概要
Databrikcs(spark)のPysparkにて単一ファイルのCSVファイルとして書き込む方法を共有します。
ただし、大量データの場合には、ファイルの単一化を実施すべきではないです。
下記の3つの設定を行うことで、単一ファイルとなります。
-
spark.sql.sources.commitProtocolClassをorg.apache.spark.sql.execution.datasources.SQLHadoopMapReduceCommitProtocolに設定 -
mapreduce.fileoutputcommitter.marksuccessfuljobsをfalseに設定 - coalesce関数によりパーティション数を
1に設定
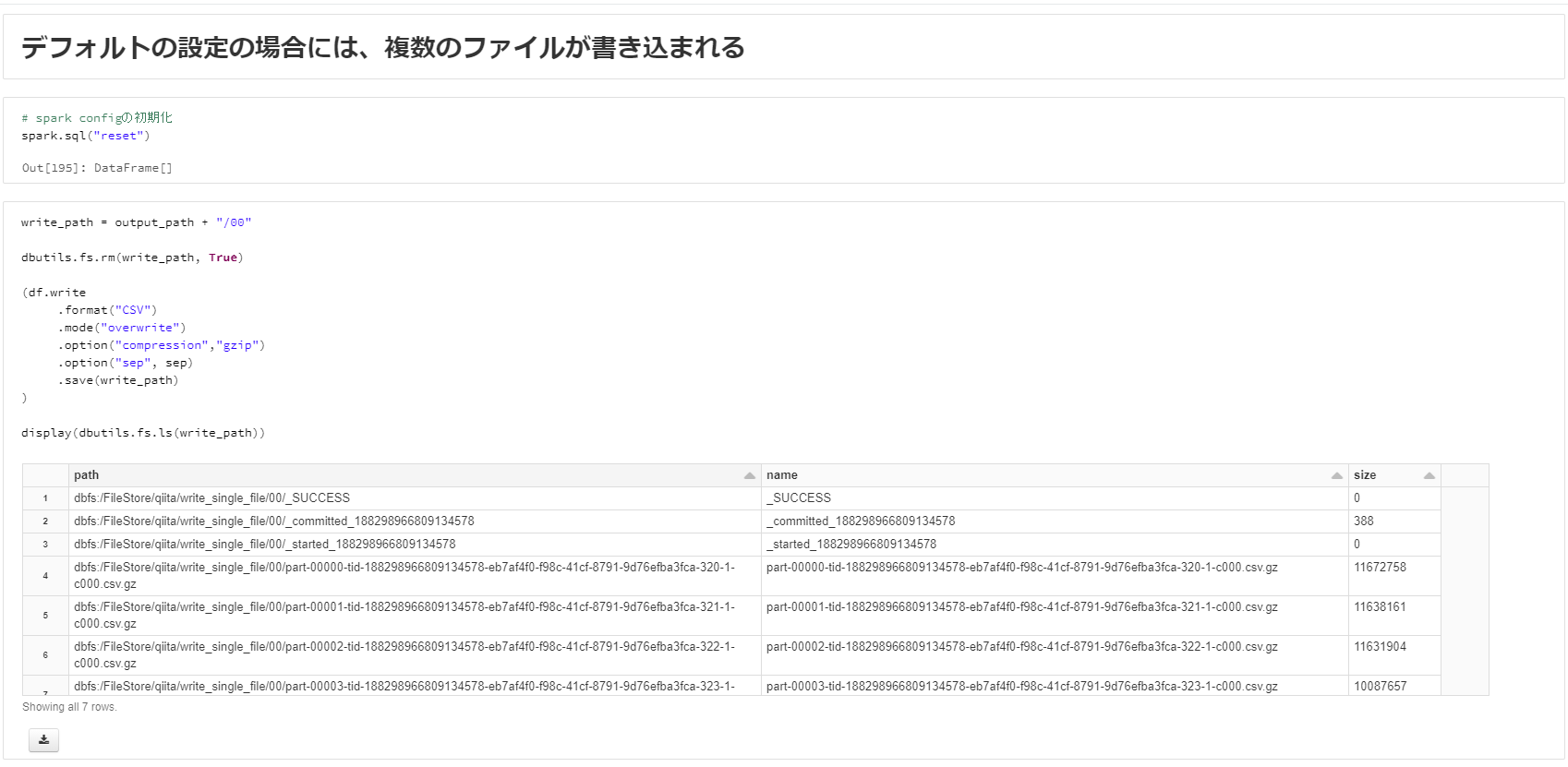
デフォルトの設定では、データを含むファイルが分割され、'_SUCCESS'などのファイルなどの無駄なファイルが書き込まれてしまいます。
本記事で紹介する方法により、単一ファイルのCSVファイルとして書き込むことができます。
コードはGithub pagesにて公開しております。
実際に試したい方は、下記のファイルをインポートしてください。
https://github.com/manabian-/databricks_tecks_for_qiita/blob/main/tecks/write_single_file/dbo/write_single_file.dbc
実施手順
Sparkコンフィグとパーティションの設定変更により、単一ファイルとして書き込む方法
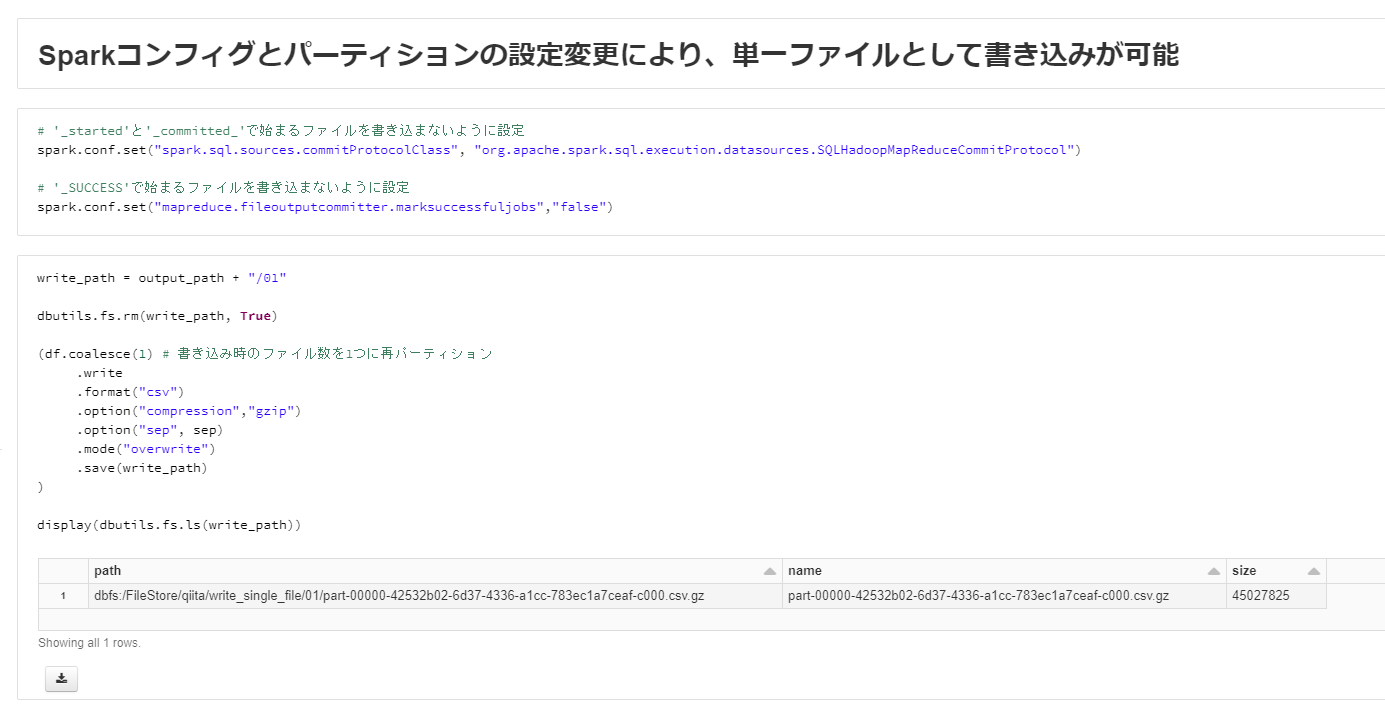
下記のようにSparkコンフィグを変更します。
# '_started'と'_committed_'で始まるファイルを書き込まないように設定
spark.conf.set("spark.sql.sources.commitProtocolClass", "org.apache.spark.sql.execution.datasources.SQLHadoopMapReduceCommitProtocol")
# '_SUCCESS'で始まるファイルを書き込まないように設定
spark.conf.set("mapreduce.fileoutputcommitter.marksuccessfuljobs","false")
書き込み前にデータフレームのパーティション数を、coalesce関数により1にします。
write_path = output_path + "/01"
dbutils.fs.rm(write_path, True)
(df.coalesce(1) # 書き込み時のファイル数を1つに再パーティション
.write
.format("csv")
.option("compression","gzip")
.option("sep", sep)
.mode("overwrite")
.save(write_path)
)
display(dbutils.fs.ls(write_path))
指定数の複数ファイルとして書き込む方法
上記の設定変更を実施したうえで、repartition関数を利用することで、指定数の複数ファイルとして書き込めます。
write_path = output_path + "/02"
dbutils.fs.rm(write_path, True)
(df.repartition(12)
.write
.format("csv")
.option("compression","gzip")
.option("sep", sep)
.mode("overwrite")
.save(write_path)
)
display(dbutils.fs.ls(write_path))

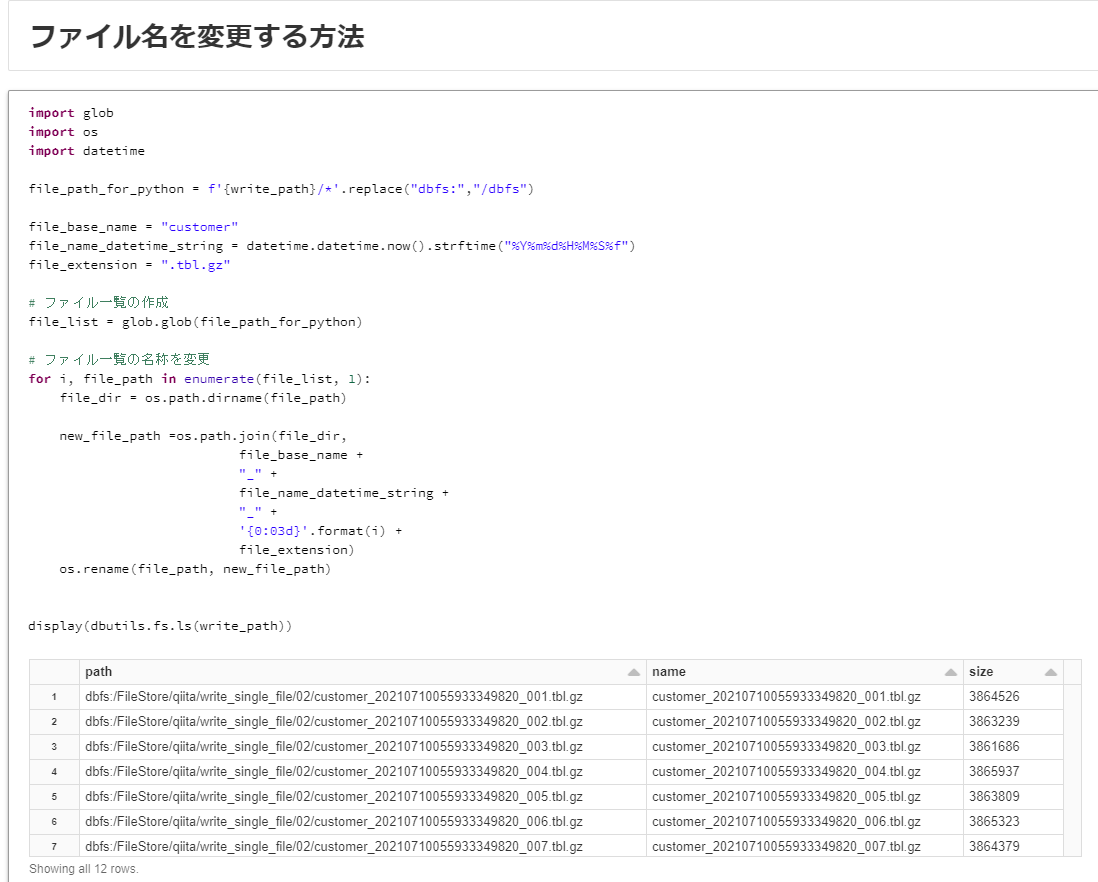
ファイル名の変更方法
ファイル名を変更する方法がSpark側の設定にはないため、Pythonにて名称を変更を実施する必要があります。
下記のコードでは、ファイル名_yyyymmddhhMMssmmmmmm_###.tbl.gzというファイル名に変更しております。
import glob
import os
import datetime
file_path_for_python = f'{write_path}/*'.replace("dbfs:","/dbfs")
file_base_name = "customer"
file_name_datetime_string = datetime.datetime.now().strftime("%Y%m%d%H%M%S%f")
file_extension = ".tbl.gz"
# ファイル一覧の作成
file_list = glob.glob(file_path_for_python)
# ファイル一覧の名称を変更
for i, file_path in enumerate(file_list, 1):
file_dir = os.path.dirname(file_path)
new_file_path =os.path.join(file_dir,
file_base_name +
"_" +
file_name_datetime_string +
"_" +
'{0:03d}'.format(i) +
file_extension)
os.rename(file_path, new_file_path)
display(dbutils.fs.ls(write_path))