こちらのの翻訳です。前後編の前編です。後編はこちら。
訳者註
GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models
の「GPTs are GPTs」は「事前学習済み文章生成型トランスフォーマー(GPT)は汎用技術(GPT)である」という意味だと理解しています。
前者のGPTs: Generative Pre-trained Transformers
後者のGPTs: General-Purpose Technologies
なので、
事前学習済み文章生成型トランスフォーマーは汎用技術である: 大規模言語モデルによる労働市場へのインパクトのポテンシャルを先見する
といったタイトルかと思います。
Databricksのユーザー会でChatGPTの勉強会やります。
注意
- 本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
- 脚注、参考文献、Appendixなどは本文をご覧ください。
アブストラクト
我々は、アメリカの労働者市場における、事前学習済み文章生成型トランスフォーマー(GPT)モデルと関連技術の潜在的な影響を調査しました。新たな手法を用いて、人間の専門性とGPT-4の分類の両方を組み合わせることで、GPTの能力との対応関係に基づいて、職業を評価しました。我々の発見では、アメリカの約80%の労働者がGPTの導入によって少なくともタスクの10%が影響を与え、労働者の約19%が自身のタスクの50%に影響を与えることを示しています。影響範囲は全ての賃金レベルに及び、高収入の職が潜在的により高い影響を受けます。特に重要なことですが、このインパクトはここ最近生産性の成長が認められる業界に限定されません。これらのモデルは注目に値する経済的、社会的、政策に関する影響を示しており、事前学習済み文章生成型トランスフォーマーは汎用技術の特性(GPT)を示していると結論づけています。
1 イントロダクション
図1に示すように、この数年、数ヶ月、数週間において、生成型AIや大規模言語モデル(LLM)の領域における進歩は凄まじいものとなっています。多くの人は、LLMを事前学習済み文章生成型トランスフォーマー(GPT)と関連づけますが、LLMは様々なアーキテクチャによってトレーニングされ、トランスフォーマーベースのモデルに限定されません(Devlin et al., 2019)。LLMはアセンブラ言語、プロテインのシーケンス、チェスゲームを含む様々な形態のシーケンシャルデータを処理、生成することができ、単なる自然言語アプリケーションを拡張します。本論文では、LLMとGPTを何かしらの形で入れ替えて使用し、ChatGPTやOpenAI Playground(この時点では、GPT-3.5ファミリーを含みますが、GPT-4ファミリーを含みません)で利用できるGPTファミリーに類似すると考えるべき手順においては具体的に指定します。我々はGPTをテキスト生成、コード生成の能力で検証し、画像や音声のような形態を追加で含める際には「生成型AI」という用語を使用します。
我々の研究は、モデル単体の進歩によってというよりは、それら周辺で開発された補完的技術で我々が目撃している範囲、スケール、能力によるモチベーションが大きいです。補完的技術の役割はいまだに確認されていますが、LLMのインパクトの最大化はより大規模なシステムとそれらとのインテグレーションにおいては、不確実性があるものに見えます(Bresnahan, 2019; Agrawal et al., 2021)。我々はLLMの生成能力の議論の多くにフォーカスしていますが、生成的であるかどうかの区別がつけにくい、カスタム検索アプリケーションや要約、分類タスクを可能とするエンべディングのような事柄を含む他のタスクのためにLLMを活用することで可能となる新たなタイプのソフトウェアやマシンコミュニケーションが存在する可能性があります。
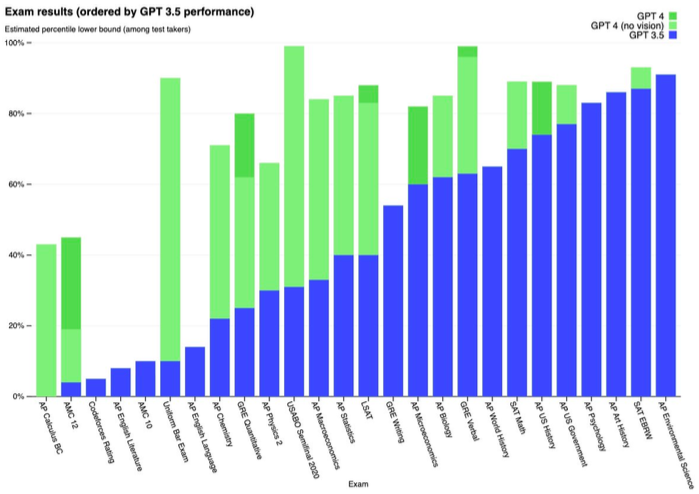
図1 モデルの能力がどれだけ急速に進歩しているのかの感覚を掴むためのもの - GPT-3.5とGPT-4の間における試験のパフォーマンスを考慮 (OpenAI, 2023b)。
この進歩の文脈を与え、技術の補完的な労働者へのインパクトの予測を行うために、LLMの能力と仕事に対するそれらの潜在的な影響を理解するための新たな手順を提案します。この手順(A.1)は、機械学習のエクスポージャーを定量化する以前からの取り組み(Brynjolfsson et al., 2018; Felten et al., 2018; Webb, 2020)を引き継ぎ、GPTに対するタスクの全体的なエクスポージャーを計測します。我々は、エクスポージャーを労働者の拡張と労働者を置き換える影響の間を区別することなしに、潜在的な経済的インパクトに対するプロキシーとして定義します。我々は、主にO*NETデータベースから得られるアメリカ経済における職業にこの手順を適用するために、人間のアノテーターと分類器としてのGPT-4自身を活用しました。
主要なエクスポージャーのデータセットを構築するために、著者によるラベルのサンプルに一致するようにチューニングされたプロンプトを用いて、人間のアノテーションとGPT-4分類の両方を収集しました。タスクレベルで収集した際にも、GPT-4のレスポンスにおいて、そして、人間と機械の評価においても類似の一致が観測されました。この計測は、人間の労働者をより効率的にするための技術的能力の推定値を反映しています。しかし、そのような技術的可能性を示唆する社会的、経済的、規制、他の決定要因は、労働者の生産性や自動化による成果を保証しません。我々の分析では、現在のモデルの能力とそれらの上に構築されると予想されるツールの両方を考慮した際、仕事の19%には少なくともタスクの50%がそれらに影響されることを示しています。人間による評価では、追加のソフトウェアや形態なしに、既存の言語、コード能力を考慮した際、アメリカの労働者の3%のみの半分以上のタスクがGPTに影響を受けるとしています。その他の生成モデルや補完的技術によって、我々の人間の評価者の見積もりでは、最大49%の労働者の半分以上のタスクがLLMの影響を受けることになることを示しています。
我々の初見では、多くの職業が、仕事のタイプによって程度の違いはありつつも、LLMの影響をある程度受けるということを人間とGPT-4のアノテーションの両方で一貫して示されています。賃金の高い職業は一般的に高い影響を受け、機械学習全体の影響における同様の評価とは結果が対照的なものとなっています(Brynjolfsson et al., 2023)。O*NETのスキルの指示書を用いてスキルセットとエクスポージャーの計測結果の回帰をとることで、重度に科学に依存しているロールとクリティカルシンキングのスキルはエクスポージャーとの負の相関があり、プログラミングや記述スキルはLLMのエクスポージャーに正の相関があることがわかりました。著者ら(2022a)に従い、我々は「ジョブゾーン」ごとの参入障壁を検証し、LLMによる職業への影響は、仕事の準備の難易度に従い緩やかに増加することを見つけ出しました。言い換えると、労働者が高い(低い)参入障壁に直面する仕事は、LLMによる大きな(小さな)影響を体験する傾向があります。
さらに我々は、経済における自動化技術の影響の分布を記した以前の取り組みと我々の計測結果を比較し、広い範囲で結果に一貫性があることを知りました。我々が検証した、その他の多くの影響に関する指標は我々の影響指標と非常に相関していましたが、手動でのルーチン作業やロボティクスの影響は負の相関を示していました。60%から72%の賃金のコントロールを伴う、これらの以前の取り組み(Acemoglu and Autor, 2011a; Frey and Osborne, 2017; Brynjolfsson et al., 2018; Felten et al., 2018; Webb, 2020; Brynjolfsson et al., 2023)によって説明されている不一致は、我々のAI影響指標における28%から40%のバリエーションを示しており、以前の技術影響指標では考慮されていません。
業界ごとにエクスポージャーを分析し、情報処理業界(4-digit NAICS)では高いエクスポージャーを示していますが、製造、農業、鉱山では低いエクスポージャーを示していることを発見しました。過去10年間における生産性の向上と、全体的なGPTのエクスポージャーの関係性は弱く見え、将来的なLLMからのメリットを得られるという潜在的、楽観的なケースは、潜在的な疾病によるコストを悪化させないかもしれません(Baumol, 2012)。
我々の分析では、GPT-4のようなLLMのインパクトは広い範囲に及ぶことを示しています。時と共にLLMの機能は定常的に改善されていますが、それらの経済成長に関する影響は継続し、現在進行中の新機能の開発を止めたとしても増加すると予測されています。また、LLMの潜在的インパクトは、補完的技術の開発を考慮した際に劇的に拡大することを知りました。全体的に、これらの特性は事前学習済み文章生成型トランスフォーマー(GPT)が汎用技術(GPT)であることを示しています。(Bresnahan and Trajtenberg, 1995; Lipsey et al., 2005)。(Goldfarb et al., 2023)は、広範なカテゴリーとしての機械学習は汎用技術であるだろうと議論しています。我々の根拠によって、機械学習ソフトウェアのサブセットであっても独立して汎用技術のステータスに合致しており、より広いインパクトをサポートしています。本論文の主な目的は、一連のLLMインパクトのポテンシャルの計測結果を示し、このような計測を効率的かつ大規模に開発するためのLLMの適用ユースケースをデモンストレーションすることです。さらに、LLMの汎用利用のポテンシャルを説明します。「GPTがGPT」であるならば、LLM開発とアプリケーション最終的な軌跡は、政策決定者が予測、規制すべき課題となるかもしれません。他の汎用技術と同様に、これらのアルゴリズムのポテンシャルの多くは、新たなタイプの仕事の生成を含む、広範な経済的に価値のあるユースケースで出現するでしょう(Acemoglu and Restrepo, 2018; Autor et al., 2022a)。我々の研究は、現在技術的に何が実現可能であるのかを計測するためのものでありますが、時を経て進化するLLMのポテンシャルによるインパクトを止むを得ず見逃すことがあります。
本論文は以下のように構成されています: セクション2では関連するこれまでの取り組みをレビューし、セクション3では手法とデータ収集を議論し、セクション4ではサマリー統計と結果を示し、セクション5では我々の計測結果とこれまでの取り組みを関連付け、セクション6では結果を探索し、セクション7でまとめを行います。
2 文献のレビュー
2.1 大規模言語モデルの進歩
近年において、大規模言語モデル(LLM)は人工知能研究の分野で存在感を増し、様々な複雑な言語ベースのタスクに取り組む能力を示しています。この進歩は、増加したモデルパラメーター数、トレーニングデータボリュームの増加、強化されたトレーニング環境を含む様々な要素によって促進されています(Brown et al., 2020; Radford et al., 2019; Hernandez et al., 2021; Kaplan et al., 2020)。LaMDA (Thoppilan et al., 2022)やGPT-4(OpenAI, 2023b)のような広範かつ最先端のLLMは、これまではドメイン固有のデータを用いて専門家のエンジニアによって開発される特殊かつタスク固有のモデルが必要であった、翻訳、分類、クリエイティブな執筆、コード生成のような様々なアプリケーションで優れています。
同時に、研究者はファインチューニングや人間フィードバックによる強化学習のような手法を用いてこれらのモデルの操縦性、信頼性、使いやすさを改善しました(Ouyang et al., 2022; Bai et al., 2022)。これらの進歩は、ユーザーの意図を汲み取り、よりユーザーフレンドリーかつ実践的な出力を行うモデルの能力を強化しました。さらに、最近の研究では、LLMがプログラミングし、APIや検索エンジン、さらには他の生成型AIシステムのような他のデジタルツールを制御するポテンシャルを明らかにしました(Schick et al., 2023; Mialon et al., 2023; Chase, 2022)。これによって、より優れた有用性、パフォーマンス、一般化のために個々のコンポーネントをシームレスにインテグレーションできるようになりました。長期的にこれらのトレンドは、LLMが計算機で通常実行されるすべてのタスクを実行できる応力を持つようになるであろうことを示しています。
多くの部分において、生成型AIモデルはモジュールの専門家としてデプロイされ、キャプションからの画像生成や口語記述のような固有のタスクを実行します。しかし、LLMが他のツールに対する重要なビルディングブロックであることを認識し、より広い観点で捉えることが重要であると主張します。これらのツールの構築とそれらを包括的なシステムに組み込むことには時間を要し、経済における既存プロセスの重大な再構成を要求することになりますが、我々はすでに導入のトレンドが生じていることを観測しています。これらの制限にかかわらず、LLMは記述アシスタント、コーディング、法的リサーチのような領域における特殊アプリケーションにますますインテグレーションされており、より広範に企業や個人がGPTを導入する準備ができています。
すぐに利用できる汎用GPTは、事実に関する不正確性、内包されているバイアス、プライバシーの懸念、誤った情報のリスクのような問題のため、様々なタスクにおいて、信頼できないものであり続ける部分があるため、これらの補完的技術の重要性を強調しておきます(Abid et al., 2021; Schramowski et al., 2022; Goldstein et al., 2023; OpenAI, 2023a)。しかし、ツール、ソフトウェア、人間をループに含めるシステムを含む特殊なワークフローによって、ドメイン固有の専門性を組み入れることでこれらの欠点を克服する助けとなります。例えば、Casetextは、GPT-4が法律に関する事案や一連のドキュメントに関して不正確な詳細を提供するというリスクに対抗するために、エンベディングや要約を活用することで、弁護士にクイックかつより正確な法律リサーチの結果を提供するLLMベースの法律リサーチツールを提供します。GitHub Copilotは、ユーザーが自分の専門性によって許諾、拒否できるコードスニペットやオートコンプリートのコードを生成するためにLLMを活用しているコーディングアシスタントです。言い換えると、GPT-4は「今が何時か」を知らないのは事実ですが、時計を与えるのは簡単だということです。
さらに、LLMが特定のパフォーマンスのしきい値を上回ることでポジティブなフィードバックループが形成され、様々な文脈におけるこれらの使いやすさや有用性を強化する更なるツールを構築する助けとなります。これによって、このようなツールを作成するのに必要なコストとエンジニアリングの専門性を引き下げ、さらにLLMの導入とインテグレーションを加速する可能性があります。(Chen et al., 2021; Peng et al., 2023)また、LLMは機械学習モデル開発における重要な資産となり、研究者、データラベリングサービス、合成データ生成器に対するコーディングアシスタントとしてサポートします。例えば、人間と機械の間でのタスクやサブタスク割り当ての手法を洗練することで、このようなモデルがタスクレベルで経済的な意思決定に貢献する可能性もあります(Singla et al., 2015; Shahaf and Horvitz, 2010)。時と共にLLMが改善し、ユーザーの嗜好と一致することで、パフォーマンスにおける継続的な強化を予測することができます。しかし、これらのトレンドが様々な重大リスクをもたらということを認識することが重要です。(Khlaaf et al., 2022; Weidinger et al., 2022; Solaiman et al., 2019)
2.2 自動化技術の経済的インパクト
大規模かつ増加し続けている文献は、人工知能と広く定義されている自動化技術の労働市場へのインパクトに取り組んでいます。スキルによるバイアスのある技術的変化と、自動化のタスクモデルのコンセプトは、多くの場合、技術的な進歩は、スキルのない労働者よりもスキルのある労働者の需要を生み出すということを示した研究(Katz and Murphy, 1992)に端を欲する労働への影響を理解するための標準的なフレームワークと考えられています。このコンセプトに立脚した多くの研究が行われており、タスクベースのフレームワークにおける技術の変化や作業者の自動化の影響を探索しています(Autor et al., 2003; Acemoglu and Autor, 2011b; Acemoglu and Restrepo, 2018)。この研究の一部では、ルーチンかつ繰り返すのタスクに関与する労働者は、ルーチンバイアスのある技術的変化として知られる、技術駆動の置き換えのリスクが高くなるということを示しました。より最近の研究では、技術のタスク置き換えの効果とタスク復権(新たな技術がより広範な労働者中心のタスクの必要性を増す)の効果を区別しています(Acemoglu and Restrepo, 2018, 2019)。いくつかの研究では、自動化技術はルーチンタスクに特化した労働者の相対的な賃金の低下に後押しされ、アメリカにおける賃金の不平等につながっていると指摘しています(Autor et al., 2006; Van Reenen, 2011; Acemoglu and Restrepo, 2022b)。
これまでの研究では、AIの能力と様々な職業で行われるタスクやアクティビティとの重複を推定するために様々なアプローチを適用していました。これらの手法には、特許の説明を作業者のタスクの説明へのマッピング (Webb, 2020; Meindl et al., 2021)、AI能力をO*NETデータベースに記述されている職業技能にリンク(Felten et al., 2018, 2023)、認知能力を通じたAIタスクベンチーマークの評価の作業者タスクへの割り当て(Tolan et al., 2021)、アメリカの職業のサブセットにおけるラベル付けの自動化の可能性、その他すべてのアメリカの職業におけるポテンシャルを推定するための機械学習分類器の活用(Frey and Osborne, 2017)、タスクレベルの自動化のモデリングと職業レベルへの結果の集約(Arntz et al., 2017)、専門家の予測(Grace et al., 2018)、そして、この論文に最も適している機械学習の持続性に関する作業者のアクティビティを評価するための新た手法の発明(Brynjolfsson et al., 2018, 2023)が含まれています。これらのアプローチのいくつかは、タスクレベルにおけるAI技術の影響は職業で多様化することを明らかにしました。それぞれの職業をタスクの集合と考えると、AIツールがほぼすべての作業を行える職業を見つけ出すことは困難なことになるでしょう。(Autor et al., 2022a)では、このような自動化と拡張の影響は正の相関を持つ傾向があることを発見しています。また、LLM固有の経済的インパクトや機会を検証する研究が増加しています(Bommasani et al., 2021; Felten et al., 2023; Korinek, 2023; Mollick and Mollick, 2022; Noy and Zhang, 2023; Peng et al., 2023)。この取り組みと共に、我々の計測は言語モデルの労働市場に対するより広範かつ潜在的な関係性を特徴づける助けとなります。
汎用技術(印刷、上記エンジンなど)(GPT)は、広範な拡散、継続的改善、補完的なイノベーションの創出によって特徴付けられます(Bresnahan and Trajtenberg, 1995; Lipsey et al., 2005)。数十年を経てこれらのたどり着く結末を予測することは、特に労働者需要に関係する場合は困難です(Bessen, 2018; Korinek and Stiglitz, 2018; Acemoglu et al., 2020; Benzell et al., 2021)。汎用技術の完全なポテンシャルの理解には、多方面に渡る共同イノベーション(Bresnahan and Trajtenberg, 1995; Bresnahan et al., 1996, 2002; Lipsey et al., 2005; Dixon et al., 2021)、新たなビジネス手順の発見を含む高コストで時間を要するプロセスが必要となります(David, 1990; Bresnahan, 1999; Frey, 2019; Brynjolfsson et al., 2021; Feigenbaum and Gross, 2021)。結果として、機械学習技術の研究の多くは、システムレベルの導入にフォーカスしており、企業システムは新たな機械学習の進歩の利点を効果的に活用するためには再設計が必要になるかもしれないと議論しています (Bresnahan, 2019; Agrawal et al., 2021; Goldfarb et al., 2023)。適切に設計されたシステムは、発見プロセスを促進するAIツール (Cockburn et al., 2018; Cheng et al., 2022)によって非常に大きなビジネス価値を達成し、組織のパフォーマンスを改善します(Rock, 2019; Babina et al., 2021; Zolas et al., 2021)。LLMがGPTの評価指標を満足するのかどうかを評価するためにタスクレベルの情報を活用することで、技術と労働者の関係性を理解するために二つの観点を結合しようとしています。
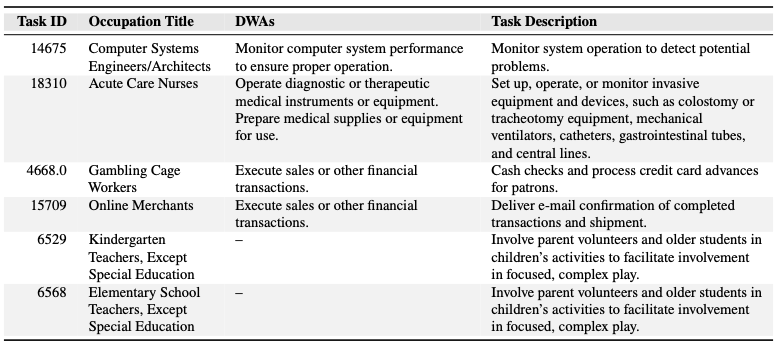
表1 O*NETデータベースから得られる職業、タスク詳細の作業アクティビティのサンプル。Gambling Cage Workersが対面での特定のDWA(Detailed Work Activities)を完了することを期待しますが、Online Merchantsは同じアクティビティをすべてコンピューターで行うことを期待するという事実からアクティビティ単体に対する集計は不正確だと捉えています。
我々はいくつかの方法でこれら多岐にわたる文献の流れの上で開発を行おうとしています。反響を受けて(Felten et al., 2023)、より広範な機械学習や自動化学習の取り組みではなく、我々はLLMのインパクトの分析にフォーカスしています。さらに、我々は影響を受けるタスクと自動化のポテンシャルを評価するために、LLM、特にGPT-4を活用する新たな手法を提案しており、ここでは人間のスコアリングの取り組みをサポートしています。結果として、我々の所見を職業と業界に集約し、現代のアメリカの労働市場における全体的なエクスポージャーの可能性を捕捉しています。
3 手法とデータ収集
3.1 USにおける職業による活動とタスクに関するデータとタスク
我々は、それぞれの詳細な作業アクティビティ(DWA)とタスクを含む1,061の職業の情報を格納しているONET 27.2データベース(ONET, 2023)を活用しています。DWAは、「プロジェクト要件を決定するためのスクリプトを研究する」といったタスク完了の一部である包括的なアクションです。一方、タスクは一つ、複数のDWAと関連づけられる、あるいはDWAと関係しない職業固有の作業単位です。表1にタスクとDWAのサンプルを示しています。使用する2つのデータセット配下から構成されています:
- 19,265のタスク、それぞれのタスクは「タスクの説明」と対応する職業で特徴づけられ、多くのタスクは1つ以上のDWAと関連づけられています。
- 2,087のDWA、多くのDWAは1つ以上のタスクと関連しており、タスクは1つ以上のDWAと関連づけられることがありますが、いくつかのタスクはDWAとの関連がありません。
3.2 賃金、雇用、人口動態に関するデータ
我々は、Bureau of Labor Statistics(アメリカ合衆国労働省労働統計局)が提供する2020年と2021年のOccupational Employmentシリーズから雇用と賃金のデータを取得しています。このデータセットには、職業タイトル、それぞれの職業の従業員の数、職業レベルでの2023年の雇用の予測、職業に就くために必要とされる典型的な教育、職業における競争力を得るために必要なOJTが含まれています(BLS, 2022)。ONET (BLS, 2023b)をONETのタスクとDWAデータセット、Current Population Survey (CPS)から導出されたBLS Labor Force Demographics (BLS, 2023a)とリンクするためにBLSが推奨する結合方法を採用しています。これらデータソースの両方はアメリカ政府によって収集され、個人事業主ではない、いわゆる公式経済で働いている従業員のほとんどが文書化されています。
3.3 エクスポージャー
我々の結果は、エクスポージャーをGPTあるいはGPTで強化されたシステムへのアクセスによって人間が固有のDWAを実行する、あるいはタスクの完了に要する時間を最低でも50パーセント削減するかどうかに関する指標として定義する、エクスポージャー手順に基づいて示されます。以下に我々の手順のサマリーを示していますが、A.1で完全な手順を確認することができます。DWAのラベルがある場合には、職業レベルの集計を行う前に、タスクレベルで集計を行います。

我々は一貫性のある品質を保持するために、特定のDWAやタスクを完了するのに必要な時間の50%を削減するように、エクスポージャーのしきい値を設定しました。我々は、生産性を劇的に増加させるアプリケーションにおいて、最も多くかつ間も無く導入がされると予測しています。このしきい値はある意味任意のものですが、アノテーターによる解釈が容易になるように選択されています。
そして、このエクスポージャーの手順を用いて、この論文における分析の大部分を下支えしている人間が生成したアノテーションとGPT-4が生成したアノテーションの両方を収集しました。
- 人間のレーティング: O*NETのDetailed Worker Activity (DWA)と、すべてのO*NETタスクのサブセットのそれぞれに手順を適用することで人間のアノテーションを取得し、これらのDWAとタスクのスコアをタスクレベルと職業レベルで集計しました。これらのアノテーションの品質を保持するために、著者は大規模なタスクとDWAのサンプルのラベル付けを行い、OpenAIの割り当て作業において様々な視点からGPTのアウトプットをレビューしている経験豊富な人間のアノテーターの協力を求めました(Ouyang et al., 2022)。
- GPT-4のレーティング: 我々はGPT-4の早期バージョン (OpenAI, 2023b)に同様の手順を実施しましたが、DWAではなくすべてがタスク/職業のペアに対してとなっています。人間のラベルセットとの一致性を高めるために、手順に若干の修正(このケースではモデルへの「プロンプト」として使用されました)を加えました。完全な一致率は表2をご覧ください。
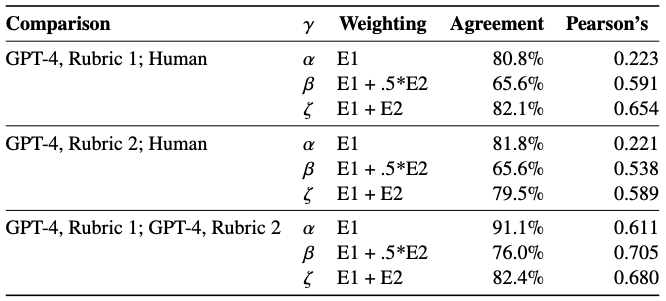
表2 モデルと人間の一致度合いとピアソンの相関スコアの比較。一致スコアは、アノテーションにおいてどの程度の頻度で2つのグループが一致するのかを見ることで決定しています。(例: E0、E1、E2)本論文ではGPT-4, Rubric 1を使用しています。
我々は興味のある従属変数を3つの主要な指標から構成しています: (i) 𝛼、上述のエクスポージャー手順のE1に対応し、職業において影響を受けるタスクの割合の下限を表示すると予期しています、(ii) 𝛽、E1と0.5*E2の合計であり、E2に対する0.5の重みは補完的ツールやアプリケーションを通じて技術をデプロイする際のエクスポージャーを考慮しており、追加の投資が必要となります、(iii) 𝜁、E1とE2の合計であり、GPTやGPT支援のソフトウェアに対する最大のエクスポージャーの評価を行うためのエクスポージャーの上限となります。表2でアノテーショングループと指標の一致度合いをまとめています。この分析の残りの部分では、指定されない限り、読者は𝛽のエクスポージャーを参照していると想定してもらって構いません。これは、ChatGPTやOpenAI Playgroundのようなツールを通じて直接的に影響を受けるすべてのタスクが、いくつかの補完的イノベーションを必要とするタスクの二倍の影響を受けることを意味します。
3.4 我々の手法の限界
3.4.1 主観的な人間の判断
我々のアプローチのおける根本的な限界は、ラベリングの主観性が元となっています。我々の研究では、GPTモデルの能力に慣れているあのテーターを採用しています。しかし、このグループは職業的な多様性があるわけではなく、馴染みのない職業のタスクの実行においてはGPTの信頼性や効果に関してバイアスのある判断につながる可能性があります。ある職業における個々のタスクに対して高品質のラベルを得るためには、それらの職業についている人々、あるいは、最低でもこれらの職業の様々なタスクに対して深い知識を持っている人とのエンゲージが必要であることは認めます。これは、これらの結果を検証する今後の取り込みにおける重要な領域を示しています。
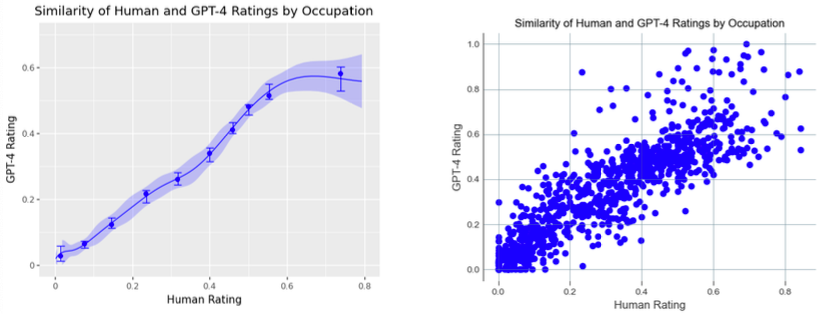
図2 人間位よる評価(x軸)とGPT-4の評価(y軸)は、職業ごとのGPTの影響に関して高いレベルでの一致を示しています。エクスポージャースコアを𝛽手法で職業に集計すると、エクスポージャーが最も高いレベルでは、GPT-4のレーティングは人間のレーティングよりも低くなる傾向があります。生の散布図とビン分けされた左プルズを示しています。エクスポージャーのレーティングが最も高いところでは、人間は平均的に職業がより影響を受けるとレーティングしています。
3.4.2 GPT-4によるGPTの計測
最近の研究では、GPT-4は複雑なタクソノミーを適用し、言葉遣いや協調における変更に対応することができる効果的な区別器として動作することが示されています。(OpenAI, 2023b)GPT-4のタスク分類の成果は、手順の言葉遣いの変化やプロンプトの順序や構成、指示における特定のサンプルの有無。提供される詳細のレベル、キーとなる用語の定義にセンシティブです。小規模な検証セットで観測される結果に基づくプロンプトの繰り返しによって、モデルの出力と手順の意図の間の一致度が増します。この結果、人間に提示される手順とGPT-4に使用される手順の違いはわずかなものとなります。この意思決定は、過度に人間のアノテーターに影響を与えることなしに、合理性のあるラベルに向けてモデルをガイドするために意図的に為されました。このため、複数のアノテーションのソースを活用していますが、どれも他のものに対して相対的な真実と考えられるものではありません。この分析においては、我々の主要な結果として人間のあのテーターの結果を示しています。LLM分類において効果的な手順を作成するための更なる改善とイノベーションは依然として可能です。そして、GPTシステムに対する全体的なエクスポージャーに関して、依然として人間とGPT-4の職業レベルでの高い一致を観測しています。(表2をご覧ください)
3.4.3 その他の弱み
- タスクベースのフレームワークの妥当性 職業をどこまでのタスクにブレークダウンできるのか、仕事の競争力を持つパフォーマンスに暗黙的に必要とされる特定カテゴリーのスキルやタスクを、このアプローチがシステム的に排除するのかどうかは不明確です。さらに、タスクはサブタスクから構成されることがあり、それらのいくつかは他のものよりもさらに自動化可能なものとなります。いくつかのタスクは、後段のタスクの完了は前タスクに依存するというように、他のタスクの前段のタスクとして機能するかもしれません。もし本当に、このタスクベースのブレークダウンが、ある職業において多くの作業がどのように実行されるのかを表現する適切な手法でなければ、我々のエクスポージャー分析は無効なものとなるでしょう。
- 相対的指標 vs. 絶対的指標 これらの指標は相対的指標ととして解釈することがベストであるだろうと考えており、推定エクスポージャーが0.6の職業は0.1のエクスポージャーよりもはるかに多く影響を受けると解釈されるべきです。
- タスク解釈と専門性の欠如 人間のアノテーターは、ラベリングのプロセスでそれぞれのDWAにマッピングされる固有の職業をほとんど認識していません。これは、タスクと職業の集計における不明瞭なロジックや、表1に示しているようなラベルにおける明確な矛盾につながります。我々は様々な集計方法を実験しており、最大マッチのアプローチ(人間<>モデルのラベルで一方が存在したらマッチングとする)でさえも、一致度合いは比較的一貫していることを発見しました。最終的には、不一致度合いが大きいタスク/職業ペアにおいては追加のラベルを収集しました。
- いくつかの早期の根拠による未来志向、変更可能性 未来のLLMアプリケーションを正確に予測することは専門家であっても困難です(OpenAI, 2023b)。出現する能力、人間の受容のバイアス、技術的進展のシフトは、作業者のタスクに対するLLMの潜在的インパクトに関する予測の精度や信頼性すべてに影響を及ぼします。我々の予測は、本来未来志向で、現在のトレンド、根拠、技術的可能性の受容をベースとしています。このため、この分野で生じる新たな進歩によって変化する場合があります。例えば、いくつかのタスクは現在LLMのインパクトがなさそうに見えますが、新たなモデルの能力の導入によって変化する可能性があります。逆に、影響を受けるとみなされているタスクが、言語モデルの適用の制限となる未知の課題に直面するかもしれません。
-
不一致のソース 不一致のソースを精力的に検証していませんが、彼らの評価において人間とモデルが「スタック」する傾向があるいくつかの場所があることを発見しました:
- 理論的にはLLMがタスクを支援、達成できるタスクやアクティビティ、それを行うための導入には複数の人々が習慣や期待を変更する必要があるもの(ミーティングや交渉など)。
- 人間による監視を必要とする規制や人間の判断や共感を示す規範が現在存在しているタスクやアクティビティ(意思決定やカウンセリングなど)。
- 合理的にタスクを自動化する技術が既に存在しているタスクやアクティビティ(予約の実施など)。
後編に続きます。
関連資料
-
ChatGPTサイトの翻訳
-
GPT-4 Technical Reportの翻訳
-
GPT-4 System Cardの翻訳
-
GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Modelsの翻訳