What Is Feature Engineering and How to Apply/Scale It for Machine Learning - The Databricks Blogの翻訳です。
特徴量エンジニアリングは、機械学習プロセスにおいて最も重要でもっとも時間を必要とするステップの一つです。データサイエンティストとデータアナリストは、モデル改善し、ビジネス上の洞察を得るためのBIレポートを作成するために、異なる特徴量の組み合わせを用いた実験に多大なる時間を費やしてしまいがちです。データサイエンティストがより膨大、かつより複雑なデータセットと格闘することで、以下のような課題をさらに困難なものにします:
- シンプルかつ一貫性のある特徴量の定義
- 既存の特徴量の検索、再利用
- 既存の特徴量を用いたモデル構築
- 特徴量とモデルのバージョンのトラッキング
- 特徴量定義のライフサイクル管理
- 特徴量計算、特徴量格納の効率の維持
- 幅広のテーブル(1000カラム以上)の効率的な計算及び格納
- 将来の実証(監査、解釈可能性)に必要となる、意思決定に用いたモデルの生成に用いた特徴量の再作成
本記事では、大規模特徴量の生成におけるデザインパターンを説明します。どのようにファーストクラスのデザインパターンが特徴量エンジニアリングプロセスをシンプルなものにし、企業に存在するサイロの効率を改善するのかをデモンストレーションするために、添付のノートブックでデザインパターンのリファレンス実装を提供します。このアプローチは最近発表した、業界初のMLOps、データプラットフォームと協調設計されたDatabricks Feature Storeと統合可能であり、Delta LakeとMLflowのストレージ、MLOpsの機能を活用することができます。
我々の例では、Apache Spark™を用いたファーストクラスの大規模特徴量エンジニアリングワークフローのメリットをデモするためにTPC-DSトレーニングデータセットを使用します。モデルが活用できる特徴量を作成するために、顧客や時間のようなディメンジョンに対して、セールス、トランザクションのようなベースとなるメトリクスを変換します。これらの複雑な変換は、自己文書化され、効率的で拡張可能なものです。ファーストクラスの特徴量エンジニアリングフレームワークは、業種固有のものではなく、特定の組織のニュアンスを捉えられるように容易に拡張されるべきです。本記事において、このような拡張可能性は、フレームワークで活用される適合高次関数を用いてデモされます。
特徴量エンジニアリングに対する我々のアプローチは、スケーラビリティに関する最大の課題のいくつかにも対応できるように設計されています。ほぼ全てのビジネスにおいて、データの成長は止まるところを知らず、データの増加は特徴量の増加を引き起こし、業界に関係なしに特徴量の作成、管理の課題は指数関数的に大きくなっていきます。本記事で議論されるフレームワークは、複数の業界で探索、実装されたものであり、そのいくつかを以下でハイライトします。
アーキテクチャ概要
本記事におけるデザインパターンは、Feature Factoryをベースとしたものです。以下の図では、典型的なワークフローを示しています。まず初めに、生データからベースの特徴量を定義し、これらはさらなる特徴量のビルディングブロックになります。例えば、特徴量total_salesがベースラインとして定義され、これから顧客ごとにグルーピングされたsales_valueを計算します。派生した特徴量は、ベースからさらに複雑な特徴量を計算するために使用することも可能です。数行のコードで、大量の特徴量を迅速かつ、ドキュメント化、テスト、検証、永続化することが可能です。
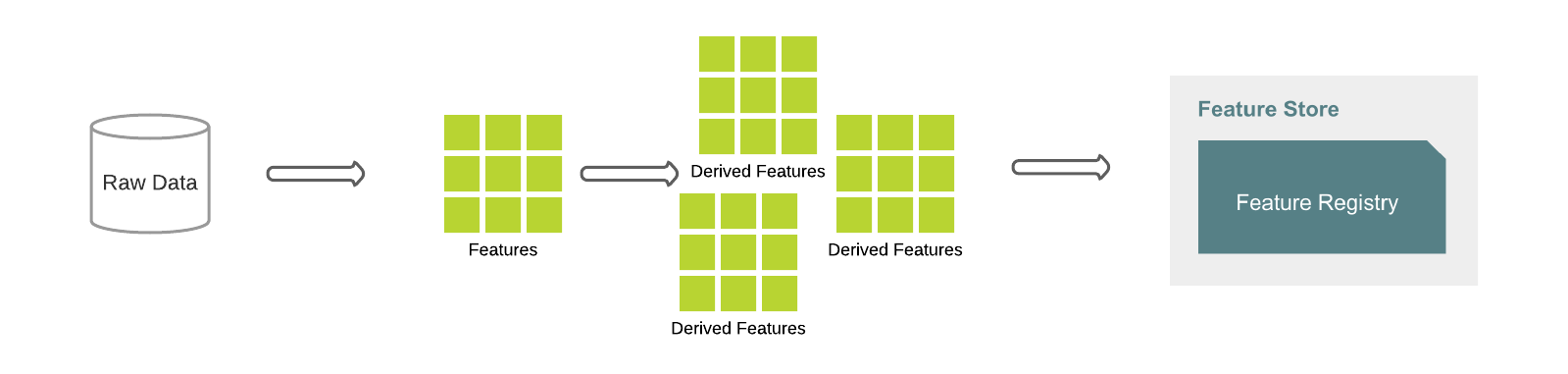
Feature Store APIを用い、特徴量の定義を生データに適用することで、データフレームとして特徴量を生成し、特徴量レジストリに保存します。Delta Lakeは、特徴量生成エンジンが活用する複数の最適化機能を提供します。さらに、特徴量定義はバージョン管理されるので、必要に応じてトレーサビリティ、再現性、時系列変化の理解、監査が可能となります。
以下のコードサンプルでは、どのように特徴量定義が具現化され、Feature Storeに登録されるのかを示しています。
def compute_customer_features(data):
features = StoreSales()
fv_months = features.total_sales.multiply("i_category", ["Music", "Home", "Shoes"]).multiply("month_id", [200012, 200011, 200010])
df = append_features(src_df, [features.collector], fv_months)
return df
customer_features_df = compute_customer_features(src_df)
シンプルな特徴量生成の結果は以下の通りです。
fs = feature_store.FeatureStoreClient()
fs.create_feature_table(
name="db.customer_features",
keys=["customer_id"],
features_df=customer_features_df,
description="customer feature table",
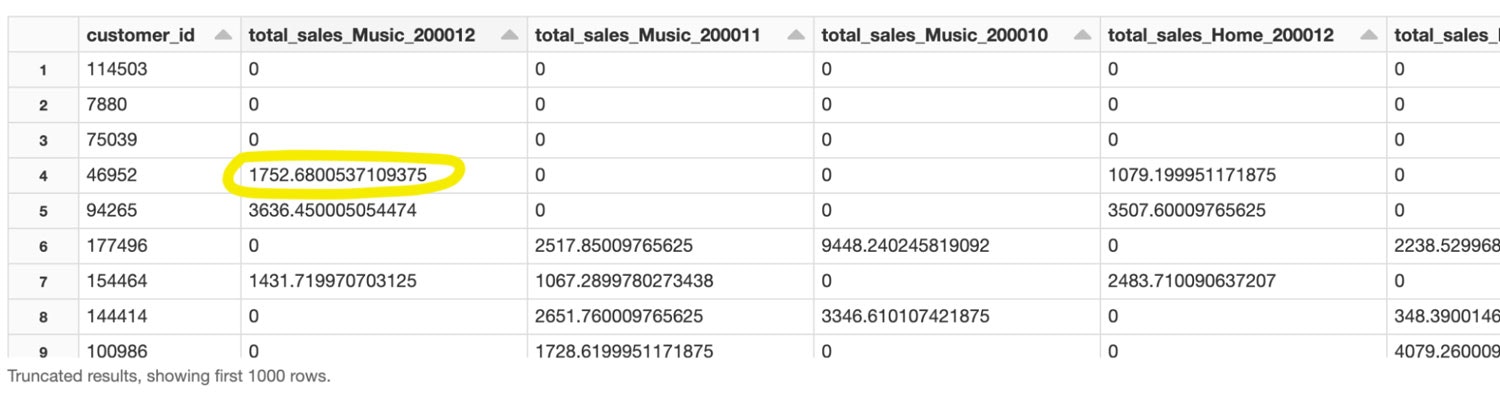
Feature Storeで生成された特徴量
例:customer_id 46952に対するtotal_sales_Music_200012が1752.68。これは、2000年12月時点のtotal_salesで定義されるこのお客様が$1,752.68の音楽の価値があることを意味します。
データセット
リファレンスとなる実装は、3つの販売チャネル:Web、店舗、カタログを含むTPC-DSをベースとしていますが、これに限定されるものではありません。この記事におけるコードサンプルは、date_dimを用いてitemテーブルと結合されたStoreSalesテーブルから生成される特徴量を示します。
- Store_Sales: ブリックアンドモルタルから生成される製品におけるトランザクション収入
- Date_Dim: 日付ディメンジョンを表現するカレンダータイプのテーブル
- Item: 販売されるSKU
ベース特徴量の定義
Spark APIは、再利用を促進し、複雑性を抽象化するラッパーといくつかの文脈定義を提供することで、特徴量エンジニアリングと密接に組み合わせられる強力な機能を提供します。Featureクラスは、以下のコンポーネントを定義するための統合インタフェースを提供します。
-
_base_colシンプルな列表現であるカラムあるいは他の特徴量 -
_filter条件のリスト、あるいは、true/falseの列表現。表現がtrueの場合、_base_colで定義されたロジックが特徴量として採用され、そうでない場合には_negative_valueを用いて計算されます -
_negative_value_filterがfalseの場合評価される表現 -
_agg_funcベースカラムを集計するために使われるSpark SQL関数。_agg_funcが定義されていない場合には、特徴量は集計表現ではありません(すなわち、"特徴量")。
class Feature:
def __init__(self,
_name: str,
_base_col: Union[Column, Feature],
_filter=[],
_negative_value=None,
_agg_func=None):
以下の例では、どのように20219年上半期のセールスを集計して特徴量を定義するのかを示しています。
total_sales = Feature(_name="total_sales",
_base_col="sales_value",
_filter=[col("month_id").between(201901, 201906)],
_agg_func=sum)
以下は上と同じ結果となります。
sum(when(col("month_id").between(201901, 201906), col("sales_value")).otherwise(None))
特徴量のモジュール化
特徴量エンジニアリングにおける一般的な問題は、データサイエンスチームが自身で特徴量を定義したとしても、特徴量の定義が文書化されず、他のチームは参照もできず、容易に共有できないというものです。このことから、重複する労力、コードが生じることになり、最悪のケースにおいては、同じ目的でありながらも異なるロジック、結果をもたらす特徴量が作成されることになります。チーム横断でのバグフィックス、改善、ドキュメント作成を行うことは容易ではありません。特徴量定義のモジュール化はこれらの一般的な問題を軽減します。
組織内の異なる部門が同じコンセプトを異なる方法で計算するケースが多くあるため、企業、サイロ横断での共有には別の抽象化レイヤーが必要となります。例えば、net_salesを組織内のより広い範囲で活用できるように派生できるするためには、net_salesと共通項をcommon_module(例:sales_common)に昇格させて、ユーザーがそれに対してビジネスルールを注入できるようにします。特徴量の多くは他のLOB(ラインオブビジネス)と重複しないので、共通モジュールには昇格されません。しかし、このことは、このような特徴量が他のLOBにとって価値が無いことを意味するわけではありません。概念上の境界を越えて特徴量を組み合わせることは可能ですが、共通する上位概念が存在しない場合には、ソースのコンセプト(例:チャネル)のルールに従って使用すべきです。例えば、店舗の売り上げを予測する機械学習(ML)モデルは、多くのケースでカタログの特徴量によって付加価値を生み出します。catalog_salesが店舗セールスの重要なインジケータであると仮定した場合には、これらの概念上の境界を越えて特徴量が結合されます。この際ユーザーは、外部モジュールに関する定義ルール(例:ネームスペース)を理解する必要があります。抽象化レイヤーに関するさらなる議論はこの記事のスコープ外となります。
リファレンス実装においては、モジュールはFeature Family(特徴量コレクション)として実装されます。特徴量に対して容易にアクセスできるように、読み取り専用のプロパティが定義されます。特徴量ファミリーは、特徴量コレクションのベースクラス、フィルター、その他オブジェクトとして動作し、genericであるImmutableDictBaseクラスを拡張して実装されます。以下のサンプルコードでは、特徴量からフィルタリング定義が抽出され、別のFilterクラスを生成します。複数のファミリーで共有される共通特徴量も抽出され、再利用できるように共有のFeaturesクラスに取り込まれます。フィルターと共通特徴量は、共通定義に基づいて新たな特徴量セットを定義するStoreSalesファミリークラスによって継承されます。
以下のサンプルコードでは、一つのチャンネルのみが存在しています。複数のチャンネルで同じCommonFeaturesを共有します。特定のチャンネルから特徴量定義を抽出するには、シンプルにファミリークラスのプロパティにアクセスするだけです。(例:store_channel.total_sales)
class CommonFeatures(ImmutableDictBase):
def __init__(self):
self._dct["CUSTOMER_NUMBER"] = Feature(_name="CUSTOMER_NUMBER", _base_col=f.col("CUSTOMER_ID").cast("long"))
self._dct["trans_id"] = Feature(_name="trans_id", _base_col=f.concat("ss_ticket_number","d_date"))
@property
def customer(self):
return self._dct["CUSTOMER_NUMBER"]
@property
def trans_id(self):
return self._dct["trans_id"]
class Filters(ImmutableDictBase):
def __init__(self):
self._dct["valid_sales"] = f.col("sales_value") > 0
@property
def valid_sales(self):
return self._dct["valid_sales"]
class StoreSales(CommonFeatures, Filters):
def __init__(self):
self._dct = dict()
CommonFeatures.__init__(self)
Filters.__init__(self)
self._dct["total_trans"] = Feature(_name="total_trans",
_base_col=self.trans_id,
_filter=[],
_negative_value=None,
_agg_func=f.countDistinct)
self._dct["total_sales"] = Feature(_name="total_sales",
_base_col=f.col("sales_value"),
_filter=self.valid_sales,
_negative_value=0,
_agg_func=f.sum)
@property
def total_sales(self):
return self._dct["total_sales"]
@property
def total_trans(self):
return self._dct["total_trans"]
特徴量の操作
特徴量の生成においてよく見られるパターンが存在します。冗長性を削減し、再利用をシンプルなものにし、定義の可読性を高めるために、高次関数を含めるように特徴量を拡張するというものです。以下のような例が考えられます。
- 分析者は多くのケースで、先月、前四半期、去年など様々な期間における、様々な製品のトレンドを計測、比較したいと考えます。
- 広告プレースメントのための推薦システム開発において、製品カテゴリ、市場セグメントにおける顧客の購買パターンを分析するデータサイエンティスト。
多くの異なるユースケースにおいて、より深い、強力な、固有の特徴量を作成するために、一連の類似した(同一の)ベース特徴量に基づいて、非常に似通った一連の操作(例:フィルタ)を実装しています。
リファレンス実装においては、特徴量はFeatureクラスとして定義されます。Featureクラスのメソッドとして、オペレーションが実装されます。より多くの特徴量を作成するために、個別の時間レンジ、値、データカラム(Spark SQLエクスプレッション)などの増幅器を用いてベースの特徴量が増幅されます。例えば、月ごとのセールス合計の特徴量ベクトルを生成するために、セールス合計の特徴量は、月のレンジによって増幅されます。
total_sales * [1M, 3M, 6M] => [total_sales_1M, total_sales_3M, total_sales_6M]
カテゴリ変数に対しても増幅を行うことができます。以下の例では、カテゴリ変数を用いてどのようにtotal_sales特徴量を派生させるのかを示しています。
total_sales * [home, auto] => [total_sales_home, total_sales_auto]
これらのプロセスは組み合わせ可能であることに注意してください。さらに特徴量を変換するために、様々な増幅器によって生成される特徴量を組み合わせることができます。
total_sales_1M * [home, auto] => [total_sales_1M_home, total_sales_1M_home, total_sales_1M_home]
必要に応じて、特徴量のリストなどで増幅された特徴量リストに対して、リストの内包表現を行う際に、高次のラムダ関数を適用することができます。以下の出力変数total_sales_1M_homeは過去一ヶ月におけるホームグッズとして派生した店舗セールスです。データサイエンティストは、多くの場合、彼らだけが読める非効率な数百行のコードを用いて、データと格闘することに数日を費やします。このフレームワークは手間のかかる課題を劇的に低減します。
参考資料
[Python]List Comprehension リストの作り方いろいろ - Qiita
total_sales_by_time = total_sales * [1M, 3M, 6M]
categorical_total_sales_by_time = total_sales_by_time * [home, auto] =>
[
total_sales_1M_home, total_sales_1M_home, total_sales_1M_home, total_sales_1M_auto, total_sales_1M_auto, total_sales_1M_auto,
total_sales_3M_home, total_sales_3M_home, total_sales_3M_home, total_sales_3M_auto, total_sales_3M_auto, total_sales_3M_auto,
total_sales_6M_home, total_sales_6M_home, total_sales_6M_home, total_sales_6M_auto, total_sales_6M_auto, total_sales_6M_auto
]
特徴量ベクトル
ベクトルのオペレーションとともに特徴量を格納することで、特徴量に対するオペレーションをさらにシンプルなものにすることができます。特徴量ベクトルは、特徴量名のリストによってFeatureディクショナリーから生成することができます。
features = Features()
fv = FeatureVector.create_by_names(features, ["total_sales", "total_trans"])
シンプルな積算、除算、あるいは既存ベクトルに対するstats関数を用いて、特徴量ベクトルから他の特徴量ベクトルを作成することができます。特徴量ベクトルは、既存のベース特徴量のリストから特徴量を生成するプロセスをシンプルなものにするために、積算、除算、統計解析のメソッドを実装しています。同様に、スケール、二値化などの一般的な特徴量生成処理を実行するために、Sparkの特徴量トランスフォーマーをラップすることもできます。こちらはOne-hotエンコーディングの例となります。
fv2d = fv.multiply_categories("category", ["GROCERY", "MEAT", "DAIRY"])
これにより、それぞれのカテゴリー(grocery、meat、dairy)におけるtotal_sales、total_transに対する新たな特徴量が生成されます。これをよりダイナミックなものにするために、ハードコーディングするのではなく、カテゴリー変数をディメンジョンテーブルのカラムから読み込むことも可能です。増幅によるアウトプットは、2次元のベクトルであることに注意してください。
| GROCERY | MEAT | DAIRY | |
|---|---|---|---|
| total_sales | total_sales_grocery | total_sales_meat | total_sales_dairy |
| total_trans | total_trans_grocery | total_trans_meat | total_trans_dairy |
以下では、FeatureVectorをどのように実装するのかを示しています。
class FeatureVector:
def __init__(self, features: List[Feature] = None):
if not features:
self._features = []
else:
self._features = features
def __add__(self, other):
"""
Overrides default add so that two feature vectors can be added to form a new feature vector.
e.g. fv1 = fv2 + fv3 in which fv1 contains all features from both fv2 and fv3
:param other:
:return:
"""
return FeatureVector(self._features + other._features)
@classmethod
def create_by_names(cls, feature_collection, feature_names: List[str]):
feat_list = [feature_collection[fn] for fn in feature_names]
return FeatureVector(feat_list)
def multiply(self, multiplier_col: str, multiplier_values: List[str]):
feats = FeatureVector()
for feature in self._features:
fv = feature.multiply(multiplier_col, multiplier_values)
feats += fv
return feats
def create_stats(self, base_name: str, stats=["min", "max", "avg", "stdev"]):
cols = [f.col(feat.name) for feat in self._features]
fl = []
for stat in stats:
if stat == "min":
fl.append(Feature(_name=base_name + "_min", _base_col=f.array_min(f.array(cols))))
elif stat == "max":
fl.append(Feature(_name=base_name + "_max", _base_col=f.array_max(f.array(cols))))
elif stat == "avg":
fl.append(Feature(_name=base_name + "_avg", _base_col=avg_func(f.array(cols))))
elif stat == "stdev":
fl.append(Feature(_name=base_name + "_stdev", _base_col=stdev_func(f.array(cols))))
return FeatureVector(fl)
def to_cols(self):
return [f.col(feat.name) for feat in self._features]
def to_list(self):
return self._features[:]
One-hotエンコーディング
One-hotエンコーディングは、特徴量の増幅においてわかりやすいものであり、以下のコードでウォークスルーしています。特徴量のエンコーディングは、特徴量がカテゴリ変数によって増幅された際に、対応するカラムが1、それ以外のカラムが0に設定されるように、* base_colを1*、negative_valueを0として定義します。
src_df = spark.createDataFrame([(1, "iphone"), (2, "samsung"), (3, "htc"), (4, "vivo")], ["user_id", "device_type"])
encode = Feature(_name="device_type_encode", _base_col=f.lit(1), _negative_value=0)
onehot_encoder = encode.multiply("device_type", ["iphone", "samsung", "htc", "vivo"])
df = append_features(src_df, ["device_type"], onehot_encoder)

推定による増幅
動的なアプローチによって、数行のコードで膨大な量の特徴量を生成することが可能となります。例えば、10の特徴量の特徴量ベクトルを100の個別の値を持つカテゴリー変数のカラムで増幅することで1000のカラム、さらに3つの期間によって増幅した場合には3000のカラムを生成することになります。これは、時間ベースの統計観測においては一般的なシナリオです(例、max、min、average、年間のトレンド)。
特徴量の数が増えるに従い、Sparkのジョブ完了に時間がかかるようになります。重複するレンジにおいて特徴量の再計算が頻繁に発生します。例えば、月間、四半期、半年、年間のトランザクションを計算するために、同じデータセットが複数回集計されます。どうすれば、パフォーマンスを制御化に置きつつも、容易な特徴量生成のプロセスを楽しむことができるのでしょうか?
モデルのパフォーマンスを改善する一つの方法は、ソーステーブルを事前に集計しておき、集計済みデータから特徴量を計算するというものです。以降のロールアップ処理で小規模のデータセットで活用できるように、* total_sales*をカテゴリー、月ごとに事前集計することができます。この方法は、sumやcountのような狭い変換において分かりやすいものですが、中央値やdistinctのような広い変換ではどうなるのでしょうか?大規模データセットに対して低いエラーマージンを維持しつつも、パフォーマンスを保つために、以下では二つの手法を紹介しています。
HyperLogLog
HyperLogLog(HLL)は、データセットにおける別個の値のカウントの近似値を計算するために利用できる機械学習アルゴリズムです。別個の値のカウント、さらには、少ないメモリーフットプリントによる固定長のバイナリースケッチを作成するための高速な手段を提供します。HLLは複数のスケッチのunionを効率的に計算することができ、スケッチのカーディナリティを用いてdistinct countを近似計算します。HLLを用いることで、月ごとのトランザクション総数をスケッチとして事前集計することができ、四半期のトランザクション総数は、シンプルに三つの事前計算済みの月間スケッチのunionとなります。
total_trans_quarter = cardinality(total_trans_1m_sketch U total_trans_2m_sketch U total_trans_3m_sketch)
計算は以下の図で表現できます。

MinHash
増幅処理の結果を近似する他の方法として、二つのスケッチを交差させ、交差部分のカーディナリティを計算するというものがあります。
total_trans_grocery_12m = cardinality(total_trans_12m total_trans_grocery)
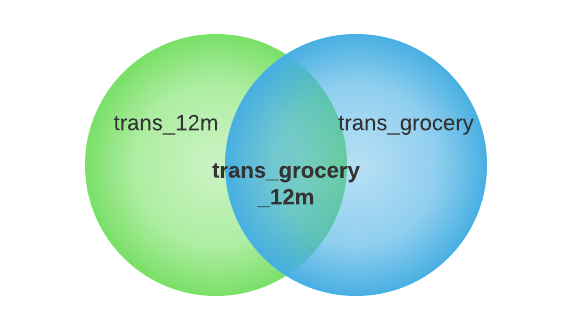
交差は包除原理(Inclusion-exclusion principle)で計算できます。
|AB| = |A| + |B|-|AB|
しかし、このような方法による交差の計算は、推定による積算エラーを引き起こす可能性があります。
MinHashは、二つのセット間のJaccard類似度を推定するための高速アルゴリズムです。精度と計算、ストレージリソースのトレードオフは、異なるハッシュ関数と置換関数の数でチューニングすることができます。MinHashを用いることで、二つの結合されたセットのdistinct valueを線形の時間、および小規模かつ固定のメモリーフットプリントで計算することができます。
MinHashによる増幅の詳細は、以下のノートブックに含まれています。
特徴量定義におけるガバナンス
Databricksノートブックでは、特徴量定義のバージョンを管理し、Githubのreposと連携できます。自動化されたジョブを用いることで、新たな特徴量に対して機能テスト、統合テストが可能となります。異なるシナリオにおけるパフォーマンスのインパクトを特定するために追加のストレステストを実施できます。パフォーマンスがある閾値を超えた場合には、特徴量に対してパフォーマンス警告フラグが立てられます。すべてのテストを通過し、コードが承認されたら、新たな特徴量定義が実運用に移行します。
MLflowのトラッキングとログによって、特徴量からモデルを構築する際、コードのバージョンとソースのデータを追跡し、記録します。 mlflow.spark.autolog()を用いることで、Sparkのデータソースパス、バージョン、フォーマットを記録するように設定できます。モデルはトレーニングデータとコードリポジトリ上の特徴量定義と紐づけられます。
エクスペリメントを再現させるためには、一貫性のあるデータセットを使用する必要があります。Delta Lakeのタイムトラベルによって、過去の断面のデータを検索することができます。
注意
タイムトラベルは長期間のバージョンを保持することを目的としたものではありません。Deltaを使用したとしても、依然としてデータの長期保管においては標準的なアーカイブプロセスが必要となります。
特徴量の探索
特徴量の数が増えるに従い、特定の特徴量定義の検索、一覧が難しくなります。
抽象化された特徴量クラスによって、それぞれの特徴量にコメント属性を追加することができ、自動で特徴量のクラスタリングを行うために、特徴量コメントにテキストマイニングアルゴリズムを適用することができます。
Databricksにおいて、我々は特徴量クラスタリングアプローチの実験を行い、見込みのある結果を得ています。このアプローチでは、入力として適切なコメントが特徴量に記載されていることを前提としています。コメントはTF-IDFの特徴量空間に変換され、似たコメントを同じグループに集めるために、Birchクラスタリングを適用します。それぞれのグループのトピックは、特徴量グループにおける高ランクキーワードとなります。
特徴量のクラスタリングは、様々な用途に使えます。特徴量をグルーピングすることで、開発者が容易に特徴量を探索できるようになります。別のユースケースとしては、特徴量のコメントの妥当性をチェックできます。特徴量が適切に文書化されていない場合、当該特徴量は期待した通りクラスタリングされないことになります。
まとめ
本記事では、大規模特徴量をどのように定義、管理するのかを説明するために、特徴量生成のデザインパターンを示しました。この自動化された特徴量エンジニアリングによって、特徴量変換による動的に特徴量を生成し、特徴量ベクトルを用いることで効率的な蓄積、増幅を行えます。推定ベースの方法による事前計算済みの特徴量の統合、交差を用いることで、派生特徴量の計算を改善できます。さらに特徴量はシンプルかつ効率的に複雑な操作を実装できるように拡張できます。そうでないと、極端にコストがかかる関数となり、異なるバックグラウンドを持つユーザーに対してシンプルにしなくてはなりません。
この記事が、ワークフローを円滑にし、文書化を促進し、重複を最小化し、特徴量データセット間の一貫性を保証するための皆様の特徴量ファクトリーの実装の助けになれば幸いです。
上のノートブックをウォークスルーした記事です。