こちらの投稿をみると一ヶ月前に公開されていたようです。見逃していました。
我々の新たなアーキテクチャセンターで、あなたの最も重要なデータとAIの取り組みの構築、スケーリングのための設計図を手に入れましょう!パイプライン、ダッシュボード、AIモデルを構築するのだとしても、これらのリファレンスアーキテクチャはどのように迅速にそれを行うのかを説明してくれます。
あなたが見つけられるもののスナップショットです:
- Databricksにおけるインテリジェントデータウェアハウス
- Databricks AIセキュリティフレームワーク(DASF)
- Lakeflow宣言型パイプラインによるプロダクションETLのこうちく
- などなど!
アーキテクチャセンターはこちらです。
概要
Databricks Architecture Centerは、データエンジニアやアーキテクト向けに設計された包括的なリファレンスアーキテクチャ集です。データパイプライン、ダッシュボード、AIモデルの構築において、実証済みのベストプラクティスと設計パターンを提供します。Unity Catalogによる統合ガバナンス、メダリオンアーキテクチャ(Bronze/Silver/Gold)によるデータ階層化、バッチとストリーミングの統合処理など、モダンなデータ基盤に必要な要素を網羅しています。各アーキテクチャは、AWS、Azure、GCPなどのクラウドプロバイダーとの統合方法も含めて詳細に解説されており、組織のデータ戦略を加速させる実践的なガイドとなっています。
主要なアーキテクチャカテゴリ
| カテゴリ | 内容 | 主な用途 |
|---|---|---|
| データ取り込み | バッチ、CDC、ストリーミングパターン | リアルタイムデータパイプライン構築 |
| データウェアハウジング | SQLアナリティクスとBI統合 | 分析基盤の構築 |
| 機械学習/AI | Mosaic AI、MLflow統合 | MLOpsパイプライン実装 |
| 生成AI | LLMアプリケーション構築 | エンタープライズAIソリューション |
| 業界特化型 | 製造業向けIndustrial AI等 | 業界固有の要件対応 |
アーキテクチャの基本構成
各リファレンスアーキテクチャは、以下の標準的なレイヤー構造に基づいて設計されています:
データソース → 取り込み → 変換 → クエリ/処理 → 配信 → 分析 → ストレージ
この一貫した構造により、異なるユースケース間でも共通の設計原則を適用できます。
メリット、嬉しさ
1. 実装時間の大幅短縮
Architecture Centerが提供する実証済みのパターンを活用することで、ゼロから設計する場合と比較して実装期間を大幅に短縮できます。特に以下の点で効果的です:
- 設計の迷いを解消: ベストプラクティスが明確に示されているため、技術選定や設計判断で迷う時間を削減
- 統合パターンの再利用: クラウドサービスとの統合方法が具体的に示されており、試行錯誤を回避
- チーム間の認識統一: 標準化されたアーキテクチャにより、開発チーム内での共通理解が促進
2. エンタープライズグレードの信頼性
各アーキテクチャは実際の企業導入事例に基づいており、以下の要件を満たしています:
| 要件 | 実現方法 |
|---|---|
| スケーラビリティ | Photonエンジンによる高速処理とサーバーレスコンピュート |
| ガバナンス | Unity Catalogによる統一的なデータ管理 |
| セキュリティ | ネットワーク境界の分離とアクセス制御 |
| 監視性 | Azure Monitor、AWS CloudWatchとの統合 |
3. クラウドネイティブな統合
各クラウドプロバイダー(AWS、Azure、GCP)との最適な統合方法が示されており、既存のクラウド投資を最大限活用できます。例えば:
- Azure: Power BI、Microsoft Purview、Azure DevOpsとのネイティブ統合
- AWS: Amazon Redshift、S3、IAMとのシームレスな連携
- マルチクラウド: Delta Sharingによるクラウド間データ共有
使い方の流れ
ステップ1: ユースケースに合ったアーキテクチャの選択
Architecture Centerにアクセスし、自組織のニーズに最も適合するアーキテクチャを特定します:
- https://www.databricks.com/resources/architectures にアクセス
- Featured architecturesセクションで主要なアーキテクチャを確認
- Architecture libraryから詳細なカテゴリを探索
ステップ2: リファレンスアーキテクチャのダウンロードと分析
選択したアーキテクチャについて、以下の資料を入手・確認します:
| 資料タイプ | 内容 | 活用方法 |
|---|---|---|
| アーキテクチャ図 | アーキテクチャの詳細図 | 技術レビューや設計会議での共有 |
| 構成説明 | 各コンポーネントの役割と関係性 | システム設計書の基礎資料として |
| 統合パターン | クラウドサービスとの接続方法 | インテグレーション設計の参考 |
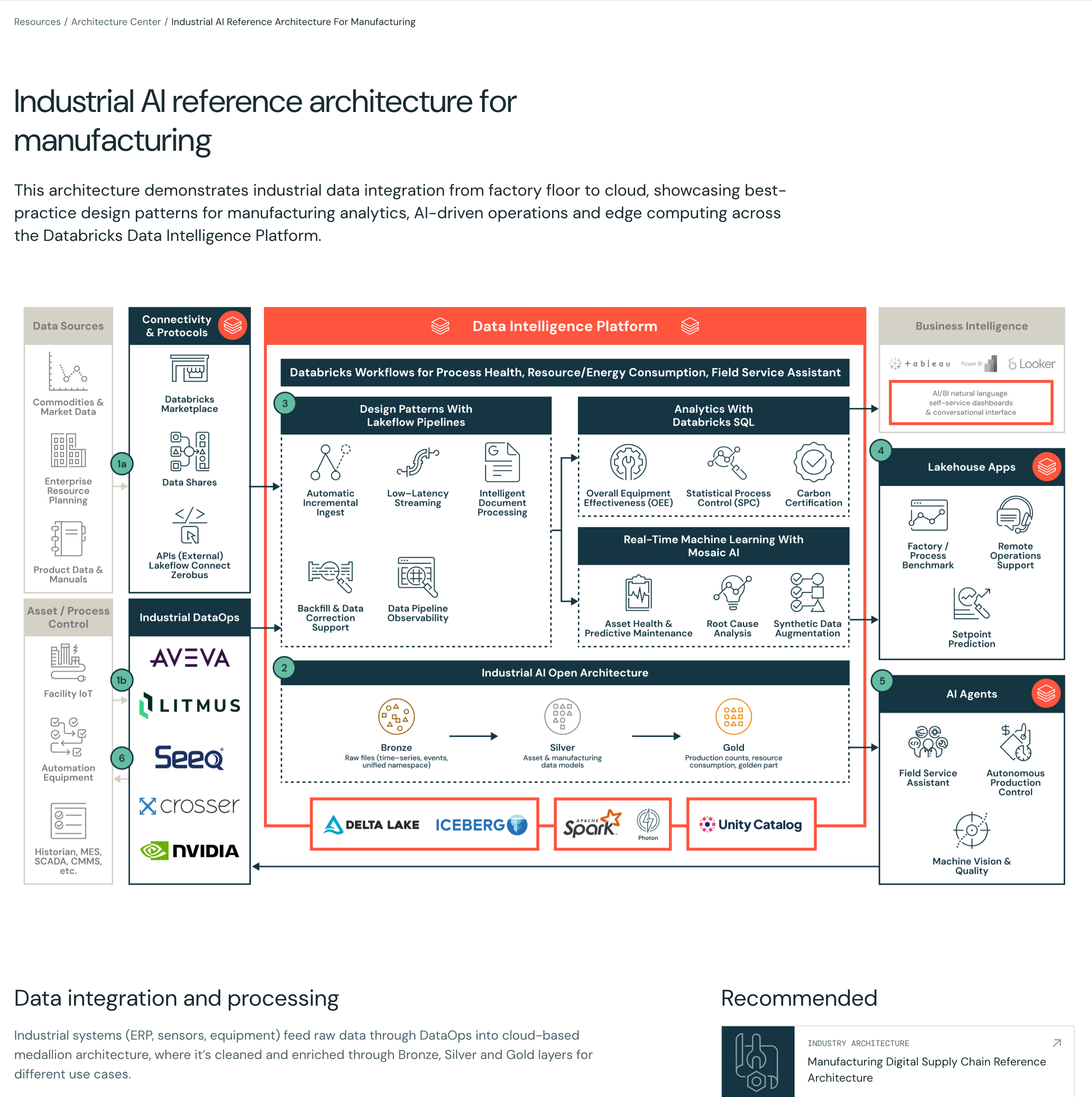
ステップ3: 自社要件へのマッピング
ダウンロードしたアーキテクチャを基に、自社の要件と照らし合わせます:
- 既存システムの棚卸し: 現在のデータソースとシステムを整理
- ギャップ分析: リファレンスアーキテクチャと現状の差異を特定
- 優先順位付け: 段階的な実装計画を策定
ステップ4: 技術詳細の深掘り
Architecture Centerで提供される設計パターンを基に、実装に必要な技術詳細を別途調査:
設計パターン(Architecture Center) → 技術ドキュメント(docs.databricks.com) → 実装
例えば、メダリオンアーキテクチャの場合:
- Architecture Center: 3層構造の概念と利点を理解
- 技術ドキュメント: Delta Live Tablesの具体的な実装方法を学習
- 実装: 自社データに合わせたパイプラインを構築
ステップ5: プロトタイプの構築と検証
小規模なプロトタイプから開始し、段階的に拡張:
- 概念実証(PoC): 単一のデータソースで基本的なパイプラインを構築
- パイロット: 複数のデータソースと実際のユースケースで検証
- 本番展開: 検証済みのアーキテクチャを全社展開
注意点
1. Architecture Centerの位置づけを正しく理解
Architecture Centerは設計ガイドであり、実装マニュアルではありません:
- 提供されるもの: アーキテクチャパターン、ベストプラクティス、設計原則
- 提供されないもの: コード例、ステップバイステップの実装手順、ハンズオンチュートリアル
実装の詳細については、Databricks公式ドキュメントや技術トレーニングを別途参照する必要があります。
2. 組織の成熟度に応じた段階的導入
Architecture Centerが提示する完全なアーキテクチャを一度に実装する必要はありません:
- 初期段階: 基本的なETLパイプラインとデータレイク構築から開始
- 成長段階: Unity Catalogによるガバナンス層の追加
- 成熟段階: AI/MLワークロードの統合とリアルタイム処理の実装
3. クラウドコストの最適化
アーキテクチャ実装時は、以下のコスト最適化ポイントに注意:
- コンピュートリソース: ワークロードに応じたクラスターサイズの選択
- ストレージ: データのライフサイクル管理とアーカイブ戦略
- ネットワーク: リージョン間データ転送の最小化
4. 既存システムとの統合
レガシーシステムとの統合には以下の考慮が必要:
- データ移行: 段階的な移行計画とロールバック戦略
- API互換性: 既存アプリケーションとの接続性確認
- 運用プロセス: 既存の運用フローとの整合性確保
まとめ
Databricks Architecture Centerは、データとAIを統合する現代的なデータプラットフォームを構築するための実践的な設計ガイドです。実証済みのアーキテクチャパターン、メダリオンアーキテクチャによるデータ品質管理、Unity Catalogによる統合ガバナンスなど、エンタープライズレベルのデータ基盤に必要な要素を包括的にカバーしています。
重要な点は、Architecture Centerは「何を構築すべきか」という設計の青写真を提供するものであり、具体的な実装手順は含まれていないということです。各組織は、提供されるリファレンスアーキテクチャを出発点として、自社の要件に合わせてカスタマイズし、別途技術ドキュメントを参照しながら実装を進める必要があります。
段階的な導入アプローチを採用し、既存システムとの統合を慎重に計画することで、リスクを最小限に抑えながら、データ駆動型組織への変革を実現できます。Architecture Centerは、その道筋を明確に示す羅針盤として機能し、データエンジニアとアーキテクトが自信を持って次世代のデータプラットフォームを設計できるよう支援します。