
MLflowモデルを用いたバッチ推論
MLflowは、記録あるいは登録された任意のモデルをspark UDFにロードするための容易なインタフェースを提供します。モデルレジストリや記録されたエクスペリメントランのUIから、モデルのURIを検索することができます。
logged_model_uri = f"runs:/{run.info.run_id}/summarization_model"
loaded_model = mlflow.pyfunc.spark_udf(spark, model_uri=logged_model_uri, result_type='string')
summaries = df.select(df.title, df.text, loaded_model(df.text).alias("summary"))
Hugging Faceトランスフォーマートレーナーを用いたシングルマシンにおけるモデルのファインチューニング
ある時には、事前学習済みのモデルがそのままでは皆様の要件を満たさず、自身のデータに対してモデルをファインチューニングする必要があります。例えば、サポートチケットを皆様のサポートチームのオントロジーに分類するテキスト分類機を基本モデルをベースとして作成したい、あるいはご自身のデータをベースとしたカスタムのスパム分類機を作成したいと考えているものとします。
モデルをファインチューンするためにDatabricksを離れる必要はありません。適度なサイズのデータセットであれば、GPUをサポートしているシングルマシンでこれを行うことができます。Hugging FaceトランスフォーマーのTrainerユーティリティは、モデルトレーニングのセットアップと実行を非常に簡単なものにします。大規模なデータセットに対しては、Databricksはマルチマシン、マルチGPUの分散ディープラーニングもサポートしています。
プロセスは以下のようになります: GPUサポートのあるシングルマシンを作成し、データセットを準備してドライバーにデータセットをダウンロードし、Trainerを用いてモデルトレーニングを実行し、MLflowにモデルを記録します。
データの準備とダウンロード
Trainerの要件を満たすテーブルにご自身のトレーニングデータをフォーマットするところからスタートします。テキスト分類においては、これはテキストのカラムとラベルのカラムの2つのカラムを持つテーブルとなります。サンプルノートブックでは、スパムデータからいくつかのテキストメッセージをロードしています。

Hugging Faceのトランスフォーマーはテキスト分類のためのモデルローダーとしてAutoModelForSequenceClassificationを提供しており、これはカテゴリーのラベルとして整数値のIDを必要とします。しかし、整数値のラベルの文字列のラベルへのマッピングも指定する必要があります。文字列のラベルを持つデータフレームの場合、以下のようにしてこの情報を収集することができます:
labels = sms.select(sms.label).groupBy(sms.label).count().collect()
id2label = {index: row.label for (index, row) in enumerate(labels)}
label2id = {row.label: index for (index, row) in enumerate(labels)}
そして、pandas_udfを用いてラベルのカラムとして整数値のIDを作成します:
from pyspark.sql.functions import pandas_udf
import pandas as pd
@pandas_udf('integer')
def replace_labels_with_ids(labels: pd.Series) -> pd.Series:
return labels.apply(lambda x: label2id[x])
sms_id_labels = sms.select(replace_labels_with_ids(sms.label).alias('label'), sms.text)
データをトレーニング/テストに分割し、ドライバーのファイルシステムからデータを利用できるようにします。これを行う方法の一つは、DBFSルートボリュームやマウントポイントを用いるというものです。
(train, test) = sms_id_labels.persist().randomSplit([0.8, 0.2])
# Write the tables to DBFS.
train_dbfs_path = f"{tutorial_path}/sms_train"
test_dbfs_path = f"{tutorial_path}/sms_test"
train_df = train.write.parquet(train_dbfs_path, mode="overwrite")
test_df = test.write.parquet(test_dbfs_path, mode="overwrite")
マウントされている/dbfsパスを用いて、ドライバーのファイルシステムからこれらのparquetファイルを利用することができます。トレーニングデータセット、評価用データセットを作成するために、Hugging Face Datasetsユーティリティを用いてparquetファイルへのパスを指定することができます。
from datasets import load_dataset
train_test = load_dataset("parquet", data_files={"train":f"/dbfs{train_dbfs_path}/*.parquet", "test":f"/dbfs{test_dbfs_path}/*.parquet"})
このモデルは、ダウンロードされたデータにあるテキストではなく、トークン化された入力を受け付けます。ベースモデルとの互換性を保証するために、ベースモデルからロードされたAutoTokenizerを活用します。HuggingFace datasetsによって、トレーニングデータとテストデータの両方に定常的にトークナイザーを直接適用することができます。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model)
def tokenize_function(examples):
return tokenizer(examples["text"], padding=False, truncation=True)
train_test_tokenized = train_test.map(tokenize_function, batched=True)
トレーナーの構築
Trainerクラスは、メトリクス、ベースモデル、トレーニング設定を必要とします。デフォルトでは、Trainerはメトリックとして損失を計算して使用しますが、これは解釈が困難です。以下に、モデルトレーニングにおける精度を追加で計算するメトリクス関数を作成するサンプルを示します。
import numpy as np
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
テキスト分類においては、テキスト分類のためのベースモデルをロードするためにAutoModelForSequenceClassificationを使用します。以下では、クラスの数とラベルのマッピングを指定しています。
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(base_model, num_labels=2, label2id=label2id, id2label=id2label)
最後に、トレーニング設定を作成しなくてはなりません。TrainingArguments
クラスでは出力ディレクトリ、評価戦略、学習率、その他のパラメーターを指定することができます。
from transformers import TrainingArguments, Trainer
training_output_dir = "sms_trainer"
training_args = TrainingArguments(output_dir=training_output_dir, evaluation_strategy="epoch")
data collatorを用いて、トレーニングデータセットと評価データセットの入力バッチを作成します。デフォルト設定でDataCollatorWithPaddingを用いることで、テキスト分類の優れたベースラインパフォーマンスを実現します。
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer)
これらすべてのパラメーターが構成されたら、Trainerを作成することができます。
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_test_dataset["train"],
eval_dataset=train_test_dataset["test"],
compute_metrics=compute_metrics,
data_collator=data_collator,
)
モデルのトレーニングとロギングの実行
Hugging FaceのインタフェースはMLflowとの親和性があり、MLflowCallbackを用いることで、モデルトレーニングにおけるメトリクスを自動で記録します。しかし、トレーニングしたモデルはご自身で記録する必要があります。上のサンプルと同様に、トレーニングしたモデルをトランスフォーマーパイプラインにラッピングし、MLflowのpyfuncのlog_model機能を用いることをお勧めします。これを行うためには、カスタムモデルクラスが必要となります。
import mlflow
import torch
pipeline_artifact_name = "pipeline"
class TextClassificationPipelineModel(mlflow.pyfunc.PythonModel):
def load_context(self, context):
device = 0 if torch.cuda.is_available() else -1
self.pipeline = pipeline("text-classification", context.artifacts[pipeline_artifact_name], device=device)
def predict(self, context, model_input):
texts = model_input[model_input.columns[0]].to_list()
pipe = self.pipeline(texts, truncation=True, batch_size=8)
labels = [prediction['label'] for prediction in pipe]
return pd.Series(labels)
MLflowランにトレーニングをラッピングし、トークナイザーのトランスフォーマーパイプラインとトレーニング済みモデルを構成し、ローカルディスクに書き込みます。最後に、モデルをMLフローに記録します。
from transformers import pipeline
model_output_dir = "./sms_model"
pipeline_output_dir = "./sms_pipeline"
model_artifact_path = "sms_spam_model"
with mlflow.start_run() as run:
trainer.train()
trainer.save_model(model_output_dir)
pipe = pipeline("text-classification", model=AutoModelForSequenceClassification.from_pretrained(model_output_dir), batch_size=8, tokenizer=tokenizer)
pipe.save_pretrained(pipeline_output_dir)
mlflow.pyfunc.log_model(artifacts={pipeline_artifact_name: pipeline_output_dir}, artifact_path=model_artifact_path, python_model=TextClassificationPipelineModel())
推論でモデルをロードするのは、MLflowでラップされた事前学習済みモデルのロードと同じ方法です。
logged_model = "runs:/{run_id}/{model_artifact_path}".format(run_id=run.info.run_id, model_artifact_path=model_artifact_path)
# Load model as a Spark UDF. Override result_type if the model does not return double values.
sms_spam_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=logged_model, result_type='string')
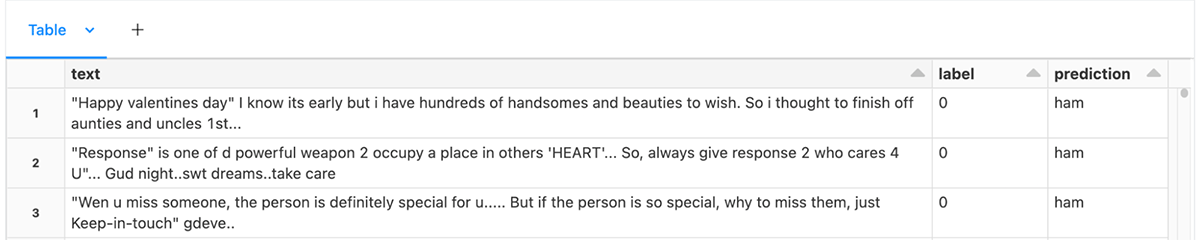
test = test.select(test.text, test.label, sms_spam_model_udf(test.text).alias("prediction"))
display(test)
このセクションでは、新たなテキスト分類問題に対してモデルをファインチューンするために、Hugging Face Transformer Trainer APIをどのように直接活用できるのかをデモンストレーションしました。様々なタスクに対して、様々なNLPモデルをファインチューンすることができ、AutoModel classes for Natural Language Processingは優れた基盤を提供します。
まとめ
このブログ記事では、いくつかのベストプラクティスをデモンストレーションし、Databricks上でNLPタスクにトランスフォーマーを活用し始めるのがどれだけ簡単なのかを説明しました。
推論で思い出すべきキーポイントは:
- Hugging Faceトランスフォーマーパイプラインは、トランスフォーマーモデルの活用を容易にします。
- クラスターの使用率を最大化するために、必要に応じてデータの再パーティショニングを行います。
- GPUを効率的に活用するようにバッチサイズをチューニングすることができます。
- Sparkは自動でマルチマシンGPUlクラスターにGPUを割り当てます。
- Pandas UDFはモデルのブロードキャストとデータのバッチを管理します。
- パイプラインはMLflowへのトランスフォーマーモデルの記録をシンプルにします。
シングルマシンのモデルトレーニングに関して思い出すべきキーポイントは:
- Hugging FaceトランスフォーマーのTrainerはモデルをファインチューンする際にアクセスする手段を提供します。
- Sparkでデータを準備し、モデリングのタスクにおいては必要に応じて任意のラベルをIDにマッピングし、トークン化はHugging Faceトランスフォーマーに任せます。
- ドライバーのファイルシステムからデータセットを利用できるようにします。
- モデルに適したトークナイザーをロードするためにAutoTokenizerを用いてデータセットをトークン化します。
- ファインチューニングするためにTrainerを活用します。
- トークナイザーとファインチューニングされたモデルからパイプラインを構成します。
- パイプラインをラッピングするカスタムモデルを用いてMLflowにモデルを記録します。
Databricksにおけるモデルトレーニングと推論をスケールするよりシンプルな方法に、我々は投資を行なっていきます。データロード、分散モデルトレーニング、MLflowモデルとしてHugging Faceトランスフォーマーパイプラインとモデルの記録に関する改善点を楽しみにしていてください。
これらのサンプルをスタートするには、事前学習済みモデルとファインチューニングを用いてこれらのノートブックをインポートしてください。