Spark Partitions - Blog | luminousmenの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Sparkはクラスターで並列にデータを処理するためのエンジンです。Apache Sparkにおける並列性によって、開発者はクラスターの数百のマシン上でタスクを並列かつ独立に実行できるようになります。これはすべてApache Spakrの基本概念であるRDDによるものです。
内部では、これらのRDDは異なるクラスターノードのパーティションとして格納されます。パーティションは基本的に大規模分散データセットの論理的な塊です。これによって、クラスターに渡って作業を分配し、タスクをより小さいパーツに分割し、ノードごとのメモリー要件を削減することができます。パーティションはApache Sparkにおける並列性のメインユニットです。
パーティションについて話しましょう
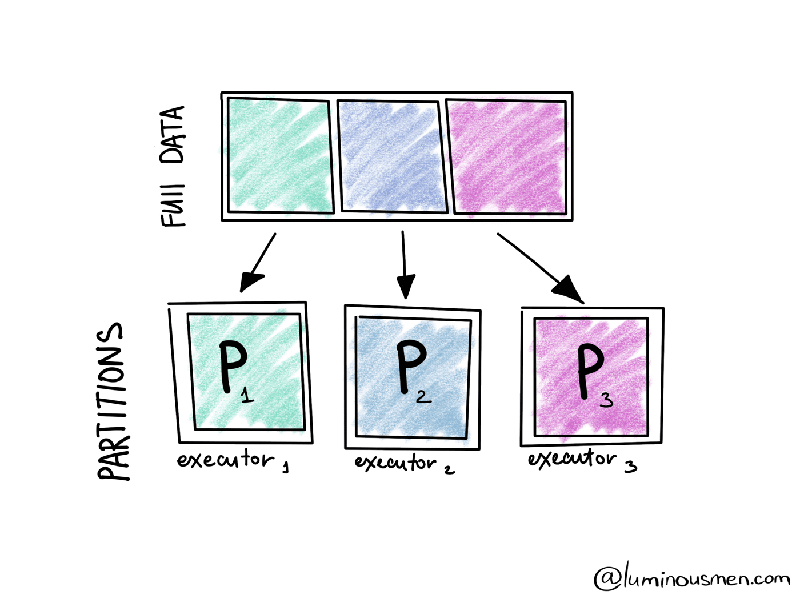
Sparkのパーティション≠Hiveのパーティションであることに注意してください。これらは両方がデータの塊ですが、Sparkは並列で処理を行うためにメモリーでデータを分割します。Hiveのパーティションは永続化のために、ストレージ、ディスクに格納されます。以降では、パーティションという際にはSparkのパーティションを意味します。
パーティションの存在に気づいていないとしてもパーティションを使用しますが、これらを操作することでデータ処理を高速化することができます。
内部で何が起きているのかを見ていきましょう。
import pandas as pd
import numpy as np
length = 100
names = np.random.choice(['Bob', 'James', 'Marek', 'Johannes', None], length)
amounts = np.random.randint(0, 1000000, length)
country = np.random.choice(
['United Kingdom', 'Poland', 'USA', 'Germany', None],
length
)
df = pd.DataFrame({'name': names, 'amount': amounts, 'country': country})
transactions = spark.createDataFrame(df)
print('Number of partitions: {}'.format(transactions.rdd.getNumPartitions()))
print('Partitioner: {}'.format(transactions.rdd.partitioner))
print('Partitions structure: {}'.format(transactions.rdd.glom().collect()))
パーティションの構造を見てみると、我々のデータが4つのパーティション(私のラップトップは4コアであり、Sparkがスタンドアローンモードで4つのエグゼキューターを作成しているためです)に分割されており、このデータフレームに変換処理を適用すると、それぞれのパーティションに対する処理は個別のスレッドで行われます(私の場合、それぞれのプロセッサコアとないります)。
でも、一体どうしてこのことを考えるのでしょうか?
最も重要な理由はパフォーマンスです。シングルノードでの計算に必要なすべてのデータを持つことで、シャッフル(シリアライゼーションとネットワークトラフィックを必要とします)のオーバーヘッドを削減します。
2つ目の理由はコスト削減です。クラスターの利用率を改善することで、アイドル状態のリソースの削減に役立ちます。
これらの問題を効率的に解決するために、パーティションを管理するためのメカニズムが必要となります。
Repartitioning(再パーティショニング)
パーティションを管理する1つ目の方法はrepartitionオペレーションです。
再パーティショニングとは、クラスターで分割されるデータのパーティションの数を増減するオペレーションです。このプロセスには、フルシャッフルが含まれます。結果として、再パーティショニングは高コストなプロセスであることは明白です。典型的なシナリオでは、データの大部分がシリアライズ、移動、デシリアライズされるべきです。
例えば、
repartitioned = transactions.repartition(8)
print('Number of partitions: {}'.format(repartitidoned.rdd.getNumPartitions()))
print('Partitions structure: {}'.format(repartitioned.rdd.glom().collect()))
パーティションの数が8に増加し、データがパーティションごとに再配置されたことがわかります。
直接パーティションの数を指定することに加え、データをパーティショニングしたいカラム名を指定することができます。
例えば、
repartitioned = transactions.repartition('country')
print('Number of partitions: {}'.format(repartitidoned.rdd.getNumPartitions()))
print('Partitions structure: {}'.format(repartitioned.rdd.glom().collect()))
パーティションの数は200になり、これらのパーティションの多くが完全に空になっていることがわかります。本書はこのポイントを議論します。
このオペレーションがあまり有用ではないケースが多く、お使いのSparkジョブをどのように高速化できるのかを明確に理解している場合にのみ、この方法を活用する意義があります。
Coalesce(結合)
パーティションを管理する2つ目の方法はcoalesceです。
このオペレーションはパーティションの数を削減し、フルシャッフルを回避します。 エグゼキューターは安全に最小数のパーティションにすることができ、冗長なノードからのみデータを移動します。このため、パーティションの数を減らす必要がある場合には、repartitionよりもcoalesceを使うべきです。
しかし、データ処理の並列性を劇的に削減できることを理解すべきです。coalesceは多くの場合、変換のチェーンでさらにプッシュアップされ、望んでいるよりも少ないノードになる場合があります。これを避けるためには、shuffle = trueを指定することができます。これはシャッフルのステップを追加しますが、可能であれば再シャッフルされたパーティションがすべてのクラスターリソースを使用します。
coalesced = transactions.coalesce(2)
print('Number of partitions: {}'.format(coalesced.rdd.getNumPartitions()))
print('Partitions structure: {}'.format(coalesced.rdd.glom().collect()))
我々のトイサンプルでは、残りのパーティションをウォークスルーし、どのデータが移動され、どのデータがそのままの場所にあるのかを確認することができます。
パーティションのレイヤー
異なるデータ処理のレイヤーのSparkパーティションのトピックにハイライトしたいと思います。この記事では、これらの1つのレイヤーのみを話したいと思いますが、次の記事では直接的なティップスをフォローアップします。
物理レベルにおいて、パーティションの数が重要となる3つのステージが存在します。入力、シャッフル、出力です。
これらのそれぞれは、異なる方法で調整、管理します。例えば、入力と出力では、パーティションのサイズを制御できますが、出力においては、coalesceやrepartitionを行うことで、ファイルの数やタスクの数を制御することもできます。シャッフルにおいては、ネットワークを移動するデータの数を制御することができます。
入力ステージにおけるパーティショニング
入力データセットのサイズに基づいてパーティションの数を決定するところからスタートしましょう。
データを分割できる場合、Sparkは入力データを非常にうまく取り扱うことができます。どのようにHDFSやCassandraのようなデータストレージがデータを配置するのかと、どのようにSparkが読み込みの際にデータを分割するのかには明確な一致点があります。
10ノードに分散されるHDFS上の未圧縮のテキストファイルから構成される約30GB(~30000 MB)の入力データを想定してみましょう。
SparkがHDFSから読み込みまず、単一の入力スプリットに対する単一のパーティションを作成します。入力スプリットはファイルを読み込むために使われるHadoopのInputFormatで設定されます。HDFSに格納された30GBの未圧縮のテキストファイルがあり、デフォルトのHDFSブロックサイズの設定(128MB)とデフォルトのspark.files.maxPartitionBytes(128MB)によって240ブロックに格納されるので、このファイルから読み込むデータフレームは240パーティションとなります。
これはSparkのデフォルトの並列性(spark.default.parallelism)の値と一致します。
お使いのデータが分割できない場合、Sparkhがデフォルトのパーティション数を使用します。ジョブがスタートする際、パーティションの数はすべてのエグゼキューターノードのトータルのコア数と等しくなります。
シャッフルパーティショニング
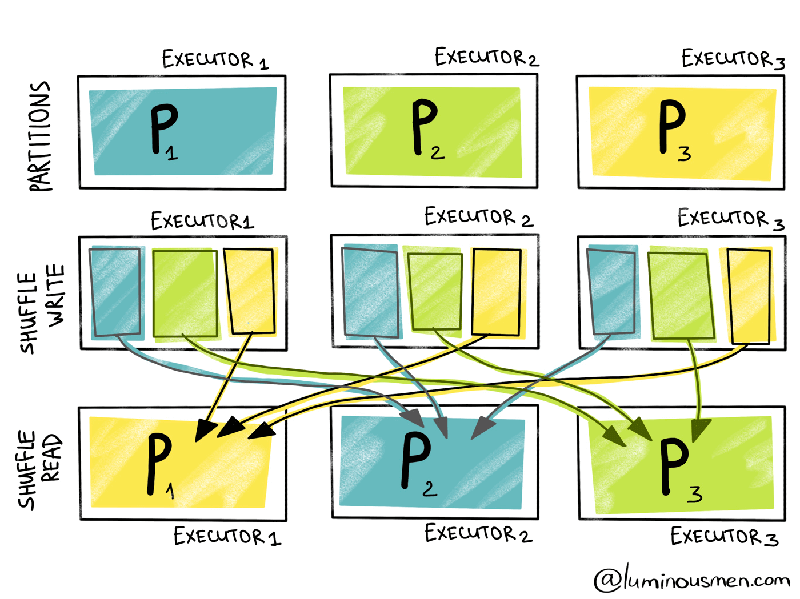
Sparkパイプラインにおいて最も苦痛なスポットは、他のパーティションの情報を必要とし、シャッフルを引き起こすワイドな変換処理です。残念ですが、このような変換処理を取り除くことはできますが、性能に対するシャッフルのインパクトを軽減することはできます。
シャッフルパーティションはワイドな変換処理におけるデータのシャッフルで用いられるパーティションです。しかし、ワイドな変換処理においては、シャッフルパーティションの数は200に設定されています。お使いのデータが大きいか小さいか、お使いのクラスター構成が20のエグゼキューターかどうかは問題ではなく、依然として200です。はい、はい、これはrepartitionのセクションで見たものであり、これはミステリアスな数値です。
このため、シャッフルにおける並列性を制御するパラメーターはspark.sql.shuffle.partitionsとなります。デフォルトが200である理由は、現実世界での経験によってこれが非常に良いデフォルト値であることがわかったためです。しかし、実際には、この値は常に悪いものとなります。
小規模のデータを取り扱う際、通常はシャッフルパーティションの数を減らすべきであり、さもないとパーティションごとに少数のエントリーを持つ大量のパーティションを引き起こすことになり、すべてのエグゼキューターの使用率は低いものとなり、エグゼキューター間のネットワークデータ先頭層に要する時間が増加することになります。
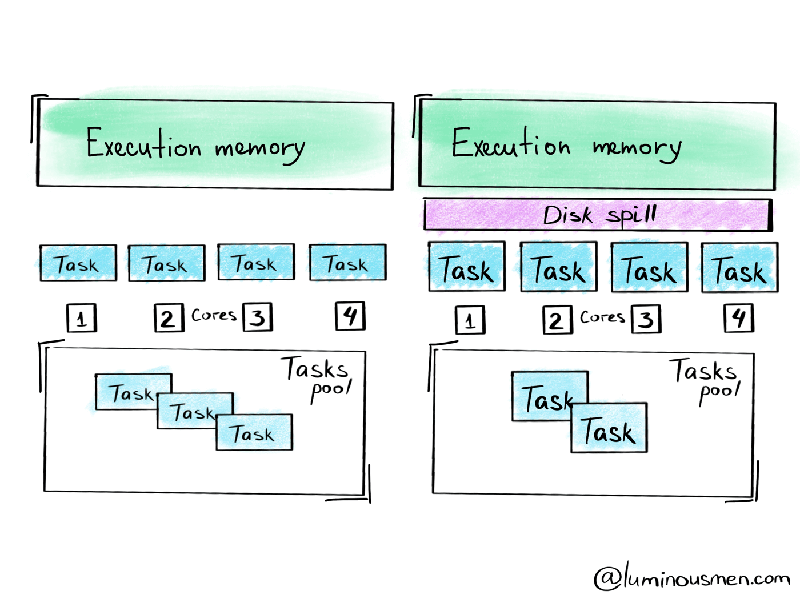
一方、少なすぎるパーティションに大量のデータが存在すると、エグゼキューターで処理されるタスクの数が少なくなり、個々のエグゼキューターでのロードが増え、メモリーエラーを引き起こすことになります。また、エグゼキューターで利用できるメモリー以上のパーティションサイズにすると、ディスクへの溢れ(スピル)を引き起こします。スピルは考えられる範囲で最も遅いものです。 基本的に、ディスクへのスピルを行なっている間、Sparkのオペレーションはメモリーに収まらない場合、RAMの一部のデータをディスクに書き出し、任意のサイズのデータに対してSparkジョブが稼働するようにします。あなたのパイプラインを壊しはしませんが、ディスクI/Oとガーベージコレクションの追加のオーバーヘッドによって、非常に非効率的なものとなってしまいます。
このため、spark.sql.shuffle.partitionsは、Sparkを使う際に最も頻繁に設定するパラメーターの一つとなります。
出力のパーティショニング
適切に選択された条件でパーティションされたデータを保存することで、以降の処理パイプラインにおいて必要なデータの読み込み、取得を劇的に高速化することができます。
最初に、いくつかのケースにおいては、データソースのパーティション検索の後にパーティションのプルーニング(刈り込み)を使うことができ、Sparkがクエリーの際に読み込むファイルとパーティションの数を限定することができます。時には(例えばAWS S3)、不要なパーティション検索すらも回避することができます。Spark 3.0における動的パーティションプルーニングの概念も重要です。しかし、時にはこれらの最適化が状況を悪化させることもあります。例えば、最初のクエリーにおいてパーティションを理解するためのメタデータを取得するために、ファイルシステムを再帰的にスキャンする処理に(パーティションの数が多い場合)非常に長い時間がかかることがあります。また、すべてのテーブルメタデータは、ドライバープロセスのメモリーにマテリアライズされなくてはならないため、メモリー使用量が非常に大きくなります。
第二に、データフレームをディスクに保存する際には、パーティションのサイズに特別の注意を払ってください。書き込みの際、Sparkはタスクごとに1つのファイル(パーティションあたり1ファイル)を生成し、読み込みの際にはタスクで最低1つのファイルを読み込みます。ここでの問題は、データフレームが保存されたクラスターの構成では、より多くのメモリーを搭載していたため、何の問題もなしに大きなパーティションサイズを処理できていましたが、保存されたデータフレームを小規模なクラスターで読み込もうとすると問題となる場合があるということです。
例えば、大規模な前処理用のクラスターがあり、小規模かつよりコスト効率の高いサービス用のクラスターがあったとします。この状況でのソリューションは、後段のクラウターが溺れないように、書き込みの前にデータフレームをより多いパーティションにrepartitionするというものです。
まとめ
- パーティションの数を増やす際には、
repartition()(フルシャッフルを実行します)を使います。 - パーティションの数を減らす際には、
coalesce()(シャッフルを最小化します)を使います。
今日は、物理レベルのパーティションについてお話ししました。次の記事では、より高位のレベルに移動し、パーティションチューニングをどのように行うのかをお話しします。