こちらの手順をウォークスルーします。
こちらも参考にしています。
警告!
クラウド横断での接続を行う構成ですので、以下の点には注意してください。
- アクセスに用いる認証情報は厳重に管理してください。
- クラウド間通信のコストが発生することに注意してください。
AWS側での作業
S3バケットの作成
taka-bucket-from-azureというS3バケットを作成します。S3ブロックパブリックアクセスは有効化してください。

IAMユーザーの作成
ここではs3-userというユーザーを作成し、AmazonS3FullAccessのポリシーをアタッチします。

注意
ここでは強力な権限であるAmazonS3FullAccessを付与していますが、ご自身のセキュリティ要件に基づいた権限設定を行ってください。
セキュリティ認証情報タブにアクセスし、アクセスキーセクションにあるアクセスキーを作成ボタンをクリックし、必要に応じて説明タグを追記してアクセスキーを作成します。

アクセスキーとシークレットアクセスキーをメモしておきます。

警告!
これらのキーは厳重に管理してください。
Azure側での作業
上のステップで取得したアクセスキーをAzure Databricksで使えるように設定を行います。これらのキーを平文で管理することは推奨しておらず、シークレットに格納することを推奨しています。
Azure Databricksの場合、シークレットの管理方法には2つの選択肢があります。
- Azure Key Vaultによる管理
- Azure Databricksによる管理
ここでは、Azure Databricksで管理するアプローチを取りますが、要件に基づいて管理方法を選択ください。
シークレットの管理をするためには、Databricks CLI(コマンドラインインタフェース)を使う必要があります。
ローカルマシンでDatabricks CLIをインストールします。あるいは、Azure Cloud Shellをお使いください。ここでは、ローカルマシンにインストールしたDatabricks CLIで作業します。
Databricks CLIのセットアップ
Databricks CLIのセットアップには、Azure Databricksワークスペースでパーソナルアクセストークンを取得する必要があります。
ワークスペースにアクセスし、右上のユーザーアイコンをクリックし、設定を選択します。ユーザー > 開発者にアクセスし、アクセストークンの管理をクリックします。
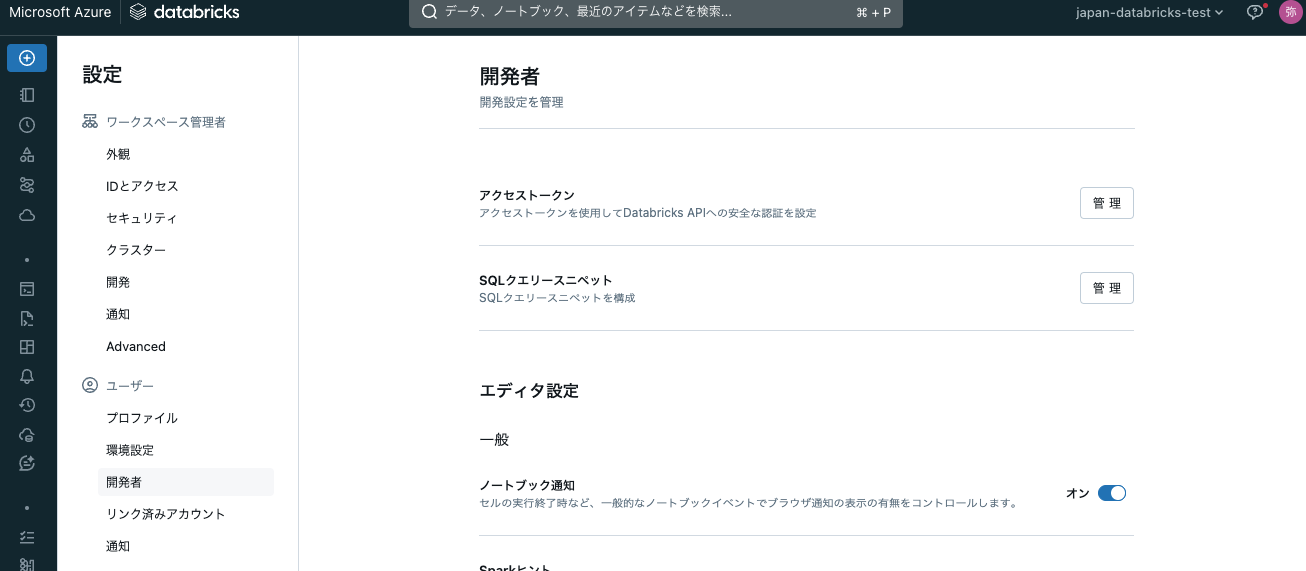
新規トークンを作成をクリックし、コメントと有効期間を指定してトークンを作成します。表示されるトークンをメモしておきます。有効期間を指定しない場合は無期限有効となります。
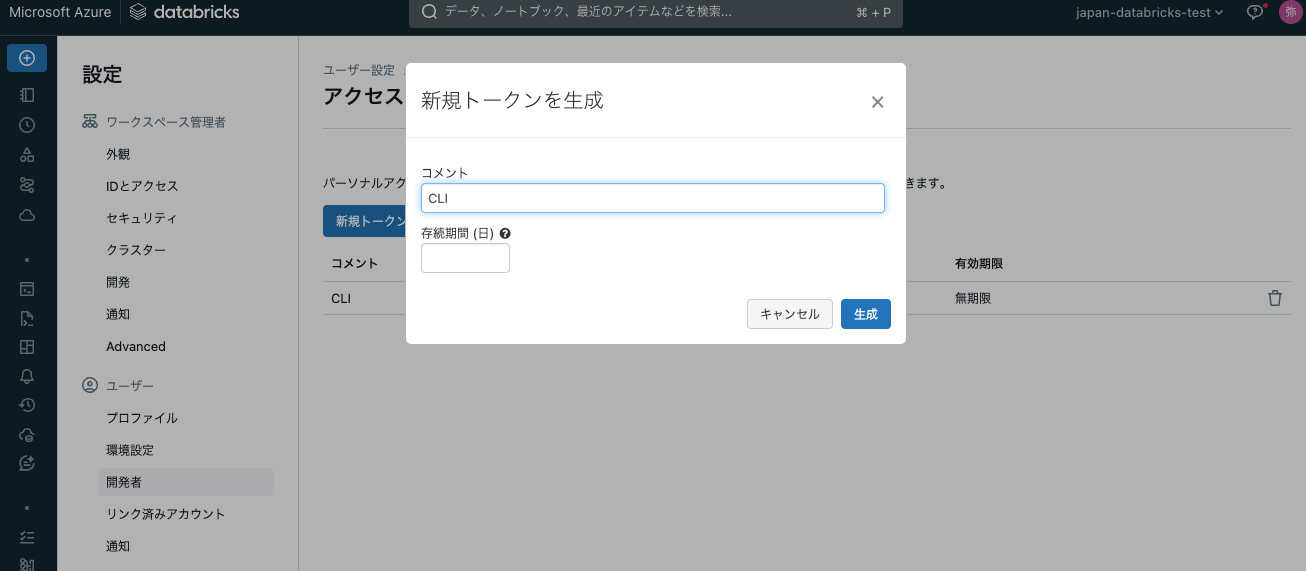
警告!
このトークン
は厳重に管理してください。
こちらの手順に従い、コマンドプロンプトやターミナルを起動し、以下を実行します。
databricks configure
Azure Databricksワークスペースのホスト名を聞かれるので、使用するワークスペースにブラウザでアクセスし、https://以降から.net/までを貼り付けます。次にパーソナルアクセストークンを聞かれるので、上で取得したパーソナルアクセストークンを設定します。これで、Databricks CLIの設定は完了です。

注意
上の例では、--profile testを指定していますが、これはプロファイルを指定しています。複数環境を操作する場合にはプロファイルを作成すると、簡単に設定を切り替えられるので作業が楽になります。
シークレットスコープの作成
シークレットは複数作成することができ、それらはシークレットスコープで管理することができます。ですので、先にシークレットスコープを作成します。
Databricks CLIで以下を実行します。ここではs3_accessというシークレットスコープを作成しています。また、プロファイルtestを指定して、接続先を指定してます。
databricks secrets create-scope s3_access -p test
スコープが作成されたことを確認します。
databricks secrets list-scopes -p test
Scope Backend Type
s3_access DATABRICKS
シークレットの作成
以下の二つのコマンドを実行して、aws_access_key_idとaws_secret_access_keyのシークレットを作成します。
注意
aws_access_key_idはAKIで始まる文字列です。
databricks secrets put-secret --json '{
"scope": "s3_access",
"key": "aws_access_key_id",
"string_value": "AKI..."
}' -p test
databricks secrets put-secret --json '{
"scope": "s3_access",
"key": "aws_secret_access_key",
"string_value": "....."
}' -p test
シークレットが登録されたことを確認します。
databricks secrets list-secrets s3_access -p test
Key Last Updated Timestamp
aws_access_key_id 1716255148842
aws_secret_access_key 1716255154670
注意
シークレットにアクセスコントロールを施すことができます。セキュリティ要件に基づき、適切な設定を行ってください。
Databricksクラスターの設定
これで、Azure Databricksから上述のシークレットを利用できるようになりました。クラスターからシークレットを使用するようにするには、もう一つの設定が必要です。設定を行わない場合、S3からアクセスが拒否されます。
使用するクラスターの高度な設定を展開します。

ここの環境変数に以下を貼り付けます。
AWS_SECRET_ACCESS_KEY={{secrets/s3_access/aws_secret_access_key}}
AWS_ACCESS_KEY_ID={{secrets/s3_access/aws_access_key_id}}
注意
この例では、上のようになっていますが、s3_accessは実際に作成したシークレットスコープ名、aws_secret_access_keyやaws_access_key_idは実際に作成したシークレット名で置き換えてください。
これでクラスターを再起動します。
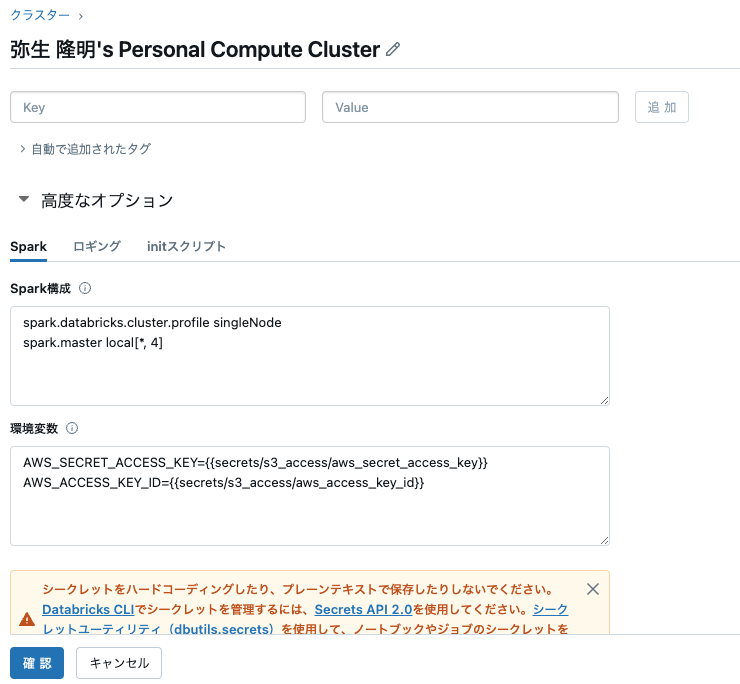
注意
この設定は当該クラスターにアクセスできるすべてのユーザーに対して有効となります。クラスターのアクセス権を適切に設定してください。
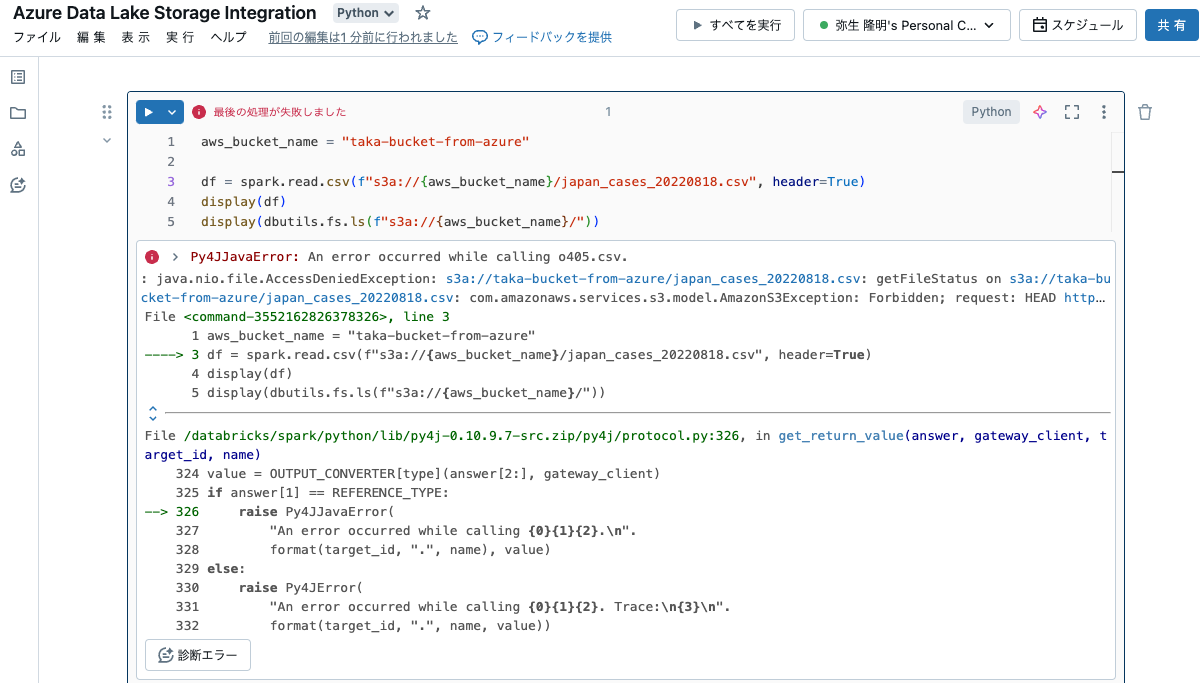
改めて以下を実行します。CSVファイルは事前に配置してあります。
aws_bucket_name = "taka-bucket-from-azure"
df = spark.read.csv(f"s3a://{aws_bucket_name}/japan_cases_20220818.csv", header=True)
display(df)
display(dbutils.fs.ls(f"s3a://{aws_bucket_name}/"))
これでアクセスできました。

