Rapid NLP Development With Databricks, Delta, and Transformers - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
自由記述のテキストデータは、構造化データの領域では利用できないアクション可能な洞察を提供することができます。保険会社は、他の方法では知ることができない主訴の特性を理解するために、主訴を調整する担当者のノートを活用するかも知れません。IT部門は、サポートチケットのリクエストを適切な専門チームにルーティングするために、効率的にチケットを解析するかも知れません。自由記述のテキストからこのレベルの価値を生成することは困難となることがありますが、トランスフォーマーモデルと呼ばれる一連のモデルは、企業のデータサイエンス実践者が容易に活用できる強力なツールセットを提供しています。
トランスフォーマーモデルは、これまでの手法よりも効果的かつ効率的にテキストのセマンティックを捕捉するセルフアテンションというニューラルネットワークアーキテクチャを活用しています。また、これらは、モデルの開発者によってmasked language modelingやnext sentence predictionのようなテクニックを用いて大規模テキストコーパスによってトレーニングされたことを意味する転送学習という形態を取ります。このモデルは、本書の焦点であるテキスト分類を含む様々な後段のタスクで使用することができる、ワードエンベディングを生成するように設計されています。
本書では、トランスフォーマーモデルのハイレベルの概要と、これらをトレーニングする際の検討事項を説明します。実装の詳細やDelta LakeやマネージドMLflowとのインテグレーションに関しては、ソリューションアクセラレータを参照ください。
トランスフォーマーを使い始める
Hugging Faceはトランスフォーマーモデルを発見・アクセスしやすくすることにフォーカスしている企業です。多様なモデルやデータセットへのアクセスを提供しています。Hugging Faceによってメンテナンスされているtransformersライブラリを用いることで、お使いのDatabricksワークスペースでアーティファクトをダウンロードし、使用することができます。このライブラリはDatabrikcs機械学習ランタイムバージョン10.4以降に含まれており、それより新しいバージョンではpipでインストールすることができます。
ライブラリを使い始めるには、Hugging Faceのモデルハブからbert-base-uncasedのようなトランスフォーマーのアーキテクチャを選択します。そして、トークナイザーとモデルをダンロードするために以下のコードを実行します。
from transformers import AutoTokenizer, AutoModel
model_type = 'bert-base-uncased'
tokenizer = AutoTokenizer.from_pretrained(model_type)
model = AutoModel.from_pretrained(model_type)
トークナイザーによるデータの前処理
トークナイザーはいくつかの前処理ステップを実行します。最初に、テキストをトークンに分割し、トークンをモデルのボキャブラリーにマッピングします。BERTのボキャブラリは、単語、単語の断片、数字、句読点や記号の30,522エントリーから構成されています。また、モデルには観測の開始地点([CLS])や文の区切り([SEP])のような情報を捕捉する特殊なトークンが含まれています。
from itertools import islice
# Display the first five entries in BERT's vocabulary
for token, token_id in islice(tokenizer.vocab.items(), 5):
print(token_id, token)

# Display BERT's special tokens
for token_name, token_symbol in tokenizer.special_tokens_map.items():
print(token_name, token_symbol)

BERTのボキャブラリのトークンIDとトークン、特殊なトークン
「Databricks」のようにBERTのボキャブラリに存在しないトークンは、マッチするように断片に分割されます。
token_ids = tokenizer.encode("transformers on Databricks are awesome")
Token_ids

# Map token ids to BERT's tokens
id_to_token = {token_id: token for token, token_id in tokenizer.vocab.items()}
[id_to_token[id] for id in token_ids]

トークン化されたシーケンスは、BERTのボキャブラリーや特殊なトークンにマッピングし直すことができるトークンIDのリストを生成します。
また、トークナイザーは入力シーケンスの切り取りとパディングを行います。それぞれのモデルには、許容できるトークン化シーケンスの最大長を持っています。BERTや多くの他のモデルでは、その長さは512トークンです。入力テキストをトークン化する際、最初の512トークン以降に生成されたすべてのトークンは削除、あるいは「切り取られ」ます。
さらに、トークンのシーケンスは「パディング」されます。トランスフォーマーモデルは、一度のすべてのトレーニングデータセットに対してトレーニングするのではなく、データのバッチに対してトレーニングされます。それぞれのバッチは同じ長さである必要がありますが、観測されるテキストの長さは大きく異なります。トークン化されたあるシーケンスは512要素よりもはるかに長いかも知れませんし、他のものははるかに短いかもしれません。均一な長さにする必要がある際、パディングによってトークン化されたシーケンスにゼロが追加されます。ゼロの値はBERTのボキャブラリの特殊トークンである[PAD]を表します。
records = ["transformers are easy to run on Databricks",
"transformers can read from Delta",
"transformers are powerful"]
def tokenize(batch):
"""
Truncate to the max_length; pad any resulting sequences with
length less than max_length
"""
return tokenizer(batch, padding='max_length', truncation=True, max_length=10, return_tensors="pt")
tokenized = tokenize(records)
tokenized_lengths = [len(sequence) for sequence in tokenized['input_ids']]
print("Tokenized and padded sequences")
for sequence in tokenized['input_ids']:
print(sequence)
print(f"\nTokenized sequence lengths\n{tokenized_lengths}")

同じ処理ステップでトークン化されパディングされたテキストシーケンス
トークナイザーの切り取りとパディングの挙動は設定可能であり、テストし比較することができる様々な戦略が存在します。トレーニング時間を短縮するために切り取りを行いますが、より長いシーケンスが一般的である場合、情報の損失によって予測パフォーマンスの妨げになることがあります。優れた汎用的な戦略としてdynamic paddingを検討してください。このテクニックはトークン化ではなくモデルトレーニングの際にシーケンスをパディングします。ダイナミックパディングは、バッチで最長の長さにそれぞれのバッチをパディングし、パディングされるトークンの数が最小になるように維持します。
ワードエンベディングを用いたテキスト分類
トークン化されたテキストは、ワードエンベディングを生成するために直接入力することができ、特殊トークンを含むそれぞれの入力トークンに対して一つのエンベディングを生成します。これらのエンベディングは様々な自然言語処理タスクで使用することができます。
import torch
with torch.no_grad():
token_embeddings = model(input_ids = tokenized['input_ids'],
attention_mask = tokenized['attention_mask']).last_hidden_state
sequence_length = [len(embedding_sequence) for embedding_sequence in token_embeddings]
cls_embedding = token_embeddings[0][0]
embedding_dim = cls_embedding.shape[0]
print(f"\nEmebdding sequence lengths\n{sequence_length}")
print(f"\nDimension of a single token embedding\n{int(embedding_dim)}")

モデルの最後のレイヤー(最後の隠し状態)で生成されたエンベディングの長さと次元
例えば、テキスト分類においては、それぞれの観測事項の特殊トークン[CLS]に関連づけられたエンベディングのみを使用するのが一般的です。このエンベディングは、テキストを一連のユーザー定義カテゴリーに分類するフィードフォワードニューラルネットワークに入力されます。トランスフォーマーライブラリは、AutoModelForSequenceClassificationクラスを通じてこのアーキテクチャをすぐに使用できるように実装しています。このクラスによって、ユーザーはトランスフォーマーのモデル名とモデルのニューラルネットワークのレイヤーの最後にアタッチされるclassification headを指定することができます。そして、シンプルに分類するラベルの数を指定します。例として、Hugging Faceのデータハブで利用できるbanking77 datasetには、銀行に関する質問が77の意図に分類されています。このため、モデルのnum_labelsパラメーターは77に設定されます。
from transformers import AutoModelForSequenceClassification
sequence_classification_model = AutoModelForSequenceClassification.from_pretrained(model_type, num_labels=77)
sequence_classification_model.classifier

マルチクラス分類のために分類ヘッドが追加されたBERTトランスフォーマーモデル
そして、このモデルはトレーニングデータセットに対してファインチューンされます。トレーニングにおいては、エンベディングや分類ヘッドを生成するレイヤーを含むネットワークのすべてのレイヤーで学習可能なパラメーターがアップでオートされます。このファインチューニングされたモデルから、予測ラベルと確率を生成することができます。
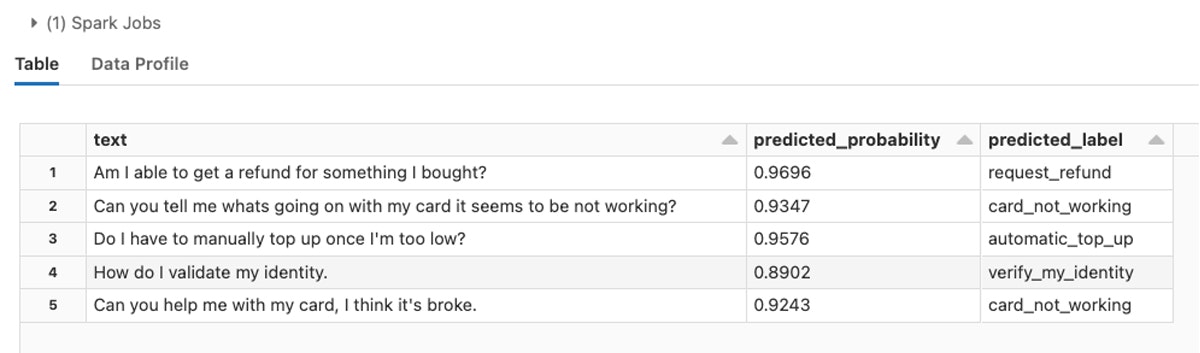
banking77データセットに対してファインチューンされたトランスフォーマーモデルから生成された予測結果
banking77データセットなどを用いたモデルトレーニングの実装の詳細についてはsolution acceleratorをご覧ください。
トランスフォーマーモデルの最適化
トランスフォーマーモデルは、トレーニングし推論に適用するには大規模で膨大な計算量を必要とします。本書で議論しているBERTモデルは、1.1億の学習可能なパラメーターを有しています。より最近のアーキテクチャのいくつかはさらに大規模なものとなっています。極端な例ではGPT-3は1750億のパラメーターがあります。幸運なことに、モデルのトレーニング時間を削減し、推論をスピードアップする方法があります。
モデルのファミリーにdistilled models(蒸留モデル)というものがあり、これは大規模なモデルである「教師」を小規模なバージョンである「生徒」に圧縮することで、モデルのサイズと計算処理の複雑度を削減します。Hugging Faceモデルハブにおいては、通常これらのモデルの名前にはdistilが含まれており、distilbert-base-uncasedといったものとなります。蒸留モデルはよりクイックにファインチューンし、大規模な教師よりも高速に推論を行うことができます。以下のエクスペリメントでは、映画のレビューと感情を含むIMDB datasetに対するモデルを比較しています。モデルサイズ、GPUメモリー消費、トレーニング時間、すべての評価用データセットのスコアリングに要した時間の大きな違いに注意してください。興味深いことに、予測パフォーマンスはモデル全体で大きな違いはありません。
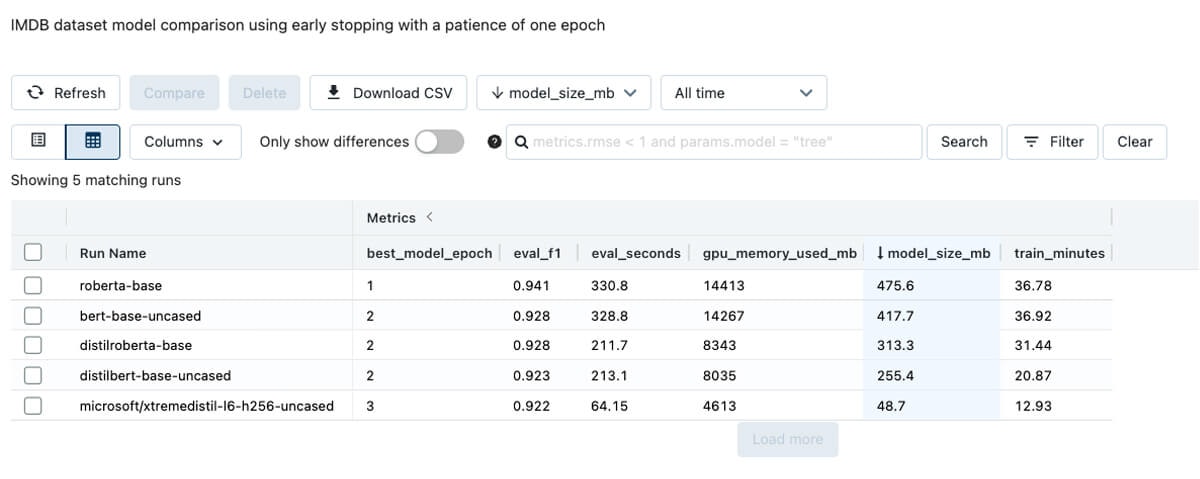
デフォルトのトランスフォーマートレーナー引数とバッチサイズ16でトレーニング、評価を行った際のモデルの比較。
蒸留の他に、トレーニングの設定とGPUタイプは大きなインパクトをもたらします。ファインチューニングのプロセスを管理するトランスフォーマーのTrainerクラスの設定を調整することで、トレーニングと推論の時間を劇的に削減することができます。IMDBデータセットに対してモデルのファインチューニングを行う際、バッチサイズやトレーニングにおける数値精度、勾配集積ステップに関係する設定の調整は、単一のトレーニングエポックにおけるトレーニングと推論の時間の大きな削減につながりました。
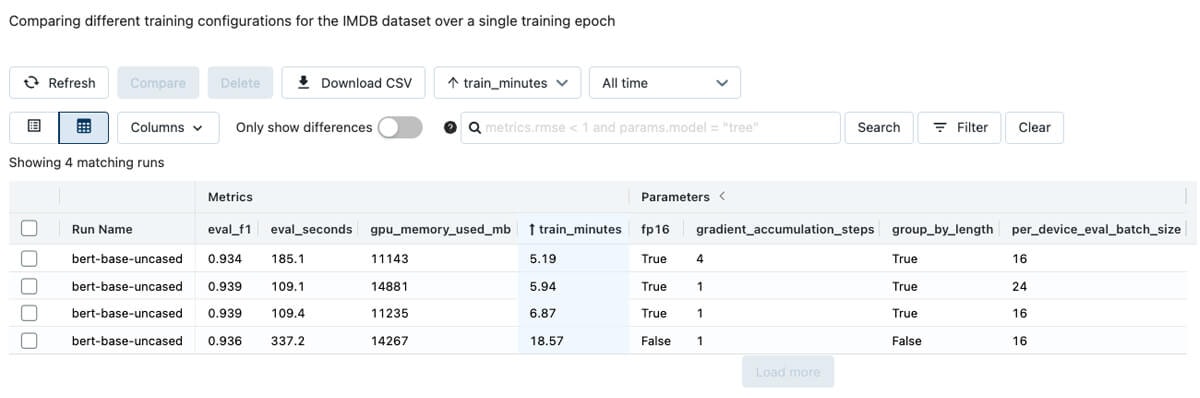
単一エポックにおいて異なるトレーニング設定の比較
さらに、GPUタイプの選択はトレーニングと推論の時間にインパクトを与えます。
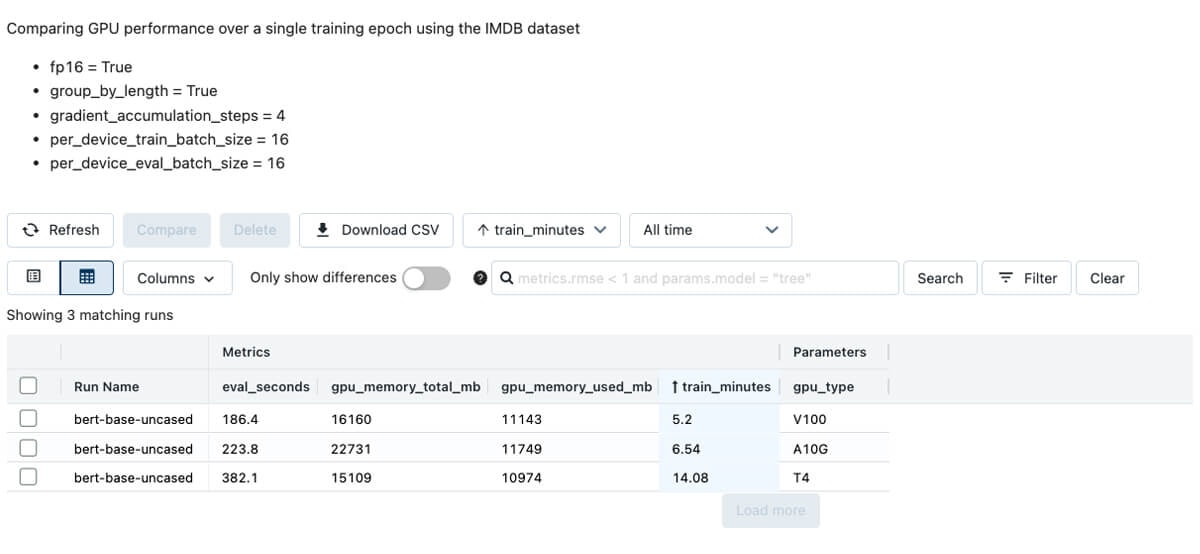
IMDBデータセットに対してNVIDIA V100 GPUタイプは最も速いトレーニングを実現しますが、最も高価です。
GPUインスタンスはトレーニングに必要で、推論も劇的に高速化しますが、GPUの推論はオプションです。CPUによる推論を加速するには量子化と蒸留モデルの使用を検討してください。量子化は、推論のレーテンシーを削減するために、高速でより精度の低い数値表現を使用します。これは、ファインチューンされたトランスフォーマーモデルに容易に適用することができます。
import torch
import torch.nn as nn
from torch.quantization import quantize_dynamic
quantized_model = quantize_dynamic(trainer.model.to("cpu"),
{nn.Linear},
dtype=torch.qint8)
banking77データセットに対してファインチューンされたdistilbert-base-uncasedモデルの線形レイヤーを量子化することで、サイズを約半分にすることができました。CPUによる推論のレーテンシーは2/3に削減され、テストデータに対するモデルのF1スコアは0.01減少しただけでした。
事前トレーニングおよび事前ファインチューン
あるケースにおいては、すぐに利用できるオプションがすでにそんざいしているので、テキスト分類モデルのファインチューニングが不要というケースがあります。例えば、distilbert-base-uncased-finetuned-sst-2-englishモデルは、テキストと感情のカテゴリを含むSST-2 datasetに対してファインチューニングされた事前トレーニング済みのモデルから構成されています。このモデルとトークナイザーは、パイプラインの形態でロードすることができ、追加のトレーニングなしに生のテキストに直接適用することができます。以前のブログ記事ではこのトピックにディープダイブしています。
from transformers import pipeline
sentiment_pipeline = pipeline('sentiment-analysis')
records = ["Transformers on Databricks are the best!",
"Without Delta, our data lake has devolved into a data swamp!"]
for prediction in sentiment_pipeline(records):
print(prediction)

ファインチューンされた分類パイプラインから感情を予測
まとめ
トランスフォーマーはパワフルかつアクセス可能で、Databricksレイクハウスプラットフォームはモデルのファミリーのトレーニングと管理に優れています。Delta Lakeは効率的かつ高精度な機械学習や分析のデータ基盤を提供します。フレンドリーなユーザーインタフェースを通じて、GPUインスタンスや機械学習ランタイムを含むクラスターを配備する柔軟性は、データサイエンティストによるトランスフォーマーのトレーニングを強力に支援します。また、異なるモデルやトレーニング設定による実験は、マネージドMLflowによって容易に管理されます。結果はクリアにドキュメント化され共有可能となり、作業内容が失われることは決してなく、最終モデルを容易にデプロイすることができます。
トランスフォーマーモデルのトレーニングと比較をスタートするには、このリポジトリをRepoとしてお使いのDatabricksワークスペースにクローンしてください。