GPU-accelerated Sentiment Analysis Using Pytorch and Huggingface on Databricks - The Databricks Blogの翻訳です。
感情分析は、レビュー、メール、ツィートなどのテキスト本体で表現される感情を分析するために一般的に用いられます。この様な分析を行うために、ディープラーニングベースの技術を用いるのが最も人気のある方法です。しかし、これらの技術は非常に計算資源を必要とし、アーキテクチャ、使用されるエンべディングに依存しますが、多くのケースでGPUを使用する必要が出てきます。Huggingface( https://huggingface.co/ )は、これらのエンべディングをシームレスかつ再現可能な形でアクセスできる様にする、トランスフォーマーのパッケージに関するフレームワークをまとめ上げています。ここでは、PyTorchの中でHuggingfaceパッケージを用い、DatabricksのMLランタイムとインフラストラクチャを活用して、どのようにスケーラブルな感情分析を行うのかを説明します。
感情分析
感情分析は、ユーザーの感情の極性(ドキュメントによるとユーザーはポジティブな感情を持っているのか、ネガティブな感情を持っているのか)を推定するプロセスです。感情には、ユーザーがトピックに対して、強いポジティブな感情もネガティブな感情も持っていない、3つ目のニュートラルなカテゴリも存在します。感情分析は、意見のマイニングの一形態であり、特定の側面や機能に対するユーザーのスタンスを抽出するスタンス、側面検知とは異なります。
例えば、以下の文章における感情は極度にポジティブと言えます。
「レストランは素晴らしかった」
しかし、以下の文章を考えてみましょう。
「レストランは素晴らしかったが、場所はもう少しいい場所が良かったな」
感情を推察することは困難になりますが、場所に関するスタンスはネガティブであったとしても、レストランに対するユーザーのスタンスは全体的にポジティブであると言えます。まとめると、スタンス検知は、特定の側面に対する多くの情報を提供しますが、感情分析は粗い粒度の情報を提供します。
感情分析は、特定の製品、イベントに対する公衆の反応に関する顧客の感情を確認するために用いられます。
感情分析のタイプ
感情分析は、用語ベースの技術、あるいは機械学習ベースの技術を用いて実行されます。用語ベースの技術は、事前にラベル付けがされた語彙を用いて、テキストから感情を推定します。トークン化された単語に割り当てられる個々の感情から、感情を集約するために数多くの技術が使用されます。この分野における有名なフレームワークのいくつかには、SentiNet、AFINNがあります。NLTKを伴うオープンソースパッケージである、VADERは、特にソーシャルメディアのポストを分析するために使用されます。機械学習ベースの感情分析は、テキストの感情を推論するために、ディープラーニング(DL)アーキテクチャと事前学習済みエンベディングを用います。この記事では、Huggingfaceで利用できるエンベディングを通じて、MLベースの技術のみをカバーします。データに対するドメイン固有のラベルを利用できる場合、アーキテクチャとエンベディングから構成される感情分析モデルをファインチューニングすることができます。小規模のラベル付きデータしか利用できない場合であっても、このような教師あり学習を改善できるケースは多くあります。Elmo、BERT、Robertaのようなエンベディングは、この様な目的で使用する言語エンベディングで人気があるものです。
トランスフォーマーのご紹介
Huggingfaceはモデルの利用、共有のプロセスを標準化する狙いで使用できるフレームワークを生み出しました。使いやすいAPIを通じて、様々な異なるモデルを用いた実験を容易なものにします。トランスフォーマーパッケージはPytorchとTensorflowの両方で使用できますが、この記事ではPythonライブラリのPytorchを使用します。トランスフォーマーパッケージを用いて推論を実行する最も簡単な方法を以下に示します。
from transformers import AutoModelForSequenceClassification
from transformers import AutoTokenize
MODEL = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
model = AutoModelForSequenceClassification.from_pretrained(MODEL)
tokenized_text = tokenizer(["Hello world"], padding=True, return_tensors='pt')
output = model(tokenized_text['input_ids'])
pt_predictions = nn.functional.softmax(output.logits, dim=1)
上の例を見ると、トークナイザーとモデルクラスをインポートしていることに気づきます。BERTのような事前学習済みモデルを指定することで、これらをインスタンス化することができます。こちらからモデルを検索することができます。トークン化するために一連の文字列をトークナイザに引き渡し、結果はパディングされ、Pytorchのテンソルとして返却すべきであることを指定できます。トークン化された結果は、エンコードされたテキストを抽出し、モデルに引き渡すオブジェクトとなります。感情スコアとして結果を正規化する感情分析の場合には、モデルの結果はsoftmaxレイヤーに引き渡されます。
(マルチ)GPUインタフェース
推論のプロセスは以下のコンポーネントから構成されます。
- トークン化されたデータバッチをサーブするDataloader
- 推論を実行するモデルクラス
- GPUデバイスにおけるモデルの並列化
- 推論、結果の抽出のためにデータに対するイテレーションを実行
Dataloader
Pytorchは、トレーニング、推論のために用いるデータのバッチを抽出するためにDataloader抽象化を用います。Datasetクラスを拡張するクラスオブジェクトを入力として受け取ります。ここではクラスTextLoaderを呼び出します。このクラスには最低2つのメソッドが必要となります。
-
__len__(): データ全体の長さを返却 -
__getitem__(): 単一のデータ要素を抽出し返却
MODEL = "distilbert-base-uncased-finetuned-sst-2-english"
class TextLoader(Dataset):
def __init__(self, file=None, transform=None, target_transform=None, tokenizer=None):
self.file = pd.read_json(file, lines=True)
self.file = self.file
self.file = tokenizer(list(self.file['full_text']), padding=True, truncation=True, max_length=512, return_tensors='pt')
self.file = self.file['input_ids']
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.file)
def __getitem__(self, idx):
data = self.file[idx]
return(data)
これで、Dataloaderは、一度のイテレーションでロードされるデータのバッチサイズとともに、ここではdataと名付けられたクラスのオブジェクトインスタンスを受け付けます。ここでは、データの並び順を保持したいため、shuffle フラグをFalseに設定していることに注意してください。
Dataloaderは、それぞれのGPUデバイスで使用するために受け取るデータの分割を自動で執り行いまうs。データが均等に分割できない場合には、要素をドロップするか、重複するデータポイントでバッチをパディングするオプションを提供します。これは特に、推論、予測プロセスの際に心に留めておくことになるかもしれません。
tokenizer = AutoTokenizer.from_pretrained(MODEL)
data = TextLoader(file=file = ‘/PATH_TO/FILE.txt', tokenizer=tokenizer)
train_dataloader = DataLoader(data, batch_size=120, shuffle=False) # Shuffle should be set to False
モデルクラス
モデルクラスは、上で見たコードと非常に似たものとなります。唯一の違いはnn.moduleクラスでラッピングされているということです。モデル定義は、__init__で初期化され、forwardメソッドでHuggingfaceからロードされたモデルを適用します。
class SentimentModel(nn.Module):
def __init__(self):
super(SentimentModel, self).__init__()
self.model = AutoModelForSequenceClassification.from_pretrained(MODEL)
def forward(self, input):
output = self.model(input)
pt_predictions = nn.functional.softmax(output.logits, dim=1)
return(pt_predictions)
model3 = SentimentModel()
モデル並列化およびGPUディスパッチ
Pytorchでは、作成されたモデルや変数は明示的にGPUに対してディスパッチされる必要があります。これは、.to('cuda')メソッドを用いてのみ実行可能です。複数のGPUがある場合には、.to(cuda:0)として、デバイスIDを指定します。さらに、データ、トレーニング実行の並列化や、お使いのクラスターにおけるGPUデバイスにまたがる推論のメリットを享受するためには、モデルをDataParallelでラッピングする必要があります。
このコードでは、お使いのクラスターに1つ以上のGPUがあることを想定していますが、そうでない場合に必要な変更はdevice_idsを[0]に変えるか、シンプルにこのパラメーターを指定しない(デフォルトのGPUデバイスIDは自動で選択されます)ということだけです。
dev = 'cuda'
if dev == 'cpu':
device = torch.device('cpu')
device_staging = 'cpu:0'
else:
device = torch.device('cuda')
device_staging = 'cuda:0'
try:
model3 = nn.DataParallel(model3, device_ids=[0,1,2,3])
model3.to(device_staging)
except:
torch.set_printoptions(threshold=10000)
イテレーションループ
以下のループでは、データバッチに対するイテレーションを行い、データをモデルに引き渡す前に、GPUデバイスにデータを転送します。結果はデータストアにエクスポートできる様に結合されます。
out = torch.empty(0,0)
for data in train_dataloader:
input = data.to(device_staging)
if(len(out) == 0):
out = model3(input)
else:
output = model3(input)
with torch.no_grad():
out = torch.cat((out, output), 0)
file = '/PATH_TO/FILE.txt'
df = pd.read_json(file, lines=True)['full_text']
res = out.cpu().numpy()
df_res = pd.DataFrame({ "text": df, "negative": res[:,0], "positive": res[:,1]})
display(df_res)
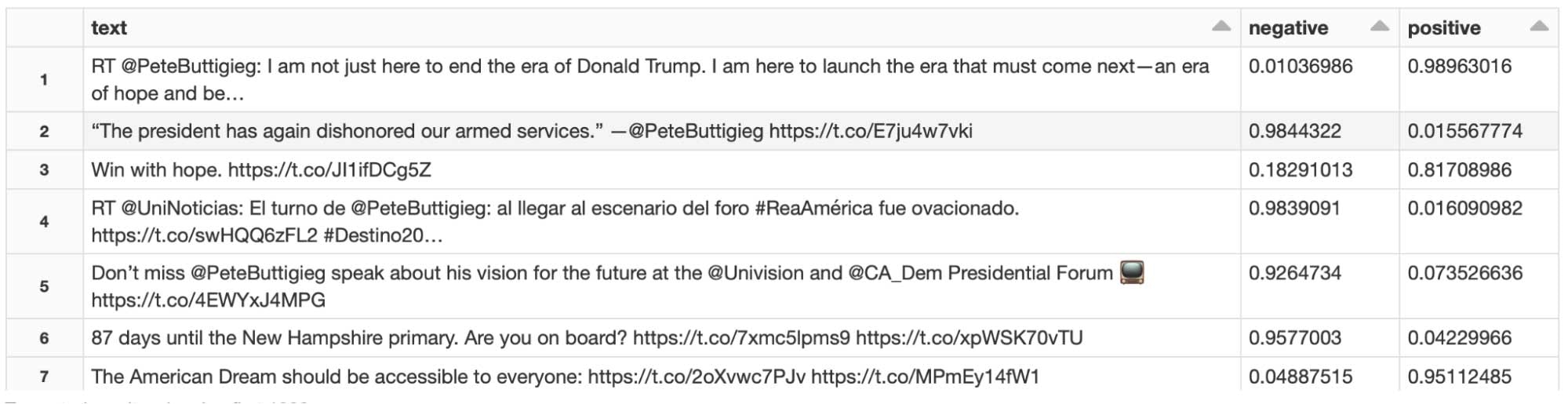
大量ファイルに対するスケーラブルな推論
上ので例では、データは単一のファイルから読み込まれましたが、大規模データを取り扱う際にデータ全てが一つのファイルに格納されている可能性は低いです。以下には、複数ファイルに対するDataloaderを用いる際の変更点のハイライトとともに、全体のコードを示しています。
MODEL = "distilbert-base-uncased-finetuned-sst-2-english"
def get_all_files():
file_list = ['/PATH/FILE1',
'/PATH/FILE2',
'/PATH/FILE3']
return(file_list)
class TextLoader(Dataset):
def __init__(self, file=None, transform=None, target_transform=None, tokenizer=None):
self.file = pd.read_json(file, lines=True)
self.file = self.file
self.file = tokenizer(list(self.file['full_text']), padding=True, truncation=True, max_length=512, return_tensors='pt')
self.file = self.file['input_ids']
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.file)
def __getitem__(self, idx):
data = self.file[idx]
return(data)
class SentimentModel(nn.Module):
def __init__(self):
super(SentimentModel, self).__init__()
self.model = AutoModelForSequenceClassification.from_pretrained(MODEL)
def forward(self, input):
output = self.model(input)
pt_predictions = nn.functional.softmax(output.logits, dim=1)
return(pt_predictions)
dev = 'cuda'
if dev == 'cpu':
device = torch.device('cpu')
device_staging = 'cpu:0'
else:
device = torch.device('cuda')
device_staging = 'cuda:0'
tokenizer = AutoTokenizer.from_pretrained(MODEL)
all_files = get_all_files()
model3 = SentimentModel()
try:
model3 = nn.DataParallel(model3, device_ids=[0,1,2,3])
model3.to(device_staging)
except:
torch.set_printoptions(threshold=10000)
for file in all_files:
data = TextLoader(file=file, tokenizer=tokenizer)
train_dataloader = DataLoader(data, batch_size=120, shuffle=False) # Shuffle should be set to False
out = torch.empty(0,0)
for data in train_dataloader:
input = data.to(device_staging)
if(len(out) == 0):
out = model3(input)
else:
output = model3(input)
with torch.no_grad():
out = torch.cat((out, output), 0)
df = pd.read_json(file, lines=True)['full_text']
res = out.cpu().numpy()
df_res = pd.DataFrame({ "text": df, "negative": res[:,0], "positive": res[:,1]})
まとめ
ここでは、Pytorchを用いた感情分析に用いられるHuggingfaceフレームワークの使用法を議論しました。さらに、推論プロセスを高速するために、どのようにGPUを活用するのかを示しました。簡単に使用できるMLランタイムと、最先端のGPUを利用できるDatabricksプラットフォームを用いることで、これらのソリューションの実験とデプロイが容易になります。
詳細に関しては、添付のノートブックをご覧ください!
ローカライズ版はこちらです。現在最後のセルでは同じファイルを複数回指定しています。