Databricksではpandasを使えるのですが、その過程でやりたいことによっては詰まることもあるかと思います。こちらでは、その際のティップスをまとめます。DatabricksではSparkを前提としている機能が多いので、場合によってはSparkデータフレームへの変換が必要となります。
話がややこしくなるので、Pandas API on Sparkに関しては一旦脇に置いておきます。
pandasデータフレームをテーブルとして保存したい
pandasデータフレームでは直接テーブルに書き込めないので、一旦Sparkデータフレームに変換してから保存します。
import pandas as pd
data = [
["James", "", "Smith", 30, "M", 60000],
["Michael", "Rose", "", 50, "M", 70000],
["Robert", "", "Williams", 42, "", 400000],
["Maria", "Anne", "Jones", 38, "F", 500000],
["Jen", "Mary", "Brown", 45, None, 0],
]
columns = ["FirstName", "MiddleName", "LastName", "Age", "Gender", "Salary"]
# pandasデータフレームの作成
pandasDF = pd.DataFrame(data=data, columns=columns)
# データフレームの表示
print(pandasDF)
FirstName MiddleName LastName Age Gender Salary
0 James Smith 30 M 60000
1 Michael Rose 50 M 70000
2 Robert Williams 42 400000
3 Maria Anne Jones 38 F 500000
4 Jen Mary Brown 45 None 0
saveAsTableを用いて書き込み先のテーブルを指定します。ここでは、takaakiyayoi_catalog.default.sample_tableを指定します。
# Sparkデータフレームへの変換
sparkDF = spark.createDataFrame(pandasDF)
# テーブルへの書き込み
sparkDF.write.mode("overwrite").saveAsTable("takaakiyayoi_catalog.default.sample_table")
カタログエクスプローラからテーブルを確認できます。
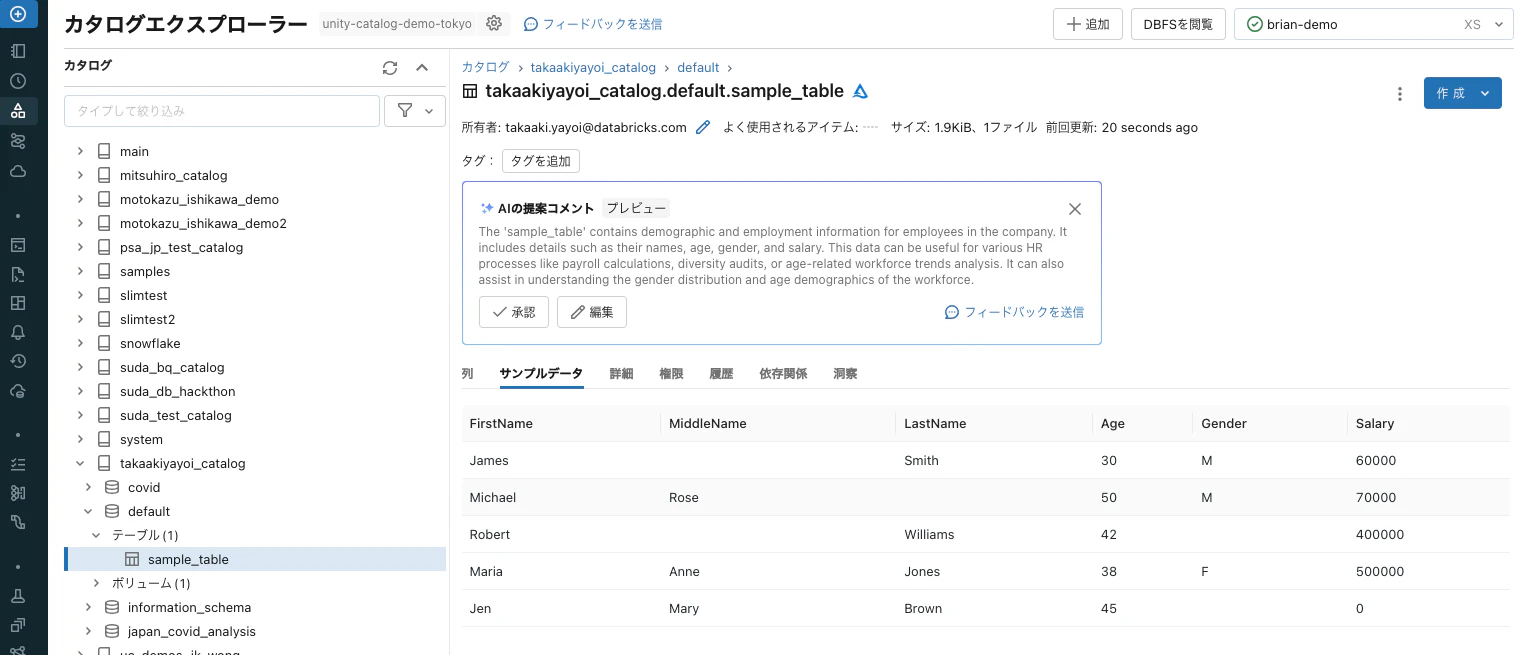
テーブルからpandasデータフレームに読み込みたい
こちらも、一旦Sparkデータフレームに読み込んだあとでpandasデータフレームに変換します。
# テーブルからの読み込み
newSparkDF = spark.read.table("takaakiyayoi_catalog.default.sample_table")
# pandasデータフレームへの変換
newPandasDF = newSparkDF.toPandas()
newSparkDF.show()
+---------+----------+--------+---+------+------+
|FirstName|MiddleName|LastName|Age|Gender|Salary|
+---------+----------+--------+---+------+------+
| James| | Smith| 30| M| 60000|
| Michael| Rose| | 50| M| 70000|
| Robert| |Williams| 42| |400000|
| Maria| Anne| Jones| 38| F|500000|
| Jen| Mary| Brown| 45| NULL| 0|
+---------+----------+--------+---+------+------+
単一のCSVファイルとして保存したい
Sparkデータフレームでデータを加工した後で、単一のCSVファイルとして保存したいというのはよくある話かと思います。ただ、何も気にせずにSparkのwriteで保存すると期待した通りに動作しません。以下の例ではボリュームにCSVファイルを出力しています。
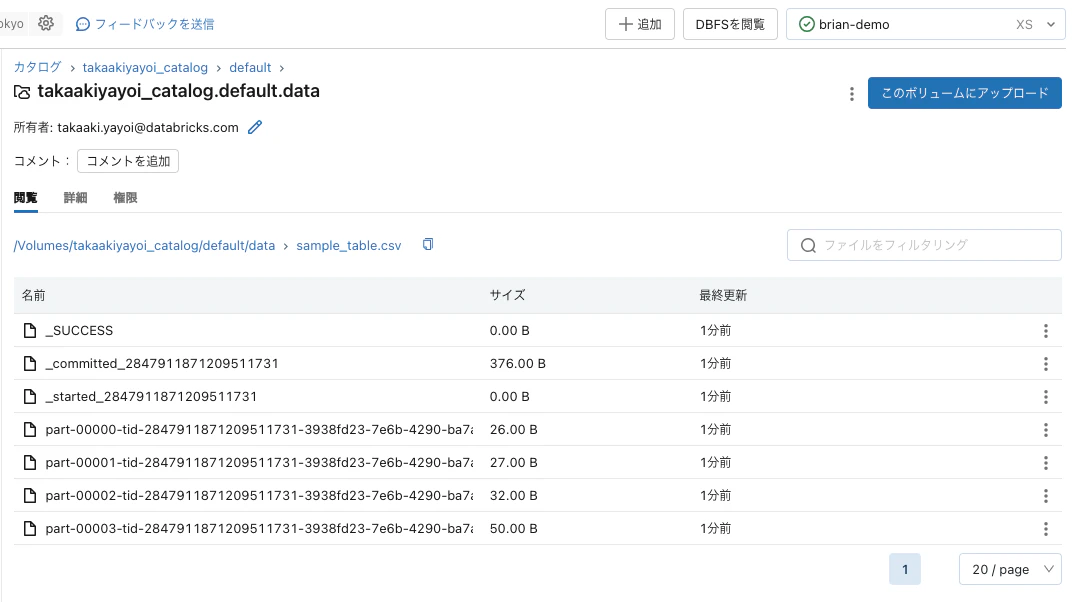
sparkDF.write.format("csv").save("/Volumes/takaakiyayoi_catalog/default/data/sample_table.csv")
このように、ファイルではなくディレクトリが作成されます。

ディレクトリには複数のファイルが作成されています。これは、Sparkが分散処理のためにファイルをパーティションという単位に分割する仕様となっているためです。設定で1ファイルにまとめることはできますが、メモリの制約がなければ素直にpandasデータフレームに変換してから保存した方が楽です。
pandasDFtoWrite = sparkDF.toPandas()
pandasDFtoWrite.to_csv("/Volumes/takaakiyayoi_catalog/default/data/sample_table_file.csv")
これで単一のCSVファイルが作成されます。ボリュームにはpandas APIからも普通にアクセスできます。

ボリュームにはシェルからもアクセスできます。
%sh
cat /Volumes/takaakiyayoi_catalog/default/data/sample_table_file.csv
,FirstName,MiddleName,LastName,Age,Gender,Salary
0,James,,Smith,30,M,60000
1,Michael,Rose,,50,M,70000
2,Robert,,Williams,42,,400000
3,Maria,Anne,Jones,38,F,500000
4,Jen,Mary,Brown,45,,0
途中からボリュームが便利だという話に変わってしまった気がしなくもありません。
参考資料
- サンプルを通じたPandasとPySparkデータフレームの比較
- PySparkことはじめ
- DatabricksにおけるPySpark、pandasデータフレームの変換の最適化
- PySparkとPandasのDataFrameの相互変換
- PySpark: シングルファイルとしてCSVを保存する - connecting the dots
- Databrikcs(Spark)のPysparkにて単一ファイルとしてCSVファイルを書き込む方法
- Solved: When I save a Spark dataframe using df.write.forma... - Databricks - 21582