こちらを昨年書きましたが、より詳細な手順にまとめます。
全体像
以下では、AWSアカウントIDが<deployment-acct-id>であるDatabricksをデプロイしたAWSアカウントAと、AWSアカウントIDが<bucket-owner-acct-id>であるアクセス先のS3バケットがあるAWSアカウントBを考えます。
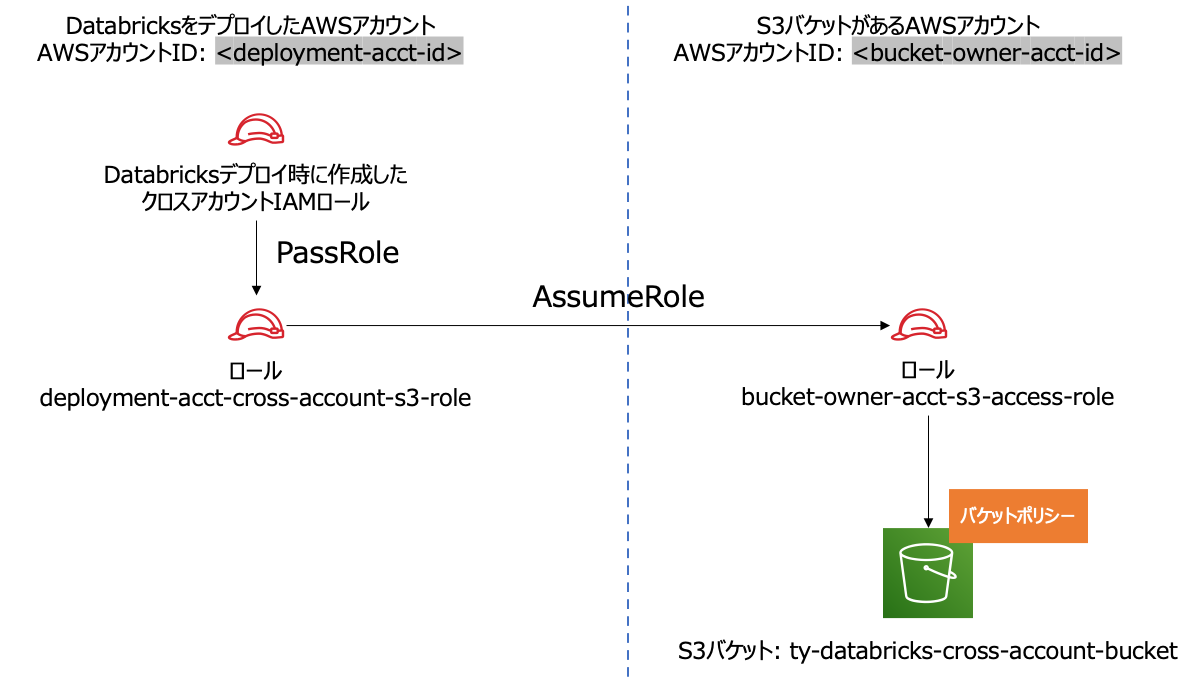
この作業では、以下のロールARN、インスタンスプロファイルのARNを使用します。
arn:aws:iam::<deployment-acct-id>:role/deployment-acct-cross-account-s3-rolearn:aws:iam::<deployment-acct-id>:instance-profile/deployment-acct-cross-account-s3-rolearn:aws:iam::<bucket-owner-acct-id>:role/bucket-owner-acct-s3-access-role
DatabricksがデプロイされているAWSアカウントでの作業(1回目)
アクセス先S3があるAWSアカウントにアクセスするIAMロールの作成
- DatabricksがデプロイされているAWSアカウントでAWSマネジメントコンソールにログインします。
- IAM > ロールに移動し、ロールを作成をクリックします。
-
信頼されたエンティティタイプではAWSのサービス、一般的なユースケースでEC2を選択し、次へをクリックします。

- ポリシーはあとで設定するので、ロール名を付けてロールを作成します。ここでは
deployment-acct-cross-account-s3-roleというロールとしています。

- ロール
deployment-acct-cross-account-s3-roleのARNをメモしておきます。
アクセス先S3があるAWSアカウントでの作業
S3バケットの作成
- アクセス先S3があるAWSアカウントでAWSマネジメントコンソールにログインします。
- S3バケットが存在しない場合には作成します。ここでは
ty-databricks-cross-account-bucketというバケットを作成します。
S3にアクセスするロールの作成
-
IAM > ロールに移動し、ロールを作成をクリックします。
-
信頼されたエンティティタイプではAWSのサービス、一般的なユースケースでEC2を選択し、次へをクリックします。
-
ポリシーはあとで設定するので、ロール名を付けてロールを作成します。ここでは
bucket-owner-acct-s3-access-roleというロールとしています。
-
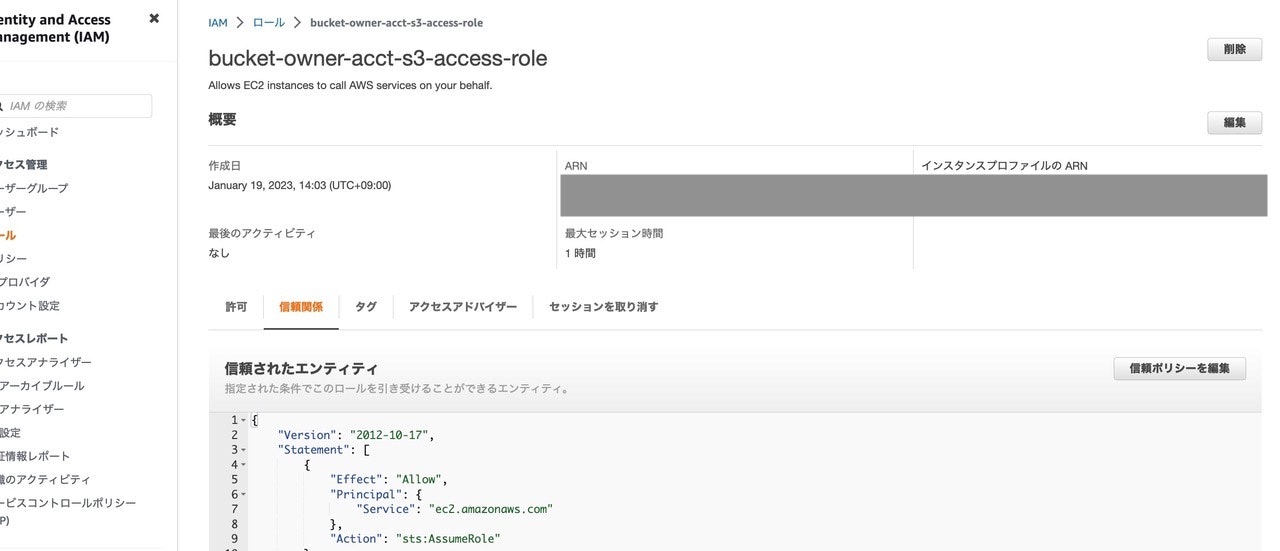
作成した
bucket-owner-acct-s3-access-roleロールにアクセスし、信頼関係を開き、信頼ポリシーを編集をクリックします。
-
以下の信頼ポリシーを入力します。これによって、DatabricksをデプロイしたAWSアカウントAのロール
deployment-acct-cross-account-s3-roleがこのロールに対してAssumeRoleアクションを実行できるようになります。JSON{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::<deployment-acct-id>:role/deployment-acct-cross-account-s3-role" }, "Action": "sts:AssumeRole" } ] }
S3のバケットポリシーの設定
上のロールによるS3へのアクセスを許可します。
-
S3バケット
ty-databricks-cross-account-bucketにアクセスし、アクセス許可を開きます。 -
バケットポリシーを編集します。
-
以下の内容を入力して保存します。これによって、ロール
bucket-owner-acct-s3-access-roleがこのS3バケットを操作できるようになります。JSON{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::<bucket-owner-acct-id>:role/bucket-owner-acct-s3-access-role" }, "Action": [ "s3:GetBucketLocation", "s3:ListBucket" ], "Resource": "arn:aws:s3:::ty-databricks-cross-account-bucket" }, { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::<bucket-owner-acct-id>:role/bucket-owner-acct-s3-access-role" }, "Action": [ "s3:PutObject", "s3:PutObjectAcl", "s3:GetObject", "s3:DeleteObject" ], "Resource": "arn:aws:s3:::ty-databricks-cross-account-bucket/*" } ] }
DatabricksがデプロイされているAWSアカウントでの作業(2回目)
アクセス先S3があるAWSアカウントにアクセスするIAMロールのポリシーの更新
-
DatabricksがデプロイされているAWSアカウントでAWSマネジメントコンソールにログインします。
-
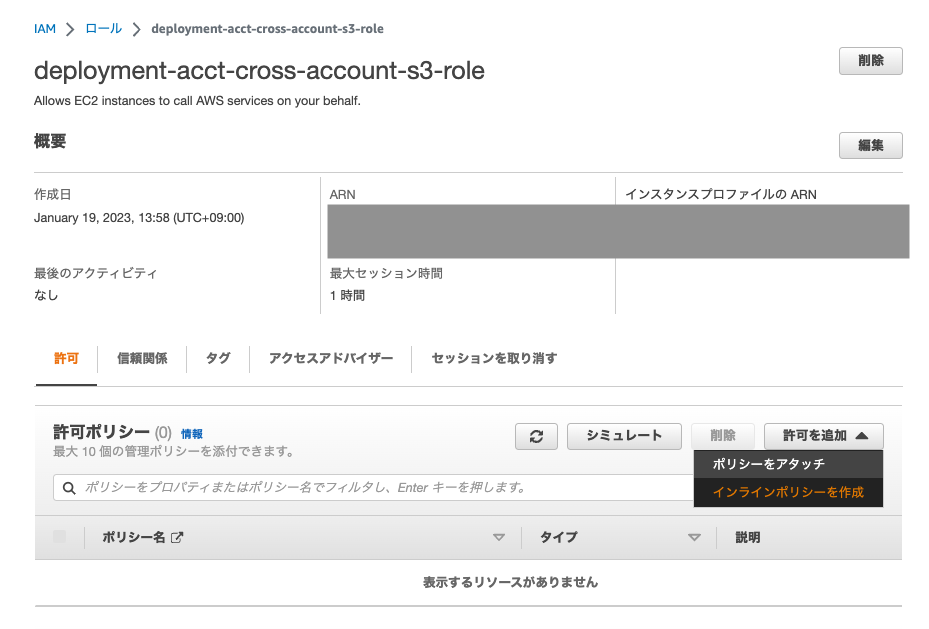
IAM > ロールに移動し、ロール
deployment-acct-cross-account-s3-roleにアクセスします。 -
許可を追加、インラインポリシーを作成をクリックします。
-
JSONを開き、以下の内容を入力します。
JSON{ "Version": "2012-10-17", "Statement": [ { "Sid": "Stmt1487884001000", "Effect": "Allow", "Action": [ "sts:AssumeRole" ], "Resource": [ "arn:aws:iam::<bucket-owner-acct-id>:role/bucket-owner-acct-s3-access-role" ] } ] } -
名前をつけてポリシーを作成します。ここでは、
deployment-acct-cross-account-s3-policyというポリシーにしています。これによって、ロールdeployment-acct-cross-account-s3-roleがS3のあるAWSアカウントのロールbucket-owner-acct-s3-access-roleに対して、AssumeRoleアクションを実行できるようになります。
クロスアカウントIAMポリシーの更新
最後に、Databricksサービスからロールdeployment-acct-cross-account-s3-roleを利用できるようにします。
-
Databricksデプロイ時に作成したクロスアカウントIAMロールにアクセスします。
-
ポリシーを編集します。以下のブロックをポリシーに追加します。これによって、Databricksからロール
deployment-acct-cross-account-s3-roleにアクセスできるようになります。JSON{ "Effect": "Allow", "Action": "iam:PassRole", "Resource": "arn:aws:iam::<deployment-acct-id>:role/deployment-acct-cross-account-s3-role" }
インスタンスプロファイルARNの取得
ロールdeployment-acct-cross-account-s3-roleにアクセスして、インスタンスプロファイルの ARNをメモしておきます。
Databricksでの作業
インスタンスプロファイルの作成
-
Databricksワークスペースにログインし、管理コンソールにアクセスします。
-
Instance Profilesにアクセスし、+インスタンスプロファイルを追加をクリックします。
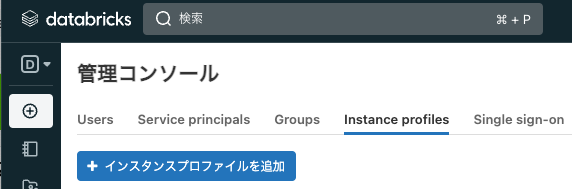
-
インスタンスプロファイルARNに、ロール
deployment-acct-cross-account-s3-roleのインスタンスプロファイルARNを入力して、追加をクリックします。
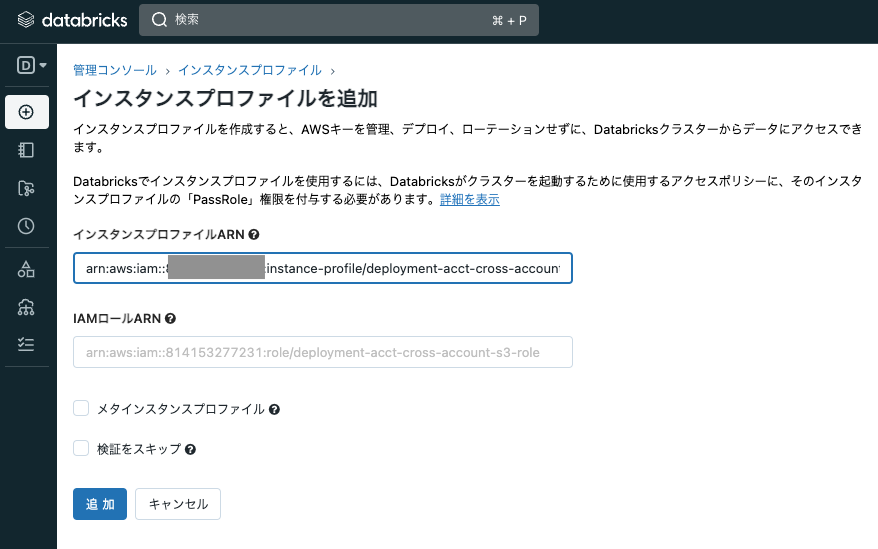
注意
インスタンスプロファイルを追加する際にエラーが発生する場合、上述のIAMの設定が適切に行われていない可能性があります。IAMのポリシーを確認してください。 -
インスタンスプロファイルが追加されました。
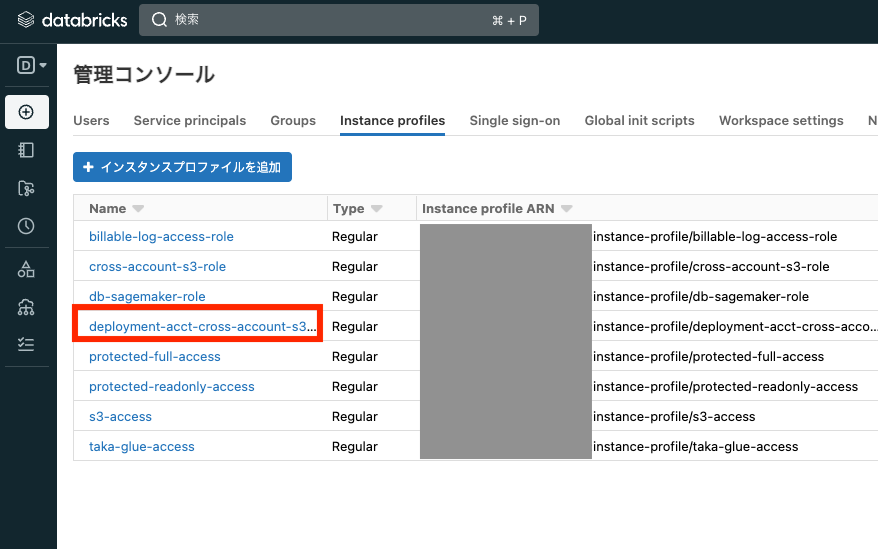
クラスターの設定
上のステップで追加したインスタンスプロファイルとSpark設定を行います。
-
クラスターにアクセスし、編集をクリックします。
-
インスタンスプロファイルで上のステップで追加したインスタンスプロファイルを選択します。
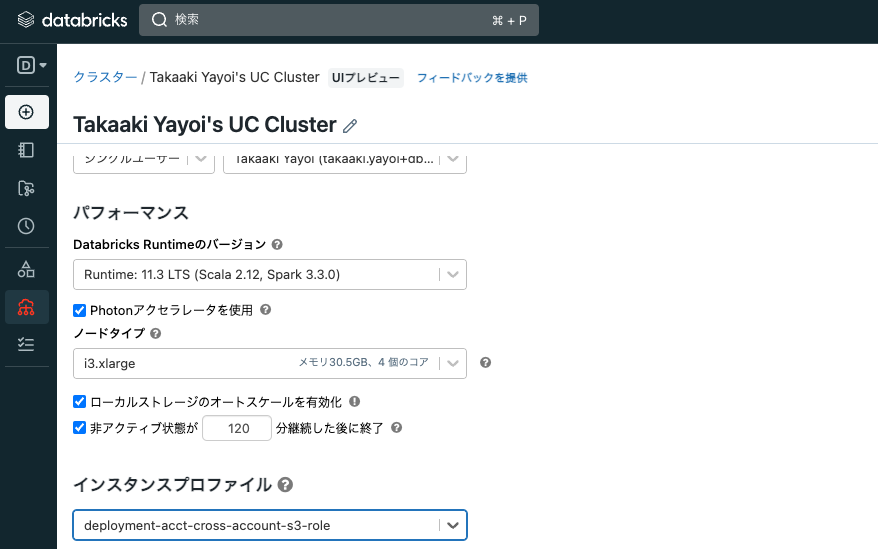
-
高度なオプションを展開して、Sparkにアクセスします。
-
以下の行を追加します。
fs.s3a.assumed.role.arn arn:aws:iam::<bucket-owner-acct-id>:role/bucket-owner-acct-s3-access-role fs.s3a.aws.credentials.provider org.apache.hadoop.fs.s3a.auth.AssumedRoleCredentialProvider -
確認をクリックして編集を終了します。
-
クラスターを起動します。
動作確認
一旦ここで接続を確認します。
-
アクセス先のS3バケットが空の場合は、適当なファイルをアップロードしておきます。
-
上で設定したクラスターにノートブックをアタッチします。
-
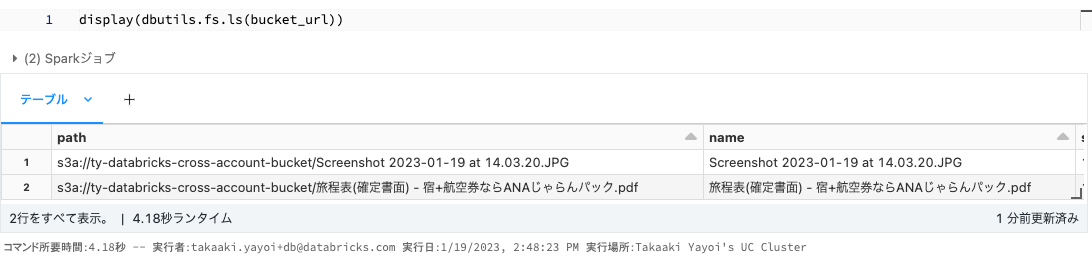
以下のセルを実行します。
Pythondisplay(dbutils.fs.ls("s3a://ty-databricks-cross-account-bucket")) -
以下のようにファイル一覧が表示されれば成功です。
マウントポイントの作成
上の通り、直パスでもアクセスは可能ですが、マウントポイントを作成することも可能です。
# S3バケットのURL
bucket_url = "s3a://ty-databricks-cross-account-bucket"
# マウントポイント名
mount_point_name = "cross-account-bucket"
# S3バケットのAWSアカウントにあるS3アクセス用IAMロールのARN
s3_access_arn = "arn:aws:iam::<bucket-owner-acct-id>:role/bucket-owner-acct-s3-access-role"
dbutils.fs.mount(bucket_url, f"/mnt/{mount_point_name}",
extra_configs = {
"fs.s3a.credentialsType": "AssumeRole",
"fs.s3a.stsAssumeRole.arn": s3_access_arn,
"fs.s3a.canned.acl": "BucketOwnerFullControl",
"fs.s3a.acl.default": "BucketOwnerFullControl"
}
)
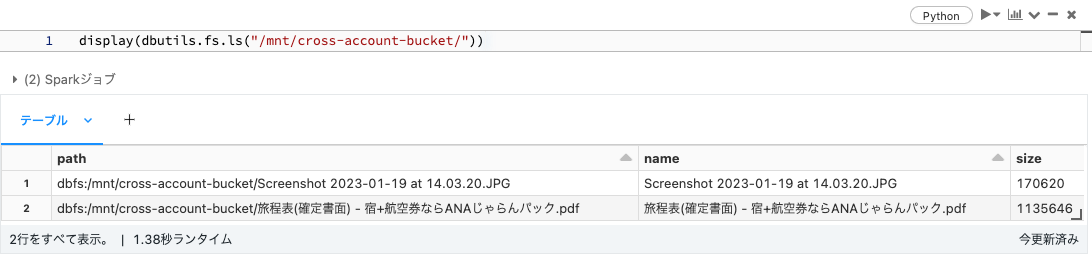
これで、/mnt/cross-account-bucket/というマウントポイント経由でクロスアカウントのS3バケットにアクセスすることができるようになります。このマウントポイントは明示的にアンマウントしない限り永続化されます。
display(dbutils.fs.ls("/mnt/cross-account-bucket/"))
参考資料
- DatabricksにおけるAssumeRoleポリシーを用いたS3バケットに対するセキュアなクロスアカウントアクセス - Qiita
- AWS iam:PassRoleって何だ - karakaram-blog
- Access cross-account S3 buckets with an AssumeRole policy | Databricks on AWS
- Mounting cloud object storage on Databricks | Databricks on AWS