How to Scale SHAP Calculations With PySpark and Pandas UDF - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
モチベーション
意思決定における機械学習(ML)アプリケーション、特にディープラーニング(DL)モデルの急激な増加に伴い、そのようなモデルに基づいたキーとなるビジネス意思決定の正当性を評価し、ブラックボックスの中を精査することがより重要になっています。例えば、特定の顧客に対するピアツーピアの融資において、MLモデルがクレジットリスクを算定する、あるいはローンの申請を却下するケースにおいて、モデルの導入を促進するためには、このモデルがなぜこのような意思決定を行なったのかをビジネスステークホルダーに対して説明することは重要な手段となり得るでしょう。多くの場合、MLの解釈はビジネス用件のみではなく、なぜ顧客に対して特定の決定、あるいは選択がなされたのかを理解するための規制的な要件にもなります。SHapley Additive exPlanations(SHAP)は説明可能なAIに対して活用できる重要なツールであり、MLモデルやニューラルネットワークがビジネス課題を解決するためにもたらす結果の信頼性を確立するのに役立ちます。
SHAPは、Game Theoryに基づいたモデル説明のための最先端のフレームワークです。このアプローチには、お使いのデータセットのデータポイントに対する、モデルの特徴量とモデルの出力の線形的な関係性の発見が含まれています。このフレームワークを用いることで、あなたはモデルの出力を局所的あるいは大極的に解釈することができます。大極的な解釈は、それぞれの特徴量がどれだけ出力に対してポジティブ、あるいはネガティブに寄与しているのかの理解に役立ちます。一方、局所的な解釈は、特定の観測結果におけるそれぞれの特徴量の影響度を理解するのに役立ちます。
データサイエンスコミュニティで広く受け入れられている最も一般的なSHAP実装は、シングルノードマシンで実行されており、これは利用できるコア数に関係なく、全ての計算が単体のコアで実行されることを意味しています。このため、分散処理能力を活用することができず、単一コアの制限に束縛されることになります。
この記事では、特に局所的解釈を対象として、複数マシンでのSHAP値の計算の並列化のためのシンプルな方法をデモンストレーションします。次に、データセットの行、列の数の増加に伴って、このソリューションがどのようにスケールするのかを説明します。最後に、Sparkを用いてSHAPの計算を並列化する際に何がうまくいくのか、何を避けるべきなのかといった我々の知見をハイライトします。
シングルノードにおけるSHAP
説明可能性を理解するために、SHAPはモデルをExplainerに変換します。これにより、個々のモデルの予測はExplainerを適用することで説明されることになります。Pythonの有名なものを含み、異なるプログラミング言語におけるいくつかのSHAP値計算の実装が存在しています。この実装においては、それぞれの観測結果に対する説明を取得するために、お使いのモデルに適したExplainerを適用することができます。以下のコードスニペットは、どのようにRandom Forest Classifierに対してTreeExplainerを適用するのかを示しています。
import shap
explainer = shap.TreeExplainer(clf)
shap_values = explainer.shap_values(df)
この方法は小さなデータボリュームではうまく動作しますが、実装がシングルノードをベースとしているため、MLモデルの出力が数百万レコードになるとうまくスケールしません。例えば、以下の図1のグラフでは、シングルノードマシン(4コア、メモリー30.5GB)において、レコード数の増加に伴うSHAP値計算時間の増加を示しています。1Mの行、50カラムよりもデータが大きくなるとマシンはアウトオブメモリーとなってしまったため、これらの値は図に含まれていません。見てわかるように、実行時間はレコード数に対して概ね線形で増加しており、これは実世界シナリオでの活用には適していません。例えば、機械学習モデルがなぜモデルの予測を行なったのかを理解するのに10時間待たなくてはいけないとしたら、非効率的であり多くのビジネス環境で受け入れられるものではありません。
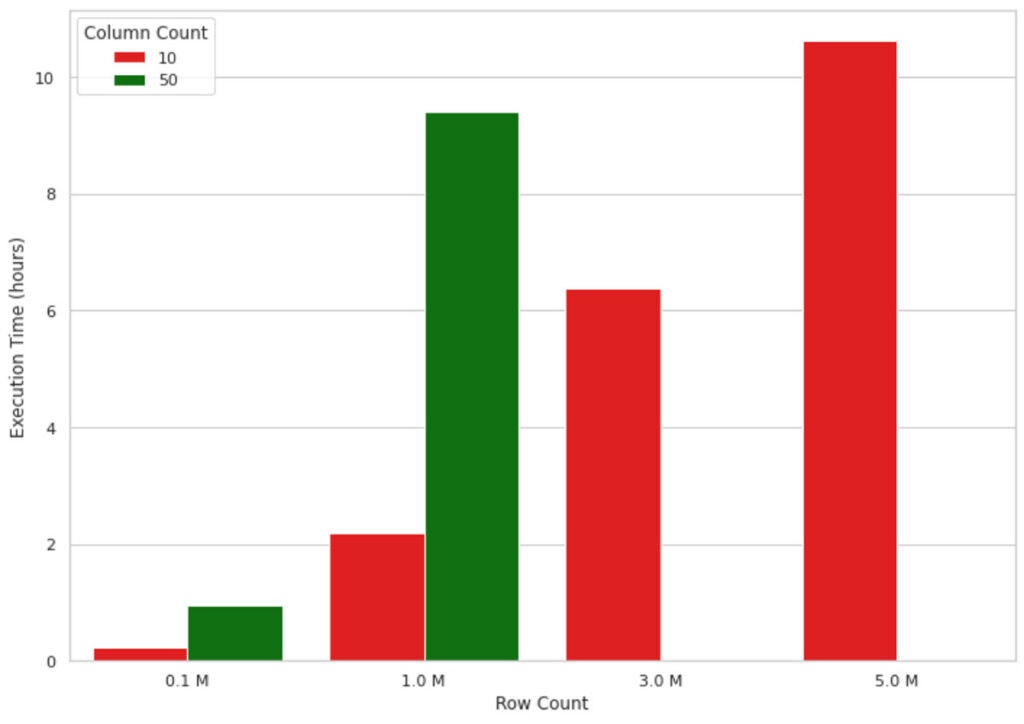
図1: シングルノードにおけるSHAP計算の実行時間
この問題を解決できる可能性がある方法の一つに近似計算を行うというものがあります。shap_valuesメソッドの引数のapproximateをTrueに設定することができます。こうすることで、ツリーの下位のスプリットが高い重みを持つことになりますが、特定の計算とSHAP値の一貫性は保証されません。これは計算速度を改善しますが、モデル出力に対する不正確な説明に直面することになるかもしれません。さらに、引数approximateはTreeExplainersでしか使用できません。
別のアプローチは、複数コアでExplainerアプリケーションを並列化するために、Apache Spark™のような分散処理フレームワークを活用するというものになるでしょう。
PySparkを用いてSHAP計算をスケールさせる
SHAP計算を分散するために、このPython実装とPySparkのPandas UDF(ユーザー定義関数)を活用しています。また、ここではkddcup99データセットを用いてネットワーク侵入検知を実現する予測モデルを構築します。この予測モデルは侵入、攻撃と呼ばれる悪性な接続と、通常の接続を区別します。このデータセットは侵入検知の目的のために用いるには欠陥があるものとして知られています。しかし、この記事では、背後のMLモデルのセマンティクスではなく、SHAP値の計算にフォーカスしています。
この実験で我々が構築する2つのモデルは、異なるカラムサイズに対するソリューションのスケーラビリティを示すために、10の特徴量、50の特徴量のデータセットに対してトレーニングしたシンプルなRandom Forestの分類器となります。オリジナルのデータセットは50カラム以下であったため、必要なデータボリュームにするために幾つかのカラムを複製していることに注意してください。実験に用いたデータのボリュームは4Mから1.85GBとなっています。
コードの詳細に入る前に、SparkデータフレームとUDFがどのように動作するのかを簡単に説明させてください。Sparkデータフレームは(行ごとに)クラスターに分散され、それぞれの行のグループはパーティションと呼ばれ、それぞれのパーティションは(デフォルトでは)1コアで処理されます。これが、Sparkが並列処理を実現する基本動作となります。pandasを容易にSHAPに入力することができ、高性能であるためPandas UDFは自然な選択肢となります。vectorized UDFとも呼ばれることがあるpandas UDFは、データ転送を最適化するためにApache Arrowを用いることで、Python UDFよりも優れた性能を提供します。
以下のコードスニペットでは、PySparkでPandas UDFを用いて、どのようにExplainerを並列に適用するのかをデモンストレーションしています。calculate_shapというpandas UDFを定義し、この関数をmapInPandasに引き渡しています。このメソッドはPySparkデータフレームに並列化されたメソッドを適用するために使用されます。
def calculate_shap(iterator: Iterator[pd.DataFrame]) -> Iterator[pd.DataFrame]:
for X in iterator:
yield pd.DataFrame(
explainer.shap_values(np.array(X), check_additivity=False)[0],
columns=columns_for_shap_calculation,
)
return_schema = StructType()
for feature in columns_for_shap_calculation:
return_schema = return_schema.add(StructField(feature, FloatType()))
shap_values = df.mapInPandas(calculate_shap, schema=return_schema)
図2では、1Mの行と10カラムのデータに対して、シングルノードマシンと2、4、6、8、16、32のサイズのクラスターの実行時間を比較しています。全てのクラスターで使用しているマシンは同じもの(4コア、メモリー30.5GB)です。興味深い点として、並列化されたコードはクラスターのノードの全てのコアを活用しているというものがあります。このため、サイズ2のクラスターを使ったとしても、約5倍の性能改善が認められています。
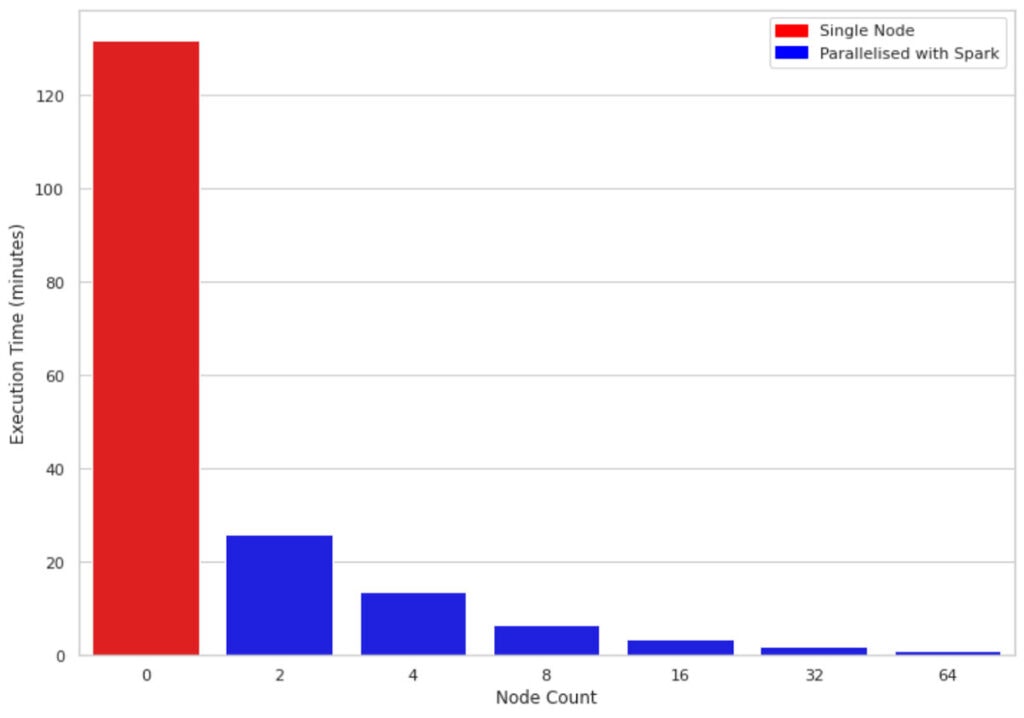
図2: シングルノードと並列処理におけるSHAP計算実行時間(1M行、10カラム)
増加するデータサイズに合わせてスケールさせる
SHAP実装の都合上、行を追加するよりも特徴量を追加する方が性能へのインパクトが大きくなります。ここまでで、SparkとPandas UDFを用いることでSHAP値をより高速に計算できることを見てきました。それでは、追加の特徴量/カラムに対してSHAPがどのように動作するのかを見ていきましょう。
直感的に、データサイズの増加は、SHAPアルゴリズムを実行するためにより多くの計算が必要になることを意味します。図3では、異なる行、列の数に対する16ノードクラスターのSHAP値の計算時間を示しています。行の増加とおおよそ比例して実行時間が増加しており、行数が2倍になると実行時間もおおよそ2倍になります。カラム数の増加は実行時間と比例関係にあり、1カラムの追加は実行時間を約80%増加させています。
これらの観察(図2と図3)から、データ量の増加に対して、実行時間を現実的な範囲に収めるために、計算処理を水平にスケールさせる(より多くのワーカーノードを追加する)ことができると結論づけました。
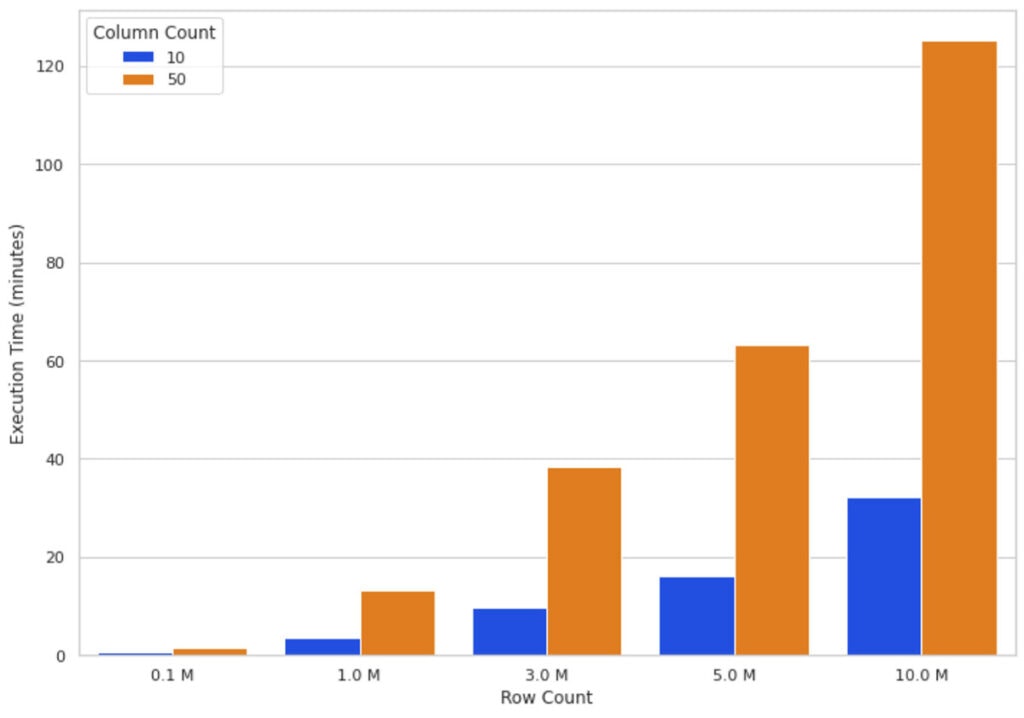
図3: 異なる行、列のデータに対する16ノードの並列SHAP計算時間
いつ並列化を考えるべきか?
ここでお答えしたい質問は*並列化の価値が出るのはいつか?追加の知識が必要だとしても、SHAP計算を並列化するためにいつPySparkを使い始めるべきか?*です。我々は、SHAP計算時間を改善するためにクラスターサイズを2倍にすることの効果を計測する実験を行いました。この実験の目的は、どの程度のサイズのデータであれば、問題に対してより多くの水平リソースを投入する(より多くのワーカーノードを追加)ことを正当化できるのかを検証することです。
我々は10カラムのデータの行数を10、100、1000から10Mに増加させて、SHAP計算を実行しました。それぞれの行数において、クラスターサイズを2、4、32、64として、4回実行時間を計測しました。実行時間の比率は、同じSHAP値の計算に対して、半分のサイズ(2と32)のクラスターの実行時間に対する、大規模クラスターサイズ(4と64)の実行時間の比率となります。
図4では実験結果を示しています。キーとなる知見を以下に示します。
- 小規模な行数においては、クラスターサイズを2倍にしても実行時間は改善されません。いくつかのケースでは、Sparkタスク管理によるオーバーヘッドによって性能が悪化します(このため、Execution Time Ratioが1より大きくなっています)。
- 行数を増やすと、クラスターサイズを倍増させることはより効果的になります。10M行のデータに対しては、クラスターサイズを倍増させることで、実行時間を約半分にすることができます。
- すべての行数においては、クラスターサイズを32から64にするよりも、2から4にする方がより効果的になります(青とオレンジの線のギャップに注目してください)。クラスターサイズが大きくなると、より多くのノードを追加する際のオーバーヘッドも増加します。これは、パーティションあたりのデータサイズが小さくなりすぎて、より適切なデータ/パーティションサイズではなく、小さいデータを処理するために別個のタスクを生成するオーバーヘッドによるものです。
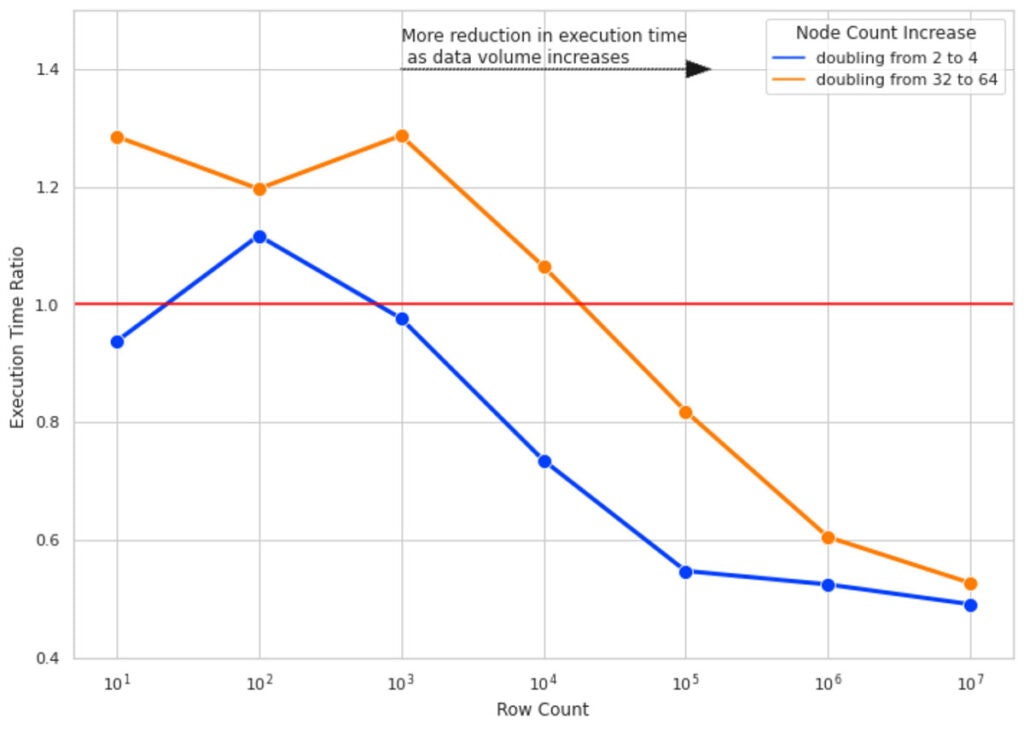
図4: 異なるデータボリュームにおいて、クラスターサイズを倍増させることによる実行時間への影響
学び
再パーティショニング
上で説明したように、Sparkはパーティションの概念を用いて並列処理を実装しています。データは行の塊(パーティション)に分割され、それぞれのパーティションはデフォルトでは単一のコアで処理されます。Apache Sparkによって最初にデータが読み込まれた際、お使いのクラスターで処理を実行したい計算処理に最適化されていない場合があります。特に、SHAP値を計算する際には、使用しているデータセットを再パーティショニングすることでより優れた性能を得られる可能性があります。
作成することによるオーバーヘッドが計算の並列化のメリットを上回ってしまうような、小さすぎるパーティションをしないように、適切なバランスを見出すことが重要となります。
我々のパフォーマンステストにおいては、以下のコードを用いてクラスターの全てのコアを活用することにしました。
df = df.repartition(sc.defaultParallelism)
より大きいボリュームのデータに対して、コア数の2あるいは3倍の値を設定したいと考えるかもしれません。重要なのは、お使いのデータに対して実験を行い、ベストなパーティショニング戦略を見つけ出すことです。
display()の使用
Databricksノートブックを使用している場合、実行時間をベンチマークする際にdisplay()関数の使用を避けたいと考えるかもしれません。display()を使用した場合、全体の変換処理がどの程度の時間を要したのかを示さない場合があります。ファイルへの書き込みなど計測したい処理に依存して、クエリーに投入される行数に暗黙的な制限が存在し、ドライバーに結果を集約する際の追加のオーバーヘッドが含まれます。我々は、Sparkのwriteの"noop"フォーマットを用いて実行時間を計測しました。
まとめ
この記事では、PySparkとPandas UDFを用いて並列化を行うことで、SHAP計算を高速化するソリューションを紹介しました。そして、データボリュームの増加、異なるマシンタイプ、設定変更に対するソリューションのパフォーマンスを評価しました。キーとなる知見を以下に示します。
- シングルノードのSHAP計算においては、行数、カラム数の増加に対して実行時間は線形に増加します。
- PySparkによるSHAP計算の並列化によって、お使いのクラスターの全CPUを用いて計算を行うことで性能を改善します。
- データボリュームが大きい場合、クラスターサイズの増加はより効果的なものになります。小規模データに対しては、この方法は効果的ではありません。
今後の取り組み
垂直スケーリング - このブログ記事の目的は、大規模データセットに対するSHAP値計算のパフォーマンスを改善するために、どのように水平にスケーリングできるかを説明するというものでした。我々は、クラスターのそれぞれのノードが4コア、メモリー30.5GBというところからスタートしました。将来、並列に加えて垂直のスケーリングすることによる性能改善を検証することは興味深いものであると考えています。例えば、4ノードのクラスター(4コア、メモリー30.5GB)と2ノードのクラスター(8コア、メモリー61GB)の性能を比較するというものです。
シリアライズ/デシリアライズ - 説明した通り、Python UDFではなくPandas UDFを使用した主要な理由は、Pandas UDFではJVMとpythonのプロセスとの間のシリアライぜーション/デシアライゼーションの性能を改善するためにApache Arrowを使用しているということがあります。Arrowのバッチサイズを実験することで、SparkのデータパーティションをArrowのレコードバッチに変換する際の最適化を行える余地があり、これによって、さらなる性能改善の可能性があります。
分散SHAP実装との比較 - 我々のソリューションの結果と、Shparkleyのような分散SHAP実装とを比較するのも面白いかもしれません。このような比較調査を行う際には、最初の時点で双方のソリューションの出力を比較できるようにしておくことが重要です。