こちらの続きです。
こちらのノートブックを実行していきます。動画はこちら。
0. セットアップ
このノートブックの一般的なヒント:
- Spark UIはクラスター -> Spark UIでアクセス可能
- Spark UIの詳細な調査は後のエピソードで行います
-
sc.setJobDescription("Description")はSpark UIのアクションのジョブ説明を独自のものに置き換えます -
sdf.rdd.getNumPartitions()は現在のSpark DataFrameのパーティション数を返します -
sdf.write.format("noop").mode("overwrite").save()は、実際の書き込み中に副作用なしで変換を分析および開始するための良い方法です
クラスターは前回と同じ4コアのクラスターです。
from pyspark.sql import SparkSession
from pyspark.sql import functions as f
import pyspark
# AQEをオフにする。ここではジョブが増えると混乱する可能性があるため。
spark.conf.set("spark.sql.adaptive.enabled", "false")
# データフレームをキャッシュしないようにする。これにより、結果が再現可能でない場合がある。
spark.conf.set("spark.databricks.io.cache.enabled", "false")
行数とパーティション数を指定してSparkデータフレームを作成する関数。
def sdf_generator(num_rows: int, num_partitions: int = None) -> "DataFrame":
return (
spark.range(num_rows, numPartitions=num_partitions)
.withColumn("date", f.current_date())
.withColumn("timestamp",f.current_timestamp())
.withColumn("idstring", f.col("id").cast("string"))
.withColumn("idfirst", f.col("idstring").substr(0,1))
.withColumn("idlast", f.col("idstring").substr(-1,1))
)
sdf_gen = sdf_generator(20)
sdf_gen.count()
20
sdf_gen.show()
+---+----------+--------------------+--------+-------+------+
| id| date| timestamp|idstring|idfirst|idlast|
+---+----------+--------------------+--------+-------+------+
| 0|2024-12-03|2024-12-03 02:17:...| 0| 0| 0|
| 1|2024-12-03|2024-12-03 02:17:...| 1| 1| 1|
| 2|2024-12-03|2024-12-03 02:17:...| 2| 2| 2|
| 3|2024-12-03|2024-12-03 02:17:...| 3| 3| 3|
| 4|2024-12-03|2024-12-03 02:17:...| 4| 4| 4|
| 5|2024-12-03|2024-12-03 02:17:...| 5| 5| 5|
| 6|2024-12-03|2024-12-03 02:17:...| 6| 6| 6|
| 7|2024-12-03|2024-12-03 02:17:...| 7| 7| 7|
| 8|2024-12-03|2024-12-03 02:17:...| 8| 8| 8|
| 9|2024-12-03|2024-12-03 02:17:...| 9| 9| 9|
| 10|2024-12-03|2024-12-03 02:17:...| 10| 1| 0|
| 11|2024-12-03|2024-12-03 02:17:...| 11| 1| 1|
| 12|2024-12-03|2024-12-03 02:17:...| 12| 1| 2|
| 13|2024-12-03|2024-12-03 02:17:...| 13| 1| 3|
| 14|2024-12-03|2024-12-03 02:17:...| 14| 1| 4|
| 15|2024-12-03|2024-12-03 02:17:...| 15| 1| 5|
| 16|2024-12-03|2024-12-03 02:17:...| 16| 1| 6|
| 17|2024-12-03|2024-12-03 02:17:...| 17| 1| 7|
| 18|2024-12-03|2024-12-03 02:17:...| 18| 1| 8|
| 19|2024-12-03|2024-12-03 02:17:...| 19| 1| 9|
+---+----------+--------------------+--------+-------+------+
データフレームのパーティションの分布を表示する関数。
def rows_per_partition(sdf: "DataFrame", num_rows: int) -> None:
sdf_part = sdf.withColumn("partition_id", f.spark_partition_id())
sdf_part_count = sdf_part.groupBy("partition_id").count()
sdf_part_count = sdf_part_count.withColumn("count_perc", 100*f.col("count")/num_rows)
sdf_part_count.orderBy("partition_id").show()
rows_per_partition(sdf_gen, 20)
コア数と等しい数のパーティションが作成され、均等にデータが分配されていることがわかります。
+------------+-----+----------+
|partition_id|count|count_perc|
+------------+-----+----------+
| 0| 5| 25.0|
| 1| 5| 25.0|
| 2| 5| 25.0|
| 3| 5| 25.0|
+------------+-----+----------+
データフレームのパーティションと指定されたカラムのグループの分布を表示する関数。
def rows_per_partition_col(sdf: "DataFrame", num_rows: int, col: str) -> None:
sdf_part = sdf.withColumn("partition_id", f.spark_partition_id())
sdf_part_count = sdf_part.groupBy("partition_id", col).count()
sdf_part_count = sdf_part_count.withColumn("count_perc", 100*f.col("count")/num_rows)
sdf_part_count.orderBy("partition_id", col).show()
データフレームのidfirst列の値とパーティションの組み合わせのグループの分布を表示します。こちらは、後ほど列名を指定したrepartitionの挙動を確認する際に使用します。idfirstはid列の最初の一桁を格納しています。こちらを使うことで、データの偏りを擬似的に再現することができます。
rows_per_partition_col(sdf_gen, 20, "idfirst")
+------------+-------+-----+----------+
|partition_id|idfirst|count|count_perc|
+------------+-------+-----+----------+
| 0| 0| 1| 5.0|
| 0| 1| 1| 5.0|
| 0| 2| 1| 5.0|
| 0| 3| 1| 5.0|
| 0| 4| 1| 5.0|
| 1| 5| 1| 5.0|
| 1| 6| 1| 5.0|
| 1| 7| 1| 5.0|
| 1| 8| 1| 5.0|
| 1| 9| 1| 5.0|
| 2| 1| 5| 25.0|
| 3| 1| 5| 25.0|
+------------+-------+-----+----------+
1. パーティショニングの復習
最も重要なことは良い並列化を実現することです。
- これは、パーティションの数が利用可能なコアの数に依存するべきであることを意味します。Sparkの言葉で言うと、
spark.sparkContext.defaultParallelismです。推奨されるのは2-4倍の係数ですが、実際にはメモリとデータサイズに依存します。小さなデータサイズでは1倍の係数でも問題なく動作します。 - 良い並列化を実現するためには、均等に(理想的には一様に、最悪でも正規分布に)分布されたデータセットを持つことも重要です。データの偏りは、狭い変換でも1つのパーティションやタスクに依存することになり、全体の実行が遅くなる可能性があります。
パーティションサイズ
- パーティションサイズが非常に大きい場合(> 1GB)、OOM(メモリ不足)、ガベージコレクション(GC)やその他のエラーが発生する可能性があります。
- インターネット上の推奨事項では、100-1000 MBの範囲が良いとされています。例えば、Sparkは最大パーティションバイト数のパラメータを128 MBに設定しています。もちろん、これはマシンと利用可能なメモリに依存します。利用可能なメモリの限界を超えないように注意してください。
分散オーバーヘッド
- 以前の実験で見たように、パーティションの数が多すぎると、スケジューリングと分散のオーバーヘッドが増加します。
- 実行時間が全体のタスク時間の少なくとも90%を占めていない場合や、タスクが100 ms未満の場合、それは通常短すぎます。
こちらも参照してください: https://stackoverflow.com/questions/64600212/how-to-determine-the-partition-size-in-an-apache-spark-dataframe
2. リパーティショニングの仕組み
- ドキュメント: https://spark.apache.org/docs/latest/api/python/reference/pyspark.sql/api/pyspark.sql.DataFrame.repartition.html#pyspark.sql.DataFrame.repartition
- リパーティションはパーティションの数を増減させることができます
- リパーティションはデータのシャッフルを必要とするため、コアレスよりも非効率的になることがあります
- 一方で、コアレスがパーティションを単に結合するのに対し、リパーティションは均等な分布を作成します
- パーティションの数に基づいてパーティションを分割する代わりに、列に基づいてパーティションを分割することができます
- パーティションの数が定義されていない場合、デフォルト値は
spark.sql.shuffle.partitionsに依存し、これは200にデフォルト設定されています(後のエピソードでワイドな変換を評価する際に重要です)
num_rows = 20000
4つのパーティションから構成される2万行のデータフレームを作成します。
sdf1 = sdf_generator(num_rows, 4)
sdf1.rdd.getNumPartitions()
4
row_count = sdf1.count()
print(row_count)
20000
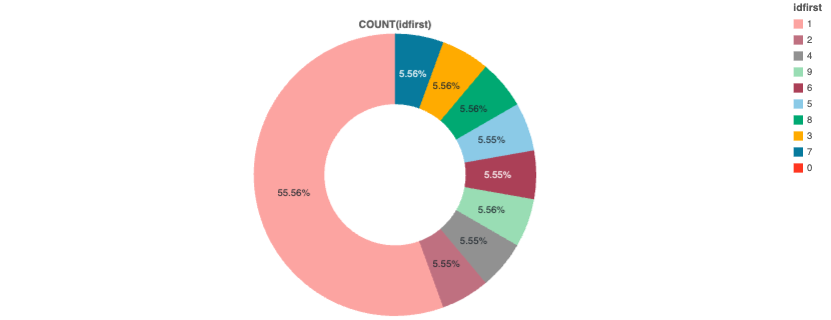
ここではidfirst列の分布を確認するために円グラフを作成しています。1の比率が多いということを覚えておいてください。
display(sdf1)
パーティションの分布を確認します。
rows_per_partition(sdf1, num_rows)
+------------+-----+----------+
|partition_id|count|count_perc|
+------------+-----+----------+
| 0| 5000| 25.0|
| 1| 5000| 25.0|
| 2| 5000| 25.0|
| 3| 5000| 25.0|
+------------+-----+----------+
idfirstとパーティションの関係性を確認します。
rows_per_partition_col(sdf1, num_rows, "idfirst")
+------------+-------+-----+----------+
|partition_id|idfirst|count|count_perc|
+------------+-------+-----+----------+
| 0| 0| 1| 0.005|
| 0| 1| 1111| 5.555|
| 0| 2| 1111| 5.555|
| 0| 3| 1111| 5.555|
| 0| 4| 1111| 5.555|
| 0| 5| 111| 0.555|
| 0| 6| 111| 0.555|
| 0| 7| 111| 0.555|
| 0| 8| 111| 0.555|
| 0| 9| 111| 0.555|
| 1| 5| 1000| 5.0|
| 1| 6| 1000| 5.0|
| 1| 7| 1000| 5.0|
| 1| 8| 1000| 5.0|
| 1| 9| 1000| 5.0|
| 2| 1| 5000| 25.0|
| 3| 1| 5000| 25.0|
+------------+-------+-----+----------+
ベースラインとなる4パーティションのデータフレーム作成のジョブを確認します。
sc.setJobDescription("Baseline 4 partitions")
sdf1.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
sdf1.rdd.getNumPartitions()
4
パーティション数3にリパーティションします。
sdf_3 = sdf1.repartition(3)
sdf_3.rdd.getNumPartitions()
3
coalecseとは異なり、repartitionではほぼ均等にパーティションにデータが分配されます。
rows_per_partition(sdf_3, num_rows)
+------------+-----+----------+
|partition_id|count|count_perc|
+------------+-----+----------+
| 0| 6667| 33.335|
| 1| 6667| 33.335|
| 2| 6666| 33.33|
+------------+-----+----------+
coalesceでは不可能であった、パーティション数の増加を行います。
sdf_12 = sdf1.repartition(12)
sdf_12.rdd.getNumPartitions()
12
こちらもほぼ均等にデータが分配されていることがわかります。
rows_per_partition(sdf_12, num_rows)
+------------+-----+----------+
|partition_id|count|count_perc|
+------------+-----+----------+
| 0| 1667| 8.335|
| 1| 1666| 8.33|
| 2| 1666| 8.33|
| 3| 1666| 8.33|
| 4| 1667| 8.335|
| 5| 1667| 8.335|
| 6| 1667| 8.335|
| 7| 1667| 8.335|
| 8| 1666| 8.33|
| 9| 1667| 8.335|
| 10| 1667| 8.335|
| 11| 1667| 8.335|
+------------+-----+----------+
ここまではパーティションの数を指定していましたが、今度は特定の列idfirstを指定してリパーティションします。リパーティションはシャッフルを伴う処理なので、この際のパーティション数はspark.sql.shuffle.partitionsに従います。
spark.conf.set("spark.sql.shuffle.partitions", 200)
sdf_col_200 = sdf1.repartition("idfirst")
sdf_col_200.rdd.getNumPartitions()
200
しかし、実際にデータを確認すると200個のパーティションは表示されません。これは、repartitionに指定されている列idfirstには10種類の値しかないためです。結果として、パーティション数は200ですが、空のパーティションが多く作成されています。
rows_per_partition(sdf_col_200, num_rows)
+------------+-----+----------+
|partition_id|count|count_perc|
+------------+-----+----------+
| 3| 1111| 5.555|
| 18| 1111| 5.555|
| 26| 1111| 5.555|
| 35| 1| 0.005|
| 49| 1111| 5.555|
| 75| 1111| 5.555|
| 139| 1111| 5.555|
| 144|11111| 55.555|
| 166| 1111| 5.555|
| 189| 1111| 5.555|
+------------+-----+----------+
idfirst列と突き合わせると、値が1の比率が高いので当該のパーティションにデータが多く分配され、0は1レコードしかないのにも関わらず1つのパーティションを占有していることがわかります。
rows_per_partition_col(sdf_col_200, num_rows, "idfirst")
+------------+-------+-----+----------+
|partition_id|idfirst|count|count_perc|
+------------+-------+-----+----------+
| 3| 7| 1111| 5.555|
| 18| 3| 1111| 5.555|
| 26| 8| 1111| 5.555|
| 35| 0| 1| 0.005|
| 49| 5| 1111| 5.555|
| 75| 6| 1111| 5.555|
| 139| 9| 1111| 5.555|
| 144| 1|11111| 55.555|
| 166| 4| 1111| 5.555|
| 189| 2| 1111| 5.555|
+------------+-------+-----+----------+
Shuffle Read Recordsの最大値は11111ですが、最小値は0になっています。
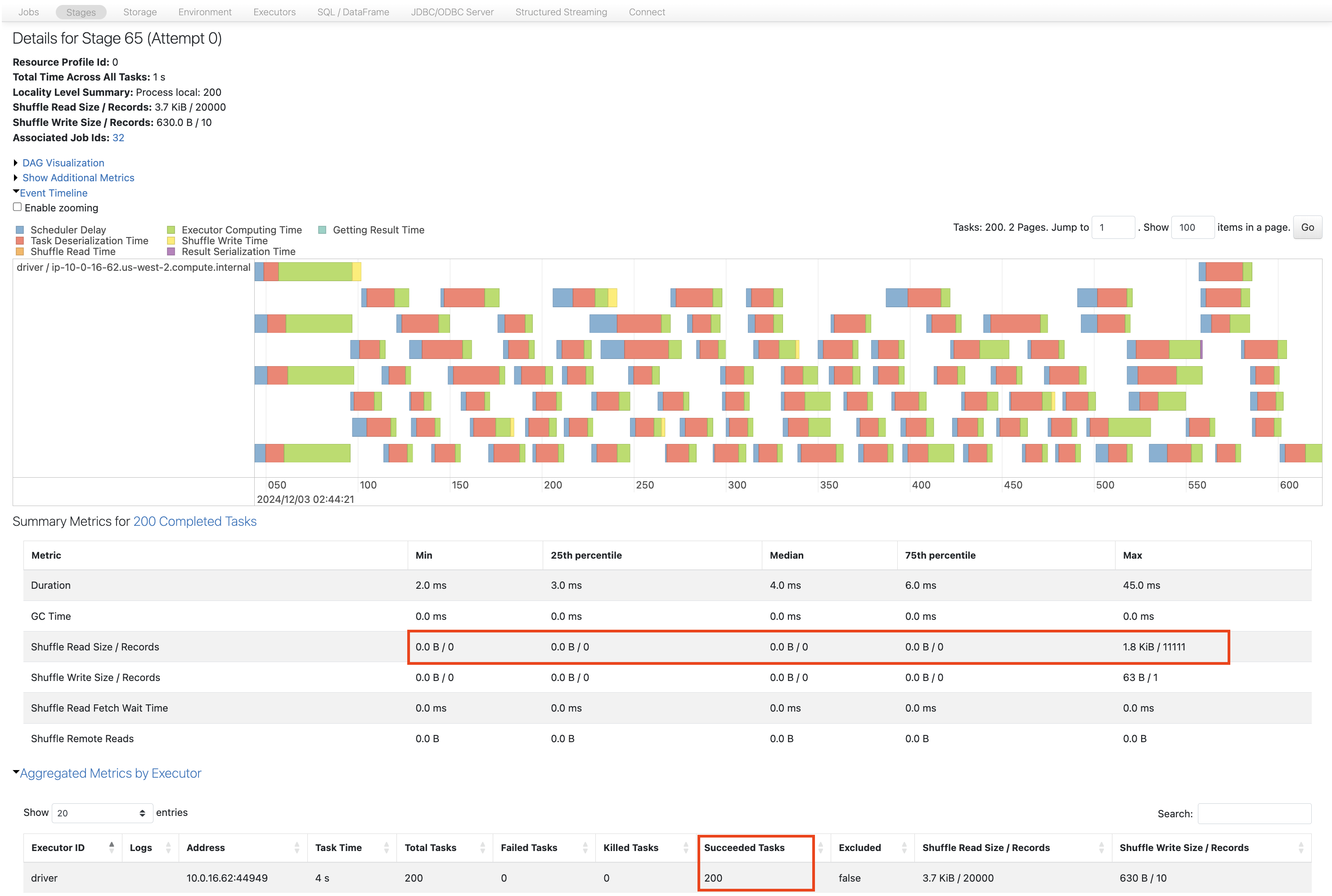
今度はspark.sql.shuffle.partitionsを20にします。以降では、idfirstごとのパーティションが作成されず、同一のパーティションに複数のidfirstが含まれてしまっています。これは、パーティションに分配する際にPartitionId=hash(key)%partitionCountでパーティションを決定しており、パーティション数が小さいとパーティションIDが重複する確率が増加するためです。このため、キーごとにパーティションが作成されるようにするには、十分な数のパーティションを準備する必要があります。詳細は以下の記事をご覧ください。
- Sparkにおけるパフォーマンスとパーティショニング戦略 #Spark - Qiita
- Spark repartitioning by column with dynamic number of partitions per column - Stack Overflow
spark.conf.set("spark.sql.shuffle.partitions", 20)
sdf_col_20 = sdf1.repartition("idfirst")
sdf_col_20.rdd.getNumPartitions()
20
rows_per_partition(sdf_col_20, num_rows)
+------------+-----+----------+
|partition_id|count|count_perc|
+------------+-----+----------+
| 3| 1111| 5.555|
| 4|11111| 55.555|
| 6| 2222| 11.11|
| 9| 2222| 11.11|
| 15| 1112| 5.56|
| 18| 1111| 5.555|
| 19| 1111| 5.555|
+------------+-----+----------+
rows_per_partition_col(sdf_col_20, num_rows, "idfirst")
+------------+-------+-----+----------+
|partition_id|idfirst|count|count_perc|
+------------+-------+-----+----------+
| 3| 7| 1111| 5.555|
| 4| 1|11111| 55.555|
| 6| 4| 1111| 5.555|
| 6| 8| 1111| 5.555|
| 9| 2| 1111| 5.555|
| 9| 5| 1111| 5.555|
| 15| 0| 1| 0.005|
| 15| 6| 1111| 5.555|
| 18| 3| 1111| 5.555|
| 19| 9| 1111| 5.555|
+------------+-------+-----+----------+
sdf_col_10 = sdf1.repartition(10, "idfirst")
sdf_col_10.rdd.getNumPartitions()
10
rows_per_partition(sdf_col_10, num_rows)
+------------+-----+----------+
|partition_id|count|count_perc|
+------------+-----+----------+
| 3| 1111| 5.555|
| 4|11111| 55.555|
| 5| 1112| 5.56|
| 6| 2222| 11.11|
| 8| 1111| 5.555|
| 9| 3333| 16.665|
+------------+-----+----------+
rows_per_partition_col(sdf_col_10, num_rows, "idfirst")
+------------+-------+-----+----------+
|partition_id|idfirst|count|count_perc|
+------------+-------+-----+----------+
| 3| 7| 1111| 5.555|
| 4| 1|11111| 55.555|
| 5| 0| 1| 0.005|
| 5| 6| 1111| 5.555|
| 6| 4| 1111| 5.555|
| 6| 8| 1111| 5.555|
| 8| 3| 1111| 5.555|
| 9| 2| 1111| 5.555|
| 9| 5| 1111| 5.555|
| 9| 9| 1111| 5.555|
+------------+-------+-----+----------+
sdf_col_5 = sdf1.repartition(5, "idfirst")
sdf_col_5.rdd.getNumPartitions()
5
rows_per_partition(sdf_col_5, num_rows)
+------------+-----+----------+
|partition_id|count|count_perc|
+------------+-----+----------+
| 0| 1112| 5.56|
| 1| 2222| 11.11|
| 3| 2222| 11.11|
| 4|14444| 72.22|
+------------+-----+----------+
rows_per_partition_col(sdf_col_5, num_rows, "idfirst")
+------------+-------+-----+----------+
|partition_id|idfirst|count|count_perc|
+------------+-------+-----+----------+
| 0| 0| 1| 0.005|
| 0| 6| 1111| 5.555|
| 1| 4| 1111| 5.555|
| 1| 8| 1111| 5.555|
| 3| 3| 1111| 5.555|
| 3| 7| 1111| 5.555|
| 4| 1|11111| 55.555|
| 4| 2| 1111| 5.555|
| 4| 5| 1111| 5.555|
| 4| 9| 1111| 5.555|
+------------+-------+-----+----------+
様々なrepartitionのSparkジョブをSpark UIで確認します。
sc.setJobDescription("Repartition from 4 to 3")
sdf_3.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
sc.setJobDescription("Repartition from 4 to 12")
sdf_12.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
sc.setJobDescription("Repartition from 4 to 5 with col")
sdf_col_5.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
3. リパーティション(および部分的にコアレス)を使用するタイミング
- 前述のように、コアの数に依存してデータを別の数のパーティションに再バランスしたい場合。例えば、最初に7つのパーティションがあり、4つのコアがある場合、8に増やす(詳細は次で)
- データの偏りがあり、一部のパーティション/タスクが他よりも長く実行される場合。これはjoinや他のワイドな変換にも影響を与える可能性があります。リパーティションはこれを処理します。(詳細は次で)
- join操作は事前にデータをリパーティションすることで利益を得ることができます。リパーティションはjoin中のデータのシャッフルを減らします。しかし、カラムキーに基づく他のシャッフル操作も同様です(後のエピソードで学びます)
- フィルター操作がより効率的になります。(詳細は次で)
- 大きなフィルター操作は多くの空のパーティションを引き起こす可能性があります。例えば、1000万行と1000のパーティションがあり、フィルター後に10行が残る場合。これは、次の操作(例えばカウント)にとって突然のオーバーヘッドになります。(詳細は次で)
- 書き込みを最適化または影響を与える。後で学ぶように、書き込みはパーティションの数に依存します。パーティションの数が多いと書き込みが非最適になります。例えば、パーケットでのファイル作成は書き込み直前のパーティション数にも依存します。(後のエピソードで学びます)
こちらも参照してください:
4. 参考文献
- CoalesceとRepartitionの速度に関する興味深い議論: https://stackoverflow.com/questions/31610971/spark-repartition-vs-coalesce
- リパーティションを使用するタイミング: https://medium.com/@zaiderikat/apache-spark-repartitioning-101-f2b37e7d8301
- パーティション数を決定するための要因: https://stackoverflow.com/questions/64600212/how-to-determine-the-partition-size-in-an-apache-spark-dataframe
次回は、いくつかのシナリオを通じてrepartitionとcoalesceの使い所を学びます。
こちらに続きます。