こちらのの翻訳です。前後編の後編です。前編はこちら。
Databricksのユーザー会でChatGPTの勉強会やります。
注意
- 本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
- 脚注、参考文献、Appendixなどは本文をご覧ください。
4 結果
汎用技術は比較的レアであり、それらの浸透度合い、継続的な改善、膨大な共同発明や副次的結果によって特徴づけられます(Lipsey et al., 2005)。GPT(事前学習済み文章生成型トランスフォーマー)の労働市場へのインパクトの評価は、全体的な生産性要因や資本投入のポテンシャルを考慮していないので限定的なものです。これらの労働者に対する影響に加え、GPTはこれらの次元にも影響をもたらす可能性があります。
このステージでは、特定のGPTの評価指標は他のものよりも評価が容易です。例えば、これらのモデルの能力の長期的インパクトや、補完的アプリケーションやシステムの成長の評価は長期的に見てより現実性を増していきます。この初期ステージにおける我々の主要なフォーカスは、アルゴリズムのカテゴリーとして機械学習のGPTのポテンシャルを評価するために仕事への応募を通じた機械学習の拡散に関する(Goldfarb et al., 2023)の分析と同様にに、GPT言語モデルが経済に広範な影響をもたらすという仮説を検証することです。仕事への応募を用いたり、一般的な機械学習を研究するのではなく、人間とGPTのアノテーションの両方を用いたタスク評価アプローチによって、GPTのインパクトが類似タスクや類似職業の小規模セットに限定されるのかどうかを明らかにするのかを検証することです。
我々の所見は、タスクレベルの能力をベースとして、GPTはアメリカ経済における様々な職業に大きな影響を及ぼし、汎用技術の鍵となる属性を備えていることを示しています。以下のセクションでは、様々なロールと賃金の構造における結果を議論します。アメリカ経済における業界の相対的エクスポージャーのその他の結果についてはAppendix Dをご覧ください。
4.1 サマリー統計
これらの計測におけるサマリー統計は表3にあります。人間のアノテーションとGPT-4のアノテーションの両方が、平均的な職業レベル𝛼の値が0.14と0.15の間にあり、中央値の職業においてはタスクの15%がGPTの影響を受けることを示しています。この数値は、𝛽では30%以上に増加し、𝜁では50%を上回ります。偶然ですが、人間とGPT-4のアノテーションもデータセットにある全体のタスクの15%と14%の間になっており、GPTの影響を受けるとしています。
𝛽の値に基づき、労働者の80%が最低一つのタスクがGPTの影響を受ける職業に属しており、労働者の19%がタスクの半分が影響を受けるとラベル付された職業に属していると推定しています。
影響を受けるタスクのポテンシャルは多岐に渡りますが、GPTはこのポテンシャルを完全に実現するためにより広範なシステムに組み込まれるべきです。汎用技術に共通するように、このような共同発明の障壁はGPTの経済的アプリケーションへの急速な拡散の障害となるかもしれません。さらに、特にモデルの能力が人間のレベルと等しい、あるいは上回る場合には、人間による監視の必要性を予測することは困難となります。人間位よる監視の要件は最初は導入や拡散のスピードを低下させるかもしれませんが、GPTやGPTで強化されたシステムのユーザーは、時と共に技術に精通するようになり、特にアウトプットをいつ信頼し、どのように信頼するのかを理解するようになるでしょう。

表3 我々の人間とモデルによるエクスポージャーデータのサマリー統計
4.2 賃金と雇用
図3では、経済に対するエクスポージャーの強度を示しています。最初のプロットでは労働者数の合計、二番目のプロットでは職業全体でのエクスポージャーを示しています。グラフのそれぞれの点は、y軸では労働者(職業)の推定パーセンテージ、x軸ではエクスポージャーのレベルを示しています。例えば、人間のアノテーターは労働者の2.4%が𝛼50-exposed、18.6%が𝛽50-exposed、49.6%が𝜁50-exposedであると決定しており、しきい値の50%は図2の右のプロットのx軸、労働者のパーセンテージはy軸から来ています。x軸の任意のポイントにおいて、𝛼と𝜁の間の垂直の距離は、GPTによる直接の影響に加えて、ツールやアプリケーションによる潜在的なエクスポージャーを示しています。エクスポージャーの分布は労働者と職業の両方で類似しており、職業に対する労働者の集中は、GPTやGPTで強化されたソフトウェアに対する職業への影響に高い相関がないことを示しています。
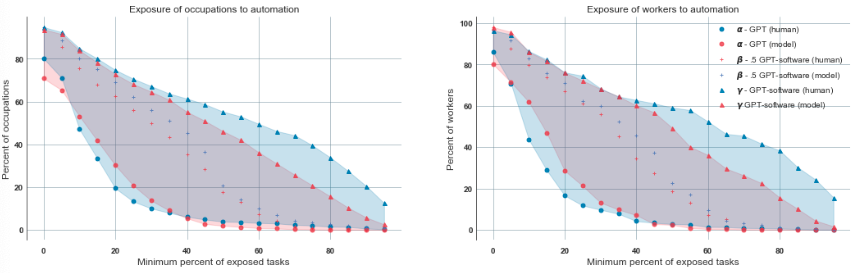
図3 経済に対するエクスポージャー強度、左は影響を受ける職業のパーセンテージで右は影響を受ける労働者のパーセンテージです。エクスポージャーの分布は労働者と職業の両方で類似しており、職業に対する労働者の集中は、GPTやGPTで強化されたソフトウェアに対する職業への影響に高い相関がないことを示しています。しかし、我々は特定ドメインにGPTで強化されたソフトウェアの開発に投資することで、より相関が高くなるであろうことを予測しています。
職業レベルで集計することで、図4に示すように人間のアノテーションとGPT-4のアノテーションは、定量的な類似性を示しており、相関する傾向があります。人間によるアノテーションはGPT-4のアノテーションと比較して、高収入の職業においてはエクスポージャーが非常に低いと推定しています。高いエクスポージャーの低収入の職業や、低いエクスポージャーの高収入の職業が多数ありますが、ビンわけされた散布図プロットの全体的なトレンドは、収入が高いほどGPTによる影響が増すことを示しています。
GPTによる潜在的な影響は、現在の雇用レベルと若干の相関があるように見えます。図4では、全体的なエクスポージャーに対する人間のレーティングとGPT-4のレーティングの両方は、職業レベルに集計され(y軸)、雇用数の合計の対数(x軸)と比較されています。どちらのプロットも、様々な雇用レベルにおけるGPTエクスポージャーに大きな違いを示していません。
4.3 スキルの重要性
このセクションでは、職業におけるスキル(ONETデータセットに記述)の重要性と我々のエクスポージャー指標の関係性を調査します。最初に、ONETで提供されているBasic Skills(スキルの定義はAppendix Bをご覧ください)を取得し、解釈しやすくなるように、それぞれの職業におけるスキルの重要度の指標を正規化します。そして、スキルの重要度とエクスポージャーの関係の強さを検証するためにエクスポージャー指標(𝛼, 𝛽, 𝜁)に対する回帰分析を行います。
我々の所見は、scienceとcritical thinkingのスキルの重要度は、エクスポージャーとの強い負の相関を示しており、これらのスキルを必要とする職業は現行の言語モデルによるインパクトを受けにくいことを示しています。逆にprogrammingやwritingのスキルはエクスポージャーとの強い正の相関を示しており、これらのスキルに関係する職業は、言語モデルによる影響を受ける可能性があることを示しています(詳細な結果は表5をご覧ください)。
4.4 参入障壁
次に、仕事のタイプによってエクスポージャーに違いがあるかどうかをより理解するために、参入障壁を検証します。そのようなプロキシーの一つは、「ジョブゾーン」と呼ばれるO*NETの職業レベルの説明文です。ジョブゾーンは、(a) その職業の職を得るために必要な教育レベル、(b) その仕事を行うために必要な関連する経験、(c) その仕事をこなうために必要なOJTの度合いで類似している職業をグルーピングします。ONETデータベースでは、5つのジョブゾーンがあり、ジョブゾーン1は最低限の準備(3ヶ月)を必要とし、ジョブゾーン5は最も多岐にわたる準備を要し、4年以上を必要とします。ジョブゾーンにおいて、収入の中央値が単調増加すると、必要とされる準備のレベルも増加し、ジョブゾーン1の中央値にいる労働者の収入は$30,230であり、ジョブゾーン5の中央値にいる労働者の収入は$80,980となります。図3と同様に図5では、エクスポージャーのしきい値ごとに労働者のパーセンテージをプロットしています。平均的に、ジョブゾーン1からジョブゾーン5を通じて、50%以上の𝛽エクスポージャーをもつ労働者のパーセンテージは、それぞれ0.00%(ジョブゾーン1)、6.11%(ジョブゾーン2)、10.57%(ジョブゾーン3)、34.5% (ジョブゾーン4)、26.45%(ジョブゾーン5)で𝛽を有していることを観測しました。

図4 人間とGPT-4の評価者によって評価された様々な職業における言語モデル(LLM)による影響を描いたビン分け散布図。これらのプロットは、職業レベルにおけるGPT(𝛽)のエクスポージャーと職業における合計雇用数の対数と職業の年間賃金の中央値を比較しています。いくつかの不一致が存在しますが、人間とGPT-4の評価は両方とも、賃金の高い職業ほどLLMの影響を受けることを示しています。さらに、我々の手法においては、数多くの低賃金の職業が高いエクスポージャーを示しています。平均エクスポージャースコアを計算する際、職業におけるコアのタスクは、補足的なタスクの2倍の重みが設定されています。雇用と賃金のデータは、2021年5月に実施されたBLS-OESサーベイを基にしています。

図5 職業に求められる教育レベル、OJTに基づいて分類される類似職業のグループである5つのジョブゾーンにおける職業の𝛽エクスポージャーのレーティング。
4.4.1 参入に必要な基本的教育
ジョブゾーンの導入によって、必要とされる教育 - これ自身がスキル獲得のプロキシーです - と、必要とされる準備の両方を考慮することになるので、これらの変数を解きほぐすデータを探しました。Bureau of Labor Statisticsの職業データ: 職業における"Typical Education Needed for Entry"と"On-the-job Training Required to Attain Competency"から2つの変数を活用しています。これらの要因を検証することで、労働力における潜在的な示唆でトレンドを明らかにすることを狙いとしています。教育やOJTトレーニングの要件のデータがない3,504,000人の労働者が存在しており、これらはサマリーの表からは除外されています。
我々の分析は、学士、修士、専門的学位を持つ個人は、公式の教育認定を持たない個人よりもGPTやGPTで強化されたソフトウェアの影響を受けることを示しています(表7をご覧ください)。興味深いことに、何かしらの大学教育を受けているが学位を持たない個人もGPTやGPTで強化されたソフトウェアの影響を受けることがわかりました。参入障壁を示している表を検証することで、エクスポージャーが最小の職業では、最長期間のトレーニング、競争力を得た後に(収入の中央値において)潜在的に低い給与が必要であることを発見しました。逆に、OJTを必要としない、あるいはインターンシップ/研修生のみが必要とされる仕事は、高い収入を実現するように見えますがGPTの影響が大きくなります。
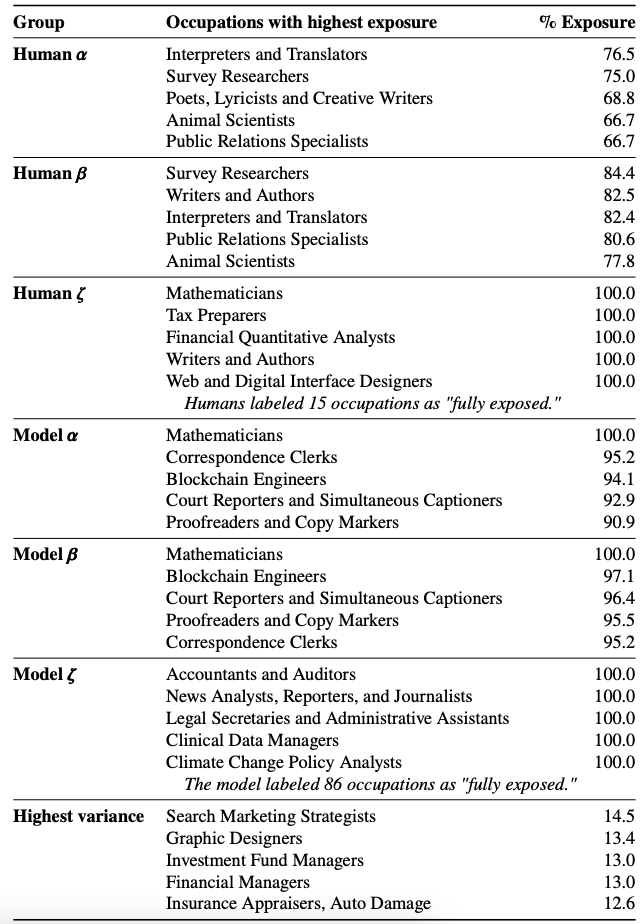
表4 それぞれの計測に沿って最も高いエクスポージャーを示す職業。最後の行では、最高の$𝜎^2$の値を示す職業を一覧しており、これらは脆弱性予測において最も高い変動性をもっていることを示しています。エクスポージャーのパーセンテージは、GPT(𝛼)、GPTで強化されたソフトウェア(𝛽や𝜁)によって影響を受ける職業のタスクの割合を示しており、エクスポージャーはタスクを完了するために要する時間が最低でも50%削減される駆動力として定義されています(exposure rubric A.1をご覧ください)。このようにして、このテーブルにリストされた職業は、GPTやGPTで強化されたソフトウェアはがそれらのタスクの大部分を完了するのに必要な時間を劇的に削減することが可能であると推定した職業ですが、これらの技術によってこれらのタスクが完全に自動化されるということを必ずしも意味しません。

表5 O*NET Skillsに対するエクスポージャー指標のOLS回帰の結果

表6 ジョブゾーンごとのGPTのエクスポージャー
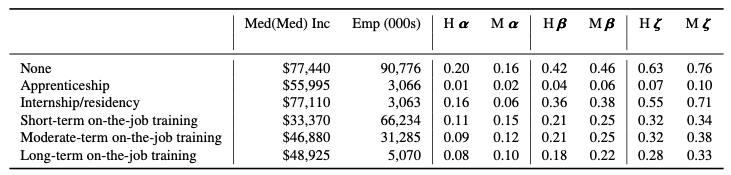
表7 仕事における競争力を得るのに必要なOJTのレベルでグルーピングされた職業ごとの平均エクスポージャーのスコア。エクスポージャースコアと共に、それぞれの職業の年間収入の中央値、それぞれのグループの合計労働者数を千人単位で表示しています。
5 計測結果の検証
5.1 以前の取り組みとの比較
本論文は、AIや自動化の進歩による職業へのエクスポージャーを検証するこれまでの数多くの実験、研究に基づいてことを進めることを狙いとしています。これまでの研究では、以下を含む様々な手法が用いられています:
- どの職業が、ルーチン vs. 非ルーチン、手動 vs. 認知タスクのコンテンツを持つのかを特徴付けるためにO*NETのような職業的なタクソノミーの活用(Autor et al., 2003; Acemoglu and Autor, 2011a)。
- タスクのテキスト記述を特許における技術的優位性の記述にマッピング。(Kogan et al., 2021; Webb, 2020)
- AIシステムの能力を職業的技能にリンクし、これらの技能が求められる職業に対するエクスポージャーの推定値を集計。(Felten et al., 2018, 2023)
- AIタスクのベンチマーク評価の結果を、認知科学文献から抽出された14の認知能力のセットを通じて、59の作業タスクにマッピング。 (Tolan et al., 2021)
- 専門家が高い自信を持つ一連のONETの職業に対する自動化ポテンシャルの専門家によるラベル付けと組み合わされた、その他のONETの職業の自動化ポテンシャルを推定するための確率論的分類器。(Frey and Osborne, 2017)
- 経済において労働者が完了しているアクティビティに対する「機械学習の適合性」(SML)を評価するための手順の構築(Brynjolfsson and Mitchell, 2017; Brynjolfsson et al., 2018, 2023)。
これらの以前の取り組みのサマリー統計のセットを表8に示しています。
本論文の方法論は、LLMの能力とO*NETデータベースで報告されている労働者のタスクとの重複部分を評価するための手順を構築することで、主にSMLアプローチをベースとしています。表9では、(Felten et al., 2018) (表の"AI Occupational Exposure Score")や(Frey and Osborne, 2017) (Frey & Osborne Automation)から得られた職業レベルのエクスポージャー指標に対する我々の新たなLLMエクスポージャー計測のOLS回帰の結果を示しており、これら3つの技術の全てのスコア(Webb, 2020)は、(Acemoglu and Autor, 2011a)や(Brynjolfsson et al., 2018, 2023) (SML)のルーチンの手動、認知的スコアで正規化されています。また、コントロールとして、最新のBLS Occupational Employment Surveyから得られた職業給与を年換算したものを用いています。本論文で示されている新たなスコアを表現する4つの出力変数は、これまでの取り組みによって予測されています。
GPT-4 Exposure Rating 1は、全体的な手順がGPT-4によって評価されていることに対応しており、完全なエクスポージャーのポテンシャルは1としてコードされ、エクスポージャーのポテンシャルがないことは0、部分的なエクスポージャー(我々のラベリングのスキームではE2となります)は0.5としてコードされています。GPT-4 Exposure Rating 2は、同様に全体的な影響としてスコアリングされますが、若干異なるプロンプトを用いています。2つのプロンプトでは結果は非常に類似しています。GPT-4 Automation Ratingは、LLMによる自動化エクスポージャーがない場合には0、完全な自動化エクスポージャーは1、レベル2、3、4はそれぞれ0.25、0.5、0.75とコーディングされる「T」手順を適用します。最後に、Human Exposure RatingはGPT-4 Exposure Rating 1と同じ手順を示していますが、論文の前半のセクションで議論したように、人間によるスコアリングが行われています。これらの結果は、上述の統計の𝛽セットに対応します。
それぞれのタイプの計測結果には一貫性があります。我々のLLMエクスポージャー計測と、ソフトウェアやAIをターゲットとした以前の計測方法には一般的に、統計的に大きな正の相関があることがわかりました。さらに、職業ごとのSMLエクスポージャースコアは、本論文で開発したエクスポージャースコアと大きな正の相関があることを示しており、同様のアプローチを行なっている2つの研究においてあるレベルの結合性を示しています。Webbのソフトウェア、AI特許ベースの計測、SML、正規化された(標準偏差で減算、除算された)ルーチン認知スコアすべてが、我々の計測方と何らかの形で正の相関を示しています。
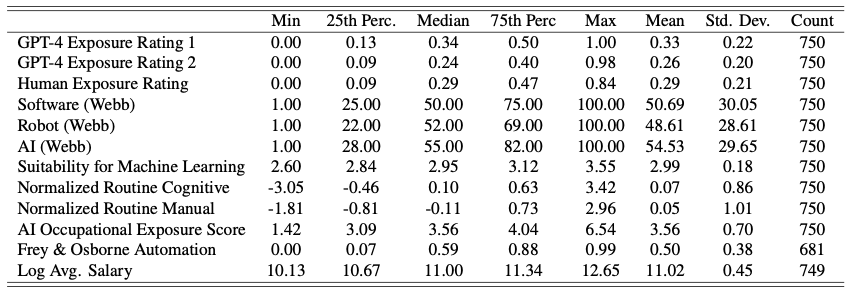
表8 AIと自動化に対する職業のエクスポージャーを計測するこれまでの取り組みのスイートのサマリー統計。この取り組みで新たにえら得た計測結果のサマリー統計も含めています。(Webb, 2020)のすべての計測結果、 (Acemoglu and Autor, 2011a)による正規化されたルーチン認知と手動スコア(職業グループの不完全な一致によって、平均値が0から若干ずれています)、(Brynjolfsson and Mitchell, 2017; Brynjolfsson et al., 2018, 2023)のSuitability for Machine Learning、(Felten et al., 2018)のAI Occupational Exposure、(Frey and Osborne, 2017)のAutomation exposureを含めています。
ソフトウェア、SML、ルーチン認知スコアのすべては、1%のレベルでLLMエクスポージャースコアと統計的に強い正の関連性を示しています。(Webb, 2020)のAIスコアの係数も、5%レベルで統計的に強い正の関係性を示していますが、カラム3とカラム4のLLMの全体的なエクスポージャーに対する2番目のプロンプトは統計的に強い関係性を示していません。多くの部分で、AI Occupational Exposure Scoreは我々のエクスポージャースコアとの相関がありません。WebbのRobot exposure scores、ルーチン主導タスクコンテンツ、 (Frey and Osborne, 2017)の全体的なAutomationメトリックは我々の主要なGPT-4と人間が評価した全体的なエクスポージャーレーティングと負の相関を示しており、ほかの計測方法においては条件によります。この負の相関は、LLMに対する物理タスクの限定的なエクスポージャーを示しています。手動の作業はLLMや現時点における追加システムのインテグレーションの影響を受けません。また、我々の自動化手法は、 (Frey and Osborne, 2017)の計測とも相関がありません。
(Felten et al., 2018)や(Frey and Osborne, 2017)との低い相関は、アプローチの違いによって説明できる可能性があります。(SLMの論文にあるように)DWAやタスクレベルのスコアリングを職業に集約するのではなく、AIの能力を労働者の技能にリンクしたり、職業の特定に基づいて直接エクスポージャーをスコアリングすることは、職業のコンテンツに関する観点に若干の違いをもたらします。
すべての回帰において、$R^2$は60.7%(カラム3)と72.8%(カラム5)の間にあります。これはLLMの能力に明示的にフォーカスしている我々の計測方法は、ほかの手法と比較して28から40%の説明できない不一致があることを示しています。AI関連のエクスポージャースコアに関しては特に、ほかの計測方法との組み合わせには、我々のスコアとの強い相関を示すであろうことを予測しています。しかし、これまでの取り組みにおいては、LLM技術のさらなる進展に関する情報は限定的です。同様に、将来の機械学習技術に対する我々の理解は、現在の手順では完璧に捕捉できていないと考えています。
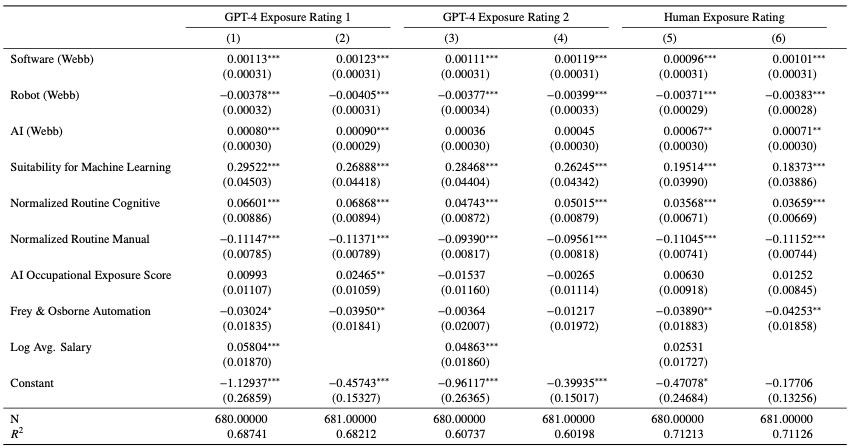
表9 これまでの取り込みに対するGPTスコアの回帰。AIや自動化の職業的エクスポージャーを定量化するためのこれまでの取り組みに対する、我々の手順によるエクスポージャー計測の回帰係数。また、2021年5月のBLS-OESサーベイによる年換算した賃金も含めています。それぞれの計測結果は、オリジナルのスケールに維持されていますが、(Acemoglu and Autor, 2011a)のルーチン認知、ルーチン手動スコアは例外です。これら2つのスコアは、平均が0、分散が1になるように標準化されています。全体的に、これまでの取り組みとの強い正の相関を確認していますが、我々の新たな計測方法で説明されるべき大きな残差分散があります。カラム1とカラム2は我々の主要なGPT-4レーティングの𝛽エクスポージャー計測指標をベースにしています。カラム3とカラム4は、同様に頑健性のためにGPT-4による𝛽エクスポージャー計測指標をベースにしています。カラム5とカラム6は、カラム1とカラム2と同じ手順で人間によるレーティングを反映しています。
6 議論
6.1 汎用技術としてのGPT
本論文の前半で、我々はGPTが汎用技術として分類される可能性を議論しました。この分類には、GPTは3つのコアの評価指標を満たす必要があります: 継続的な改善、経済への浸透、補完的イノベーションを生み出す能力です(Lipsey et al., 2005)。全体的なAIと機械学習の文献から得られる根拠は、GPTが最初の評価指標を満たしていることを示しています - これらは、さらに複雑なタスクセットやユースケースを完了する、あるいは支援するための能力で継続的に機能が改善されています(2.1をご覧ください)。この論文では、残り2つの評価指標をサポートする根拠を示しており、GPT自体が経済において幅広いインパクトを持っていることと、特にソフトウェアやデジタルツールを通じてGPTによって実現される補完的イノベーションが経済活動に対して様々なアプリケーションを有していることを発見しています。
図3では、LLMをベースとした補完的ソフトウェアの潜在的な経済的インパクトを説明しています。x軸(職業が影響を受けるタスクの割合)の特定のポイントの𝛼と𝜁の間のy軸(すべての職業の割合)の差を取ることで、LLM自身による直接の影響に加えて、ツールやソフトウェアによるエクスポージャーの潜在的な属性に関する職業内の集計値を得ることができます。すべてのタスクにおける𝛼と𝜁の差の平均値が、GPT-4のアノテーションを用いた際には0.42、人間のアノテーションを用いた際には0.32(図3をご覧ください)であり、GPTで強化されたソフトウェアの平均的なタスクの影響のインパクトは、LLM自体による平均的な影響(人間によるアノテーションとGPT-4のアノテーションの両方で平均の𝜁は0.14)の2倍以上であることを示しています。我々の所見は、これらのモデルをそのままで利用することで、意味のある割合の労働者とタスクに関係が出てきますが、それらが生み出すソフトウェアのイノベーションによってより広範なインパクトを推進することを示しています。
技術の観点の一つのコンポーネントは、ビジネスやユーザーによる導入のレベルです。本論文では、これらのモデルの導入をシステム的に分析していませんが、LLMの導入と活用がさらに広がっていることを示す早期の定量的な根拠が存在しています。LLM上での比較的シンプルなUIの改善のパワーが、ChatGPTのロールアウトの根拠となりました - ここでは、API経由で複数バージョンのモデルを利用することができましたが、ChatGPTのインタフェースのリリースの後で使用量は爆発的に増加しました。(Chow, 2023; OpenAI, 2022)このリリースに続き、数多くの商用の調査によって、過去数ヶ月を通じてLLMの労働者やファームにおける導入は増加し続けていることを示しています。(Constantz, 2023; ResumeBuilder.com, 2023)
これらのモデルが広範に導入されましたが、既存のボトルネックを特定することになりました。これらの活用のキーとなる決定要因は、人間がこれらに持つ自信のレベルと習慣です。例えば、法律の専門性においては、モデルの有用性は法律の専門家がオリジナルの文書を検証したり、独立した調査を行って理由付けを行うことなしに、これらのアウトプットを信頼できるかどうかで決まります。この技術のコストや柔軟性、労働者やファームの嗜好、インセンティブもまたLLMをベースとしたツールの導入において重要な役割を担います。このようにして、導入はLLMに関係する倫理的、安全リスクのいくつかにおける進歩によって推進されるのかもしれません: それらの一部は、バイアス、事実の捏造、誤った割り当てなどです。(OpenAI, 2023a)
さらに、LLMの導入はデータの可用性、規制の品質、イノベーションの文化、パワーと興味の分布のような要因によって、それぞれの経済圏で変わってくるでしょう。結果として、労働者やファームによる大規模言語モデルや導入に対する包括的な理解には、これらの複雑さに対するさらに深い探索が必要となります。
一つの可能性は、タスクの大部分に対する品質改善よりも、時間短縮、シームレスなアプリケーションを実現することの重要性を重視するであろうということです。別の可能性として、初期状態では拡張にフォーカスし、自動化にフォーカスするというものがあります(Huang and Rust, 2018)。これが形を成す一つの方法は、仕事が最初に不安定(ライターがフリーランサーになる)となる拡張フェーズが、完全な自動化の前に実行されるというものです。
6.2 アメリカ公共政策への示唆
LLMを含む自動化技術の導入は、これまでは経済的不均衡や労働者の混乱を悪化させ、反対的な副作用を引き起こすことがありました。(Acemoglu and Restrepo, 2022a; Acemoglu, 2002; Moll et al., 2021; Klinova and Korinek, 2021; Weidinger et al., 2021, 2022)アメリカにおける労働者の影響を検証した我々の結果は、LLMとそれが生み出す補完技術によって突きつけられる潜在的な経済の混乱に対して社会的、政策的な準備の必要性を強制しています。急激にLLMが導入される経済へのスムーズに移行するための特定の政策の処方性を提案することは本論文のスコープ外ですが、(Autor et al., 2022b)のような以前の取り組みでは、教育、労働者訓練、セーフティネットプログラムの再建などに関連するUSの政策におけるいくつかの重要な方向性を明確にしています。
6.3 制限と今後の取り組み
この研究には、さらなる調査を正当化するいくつかの制限があります。特に、我々のアメリカへのフォーカスは我々の所見を、業界構造、技術的インフラストラクチャ、規制のフレームワーク、言語の多様性、文化のコンテキストなどの要因から、生成型モデルの導入やインパクトが異なる他の国への一般化を制限しています。ほかの研究者がベースにできるように、研究のスコープを拡大し、我々の手法を共有することでこの制限に対応できることを望んでいます。
以降の研究の取り組みでは2つの研究を検討すべきです: 様々なセクターや職業におけるGPT導入パターンの探索と、我々のエクスポージャースコアのスコープを超えた労働者のアクティビティに関連する最先端モデルの実際の能力と制限の精査です。例えば、最近のGPT-4によるマルチモーダルの能力の進歩にも関わらず、直接的なGPTのエクスポージャーの𝛼レーティングでは視覚能力を検討していません。(OpenAI, 2023b)今後の取り組みでは、それらが推し進めるこのような機能の進歩のインパクトも検討すべきです。理論上のパフォーマンスと実際のパフォーマンスには、特に複雑かつ際限のないドメイン固有のタスクでは、不一致が生じるであろうことを我々は認めています。
7 結論
まとめとして、この研究ではLLM、特にGPTのアメリカ経済における様々な職業、業界に対する潜在的インパクトの検証を行いました。LLMの能力と仕事に対する潜在的影響を理解するための新たな手法を適用することで、多くの職業がある程度GPTの影響を受けることを観測し、高給の職業は一般的に、多くのタスクが影響を受けることを示しています。我々の分析では、現在のモデルの能力と予測されるGPTで強化されたソフトウェアの両方を検討した際には、仕事の約19%で最低でも50%のタスクがGPTの影響を受けるという結果になりました。
我々の研究は、USの労働者に対するGPTの汎用性のポテンシャルと可能性のある示唆をハイライトすることを狙いとしています。これまでの文献では、現在までのGPTの印象的な改善が示されています(2.1をご覧ください)。我々の所見によって、これらの技術はUSにおいて広範な職業に行き渡るインパクトを有しているという仮説を確認しています。また、GPTによって、主にソフトウェアやデジタルツールを通じてサポートされるさらなる進歩は、様々な経済活動に大きなインパクトをもたらす可能性があることを示しています。しかし、人間の労働者をより効率的にするGPTの技術的な能力が明らかではありますが、社会的、経済的、規制、そのほかの要因が実際の労働者の生産性に影響を与える可能性を認識することが重要です。能力が進化を続けるに従い、経済に対するGPTのインパクトは存在し続け、増加し、これらの軌跡を予測し、規制する政策立案者に課題を突きつけることになります。
GPTが人間の労働者を拡張あるいは置き換える可能性や仕事の品質へのインパクト、不平等へのインパクト、スキル開発、その他数多くの結果を含む、GPTの進歩によるより広範な示唆を探索するためにさらなる研究が必要です。GPTの能力や労働力への潜在的インパクトを理解するために探索することで、政策立案者やステークホルダーは、AIの複雑なランドスケープをナビゲートするために情報に基づく意思決定を行い、未来の仕事を形作るロールを作ることが可能となります。
7.1 GPTの結論(GPT-4バージョン)
事前学習済み文章生成型トランスフォーマー(GPT)は重大なトランスフォーマーを生成し、潜在的な技術成長を獲得し、タスクを浸透させ、専門性に大きなインパクトを与えます。この研究では、GPTの潜在的な軌跡を探索し、特にUSの労働者市場におけるタスクに対するGPTの影響を計測するための手順の礎を示しました。
7.2 GPTの結論(著者による拡張バージョン)
事前学習済み文章生成型トランスフォーマー(GPT)は重大なトランスフォーマーを生成し、潜在的な技術成長を獲得し、タスクを浸透させ、専門的なマネージメントを破壊します。可能性のある軌跡の計測?革新的なタクソノミーを生成し、政策立案者を一緒に集め、すぐに過去を一般化しましょう。
謝辞
原文をご覧ください。
LLMアシスタンスステートメント
このプロジェクトにおける記述、コーディング、フォーマッティングの支援にGPT-4とChatGPTが使用されました。
関連資料
-
ChatGPTサイトの翻訳
-
GPT-4 Technical Reportの翻訳
-
GPT-4 System Cardの翻訳
-
GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Modelsの翻訳