来月9/16(火)19時から開催するもくもく会のノートブックをウォークスルーします。
使用するノートブックはこちらです。
ノートブックの取り込み方法
Gitフォルダを作成して、上のリポジトリをクローンします。
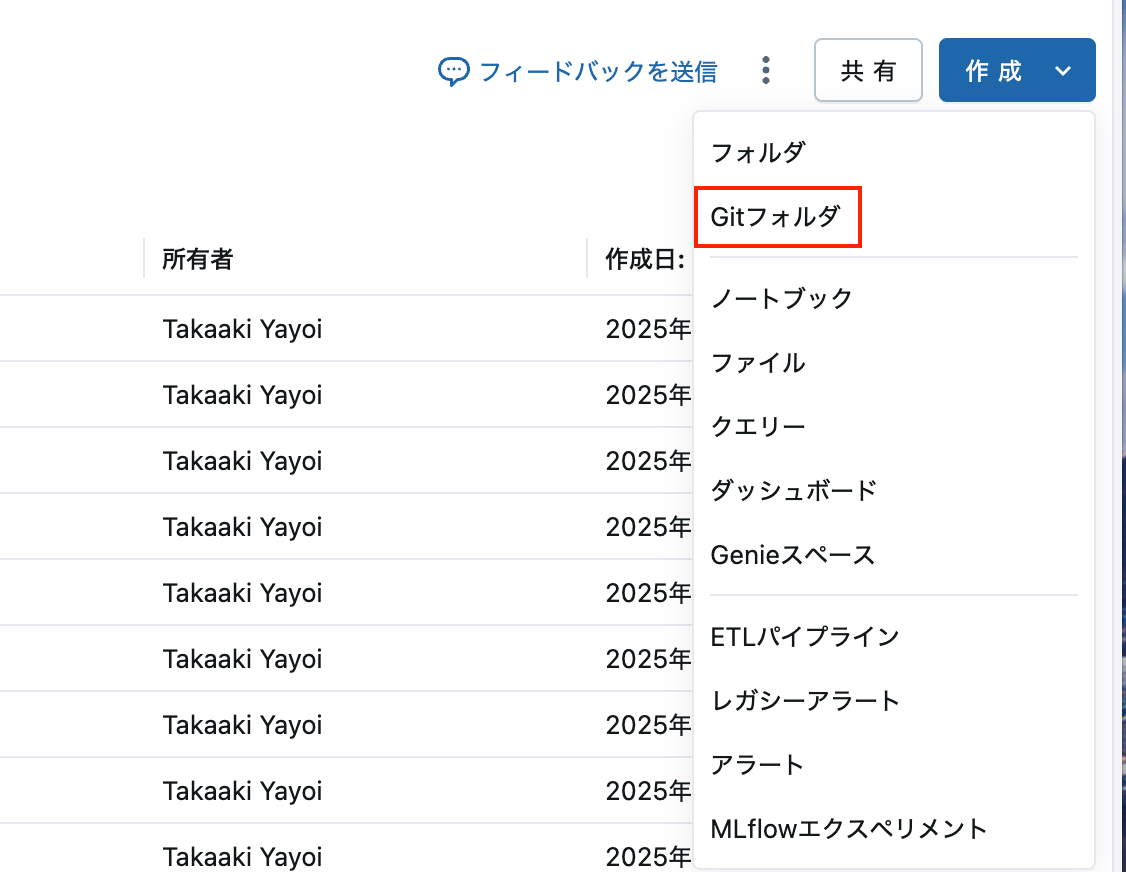
URLにhttps://github.com/taka-yayoi/spark_mokumokuを指定します。
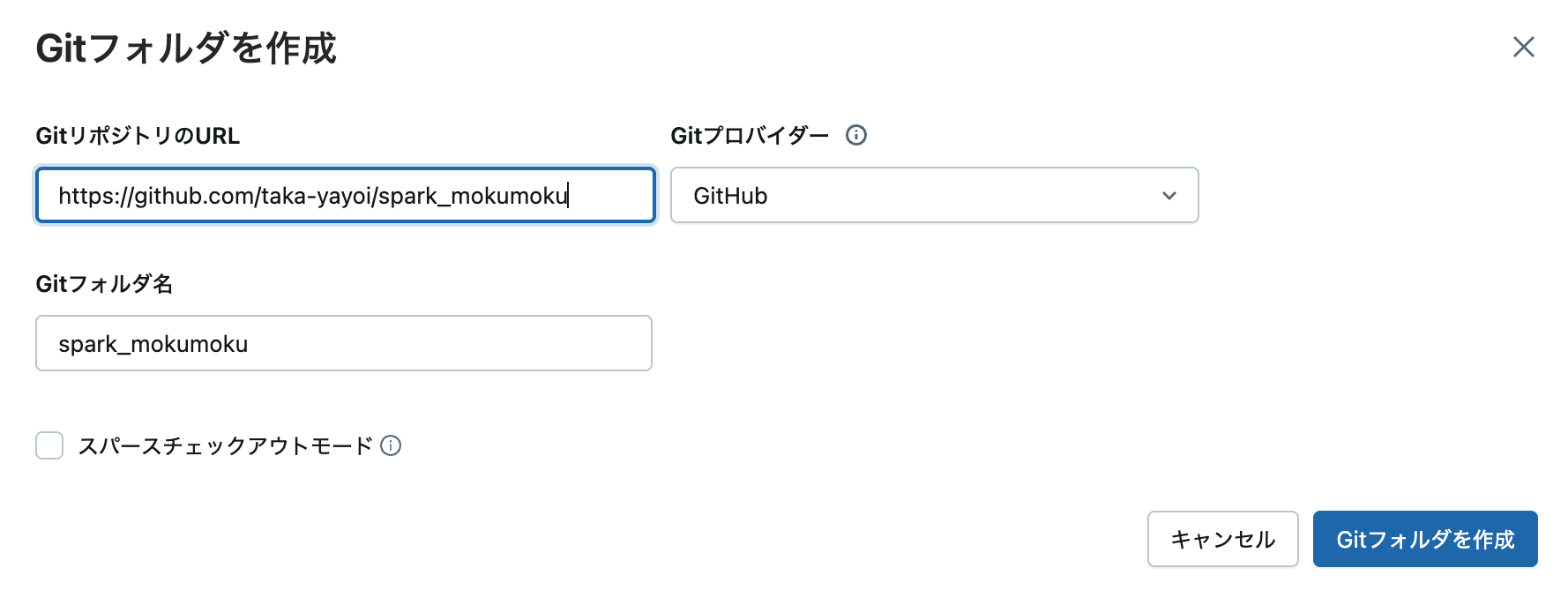
spark-mokumoku-notebookノートブックを開きます。
Apache Sparkもくもく会ハンズオンノートブック
🎯 今日の目標
このもくもく会では、Apache Sparkの基礎を実際に手を動かしながら学んでいきます。大規模データ処理の世界への第一歩を踏み出しましょう!
📋 事前準備
- Databricks Free Editionにログイン済み
- サーバレスコンピュートが起動済み
- このノートブックをインポート済み
🚀 学習の流れ
- Sparkの基本概念を理解
- データフレームの操作を習得
- 実データでの分析を実践
- SQLとの連携を学習
- Unity Catalogとの統合を理解
📚 第1部: Apache Sparkとは
Sparkの誕生ストーリー
2009年、カリフォルニア大学バークレー校で誕生したApache Sparkは、ビッグデータ処理に革命をもたらしました。Databricksの創業者たちが開発したこのフレームワークは、従来のHadoop MapReduceと比較して、中間結果をメモリーに保持することで100倍以上の高速化を実現しました。
🐼 PandasとSparkの違い
多くの方が使い慣れているPandasと比較してSparkを理解しましょう:
| 特徴 | Pandas | Apache Spark |
|---|---|---|
| 処理方式 | 単一マシン(シングルスレッド) | 分散処理(複数マシン・並列処理) |
| データサイズ | メモリに収まる範囲(通常数GB) | メモリを超える大規模データ(TB〜PB) |
| 処理速度 | 小規模データでは高速 | 大規模データで圧倒的に高速 |
| 実行タイミング | 即座に実行(Eager Evaluation) | 遅延評価(Lazy Evaluation) |
| データ構造 | DataFrame | DataFrame(分散) |
| スケーラビリティ | 垂直スケール(マシンスペック依存) | 水平スケール(ノード追加で対応) |
| エラー処理 | エラー時は最初から | 障害耐性あり(自動リトライ) |

なぜSparkを学ぶのか?
- 🚀 スピード: メモリベースの処理により、大規模データを高速に処理
- 🎯 使いやすさ: Pandasに似たDataFrame APIで学習曲線が緩やか
- 🔧 モジュール性: SQL、機械学習、ストリーミング処理など多様な用途に対応
- 📈 拡張性: データ量の増加に柔軟に対応可能
🔍 これから実行するコード
最初に、Databricksで自動的に作成されているSparkセッションを確認します。
Sparkセッションは、Sparkの全機能への入口となる重要なオブジェクトです。
# Sparkセッションの確認
# Databricksでは起動時に自動的に`spark`変数が作成されています
# これがSparkへのエントリーポイントとなります
spark
<pyspark.sql.connect.session.SparkSession at 0x7fd850e666d0>
📊 Sparkのバージョンと設定を確認
現在使用しているSparkの環境情報を確認してみましょう。
# Sparkのバージョンを確認
# サーバレスコンピュートでは最新のSparkバージョンが使用されます
print(f"Sparkバージョン: {spark.version}")
# 現在のカタログとデータベースを確認
print(f"現在のカタログ: {spark.sql('SELECT current_catalog()').first()[0]}")
print(f"現在のデータベース: {spark.sql('SELECT current_database()').first()[0]}")
Sparkバージョン: 4.0.0
現在のカタログ: workspace
現在のデータベース: default
🏗️ 第2部: Sparkの基本アーキテクチャを詳しく理解する
📐 Sparkクラスターの構成要素
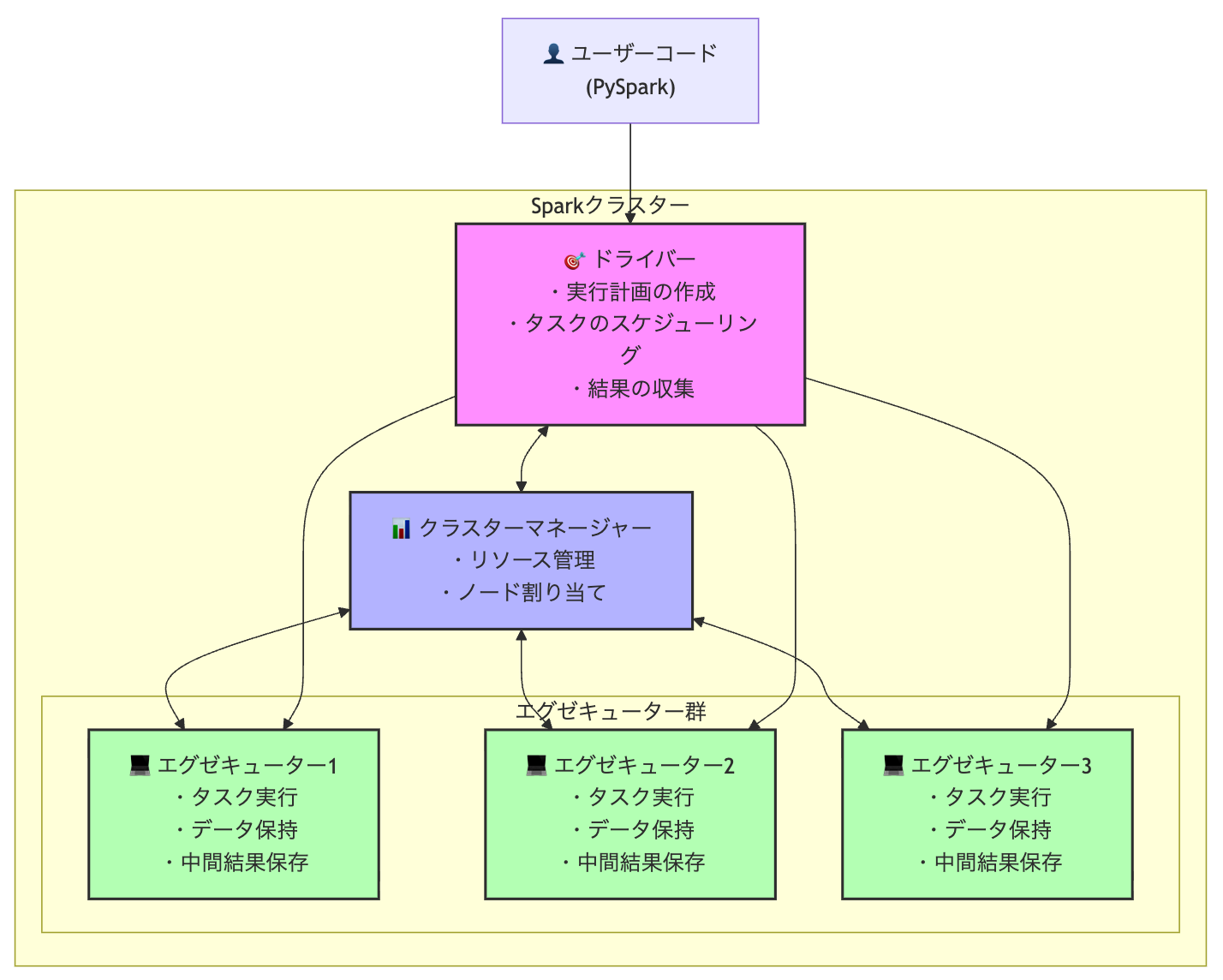
Sparkは分散処理システムとして設計されており、以下の主要コンポーネントから構成されています:
1. ドライバー(Driver)
- 役割: アプリケーション全体の司令塔
-
責任:
- ユーザーコードをタスクに変換
- タスクのスケジューリング
- エグゼキューターの監視
- 実行計画の最適化
2. エグゼキューター(Executor)
- 役割: 実際のデータ処理を実行
-
責任:
- タスクの実行
- データの保持(メモリまたはディスク)
- 中間結果の保存
- ドライバーへの結果返却
3. クラスターマネージャー
- 役割: リソースの管理と割り当て
- 種類: Databricks(サーバレス)、YARN、Mesos、Kubernetes等
🔄 処理の流れ
[ユーザーコード]
↓
[ドライバー] → 論理実行計画 → 物理実行計画 → タスク生成
↓
[クラスターマネージャー] → リソース割り当て
↓
[エグゼキューター群] → 並列実行
↓
[結果の集約]
🎯 重要な概念
- パーティション: データを分割した単位(並列処理の基本単位)
- タスク: パーティションに対する処理の単位
- ステージ: シャッフルで区切られたタスクのグループ
- ジョブ: アクションによって起動される全体の処理
🔍 アーキテクチャの動作原理
Sparkでデータ処理を実行する際の内部動作を理解しましょう:
例: 1000個の数値を処理する場合
# データフレームを4つのパーティションで作成
numbers_df = spark.range(0, 1000, 1, numPartitions=4)
このコードが実行されると、以下のような処理が行われます:
-
パーティション分割
- 0-249: パーティション1 → エグゼキューター1で処理
- 250-499: パーティション2 → エグゼキューター2で処理
- 500-749: パーティション3 → エグゼキューター3で処理
- 750-999: パーティション4 → エグゼキューター4で処理
-
並列実行
- 4つのタスクが同時に実行される
- 各エグゼキューターが独立して処理
- 処理時間は約1/4に短縮
-
結果の集約
- 各エグゼキューターの結果をドライバーが収集
- 最終的な結果を生成
サーバレス環境での最適化
Databricksのサーバレスコンピュートでは:
- パーティション数が自動的に最適化される
- リソースが動的に割り当てられる
- 負荷に応じてエグゼキューターが自動スケール"
📝 理解度チェック
- Q1: ドライバーの主な役割は何でしょうか?
- Q2: エグゼキューターは何を実行しますか?
- Q3: パーティションとタスクの関係は?
これらの質問に答えられるようになれば、Sparkアーキテクチャの基本を理解できています!
🎬 第3部: 最初のSparkデータフレームを作成
📖 トランスフォーメーションとアクションの理解
Sparkの処理は大きく2種類に分類されます:
-
トランスフォーメーション(Transformation)
- データの変換処理を定義(まだ実行されない)
- 例:
select(),filter(),groupBy()
-
アクション(Action)
- 実際に処理を実行して結果を返す
- 例:
count(),show(),collect()

Step 1: シンプルなデータフレームの作成
まず、連番データを持つデータフレームを作成します。
# 大規模データを想定して、1から100万までの数値を生成
# range()メソッドは「トランスフォーメーション」
# この時点ではデータは生成されず、処理の定義のみが作成されます
first_df = spark.range(1000000)
# データフレームの型を確認
print(f"データフレームの型: {type(first_df)}")
print(f"データフレームのクラス: {first_df.__class__.__name__}")
# スキーマ(データ構造)を確認
# この情報はメタデータとして保持されているため、データを読まずに表示できます
print(f"\nスキーマ情報: {first_df}")
print("\n詳細なスキーマ:")
first_df.printSchema()
データフレームの型: <class 'pyspark.sql.connect.dataframe.DataFrame'>
データフレームのクラス: DataFrame
スキーマ情報: DataFrame[id: bigint]
詳細なスキーマ:
root
|-- id: long (nullable = false)
Step 2: トランスフォーメーションのチェーン
複数のトランスフォーメーションを連鎖させて、処理のパイプラインを構築します。
# selectExpr()を使って、SQL式で新しいカラムを作成
# まだ実行されません - 処理の定義を追加するだけ
doubled_df = first_df.selectExpr(
"id as original_id", # 元のIDカラムをリネーム
"(id * 2) as doubled_value" # IDを2倍にした新しいカラム
)
# さらにトランスフォーメーションを追加
# メソッドチェーンで複数の処理を連結できます
final_df = doubled_df.selectExpr(
"original_id",
"doubled_value",
"(doubled_value / 1000) as divided_by_1000", # 1000で割る
"(doubled_value % 100) as modulo_100" # 100で割った余り
)
# この時点でもまだ処理は実行されていません
print("トランスフォーメーションのチェーンが定義されました")
print("実際の処理はアクションが呼ばれるまで実行されません")
トランスフォーメーションのチェーンが定義されました
実際の処理はアクションが呼ばれるまで実行されません
Step 3: アクションで処理を実行
アクションを呼び出すことで、定義した処理が実際に実行されます。
# take()アクションで上位N件を取得
# ここで初めてSparkが処理を実行します!
print("🎯 処理を実行中...")
results = final_df.take(10) # 上位10件を取得
# 結果を見やすく表示
print("\n📊 処理結果の最初の10件:")
print("-" * 80)
print(f"{'元のID':>10} | {'2倍の値':>10} | {'1000で割った値':>15} | {'100の余り':>10}")
print("-" * 80)
for row in results:
print(f"{row['original_id']:10d} | "
f"{row['doubled_value']:10d} | "
f"{row['divided_by_1000']:15.2f} | "
f"{row['modulo_100']:10d}")
🎯 処理を実行中...
📊 処理結果の最初の10件:
--------------------------------------------------------------------------------
元のID | 2倍の値 | 1000で割った値 | 100の余り
--------------------------------------------------------------------------------
0 | 0 | 0.00 | 0
1 | 2 | 0.00 | 2
2 | 4 | 0.00 | 4
3 | 6 | 0.01 | 6
4 | 8 | 0.01 | 8
5 | 10 | 0.01 | 10
6 | 12 | 0.01 | 12
7 | 14 | 0.01 | 14
8 | 16 | 0.02 | 16
9 | 18 | 0.02 | 18
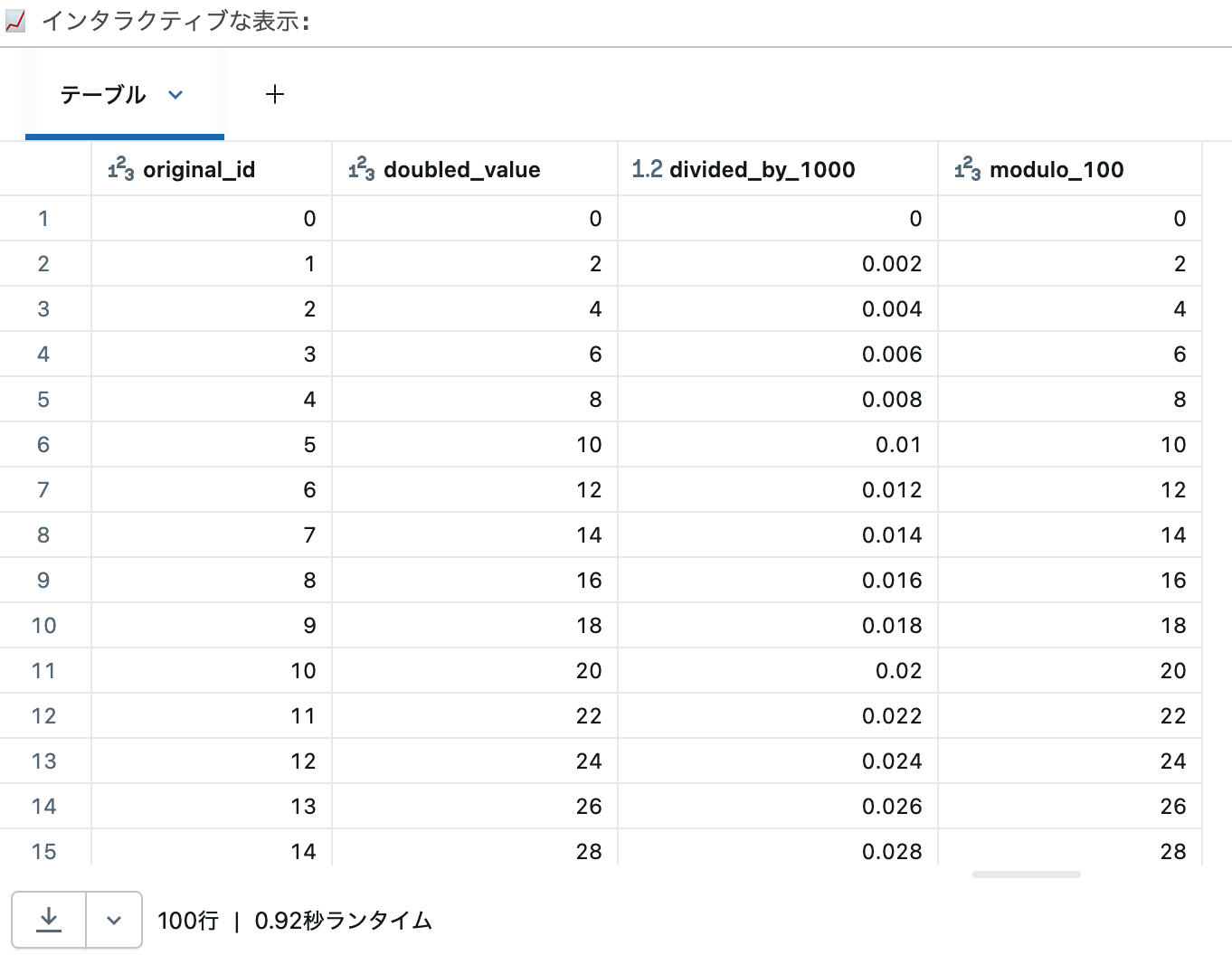
🎨 Databricksの可視化機能を活用
display()関数を使うと、結果をインタラクティブに表示できます。
# display()もアクションとして動作します
# 上位100件を表示(大量データの場合は自動的に制限されます)
print("📈 インタラクティブな表示:")
display(final_df.limit(100)) # limit()はトランスフォーメーション、display()がアクション
📊 第4部: 実データで学ぶデータ処理
💎 ダイヤモンドデータセットの紹介
ここからは、実際のデータセットを使って実践的なデータ処理を学びます。
使用するのは、約54,000個のダイヤモンドの品質と価格に関するデータです。
データの読み込み
CSV形式のファイルをSparkデータフレームに読み込みます。
# Databricksに事前に用意されているサンプルデータのパス
data_path = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv"
# CSVファイルの読み込み
# spark.read を使用してデータを読み込みます
diamonds = (
spark.read.format("csv")
.option("header", "true") # 1行目をヘッダーとして扱う
.option("inferSchema", "true") # データ型を自動推論
.load(data_path) # ファイルパスを指定して読み込み
)
# データセットの基本情報を表示
print("📊 データセットの概要:")
print(f" 総レコード数: {diamonds.count():,} 件")
print(f" カラム数: {len(diamonds.columns)} 個")
print("\n📝 カラム一覧:")
for i, col in enumerate(diamonds.columns, 1):
print(f" {i:2d}. {col}")
📊 データセットの概要:
総レコード数: 53,940 件
カラム数: 11 個
📝 カラム一覧:
1. _c0
2. carat
3. cut
4. color
5. clarity
6. depth
7. table
8. price
9. x
10. y
11. z
データの探索
データの中身を確認して、どのような情報が含まれているか理解します。
# show()メソッドで最初の数行を表示
# truncate=Falseで文字列が切れないように表示
print("💎 ダイヤモンドデータの最初の5行:")
diamonds.show(5, truncate=False)
# 各カラムの説明
print("\n📖 カラムの説明:")
print(" - carat: カラット(重さ)")
print(" - cut: カットの品質(Fair, Good, Very Good, Premium, Ideal)")
print(" - color: 色のグレード(D=最高 から J=最低)")
print(" - clarity: 透明度(I1=最低, SI2, SI1, VS2, VS1, VVS2, VVS1, IF=最高)")
print(" - price: 価格(USドル)")
💎 ダイヤモンドデータの最初の5行:
+---+-----+-------+-----+-------+-----+-----+-----+----+----+----+
|_c0|carat|cut |color|clarity|depth|table|price|x |y |z |
+---+-----+-------+-----+-------+-----+-----+-----+----+----+----+
|1 |0.23 |Ideal |E |SI2 |61.5 |55.0 |326 |3.95|3.98|2.43|
|2 |0.21 |Premium|E |SI1 |59.8 |61.0 |326 |3.89|3.84|2.31|
|3 |0.23 |Good |E |VS1 |56.9 |65.0 |327 |4.05|4.07|2.31|
|4 |0.29 |Premium|I |VS2 |62.4 |58.0 |334 |4.2 |4.23|2.63|
|5 |0.31 |Good |J |SI2 |63.3 |58.0 |335 |4.34|4.35|2.75|
+---+-----+-------+-----+-------+-----+-----+-----+----+----+----+
only showing top 5 rows
📖 カラムの説明:
- carat: カラット(重さ)
- cut: カットの品質(Fair, Good, Very Good, Premium, Ideal)
- color: 色のグレード(D=最高 から J=最低)
- clarity: 透明度(I1=最低, SI2, SI1, VS2, VS1, VVS2, VVS1, IF=最高)
- price: 価格(USドル)
# データ型(スキーマ)の詳細を確認
print("📋 データ型の詳細:")
diamonds.printSchema()
# 各データ型の説明
print("\n💡 データ型の説明:")
print(" - string: 文字列型(カテゴリカルデータ)")
print(" - double: 浮動小数点型(連続値)")
print(" - integer: 整数型")
📋 データ型の詳細:
root
|-- _c0: integer (nullable = true)
|-- carat: double (nullable = true)
|-- cut: string (nullable = true)
|-- color: string (nullable = true)
|-- clarity: string (nullable = true)
|-- depth: double (nullable = true)
|-- table: double (nullable = true)
|-- price: integer (nullable = true)
|-- x: double (nullable = true)
|-- y: double (nullable = true)
|-- z: double (nullable = true)
💡 データ型の説明:
- string: 文字列型(カテゴリカルデータ)
- double: 浮動小数点型(連続値)
- integer: 整数型
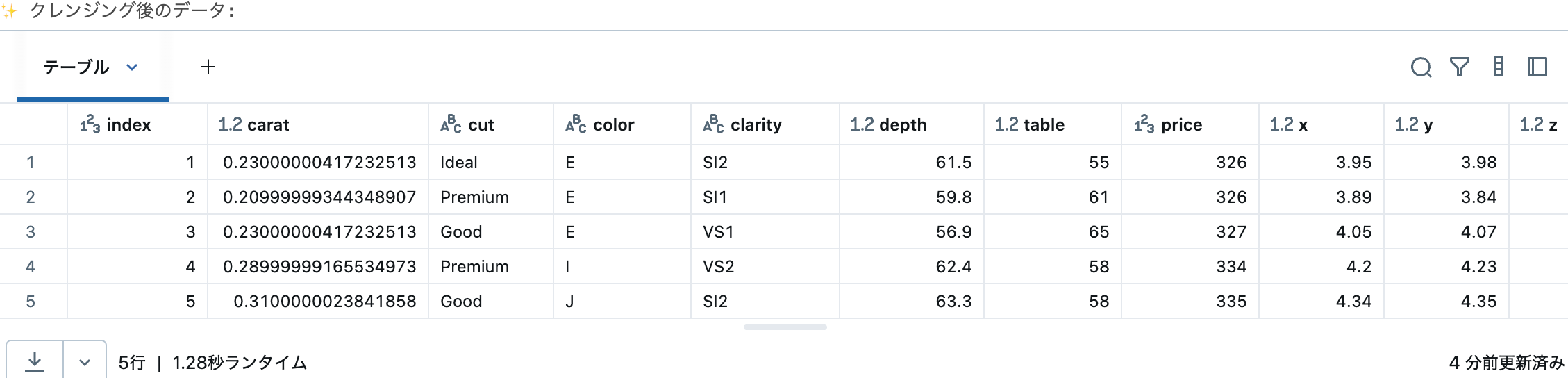
データクレンジング
分析しやすいようにデータを整形します。
from pyspark.sql.functions import col
# カラム名の変更とデータ型の調整
diamonds_clean = (
diamonds
.withColumnRenamed("_c0", "index") # 最初のカラムをindexに変更
.withColumn("price", col("price").cast("integer")) # priceを整数型に変換
.withColumn("carat", col("carat").cast("float")) # caratを浮動小数点型に変換
)
# クレンジング結果を確認
print("✨ クレンジング後のデータ:")
display(diamonds_clean.limit(5))
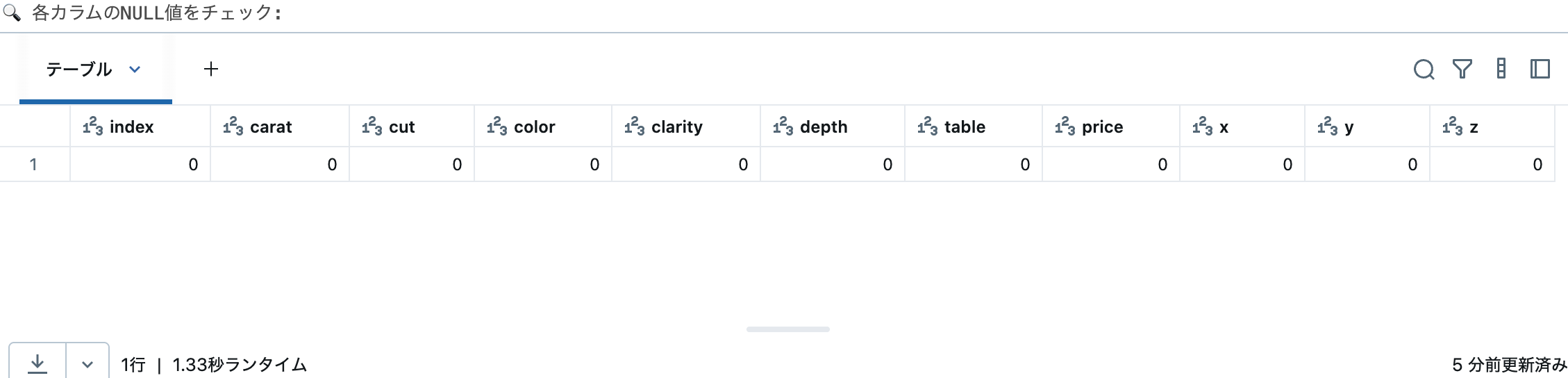
# NULL値の確認
# 実データでは欠損値の確認が重要です
from pyspark.sql.functions import count, when, isnan
print("🔍 各カラムのNULL値をチェック:")
# 各カラムのNULL値をカウントする処理の詳細
# 1. diamonds_clean.columns で全カラム名のリストを取得
# 2. 各カラムに対してcount(when(...))を適用
# - when(col(c).isNull(), c): カラムcがNULLの場合、カラム名を返す
# - count(): NULLでない値(つまり上記whenで返されたカラム名)をカウント
# - alias(c): 結果のカラム名を元のカラム名と同じにする
# 3. select([...])で全カラムのNULLカウントを一度に取得
null_counts = diamonds_clean.select([
count(when(col(c).isNull(), c)).alias(c)
for c in diamonds_clean.columns
])
# 結果を表示
# 各カラムの下に表示される数値がNULL値の個数
# 0が表示されていれば、そのカラムにはNULL値が存在しない
display(null_counts)
# 追加情報: isnan()関数について
# isnan()は数値カラムのNaN(Not a Number)をチェックする関数
# このデータセットでは文字列カラムも含まれているため、
# isNull()を使用してNULL値をチェックしています
print("\n✅ このデータセットには欠損値がないことが確認できました")
print(" (全カラムでNULL値のカウントが0)")
📈 第5部: データ分析の実践
基本的な集計処理
GroupByとAggregation関数を使って、データを集計します。
# 必要な集計関数をインポート
from pyspark.sql.functions import avg, max, min, stddev, round, count
# カット品質ごとの価格統計を計算
cut_analysis = (
diamonds_clean
.groupBy("cut") # カット品質でグループ化
.agg(
count("*").alias("個数"), # レコード数をカウント
round(avg("price"), 2).alias("平均価格"), # 平均価格(小数点2桁)
round(min("price"), 2).alias("最低価格"), # 最低価格
round(max("price"), 2).alias("最高価格"), # 最高価格
round(stddev("price"), 2).alias("価格の標準偏差") # 価格のばらつき
)
.orderBy("平均価格", ascending=False) # 平均価格の降順でソート
)
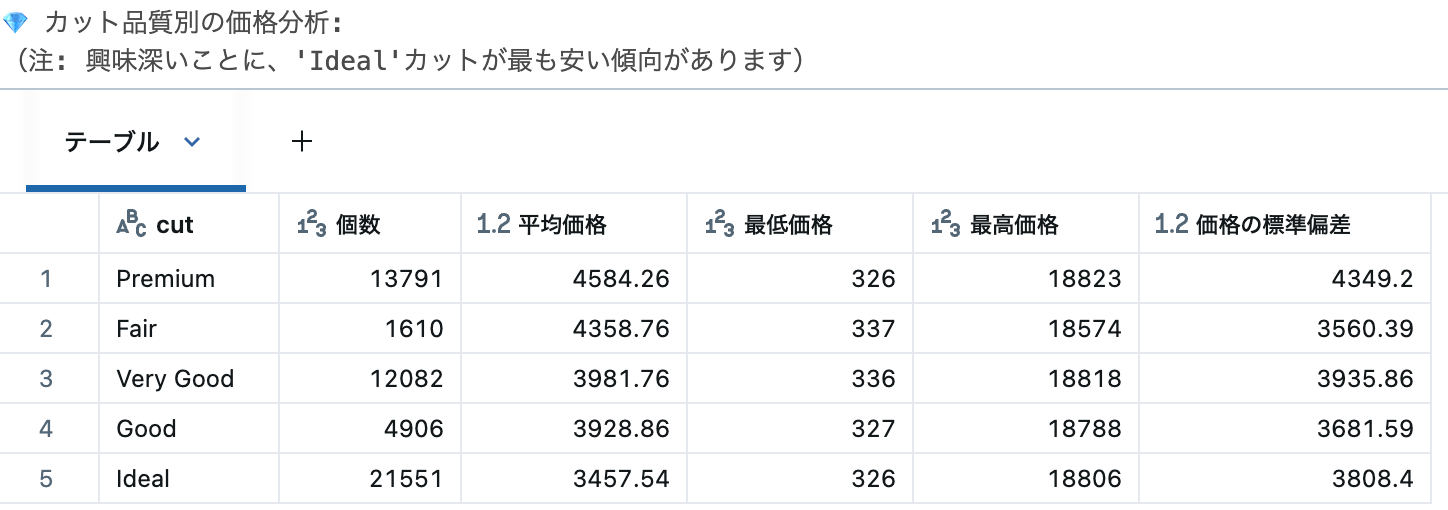
print("💎 カット品質別の価格分析:")
print("(注: 興味深いことに、'Ideal'カットが最も安い傾向があります)")
display(cut_analysis)
複雑な分析: カテゴリ分けと複合集計
条件分岐を使ったカテゴリ分けと、複数の軸での集計を行います。
from pyspark.sql.functions import when, col
# カラットサイズでカテゴリ分け
# when()関数で条件分岐を実装
# 番号を付けることで、表示時に適切な順序でソートされるようにする
diamonds_categorized = diamonds_clean.withColumn(
"carat_category",
when(col("carat") < 0.5, "1_小(< 0.5ct)")
.when(col("carat") < 1.0, "2_中(0.5-1.0ct)")
.when(col("carat") < 1.5, "3_大(1.0-1.5ct)")
.otherwise("4_特大(>= 1.5ct)")
)
# カテゴリとカットの組み合わせで集計
category_analysis = (
diamonds_categorized
.groupBy("carat_category", "cut") # 2つの軸でグループ化
.agg(
count("*").alias("個数"),
round(avg("price"), 2).alias("平均価格")
)
.orderBy("carat_category", "cut") # カテゴリ、カットの順でソート
)
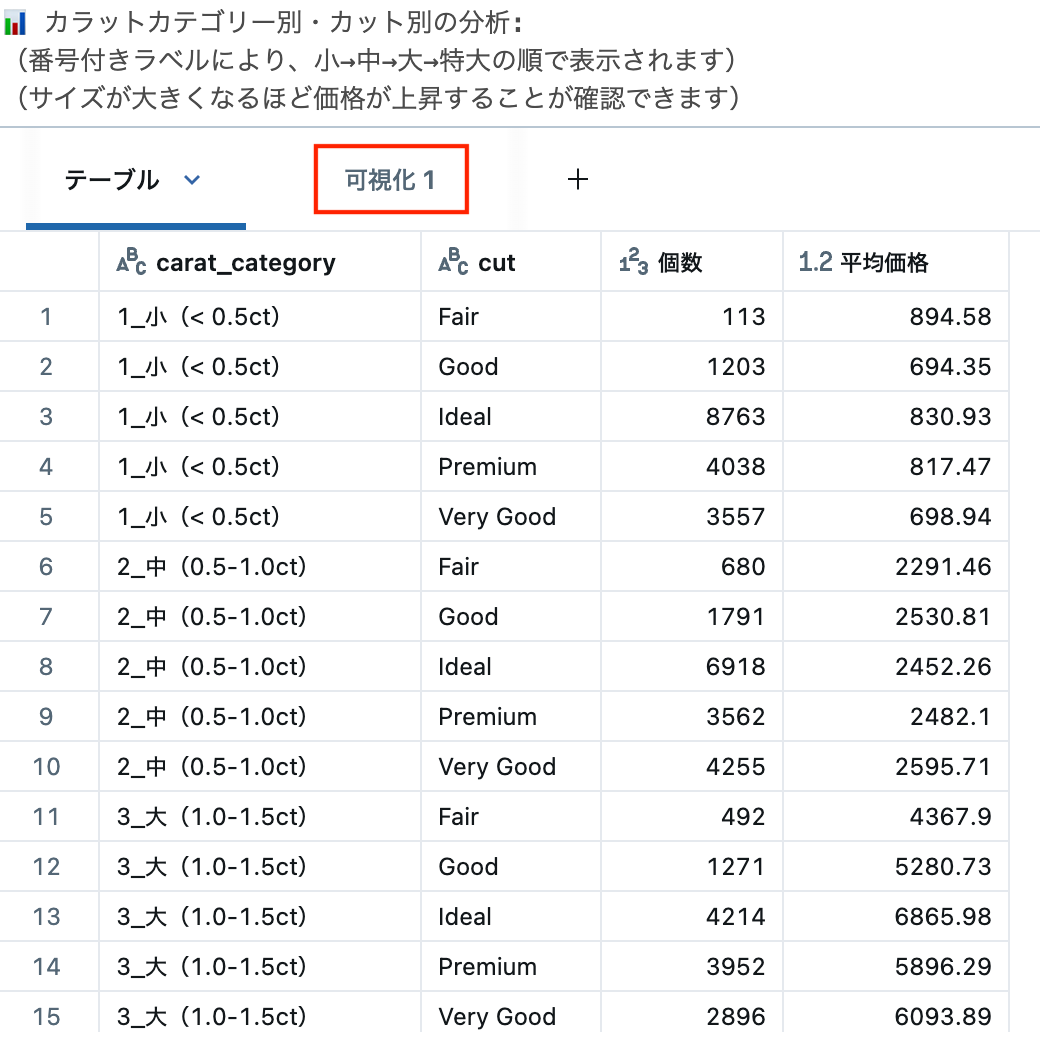
print("📊 カラットカテゴリー別・カット別の分析:")
print("(番号付きラベルにより、小→中→大→特大の順で表示されます)")
print("(サイズが大きくなるほど価格が上昇することが確認できます)")
display(category_analysis)
可視化のタブもクリックしてみてください。
ウィンドウ関数を使った高度な分析
ウィンドウ関数を使うと、グループ内でのランキングや累積値などを計算できます。
from pyspark.sql.window import Window
from pyspark.sql.functions import row_number, rank, dense_rank
# ウィンドウの定義: カット品質ごとに価格でソート
window_spec = Window.partitionBy("cut").orderBy(col("price").desc())
# 各カット品質内での価格ランキングを計算
top_diamonds = (
diamonds_clean
.withColumn("price_rank", row_number().over(window_spec)) # 順位を付与
.filter(col("price_rank") <= 3) # トップ3のみ抽出
.select("cut", "carat", "color", "clarity", "price", "price_rank")
.orderBy("cut", "price_rank") # 表示用にソート
)
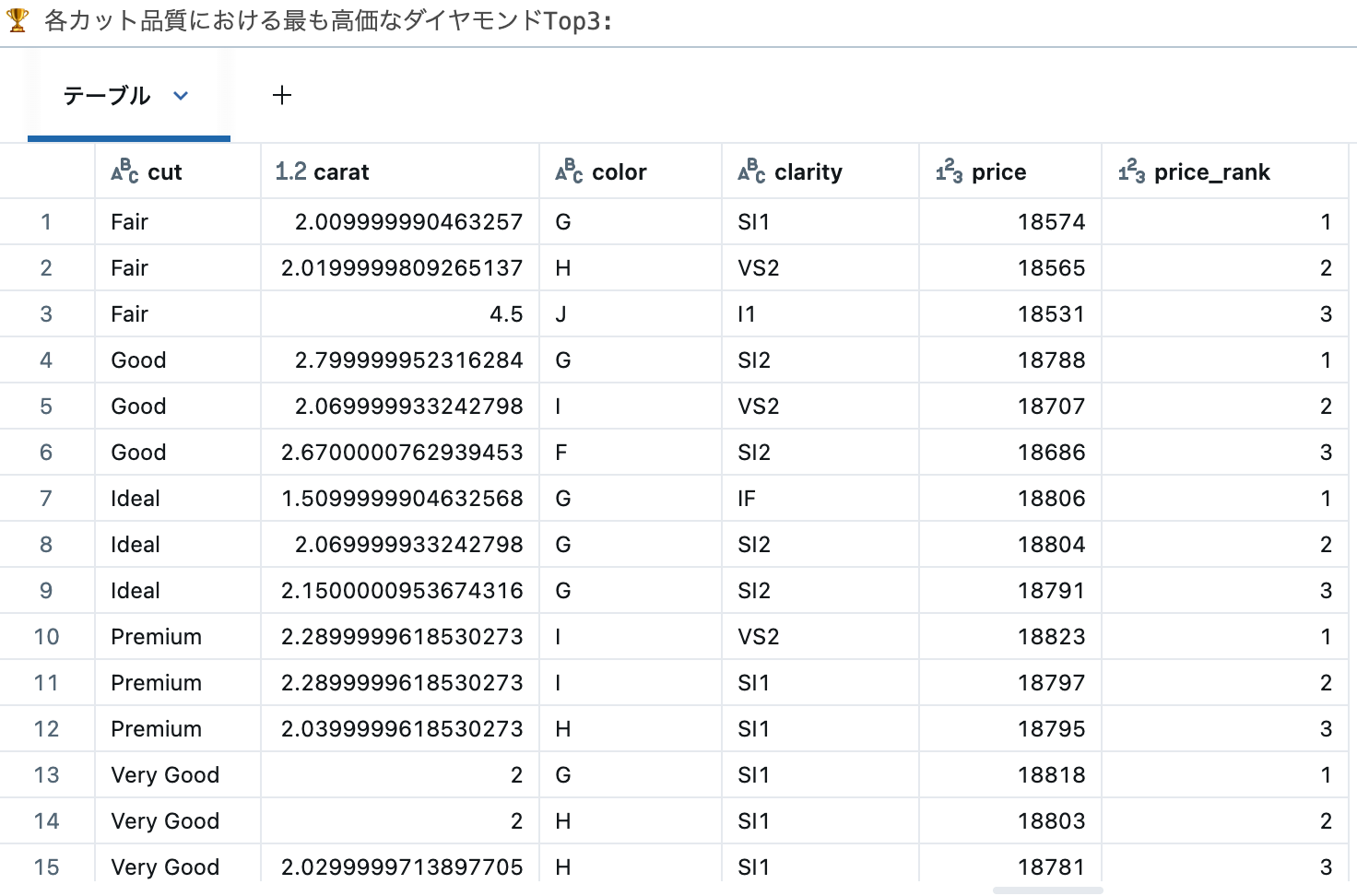
print("🏆 各カット品質における最も高価なダイヤモンドTop3:")
display(top_diamonds)
🚀 第6部: SQLとの連携
Spark SQLの活用
SparkデータフレームをSQLで操作する方法を学びます。
SQLに慣れている方にとって、非常に親しみやすいインターフェースです。
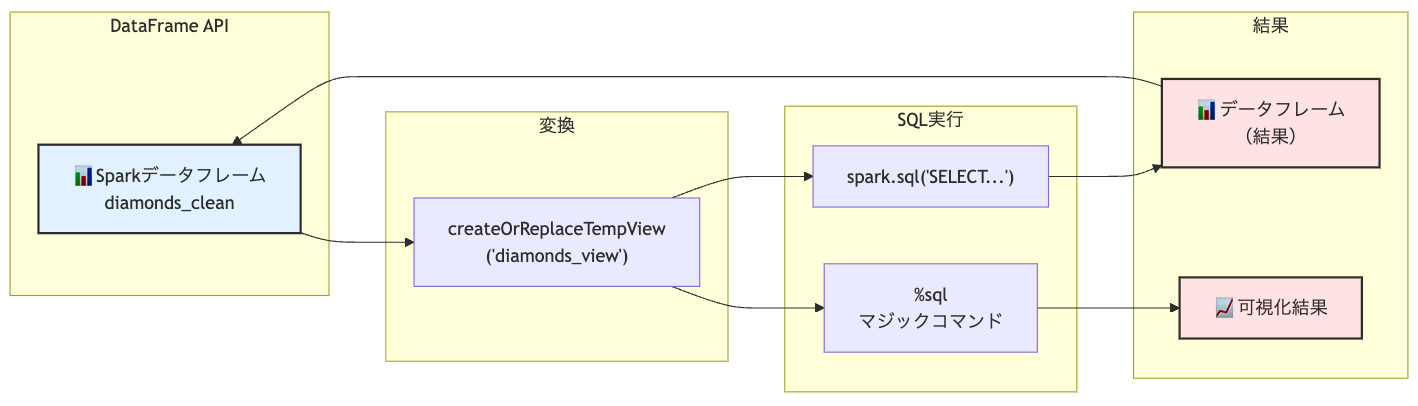
# データフレームを一時ビューとして登録
# これにより、SQLクエリでデータフレームを参照できるようになります
diamonds_clean.createOrReplaceTempView("diamonds_view")
# SQLクエリを実行
# spark.sql()メソッドでSQLを実行し、結果をデータフレームとして取得
sql_result = spark.sql("""
SELECT
cut, -- カット品質
color, -- 色のグレード
COUNT(*) as count, -- レコード数
ROUND(AVG(price), 2) as avg_price, -- 平均価格
ROUND(AVG(carat), 3) as avg_carat -- 平均カラット
FROM diamonds_view
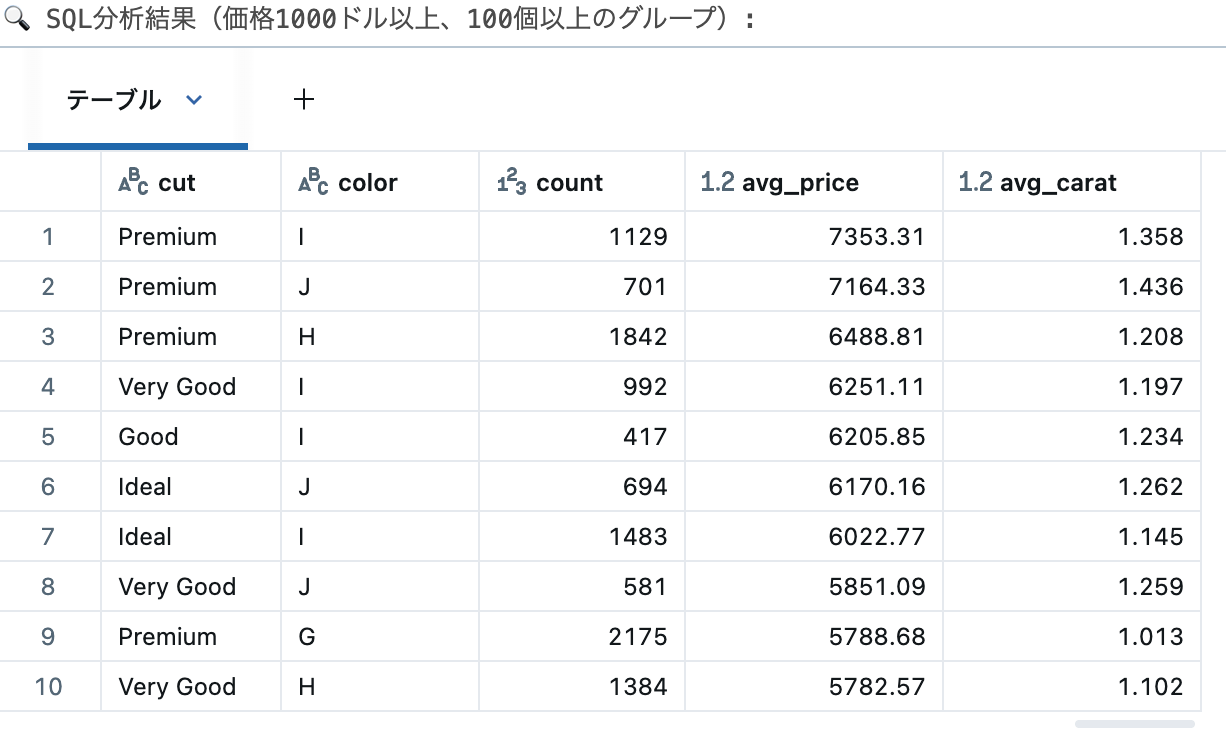
WHERE price > 1000 -- 1000ドル以上のダイヤモンドのみ
GROUP BY cut, color -- カットと色でグループ化
HAVING COUNT(*) > 100 -- 100個以上のグループのみ
ORDER BY avg_price DESC -- 平均価格の降順
LIMIT 10 -- 上位10件
""")
print("🔍 SQL分析結果(価格1000ドル以上、100個以上のグループ):")
display(sql_result)
SQLマジックコマンドの使用
Databricksでは%sqlマジックコマンドを使って、セル全体をSQLクエリとして実行できます。
%sql
-- SQLマジックコマンドで直接SQL実行
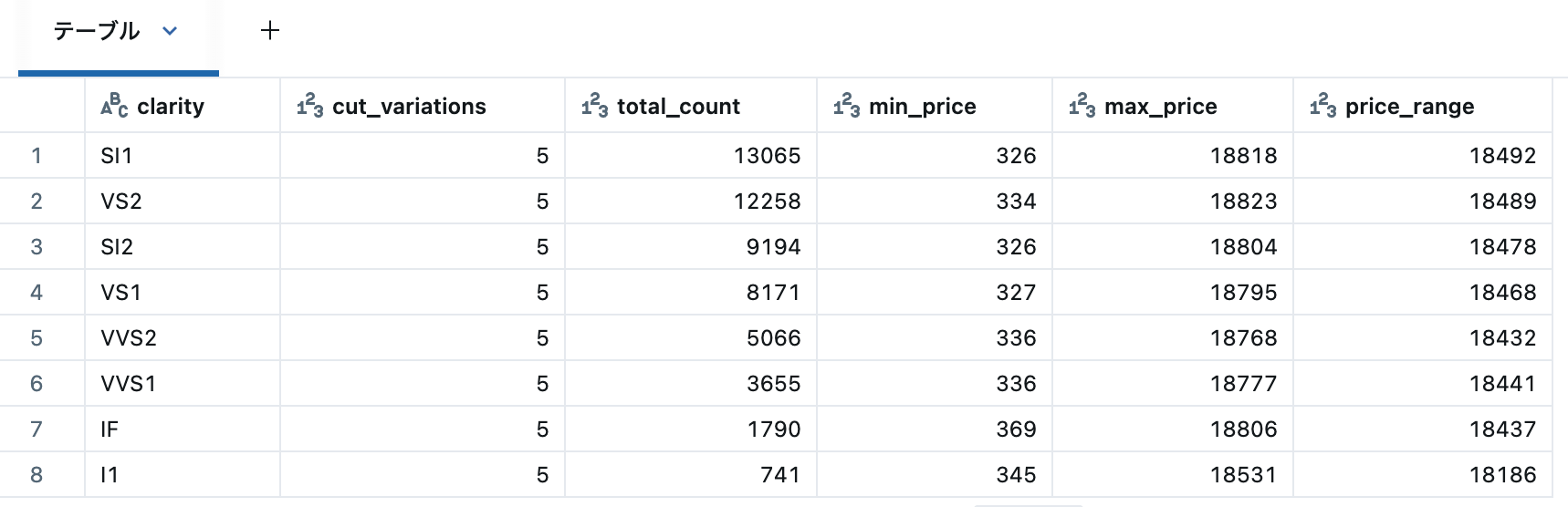
-- より複雑な分析: 透明度ごとの統計
SELECT
clarity, -- 透明度グレード
COUNT(DISTINCT cut) as cut_variations, -- カット種類の数
COUNT(*) as total_count, -- 総数
MIN(price) as min_price, -- 最低価格
MAX(price) as max_price, -- 最高価格
ROUND(MAX(price) - MIN(price), 2) as price_range -- 価格レンジ
FROM diamonds_view
GROUP BY clarity
ORDER BY total_count DESC
🎯 第7部: パフォーマンス最適化の基礎知識
📚 最適化テクニックの理解
Sparkのパフォーマンス最適化には以下のような手法があります:
- キャッシング: 頻繁に使用するデータフレームをメモリに保持
- パーティショニング: データを適切なサイズに分割
- ブロードキャスト結合: 小さなテーブルを各ノードに配布
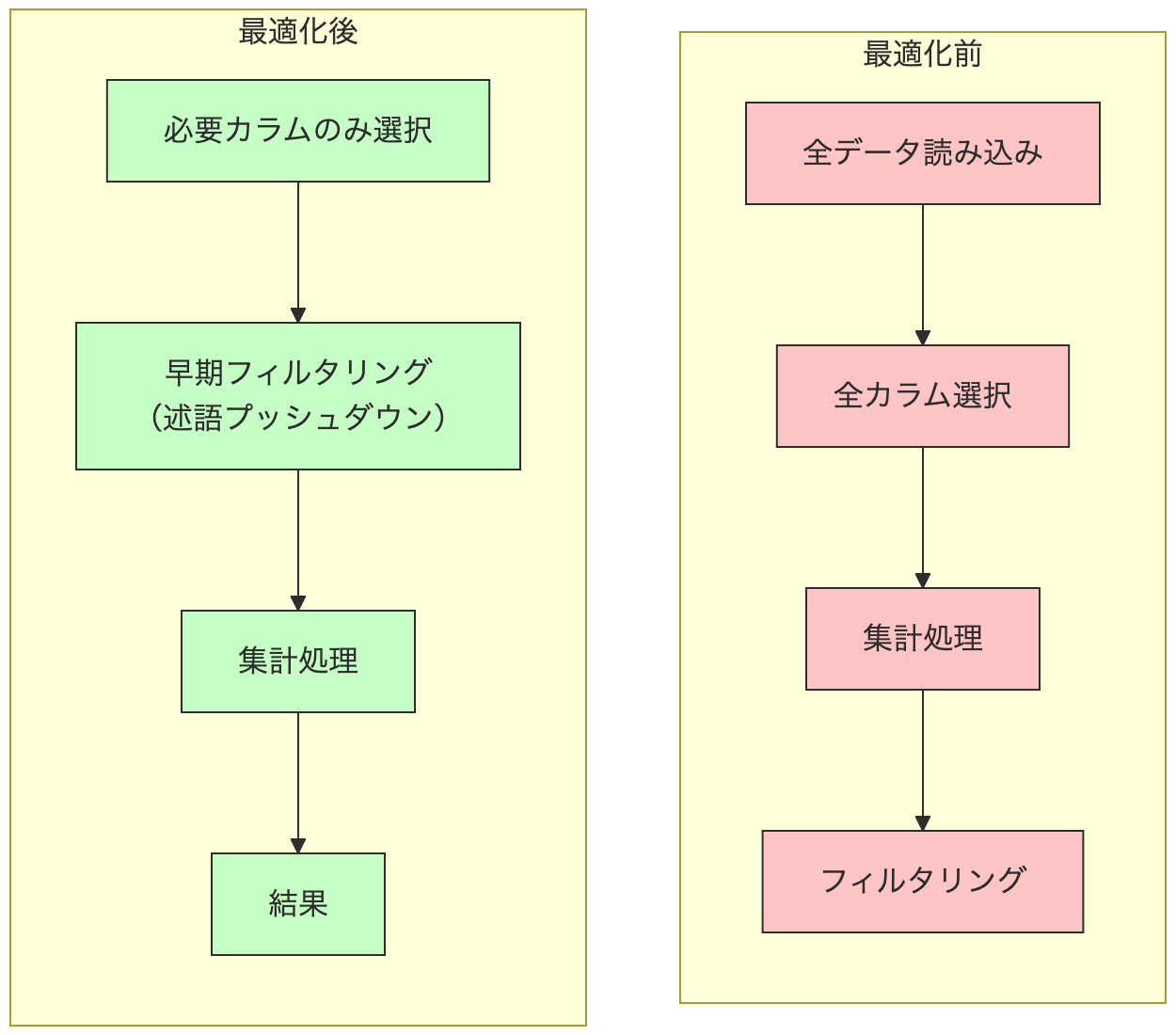
- 述語プッシュダウン: フィルタ条件を早期に適用
サーバレスコンピュートでの最適化
Databricksのサーバレスコンピュートでは、多くの最適化が自動的に行われます。
以下、実践可能な最適化テクニックを紹介します:
# 最適化のベストプラクティスを実演
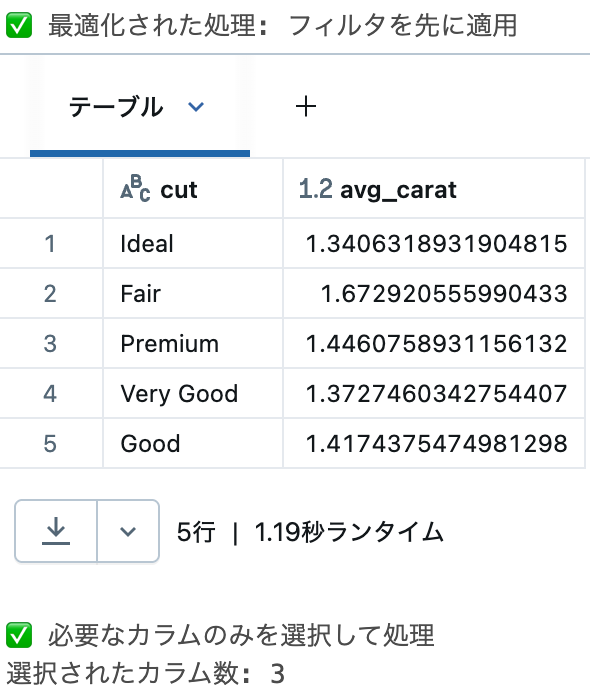
# 1. フィルタの早期適用(述語プッシュダウン)
# 良い例: フィルタを早期に適用
optimized_df = (
diamonds_clean
.filter(col("price") > 5000) # まずフィルタ(データ量を削減)
.groupBy("cut") # その後集計
.agg(avg("carat").alias("avg_carat"))
)
print("✅ 最適化された処理: フィルタを先に適用")
display(optimized_df)
# 2. 必要なカラムのみ選択
# データ転送量を削減
selected_columns = (
diamonds_clean
.select("cut", "price", "carat") # 必要なカラムのみ選択
.filter(col("price") > 10000)
)
print("\n✅ 必要なカラムのみを選択して処理")
print(f"選択されたカラム数: {len(selected_columns.columns)}")
最適化のベストプラクティス
サーバレス環境で効果的な最適化手法:
- 早期フィルタリング: WHERE句は可能な限り早い段階で適用
- カラムの選択: 必要なカラムのみをSELECT
- 適切な結合順序: 小さいテーブルを先に結合
- パーティション述語: パーティション化されたテーブルでは適切なフィルタを使用
🔄 第8部: Pandas API on Sparkの活用
Pandas APIでSparkを使う
Pandasに慣れている方でも、Sparkの分散処理能力を活用できます。
import pyspark.pandas as ps
import numpy as np
# Pandas API on Sparkでデータフレームを作成
# 通常のPandasと同じ構文で記述できます
ps_df = ps.DataFrame({
'A': np.random.rand(1000), # ランダムな値(0-1)
'B': np.random.rand(1000), # ランダムな値(0-1)
'C': np.random.randn(1000) # 正規分布に従うランダム値
})
# Pandasと同じメソッドが使える
print("📊 Pandas API on Sparkの統計情報:")
print(ps_df.describe()) # 基本統計量の表示
print("\n🔝 上位5件(Aカラムでソート):")
# sort_valuesやheadなど、Pandasでお馴染みのメソッドが使用可能
print(ps_df.sort_values('A', ascending=False).head())
📊 Pandas API on Sparkの統計情報:
A B C
count 1000.000000 1000.000000 1000.000000
mean 0.505290 0.494652 0.007897
std 0.294411 0.291331 1.031623
min 0.001276 0.001369 -3.640795
25% 0.234287 0.254717 -0.673122
50% 0.510131 0.486816 0.016236
75% 0.759370 0.750676 0.718045
max 0.999539 0.999994 4.161558
🔝 上位5件(Aカラムでソート):
A B C
198 0.999539 0.278639 0.332884
936 0.998892 0.938016 1.724161
469 0.998588 0.965553 -1.733019
184 0.998554 0.990778 0.500505
94 0.998232 0.314186 0.845150
既存のSparkデータフレームをPandas APIで操作
# SparkデータフレームをPandas API on Sparkに変換
diamonds_ps = diamonds_clean.to_pandas_on_spark()
# Pandasスタイルでの基本統計
print("💰 価格カラムの統計情報(Pandas API):")
price_stats = diamonds_ps['price'].describe()
print(price_stats)
# 基本的な集計を個別に実行
print("\n📈 カット別の基本統計:")
cut_types = diamonds_ps['cut'].unique().to_numpy() # NumPy配列に変換
for cut_type in cut_types[:3]: # デモのため最初の3つのみ表示
cut_data = diamonds_ps[diamonds_ps['cut'] == cut_type]['price']
print(f"\n{cut_type}:")
print(f" 平均: ${cut_data.mean():.2f}")
print(f" 標準偏差: ${cut_data.std():.2f}")
print(f" 件数: {len(cut_data):,}")
💰 価格カラムの統計情報(Pandas API):
count 53940.000000
mean 3932.799722
std 3989.439738
min 326.000000
25% 950.000000
50% 2401.000000
75% 5324.000000
max 18823.000000
Name: price, dtype: float64
📈 カット別の基本統計:
Ideal:
平均: $3457.54
標準偏差: $3808.40
件数: 21,551
Fair:
平均: $4358.76
標準偏差: $3560.39
件数: 1,610
Premium:
平均: $4584.26
標準偏差: $4349.20
件数: 13,791
💾 第9部: Unity Catalogとデータの永続化
📚 Unity Catalogとは
Unity Catalogは、Databricksのデータガバナンスソリューションです:
- 統一されたメタストア: すべてのデータ資産を一元管理
- 細かいアクセス制御: テーブル、カラムレベルでの権限管理
- データリネージ: データの流れを追跡
- データ発見: カタログを通じたデータの検索と理解
SparkとUnity Catalogの関係
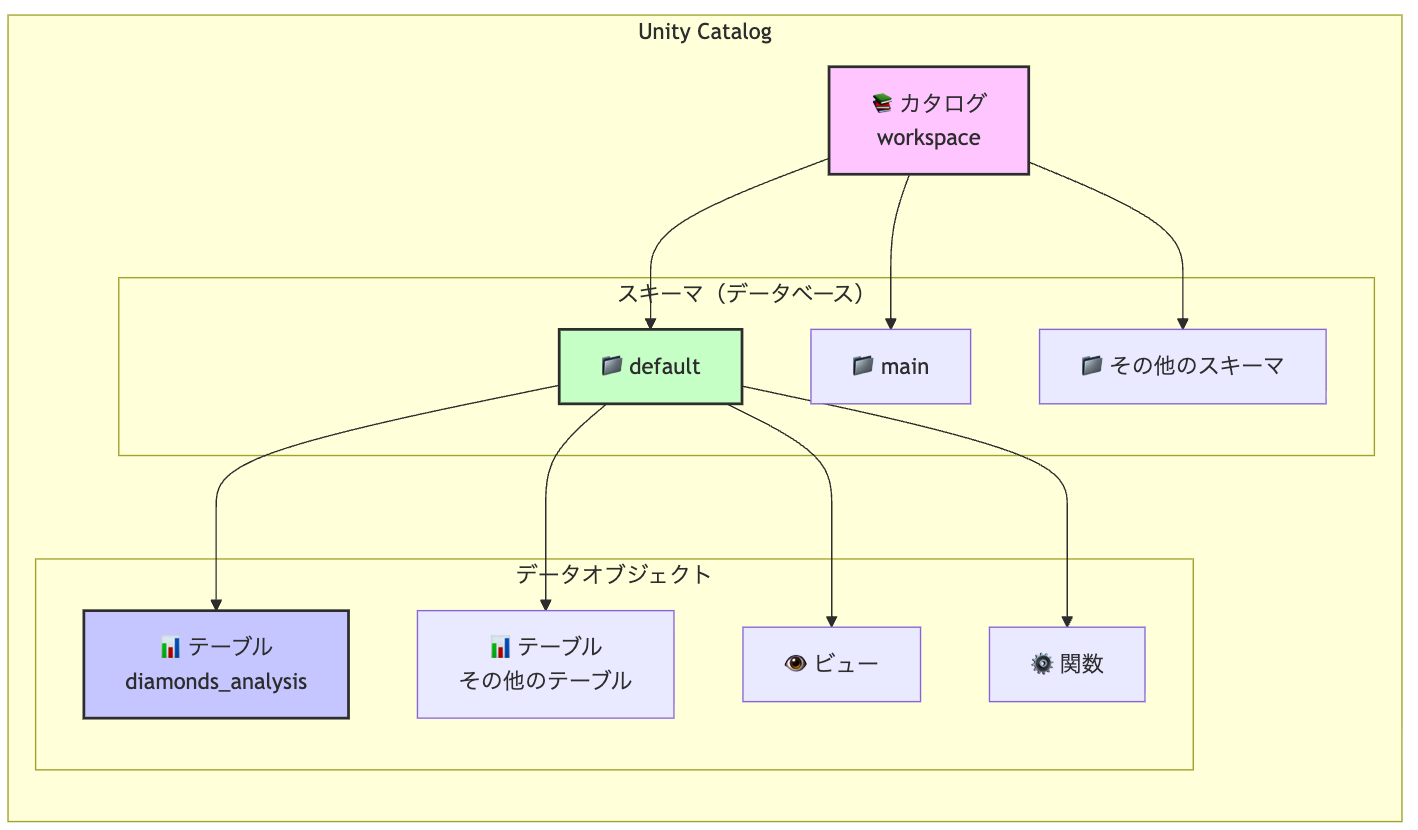
Unity Catalog階層:
├── カタログ (Catalog)
│ ├── スキーマ/データベース (Schema/Database)
│ │ ├── テーブル (Table)
│ │ ├── ビュー (View)
│ │ └── 関数 (Function)
データの保存先
サーバレスコンピュートでは、ファイルシステムへの直接書き込みが制限されているため、
Unity Catalogのテーブルとしてデータを保存します。
# 現在のカタログとスキーマを確認
current_catalog = spark.sql("SELECT current_catalog()").collect()[0][0]
current_schema = spark.sql("SELECT current_database()").collect()[0][0]
print("📍 現在の位置:")
print(f" カタログ: {current_catalog}")
print(f" スキーマ: {current_schema}")
# workspace.defaultスキーマを使用
# これは個人用の作業領域として提供されています
spark.sql("USE workspace.default")
print("\n✅ workspace.defaultスキーマに切り替えました")
📍 現在の位置:
カタログ: workspace
スキーマ: default
✅ workspace.defaultスキーマに切り替えました
マネージドテーブルとしての保存
Unity Catalogのマネージドテーブルとしてデータを保存します。
import uuid
from datetime import datetime
# ユニークなテーブル名を生成(衝突を避けるため)
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
unique_suffix = str(uuid.uuid4())[:8]
table_name = f"diamonds_analysis_{timestamp}_{unique_suffix}"
# テーブルとして保存
# Delta形式で保存されます(Databricksのデフォルト)
(
diamonds_clean.write
.mode("overwrite") # 既存テーブルがあれば上書き
.saveAsTable(f"workspace.default.{table_name}")
)
print(f"✅ テーブルが保存されました: workspace.default.{table_name}")
print("\n📊 保存されたテーブルの情報:")
spark.sql(f"DESCRIBE EXTENDED workspace.default.{table_name}").show(truncate=False)
✅ テーブルが保存されました: workspace.default.diamonds_analysis_20250824_011243_c58f2d0a
📊 保存されたテーブルの情報:
+----------------------------+---------------------------------------------------------------+-------+
|col_name |data_type |comment|
+----------------------------+---------------------------------------------------------------+-------+
|index |int |NULL |
|carat |float |NULL |
|cut |string |NULL |
|color |string |NULL |
|clarity |string |NULL |
|depth |double |NULL |
|table |double |NULL |
|price |int |NULL |
|x |double |NULL |
|y |double |NULL |
|z |double |NULL |
| | | |
|# Delta Statistics Columns | | |
|Column Names |x, y, color, carat, depth, clarity, cut, price, table, index, z| |
|Column Selection Method |first-32 | |
| | | |
|# Detailed Table Information| | |
|Catalog |workspace | |
|Database |default | |
|Table |diamonds_analysis_20250824_011243_c58f2d0a | |
+----------------------------+---------------------------------------------------------------+-------+
only showing top 20 rows
以下のセルを実行して表示されるリンクをクリックしてテーブルを確認してみましょう。DatabricksではカタログエクスプローラというUIでテーブルやデータベース、ファイル、モデルなどにアクセスすることができます。
displayHTML(f"<a href='/explore/data/workspace/default/{table_name}'>保存したテーブル</a>")
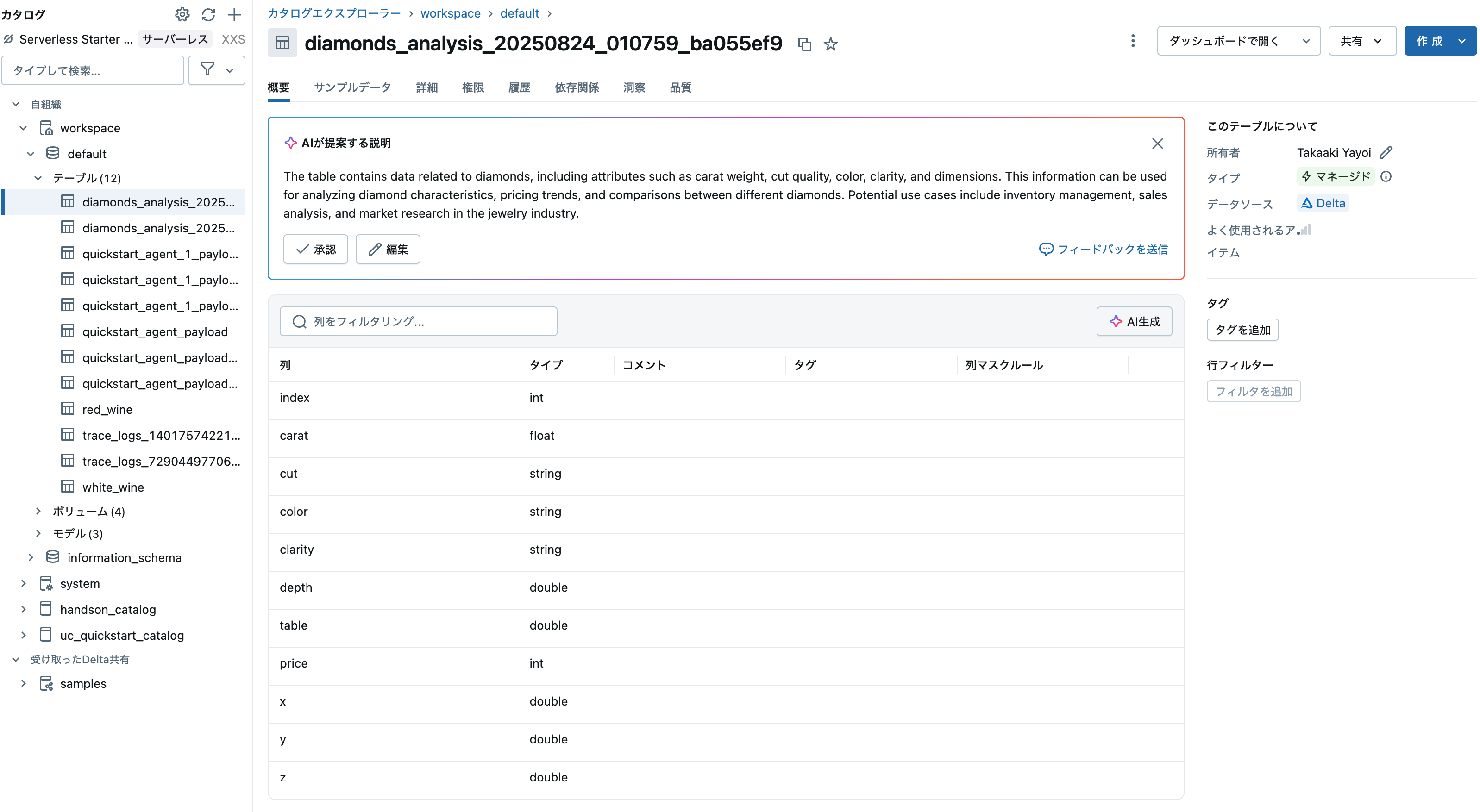
保存したテーブルの読み込み
# テーブルからデータを読み込み
loaded_df = spark.table(f"workspace.default.{table_name}")
# 読み込んだデータを確認
print(f"📥 テーブルから読み込んだデータ:")
print(f" レコード数: {loaded_df.count():,}")
print(f" カラム数: {len(loaded_df.columns)}")
# SQLでもアクセス可能
sql_query = f"""
SELECT cut, COUNT(*) as count, AVG(price) as avg_price
FROM workspace.default.{table_name}
GROUP BY cut
ORDER BY avg_price DESC
"""
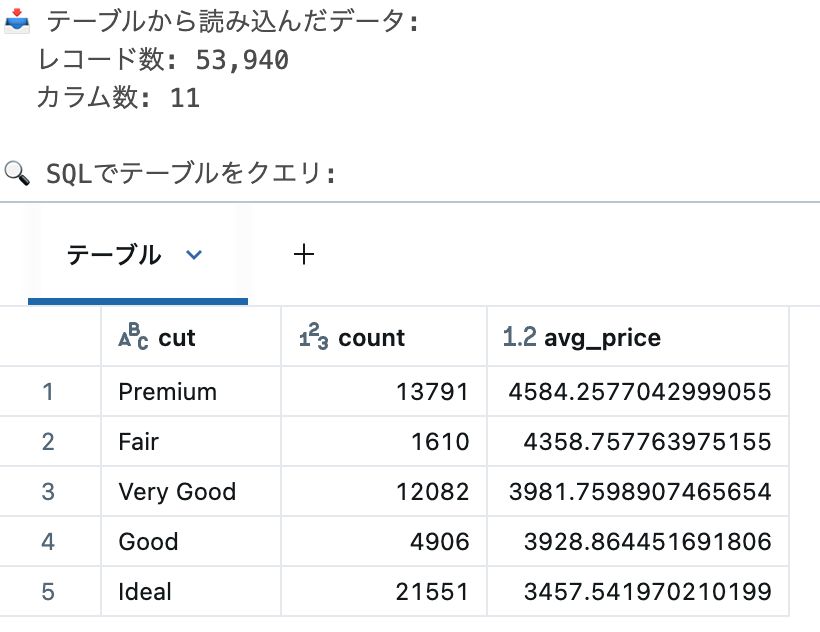
print("\n🔍 SQLでテーブルをクエリ:")
display(spark.sql(sql_query))
Delta Lake形式の利点
Databricksでは、テーブルはDelta Lake形式で保存されます。
# Delta Lakeの特徴を確認
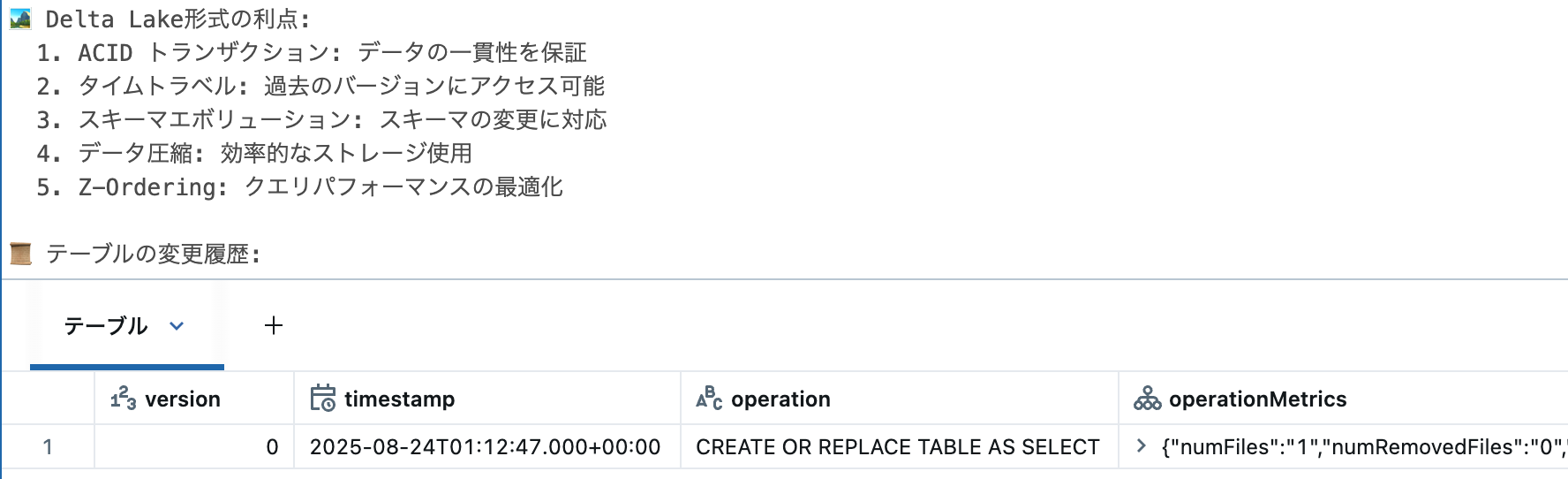
print("🏞️ Delta Lake形式の利点:")
print(" 1. ACID トランザクション: データの一貫性を保証")
print(" 2. タイムトラベル: 過去のバージョンにアクセス可能")
print(" 3. スキーマエボリューション: スキーマの変更に対応")
print(" 4. データ圧縮: 効率的なストレージ使用")
print(" 5. Z-Ordering: クエリパフォーマンスの最適化")
# テーブルの履歴を確認
print(f"\n📜 テーブルの変更履歴:")
history_df = spark.sql(f"DESCRIBE HISTORY workspace.default.{table_name} LIMIT 5")
display(history_df.select("version", "timestamp", "operation", "operationMetrics"))
🧹 第10部: クリーンアップとベストプラクティス
テーブルのクリーンアップ
# 作成したテーブルを削除(もくもく会終了時)
# コメントを外して実行してください
# spark.sql(f"DROP TABLE IF EXISTS workspace.default.{table_name}")
# print(f"🧹 テーブル {table_name} を削除しました")
print("⚠️ クリーンアップを実行する場合は、上記のコメントを外してください")
📚 学んだことのまとめ
このもくもく会で学んだ重要なポイント:
1. Sparkの基本概念
- 分散処理アーキテクチャ(ドライバーとエグゼキューター)
- 遅延評価(トランスフォーメーションとアクション)
- データフレームAPI
- Pandasとの違いと使い分け
2. データ処理テクニック
- データの読み込みとクレンジング
- 集計とグループ化
- ウィンドウ関数の活用
3. SQL統合
- SparkデータフレームのSQL操作
- 一時ビューの活用
- SQLマジックコマンド
4. Unity Catalogとの統合
- カタログ・スキーマ・テーブルの階層構造
- マネージドテーブルとしてのデータ保存
- Delta Lake形式の利点
5. ベストプラクティス
- フィルタの早期適用
- 必要なカラムのみ選択
- 適切なデータ形式の選択
🎓 次のステップ
さらに学習を深めるために
- 構造化ストリーミング: リアルタイムデータ処理
- MLlib: Sparkの機械学習ライブラリ
- Delta Lake: より高度なデータレイク機能
- Photon: Databricksの高速実行エンジン
参考リソース
- Apache Spark公式ドキュメント
- Apache Spark徹底入門
- Apache Sparkとは何か - Qiita
- PySparkことはじめ - Qiita
- Databricks Learning
- PySpark APIリファレンス
- Unity Catalogドキュメント
🚀 チャレンジ問題
もくもく会の残り時間で以下の課題に挑戦してみましょう!
ノートブックをご覧ください。
🎉 お疲れさまでした!
Apache Sparkの世界への第一歩を踏み出しました。今日学んだ基礎を活かして、より大規模で複雑なデータ処理に挑戦していってください!
💬 質問とディスカッション
- 不明な点があれば、遠慮なくメンターに質問してください
- 他の参加者と学びを共有しましょう
- 実務での活用アイデアを話し合いましょう
🔗 コミュニティ
- Databricks Community に参加して継続的に学習
- Apache Sparkユーザーグループでの情報交換
- 定期的なもくもく会への参加
Happy Sparking! ✨