こちらの前半のTechnical Reportの翻訳です。System Cardの翻訳はこちら。
Databricksのユーザー会でChatGPTの勉強会やります。
注意
- 本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
- 脚注、参考文献、Appendixなどは本文をご覧ください。
アブストラクト
画像とテキストのインプットを受け取り、テキストのアウトプットを生成することができる大規模かつマルチモーダルなモデルであるGPT-4の開発を報告します。多くの現実世界のシナリオにおいて人間より能力が劣りますが、GPT-4は司法試験をテスト受験者のトップ10%の点数で通過したことを含み、さまざまな専門的、学術的なベンチマークで人間レベルのパフォーマンスを示しています。GPT-4は文書内の次のトークンを予測するように事前学習したトランスフォーマーベースのモデルです。トレーニング後の調整プロセスによって、現実に基づく度合いや予期された挙動への準拠を示す指数における改善につながりました。このプロジェクトのコアコンポーネントは、さまざまな範囲の規模において、予測できるように挙動するインフラストラクチャと最適化手法の開発でした。これによって、GPT-4の計算量の1/1000だけでトレーニングされたモデルに基づくGPT-4のパフォーマンスのいくつかの側面を正確に予測できるようになりました。
1 イントロダクション
このテクニカルレポートは、画像とテキストのインプットを受け取り、テキストのアウトプットを生成することができる大規模かつマルチモーダルなモデルであるGPT-4を説明します。このようなモデルは、対話システム、テキスト要約、機械翻訳のようなさまざまなアプリケーションで活用できる可能性があるため、重要な研究領域となっています。このため、ここ数年、これらは非常に大きな興味の対象となっており、大きな進歩を収めています[1-28]。
このようなモデルを開発する主要なゴールの一つは、自然言語、特により複雑かつ微妙な違いのあるシナリオにおける自然言語をモデルが理解、生成する能力を改善することです。このようなシナリオにおいて能力をテストするために、GPT-4は当初は人間のために設計されたさまざまな試験によって評価されました。これらの評価において、このモデルは非常にうまく動作し、多くの場合、人間の受験者の大部分を上回りました。例えば、司法試験において、GPT-4はテスト受験者のトップ10%に入るスコアを達成しました。これは、最下位10%だったGPT-3.5とは対照的です。
従来のNLPベンチマークスイートにおいては、GPT-4は以前の大規模言語モデルと最も最先端のシステム(これらは多くの場合ベンチマーク特化のトレーニングや手動によるエンジニアリングがなされています)を上回ります。57の主題をカバーする複数選択の英語の質問であるMMLUベンチマーク[29, 30]においては、GPT-4は英語で大きな差を持って既存のモデルを上回っただけでなく、他の言語においても強力なパフォーマンスを示しました。翻訳されたMMLUのバリエーションにおいては、GPT-4は検討対象の26言語のうち24言語において英語で最も優れていたモデルを上回りました。後ほどのセクションでは、これらのモデルの能力の結果とモデルの安全性の改善と結果を議論します。
また、このレポートはプロジェクトにおける主要な課題であるさまざまな規模で予測可能に動作するディープラーニングのインフラストラクチャと最適化手法についても議論します。これによって、トレーニングの信頼度を高めるために最後の実行に対してテストされた(同様の方法でトレーニングされた小規模トレーニングに基づく)GPT-4に予想されるパフォーマンスに対する予測を行えるようになりました。
この能力にも関わらず、GPT-4には以前のGPTモデルと同様の制限があります[1, 31, 32]: 完全に信頼できるものではなく(例: 「妄想」に苦しむことがあります)、限定的なコンテキストウィンドウを持ち、経験から学びません。GPT-4のアウトプットを活用する際、特に信頼性が重要な文脈においては注意が必要です。
GPT-4の能力と制限は重要かつ新たな安全性の課題を生み出しており、潜在的な社会への影響を考えると、これらの課題に対する注意深い研究が重要な研究領域になると信じています。このレポート(Appendixの後)には、バイアス、不正な情報、過度の信頼、プライバシー、サイバーセキュリティ、増殖などに関して我々が予期しているリスクのいくつかを説明する膨大なシステムカードを含めています。また、GPT-4の開発による潜在的な害を軽減するために行った、ドメイン専門家による敵対的テストやモデル支援の安全パイプラインを含む介入の内容についても説明します。
2 本テクニカルレポートのスコープと制限
このレポートはGPT-4の能力、制限、安全に関する属性にフォーカスします。GPT-4は、公開データとサードパーティからライセンスされたデータの両方を用いて、文書内の次のトークンを予測するように事前トレーニングされたトランスフォーマースタイルのモデル[33]です。そして、このモデルは人間のフィードバックによる強化学習(RLHF)を用いてファインチューンされています[34]。GPT-4のような大規模モデルにおける競争の激しい世界や安全性を考慮して、このレポートには(モデルサイズを含む)アーキテクチャ、ハードウェア、トレーニング計算処理、データセットの構成、トレーニング方法の詳細は含めていません。
我々は自分たちのテクノロジーに対する独立的な監査にコミットしており、このリリースに同梱されているシステムカードで、この領域におけるいくつかの初期ステップが共有されています。さらなる透明性の科学的価値に対して、競争優勢性と上述の安全性の検討事項にどのような重み付けをするのかに関してアドバイスできるさらなるサードパーティに対して、さらに技術的詳細を提供できるように計画しています。
3 予測可能なスケーリング
GPT-4の大きな焦点は、予測できるようにスケールするディープラーニングスタックの構築でした。これの大きな理由は、GPT-4のような非常に大規模なトレーニングの実行においては、広範囲のモデル固有のチューニングを行うことが不可能だったためでした。これに対応するために、さまざまなスケールで非常に予測可能な挙動をするインフラストラクチャと最適化手法を開発しました。これらの改善によって、1,000倍から10,000倍少ない計算量でトレーニングされた小規模なモデルからGPTのパフォーマンスのいくつかの側面を予測できるようになりました。
3.1 損失の予測
適切にトレーニングされた大規模言語モデルの最終的な損失は、モデルのトレーニングに使用された計算量において、冪乗則で近似されると考えられます[35, 36, 2, 14, 15]。
我々の最適化インフラストラクチャのスケーラビリティを検証するために、同じ方法論を用いていますがGPT-4より最大で10,000倍少ない計算量を用いてトレーニングしたモデルから(Henighanらと同様に[15])還元不可能な損失項とスケーリング則: $L(C) = aC^b + c$をフィッティングすることで、我々のコードベースにおけるGPT-4の最終的な損失を予測しました。この予測は、いかなる部分的な結果を用いることなしに、処理開始後すぐに実行されました。フィッティングされたスケール則は、高い精度でGPT-4の最終的な損失を予測しました(図1)。
3.2 HumanEvalにおける能力のスケーリング
トレーニング前にモデルの能力に対する感触を持つことで、調整、安全性、開発における意思決定を改善することができます。最終的な損失を予測することに加え、能力をより解釈できるメトリクスを予測する方法論を開発しました。このようなメトリックの一つがHumanEvalデータセット[37]の通過率であり、さまざまな複雑度のPython関数を合成する能力を測ります。最大1,000倍の計算量でトレーニングされたモデルから外挿することで、HumanEvalデータセットのサブセットで通過率を予測することができました(図2)。
HumanEvalの個々の問題に対しては、時には大幅にパフォーマンスが悪くなることがあります。これらの課題に関わらず、近似の冪乗則の関係性$-E_P[log(pass\_rate(C))]=α∗C^{−k}$を見つけ出しました。
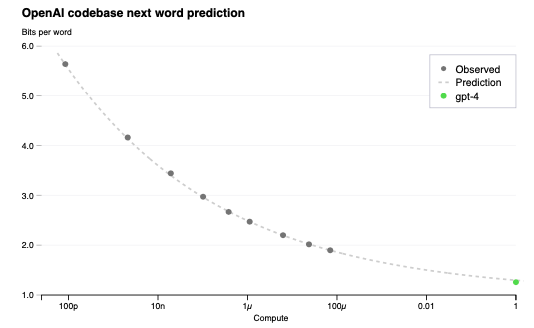
図1 GPT-4とより小規模なモデルのパフォーマンス。メトリックは内部のコードベースから導出されたデータセットの最終的な損失です。これは、トレーニングセットには含まれていない便利で大規模なコードトークンのデータセットです。異なるトレーニング計算処理量において、他の指標よりもノイズが少ない傾向があるため損失に着目することにしました。(GPT-4を除く)小規模なモデルに対する冪乗則のフィットはドットの線で示されています。このフィットは正確にGPT-4の最終的な損失を予測しています。x軸はGPT-4が1になるように正規化されたトレーニング計算量です。
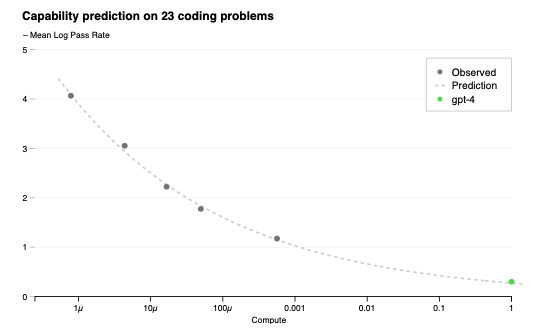
図2 GPT-4とより小規模モデルのパフォーマンス。メトリックはHumanEvalデータセットのサブセットに対する通過率の平均対数です。(GPT-4を除く)小規模なモデルに対する冪乗則のフィットはドットの線で示されています。このフィットは正確にGPT-4の最終的な損失を予測しています。x軸はGPT-4が1になるように正規化されたトレーニング計算量です。
ここでは、kとαは正の定数であり、Pはデータセットの問題のサブセットです。我々はこの関係性はこのデータセットのすべての問題で成り立つという仮説を立てました。実際には、非常に低い通過率は推定が困難あるいは不可能なので、ある程度大きなサンプルの予算がある中で、少なくともすべてのモデルによってすべての問題が解かれるように問題PとモデルMを制限しました。
トレーニング前に利用できる情報のみを用いて、トレーニングが完了する前にHumanEvalに対するGPT-4のパフォーマンスを登録しました。15の最も困難なHumanEvalの問題以外の全ては、より小規模なモデルのパフォーマンスに基づいて6つの難易度のバケットに分割されました。3番目に簡単なバケットの結果が図2に示されており、いくつかのより小規模なモデルの$log(pass\_rate)$を正確に推定できるHumanEval問題のサブセットに対しては非常に正確に結果の予測を行うことができたことを示しています。他の5つのバケットに対する予測も、最も簡単なバケットでGTP-4のパフォーマンスが下回っている例外を除き、概ねうまく実行されています。
特定の能力は依然として予測が困難です。例えば、Inverse Scaling Prize [38]が提案するいくつかのタスクでは、関数がスケールするとパフォーマンスが低下します。最近のWeiらによる結果[39]と同様に、図3のHindsight Neglect [40]と呼ばれるタスクの一つが示すように、GPT-4がこのトレンドと逆行していることを発見しました。
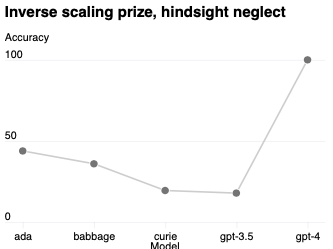
図3 Hindsight NeglectタスクにおけるGPT-4と小規模モデルのパフォーマンス。y軸に精度が表示されており、高いほど優れています。ada、babbage、curieはOpen AI APIで利用できるモデル[41]を参照しています。
我々は未来を正確に予測する能力は安全性のために重要であると信じています。前進する過程で、我々はこれらの方法を洗練し、大規模モデルのトレーニングを開始する前にさまざまな能力に対するパフォーマンス予測を登録することを計画しており、これがこの分野における一般的なゴールになることを望んでいます。
4 能力
我々はGPT-4を、本来は人間向けに設計された司法試験を含む広範なベンチマークでテストしました。これらの試験向けに特定のトレーニングは行っていません。この試験の問題の一部はトレーニングの際にモデルによって認識されています。それぞれの試験に対して、これらの質問が除外されたバリエーションを実行しており、2つに関しては低いスコアをレポートしています。我々はこの結果が代表的なものであることを信じています。汚染に関する詳細(方法論と試験ごとの統計情報)についてはAppendix Cをご覧ください。
試験は公開されているマテリアルからの引用です。試験の質問には複数選択とフリー回答の質問が含まれています。それぞれのフォーマットで別々のプロンプトを設計し、画像を必要とする質問には入力に画像を含めました。評価環境は、試験の評価セットに対するパフォーマンスに基づいて設計され、ホールドアウトされたテスト用試験で最終的な結果を報告しました。全体的なスコアは、それぞれの試験に対して公開されている方法論を用いて複数選択とフリー回答の質問のスコアを組み合わせることで決定されました。それぞれの全体的なスコアが対応するパーセンタイルを推定してレポートしました。
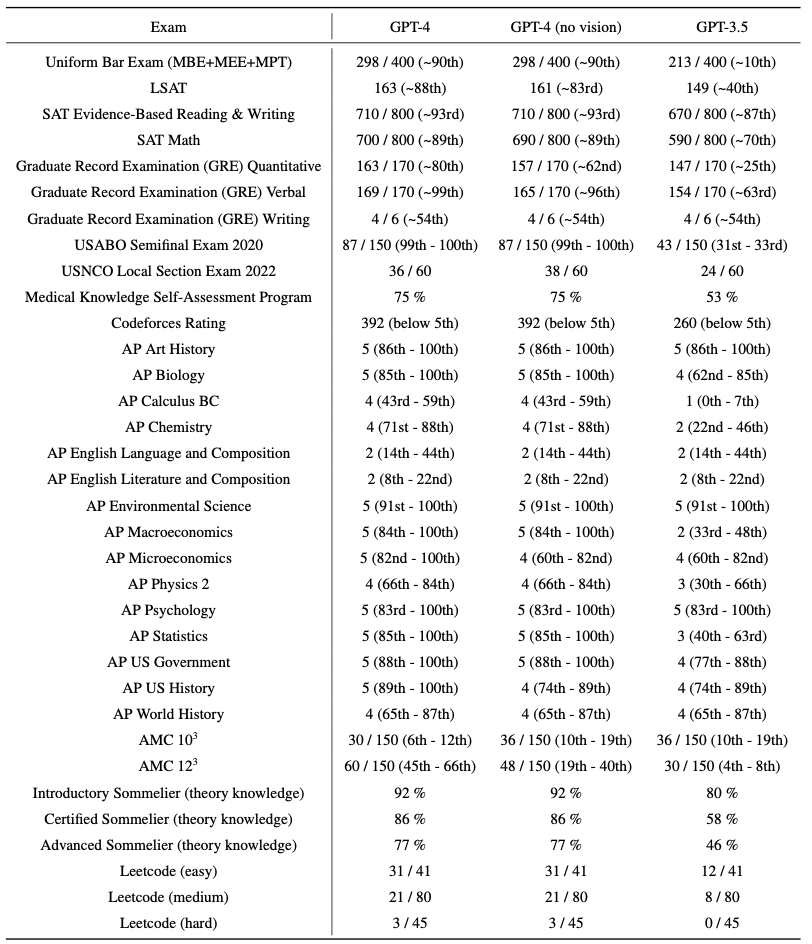
表1 学術的、専門的試験に対するGPTのパフォーマンス。それぞれのケースにおいて、リアルな試験の条件とスコアリングをシミュレーションしました。試験固有の指示に基づて採点される最終スコアとGPT-4のスコアを達成したテスト受験者のパーセンタイルを報告しました。
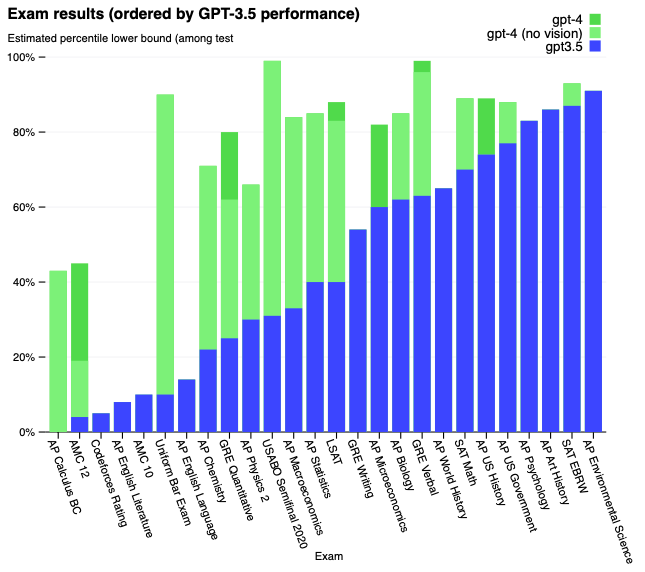
図4 学術的、専門的試験に対するGPTのパフォーマンス。それぞれのケースにおいて、リアルな試験の条件とスコアリングをシミュレーションしました。GPT-3.5のパフォーマンスに基づいて低い順から高い順に試験が並び変えられています。GPT-4はテストされた試験のほとんどでGPT-3.5を上回っています。保守的になるために、パーセンタイルのレンジの最も低い部分をレポートしていますが、これによって非常に幅広のスコアリングのビンを持つAP試験ではいくつかのアーティファクトを生成しています。例えば、GPT-4はAP Biologyでとりうる最高のスコア(5/5)を得ていますが、これはテスト受験者の15パーセントがそのスコアを達成したため、85番目のパーセンタイルとしてプロットに表示されているのみです。
GPT-4はこれらの専門的、学術的試験の大部分で人間レベルのパフォーマンスを示しています。特筆すべきこととして、テスト受験者のトップ10%のスコアでUniform Bar Examinationのシミュレーションされたバージョンを通過しています(表1、図4)。
試験におけるモデルの能力は、主に事前トレーニングプロセスから得られ、あまりRLHFの影響を受けていないように見えます。複数選択問題においては、GPT-4モデルとRLHFモデルの両方は、テストした試験において平均として同等のパフォーマンスを示しています(Appendix Bをご覧ください)。
また、言語モデルを評価するために設計された従来のベンチマークでも、事前学習したベースのGPT-4モデルを評価しました。レポートするそれぞれのベンチマークにおいて、トレーニングセットに出現するテストデータの汚染チェックを実行しました(ベンチマークごとのか完全な詳細についてはAppendix Dをご覧ください)。GPT-4を評価する際にはすべてのベンチマークにおいて数点のプロンプト[1]を用いました。
GPT-4は、多くの場合ベンチマーク固有の工夫や追加のトレーニングプロトコルが用いられた以前の最先端(SOTA)システムを含む既存の言語モデルを大きく上回っています(表2)。
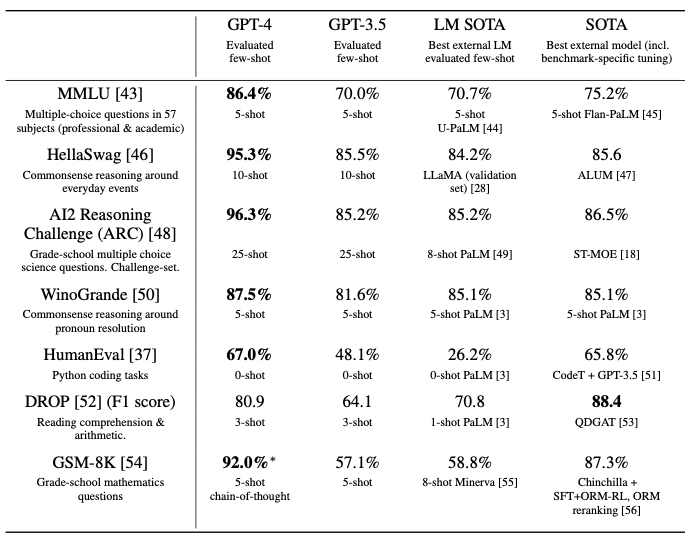
表2 学術的ベンチマークにおけるGPT-4のパフォーマンス。我々はGPT-4をベストのSOTA(ベンチマーク固有のトレーニング含む)や、数ショットを評価したLMのベストSOTAと比較しました。GPT-4はすべてのベンチマークで既存のLMを上回っており、DROP以外のすべてのデータセットでベンチマーク固有のトレーニングをしたSOTAも打ち負かしています。それぞれのタスクにおいて、評価のために用いた数ショット手法でGPT-4のパフォーマンスをレポートしています。GSM-8Kにおいては、GPT-4の事前トレーニングミックスのトレーニングセットの一部を含めており(Appendix Eをご覧ください)、複数選択問題に関しては、モデルに対するすべての回答(ABCD)をモデルに示し、人間がこのような問題を解くのと同様に回答の文字を選択するように指示しています。
多くの既存のMLベンチマークは英語で記述されています。他の言語におけるGPT-4の能力をまず理解するために、我々は57個の主題からなる複数選択問題のスイートであるMMLUベンチマーク[29, 30]をAzure Translateを用いてさまざまな言語に翻訳しました(サンプルの翻訳とプロンプトについてはAppendix Fをご覧下さい)。我々は、Latvian、Welsh、Swahiliのようにリソースの少ない言語を含む我々がテストした言語の大部分でGPT-3.5の英語のパフォーマンスや既存の言語モデル(Chinchilla [2] や PaLM [3]) をGPT-4が上回っていることを発見しました(図5)。
GPT-4はユーザーの意図に従う能力において、以前のモデルを継続的に改善します[57]。ChatGPT[58]とOpenAI API[41]に送信された5,214のプロンプトのデータセットにおいて、GPT-4によって生成されたレスポンスは、70.2%のプロンプトにおいてGPT-3.5よりも望ましいものとなりました。
我々は、サンプルごとのパフォーマンスを調査しつつGPT-4のようなモデルを評価するためのベンチマークを作成、実行するためのフレームワークであるOpenAI Evalsをオープンソース化します。Evalsは既存のベンチマークと互換性があり、開発におけるモデルのパフォーマンスを追跡するために活用することができます。我々は、より後半な失敗モードやより困難なタスクセットを表現するために、これらのさまざまなベンチマークを時間をかけて増やしていくことを計画しています。
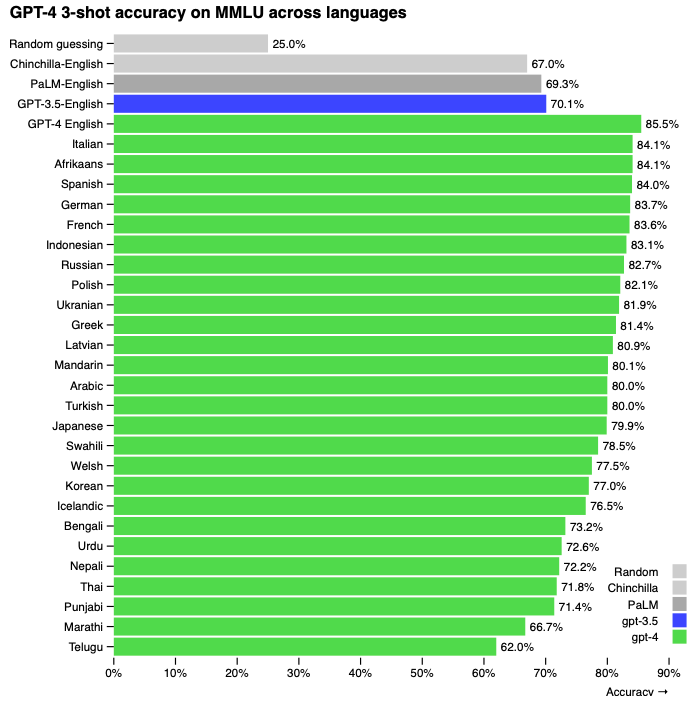
図5 MMLUにおける英語の以前のモデルと比較したさまざまな言語でのGPT-4のパフォーマンス。GPT-4はLatvian、Welsh、Swahiliのようにリソースの少ない言語を含む我々がテストした言語の大部分で既存の言語モデル[2, 3]を上回っています。
4.1 ビジュアルのインプット
GPT-4はテキストのみの環境と並行して、画像とテキストの両方から構成されるプロンプトを受け入れます。これによって、ユーザーは任意の画像、言語タスクを指定することができます。特に、このモデルは任意の形で組み合わせられたテキストと画像から構成されるインプットを受けて、テキストのアプトプットを生成します。テキストや写真、図、スクリーンショットを含む文書を含むさまざまなドメインにおいて、GPT4はテキストのみのインプットで動作するのと同様の能力を示しました。GPT-4の画像入力のサンプルを表3に示します。言語モデル向けに開発された標準的なテスト時のテクニックは、画像とテキストの両方を用いた場合でも同様に効果的です。サンプルに関してはAppendix Gをご覧ください。
学術的画像ベンチマークの限定的なセットに対する暫定的な結果に関しては、GPT-4のブログ記事[59]をご覧ください。今後の取り組みにおいて、GPT-4の視覚的能力の詳細をリリースすることを計画しています。

表3 GPT-4の視覚的入力能力をデモンストレーションするプロンプトのサンプル。プロンプトはGPT-4が回答できる複数のパネルと画像に関する質問から構成されています。
5 制限
この能力があるにも関わらず、GPT-4は以前のGPTモデルと同様の制限があります。最も重要なことですが、依然としてこれは完全に信頼できるものではありません(事実を「妄想」し、理由づけに失敗します)。特に高リスクな文脈においては、言語モデルのアウトプットを使用する際には、アプリケーション固有の要件にマッチする正確なプロコル(人間によるレビュー、追加の文脈による補強、高リスクな環境での利用を取りやめるなど)を用いて、非常に注意する必要があります。詳細はシステムカードをご覧ください。
GPT-4は以前のGPT-3.5と比べて妄想は劇的に減っています(継続的イテレーションで自分自身を改善し続けています)。GPT-4は、我々の内部的、攻撃的に設計された事実性の評価で最新のGPT-3.5よりも19%高いスコアを出しています(図6)。
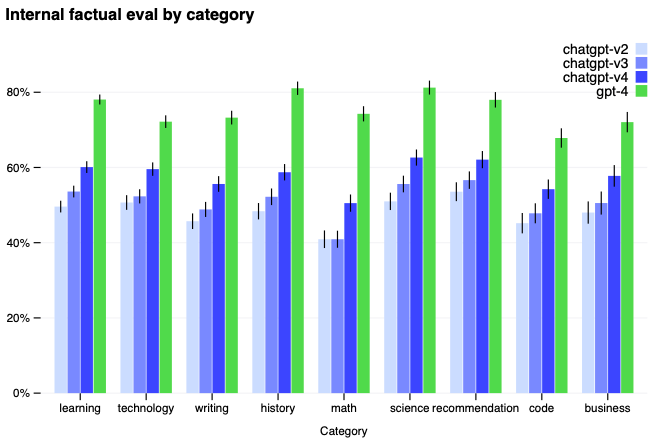
図6 内部的に設計された9つの攻撃的事実性評価におけるGPT-4のパフォーマス。y軸は精度であり、高いほど優れています。1.0の精度は、モデルの回答は評価においてすべての質問に対する人間の理想的な回答と一致したと判定されたことを意味します。我々は、GPT-4をGPT-3.5をベースとした以前の3つのChatGPTバージョンと比較しました。GPT-4はすべてのトピックにおいて劇的なゲインを得つつ、最新のGPT-3.5モデルよりも19%改善されています。
GPT-4は、モデルが攻撃的に選択された不正な文から事実を分離する能力をテストするTruthfulQA [60]のような公開ベンチマークでも進歩を見せています(図7)。これらの質問は、統計的に目立ちますが事実として正しくない回答とペアになっています。このタスクではGPT-4のベースモデルは、GPT-3.5よりも若干優れているだけでしたが、RLHFの事後トレーニングによって、GPT-3.5よりも大きな改善を認めました。表4では正しい回答と間違った回答の両方を示しています。GPT-4は一般的な言い回し(you can’t teach an old dog new tricks)を選択することに抵抗しますが、依然としてちょっとした詳細を見逃すことがあります(Elvis Presleyは役者の息子ではないので、Perkinsが正しい答えです)。
GPT-4は一般的に、2021年9月にカットオフされた大部分の事前トレーニングデータ以降に発生したイベントに対する知識が欠けており、経験から学びません。非常に多くのドメインで適しているように見えないシンプルな理由づけのエラーを起こすことがあり、ユーザーからの明らかな偽の文を受け入れることに関して極度に騙されやすいことがあります。生成するコードにセキュリティ脆弱性を導入してしまうといような、人間と同様に困難な問題で失敗することがあります。
また、GPT-4は予測を誤ることがあり、間違いを起こしそうな際にダブルチェックを行いません。興味深いことに、事前トレーニング済みモデルは高度に調整されています(回答における予測信頼度は一般的に正しい確率とマッチします)。しかし、トレーニング後のプロセスの後は、調整は減少します(図8)。

表4 TruthfulQAにおけるGPT-4の正しい回答と誤った回答の例
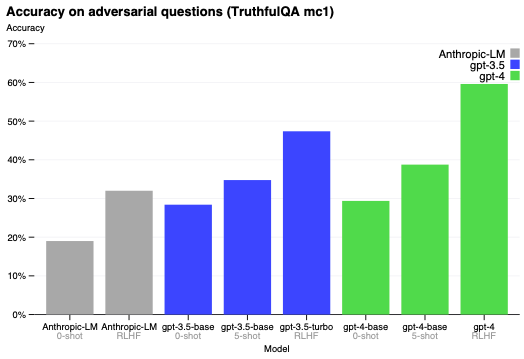
図7 TruthfulQAにおけるGPT-4のパフォーマンス。y軸が精度であり、高いほど優れています。ゼロショットのプロンプト、数ショットのプロンプト、RLHFファインチューニング後でGPT-4を比較しました。GPT-4はGPT-3.5とBaiらによるAnthropic-LM[61]を上回っています。
GPT-4の出力には、我々が修正しようとしていますが、完全に特徴づけを行い管理するにはしばらくの時間を要するバイアスが含まれています。我々は、GPT-4と我々の構築する他のシステムがユーザーのさまざまな価値を反映する合理性のあるデフォルトの挙動をするようにし、これらのシステムがある程度広範な境界内でカスタマイスできるようにし、これらの教会がどのようなものであるべきかに関する幅広いインプットを得ようと考えています。詳細はOpenAI[62]をご覧ください。
6 リスクと対策
我々はGPT-4の安全性と調整を改善するために膨大な労力を費やしました。こちらでは、攻撃的テストやレッドチーミングのためのドメイン専門家の活用や、我々のモデルアシスト安全性パイプライン[63]、以前のモデルよりも改善された安全性メトリクスをハイライトします。
ドメイン専門家による攻撃的テスト: GPT-4は、害のあるアドバイス、バグのあるコード、不正確な情報の生成といった小規模言語モデルと同様のリスクを孕んでいます。しかし、GPT-4のさらなる能力によって、新たなリスクが浮上しています。これらのリスクの程度を理解するために、長期的なAI調整のリスク、サイバーセキュリティ、バイオリスク、国際的セキュリティのようなドメインから50人以上の専門家とエンゲージしてモデルに対する攻撃的テストを行いました。彼らの発見によって、評価のためにニッチな専門性を必要とする高リスク領域でのモデルの挙動をテストすることができ、power seeking [64]のように非常に高度化されたAIでは適切となるであろうリスクを評価することができました。彼ら専門家から収集された推奨事項とトレーニングデータは、モデルの対策と改善の入力となりました。例えば、危険な化学薬品の合成方法に対するリクエストを拒否するGPT-4の能力を改善するために追加のデータを収集しました(表5)。
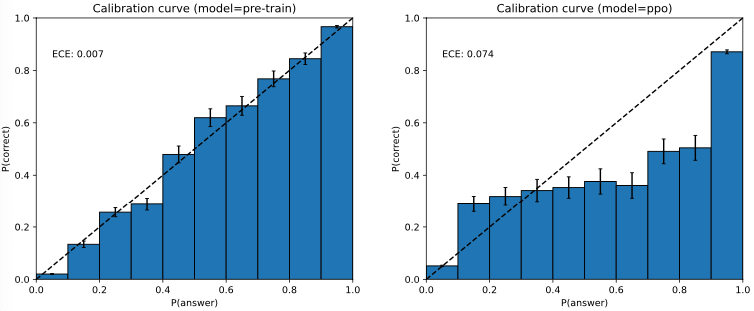
図8 左: MMLUデータセットのサブセットにおける事前トレーニング済みGPT-4モデルのキャリブレーションプロット。x軸はそれぞれの質問に対するA/B/C/Dの選択のモデルの自信度(logprob)に対応するビンであり、y軸はそれぞれのビンにおける精度です。点線の対角線は完璧なキャリブレーションを表現しています。右: 同じMMLUのサブセットにおけるトレーニング後のGPT-4モデルのキャリブレーションプロット。トレーニング後は劇的にキャリブレーションを損なっています。

表5 専門家レッドチーム: さまざまなモデルのプロンプトとコンプリーション
モデルアシストの安全性パイプライン: 以前のGPTモデルのように、ユーザーの意図に合わせたレスポンスを生成するように、人間フィードバックを伴う強化学習(RLHF) [34, 57]を用いてモデルの挙動をファインチューンしました。しかし、RLHFの後で我々のモデルは依然として危険な入力に対して脆く、安全、危険な入力の両方で望まれない挙動を示すことがあります。これらの望まれない挙動は、RLHFパイプラインの報奨モデルのデータ収集部分で、ラベル付担当者への指示が不正確であった場合に生じることがあります。危険な入力が与えられた際、犯罪を犯すアドバイスのようにモデルが望まれないコンテンツを生成することがあります。さらに、モデルは安全な入力に対して極端に注意深くなり、差し障りのないリクエストを拒否したり、過度に避けるようになることがあります。我々のモデルがよりきめ細かいレベルで適切な挙動をするようにするために、ツールとしての我々のモデルに大きく依存しています。安全に対する我々のアプローチは2つの主要コンポーネント、安全に即したRLHFトレーニングプロンプトの追加セットとルールベースの報奨モデル(RBRM)から構成されています。
我々のルールベース報奨モデル(RBRM)は、一連のゼロショットGPT-4分類器です。これらの分類器は、害のあるコンテンツの生成を拒否したり、問題のないリクエストを拒否しないなど、適切な挙動をすることを目的としたRLHFファインチューニングの過程で、GPT-4のポリシーモデルに追加の褒賞シグナルを提供します。

表6 許可されないカテゴリーにおいて改善された拒否を行うためのプロンプトとコンプリーションのサンプル

表7 許可されるカテゴリーにおいて削減された拒否のプロンプトとコンプリーションのサンプル。注意: これらの生成結果は変動し、モデルが常に上の結果を生成するわけではありません。
RBRMは3つの入力を受け取ります: プロンプト(オプション)、ポリシーモデルからのアウトプット、どのようにアウトプットを評価すべきかに関する人間が記述する指示(例: 複数選択スタイルにおける一連のルール)です。そして、RBRMは指示に従ってアウトプットを分類します。例えば、我々はモデルがレスポンスを以下のいずれかに分類する指示を指定することができます: (a) 希望のスタイルでの拒否、(b) 希望しないスタイルでの拒否(例: 回避的、とりとめのない話)、(c) 許可されないコンテンツを含む、(d) 安全な拒否しないレスポンス。そして、不法なアドバイスのような害のあるリクエストを行う一連の安全性検証用のトレーニングプロンプトにおいて、GPT-4がこれらのリクエストを拒否した際には褒賞を与えます。逆に、安全で回答可能であることが保証されたプロンプトのサブセットでリクエストを拒否しなかった際にもGPT-4に褒賞を与えます。このテクニックは、Glaeseら[65]やPerezら[66]による成果に関連しているものです。計算に最適なRBRMの重み付けのような他の改善点と組み合わせ、改善したい領域をターゲットとした追加のSFTデータを提供することで、我々のモデルよより望ましい挙動に近づけることができました。
安全性メトリクスの改善: 我々の対策によって、数多くのGPT-4の安全性属性を劇的に改善しました。我々は、GPT-3.5と比べてモデルが許可されないコンテンツ(表6)に対するリクエストを回答する傾向を82%削減し、GPT-4は我々のポリシーに沿って機微なリクエスト(医療に関するアドバイスや自傷、表7)に対して、さらに29%頻繁に反応するようになりました(図9)。RealToxicityPromptsデータセット[67]においては、GPT-4はこの時点で0.73%のみで毒物の生成法を出力し、GPT-3.5は6.48%で毒物のコンテンツを生成しました。
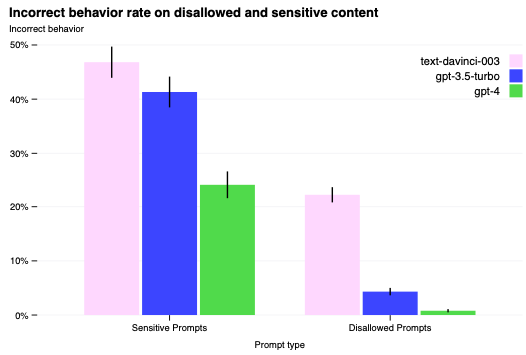
図9 センシティブあるいは許可されないプロンプトにおける間違った挙動の割合。値が少ないほど優れています。GPT-4 RLHFは以前のモデルよりもはるかに誤った挙動が削減されています。
全体として、我々のモデルレベルの介入によって、悪い挙動を引き出す難易度は上昇しましたが、行うこと自体は依然として可能です。例えば、依然として我々の利用ガイドラインに違反するコンテンツを生成するための「ジェイルブレイク」(例: 攻撃的システムメッセージ、詳細はシステムカードの図10をご覧ください)は存在しています。これらの制限が存在する限り、乱用のモニタリングや高速ないてレーティブモデル改善のパイプラインのようなデプロイ時安全技術で補完することが重要となります。
GPT-4と後継のモデルは、利益のある方法、害のある方法の両方で社会に大きな影響をもたらすポテンシャルを持っています。可能性のあるインパクトを評価し、理解する方法を改善し、未来のシステムで生じる可能性のある危険な能力の評価方法を確立するために、外部の研究者とコラボレーションしています。間も無く我々は、社会がAIの影響に備えるためのステップの推奨事項や予測されるAIの経済的インパクトに対する初期考察を公開する予定です。
7 まとめ
我々はGPT-4を、特定の困難な専門的、学術的ベンチマークにおける人間レベルのパフォーマンスをもつ大規模、マルチモーダルモデルとして特徴づけます。GPT-4は一連のNLPタスクにおいて既存の大規模言語モデルを上回っており、報告されている(多くの場合タスク固有のファインチューニングを行なっている)最先端システムの大部分より優れています。多くの場合英語で計測されていますが、多くの別の言語においても改善された能力を確認しました。予測可能なスケーリングによって、どのようにGPT-4の損失と能力の正確な予測を可能としているのかをハイライトしました。
GPT-4は増加する能力によって新たなリスクを生み出し、その安全性と調整を理解し、改善するために取られた手法と結果のいくつかを議論しました。多くの作業が残っていますが、GPT-4は広い範囲で有用で、安全にデプロイされるAIシステムへの大きな一歩を示しています。
関連資料
-
ChatGPTサイトの翻訳
-
GPT-4 Technical Reportの翻訳
-
GPT-4 System Cardの翻訳
-
GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Modelsの翻訳