気づいたら色々機能が更新されていました。
そして、製品ページはSpark Declarative Pipelinesに、今後はSpark宣言型パイプラインと呼ばせていただきます。
Lakeflow Spark宣言型パイプラインとは
Lakeflow Spark宣言型パイプラインは、DatabricksがSQLとPythonで提供するバッチおよびストリーミングデータパイプラインの構築フレームワークです。従来のデータパイプライン開発で必要だった複雑なオーケストレーション、エラーハンドリング、インクリメンタル処理のコードを大幅に削減し、宣言的なアプローチでデータ変換を定義できます。クラウドストレージやメッセージバスからのデータ取り込み、変更データキャプチャ(CDC)、リアルタイムストリーム処理などの用途に対応し、データエンジニアだけでなくSQLアナリストも利用可能です。
Lakeflow Spark宣言型パイプラインは、データパイプラインの開発と実行を簡素化する宣言型フレームワークです。パフォーマンス最適化されたDatabricks Runtime上で動作し、Apache SparkのデータフレームAPIと構造化ストリーミングを基盤としています。
Lakeflow Spark宣言型パイプラインは以下の概念で構成されています。
| 要素 | 説明 | 種類 |
|---|---|---|
| フロー(Flow) | データ処理の基本単位。ソースからデータを読み取り、処理ロジックを適用してターゲットに書き込む | ストリーミング/バッチ |
| ストリーミングテーブル | ストリーミングデータを格納するUnity Catalogマネージドテーブル。追加フローやAuto CDCフローを受け付ける | ストリーミング |
| マテリアライズドビュー | バッチ処理結果を格納するUnity Catalogマネージドテーブル。インクリメンタル処理をサポート | バッチ |
| シンク(Sink) | ストリーミングデータの出力先。Deltaテーブル、Kafka、EventHubsなどに対応 | ストリーミング |
| パイプライン | 上記の要素を組み合わせた開発・実行の単位。依存関係を自動分析し実行順序を最適化 | 統合 |
以下では、冒頭のチュートリアルをウォークスルーします。
事前準備
パイプラインのソースコードを保存するフォルダと、生成されるテーブル(マテリアライズドビューやストリーミングテーブル)を格納するカタログ、スキーマを準備しておきます。
ステップ 1: パイプラインを作成する
新規 > ETLパイプラインを選択します。
パイプライン作成画面が開くので、適切な名前をつけます。
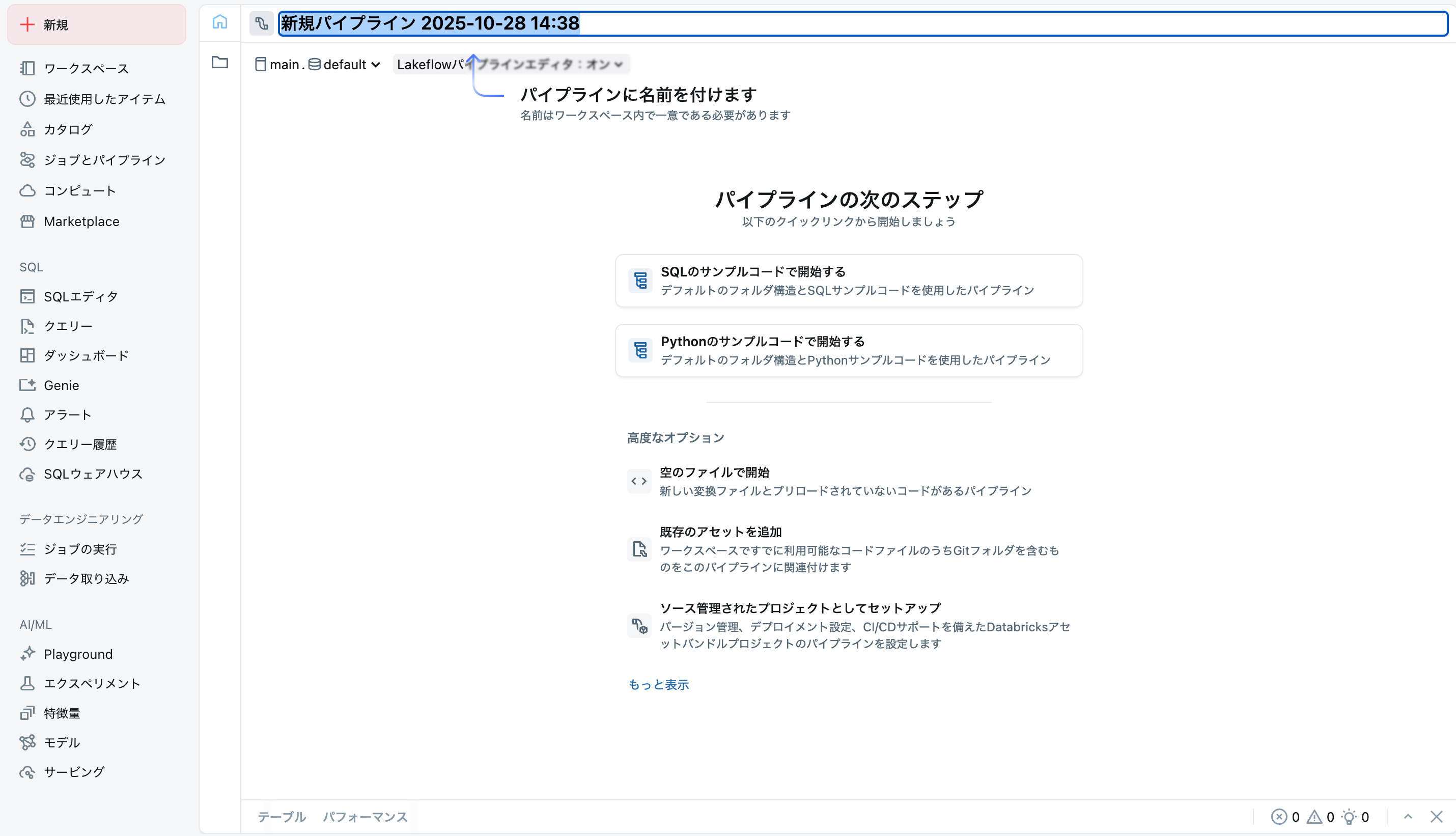
上で準備したカタログとスキーマを選択します。
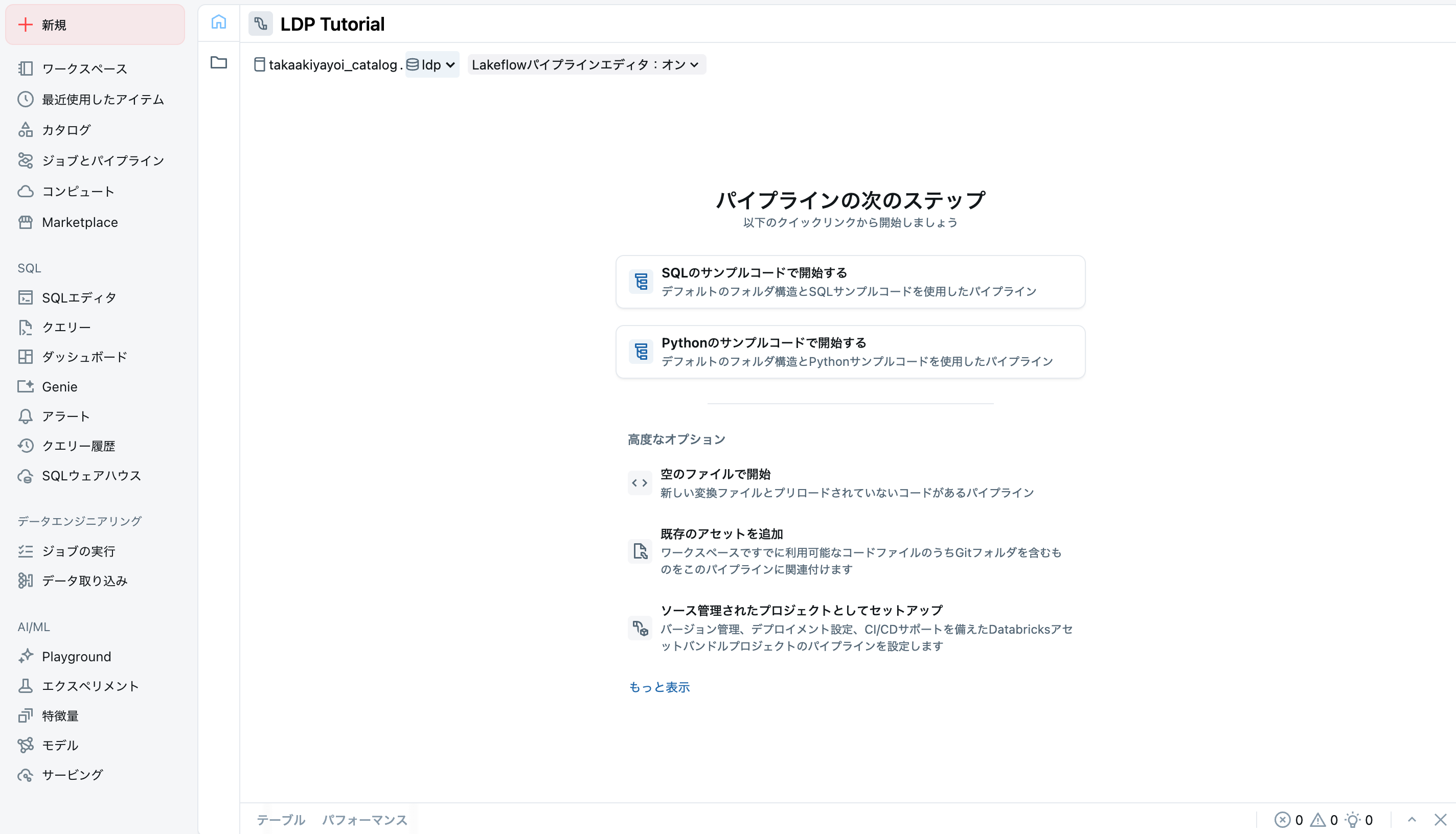
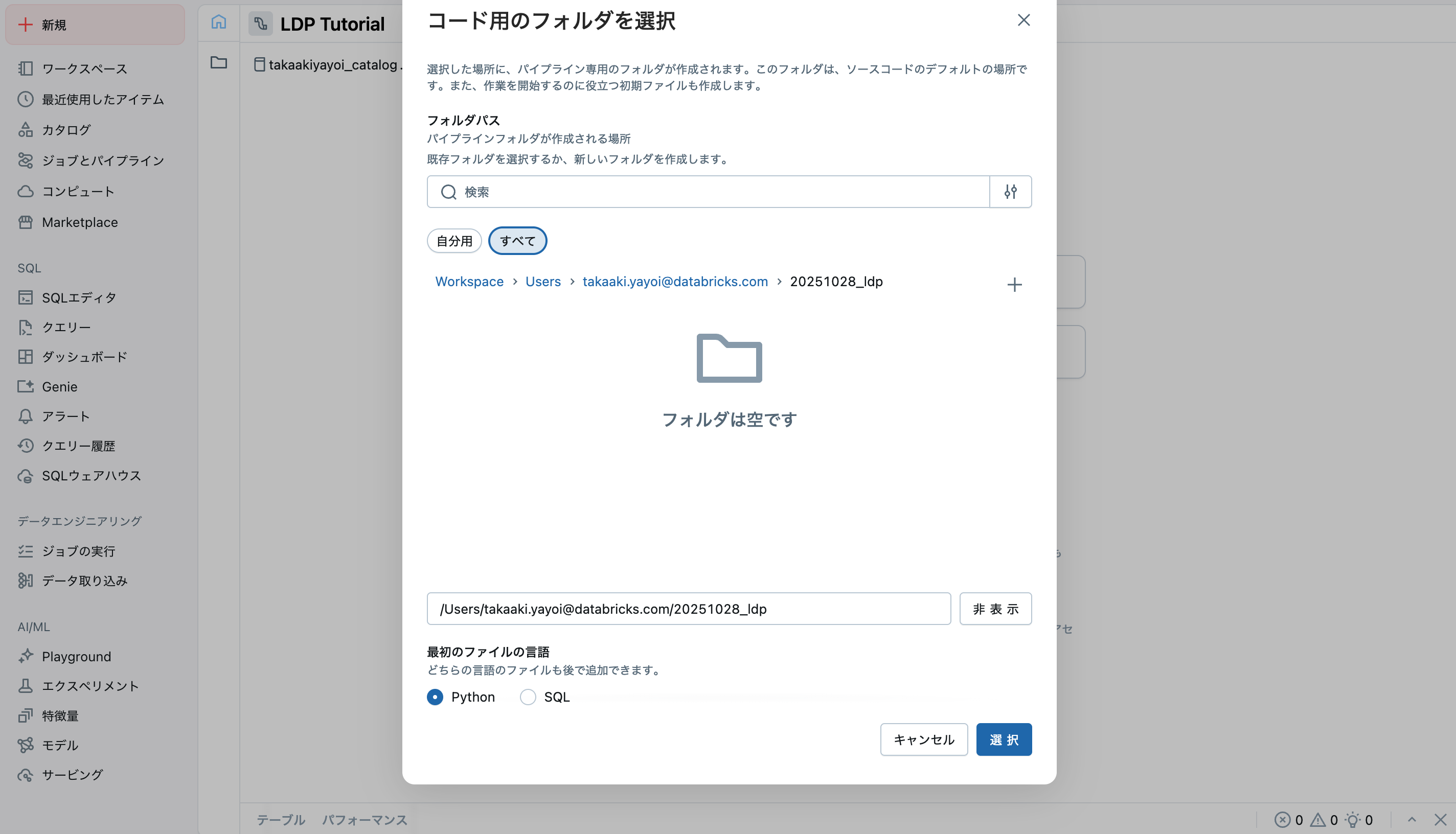
空のファイルで開始をクリックすると、ソースコードを格納するフォルダを聞かれるので選択します。ファイルの種類はPythonにします。
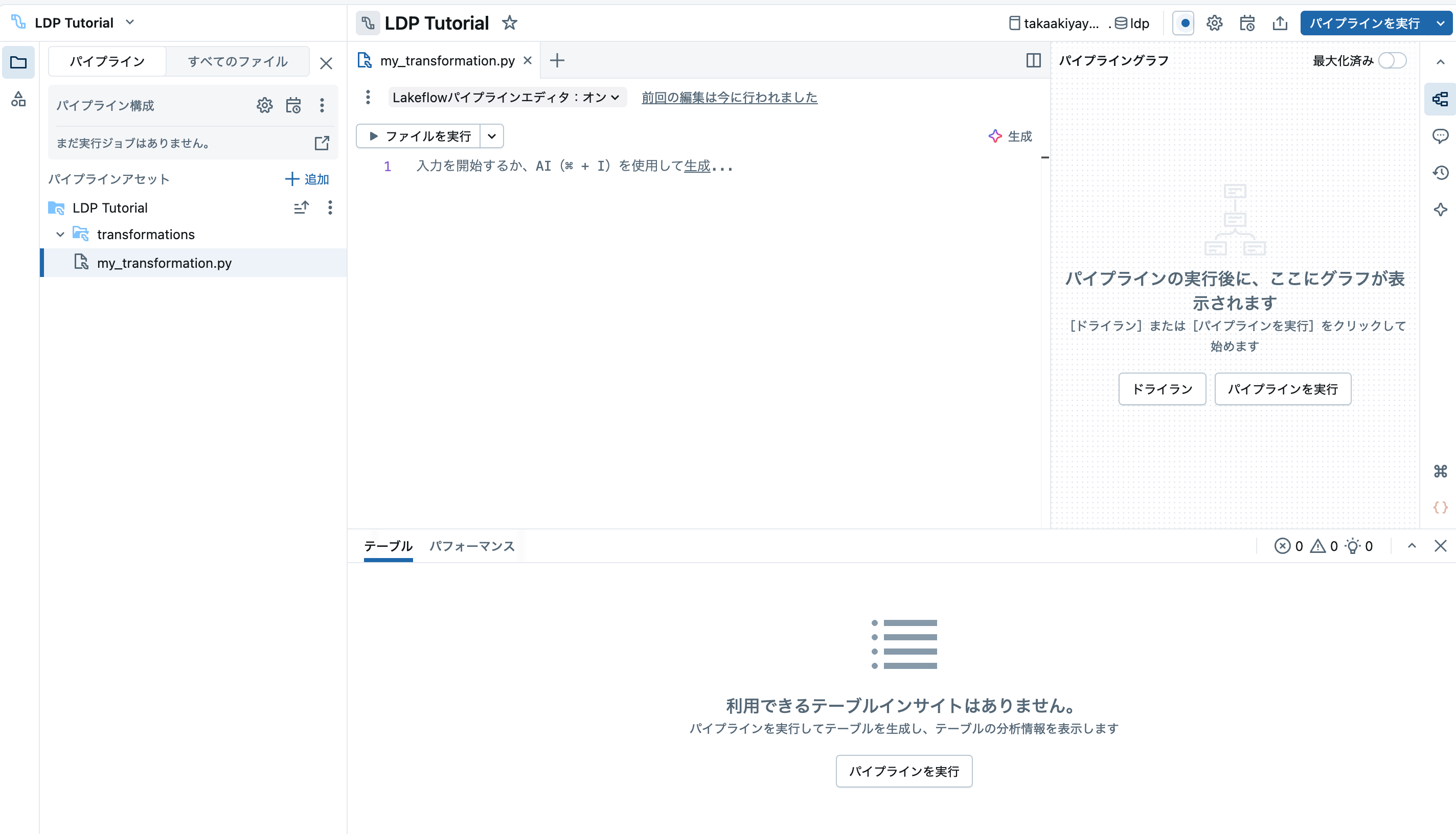
すると、パイプラインエディタが表示されます。
ステップ 2: パイプラインロジックを開発する
デフォルトで作成されているファイルtransformations/my_transformation.py二以下のコードを記述します。ライブラリやデコレーターがdpに統一されていますね。
# モジュールのインポート
from pyspark import pipelines as dp
from pyspark.sql.functions import *
from pyspark.sql.types import DoubleType, IntegerType, StringType, StructType, StructField
# ソースデータのパスを定義
file_path = f"/databricks-datasets/songs/data-001/"
# ボリュームからデータを取り込むストリーミングテーブルを定義
schema = StructType(
[
StructField("artist_id", StringType(), True),
StructField("artist_lat", DoubleType(), True),
StructField("artist_long", DoubleType(), True),
StructField("artist_location", StringType(), True),
StructField("artist_name", StringType(), True),
StructField("duration", DoubleType(), True),
StructField("end_of_fade_in", DoubleType(), True),
StructField("key", IntegerType(), True),
StructField("key_confidence", DoubleType(), True),
StructField("loudness", DoubleType(), True),
StructField("release", StringType(), True),
StructField("song_hotnes", DoubleType(), True),
StructField("song_id", StringType(), True),
StructField("start_of_fade_out", DoubleType(), True),
StructField("tempo", DoubleType(), True),
StructField("time_signature", DoubleType(), True),
StructField("time_signature_confidence", DoubleType(), True),
StructField("title", StringType(), True),
StructField("year", IntegerType(), True),
StructField("partial_sequence", IntegerType(), True)
]
)
@dp.table(
comment="Million Song Datasetのサブセットからの生データ。現代音楽トラックの特徴量とメタデータのコレクション。"
)
def songs_raw():
return (spark.readStream
.format("cloudFiles")
.schema(schema)
.option("cloudFiles.format", "csv")
.option("sep","\t")
.load(file_path))
# データを検証し、カラム名を変更するマテリアライズドビューを定義
@dp.materialized_view(
comment="分析用にクリーンアップ・準備されたMillion Song Dataset。"
)
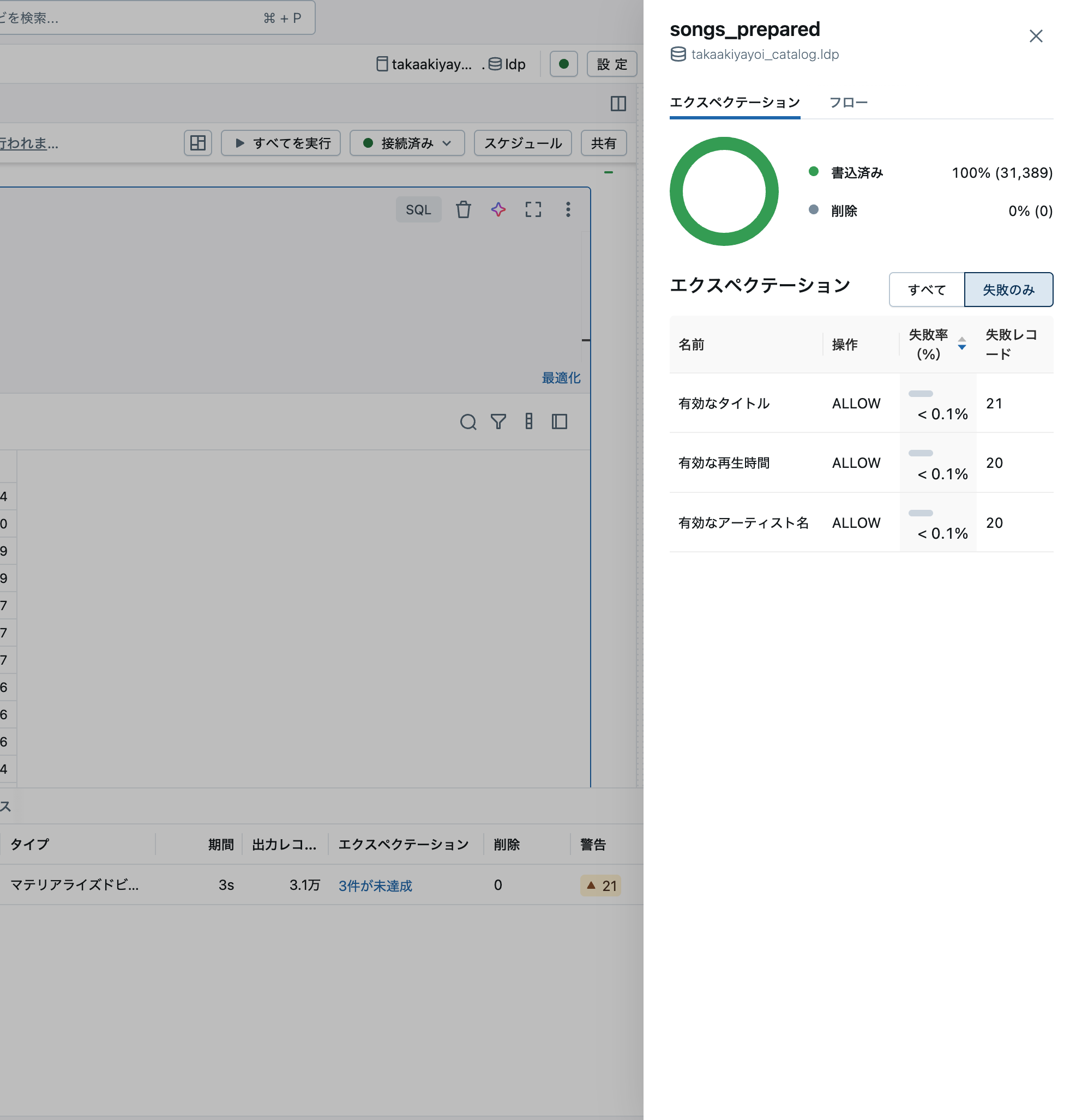
@dp.expect("有効なアーティスト名", "artist_name IS NOT NULL")
@dp.expect("有効なタイトル", "song_title IS NOT NULL")
@dp.expect("有効な再生時間", "duration > 0")
def songs_prepared():
return (
spark.read.table("songs_raw")
.withColumnRenamed("title", "song_title")
.select("artist_id", "artist_name", "duration", "release", "tempo", "time_signature", "song_title", "year")
)
# データをフィルタ・集計・ソートしたマテリアライズドビューを定義
@dp.materialized_view(
comment="各年で最も多くの曲をリリースしたアーティストごとの曲数を集計したテーブル。"
)
def top_artists_by_year():
return (
spark.read.table("songs_prepared")
.filter(expr("year > 0"))
.groupBy("artist_name", "year")
.count().withColumnRenamed("count", "total_number_of_songs")
.sort(desc("total_number_of_songs"), desc("year"))
)
これで、ロジックが実装できたので右上のパイプラインを実行をクリックします。
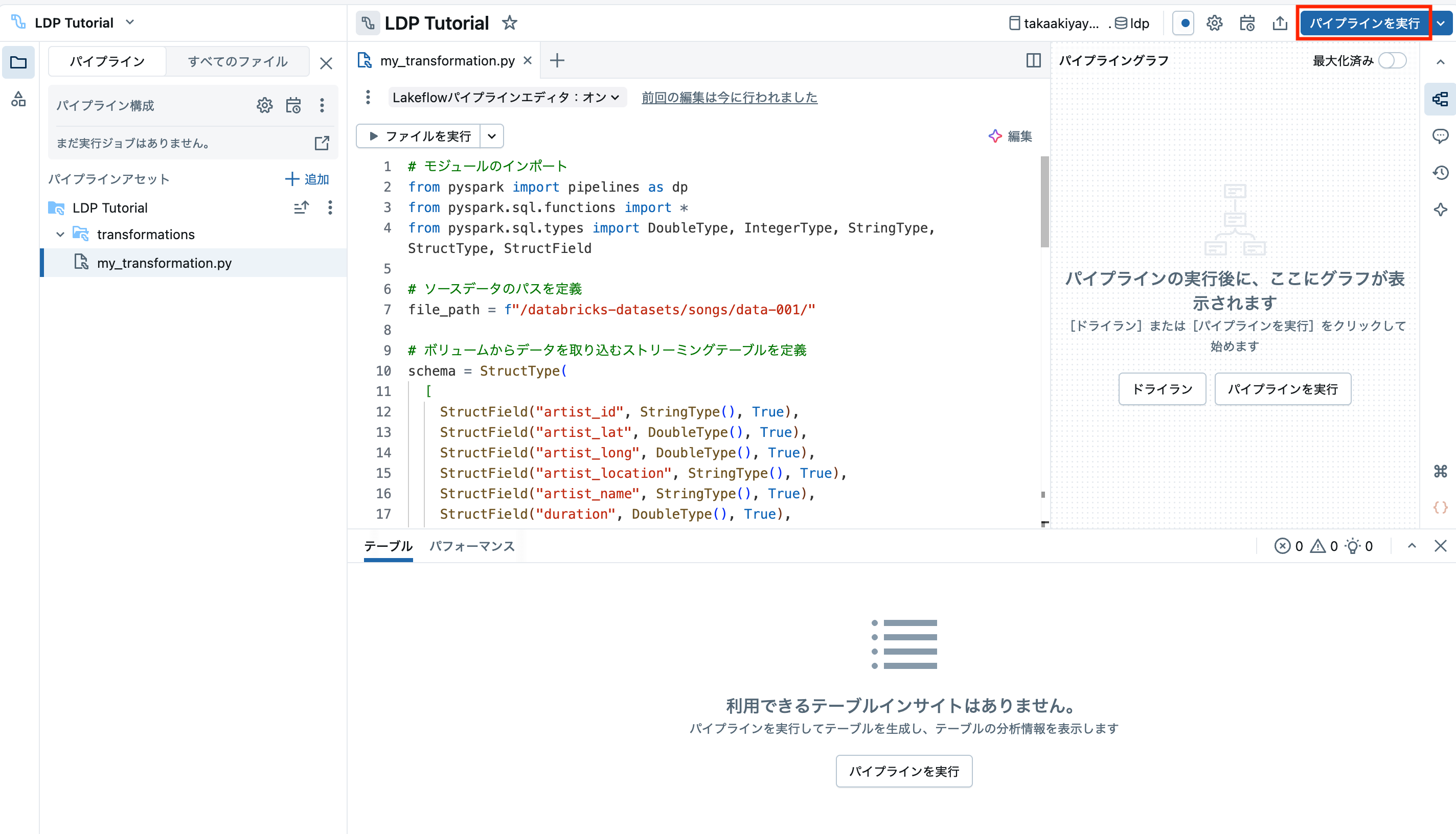
処理がスタートします。
右側にパイプラインのDAG(有効非循回グラフ)が表示されます。
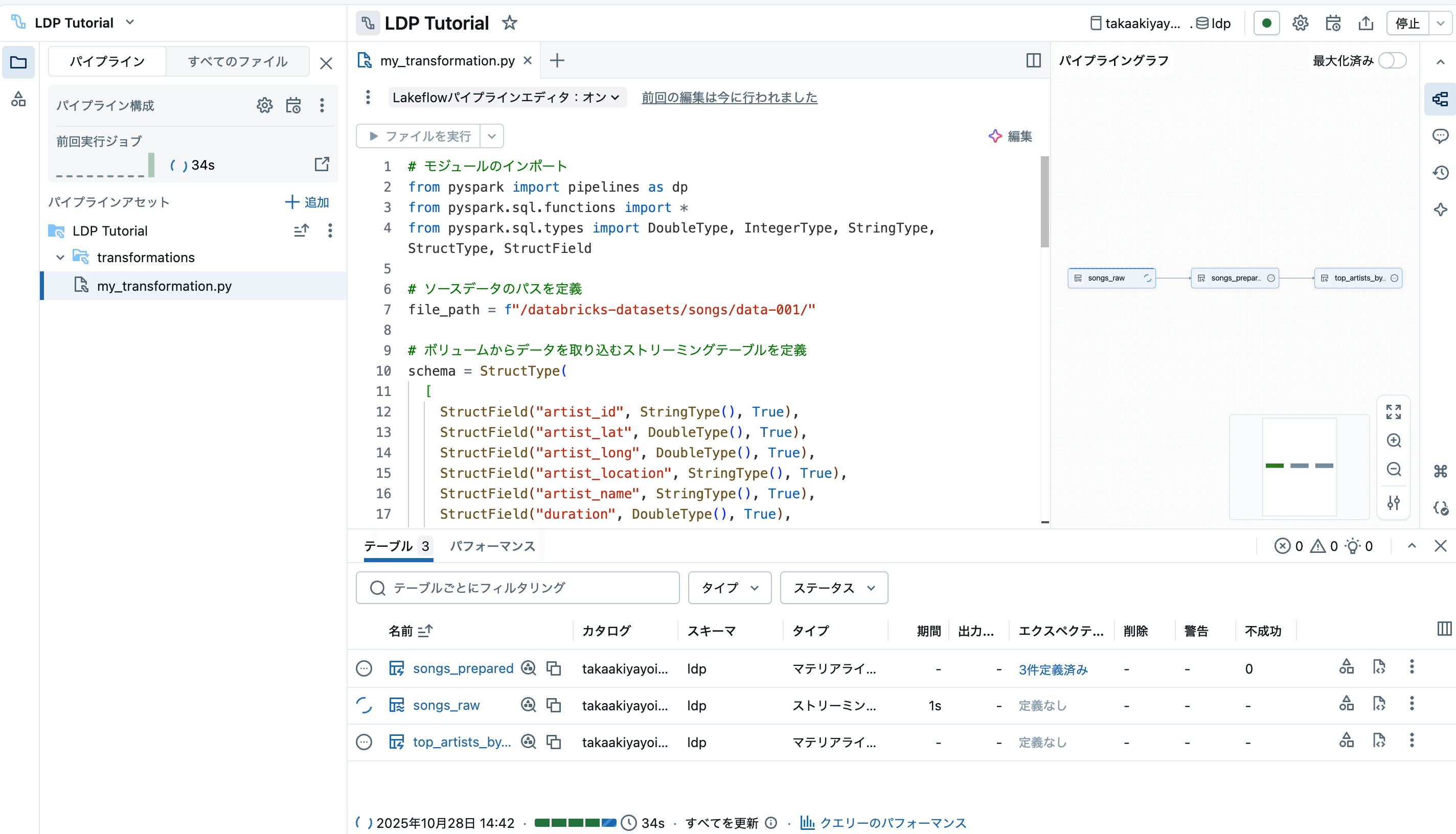
なお、右下の設定ボタンで、DAGの縦向き横向き表示を変更できます。データ処理の進捗をリアルタイムで確認できます。
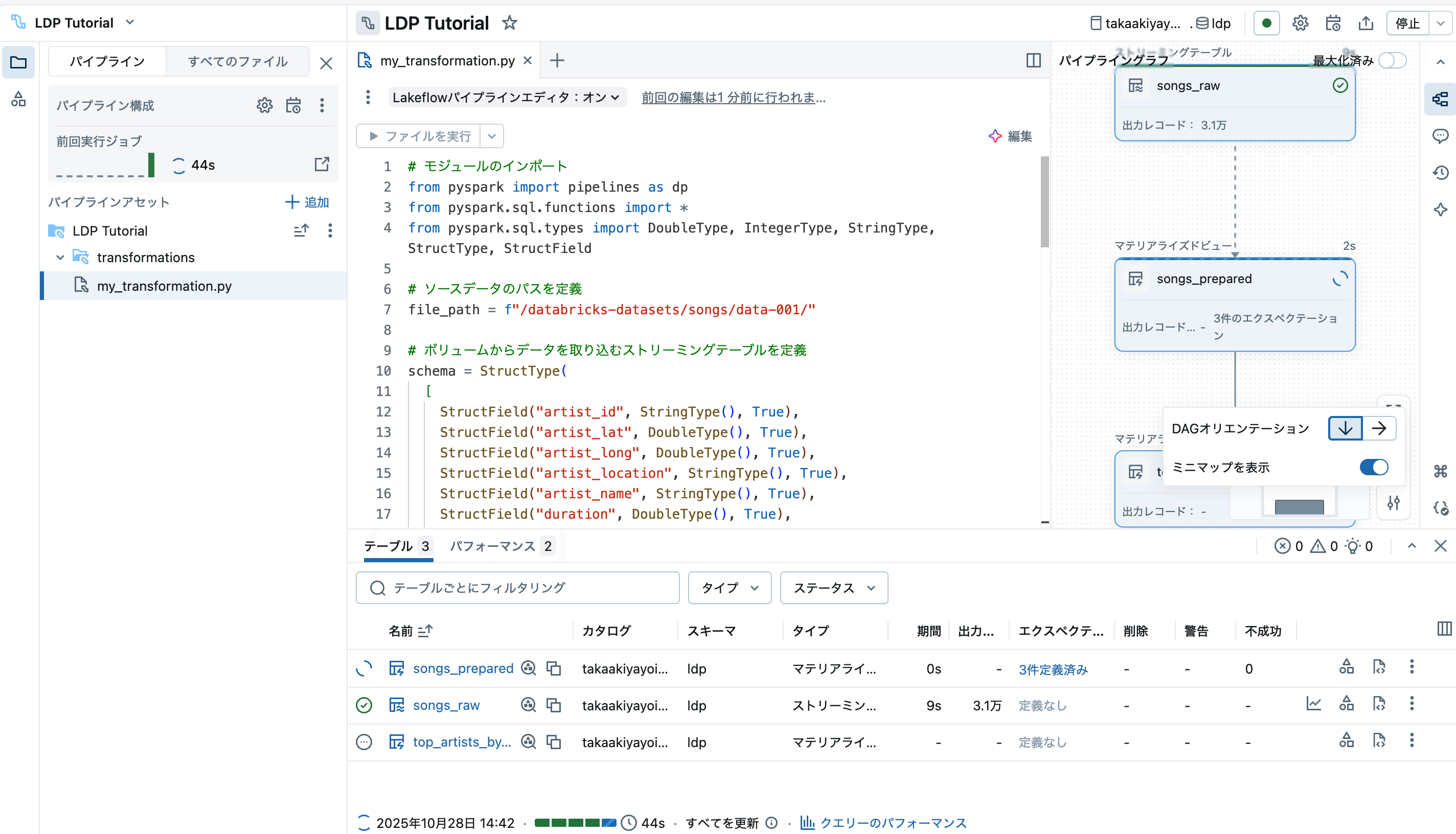
処理が完了するとグラフのすべてのノードが緑(エラーが起きたら赤)になります。
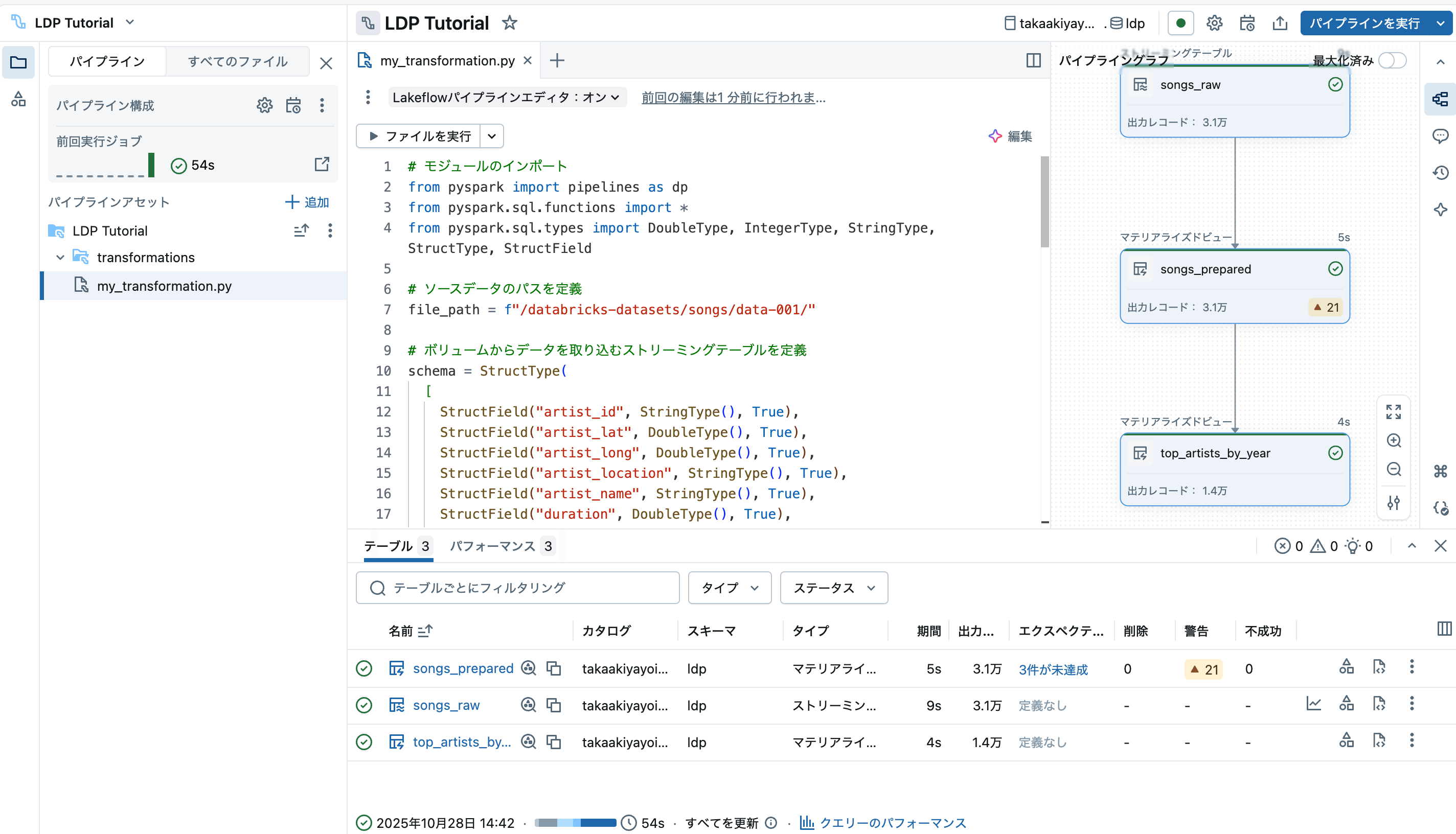
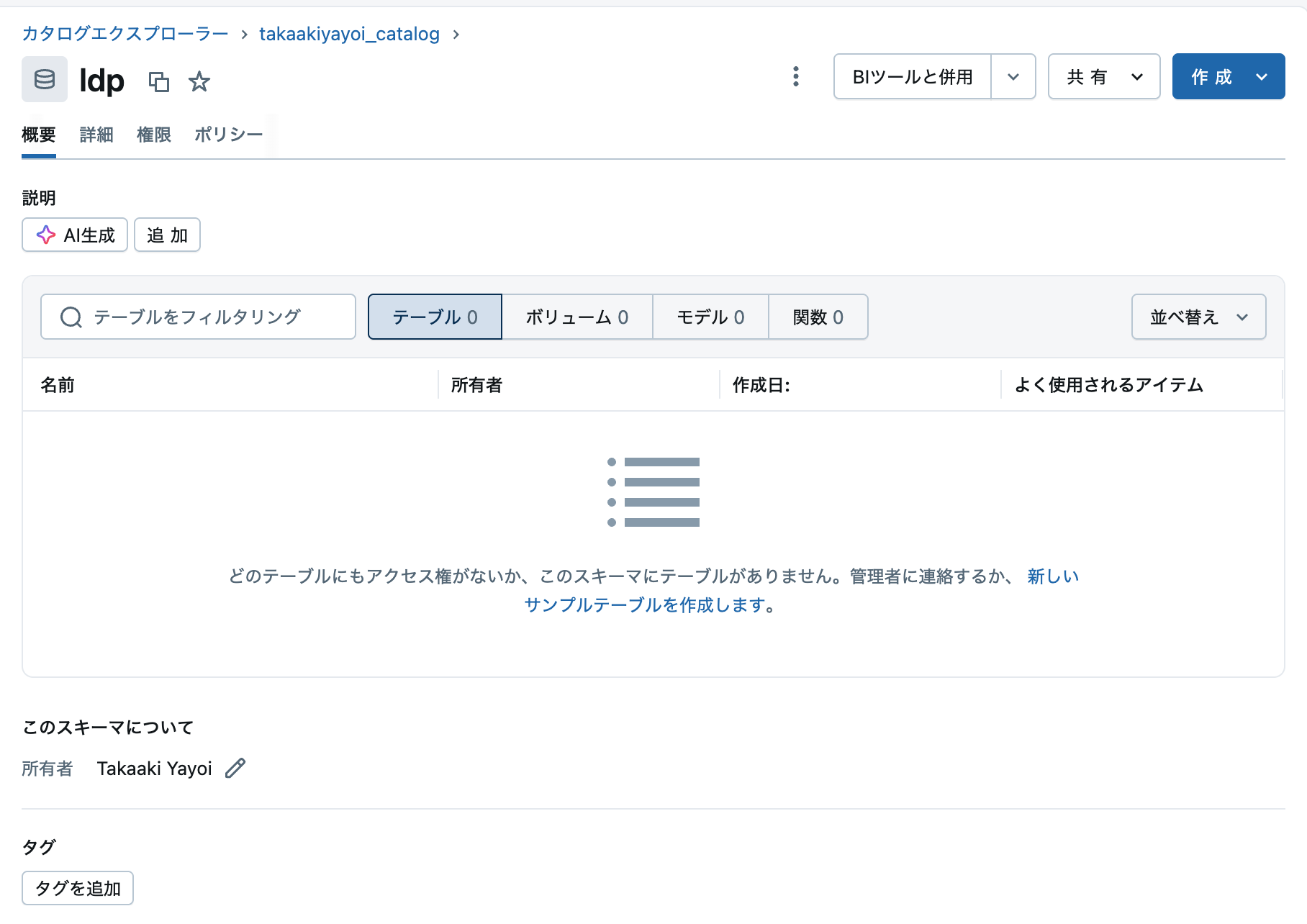
この時点で、処理されたデータを格納するテーブルが生成されているので、次のステップではこれらを探索します。
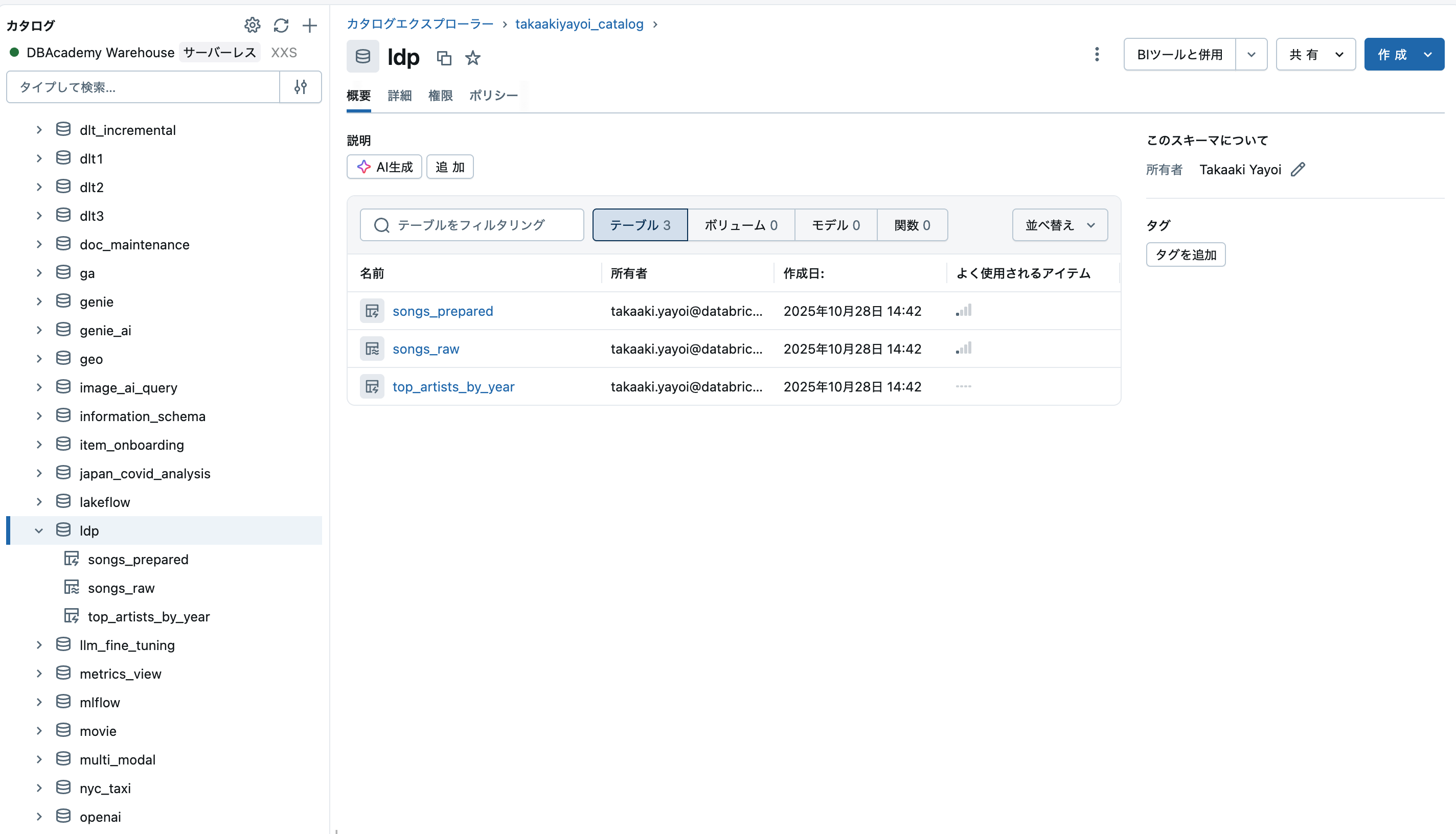
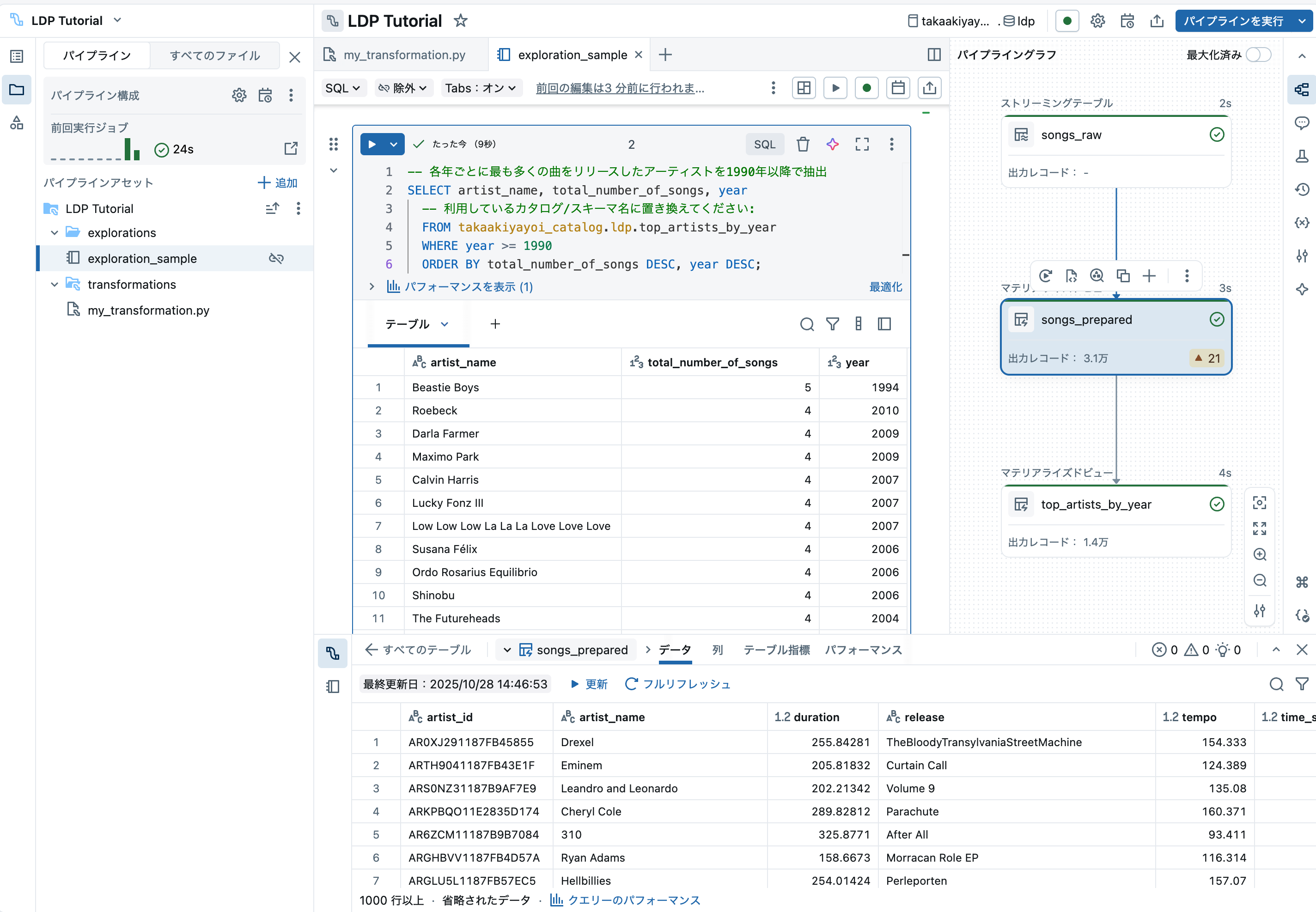
ステップ 3: パイプラインによって作成されたデータセットを探索する
追加 > 探索を選択して、探索用のファイルを作成します。
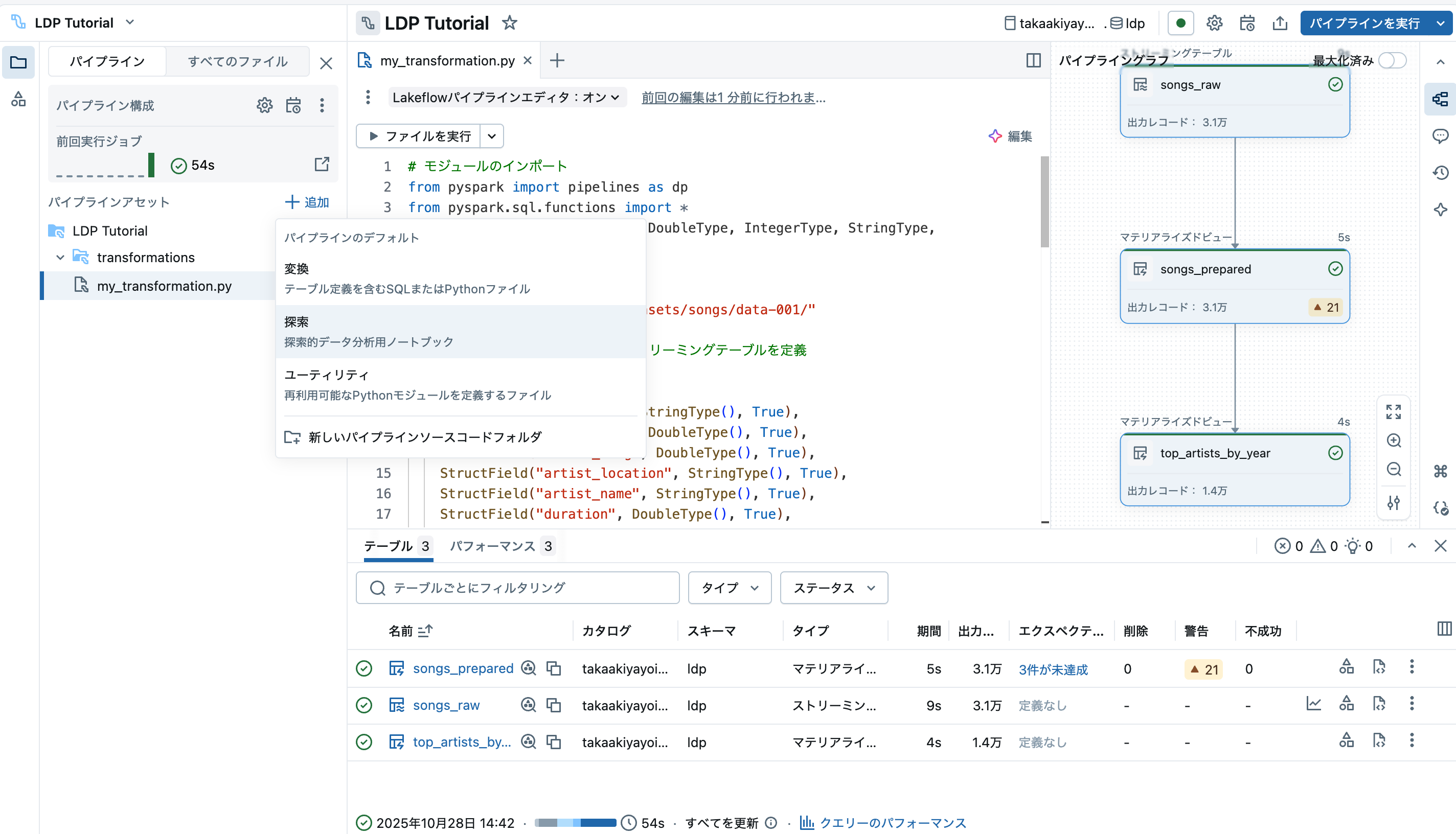
名前をつけます。今回は言語をSQLにします。
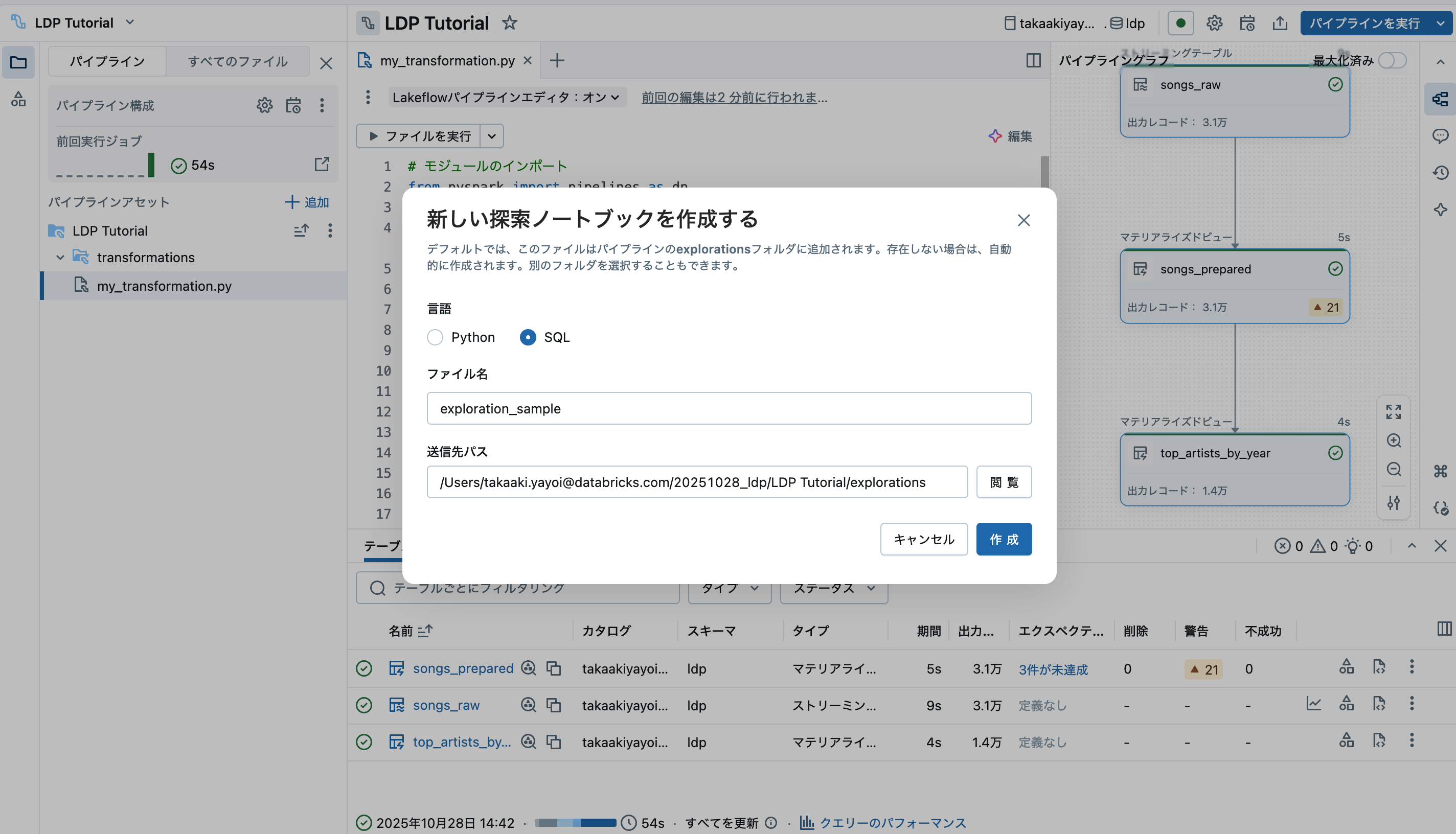
-- 各年ごとに最も多くの曲をリリースしたアーティストを1990年以降で抽出
SELECT artist_name, total_number_of_songs, year
-- 利用しているカタログ/スキーマ名に置き換えてください:
FROM takaakiyayoi_catalog.ldp.top_artists_by_year
WHERE year >= 1990
ORDER BY total_number_of_songs DESC, year DESC;
テーブルの中身を確認できます。
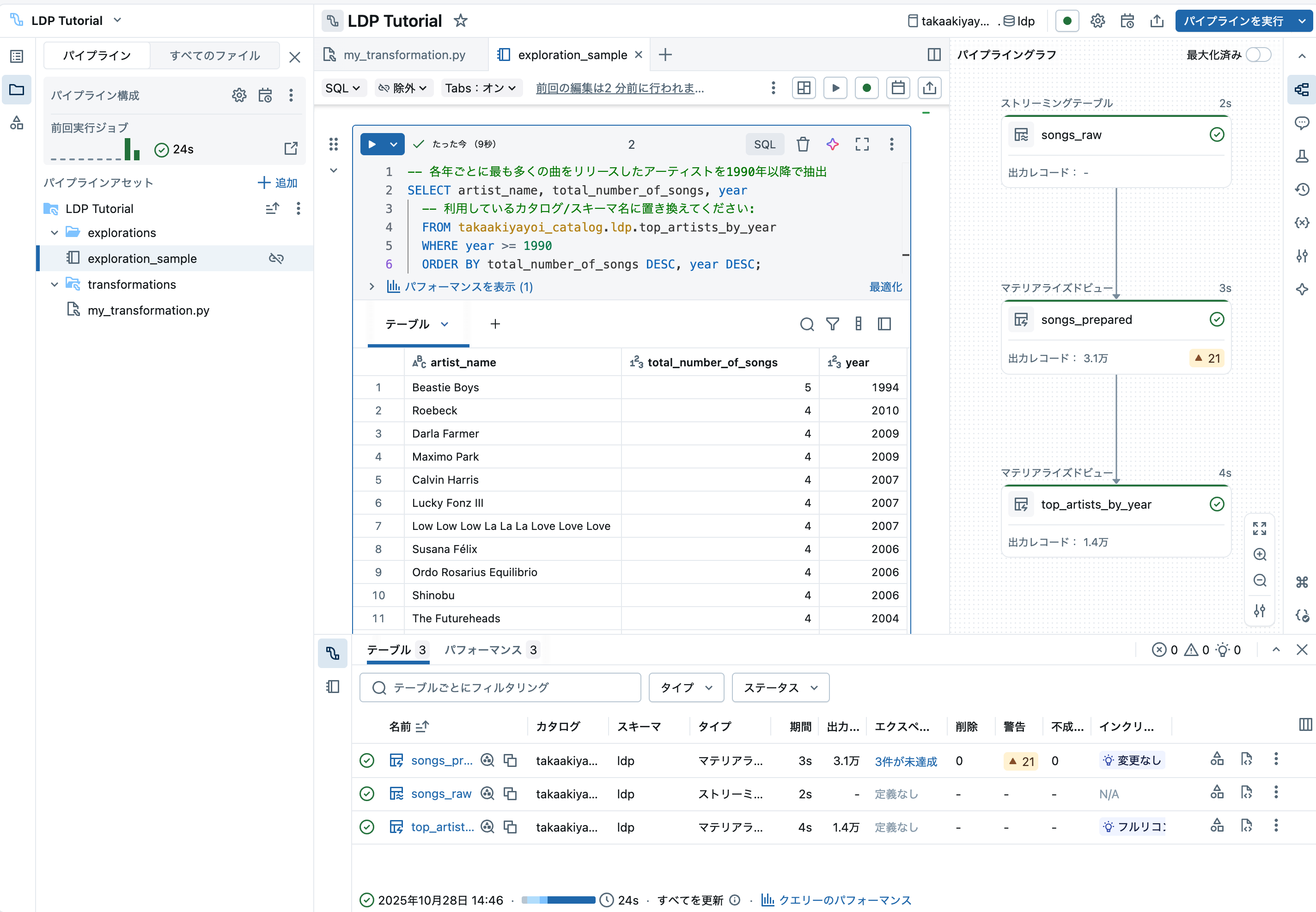
また、DAGのノードをクリックすることで処理の詳細を確認することもできます。
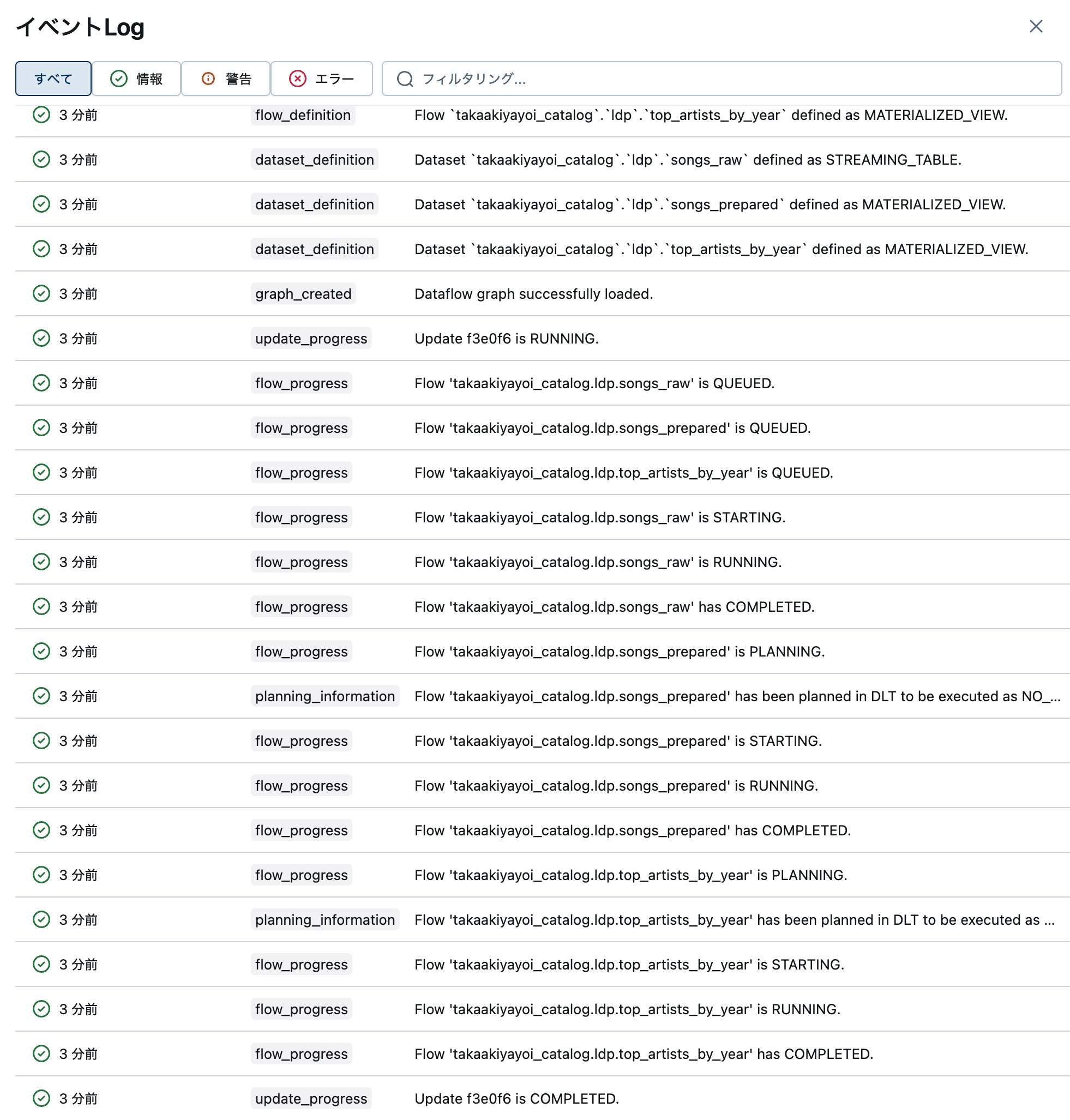
画面下部にあるインジケーターをクリックするとイベントログを確認できます。
エクスペクテーションを定義している場合には、判定結果も確認できます。
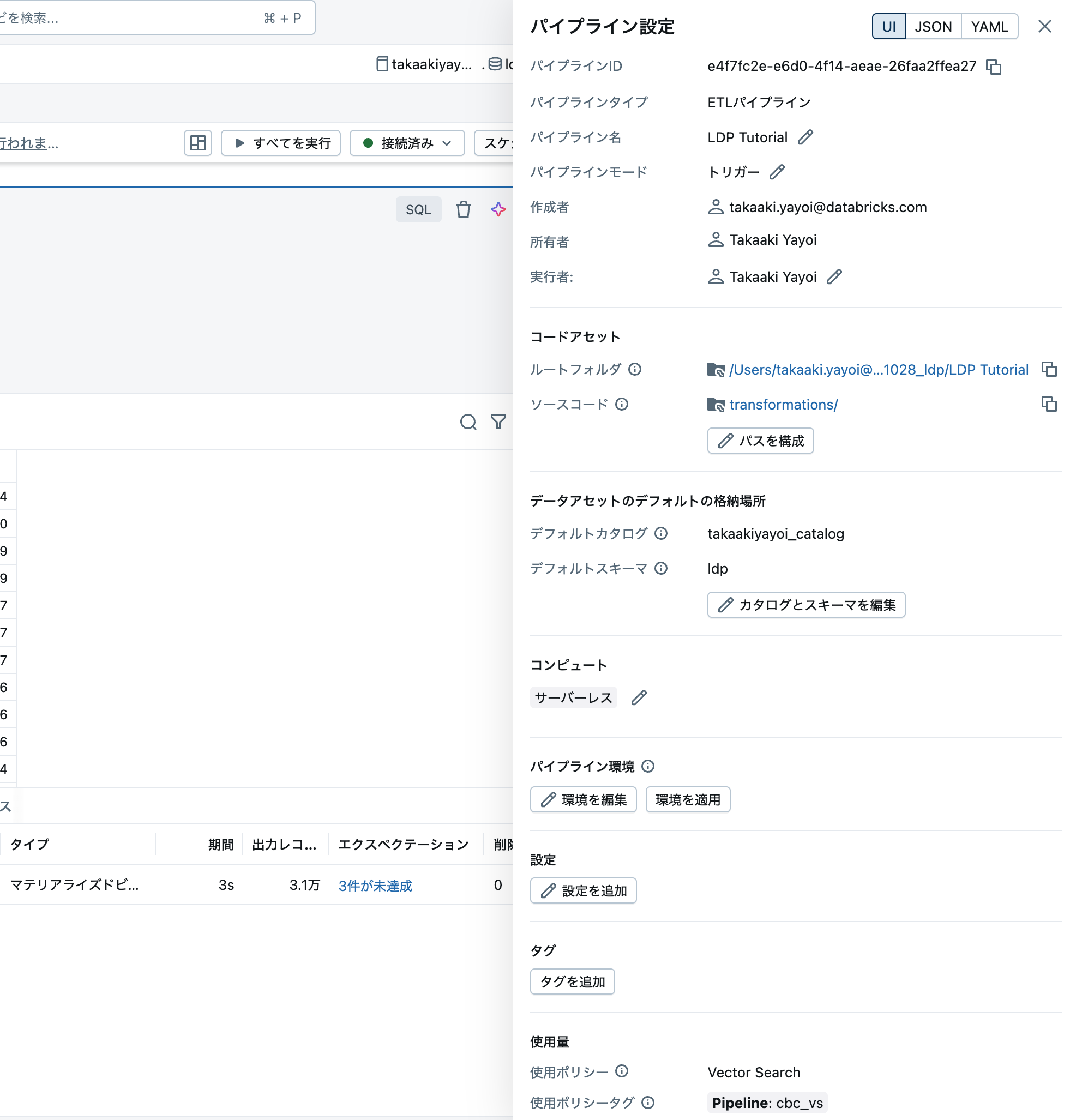
画面右上の設定からはパイプライン自身の設定を確認、変更できます。
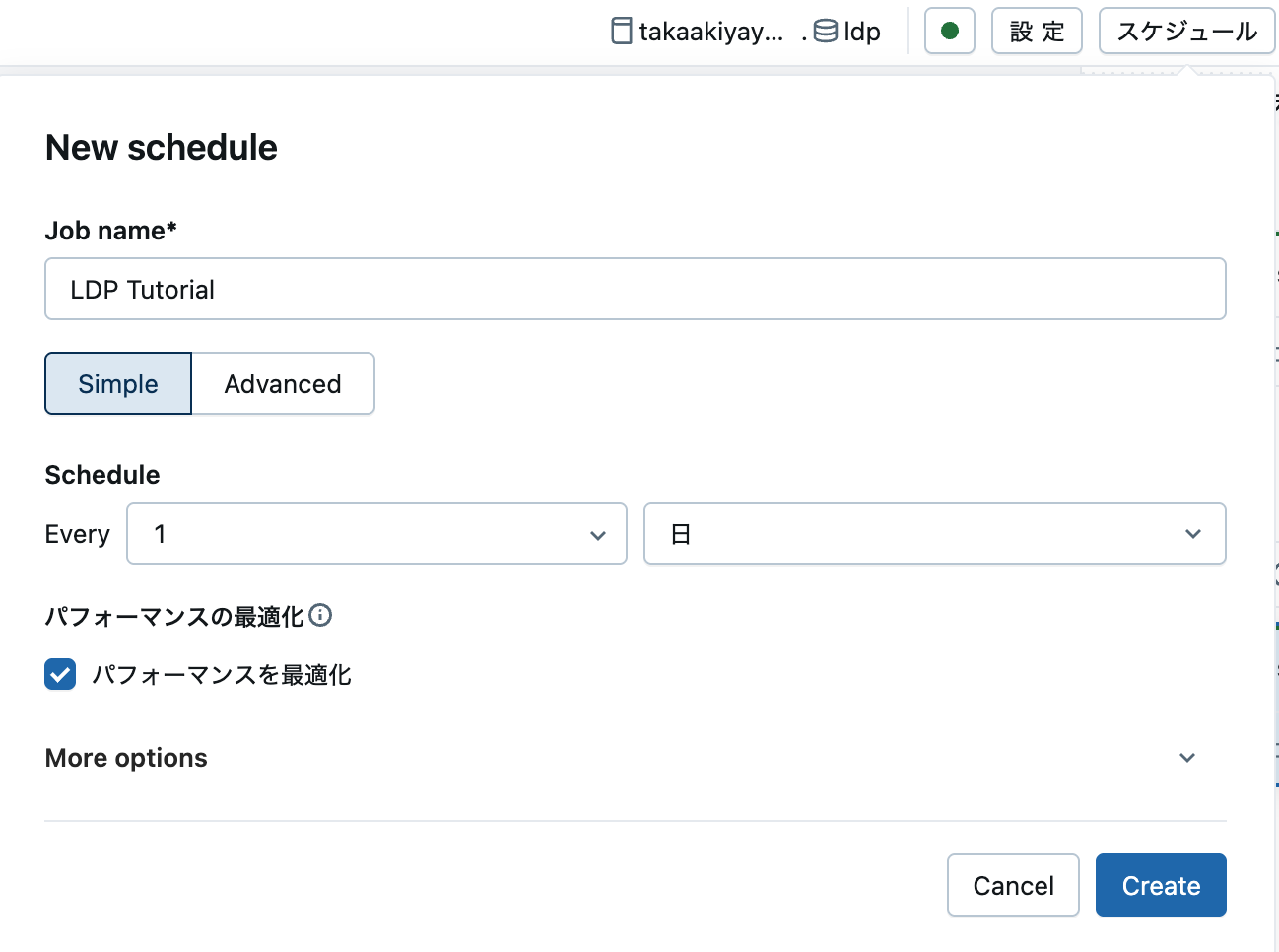
手順 4: パイプラインを実行するジョブを作成する
このデータパイプラインを定期実行したい場合には、画面右上のスケジュールボタンをクリックし、処理のスケジューリングを行います。