大規模特徴量エンジニアリングで紹介されているノートブックを実際にウォークスルーした内容です。
ノートブックの日本語訳はこちらからアクセスできます。
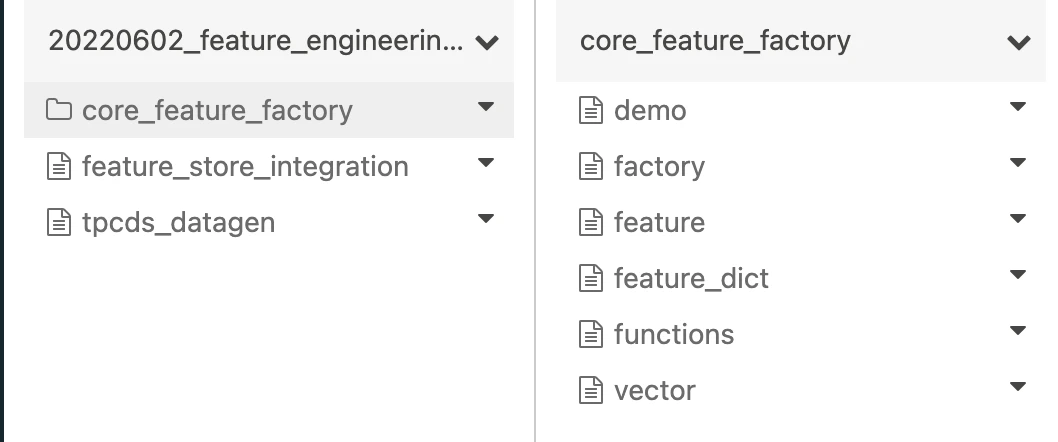
ノートブックの構成
サンプルノートブック(DBC形式)をDatbricksワークスペースにインポートすると以下のフォルダ構成となります。
注意
ノートブックのインポート方法に関しては、こちらを参照ください。
データの準備
最初にノートブックtpcds_datagenを用いてTPC-DSデータを準備します。
このノートブックはpark-sql-perfライブラリ(https://github.com/databricks/spark-sql-perf )を用いてTPC-DSデータを生成します。
このライブラリのパッケージング済みのバージョンは https://github.com/BlueGranite/tpc-ds-dataset-generator/tree/master/lib から取得できます。
注意
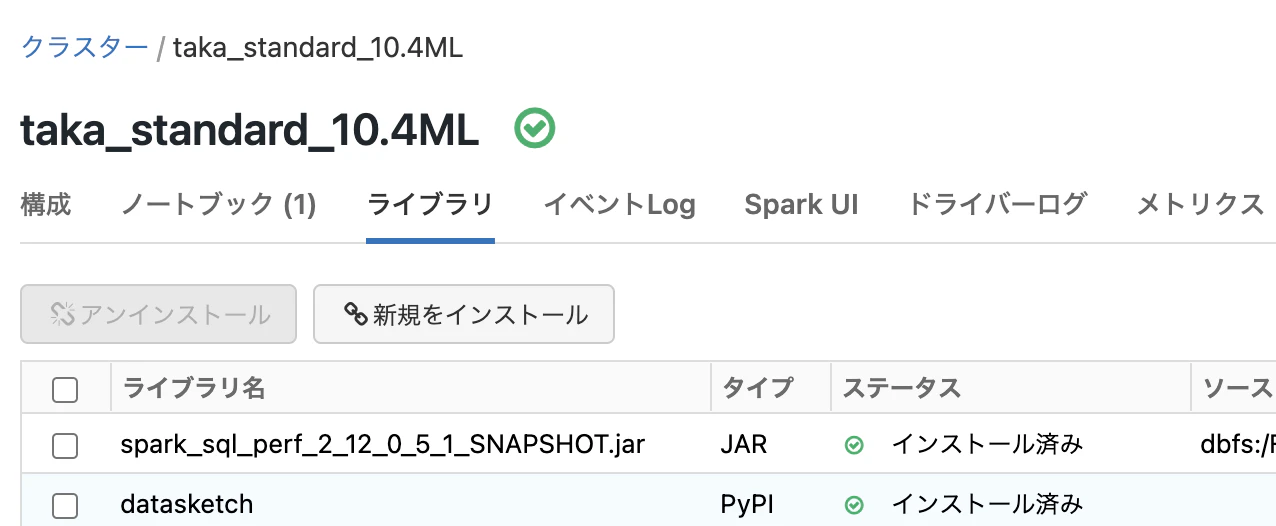
上のパッケージング済みのバージョン(spark-sql-perf_2.12-0.5.1-SNAPSHOT.jar)をクラスターライブラリとしてインストールしてください。

Cmd5のファイル格納場所、Cmd6のデータベース名を指定します。
// TPC-DSデータがダウンロードされるベースディレクトリ
val base_dir = "/tmp/takaaki.yayoi@databricks.com/blog"
val databaseName = "taka_jumpstart_db" // 明示的に指定
ノートブックを実行していくことで、TCP-DSのデータベースが作成されます。
Cmd20以降でDeltaファイルに書き込みます。
// Deltaテーブルが書き込まれるパス
// これはデモ用ノートブックのソースデータとして使用するdeltaパスとなります
val store_sales_delta_path = "/tmp/takaaki.yayoi@databricks.com/sales_store_tpcds"
最後にZ-orderingによる最適化を行います。
%sql
-- Cmd20の値でパスを変更してください
optimize delta.`/tmp/takaaki.yayoi@databricks.com/sales_store_tpcds`
zorder by d_date, i_category
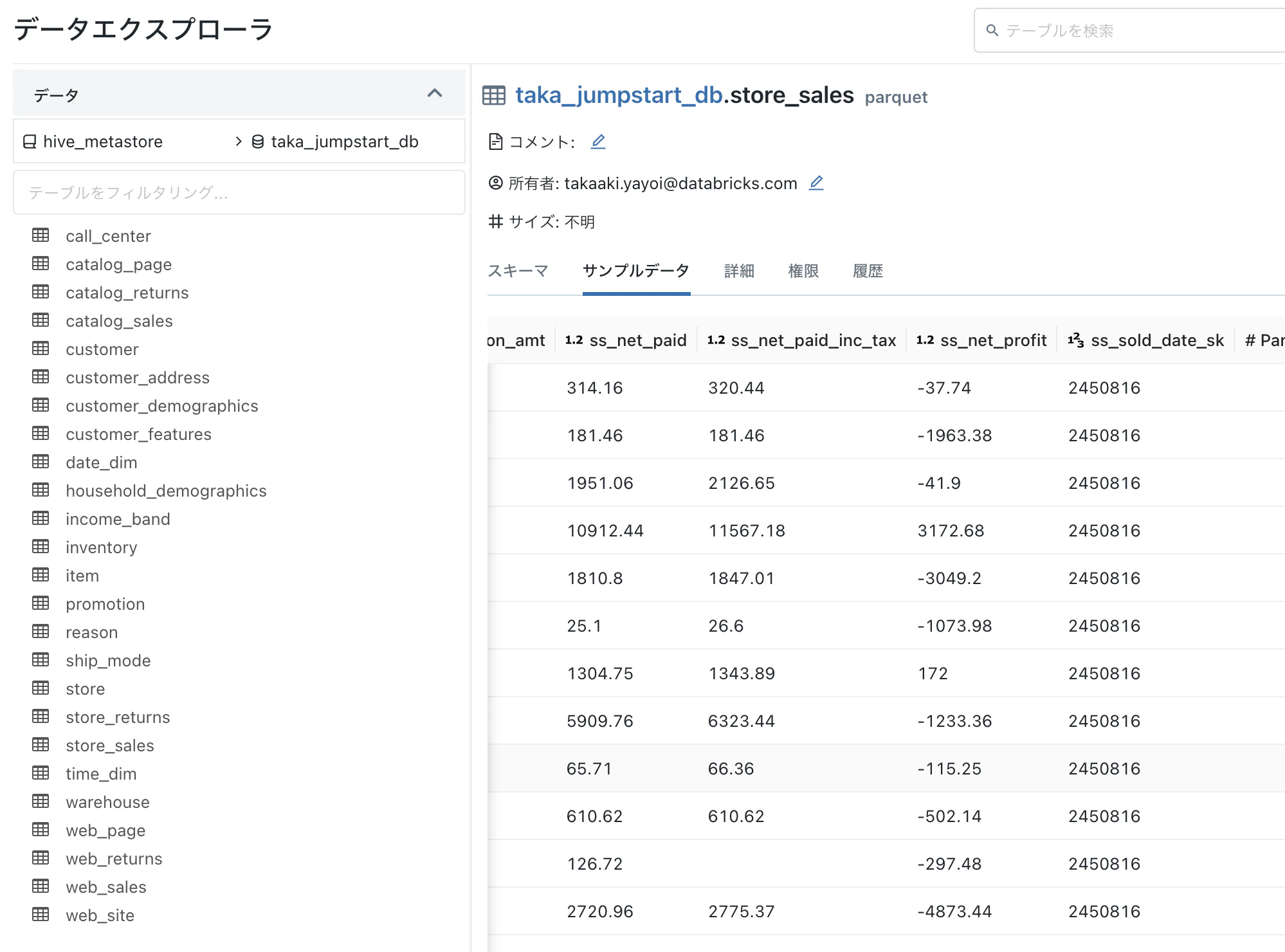
これでデータの準備ができました。以下のようなテーブルが作成されます。
特徴量エンジニアリング
注意
MinHash計算にす要するdatasketchをクラスターライブラリとしてインストールしてください。
こちらでは、core_feature_factory/demoのノートブックを使用します。なお、feature_store_integrationノートブックは、core_feature_factory/demoで使用しているプロセスを経て生成した特徴量をDatabricks Feature Storeに格納する流れを説明しています。
関連クラス・関数の宣言
特徴量の元データである共通項を管理するCommonFeaturesクラス、それから派生させたStoreSalesクラスなどを宣言します。これによって特徴量がモジュール化されます。各自で独自の特徴量計算ロジックを実装するのではなく、これらのクラスに対して操作を加えることで特徴量を計算することになるので、計算ロジックの散逸を防ぐことができ、全ての人が共通のフレームワークで計算ロジックを実装することになります。
%run ./feature_dict
計算し増幅した特徴量をベースのデータフレームに追加するappend_featuresを宣言します。
%run ./factory
平均や標準偏差を計算するヘルパー関数を宣言します。
%run ./functions
TPC-DSデータの準備
前のステップで準備したTPC-DSデータを読み込みます。
# tpcds_datagenノートブックを用いて生成したdeltaテーブル/格納場所
store_sales_delta_path = "/tmp/takaaki.yayoi@databricks.com/sales_store_tpcds"
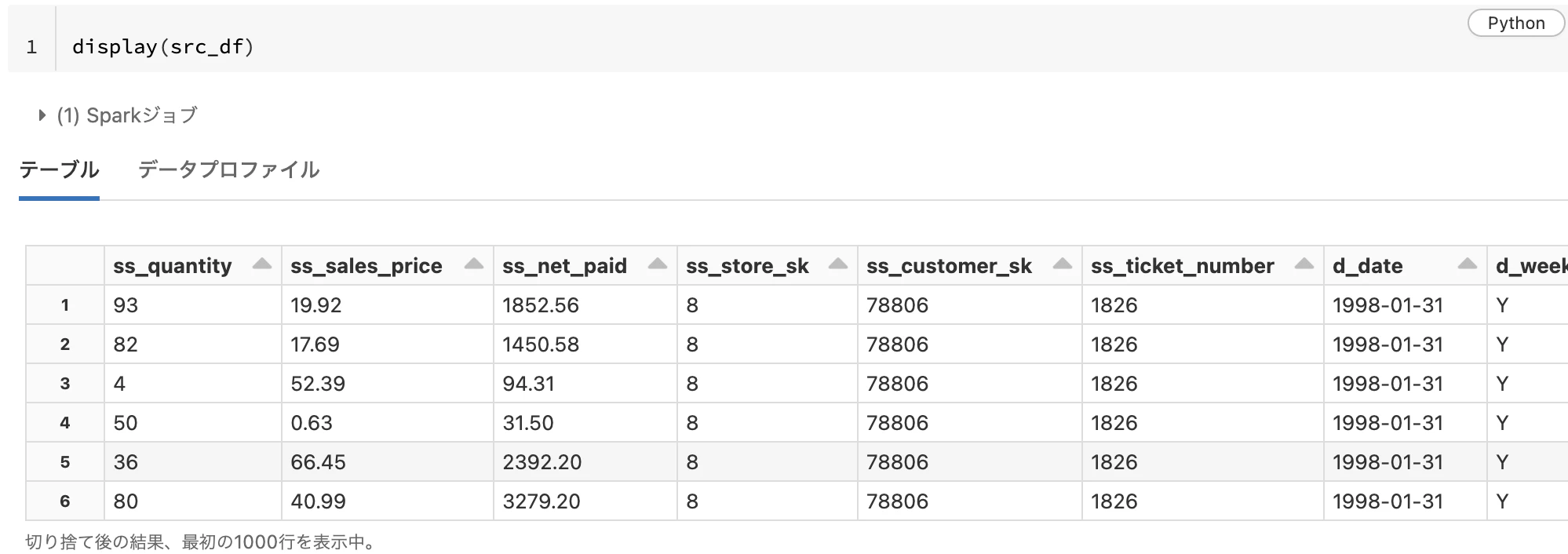
src_df = spark.table(f"delta.`{store_sales_delta_path}`")
display(src_df)
特徴量の操作
ここでは、商品カテゴリーi_categoryの"Music", "Home", "Shoes"とmonth_idの200012, 200011, 200010を掛け合わせた特徴量を計算します。
features = StoreSales()
# total_sales に i_category と month_id を掛け合わせて特徴量を増幅
fv_months = features.total_sales.multiply("i_category", ["Music", "Home", "Shoes"]).multiply("month_id", [200012, 200011, 200010])
# ベースのデータフレームに追加
# 以下の例ではcustomer_idでグルーピングしています
df = append_features(src_df, [features.collector], fv_months)
結果として、特定商品カテゴリーごと、月毎の売り上げからなる特徴量が生成されます。

One hotエンコーディング
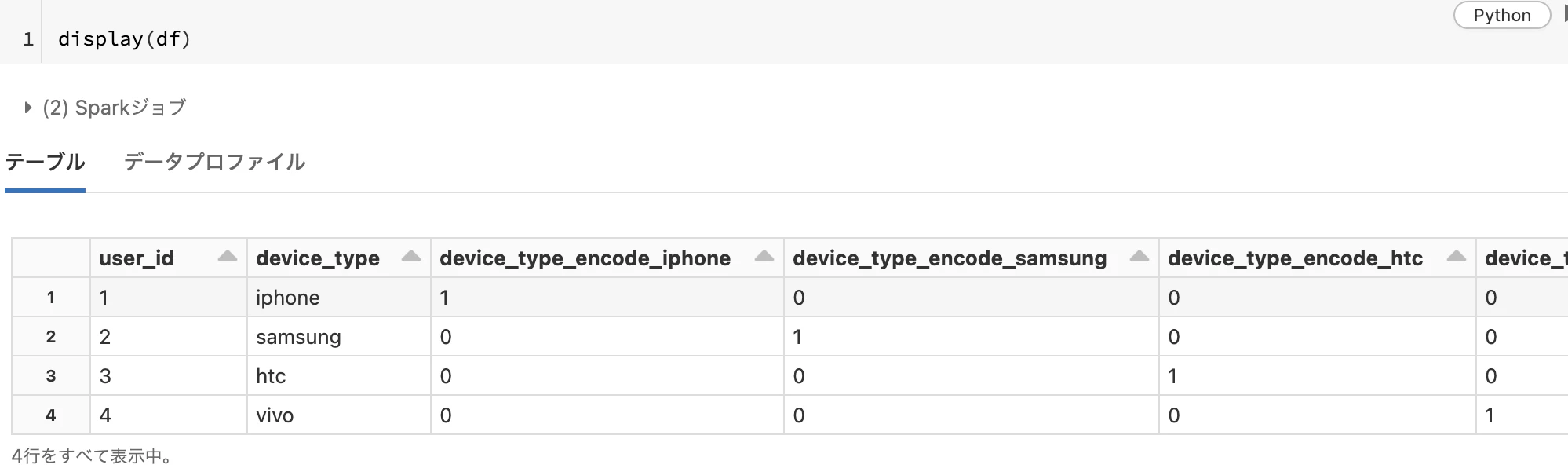
One hotエンコーディングに関しても同様の手順で操作を行うことができます。
src_df = spark.createDataFrame([(1, "iphone"), (2, "samsung"), (3, "htc"), (4, "vivo")], ["user_id", "device_type"])
encode = Feature(_name="device_type_encode", _base_col=f.lit(1), _negative_value=0)
onehot_encoder = encode.multiply("device_type", ["iphone", "samsung", "htc", "vivo"])
df = append_features(src_df, ["device_type"], onehot_encoder)
MinHash
冒頭のノートブックにサンプルが記載されています。