こちらの続きです。ここで書いてあることは、Delta Lakeにも当てはまります。
ノートブックはこちらで、動画はこちらです。
0. セットアップ
このノートブックの一般的なヒント:
- Spark UIはクラスター -> Spark UIでアクセス可能
- Spark UIの詳細な調査は後のエピソードで行います
-
sc.setJobDescription("Description")はSpark UIのアクションのジョブ説明を独自のものに置き換えます -
sdf.rdd.getNumPartitions()は現在のSpark DataFrameのパーティション数を返します -
sdf.write.format("noop").mode("overwrite").save()は、実際の書き込み中に副作用なしで変換を分析および開始するための良い方法です
from pyspark.sql import SparkSession
from pyspark.sql import functions as f
# AQEをオフにする。これは、このシナリオでは混乱を招く可能性があるため、追加のジョブを生成しないようにする。
spark.conf.set("spark.sql.adaptive.enabled", "false")
# データフレームをキャッシュしないようにする...これにより、繰り返し可能な結果が得られない場合があります。
spark.conf.set("spark.databricks.io.cache.enabled", "false")
def sdf_generator(num_rows: int, num_partitions: int = None) -> "DataFrame":
return (
spark.range(num_rows, numPartitions=num_partitions)
.withColumn("date", f.current_date())
.withColumn("timestamp",f.current_timestamp())
.withColumn("idstring", f.col("id").cast("string"))
.withColumn("idfirst", f.col("idstring").substr(0,1))
.withColumn("idlast", f.col("idstring").substr(-1,1))
)
sdf_gen = sdf_generator(20)
sdf_gen.count()
20
sdf_gen.show()
+---+----------+--------------------+--------+-------+------+
| id| date| timestamp|idstring|idfirst|idlast|
+---+----------+--------------------+--------+-------+------+
| 0|2024-12-05|2024-12-05 04:19:...| 0| 0| 0|
| 1|2024-12-05|2024-12-05 04:19:...| 1| 1| 1|
| 2|2024-12-05|2024-12-05 04:19:...| 2| 2| 2|
| 3|2024-12-05|2024-12-05 04:19:...| 3| 3| 3|
| 4|2024-12-05|2024-12-05 04:19:...| 4| 4| 4|
| 5|2024-12-05|2024-12-05 04:19:...| 5| 5| 5|
| 6|2024-12-05|2024-12-05 04:19:...| 6| 6| 6|
| 7|2024-12-05|2024-12-05 04:19:...| 7| 7| 7|
| 8|2024-12-05|2024-12-05 04:19:...| 8| 8| 8|
| 9|2024-12-05|2024-12-05 04:19:...| 9| 9| 9|
| 10|2024-12-05|2024-12-05 04:19:...| 10| 1| 0|
| 11|2024-12-05|2024-12-05 04:19:...| 11| 1| 1|
| 12|2024-12-05|2024-12-05 04:19:...| 12| 1| 2|
| 13|2024-12-05|2024-12-05 04:19:...| 13| 1| 3|
| 14|2024-12-05|2024-12-05 04:19:...| 14| 1| 4|
| 15|2024-12-05|2024-12-05 04:19:...| 15| 1| 5|
| 16|2024-12-05|2024-12-05 04:19:...| 16| 1| 6|
| 17|2024-12-05|2024-12-05 04:19:...| 17| 1| 7|
| 18|2024-12-05|2024-12-05 04:19:...| 18| 1| 8|
| 19|2024-12-05|2024-12-05 04:19:...| 19| 1| 9|
+---+----------+--------------------+--------+-------+------+
def rows_per_partition(sdf: "DataFrame") -> None:
num_rows = sdf.count()
sdf_part = sdf.withColumn("partition_id", f.spark_partition_id())
sdf_part_count = sdf_part.groupBy("partition_id").count()
sdf_part_count = sdf_part_count.withColumn("count_perc", 100*f.col("count")/num_rows)
sdf_part_count.orderBy("partition_id").show()
def rows_per_partition_col(sdf: "DataFrame", num_rows: int, col: str) -> None:
sdf_part = sdf.withColumn("partition_id", f.spark_partition_id())
sdf_part_count = sdf_part.groupBy("partition_id", col).count()
sdf_part_count = sdf_part_count.withColumn("count_perc", 100*f.col("count")/num_rows)
sdf_part_count.orderBy("partition_id", col).show()
ここまでは、以前と同様です。
ファイルの格納場所として、Unity Catalogのボリュームを指定します。
base_dir = "/Volumes/takaakiyayoi_catalog/spark/data"
100万レコードのデータフレームを保存します。
num_rows = 1000000
1. パーティション数に基づいて、いくつのファイル数が書き込まれるのか
- 答えは簡単です。ParquetはSparkのパーティションに基づいてデータを複数のsnappyファイルに分割します。これにより、これらのファイルを並行して書き込むことができます。
- Parquetの詳細はこちらで確認できます: https://learncsdesigns.medium.com/understanding-apache-parquet-d722645cfe74
パーティション数を1にして、Parquetとして保存します。
sdf = sdf_generator(num_rows, 1)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Write 1 file")
sdf.write.format("parquet").mode("overwrite").save(f"{base_dir}/test_1_file.parquet")
sc.setJobDescription("None")
1
カタログエクスプローラで保存先を確認すると、一つのsnappy.parquetファイルが保存されていることを確認できます。
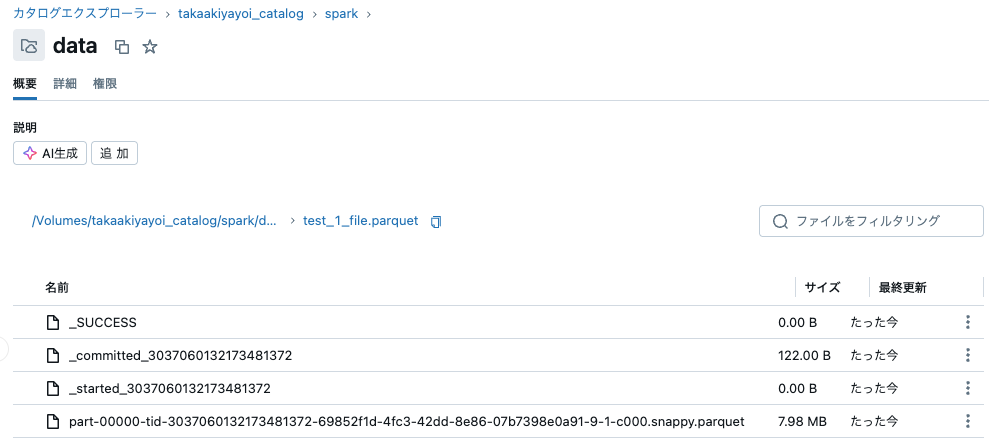
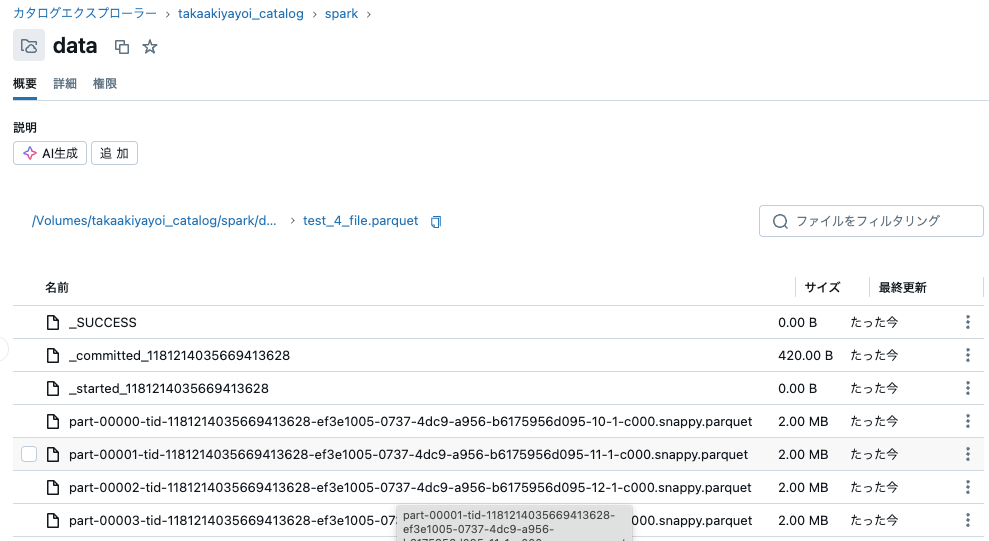
4パーティション、12パーティションで保存します。
sdf = sdf_generator(num_rows, 4)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Write 4 file")
sdf.write.format("parquet").mode("overwrite").save(f"{base_dir}/test_4_file.parquet")
sc.setJobDescription("None")
4
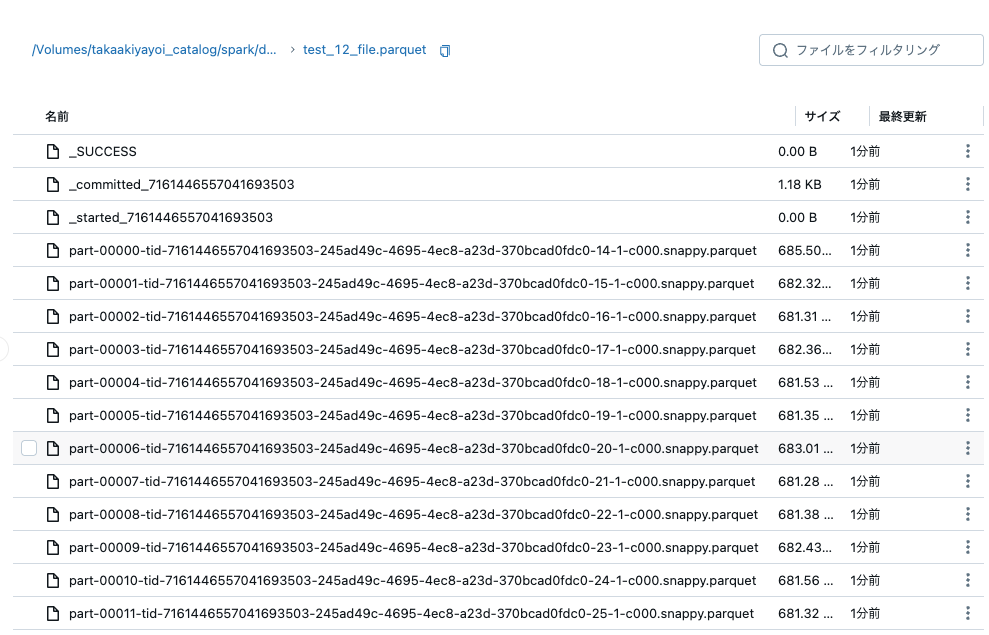
sdf = sdf_generator(num_rows, 12)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Write 12 file")
sdf.write.format("parquet").mode("overwrite").save(f"{base_dir}/test_12_file.parquet")
sc.setJobDescription("None")
12
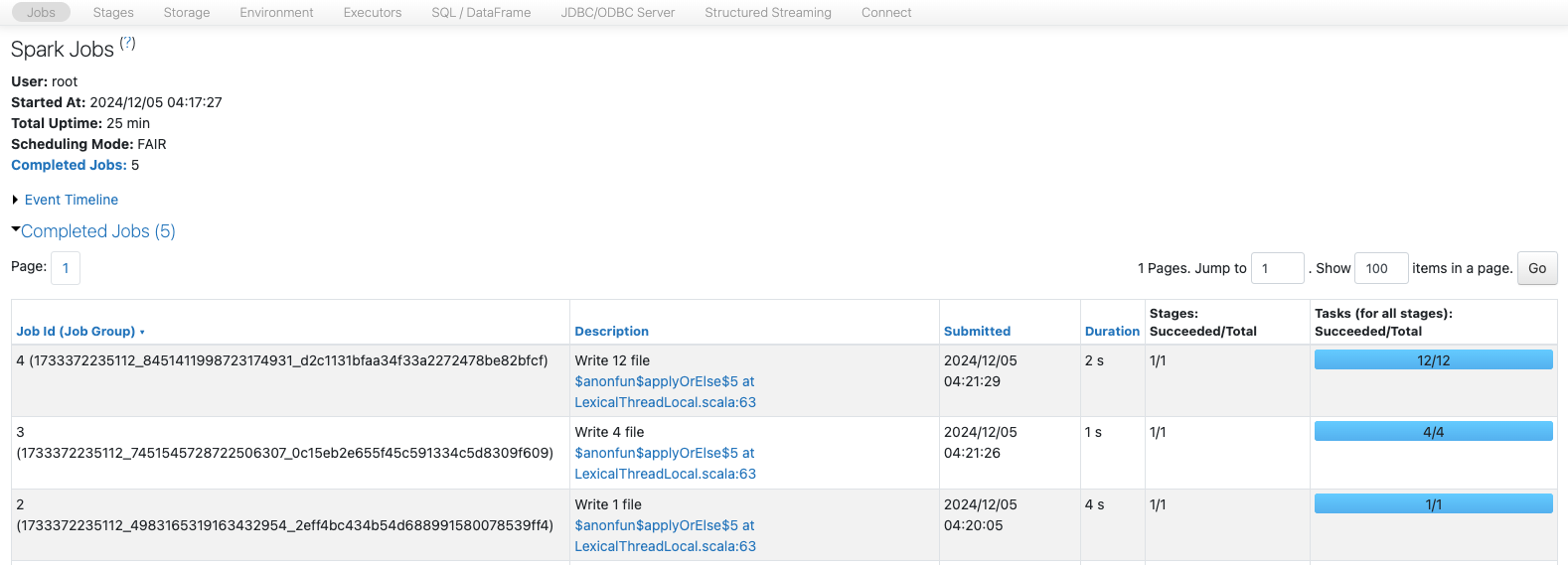
2. Spark UIでは何が表示されますか?
- 各書き込みに対して1つのジョブと1つのステージがあります。
- 書き込みにおいても、カウントがパーティションに分割する方法を決定します。1つのパーティションは、4コアにおいて4または12のパーティションよりも少ないです。12のパーティションは8MBのデータを書き込む際にオーバーヘッドがあるようです。
- SQLタブでは、書き込まれたファイルの数とデータ量も確認できます。
- ステージでは、書き込まれた行数とサイズ、実行時間も確認できます。
パーティション数が増えると、書き込みに多いても並列化の恩恵を受けることができ、書き込みを高速化することができます。
1パーティション
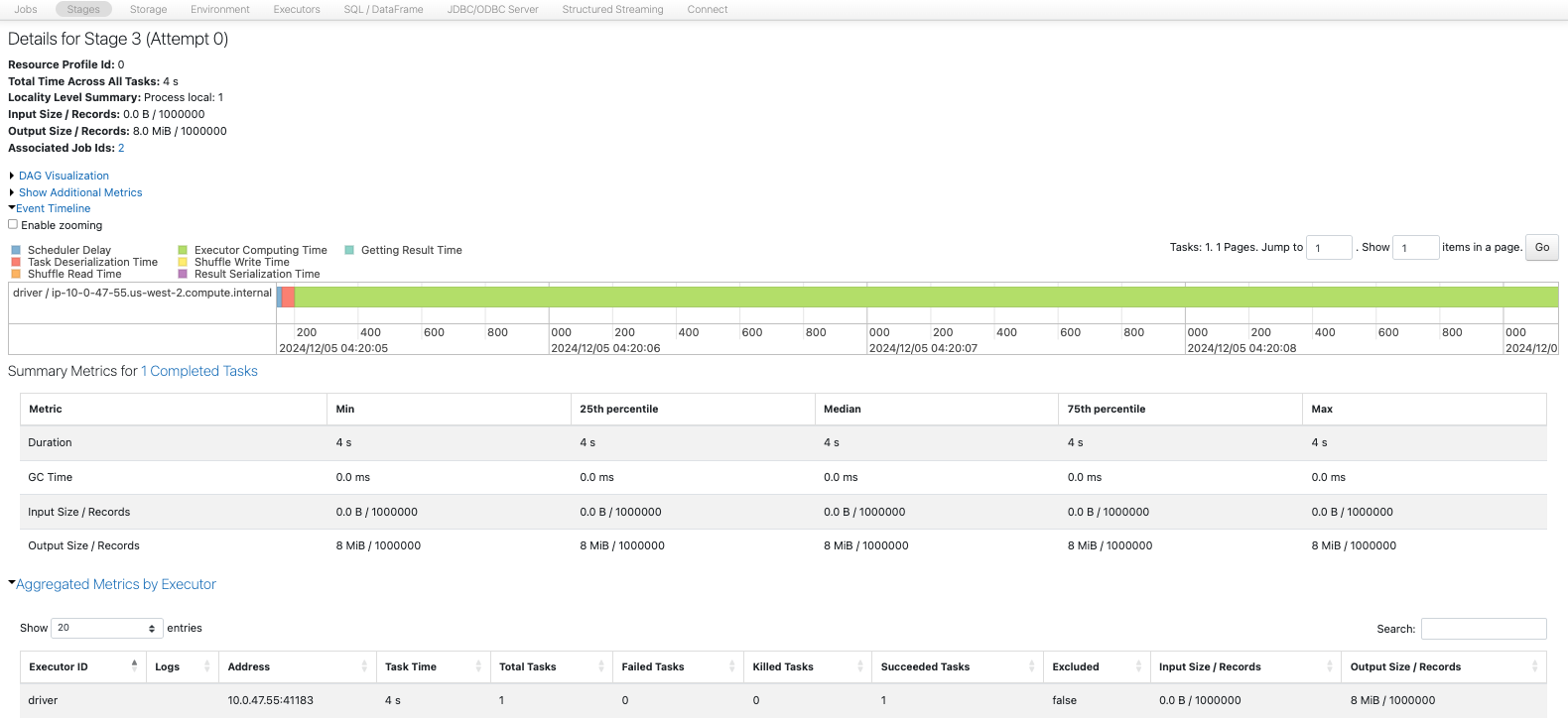
4パーティション
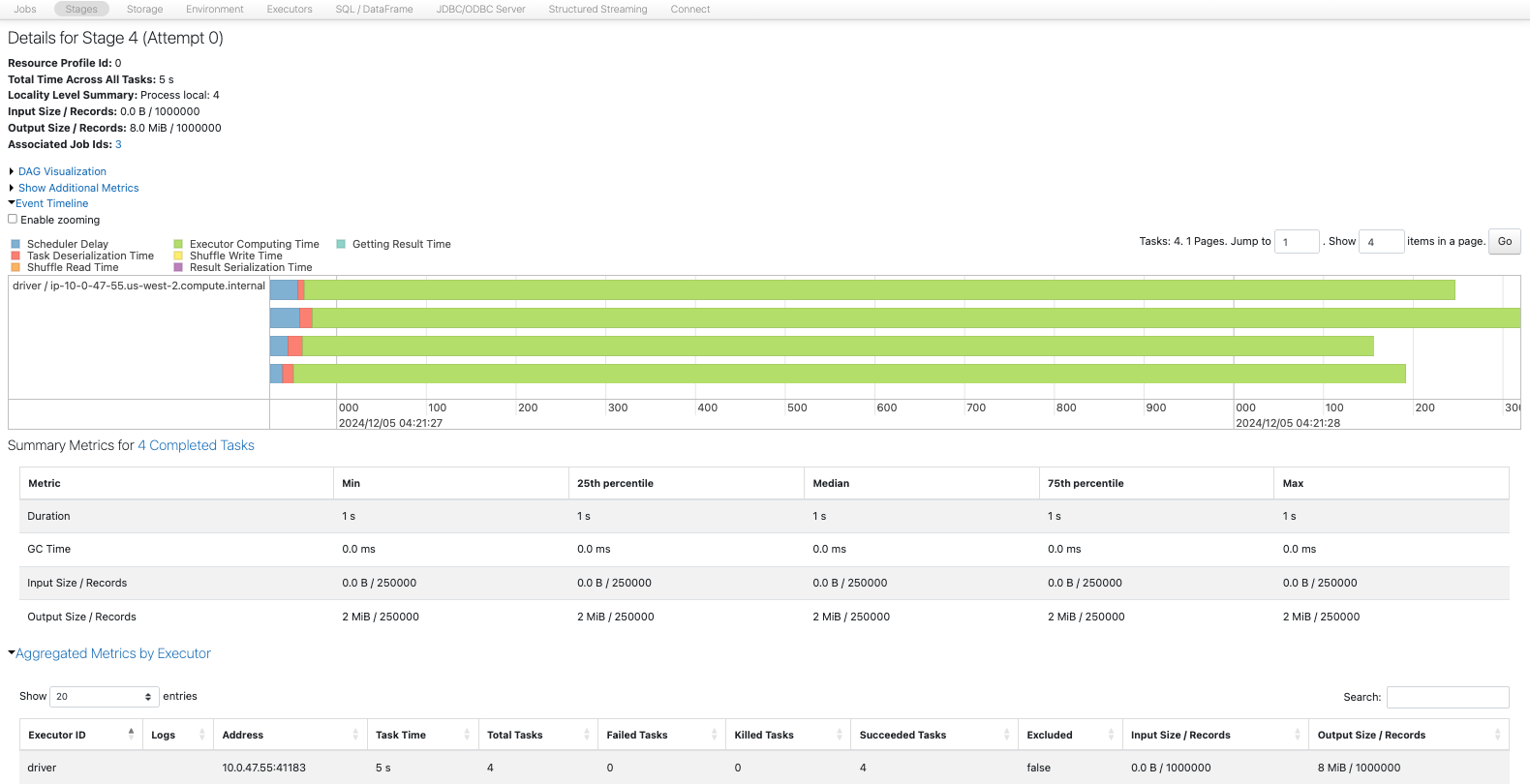
12パーティション
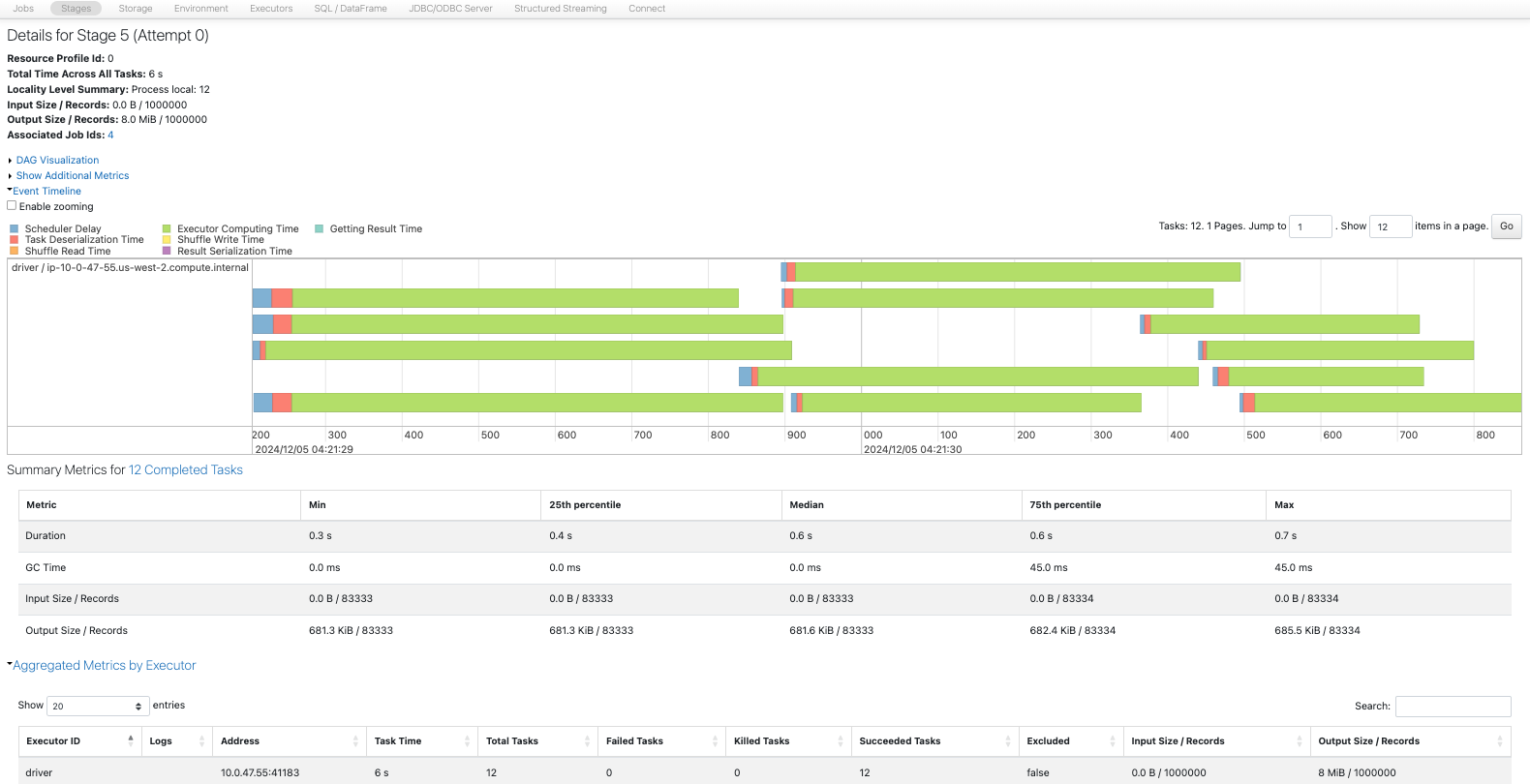

3. Coalesce と Repartition を使用してデータを保存する
- 注意: repartition はコストのかかる操作ですが、後続のプロセスに役立つ場合があります。
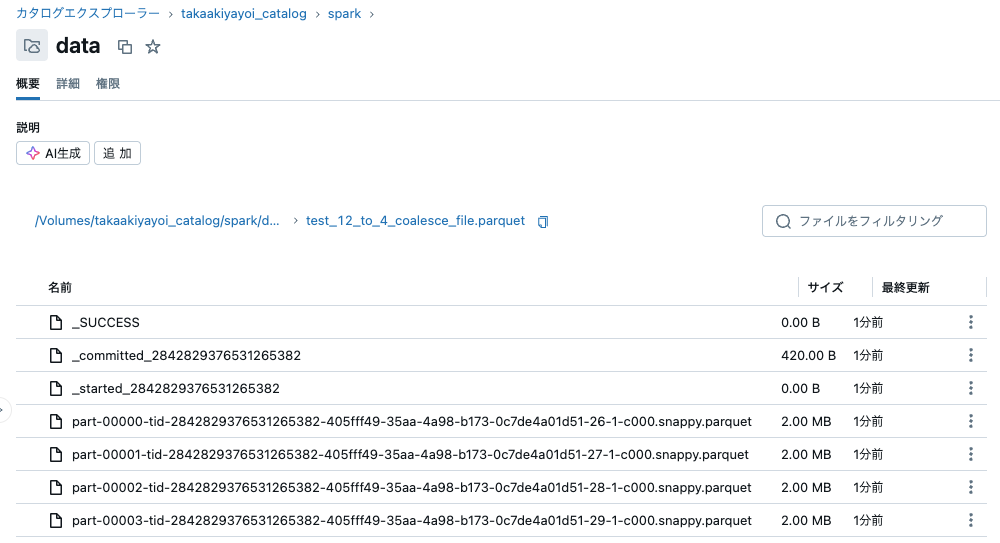
- 1つのパーティションに減らす場合、
repartition(1)はcoalesce(1)よりも優れていることがあります。すべてのコアが処理ステップに使用されるためです。
sdf = sdf_generator(num_rows, 12)
sdf = sdf.coalesce(4)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Write with Coalesce 12 to 4 file")
sdf.write.format("parquet").mode("overwrite").save(f"{base_dir}/test_12_to_4_coalesce_file.parquet")
sc.setJobDescription("None")
4
sdf = sdf_generator(num_rows, 12)
sdf = sdf.coalesce(1)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Write with Coalesce 12 to 1 file")
sdf.write.format("parquet").mode("overwrite").save(f"{base_dir}/test_12_to_1_coalesce_file.parquet")
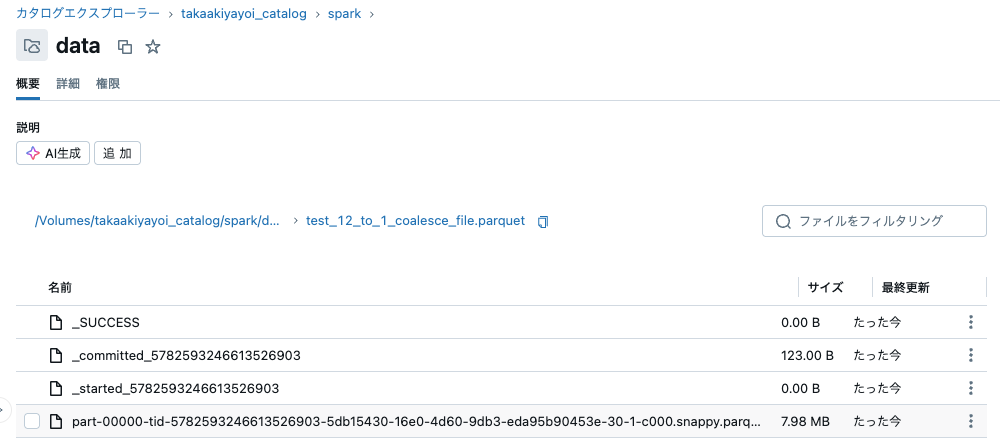
sc.setJobDescription("None")
1
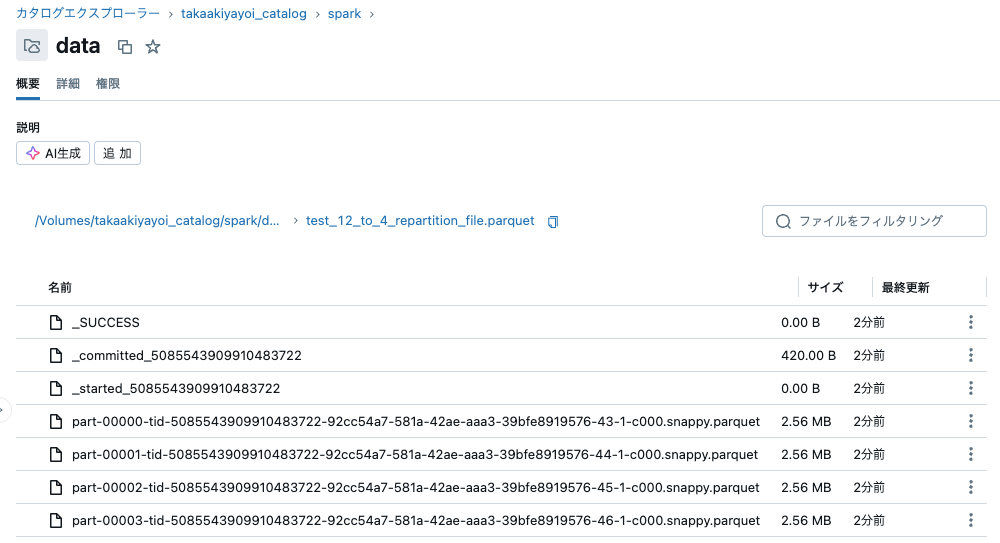
sdf = sdf_generator(num_rows, 12)
sdf = sdf.repartition(4)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Write with Repartition 12 to 4 file")
sdf.write.format("parquet").mode("overwrite").save(f"{base_dir}/test_12_to_4_repartition_file.parquet")
sc.setJobDescription("None")
4
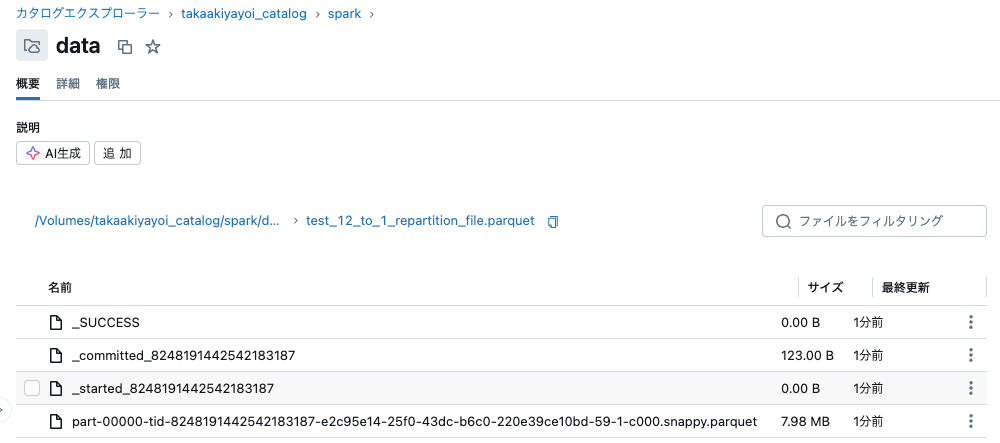
sdf = sdf_generator(num_rows, 12)
sdf = sdf.repartition(1)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Write with Repartition 12 to 1 file")
sdf.write.format("parquet").mode("overwrite").save(f"{base_dir}/test_12_to_1_repartition_file.parquet")
sc.setJobDescription("None")
1
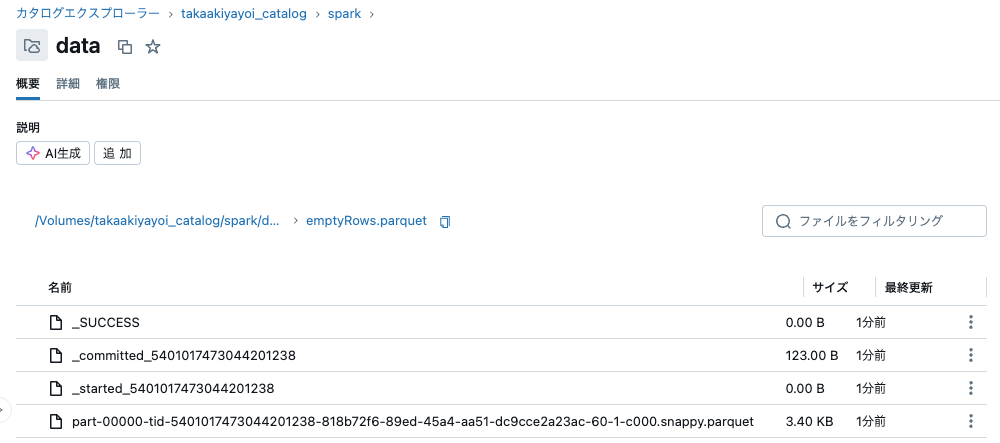
4. 書き込み時の空のパーティションの問題
- Sparkは、例えば、フィルタリング後に実際のレコード/データが含まれているパーティションのみを書き込むほどに十分スマートです。
sdf = sdf_generator(num_rows, 20)
sdf = sdf.filter(f.col("id") < 200)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Empty rows")
sdf.write.format("parquet").mode("overwrite").save(f"{base_dir}/emptyRows.parquet")
sc.setJobDescription("None")
20
rows_per_partition(sdf)
+------------+-----+----------+
|partition_id|count|count_perc|
+------------+-----+----------+
| 0| 200| 100.0|
+------------+-----+----------+
このデータフレームは20パーティションですが、レコードを含む1ファイルしか保存されていません。
5. idfirst列でのrepartition
以前と同様に、偏りのあるidfirstで、かつ少ない数でのrepartitionを行うと、同じパーティションに複数のidfirstのデータが含まれ、空のパーティションが生成されることになります。この場合は、データを持たない空のパーティションが保存されます。
sdf = sdf_generator(num_rows, 20)
sdf = sdf.repartition(10, "idfirst")
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("repartition 10 idfirst")
sdf.write.format("parquet").mode("overwrite").save(f"{base_dir}/repartition_10_idfirst.parquet")
sc.setJobDescription("None")
10
rows_per_partition(sdf)
+------------+------+----------+
|partition_id| count|count_perc|
+------------+------+----------+
| 3|111111| 11.1111|
| 4|111111| 11.1111|
| 5|111112| 11.1112|
| 6|222222| 22.2222|
| 8|111111| 11.1111|
| 9|333333| 33.3333|
+------------+------+----------+
上で表示されていないパーティションIDのファイルをカタログエクスプローラで特定し、以下で中身を表示してみます。
spark.read.parquet(f"/Volumes/takaakiyayoi_catalog/spark/data/repartition_10_idfirst.parquet/part-00000-tid-4034718789270274402-0129652f-22d3-43e1-a61a-2642b8aaf027-341-1-c000.snappy.parquet").show()
+---+----+---------+--------+-------+------+
| id|date|timestamp|idstring|idfirst|idlast|
+---+----+---------+--------+-------+------+
+---+----+---------+--------+-------+------+
パーティション数を変えて挙動を確認してみましょう。
sdf = sdf_generator(num_rows, 20)
sdf = sdf.repartition(8, "idfirst")
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("repartition 8 idfirst")
sdf.write.format("parquet").mode("overwrite").save(f"{base_dir}/repartition_8_idfirst.parquet")
sc.setJobDescription("None")
8
rows_per_partition(sdf)
+------------+------+----------+
|partition_id| count|count_perc|
+------------+------+----------+
| 0|111111| 11.1111|
| 1|111111| 11.1111|
| 2|222222| 22.2222|
| 3|333334| 33.3334|
| 5|111111| 11.1111|
| 6|111111| 11.1111|
+------------+------+----------+
こちらに続きます。