こちらのもくもく会の資料です。
冒頭の説明資料はこちら。
はじめに
本記事では、Databricks Free Editionを使用したLakeflow SDPのハンズオン演習の流れを解説します。PySpark による命令型ETLから始め、Lakeflow SDPによる宣言型パイプライン、データ品質チェック、ジョブによる自動化までを体験します。
前提条件
- Databricks Free Edition のアカウント
- 基本的なSQLの知識
事前準備: 演習ファイルの取り込み
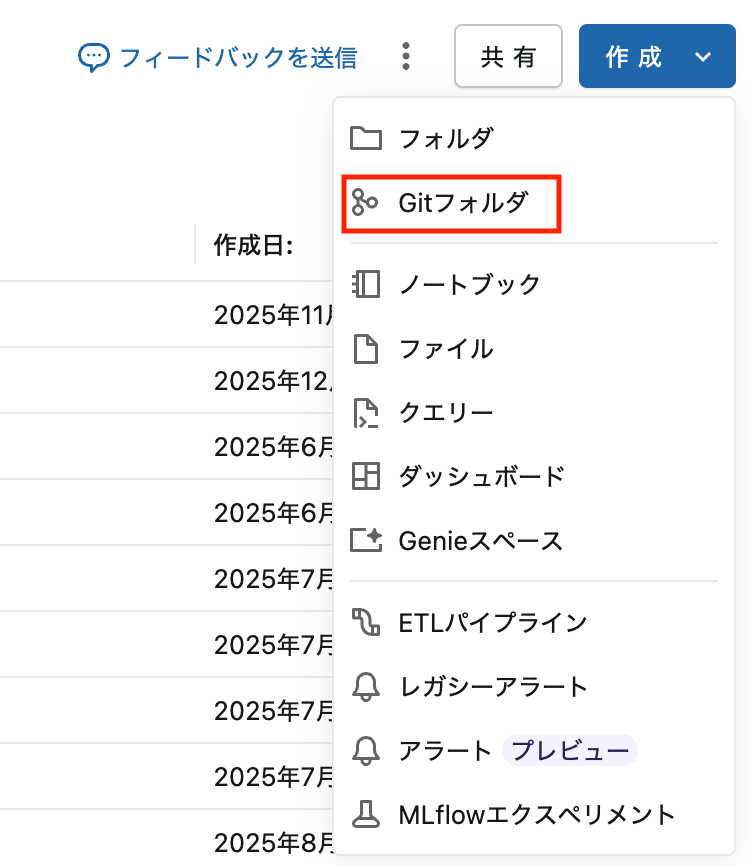
Step 1: Gitフォルダを開く
- 左サイドバーの ワークスペース をクリック
- 画面右上の 作成 をクリック
- Gitフォルダ をクリック
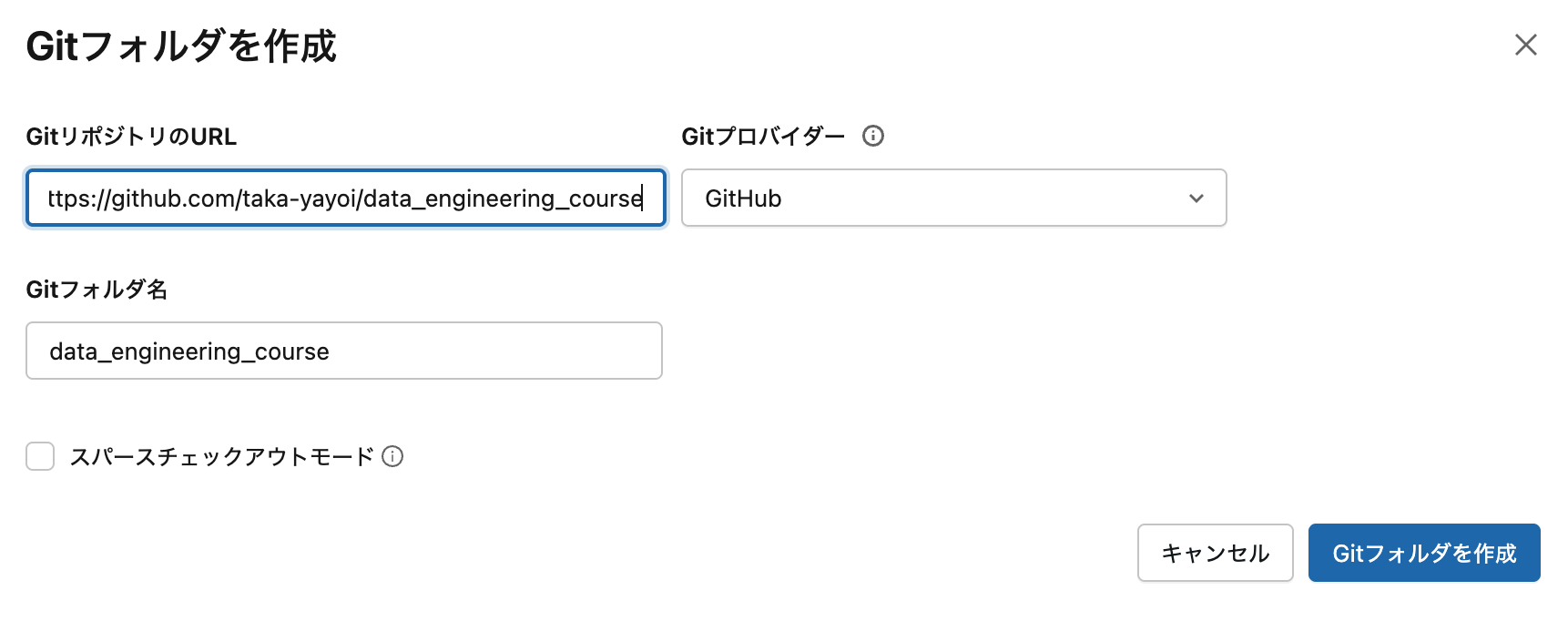
Step 2: リポジトリURLを入力
以下のURLを入力します:
https://github.com/taka-yayoi/data_engineering_course
URLを入力するとフォルダ名は自動で「data_engineering_course」になります。そのまま Gitフォルダを作成 をクリックします。
Step 3: ファイル構成を確認
クローン後のフォルダ構成:
📁 data_engineering_course/
├── 📄 README.md
├── 📁 notebooks/
│ ├── 📓 exercise_part1_imperative.py ← 演習1
│ └── 📓 exercise_part4_jobs.py ← 演習4(参考資料)
└── 📁 pipelines/
├── 📄 pipeline_basic.sql ← 演習2(リファレンス)
└── 📄 pipeline_with_expectations.sql ← 演習3(リファレンス)
演習1: PySparkによる命令型ETL
2/3のもくもく会では次の演習2から着手ください。時間が余ったら演習1を試してみてください。
この演習では、PySparkを使用してBronze → Silver → Goldのメダリオンアーキテクチャを手動で実装します。
目標
- DataFrameの基本操作を理解する
- 変換(Transformation)とアクション(Action)の違いを体験する
- メダリオンアーキテクチャの各層の役割を理解する
手順
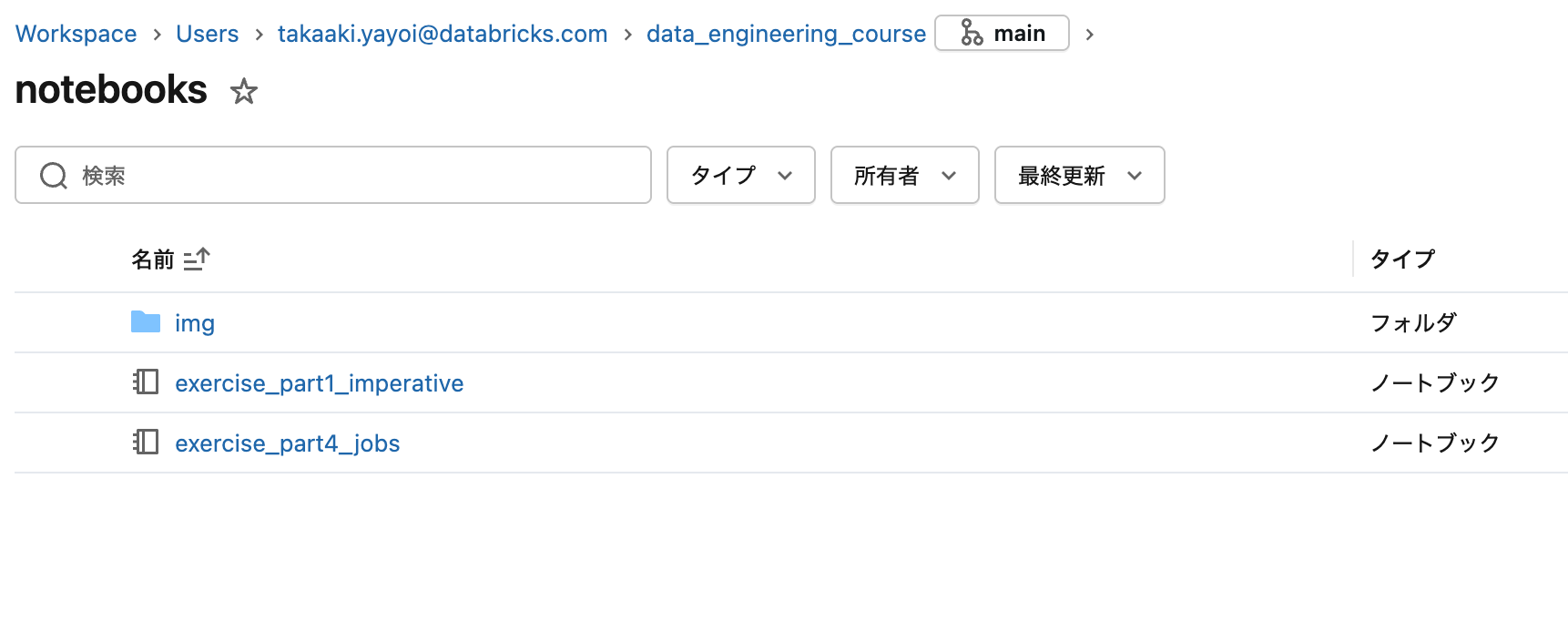
1. ノートブックを開く
data_engineering_course → notebooks → exercise_part1_imperative.py を開きます。
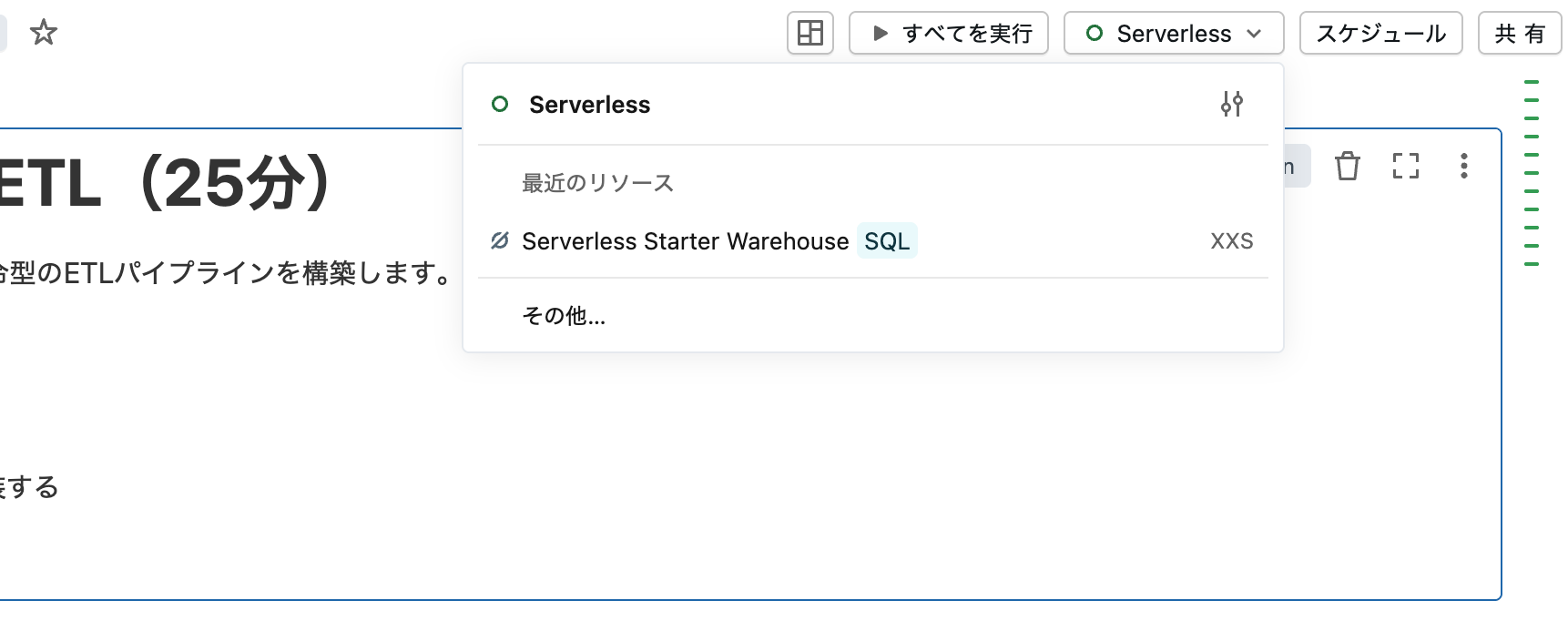
2. クラスターに接続
画面右上の 接続 をクリックし、利用可能なクラスターを選択します。
3. セルを順番に実行
各セルを順番に実行していきます。ノートブックでは以下の処理を行います:
Bronze層: 生データの取り込み
bronze_df = spark.table("samples.nyctaxi.trips")
bronze_df.write.mode("overwrite").saveAsTable("bronze_trips")
Silver層: データのクレンジング・フィルタリング
silver_df = bronze_df.filter(
(col("fare_amount") > 0) &
(col("trip_distance") > 0)
)
silver_df.write.mode("overwrite").saveAsTable("silver_trips")
Gold層: ビジネス集計
gold_df = silver_df.groupBy("pickup_zip").agg(
count("*").alias("trip_count"),
avg("fare_amount").alias("avg_fare")
)
gold_df.write.mode("overwrite").saveAsTable("gold_trips_by_pickup")
4. 結果を確認
カタログエクスプローラーで作成されたテーブルを確認します。
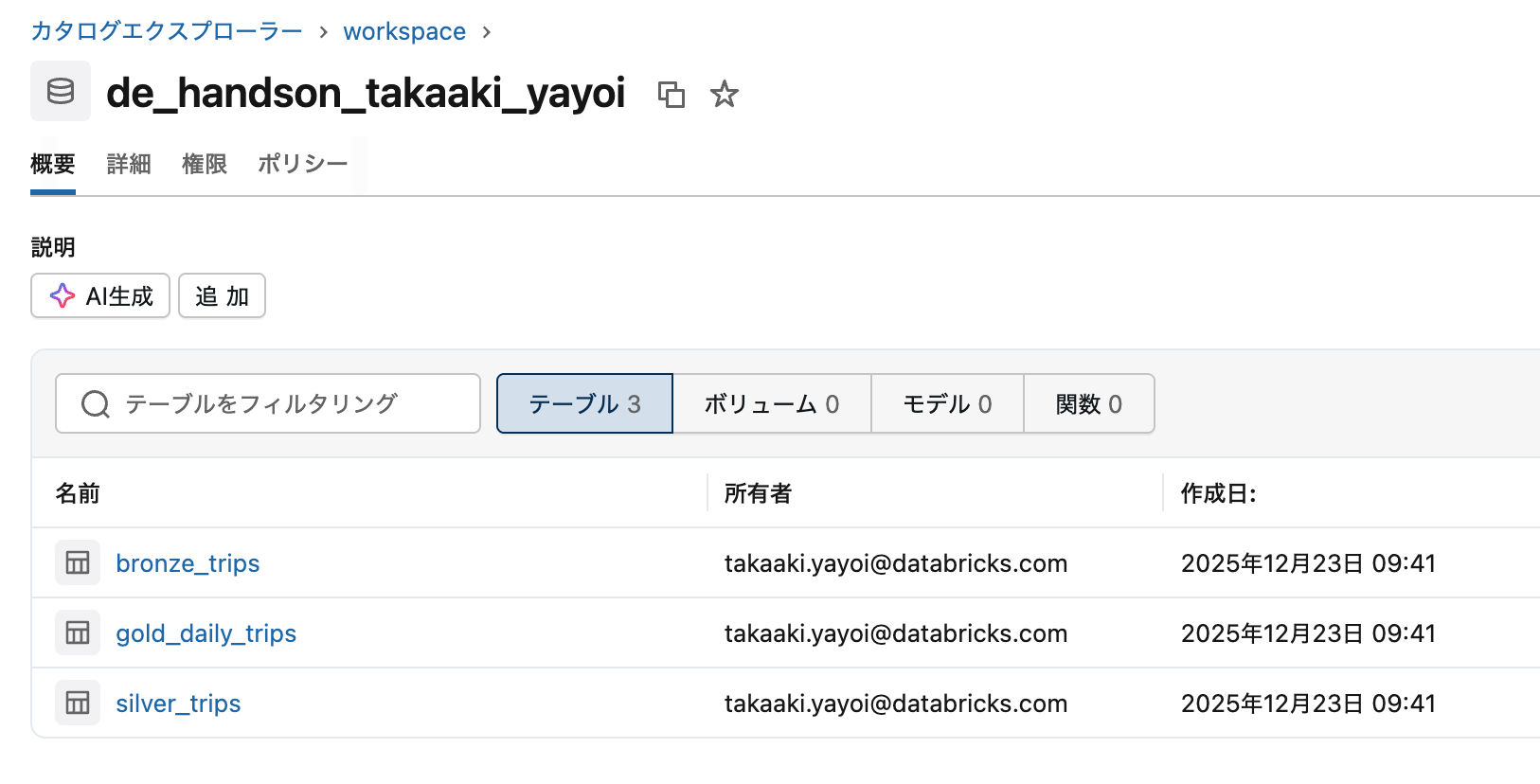
ポイント
- 命令型では「どのように処理するか」を逐一記述する
- 依存関係の管理、エラーハンドリング、再実行ロジックは自分で実装が必要
演習2: Lakeflow SDP 宣言型パイプライン
この演習では、演習1と同じ処理をLakeflow SDPで宣言的に実装します。
目標
- 宣言型パイプラインの記述方法を理解する
- マテリアライズドビュー(MV)の概念を理解する
- 命令型との違いを体感する
手順
1. パイプラインを作成
左サイドバーから データエンジニアリング → パイプライン を選択し、パイプラインを作成 をクリックします。
![パイプライン作成]
2. パイプライン設定
以下の設定を入力します:
| 項目 | 値 |
|---|---|
| パイプライン名 |
sdp_nyctaxi_pipeline (任意) |
| カタログ | workspace |
| スキーマ | 新規作成 (例: sdp_handson) |
| ソースコード | 空のファイルで開始 |
| 言語 | SQL |
![パイプライン設定画面]
3. Bronze層を記述
エディタに以下のSQLを入力します:
-- Bronze: 生データの取り込み
CREATE MATERIALIZED VIEW bronze_trips AS
SELECT * FROM samples.nyctaxi.trips
ドライラン をクリックして構文を確認します。
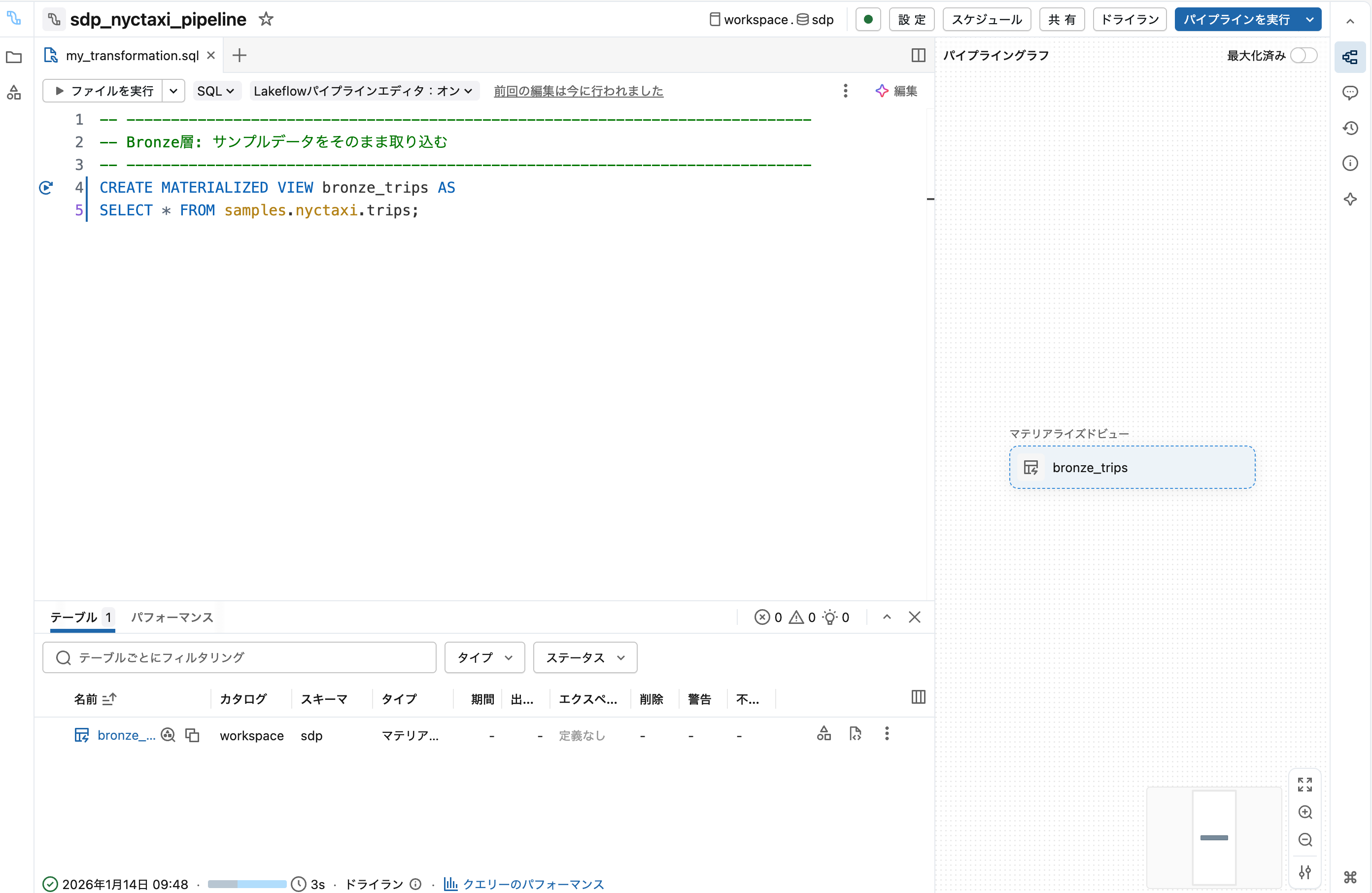
4. Silver層を追加
エディタに以下を追記します:
-- Silver: クレンジング済みデータ
CREATE MATERIALIZED VIEW silver_trips AS
SELECT *
FROM bronze_trips
WHERE fare_amount > 0
AND trip_distance > 0
ドライラン をクリックして依存関係が認識されることを確認します。
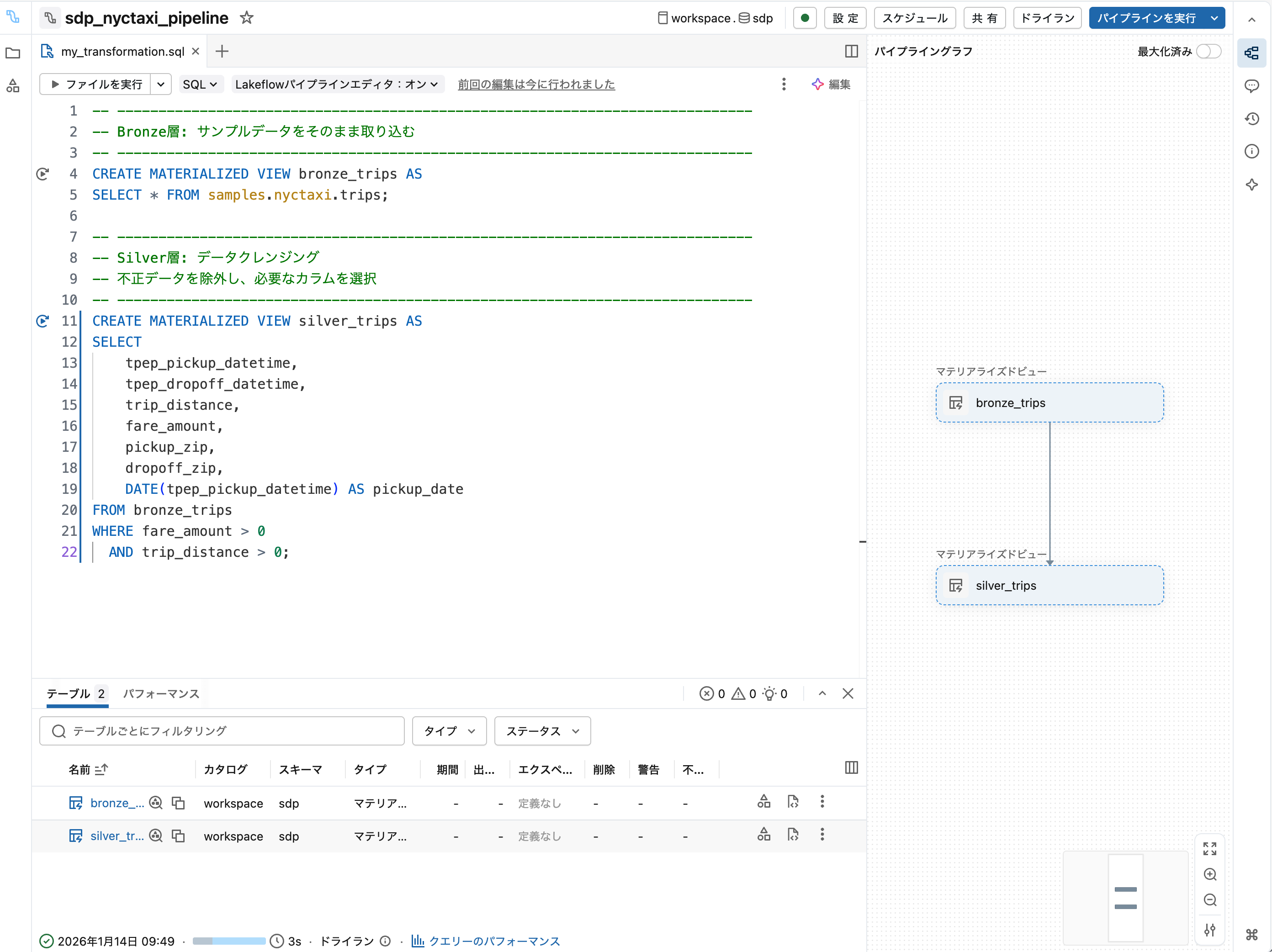
5. Gold層を追加
エディタに以下を追記します:
-- Gold: ビジネス集計
CREATE MATERIALIZED VIEW gold_trips_by_pickup AS
SELECT
pickup_zip,
COUNT(*) AS trip_count,
AVG(fare_amount) AS avg_fare
FROM silver_trips
GROUP BY pickup_zip
ドライラン で全体の依存関係を確認します。
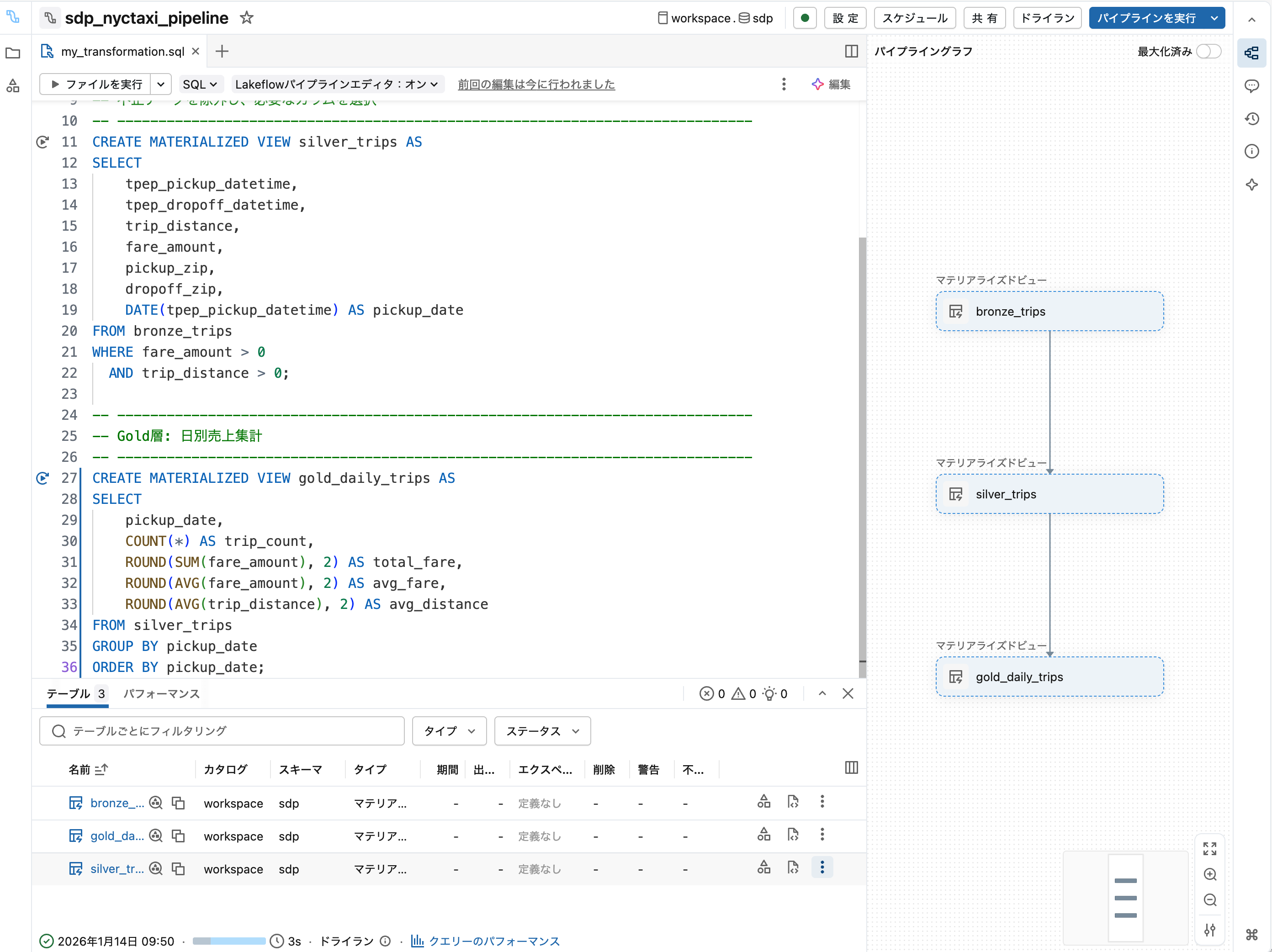
6. パイプラインを実行
実行 をクリックしてパイプラインを実行します。
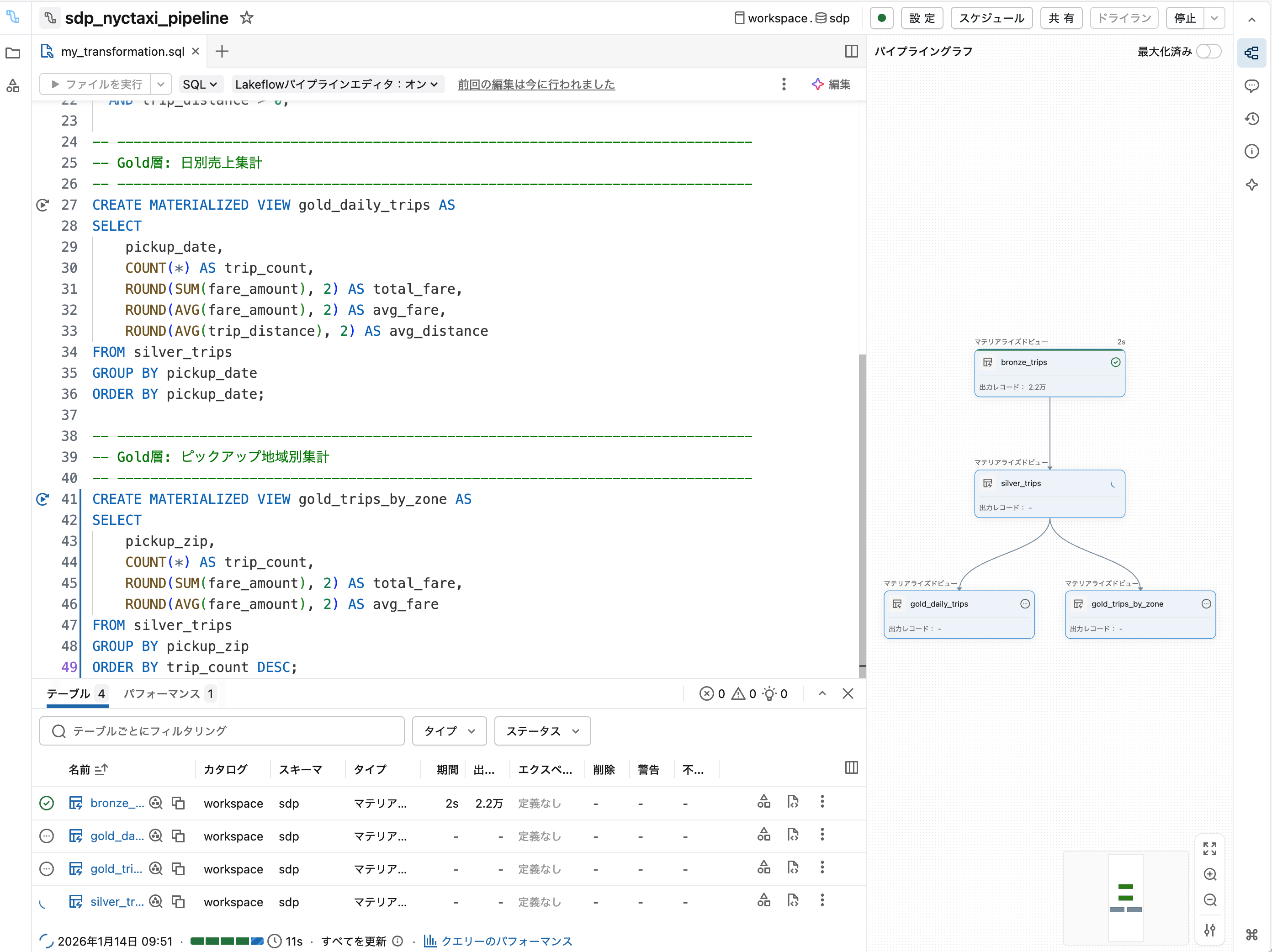
実行完了後、各テーブルのレコード数や処理時間を確認できます。
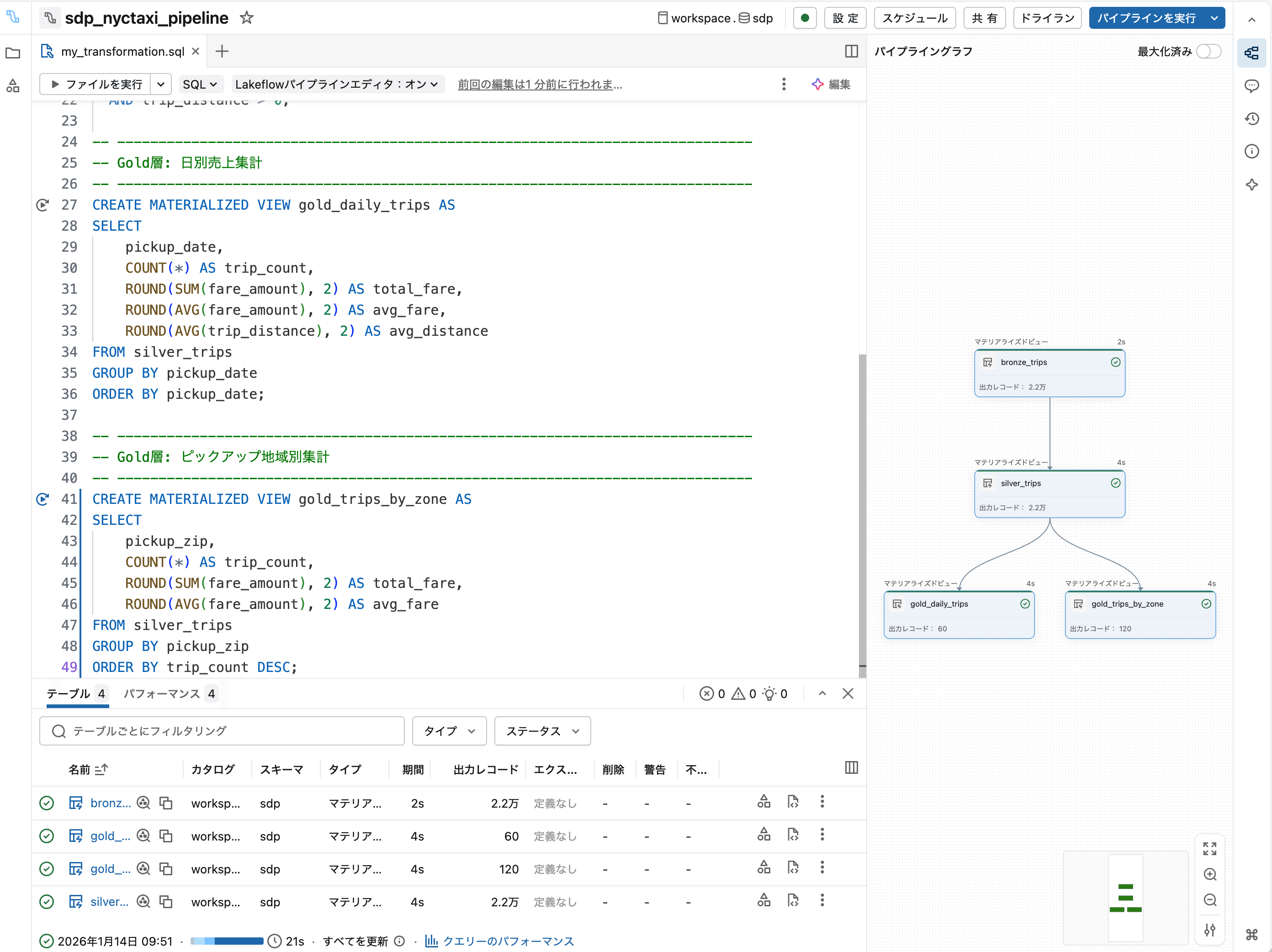
ポイント
- 宣言型では「何が欲しいか」を記述するだけ
- 依存関係はSDPが自動で解決
- ドライランで何度でも構文確認できる(データ処理は走らない)
- 実行時にマテリアライズドビューが実体化される
演習3: エクスペクテーションの追加
この演習では、演習2で作成したパイプラインにデータ品質チェックを追加します。
目標
- エクスペクテーション(データ品質制約)の記述方法を理解する
- 品質違反時の挙動を確認する
- 既存パイプラインへの後付けが容易であることを体験する
手順
1. パイプラインを編集モードで開く
演習2で作成したパイプラインを開き、編集 をクリックします。
2. Silver層にエクスペクテーションを追加
Silver層の定義を以下のように修正します:
-- Silver: クレンジング済みデータ(品質チェック付き)
CREATE MATERIALIZED VIEW silver_trips (
CONSTRAINT valid_fare EXPECT (fare_amount > 0),
CONSTRAINT valid_distance EXPECT (trip_distance > 0)
) AS
SELECT *
FROM bronze_trips
WHERE fare_amount > 0
AND trip_distance > 0
3. ドライランで確認
ドライラン をクリックして構文エラーがないことを確認します。
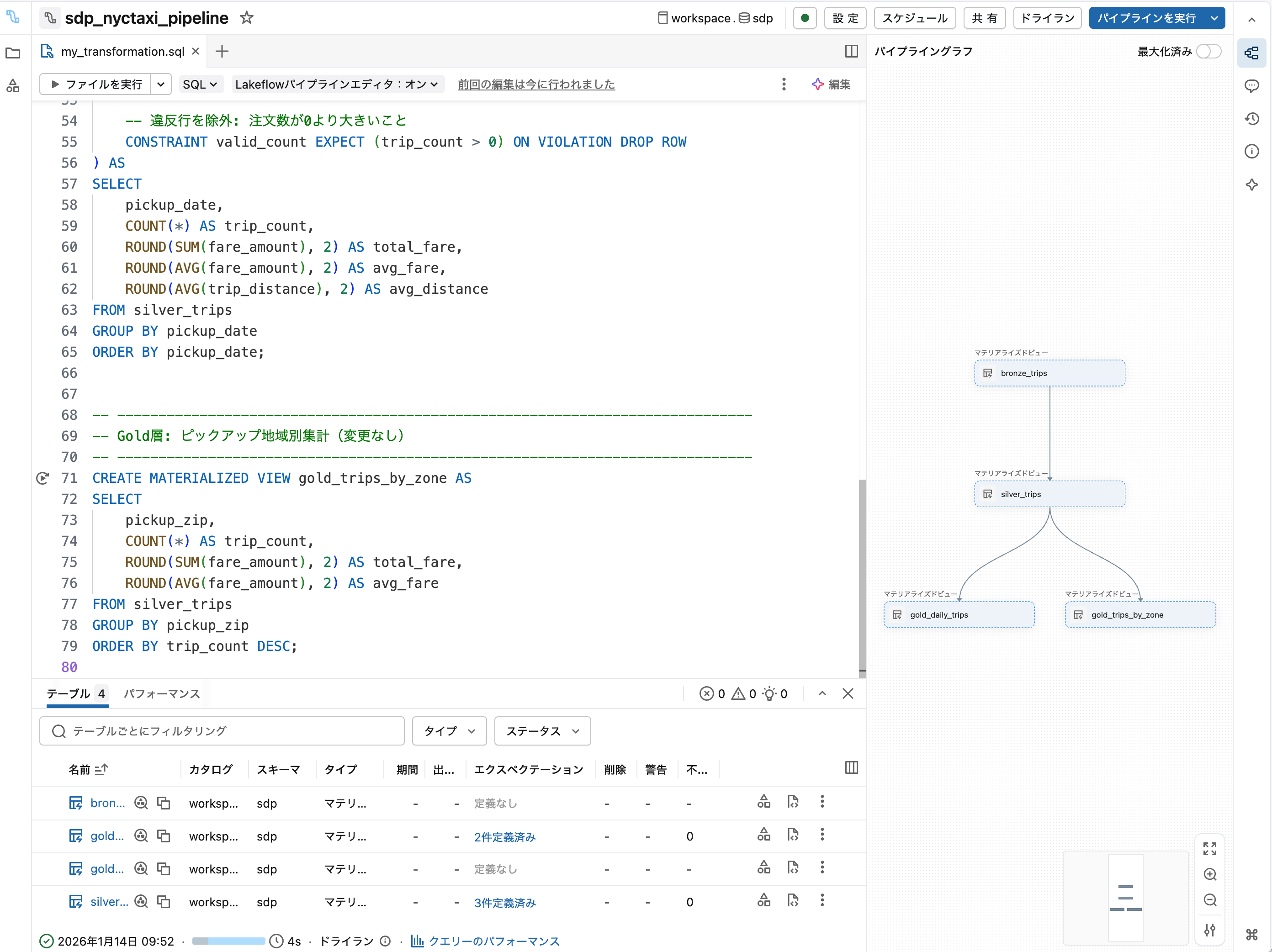
4. パイプラインを実行
実行 をクリックします。マテリアライズドビューなので、フルリフレッシュではなく通常の「実行」で問題ありません。
5. エクスペクテーション結果を確認
実行完了後、silver_tripsをクリックしてエクスペクテーションの結果を確認します。
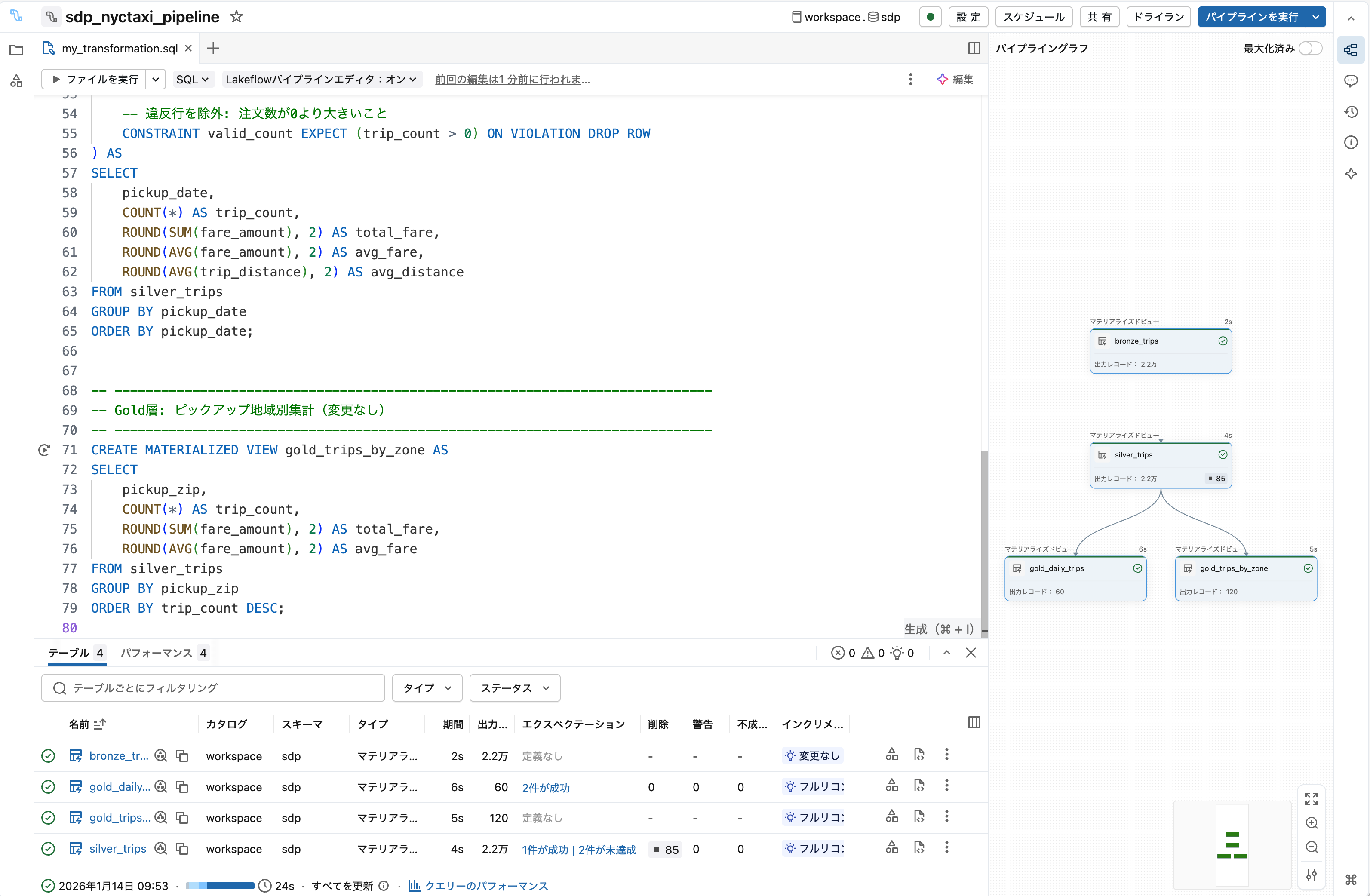
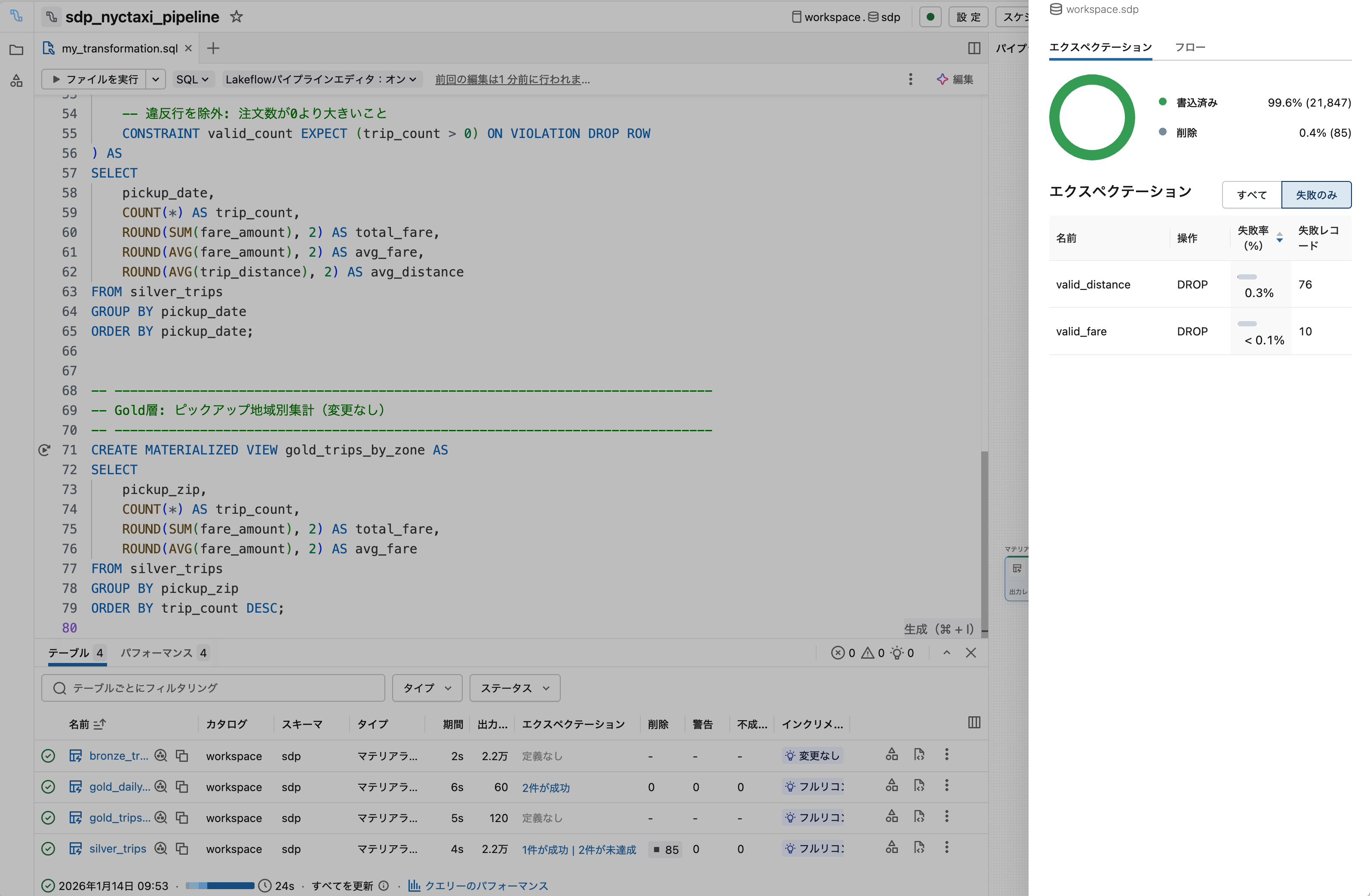
ポイント
- エクスペクテーションはデータ品質の「監視」機能
- WHERE句で除外 + エクスペクテーションで監視が一般的なパターン
- 既存パイプラインにCONSTRAINT句を追加するだけで品質チェックを後付け可能
- SDPの宣言型アプローチにより、定義変更が容易
補足: エクスペクテーションのアクション
| アクション | 違反時の挙動 |
|---|---|
EXPECT (デフォルト) |
警告のみ、処理続行 |
EXPECT ... ON VIOLATION DROP ROW |
違反行を除外 |
EXPECT ... ON VIOLATION FAIL UPDATE |
パイプライン失敗 |
演習4: ジョブによる自動化
2/3のもくもく会では、演習2-3が終わってから時間が余ったら試してみてください。
この演習では、作成したパイプラインをジョブとしてスケジュール実行する設定を行います。
目標
- Lakeflowジョブの作成方法を理解する
- スケジュール実行の設定方法を理解する
- パイプラインの運用イメージを掴む
手順
1. ジョブを作成
左サイドバーから ワークフロー を選択し、ジョブを作成 をクリックします。
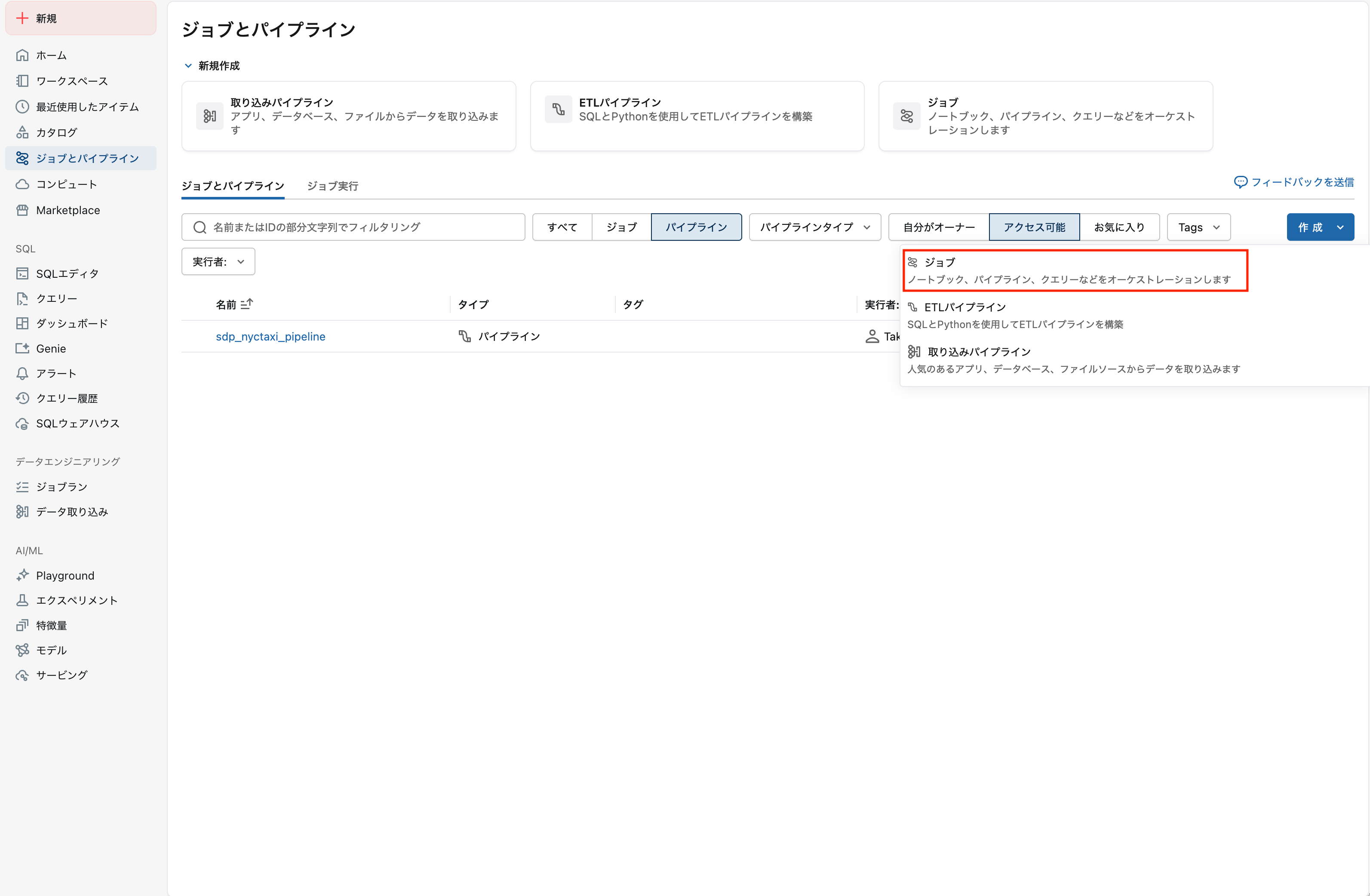
パイプラインをクリックします。
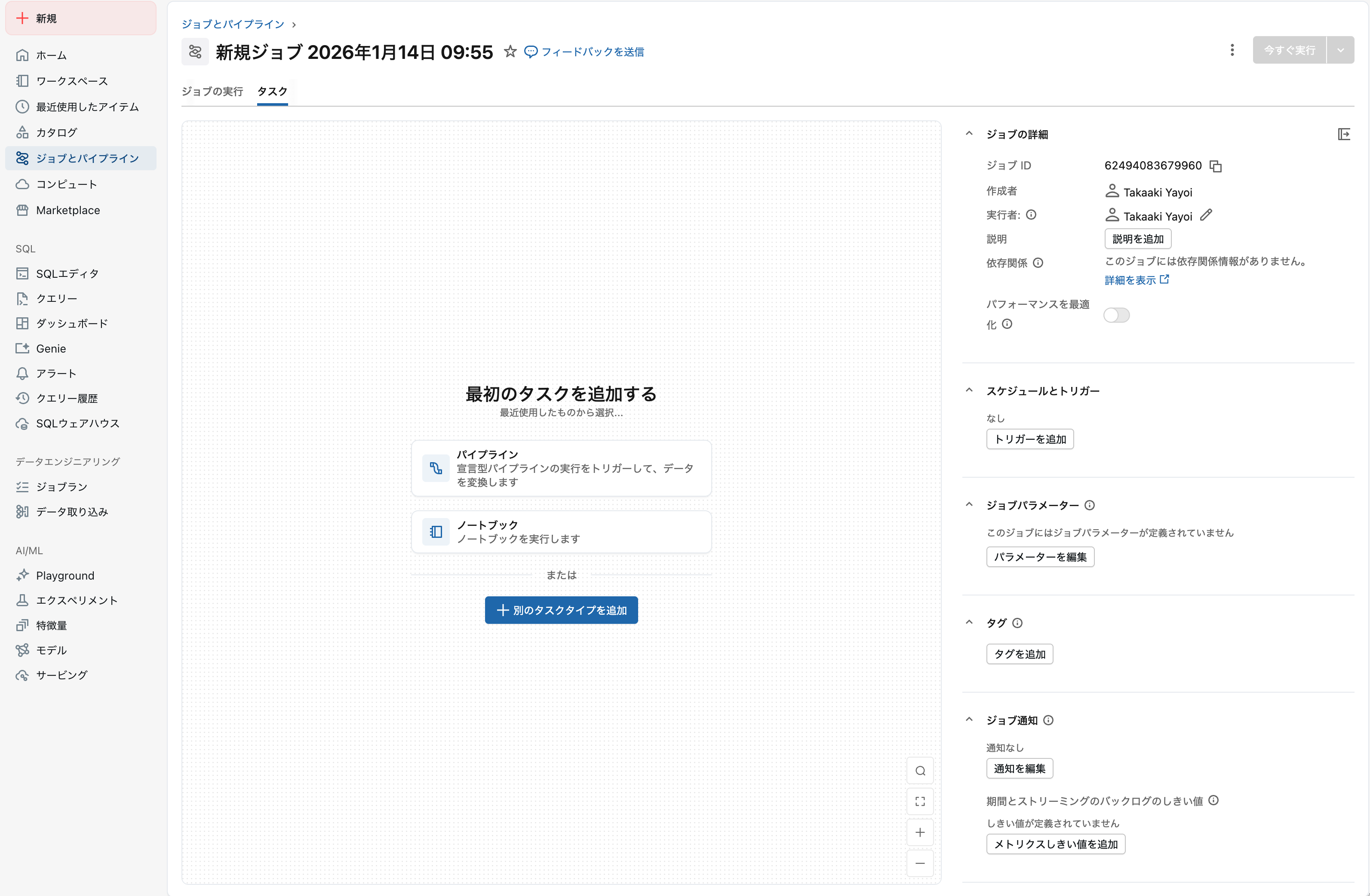
2. タスクを設定
以下の設定を入力します:
| 項目 | 値 |
|---|---|
| タスク名 | run_sdp_pipeline |
| タイプ | パイプライン |
| パイプライン |
sdp_nyctaxi_pipeline (演習2-3で作成したもの) |
タスクを設定したらタスクを作成をクリックします。
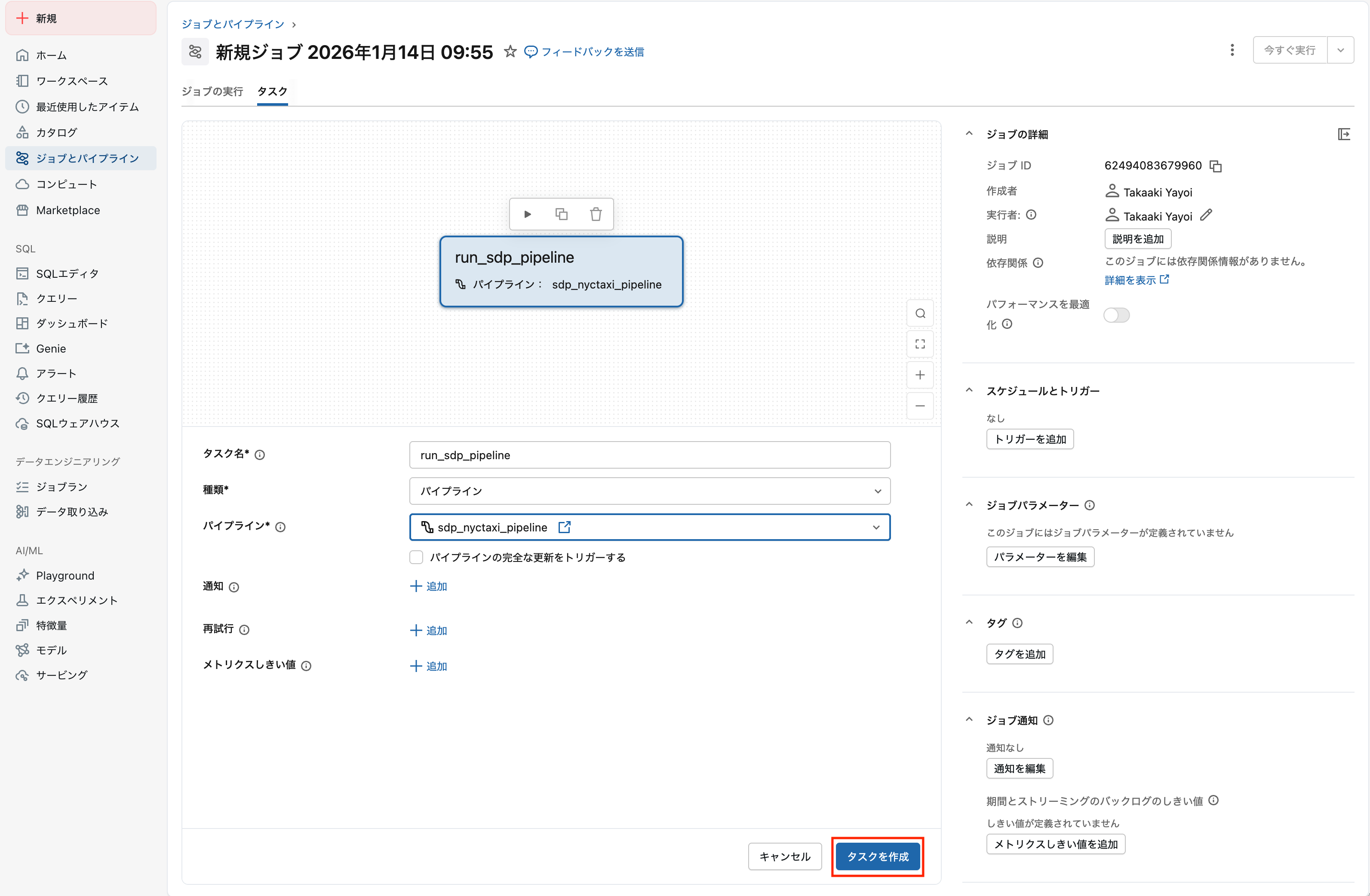
左上のジョブ名をわかりやすいものにします。
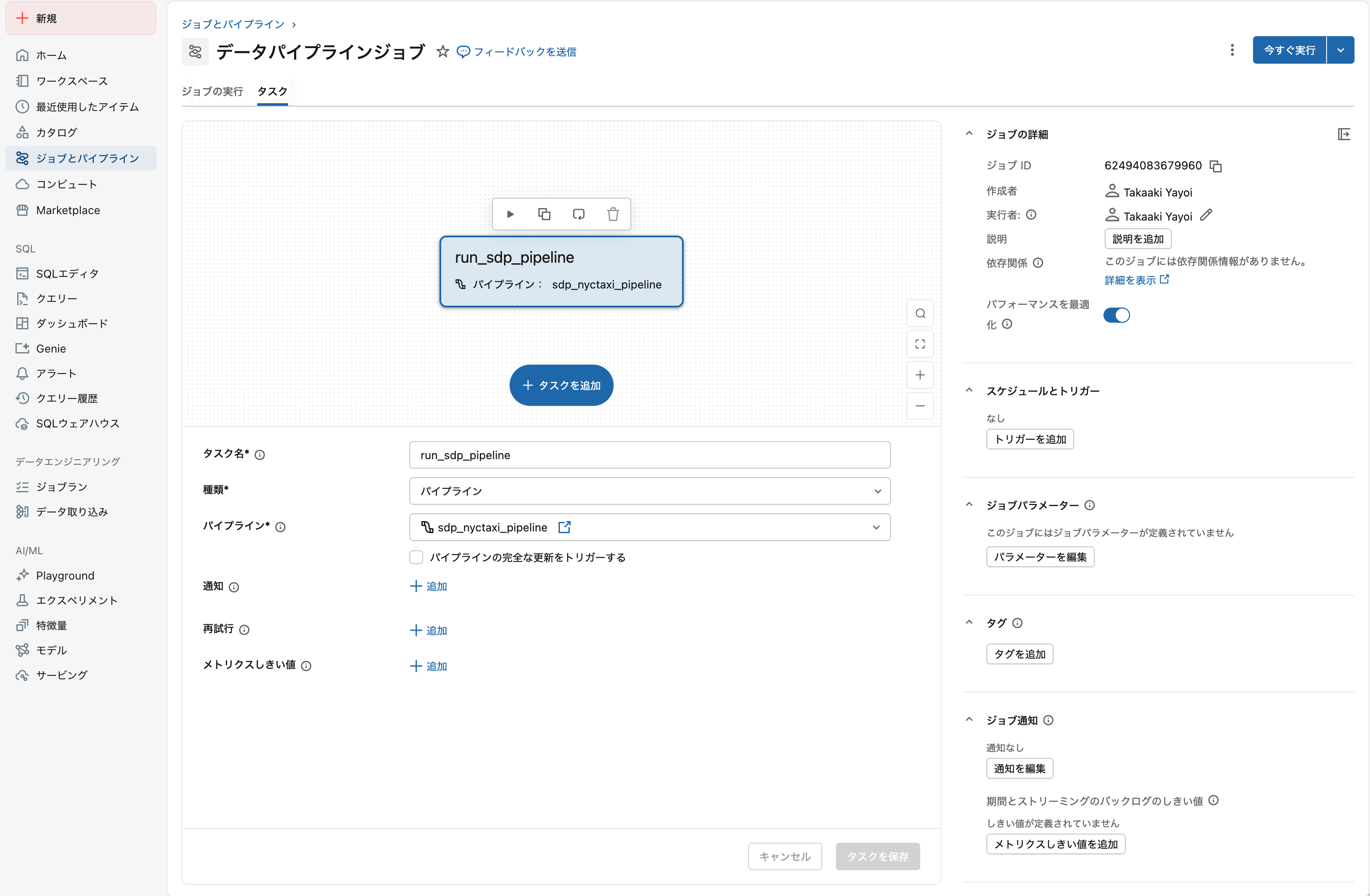
3. ジョブを手動実行
今すぐ実行 をクリックしてジョブを実行します。
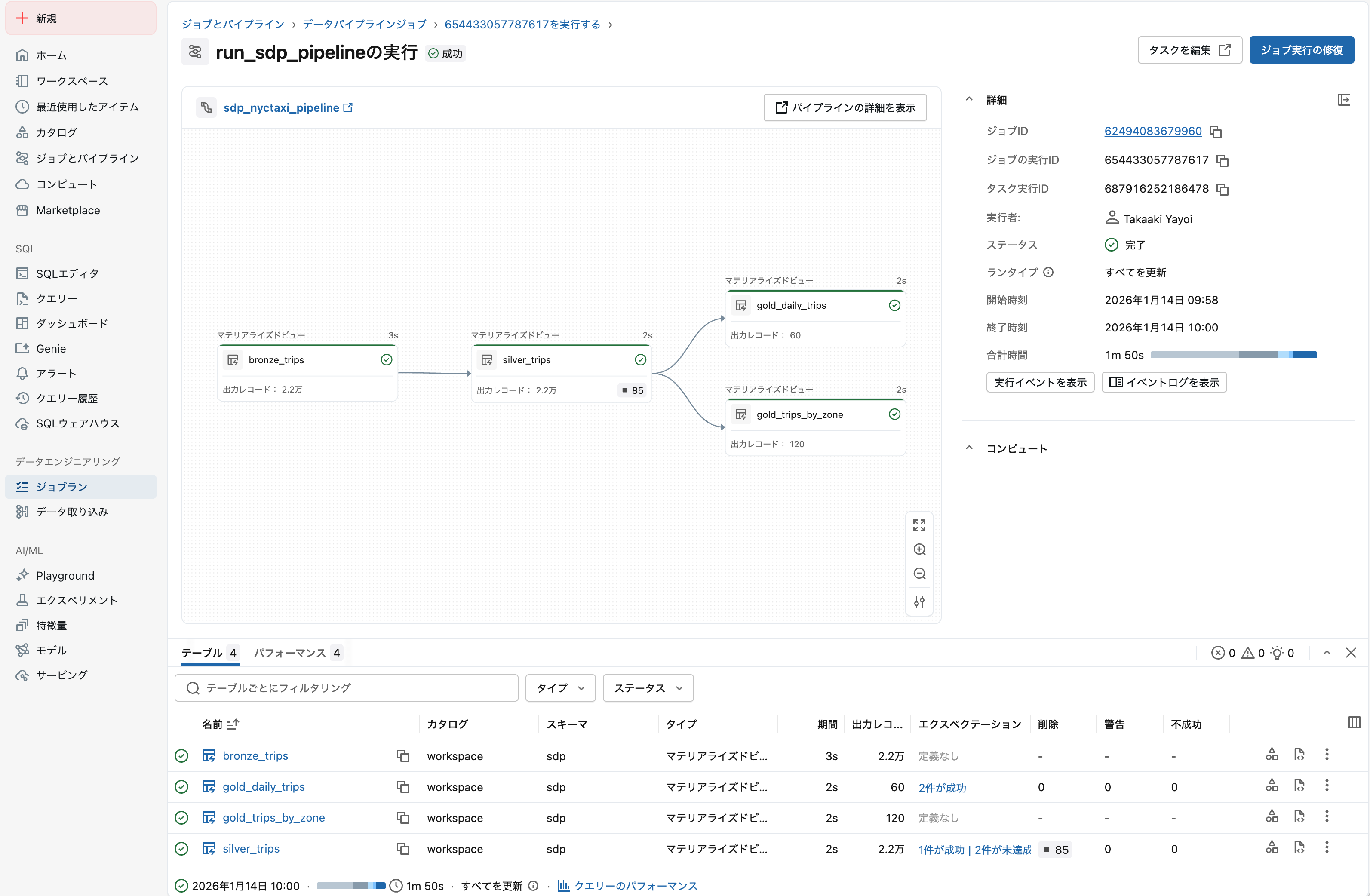
4. 実行結果を確認
実行 タブで実行履歴と結果を確認します。
5. スケジュールを設定(オプション)
スケジュールとトリガー タブで定期実行の設定が可能です。
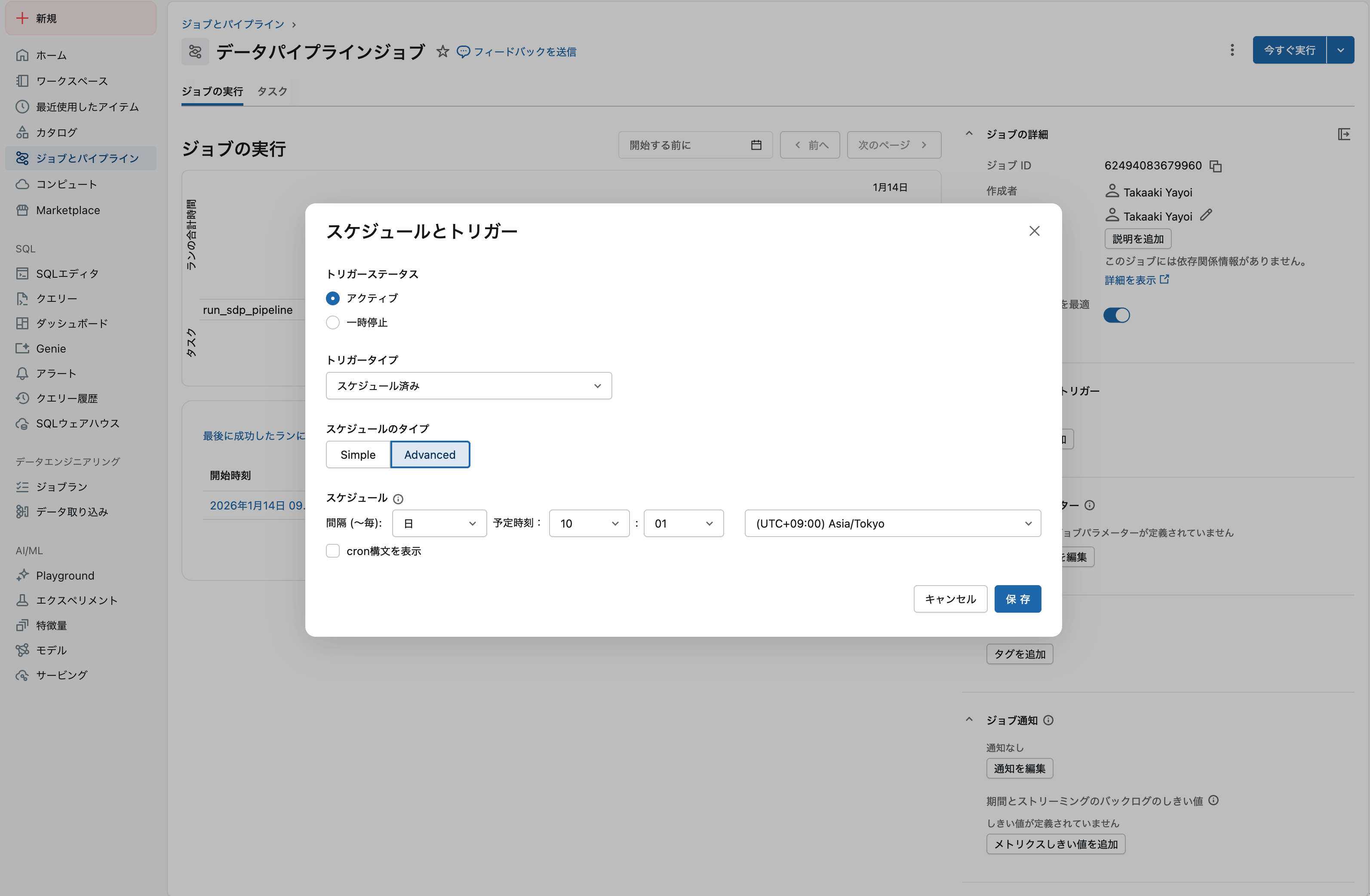
設定後は 一時停止 をクリックして、意図しない実行を防ぎましょう。
ポイント
- ジョブはパイプラインの「いつ実行するか」を管理
- スケジュール(Cron)、ファイル到着、テーブル更新など様々なトリガーに対応
- 本番運用では、アラート設定やリトライ設定も重要
まとめ
| 演習 | 学んだこと |
|---|---|
| 演習1 | PySparkによる命令型ETL、メダリオンアーキテクチャ |
| 演習2 | Lakeflow SDPによる宣言型パイプライン、MV |
| 演習3 | エクスペクテーションによるデータ品質チェック |
| 演習4 | ジョブによるパイプラインの自動実行 |
命令型 vs 宣言型
| 観点 | 命令型(PySpark) | 宣言型(SDP) |
|---|---|---|
| 記述内容 | 「どのように」処理するか | 「何が」欲しいか |
| 依存関係 | 手動で管理 | 自動で解決 |
| エラー処理 | 自分で実装 | フレームワークが対応 |
| 再実行 | ロジック実装が必要 | 自動で差分処理 |
参考資料
- Lakeflow SDP入門: 基礎から実践まで #Databricks - Qiita
- Databricksドキュメント | Databricks on AWS
- Databricksによるデータエンジニアリング | Databricks on AWS
- Lakeflow Spark宣言型パイプライン | Databricks on AWS