こちらのGUI編です。
クラスターを作成する
AutoMLの実行にはDatabricksクラスターが必要となります。機械学習ランタイム(以下の例では11.1ML)を選択してクラスターを作成し、起動しておきます。

データセットを準備する
GUIを使用してAutoMLを実行するには、トレーニングデータセットがデータベースに登録されている必要があります。
-
ノートブックを作成し、上のステップで作成したクラスターにアタッチします。

- 以下のコマンドを実行します。
あなたのユーザー名が埋め込まれたデータベース名でデータベースが作成されます。Python
import re from pyspark.sql.types import * # ログインIDからUsernameを取得 username_raw = dbutils.notebook.entry_point.getDbutils().notebook().getContext().tags().apply('user') # Username の英数字以外を除去し、全て小文字化。Username をファイルパスやデータベース名の一部で使用可能にするため。 username = re.sub('[^A-Za-z0-9]+', '', username_raw).lower() # データベース名 db_name = f"automl_{username}" # Hiveメタストアのデータベースの準備:データベースの作成 spark.sql(f"DROP DATABASE IF EXISTS {db_name} CASCADE") spark.sql(f"CREATE DATABASE IF NOT EXISTS {db_name}") # Hiveメタストアのデータベースの選択 spark.sql(f"USE {db_name}") print("database name: " + db_name)

- 以下のコマンドを実行してテーブルをデータベースに登録します。
Python
import pyspark.pandas as ps df = ps.read_csv("/databricks-datasets/COVID/covid-19-data") df["date"] = ps.to_datetime(df['date'], errors='coerce') df["cases"] = df["cases"].astype(int) # Sparkデータフレームに変換 input_sdf = df.to_spark() # データベースにテーブルcovid_19_dataとして登録 input_sdf.write.format("parquet").saveAsTable("covid_19_data")
データベースにテーブルが登録されると、サイドメニューのデータからテーブルを確認することができます。
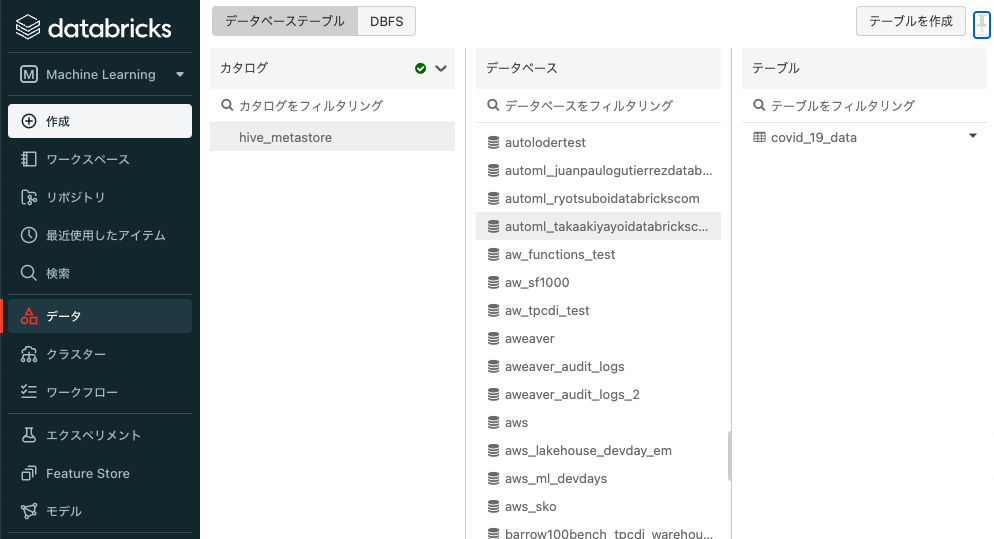

AutoMLのGUIにアクセスする
- Databricksワークスペースにログインします。画面が日本語になっていない場合は、こちらを参考にGUIを日本語に切り替えてください。
- サイドメニューのDatabricksロゴの下にDが表示されている場合にはクリックして、M Machine Learningを選択します。これはペルソナスイッチャーと呼ばれるインタフェースで、作業の内容に応じてペルソナを切り替えることでメニュー項目が切り替わります。

- サイドメニューからエクスペリメントをクリックします。

- エクスペリメント(MLflowランの管理単位)の一覧が表示されます。

- 左上にあるAutoMLエクスペリメントを作成をクリックします。AutoMLの設定画面が表示されます。

AutoMLのGUIから設定を行う
-
クラスターでは、上のステップで作成したクラスターを選択します。

-
機械学習の問題のタイプでは
予測を選択します。 -
データセットでは、Browseをクリックします。上のステップで作成したテーブルを選択して、選択をクリックします。

- すると、トレーニングデータセットのスキーマが表示されます。

- 以下の設定を行います。
-
予測ターゲットには予測対象となるカラムを選択します。ここでは、感染者数を示す
casesを選択します。 -
時間列には記録された日時を示す
dateを選択します。 -
予測期間には
30日を指定します。 - エクスペリメント名はデフォルトのままとしておきます。
-
Output Databaseには予測結果のデータを格納するデータベースを指定することができます。ここでは、Browseをクリックして、上のステップで作成したデータベースを選択して、選択をクリックします。

-
予測ターゲットには予測対象となるカラムを選択します。ここでは、感染者数を示す
- 以下のように設定されていることを確認したら、一番下にあるAutoMLを開始ボタンをクリックします。

AutoMLの実行
- トレーニングが始まると進捗を表示する画面に切り替わります。

-
リフレッシュボタンを押すと、トレーニングされたモデルの一覧が更新されます。ここでは精度指標として
val_smapeが用いられており、常にベストなval_smapeを出したモデルが上に表示されるようになっています。

- トレーニングが完了すると完了と表示されます。

AutoMLの結果の確認
- トレーニングに用いたデータの分布などを確認するには、データ探索用ノートブックの表示をクリックします。
- 別タブでノートブックが開き、データの時系列変化などを確認することができます。

- 一番精度が良かったモデルの詳細を確認するには、最適なモデルのノートブックを表示をクリックするか、モデル一覧の一番上の行のSource列のリンクをクリックしてノートブックを開きます。今回のベストモデルを作成したのはARIMAであることがわかります。

- 予測結果も確認することができます。

- また、今回は結果をデータベースに登録しているので以下の画面に表示されれている指示に従うことでデータにアクセスすることができます。

- ノートブックで以下のコマンドを実行して予測結果にアクセスします。
SQL
%sql select * from automl_takaakiyayoidatabrickscom.forecast_prediction_966f2be7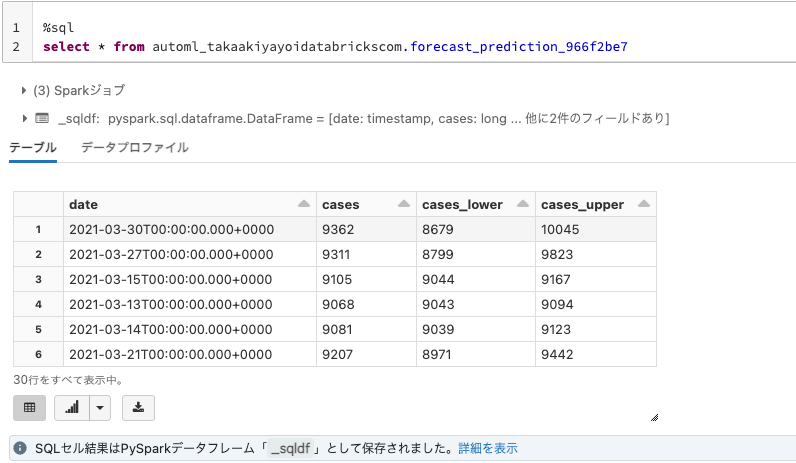

まとめ
こちらでは、GUIの操作を主体としたAutoMLを体験いただきました。Databricks AutoMLではGUIもPython APIもサポートしていますが、それよりも重要なのは中身の処理が全てわかるようになっているガラスボックスアプローチであると考えています。これには以下のメリットがあります。
- 機械学習プロジェクトにおけるベースラインモデルをクイックに構築し、以降のカスタマイズを容易に行えます。
- いわゆるシチズンデータサイエンティストとプロフェッショナルデータサイエンティストのコラボレーションも円滑に行えるようになります(シチズンデータサイエンティストがビジネス知識を活かしてベースラインモデルを構築し、プロフェッショナルデータサイエンティストがチューニングを行う等)。
この他、Databricksでの機械学習に興味がある方はこちらの記事もご覧になってください。
- Databricks AutoMLのご紹介 : 機械学習開発の自動化に対するガラスボックスアプローチ
- Databricks AutoMLのマニュアル
- あなたの機械学習プロジェクトをDatabricks AutoMLでスーパーチャージしましょう
- Databricks機械学習ガイド
- Databricksにおける機械学習チュートリアル
- Databricksで機械学習を始めてみる
- 機械学習エンジニアとしてDatabricksを使い始める
- Databricksにおける機械学習モデル構築のエンドツーエンドのサンプル