On Spark Performance and partitioning strategies | by Laurent Leturgez | datalex | Mediumの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
2020年9月の記事です。
特にデータエンジニアリングのタスクでSparkを取り扱っている際、Sparkのベストな性能を得るためにはパーティショニングに対応しなくてはなりません。
優れたパーティショニング戦略は、データとその構造、クラスターの設定を理解しています。
悪いパーティショニングは主に3つの領域でのパフォーマンス悪化につながります。
- お使いのクラスターサイズに対して多すぎるパーティション、この場合効率的にクラスターを使用できません。例えば、多すぎるタスクスケジューリングを引き起こします。
- お使いのクラスターサイズに対して十分でないパーティション、この場合メモリーとCPUの問題に対応しなくてはなりません。お使いのエグゼキューターがメモリーに大ボリュームのデータを配置する(おそらくOut Of Memory例外を引き起こすでしょう)ことによるメモリーの問題、クラスターにおける計算量が不均等になることによるCPUの問題、CPUのサブセットは処理を行いますが、他のCPUはそれらを眺めているだけとなります。
- パーティションにおけるデータの偏り。これらのパーティションに対してSparkタスクが実行される際、タスクがエグゼキューターのスロットとCPUに分配されます。データボリュームの観点でパーティションのバランスが取れていないと、いくつかのタスクは他のタスクよりも長い時間を要し、タスク全体の実行時間がスローダウンすることになります(そして、あるノードは他のノードよりも多くのCPU利用を必要とします)。
優れたパーティショニングをするためには、パーティションとは何かと内部ではどのように動作するのかを理解する必要があります。
Sparkのパーティショニングとは?
パーティショニングとは、データ構造をパーツに分割する以外の何者でもありません。Apache Sparkのような分散システムにおいては、クラスターにまたがって複数のパーツとして格納される分割データセットとして定義されます。
Sparkでは3つのデータ構造を使用します:RDD(Resilient Distributed Datasets)、データフレーム、データセットです。この構造のそれぞれがインメモリの構造となっており、データの塊(chunk)に分割することができ、それぞれの塊は物理的なノード(エグゼキューター)に配置されます。

このスキーマに拡張し、1000万行のRDDあるいはデータフレームを考えた際、4つのエグゼキューターに対する60のパーティションに分割(エグゼキューターあたり15パーティション)することができます。エグゼキューターあたり16個のCPUコアがあれば、個々のタスクが1つのパーティションを処理します。
上で見たように、優れたパーティションニングはパーティションの数と、データがパーティションにどのように分散されるのかによります。
パーティションの数
パーティションの数は様々なパラメーターに基づいて計算されます。
-
spark.default.parallelism(使用するクラスターマネージャに基づく値、詳細はhttps://spark.apache.org/docs/latest/configuration.html#execution-behavior をご覧ください) -
(同じディレクトリに存在する場合)読み込むファイルの数
-
SparkContext.textfileからテキストファイルを読み込む場合、パーティションの数は数式min(2, spark.default.parallelism)から計算されます
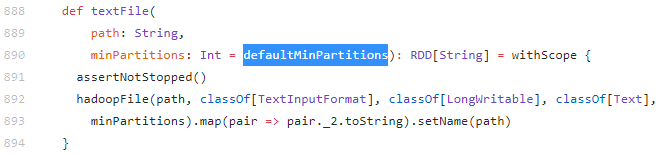
https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/SparkContext.scala
https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/SparkContext.scala
どのようにデータがパーティションに分配されるのか?
パーティションにどのように分配されるのかは、パーティショナーを呼び出すオブジェクトに依存します。
Apache Sparkでは2つの主要なパーティショナーが存在します。
- HashPartitionerは全てのパーティションに対して均等にデータを分配します。特定のパーティションキー(データフレームの場合はカラム)を指定しない場合、データはキーと紐づけられます。これによって(K,V)のペアと以下のアルゴリズムによって割り当てられる対象のパーティションが生成されます。
partitionId = hash(Key) % NumberOfPartition
HashPartitionerはSparkにおけるデフォルトのパーティショナーです。
注意
hash関数は使用するAPI言語に依存して変化します。
pythonに関してはportable_hash()関数をご覧ください。
https://github.com/apache/spark/blob/master/python/pyspark/rdd.py
scalaに関しては以下をご覧ください。
https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/Partitioner.scala
- RangePartitionerは特定のレンジに基づいてパーティションにデータを分散させます。RangePartitionerはパーティションキーとして用いられる(データフレームの)カラムを使用します。このキーは(性能問題に対応するために)サンプリングされ、値の数とターゲットのパーティション数に基づいて、このキーを用いてデータが分散されます。
これら2つのパーティショナーがあなたの目的に合わない場合には、自身でパーティショナーを作成することができます。
データフレームのケース
データフレームを取り扱っている場合、これらは(Dataframe.repartition()を呼び出すことで)明示的あるいは(データフレームのシャッフルの間に)暗黙的に再パーティションされます。
パーティション数を指定せずにDataframe.repartition()を呼び出した場合、あるいはシャッフルの際には、SparkがX個のパーティションを持つ新たなデータフレームを生成することを理解する必要があります(Xはデフォルト200のspark.sql.shuffle.partitionsパラメーターの値となります)。
これによって、大量の空のパーティションを持つデータフレームを生み出すことがあり、特に小規模のデータ(あるいは十分に大きくないデータ!)を取り扱っている場合にはスケジューリングの問題を引き起こすことがあります。
サンプルが必要ですか?
上の段落の補足をするために、以下に基づいてPythonのサンプルを書きました。
- データフレームを作成し、最初のカラムを用いてxのパーティションに再パーティショニングする関数
import random as rand
import pandas as pd
def newDf(data,values_cnt=50,partition_cnt=4):
src=[]
if (isinstance(data,list)):
raise ValueError(f"data type must be a list : {type(data)} ")
for i in range(values_cnt):
src.append([data[int(rand.triangular(0,len(data),mode=len(data)))], rand.randrange(0,1000)])
return spark.createDataFrame(src, schema=("col1 string, col2 integer")).repartition(partition_cnt,"col1")
- パラメーターとして渡されたデータフレームの詳細なアウトプットを表示する2つの関数
関数#1
import pandas as pd
def df_details(df):
df.explain()
part_num=0
row_num=0
print(f"#Partitions = {len(df.rdd.glom().collect())}")
for p in df.rdd.glom().collect():
print(f"P{part_num}")
for rowInPart in p:
print(f" Row {row_num}:{rowInPart}")
row_num=row_num+1
part_num=part_num+1
この最初の関数は以下のようなアウトプットを表示します。
names=('aaaaaaaaaa','bbbbbbbbbb',
'cccccccccc','dddddddddd',
'eeeeeeeeee','ffffffffff',
'ggggggggggg','hhhhhhhhhh')
nb_of_values=10
nb_part=4
df=newDf(data=names,
values_cnt=nb_of_values,
partition_cnt=nb_part)
df_details(df)

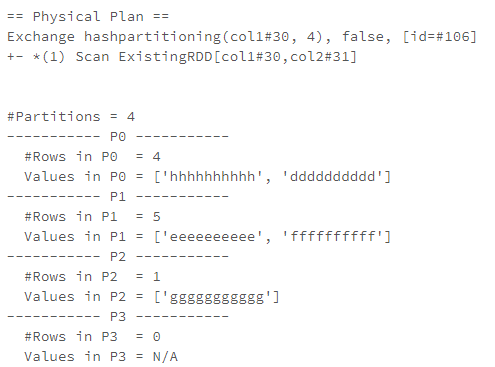
こちらから以下のことがわかります。
- 生成された物理的実行プラン。これは、
repartitionでhashPartitioningが使われることを示しています。 - データフレームのパーティションの数と、それぞれのパーティションの中身。
Hashパーティショニングを用いたとしても、(特にパーティションの数があまり多くない場合)必ずしもデータが均等に分散されないことに我々は既に気づいています。
関数#2
import pandas as pd
def df_details_2(df):
df.explain()
part_num=0
print(f"#Partitions = {len(df.rdd.glom().collect())}")
for p in df.rdd.glom().collect():
row_num=0
values=[]
print(f"----------- P{part_num} -----------")
for rowInPart in p:
if(rowInPart[0] not in values):
values.append(rowInPart[0])
row_num=row_num+1
print(f" #Rows in P{part_num} = {row_num}")
print(f" Values in P{part_num} = {values if values else 'N/A'}")
part_num=part_num+1
前の関数と同じように、この関数は再パーティションの物理的プラント、以下のパーティションごとの詳細情報を表示します。
- パーティションごとの行数
- パーティションにおける一意の値
これは、以下のような結果を表示します。
names=('aaaaaaaaaa','bbbbbbbbbb',
'cccccccccc','dddddddddd',
'eeeeeeeeee','ffffffffff',
'ggggggggggg','hhhhhhhhhh')
nb_of_values=10
nb_part=4
df=newDf(data=names,
values_cnt=nb_of_values,
partition_cnt=nb_part)
df_details_2(df)
なぜ私のデータは均等に分配されないのでしょうか?
基本的な例を見ていきましょう。以前のコードでは、namesリストに含まれる1,000,000の値で処理を実行し、これを8個のパーティションに再パーティショニングしました(私のデフォルトのparallelismは8に設定されています)。
names=('aaaaaaaaaa','bbbbbbbbbb',
'cccccccccc','dddddddddd',
'eeeeeeeeee','ffffffffff',
'ggggggggggg','hhhhhhhhhh')
nb_of_values=1000000
nb_part=8
print(f"default parallelism = {sc.defaultParallelism}")
df=newDf(data=names,
values_cnt=nb_of_values,
partition_cnt=nb_part)
df_details_2(df)
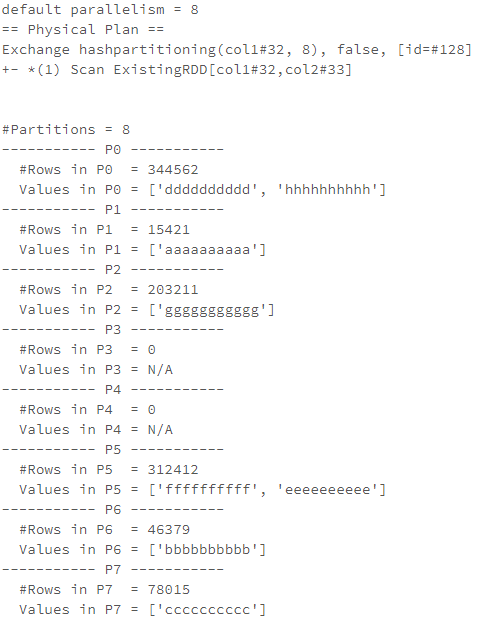
パーティションあたり単一の値が表示されず、不均等な分散になっているのはおかしなことです(データの分布にもよりますが!)。
原因はhash関数の数式(PartitionId=hash(key)%partitionCount)とパーティションの数が小さすぎることです。
パーティションごとに値を持ちたいのであれば、通常はパーティションの数を増やさなくてはなりません。しかし、私のサンプルでは、同じパーティションに2つの値を持つパーティションが存在し続けています(私は200パーティションまでテストしました)。
素敵なプロットを表示するように、データをpandasデータフレームに配置するように、この関数のソースコードを拡張しました。
import pandas as pd
def df_details_pd(df):
part_num=0
#If there is too much data, a sample can help
#parts=df.rdd.glom().sample(withReplacement=False, fraction=0.1).collect()
parts=df.rdd.glom().collect()
partCount=len(parts)
res=pd.DataFrame(data=None, index=None, columns=('value','cnt'))
for p in parts:
row_num=0
values=[]
for rowInPart in p:
if(rowInPart[0] not in values):
values.append(rowInPart[0])
row_num=row_num+1
s="Part#: {}\n Values: \n {}".format(part_num, (",\n".join(values) if values else "N/A" ))
res=res.append(pd.DataFrame([[s,row_num]], columns=('value','cnt')),ignore_index=True)
part_num=part_num+1
return res
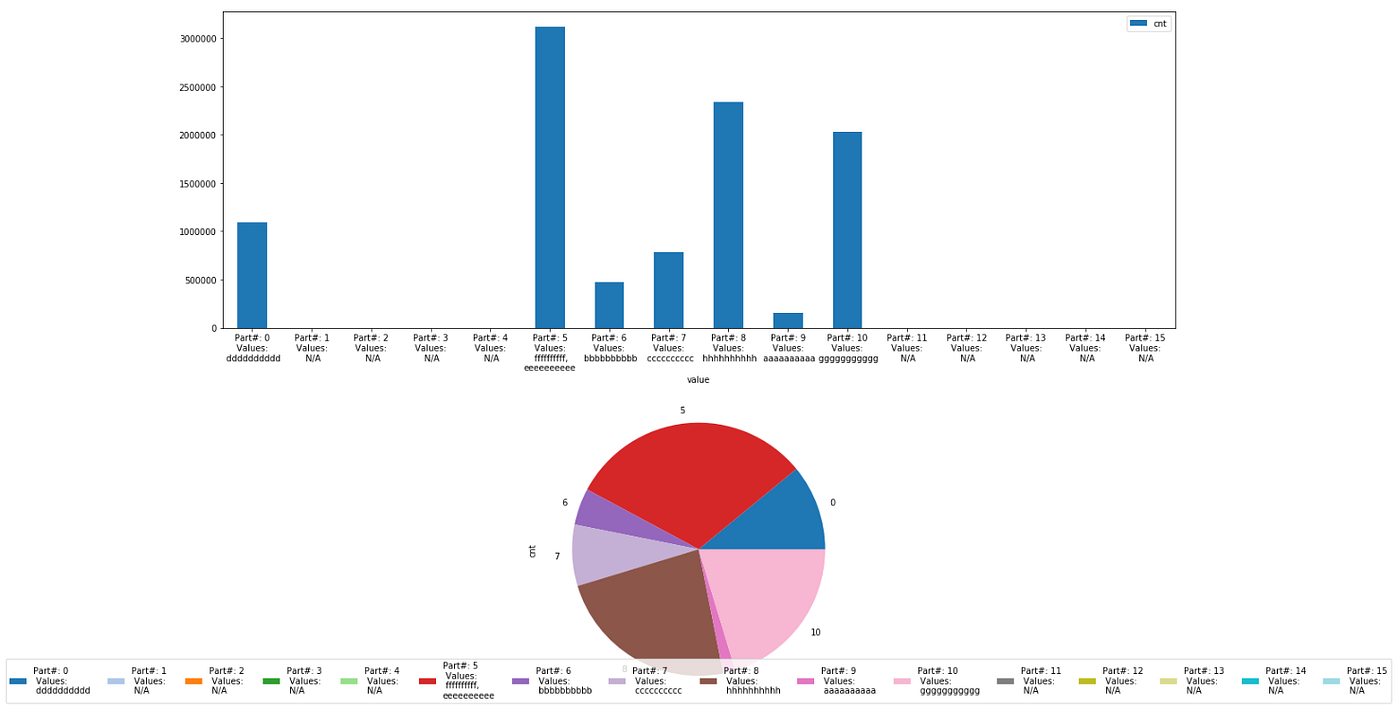
そして、matplotlibを用いてプロットを生成します。
from matplotlib import pyplot as plt
from matplotlib import cm
names=('aaaaaaaaaa','bbbbbbbbbb',
'cccccccccc','dddddddddd',
'eeeeeeeeee','ffffffffff',
'ggggggggggg','hhhhhhhhhh')
nb_of_values=10000000
nb_part=16
df=newDf(data=names,
values_cnt=nb_of_values,
partition_cnt=nb_part)
pddf_res=df_details_pd(df)
cmap = cm.get_cmap('tab20')
fig,ax=plt.subplots(2,1,figsize=(20,30))
pddf_res.plot(kind='bar',x='value', rot=0, figsize=(20,15), ax=ax[0])
pddf_res.plot(kind='pie', y='cnt', ax=ax[1], colormap=cmap)
ax[1].legend( pddf_res.value, loc='lower center', ncol=len(pddf_res.value))
このため、均等な分布を目指す場合には、自分のハッシュ関数を用いる、あるいは、パーティションあたり1つのキーのみを保持したいのであれば自分の関数を用いた方が良いです。しかし、pythonで作業している場合には、rddインタフェースを操作し、ご自身の関数を変更したデータフレームにマッピングしなくてはなりません。
自分のパーティショニング関数を指定する
自分のパーティショニング関数を指定したいのであれば、以下のことを行う必要があります。
- パラメーターとしてキーを受け取り、このキーに対応するユニークなIDを返却する関数の記述
- Spark API言語としてPythonを使用している場合にはRDD APIの操作
キーを特定のパーティションに割り当てるサンプルコードはこちらとなります(これは変なデータ分布となりますが、この特定のキーに基づいてパイティションをフィルタリングすることは興味深いことです)。初期のデータ構造をK,Vペアに変換する必要があることに注意してください。
from matplotlib import pyplot as plt
from matplotlib import cm
import pandas as pd
names=('aaaaaaaaaa','bbbbbbbbbb',
'cccccccccc','dddddddddd',
'eeeeeeeeee','ffffffffff',
'ggggggggggg','hhhhhhhhhh')
nb_of_values=100
nb_part=8
df=newDf(data=names,
values_cnt=nb_of_values,
partition_cnt=nb_part)
def myPartitionFunction(k):
return names.index(k)
df_mod=df.rdd.map(lambda x: (x[0], x)).partitionBy(nb_part,myPartitionFunction).toDF()
pddf_res=df_details_pd(df_mod)
if __name__=="__main__":
cmap = cm.get_cmap('tab20')
fig,ax=plt.subplots(2,1,figsize=(20,30))
pddf_res.plot(kind='bar',x='value', rot=0, figsize=(20,15), ax=ax[0])
pddf_res.plot(kind='pie', y='cnt', ax=ax[1], colormap=cmap)
ax[1].legend( pddf_res.value, loc='lower center', ncol=len(pddf_res.value))
これによって、上の内容を証明する以下のプロットを生成します。
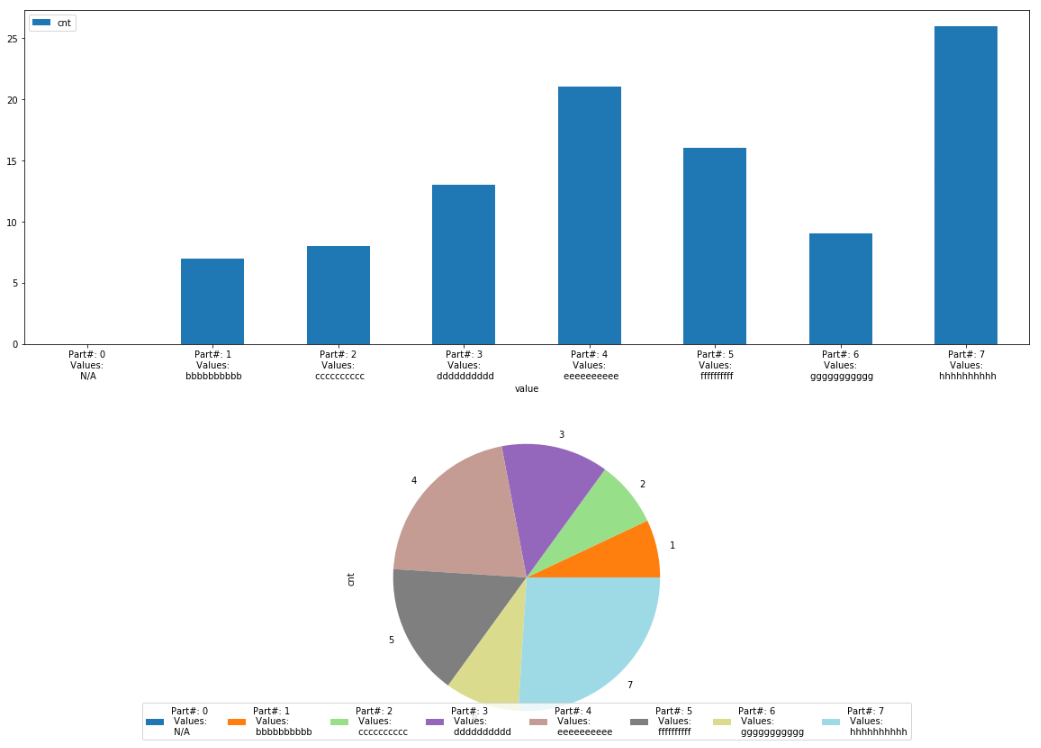
データフレームのケース
以前の章では、パーティションの数を指定しない明示的な再パーティショニング、シャッフルにおける再パーティショニングは、デフォルト200のspark.sql.shuffle.partitionsの数のパーティションを生み出すことを説明しました。
こちらがサンプルとなります。
names=('aaaaaaaaaa','bbbbbbbbbb',
'cccccccccc','dddddddddd',
'eeeeeeeeee','ffffffffff',
'ggggggggggg','hhhhhhhhhh')
nb_of_values=100
nb_part=4
print(f"default parallelism = {sc.defaultParallelism}")
df=newDf(data=names,values_cnt=nb_of_values,partition_cnt=nb_part)
print(f"BEFORE REPARTITION : Number of partitions={len(df.rdd.glom().collect())}")
df=df.repartition("col1")
print(f"AFTER REPARTITION #1: Number of partitions={len(df.rdd.glom().collect())}")
spark.conf.set("spark.sql.shuffle.partitions",8)
df=df.repartition("col1")
print(f"AFTER REPARTITION #2: Number of partitions={len(df.rdd.glom().collect())}")
df=df.repartition(4,"col1")
print(f"AFTER REPARTITION #3: Number of partitions={len(df.rdd.glom().collect())}")
以下のようなアウトプットとなります。

静的なパーティション数(デフォルト200)を避けるベストなソリューションは、Spark 3.0の新機能であるAdaptive Query Execution (AQE)を有効化することです。
この機能を用いることで、シャッフルパーティションのデフォルトの数を不適切な数(デフォルト200のspark.sql.shuffle.partitions)に指定する静的なパラメーターが定義されていたとしても、Sparkは動的にシャッフルのパーティションを強制します。
今日はこれで全てです!
この記事で説明されているサンプルはgithubからアクセスできます。