こちらのイベントでの発表資料です。
宣伝
Databricksのユーザー会でChatGPTの勉強会やります。
アブストラクト
GPT-4は、トランスフォーマーベースのモデルを使用して、次のトークンを予測するように事前学習されたAIモデルです。司法試験でトップ10%の成績を出し、人間レベルのパフォーマンスを示しました。開発プロセスでは、予測可能な挙動を示すインフラストラクチャや最適化手法の開発が重要でした。
(これはChatGPTに100字に要約してもらいました)
1 イントロダクション
このテクニカルレポートは、画像とテキストのインプットを受け取り、テキストのアウトプットを生成することができる大規模かつマルチモーダルなモデルであるGPT-4を説明しています。この数年において、このようなモデルの進歩は凄まじく、大きな注目を集めています。
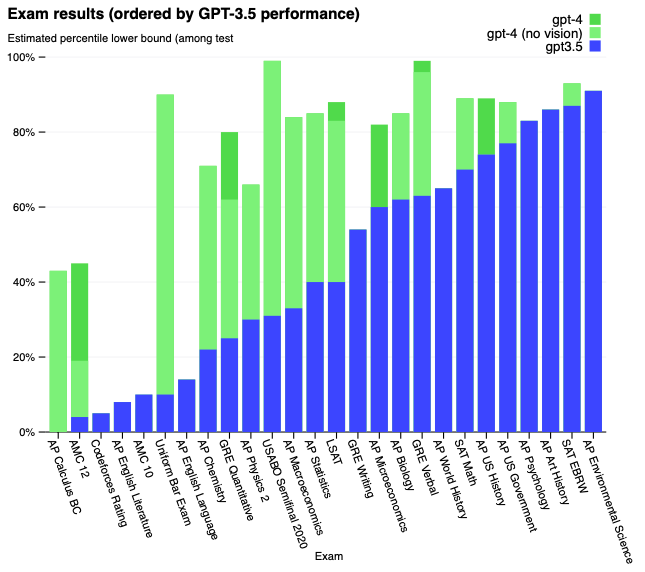
このようなモデルを開発する目的は、自然言語、特により複雑かつ微妙な違いのあるシナリオにおいて、モデルが自然言語を理解、生成する能力の改善です。このモデルは非常にうまく動作し、多くの場合、人間の受験者の大部分を上回りました。例えば、司法試験において、GPT-4はテスト受験者のトップ10%に入るスコアを達成しました。これは、最下位10%だったGPT-3.5とは対照的です。
また、このレポートはプロジェクトにおける主要な課題であるさまざまな規模で予測可能に動作するディープラーニングのインフラストラクチャと最適化手法についても議論します。
この能力にも関わらず、GPT-4には以前のGPTモデルと同様の制限があります: 完全に信頼できるものではなく(例: 「妄想」に苦しむことがあります)、限定的なコンテキストウィンドウを持ち、経験から学びません。GPT-4のアウトプットを活用する際、特に信頼性が重要な文脈においては注意が必要です。
2 本テクニカルレポートのスコープと制限
このレポートはGPT-4の能力、制限、安全性にフォーカスします。GPT-4は、文書内の次のトークンを予測するように事前トレーニングされたトランスフォーマースタイルのモデルです。そして、このモデルは人間のフィードバックによる強化学習(RLHF)を用いてファインチューンされています。GPT-4のような大規模モデルにおける競争の激しい世界や安全性を考慮して、このレポートには(モデルサイズを含む)アーキテクチャ、ハードウェア、トレーニング計算処理、データセットの構成、トレーニング方法の詳細は含めていません。
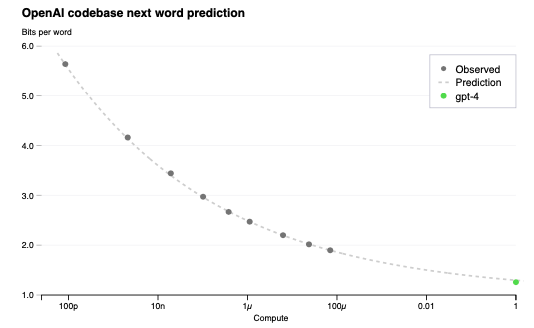
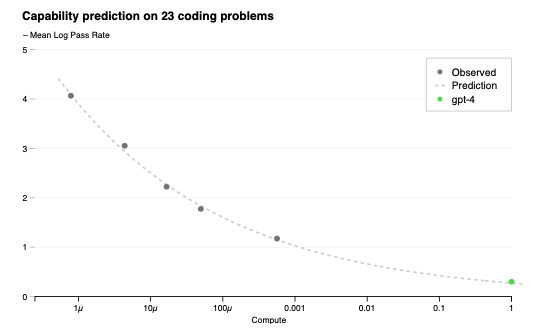
3 予測可能なスケーリング
GPT-4のフォーカスは、予測できるようにスケールするディープラーニングスタックの構築でした。これの大きな理由は、GPT-4のような非常に大規模なトレーニングの実行においては、広範囲のモデル固有のチューニングを行うことが不可能だったためでした。これに対応するために、さまざまなスケールで非常に予測可能な挙動をするインフラストラクチャと最適化手法を開発しました。これらの改善によって、1,000倍から10,000倍少ない計算量でトレーニングされた小規模なモデルからGPTのパフォーマンスのいくつかの側面を予測できるようになりました。
4 能力
GPT-4を、本来は人間向けに設計された司法試験を含む広範なベンチマークでテストしました。これらの試験向けに特定のトレーニングは行っていません。この試験の問題の一部はトレーニングの際にモデルによって認識されます。それぞれの試験に対して、これらの質問が除外されたバリエーションを実行しており、2つに関しては低いスコアをレポートしています。
4.1 ビジュアルのインプット
GPT-4はテキストのみの環境と並行して、画像とテキストの両方から構成されるプロンプトを受け入れます。これによって、ユーザーは任意の画像、言語タスクを指定することができます。特に、このモデルは任意の形で組み合わせられたテキストと画像から構成されるインプットを受けて、テキストのアプトプットを生成します。テキストや写真、図、スクリーンショットを含む文書を含むさまざまなドメインにおいて、GPT4はテキストのみのインプットで動作するのと同様の能力を示しました。

5 制限
この能力にも関わらず、GPT-4は以前のGPTモデルと同様の制限があります。最も重要なことですが、依然としてこれは完全に信頼できるものではありません(事実を「妄想」し、理由づけに失敗します)。特に高リスクな文脈においては、言語モデルのアウトプットを使用する際には、アプリケーション固有の要件にマッチする正確なプロトコル(人間によるレビュー、追加の文脈による補強、高リスクな環境での利用を取りやめるなど)を用いて、非常に注意する必要があります。
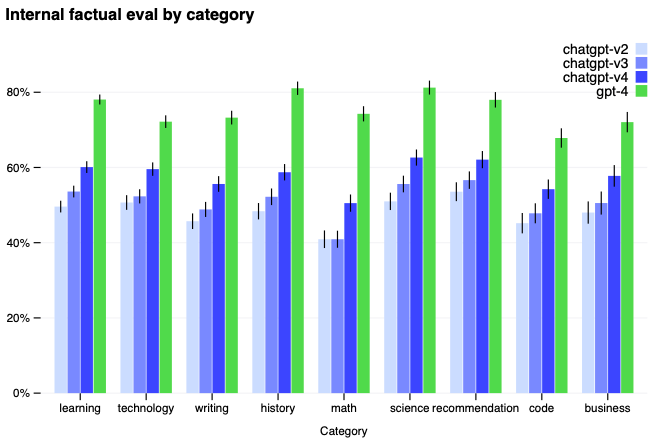
GPT-4は一般的に、2021年9月にカットオフされた大部分の事前トレーニングデータ以降に発生したイベントに対する知識が欠けており、経験から学びません。非常に多くのドメインで適しているように見えないシンプルな理由づけのエラーを起こすことがあり、ユーザーからの明らかな偽の文を受け入れることに関して極度に騙されやすいことがあります。生成するコードにセキュリティ脆弱性を導入してしまうといような、人間と同様に困難な問題で失敗することがあります。

6 リスクと対策
我々はGPT-4の安全性と調整を改善するために膨大な労力を費やしました。こちらでは、攻撃的テストやレッドチーミングのためのドメイン専門家の活用や、我々のモデルアシスト安全性パイプライン[63]、以前のモデルよりも改善された安全性メトリクスをハイライトします。
ドメイン専門家による攻撃的テスト: GPT-4は、害のあるアドバイス、バグのあるコード、不正確な情報の生成といった小規模言語モデルと同様のリスクを孕んでいます。しかし、GPT-4のさらなる能力によって、新たなリスクが浮上しています。これらのリスクの程度を理解するために、長期的なAI調整のリスク、サイバーセキュリティ、バイオリスク、国際的セキュリティのようなドメインから50人以上の専門家とエンゲージしてモデルに対する攻撃的テストを行いました。
モデルアシストの安全性パイプライン: 以前のGPTモデルのように、ユーザーの意図に合わせたレスポンスを生成するように、人間フィードバックを伴う強化学習(RLHF)を用いてモデルの挙動をファインチューンしました。しかし、RLHFの後で我々のモデルは依然として危険な入力に対して脆く、安全、危険な入力の両方で望まれない挙動を示すことがあります。さらに、モデルは安全な入力に対して極端に注意深くなり、差し障りのないリクエストを拒否したり、過度に避けるようになることがあります。
安全性メトリクスの改善: 我々の対策によって、数多くのGPT-4の安全性属性を劇的に改善しました。我々は、GPT-3.5と比べてモデルが許可されないコンテンツに対するリクエストを回答する傾向を82%削減し、GPT-4は我々のポリシーに沿って機微なリクエスト(医療に関するアドバイスや自傷)に対して、さらに29%頻繁に反応するようになりました。
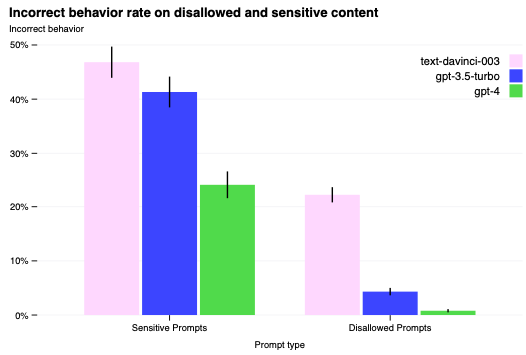
7 まとめ
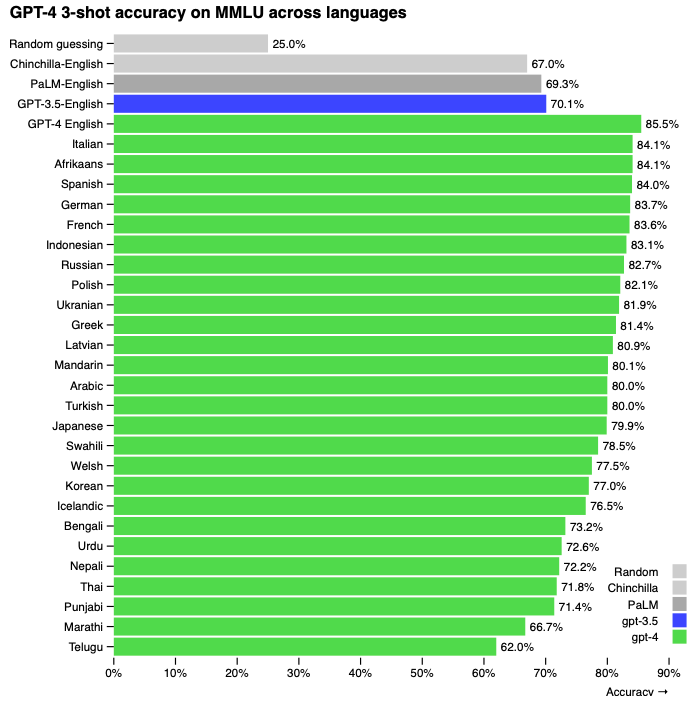
我々はGPT-4を、特定の困難な専門的、学術的ベンチマークにおける人間レベルのパフォーマンスをもつ大規模、マルチモーダルモデルとして特徴づけます。GPT-4は一連のNLPタスクにおいて既存の大規模言語モデルを上回っており、報告されている(多くの場合タスク固有のファインチューニングを行なっている)最先端システムの大部分より優れています。多くの場合英語で計測されていますが、多くの別の言語においても改善された能力を確認しました。予測可能なスケーリングによって、どのようにGPT-4の損失と能力の正確な予測を可能としているのかをハイライトしました。
GPT-4は増加する能力によって新たなリスクを生み出し、その安全性と調整を理解し、改善するために取られた手法と結果のいくつかを議論しました。多くの作業が残っていますが、GPT-4は広い範囲で有用で、安全にデプロイされるAIシステムへの大きな一歩を示しています。
Hello Dolly!
LLMが大きな注目を浴びている中、我々Databricksでは皆様自身で安価にLLMを構築できるようにオープンソース大規模言語モデルDollyを公開しました!
関連資料
-
ChatGPTサイトの翻訳
-
GPT-4 Technical Reportの翻訳
-
GPT-4 System Cardの翻訳
-
GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Modelsの翻訳